【分布式锁Redisson原理入门1】四大特征:互斥,防死锁,高性能,重入,看门狗机制,Redisson缺点 主节点宕机未同步。RedLock。
教程1:分布式锁:
4条件:互斥 不死锁 加解同一个 加解原子性
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
-
互斥性。在任意时刻,只有一个客户端能持有锁。
-
不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
-
解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
-
加锁和解锁必须具有原子性。
简单使用1
set XX nx ex 和 setnx expire
setnx users 10 #设置users的值为10,存在就不设置
expire users 20 #设置 过期时间 为 20秒后,过期
ttl users #查看过期时间
1、使用setnx上锁,通过del释放锁
2、锁一直没有释放,设置key过期时间,自动释放
set users 10 nx ex 20 #设置 users 的值为10, 存在就不设置,20秒后过期
代码中用 setIfAbsent
- 获取锁,获取失败,调用自己(自旋锁)
- 获取成功,操作数据,操作完毕,就删除锁
@GetMapping("testLock")
public void testLock() {
//1获取锁,setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111");
//2获取锁成功、查询num的值
if (lock) {
Object value = redisTemplate.opsForValue().get("num");
//2.1判断num为空return
if (StringUtils.isEmpty(value)) {
return;
}
//2.2有值就转成成int
int num = Integer.parseInt(value + "");
//2.3把redis的num加1
redisTemplate.opsForValue().set("num", String.valueOf(++num));
//2.4释放锁,del
redisTemplate.delete("lock");
} else {
//3获取锁失败、每隔0.1秒再获取
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- ab 测试, 1千个请求,100个并发
ab -n 1000 -c 100 http://192.168.2.80:8080/redisTest/testLock
- 设置锁,如果存在就不设置,3秒后过期
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111",3, TimeUnit.SECONDS);
释放他人的锁:自动过期 又删除
a先操作
1、上锁
2、具体操作服务器卡顿
3、锁自动释放
- 服务器正常了,进行操作,手动释放锁(释放的是他人的锁)
1、b抢到锁
2、具体操作,b的锁会被释放(已经被A释放了)
解决 加UUID
第一步uuid表示不同的操作
set lock uuid nx ex 10
第二步释放锁时候,首先判断当前uuid和要释放锁uuid是否一样
String uuid = UUID.randomUUID().toString();
//1获取锁,setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS);
String lockUuid = redisTemplate.opsForValue().get("lock");
//一样的时候,才释放锁
if (uuid.equals(lockUuid)) {
//2.4释放锁,del
redisTemplate.delete("lock");
}
依然可能释放别人的锁
1、上锁
2、具体操作
3、释放锁del
- 比较uuid ,一样删除操作时候,正要删除,还没有删除,锁到了过期时间,自动释放
4、删除操作 (删除的依然为b的锁)
- 过了判断就删除,判断和删除 不是原子操作
- 如果A 过了判断后,锁自动释放了,B设置上锁,A删除锁,删除的依然是B锁
1、b锁
2、具体操作
3、a释放b的锁
Lua脚本:判断值是否一样,才删除
LUA脚本是类似redis事务,有一定的原子性,不会被其他命令插队,可以完成一些redis事务性的操作。
@GetMapping("testLockLua")
public void testLockLua2() {
//1 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
//2 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
// 3 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock) {
// 执行的业务逻辑开始
// 获取缓存中的num 数据
Object value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value + "");
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set("num", String.valueOf(++num));
/*使用lua脚本来锁*/
// 定义lua 脚本。判断 KEYS的值 和 ARGV的值 是否一样,一样才调用方法删除,不一样 返回0
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,
// 那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua2();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//KEYS[1] 传递为 锁的key
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
//ARGV[1] 传递为 uuid
//如果 从 key 中 获取的值 == uuid
if redis.call('get', KEYS[1]) == ARGV[1]
then
return redis.call('del', KEYS[1]) //才调用 删除的逻辑,否则就不删除
else
return 0
end
教程2:Redisson 实现分布式锁原理
https://blog.csdn.net/u014401141/article/details/108109529
-
Redisson实现分布式锁原理
-
Redisson实现分布式锁的源码解析
-
Redisson实现分布式锁的项目代码(可以用于实际项目中)
特征
1、互斥
在分布式高并发的条件下,我们最需要保证,同一时刻只能有一个线程获得锁,这是最基本的一点。
2、防止死锁:设过期时间
在分布式高并发的条件下,比如有个线程获得锁的同时,还没有来得及去释放锁,就因为系统故障或者其它原因使它无法执行释放锁的命令,导致其它线程都无法获得锁,造成死锁。
所以分布式非常有必要设置锁的 有效时间 ,确保系统出现故障后,在一定时间内能够主动去释放锁,避免造成死锁的情况。
3、高性能:粒度 范围 时间
对于访问量大的共享资源,需要考虑减少锁等待的时间,避免导致大量线程阻塞。
所以在锁的设计时,需要考虑两点。
1、 锁的颗粒度要尽量小
。比如你要通过锁来减库存,那这个锁的名称你可以设置成是商品的ID,而不是任取名称。这样这个锁只对当前商品有效,锁的颗粒度小。
2、 锁的范围尽量要小 。比如只要锁2行代码就可以解决问题的,那就不要去锁10行代码了。
3、锁 不要控制太长的时间。
4、重入
我们知道ReentrantLock是可重入锁,那它的特点就是:同一个线程可以重复拿到同一个资源的锁。重入锁非常有利于资源的高效利用。关于这点之后会做演示。
针对以上Redisson都能很好的满足,下面就来分析下它。
获取锁机制
-
线程1 获取锁——加锁成功
- 线程去获取锁,获取成功: 根据Hash算法 选择一个点(redis节点),执行lua脚本,保存数据到redis数据库。
-
线程2 获取锁失败,While不停的尝试 获取锁
- 一直通过while循环尝试获取锁,获取成功后,xxx
-
线程1——每隔10秒看下,如果 还持有锁,延长生存时间。(看门狗)
源码
//RedissonLock类,通过这个lua脚本,判断能不能获取到锁
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
this.internalLockLeaseTime = unit.toMillis(leaseTime);
return this.evalWriteAsync(this.getName(),
LongCodec.INSTANCE, command,
"lua脚本 XXX",
Collections.singletonList(this.getName()),
this.internalLockLeaseTime,
this.getLockName(threadId));
}
if (redis.call('exists', KEYS[1]) == 0)
then redis.call('hincrby', KEYS[1], ARGV[2], 1); #重入+1,下面是设置 过去时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil; end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) #对 hash的操作
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil; end;
return redis.call('pttl', KEYS[1]);
重入的基石和详解
Redisson可以实现可重入加锁机制的原因,我觉得跟两点有关:
1、Redis存储锁的数据类型是 Hash类型
2、Hash数据类型的key值 包含了 当前线程信息。
下面是redis存储的数据

这里表面数据类型是Hash类型,Hash类型相当于我们java的
-
这里key是指 ‘redisson’,你的锁 的key
-
它的有效期还有9秒,
-
我们再来看里们的key1值为
078e44a3-5f95-4e24-b6aa-80684655a15a:45它的组成是:- guid + 当前线程的ID。
-
后面的value是就和可重入加锁有关。
图解可重入
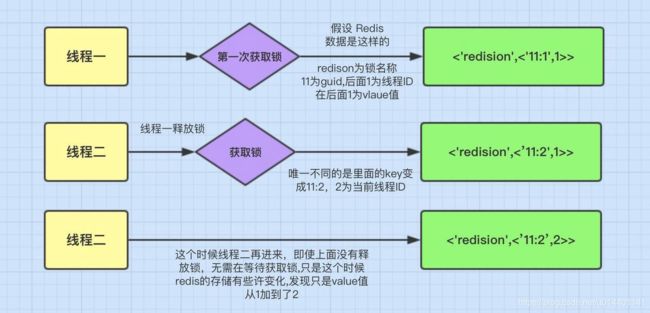
上面这图的意思就是可重入锁的机制,它最大的优点就是相同线程不需要在等待锁,而是可以直接进行相应操作。
watch dog自动延期机制
加锁 设时长 尝试加锁设时长
RLock lock = redisson.getLock("my-lock");
// 最常见的使用方法
lock.lock();
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
解释说明
使用基本锁以后,redisson使用了自动续期,**如果业务超长,运行期间自动续上30s,**不用担心业务时间长,锁自动过期被删掉。
大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
看门狗这里我自己的理解就是:
在一个分布式环境下,假如一个线程获得锁后,突然服务器宕机了,
- 那么这个时候在一定时间后这个锁会自动释放,你也可以设置锁的有效时间(不设置默认30秒),这样的目的主要是防止死锁的发生。
引出看门狗
//设置锁1秒过去
redissonLock.lock("redisson", 1);
/**
* 业务逻辑需要咨询2秒
*/
redissonLock.release("redisson");
- 线程1 进来获得锁后,线程一切正常并没有宕机,但它的业务逻辑需要执行2秒,这就会有个问题,在 线程1 执行1秒后,这个锁就自动过期了,
- 那么这个时候 线程2 进来了。那么就存在 线程1和线程2 同时在这段业务逻辑里执行代码,这当然是不合理的。
- 而且如果是这种情况,那么在解锁时系统会抛异常,因为解锁和加锁已经不是同一线程了
所以这个时候 看门狗 就出现了,它的作用就是 线程1 业务还没有执行完,时间就过了,线程1 还想持有锁的话,就会启动一个watch
dog后台线程,不断的延长锁key的生存时间。
注意 正常这个看门狗线程是不启动的,还有就是这个看门狗启动后对整体性能也会有一定影响,所以不建议开启看门狗。
lua脚本保证原子性
为啥要用lua脚本呢?
这个不用多说,主要是如果你的业务逻辑复杂的话,通过封装在lua脚本中发送给redis,而且redis是单线程的,这样就保证这段复杂业务逻辑执行的
原子性 。
看门狗 不会死锁 续期相关
关于看门狗死锁:
就是上锁时会有个过期时间,然后看门狗其实就是个定时任务,在每隔1/3默认时间时也就是10s执行一次,
然后把过期时间蓄满,所以在业务完成执行完成之前,锁不会自动过期,而业务完成之后锁也会自动过期,有个过期时间自然也就解决了死锁
通过源码分析我们知道,默认情况下,加锁的时间是30秒.如果加锁的业务没有执行完,那么到 30-10 = 20秒的时候,就会进行一次续期,把锁重置成30秒.
- 30,29,28 第20秒的时候 续期一次
那这个时候可能又有同学问了,那业务的机器万一宕机了呢?宕机了定时任务跑不了,就续不了期,那自然30秒之后锁就解开了呗.
- Redisson看门狗默认巡查周期为10秒,锁续期时间(过期时间)30秒;
- 多个线程Redisson,调用加锁的逻辑。
- 如果 加锁成功——开启 后台线程——每隔10秒 检查是否还 持有锁
- 你设置60秒,就是20秒,设置 1/3 的位置。
- 如果有 则延长锁的时间,
- 即:被此 Redis Master 持有此锁,
- 直到 Redis Master 释放锁,unlock
- 加锁失败,while循环 一直尝试 加锁,自旋。
Redis分布式锁的缺点:master实例宕机
Redis分布式锁会有个缺陷,就是在Redis哨兵模式下:
客户端1 对某个 master节点 写入了redisson锁,
-
此时会异步复制给对应的 slave节点。
-
但是这个过程中一旦发生master节点宕机,主备切换,
-
slave节点从变为了 master节点。
这时 客户端2 来尝试加锁的时候,在新的master节点上也能加锁,此时就会导致多个客户端对同一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题, 导致各种脏数据的产生 。
总结:
缺陷 在哨兵模式或者主从模式下,如果 master实例宕机的时候,可能导致多个客户端同时完成加锁。
缺点修复 RedLock
RedLock 解决 Redisson 主节点挂了,还没同步 从节点的情况
修复步骤
- 不懂
1.获取当前时间
2.设置过期时间避免死等
3.按照顺序向三个阶段顺序发出获取锁指令
4.当前时间 减去 开始获取锁时间就得到获取锁使用的时间,只有当使用的时间小于锁失效时间才算成功
5.如果获取锁失败,所有的Redis实例上进行解锁,无论Redis实例是否加锁成功,因为可能服务端响应消息丢失了但是实际成功了,毕竟多释放一次也不会有问题
代码实现RedissonReadLock
- 平时用的是 private Redisson redisson;
//创建配置文件
Config config1 = new Config();
//设置 服务的地址
config1.useSingleServer().setAddress("redis://127.0.0.1:6379");
//创建 redisson 客户端
RedissonClient redissonClient1 = Redisson.create(config1);
//获取锁
RLock lock1 = redissonClient1.getLock("LOCK_KEY");
//获取多个锁
RedissonReadLock redLock = new RedissonReadLock(lock1, lock2, lock3);
boolean isLock = false;
try {
//尝试 获取 锁
isLock = redLock.tryLock(500, 1000, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
redLock.unlock();
}