并发容器(Map、List、Set)原理
文章目录
- 并发容器(Map、List、Set)原理
-
- JUC下的并发容器
- CopyOnWriteArrayList
-
- 应用场景
- 常用API方法
- 原理
- 缺陷
- 迭代器的 fail-fast 与 fail-safe 机制
- ConcurrentHashMap
-
- 简介
- 常用API
- 数据结构
- 实现原理
- ConcurrentSkipListMap
-
- 简介
- 跳表
- 基本用法
并发容器(Map、List、Set)原理
JUC下的并发容器
jdk1.5时是基于synchronized实现的同步容器,直接在方法上或者一大段同步代码块中使用的synchronized,所有读写操作全是串行。
之后进行了优化,才有了并发容器
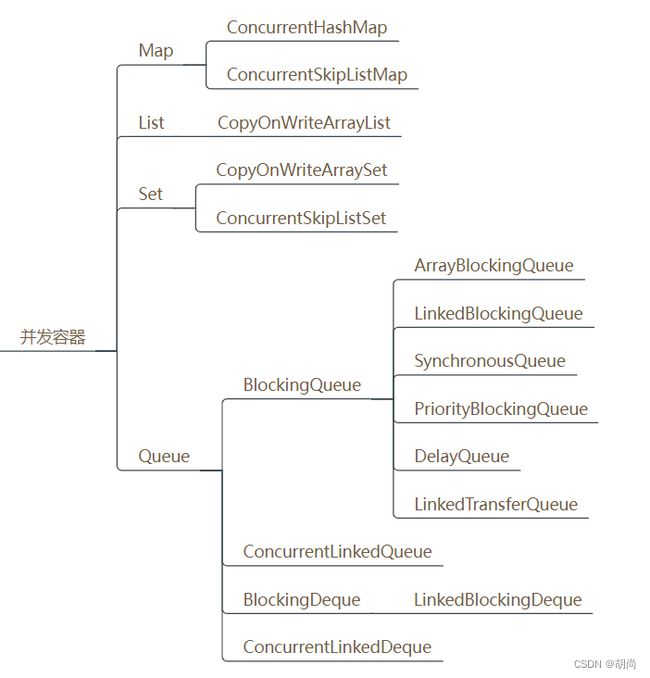
接下来介绍几个典型的并发容器
CopyOnWriteArrayList
应用场景
-
读多写少
-
不需要获取实时更新的数据
添加操作时会创建一个新数据,在新数据中添加,此时读取的还是老数据中的数据
-
数据量不大
如果数据量很大,那么拷贝的数组比较占内存空间
常用API方法
// 创建一个 CopyOnWriteArrayList 对象
CopyOnWriteArrayList phaser = new CopyOnWriteArrayList();
// 新增
copyOnWriteArrayList.add(1);
// 设置(指定下标)
copyOnWriteArrayList.set(0, 2);
// 获取(查询)
copyOnWriteArrayList.get(0);
// 删除
copyOnWriteArrayList.remove(0);
// 清空
copyOnWriteArrayList.clear();
// 是否为空
copyOnWriteArrayList.isEmpty();
// 是否包含
copyOnWriteArrayList.contains(1);
// 获取元素个数
copyOnWriteArrayList.size();
原理
CopyOnWriteArrayList底层采用的是写时复制的机制,当需要添加元素时,会创建一个新的数组出来,在新数组中进行插入操作,然后在修改属性的引用。

add()方法如下所示
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 加锁,多线程写写还是互斥的
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 创建一个比老数组长度+1的新数组,并把老数组数据拷贝到新数组中
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 把要插入的元素插入到最后位置
newElements[len] = e;
// 修改array属性的引用
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
缺陷
- 写操作时会拷贝数组,会消耗内存,可能会导致MinorGC或FullGC
- 不能实时读取最新的数据,只能保证最终一致性,因为读取时还是读取的老数组
- 适合于读多写少的场景,并且数据量不能太大,不然每次set/add都需要重新复制数组,代价比较大
迭代器的 fail-fast 与 fail-safe 机制
从下图可以发现,集合最终都是实现了Interable迭代器接口
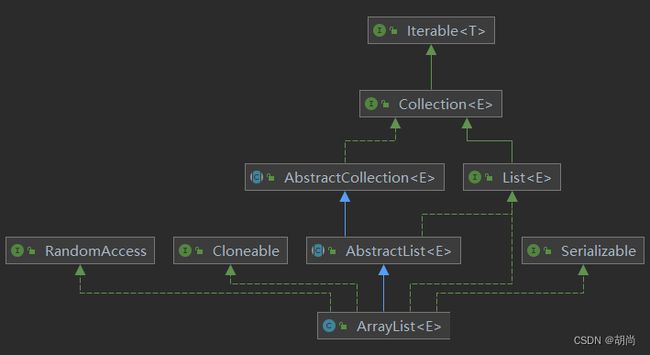
在JAVA中,迭代器在迭代的过程中如果发生了元素的修改或更新操作,迭代器一般会有两种行为表现:fail-fast 、fail-safe
fail-fast
ArrayList、HashMap 等,它们的迭代器默认都是采用 Fail-Fast 机制。例如ArrayList的迭代器源码如下所示
public E next() {
// 每一次迭代元素,都会调用checkForComodification()方法检查modCount有没有被修改
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
// 迭代器在备创建时会 expectedModCount = modCount 每一次集合元素更新操作都会改变modCount的值
final void checkForComodification() {
// 所以只要在迭代过程中发生了更新操作那么这里就会直接抛异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
fail-safe
任何对集合结构的修改都会在一个复制的集合上进行,因此不会抛出ConcurrentModificationException。在 java.util.concurrent 包中的集合,如 CopyOnWriteArrayList、ConcurrentHashMap 等,它们的迭代器一般都是采用 Fail-Safe 机制。
上面已经有了CopyOnWriteArrayList新增数据的源码了,会新建一个数组进行更新操作。而迭代的源码如下:
// 在CopyOnWriteArrayList获取迭代器时会创建一个COWIterator内部类的实例对象,参数就是当前的旧数组
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
// 在内部类COWIterator的构造方法中,就会把当前数组赋值给snapshot属性
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
// 迭代的过程中都是操作的snapshot属性指向的老数组。
// 所以即使再迭代过程中出现了更新操作,把array属性的引用改为了新数组内存地址,但是迭代过程中还是使用的snapshot属性指向的老数组内存地址
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
所以fail-safe机制存在一些缺陷:
- 无法实时获取最新的数据
- 更占用内存空间
ConcurrentHashMap
简介
是java线程安全的哈希表。JDK1.8之前采用的分段锁,JDK1.8时采用的循环CAS+synchronized来实现的。官方的解释是:分段锁的锁对象需要占用更多内存空间、提高GC效率
常用API
// 创建一个 ConcurrentHashMap 对象
ConcurrentHashMap<Object, Object> concurrentHashMap = new ConcurrentHashMap<>();
// 添加键值对
concurrentHashMap.put("key", "value");
// 添加一批键值对
concurrentHashMap.putAll(new HashMap());
// 使用指定的键获取值
concurrentHashMap.get("key");
// 判定是否为空
concurrentHashMap.isEmpty();
// 获取已经添加的键值对个数
concurrentHashMap.size();
// 获取已经添加的所有键的集合
concurrentHashMap.keys();
// 获取已经添加的所有值的集合
concurrentHashMap.values();
// 清空
concurrentHashMap.clear();
数据结构
HashTable的数据结构
所有外部直接调用的方法上都是直接加了synchronized关键字,所有操作都是串行的,效率很低

JDK1.7 中的ConcurrentHashMap
在jdk1.7及其以下的版本中,结构是用Segments数组 + HashEntry数组 + 链表实现的

// Segment继承了ReentrantLock,它说到底就是一个锁对象
static class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
JDK1.8中的ConcurrentHashMap
抛弃了Segments分段锁的方案。改用了和HashMap一样的数据结构:数组+链表+红黑树。使用的是cas + synchronized的方式保证数据的一致性

实现原理
直接来看1.8版本ConcurrentHashMap中的put()方法
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
// 死循环
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 数组如果为null时先初始化数组,然后重新走一遍循环
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 如果数组中这个下标位置没有存值,则直接将要插入的Node存进去
// 这里是CAS的操作,如果出现多线程竞争就只有一个线程能插入成功,其他失败的线程再去走一遍循环
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
// 如果数组下标位置已经存在了值,那么就走下面的逻辑,加synchronized关键字,再去遍历链表,判断key是否相等,进行覆盖/链表尾插法
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 覆盖value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 尾插法
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 是否链表转红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
从上面可以看出来,其实JDK1.8还是采用的分散写的设计思路。
还有一个小知识点就是Hashtable.Entry.value和ConcurrentHashMap.Node.val的不同
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value; // Hashtable中是直接在方法上加synchronized,所以vlaue上就没必要再加volatile关键字了
Entry<K,V> next;
...
}
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val; // 而ConcurrentHashMap是采用的CAS,所以需要加上volatile来保证内存可见性
volatile Node<K,V> next;
...
}
ConcurrentSkipListMap
简介
用的比较少,了解即可
ConcurrentSkipListMap 是 Java 中的一种线程安全、基于跳表实现的有序映射(Map)数据结构。
它是对 TreeMap 的并发实现,支持高并发读写操作。
ConcurrentSkipListMap适用于需要高并发性能、支持有序性和区间查询的场景,能够有效地提高系统的性能和可扩展性。
使用场景:
- 链表有序的场景
- 数据量较大(链表较长)
跳表
跳表是一种基于有序链表的数据结构,支持快速插入、删除、查找操作,其时间复杂度为O(log n),比普通链表的O(n)更高效。
数据结构网址
有序链表
![]()
二层跳表

三层跳表

跳表的查找
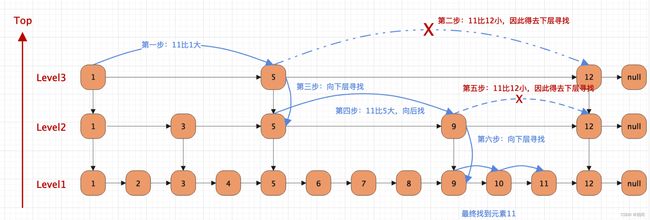
跳表的插入
新插入的元素在最底层一定是存在的,至于高层的索引层中是否存在是根据随机算法来决定的
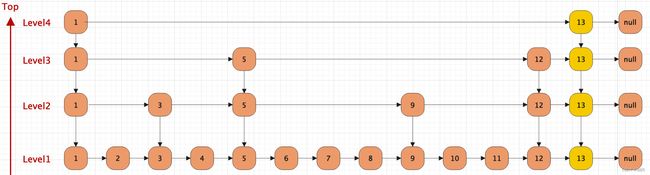
跳表的特性
- 跳表每一层都是有序的,默认是升序
- 最底层包含所有元素
- 如果某个元素出现在了LevelN层,那么N层之下的每一层都有这个元素
- 每一个节点都包含了两个指针,一个指向同一级链表中的下一个元素,一个指向下一层级别链表中的相同值元素。
基本用法
public class ConcurrentSkipListMapDemo {
public static void main(String[] args) {
ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();
// 添加元素
map.put(1, "a");
map.put(3, "c");
map.put(2, "b");
map.put(4, "d");
// 获取元素
String value1 = map.get(2);
System.out.println(value1); // 输出:b
// 遍历元素
for (Integer key : map.keySet()) {
String value = map.get(key);
System.out.println(key + " : " + value);
}
// 删除元素
String value2 = map.remove(3);
System.out.println(value2); // 输出:c
}
}