计算机体系结构复习笔记
本篇复习笔记对应的课本是《计算机体系结构 量化研究方法》
参考了老师的PPT,以及总结了课后习题和考试题
文章目录
- 1. 计算机体系结构基础
-
- 1.1 计算机系统的分层
- 1.2 计算机体系结构和实现
- 1.3 计算机设计的任务
- 1.4 性能评测和报告
- 1.5 计算机量化设计的原则
- 1.6 计算机体系结构的分类
- 2. 指令级体系结构
-
- 2.1 指令集体系结构分类
- 2.2 解释存储地址
- 2.3 寻址模式
- 2.4 优化指令格式
- 2.5 指令集中的操作
- 2.6 精简指令集计算机与复杂指令集计算机
- 2.7 DLX体系结构
- 3. 流水技术
-
- 3.1 流水概念
-
- 3.1.1 基本概念
- 3.1.2 DLX的一种简单实现
- 3.2 DLX基本流水线
-
- 3.2.1 DLX流水线
- 3.2.2 流水线的基本性能问题
- 3.3 流水线冒险
-
- 3.3.1 冒险的概念
- 3.3.2 带暂停流水线的性能
- 3.3.3 结构冒险
- 3.4 数据冒险
- 3.5 控制冒险
- 3.6 扩展DLX流水线→处理多周期操作
- 3.7 动态方法解决数据相关
- 3.8 利用硬件对转移进行动态预测
- 3.9 借助多发射提高指令级并行
- 3.10 指令级和线程级并行
- 4. 存储体系
-
- 4.1 简介
- 4.2 cache 基本知识
-
- 4.2.1 访问cache
- 4.2.2 cache 缺失/失效处理
- 4.2.3 写直达和写返回
- 4.2.4 利用空间局部性
- 4.2.5 增大主存——cache带宽
- 4.3 衡量/提高cache性能
-
- 4.3.1 衡量cache性能
- 4.3.2 借助块放置方式降低cache失效率
- 4.3.3 在cache中定位一个块
- 4.3.4替换原则
- 4.3.5 利用多级cache减少失效开销
- 4.4 虚拟存储器
-
- 4.4.1 放置和查找页面
- 4.4.2 用TLB加快地址变换
- 4.4.3 虚拟存储器,TLB和cache的统一
- 4.4.4 虚拟存储器的保护
- 4.4.5 页面失效和TLB失效的处理
1. 计算机体系结构基础
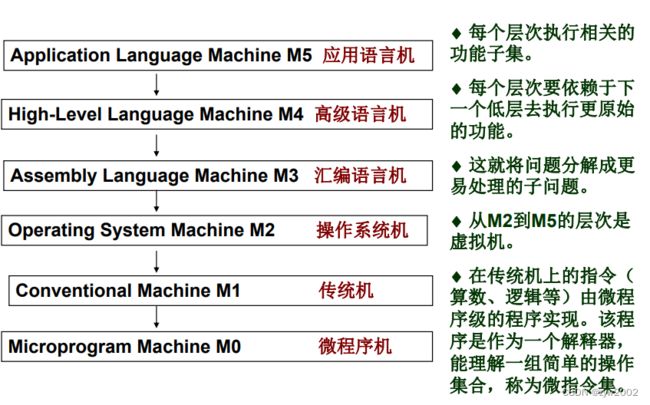
1.1 计算机系统的分层
1.2 计算机体系结构和实现
计算机体系结构指的是那些对程序员可见的系统属性,或者那些对程序的逻辑执行有直接影响的属性
一个机器的设计包括两个部分: 组织和硬件
相同的指令集体系结构可有不同的组织
相同的指令集体系结构和组织在硬件实现上可不同。
体系结构方面的属性: 指令集,I/O机制,寻址技术,表示各种数据类型的位数(数字、字符)
组织方面的属性:对于程序员透明的硬件细节,控制信号,计算机/外设接口,存储技术
硬件方面的属性:封装技术,电源, 冷却
1.3 计算机设计的任务
在满足功能需求的同时,保障高性能和低价格
响应时间/ 执行时间:一个时间从开始执行到执行结束的用时

吞吐率:在给定时间内,完成的工作数量
墙上时钟时间,响应时间或运行时间:包括磁盘访问,内存访问,输入/输出活动,操作系统开销
CPU时间:表示CPU正在计算的时间,不包括等待I/O或运行其他程序(多路程序)的时间。
用户CPU时间(程序)
系统CPU时间(OS)
选择程序来评估性能:
四个层次的程序, 按预测精确度从高到底的次序




基准测试程序(Benchmark Suites)

1.4 性能评测和报告
性能测试报告的准则:可重现性(reproducibility)

平均执行时间:

加权执行时间:

几何平均值:

1.5 计算机量化设计的原则
使常见情况更快: 照顾经常发生的情况, 对资源使用也是这个道理
阿姆达尔定律: 由某些部分加速所得到的性能提高受加速部分的百分率所限。
加速比的定义:

加速比取决于两个因素: 能加速的部分, 能加速的程度

回报递减法则: 对于一部分性能的提高,总体加速比的提高呈递减
总体加速比有上界是1
CPU时间:
C P U \mathrm{CPU} CPU time = C P U =\mathrm{CPU} =CPU clock cycles for a program × \times × Clock cycle time
CPU time = CPU clock cycles for a program Clock rate \text { CPU time }=\frac{\text { CPU clock cycles for a program }}{\text { Clock rate }} CPU time = Clock rate CPU clock cycles for a program
IC: 指令数
CPI: 每条指令的平均时钟数
C P I = CPU clock cycles for a program I C \mathrm{CPI}=\frac{\text { CPU clock cycles for a program }}{\mathrm{IC}} CPI=IC CPU clock cycles for a program
执行时间公式:
CPU time = I C × C P I × =\mathrm{IC} \times \mathrm{CPI} \times =IC×CPI× Clock cycle time
CPU time = I C × C P I Clock rate =\frac{\mathrm{IC} \times \mathrm{CPI}}{\text { Clock rate }} = Clock rate IC×CPI
Instructions Program × Clock cycles Instruction × Seconds Clock cycle = Seconds Program = C P U \frac{\text { Instructions }}{\text { Program }} \times \frac{\text { Clock cycles }}{\text { Instruction }} \times \frac{\text { Seconds }}{\text { Clock cycle }}=\frac{\text { Seconds }}{\text { Program }}=\mathrm{CPU} Program Instructions × Instruction Clock cycles × Clock cycle Seconds = Program Seconds =CPU time
CPU clock cycles = ∑ i = 1 n I C i × C P I i \text { CPU clock cycles }=\sum_{i=1}^{n} \mathrm{IC}_{i} \times \mathrm{CPI}_{i} CPU clock cycles =i=1∑nICi×CPIi
where I i I_{i} Ii represents number of times instruction i i i is executed in a program and C P l i \mathrm{CPl}_{i} CPli represents the average number of clock cycles for instruction i i i. This form can be used to express CPU time as:
CPU time = ( ∑ i = 1 n I C i × C P I i ) × =\left(\sum_{i=1}^{n} \mathrm{IC}_{i} \times \mathrm{CPI}_{i}\right) \times =(∑i=1nICi×CPIi)× Clock cycle time
CPI = ∑ i = 1 n I C i × C P I i Instruction count = ∑ i = 1 n I C i Instruction count × C P I i \text { CPI }=\frac{\sum_{i=1}^{n} \mathrm{IC}_{i} \times \mathrm{CPI}_{i}}{\text { Instruction count }}=\sum_{i=1}^{n} \frac{\mathrm{IC}_{i}}{\text { Instruction count }} \times \mathrm{CPI}_{i} CPI = Instruction count ∑i=1nICi×CPIi=i=1∑n Instruction count ICi×CPIi
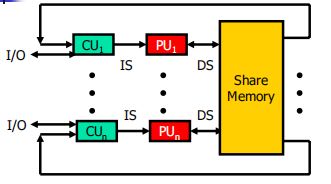
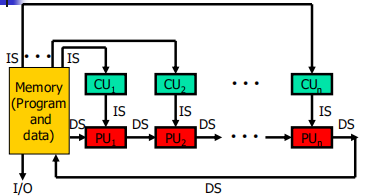
1.6 计算机体系结构的分类
SISD(single instruction stream over a single data stream)
单指令流单数据流
- SIMD(single instruction stream over multiple data stream)
单指令流多数据流 - MIMD(multiple instruction over multiple data streams)
多指令流多数据流 - MISD(multiple instruction streams and a single data stream)
多指令流单数据流
-
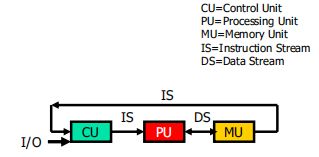
SISD (Single Instruction Stream over a Single DataStream)computer(单指令流单数据流计算机)
-
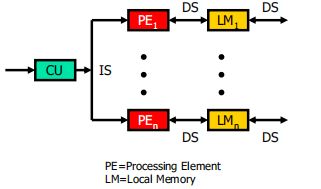
SIMD( Single Instruction Stream over Multiple DataStream)computer (单指令流多数据流计算机)
-
MIMD(Multiple Instruction Stream over Multiple DataStream)computer (多指令流多数据流计算机)
-
MISD(Multiple Instruction Stream over a Single DataStream)computer (多指令流单数据流计算机)
MIMD model —general-purpose computations
SIMD and MISD —special-purpose computations
Popularity decrease:MIMD>SIMD→MISD
2. 指令级体系结构
2.1 指令集体系结构分类
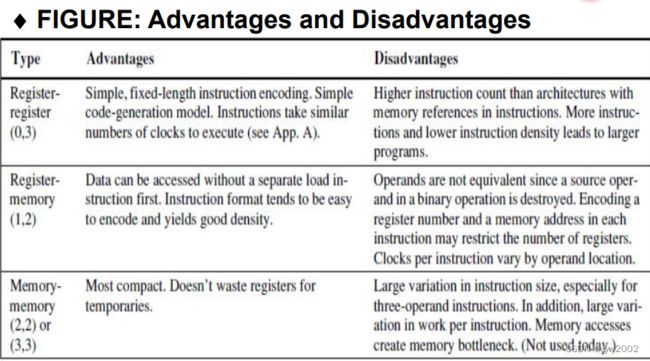
CPU内部存储的类型是最基本的区别: 堆栈、累加器、寄存器组
操作数是明确或隐含命名的: 栈顶, 一个操作数是累加器本身,或者是寄存器,或者是存储器位置
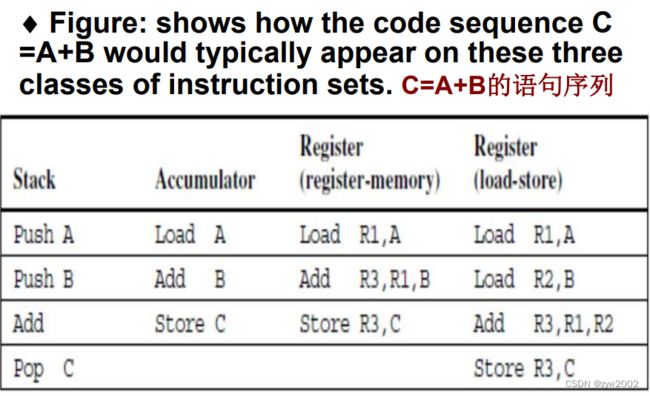
两类寄存器机 :
寄存器-存储器体系结构,寄存器-寄存器体系结构
存储器-存储器体系结构,现在没有
通用寄存器计算机GPR的优势: 快,易于编译器有效使用
由于寄存器能存值,使得降低了存储访问,程序加速,代码密度提高
GPR按特性划分:
ALU有两个还是三个操作数: 三操作数格式(一个结果,两个源操作数);二操作数格式(一个操作数既是源也是结果操作数)
有多少操作数可以是存储地址:
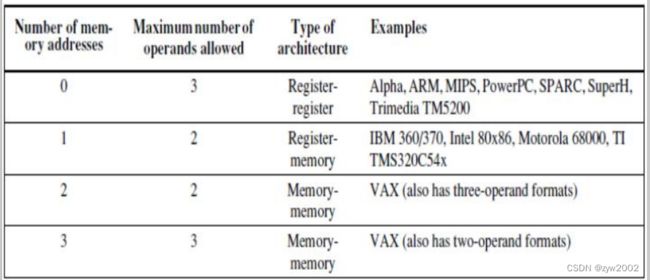
2.2 解释存储地址
存储地址是如何被解释的?
字节寻址, 可访问字节(8 bits)、半字(16 bits)、字(32 bits). 多数计算机也可访问双字(64 bits)
字中字节的排序:
小端字节序:低地址装最低有效数
高端字节序:低地址装最高有效数
对齐:
不对齐则要访问多次
寻址模式:计算机如何规定地址
可规定:常数, 寄存器,存储地址
有效地址
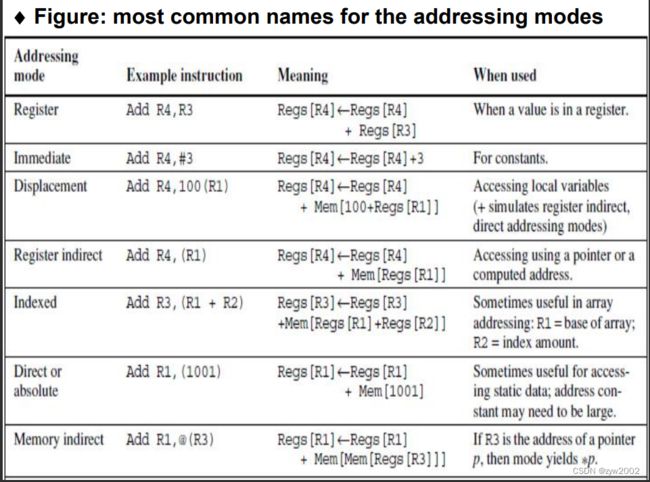
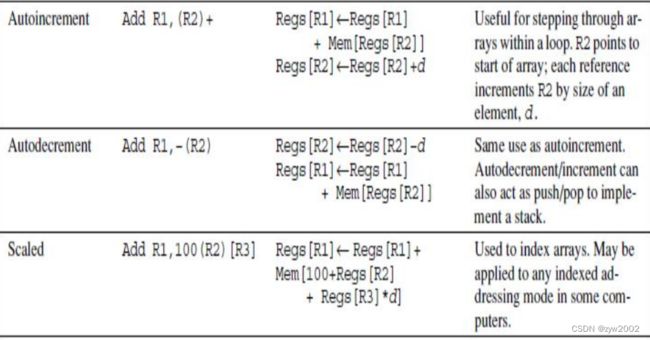
2.3 寻址模式
位移寻址模式(Displacement Addressing Mode)

立即或文字寻址(Immediate or Literal Addressing Mod)

总结: 存储器寻址
至少应支持这三种寻址模式
位移至少12到16位,立即数至少8到16位
2.4 优化指令格式
基本问题: 指令格式长度
决定了机器的丰富性、灵活性
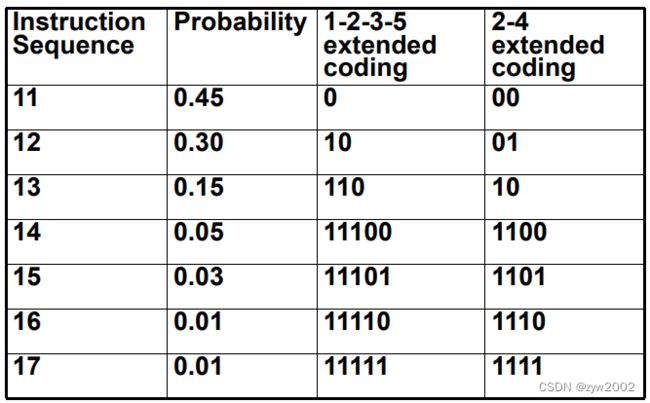
哈夫曼编码: 用更少的位表示更常出现的字符
构造哈夫曼树
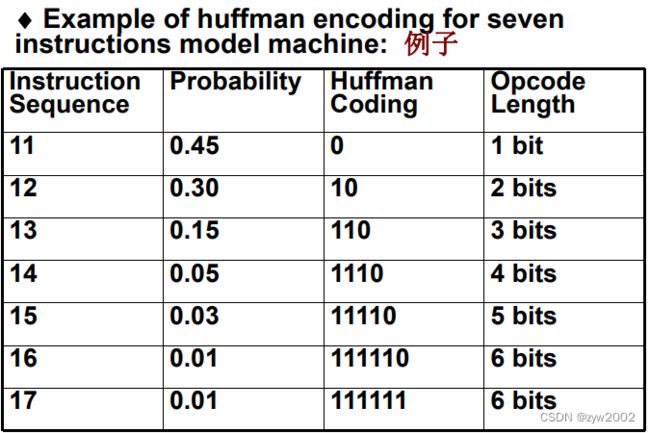

前缀码: 任何码字都不是其他码字的前缀
哈夫曼码的位数最少, 冗余最小, 但结构不整齐,扩展码是一个折中
操作数: 可有(明确给出)3个、2个、1个操作数的指令格式,或者有0个操作数的(隐含操作数)指令格式
可用间接寻址、寄存器间接寻址、位移寻址来缩短
操作数长度
指令集编码:
操作在opcode中定义,如何对寻址模式编码。
矛盾的需求:寄存器和寻址模式越多越好、寄存器和寻址模式域的大小对平均指令大小,进而对程序大小的影响、期望指令大小易于处理:字节的倍数
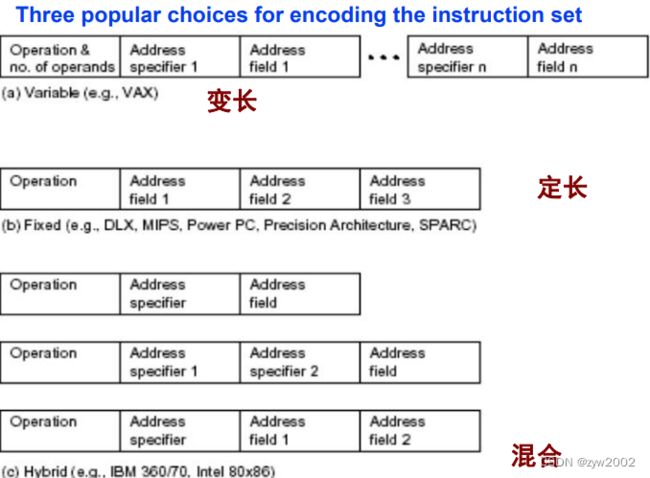
变长: 允许所有操作有任何寻址模式,当有很多寻址模式和操作时最佳
定长: 将操作和寻址模式结合到操作码域,当有很少寻址模式和操作时最佳
混合:程序大小与易于解码之间的折中
多数广泛执行的指令是简单操作
简单指令占大多数、应快速实现这些指令
2.5 指令集中的操作
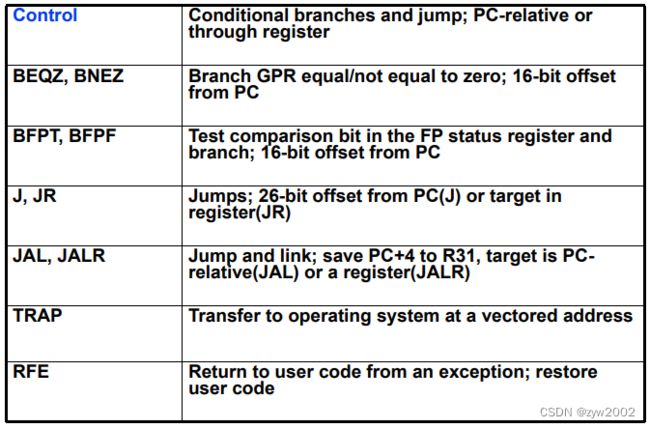
控制流指令:条件转移、跳转、过程调用、过程返回
控制流指令的寻址模式:
大多情况,必须明确规定目标地址,过程返回则例外。
最常用方法:提供一个相对于、可加到PC的位移
优势: 目标通常在附近, 需要位数少、便于链接;
当目标未知时:返回或非直接跳转要采取另外的寻址方法’
必须动态确定目标地址,可命名一个寄存器,它包含目标地址
2.6 精简指令集计算机与复杂指令集计算机
RISC(reduced instruction set computer): -精简指令集计算机
指令类型少,运行快: 指令简单, 因此运行非常快,需要
更少的晶体管, 设计和制造更便宜。
CISC’s(Complex Instruction Set Computers)—传统计算机称为复杂指令集计算机: 汇编语言程序量小,这通过硬件来实现


RISC的设计特征:


RISC设计的最新进展:
有些阶段可合并;超流水线, 但实现困难, 不太用;超标量,几乎现代微处理器都是
2.7 DLX体系结构






3. 流水技术
3.1 流水概念
3.1.1 基本概念
- 流水线是什么?
流水是多条指令重叠执行的一种实现技术。目前,流水是快速 CPU 的关键实现手段。
在计算机流水技术中,流水线的每一个阶段完成指令的一个部分。每一步骤被称作流水段(pipe stage、pipe segment) - 吞吐量、机器周期
指令流水线的吞吐率(throughput)取决于从流水线中流出指令的速度,即单位时间里所流出的指令数。
流水线的各个阶段是依次连接在一起的,各个阶段同时工作。指令在流水线中每前进一个阶段所需的时间是一个机器周期。机器周期取决于流水线中最慢的部分。在计算机中,这个机器周期通常是一个时钟周期(有时可以是两个,但很少超过两个),但时钟周期可以会有多个相位。 - 性能
流水设计的目标就是平衡个流水部件的时间长度,这样流水线机器中每条指令所需时间就等于(指令在非流水机器上所需执行时间/流水段数)
在这种情况下,流水线的加速比就等于流水线的段数。
通常,流水线的各段很难做到完全的平衡。因此流水线会引入一些额外开销。 - 两个视角看待加速
流水线可以让每条指令的平均执行时间降低。如果从多周期指令的角度看,流水线可以降低 CPI 值;
如果从单周期指令的角度看,流水线可以减低时钟周期时间值。
流水线是在顺序指令流中挖掘指令并行执行的一种实现技术,对于应用程序员来说是透明的。
3.1.2 DLX的一种简单实现
-
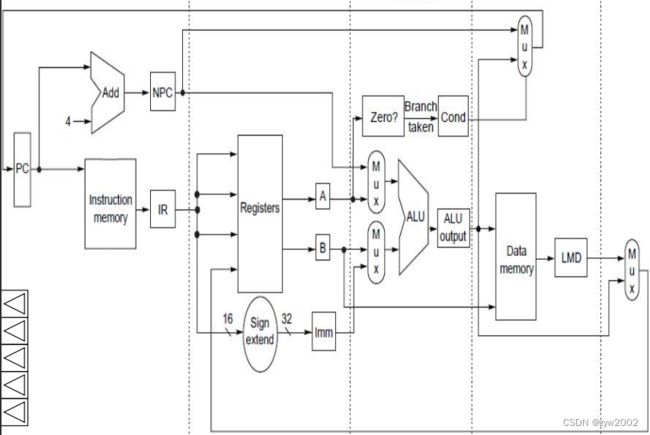
DLX指令的5个步骤
每条 DLX 整型指令至多需要 5 个时钟周期。分别为:
1、 取指令周期(IF)
2、 指令译码/寄存器读取周期(ID)
3、 执行/计算有效地址周期(EX)
4、 存储器访问/转移完成周期(MEM)
5、 写回结果周期(WB) -
取指令(IF)
IR <- Mem[PC]
NPC<- PC+4
操作:送出PC, 并将指令从存储器提取到指令寄存器中(IR);将PC递增4,以完成下一顺序指令的寻址。IR用于保存将在后续时钟周期中需要的指令,寄存器NPC用于保存下一个顺序的PC。 -
指令译码/寄存器取(ID)
A <- Regs[IR6..10]
B<- Regs[IR11..15]
Imm<-IR的符号拓展立即数字段
操作:解码,读取寄存器。IR的输出被读入两个临时的寄存器A和B; IR的低16位进行了符号拓展,并存储在临时寄存器Imm中。 指令解码和寄存器取可并行进行。 -
执行/计算有效地址周期(EX)
根据指令的类型进行四种操作之一
1)存储器引用
ALUoutput <- A+ Imm
操作:计算出有效地址,并放到ALUoutput
2)寄存器-寄存器ALU指令
ALUoutput<- A func B
操作:对A和B执行一定的操作,并把结果保存在ALUoutput
3)寄存器-立即数ALU指令
ALUOutput<- A op Imm
操作:操作:对A和op执行一定的操作,并把结果保存在ALUoutput
4)转移
ALUoutput<-NPC + Imm
Cond<-(A op 0)
操作:ALU计算NPC+imm得到目标地址,检测A确定是否转移
为什么有效地址/执行可结合到一个时钟周期内?
没有指令在计算数据地址、目标地址的同时还对数据进行操作。 -
存储器访问/转移完成周期(MEM)
只有load、store和branch指令在这个周期活跃
1)寄存器引用(load\store)
LMD <- Mem[ALUoutput]orMem[ALUoutput]<-B
操作:如果是Load指令,访问得到的数据放到LMD(load memory data); 如果是Store指令,寄存器B中的数据写入到内存中;
2)转移(branch)
if (cond) PC <-ALUoutput else PC<- NPC
转移成功:转移目标地址送到PC
转移不成功:NPC送到PC -
写回(WB)
1)寄存器-寄存器ALU指令
Regs[IR16..20]<-ALUoutput
2)寄存器-立即数类型
Regs[IR11..15]<-ALUOutput
3)Load指令
Regs[IR11..15]<-LMD
操作:写结果到寄存器中
- 非流水线DLX的性能问题


图 3.1 是指令所途径的数据通路。在这个实现中,branch 和 store 指令需要 4 个周
期。而其余的整形指令均需 5 个周期。

3.2 DLX基本流水线
3.2.1 DLX流水线
-
如何用流水线:
只需在每个时钟周期开始一条新指令。
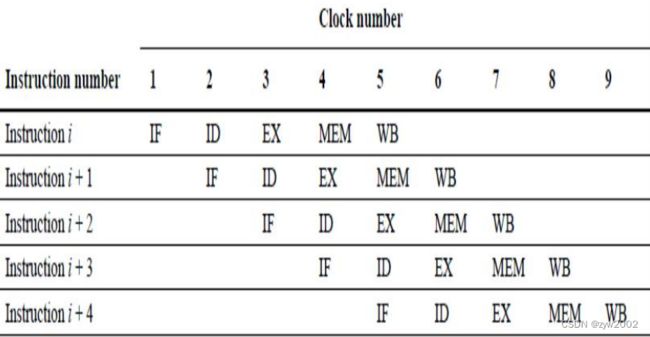
-
DLX流水线的简单画法
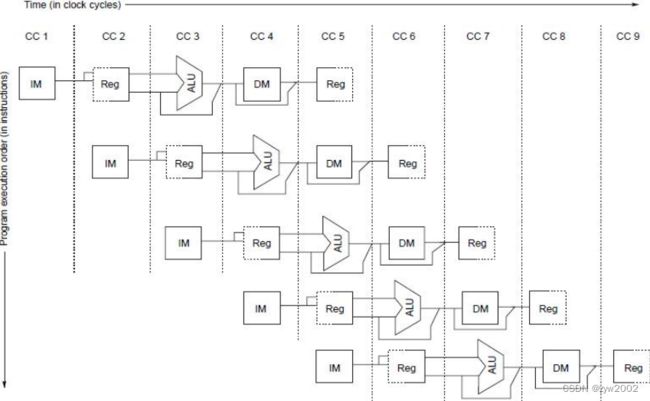
-
实际的流水线
流水线段之间传送的值必须放在寄存器中。
流水线寄存器(pipeline registers),或者叫流水线锁存器(pipeline latche)
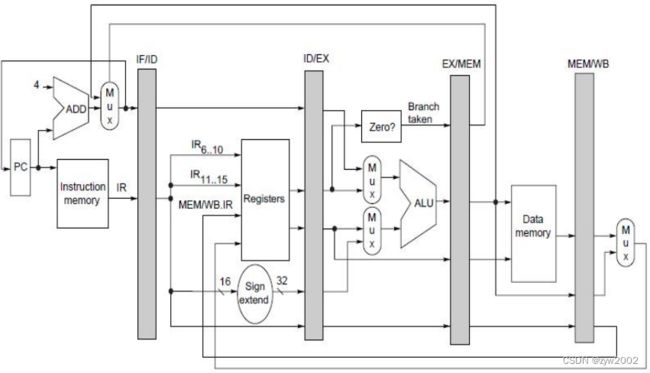
流水线寄存器包含数据和控制信息。 值放在寄存器中, 沿流水线传送, 直至不再需要。
例如:load或ALU要写的寄存器由MEM/WB流水线寄存器提供 -
流水线各个阶段发生的事情
前两段的动作对所有种类的指令都一样;IF的动作取决于EX/MEM中的指令是否是成功转移;



-
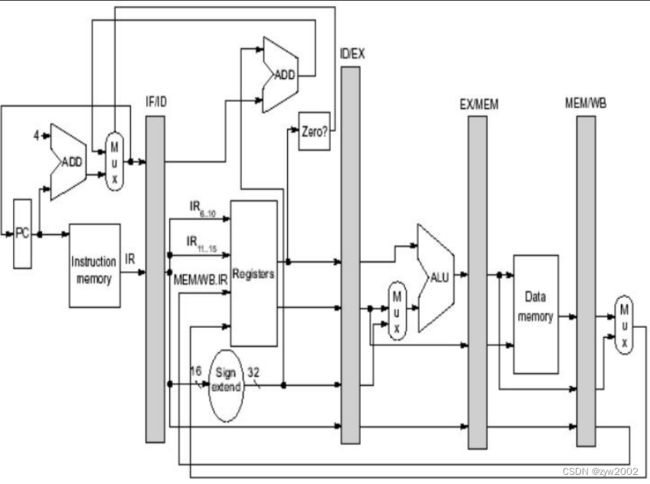
如何控制流水线?4个多路选择器
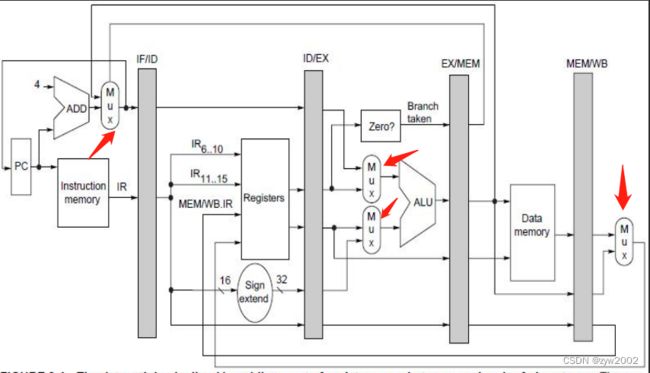
1)在ALU中有两个多路选择器: 取决于指令的类型
其中上方的多路选择器:是否是转移指令
下方的多路选择器:指令是否是一个寄存器-寄存器类型的操作或者其他类型的操作
- IF阶段的多路选择器:选择是采用自增后的PC还是EX/MEM.ALUoutput的结果去写入PC
- ME/MWB阶段的多路选择器:判断写回阶段的指令是load指令还是ALU 操作
3.2.2 流水线的基本性能问题
-
流水线改进的是吞吐量:
增加了吞吐量, 但没有降低每条指令的运行时间
由于控制开销, 每条指令运行时间稍微增加
吞吐量增加,程序运行更快 -
影响流水线性能的因素:
流水线开销:寄存器延迟和时钟偏差
不平衡:时钟运行速度不能超过时间需要最慢的管道阶段。






3.3 流水线冒险
3.3.1 冒险的概念
冒险:阻止下一条指令执行,降低了性能
- 冒险的类型
结构冒险:由计算机硬件设计造成的资源冲突
数据冒险:一条指令依赖于上一条指令的计算结果
控制冒险:由branch和改变PC的指令引起 - 如何解决冒险?
一些指令继续,另一些指令延迟
当指令阻塞时:后发射的指令也阻塞、以前发射的指令继续
在暂停期间不取指
3.3.2 带暂停流水线的性能
- 流水线的加速比

- 把流水线看做是改进CPI


- 流水线看做是改进时间周期

3.3.3 结构冒险
结构冒险的例子:
不完全流水化造成阻塞、一些资源未足够复制、若寄存器写端口只有一个,而流水线要在一个周期执行两个写、数据和指令共享存储器时, 引起冲突
只有一个存储端口的机器在内存引用时产生冲突。如下图,load指令使用内存存储数据同时存取指令3要从内存中获取一条指令.
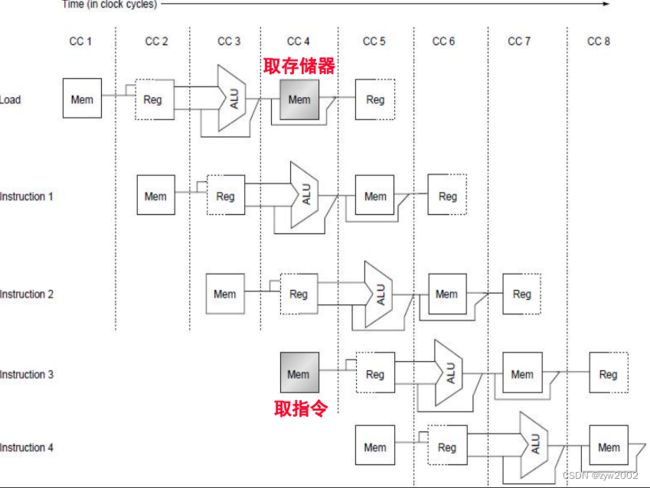
发生存储器访问时,需要阻塞流水线一个周期.
失速(stall)通常被称为管道气泡(pipeline bubble)或只是气泡(bubble),因为它漂浮在管道中占用空间,却不带有用的东西。
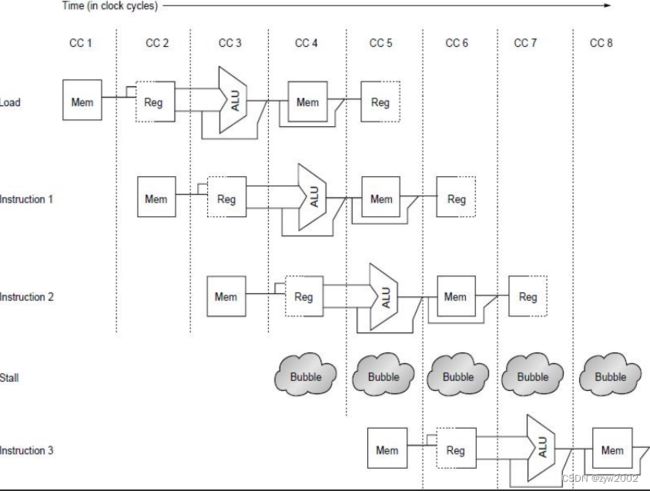
另一种画法
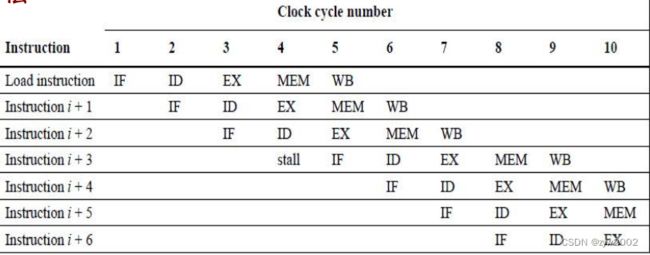



硬件解决方案:
- 将缓存(cache)分为数据缓存和指令缓存
- 使用指令缓冲区(buffer)来装指令
为什么允许结构冒险?
减少开销 ;不需要流水线寄存器,从而不引入延迟.
3.4 数据冒险
数据冒险:当流水线改变读写操作数的顺序

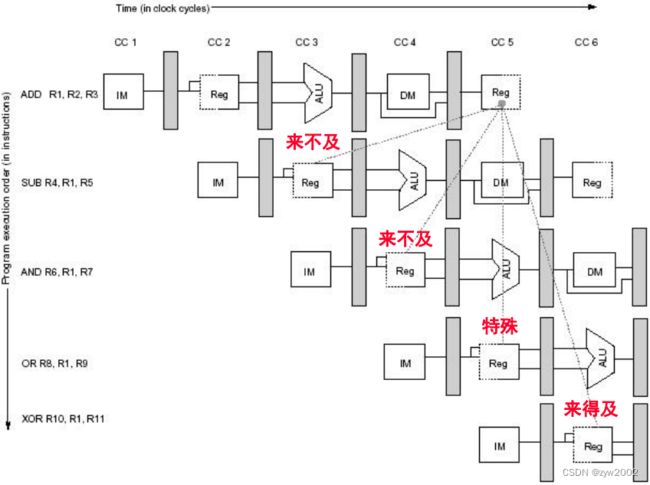
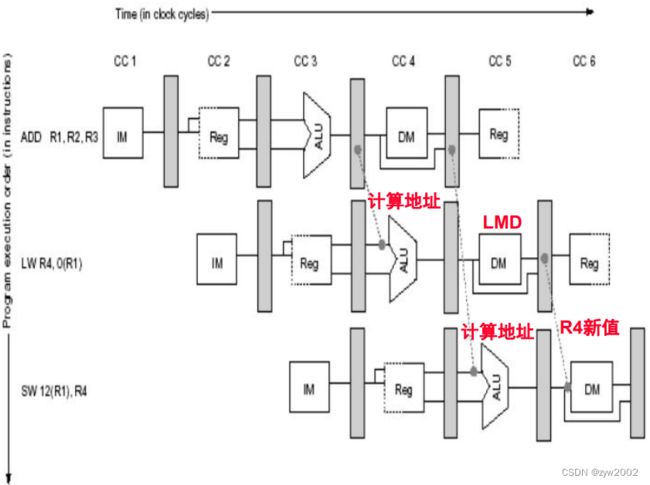
通过**前送(forward)**最小化数据冒险造成的停顿
结果从ADD生产它(EX/MEM)移动到SUB需要它的地方(ALU输入锁存),从而避免失效(stall)
Forwarding 的工作原理
- ALU result from EX/MEM register is always fed back to ALU input latches.
- detects -> previous ALU has written a pipeline register -> it is a source for current ALU -> select forwarded result (not register file) as input
- 由EX/MEM寄存器产生的ALU总是反馈给ALU的输入锁存器。
- 检测,前一个ALU已经写入到了流水线寄存器,选择转发结果(而不是不是寄存器)作为输入
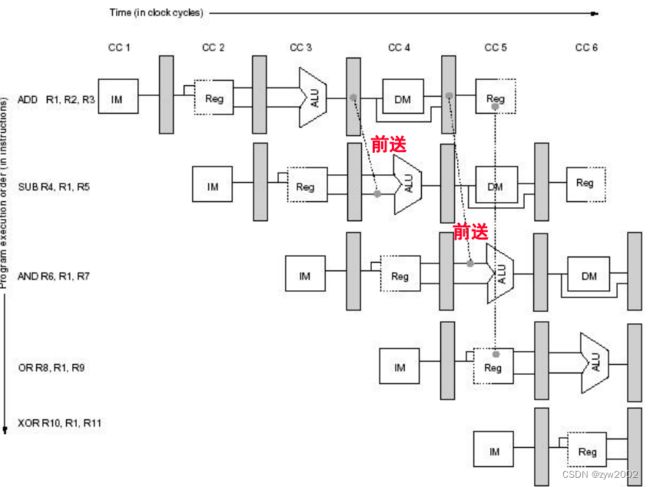
广义的转发:从一个单元转发到另外一个单元
例如下面的例子:

数据冒险分类
RAW, WAW, WAR
读后写(RAW): 读完之后才能正确的写,否则写入的是旧值。最常见的
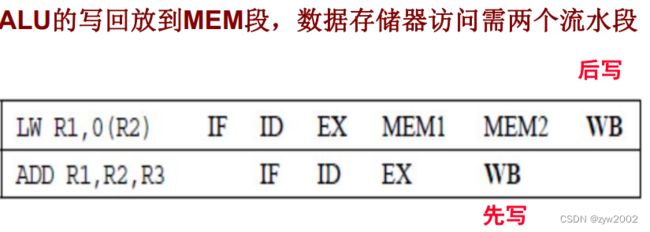
写后写(WAW):只会发生在在多个阶段都会写的流水线中。DLX只在WB阶段写,不会发生WRW冒险
如果改成下面这样,就会发生WAW冒险
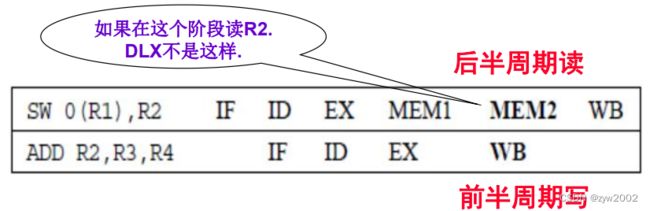
写后读(WAR): 不会出现,因为所有读都早在ID,所有写都晚在WB
如果改成下面这样,就会发生WAR冒险
写后写(RAR):不属于冒险
需要停顿的数据冒险
前送(Forwarding)不能解决所有问题

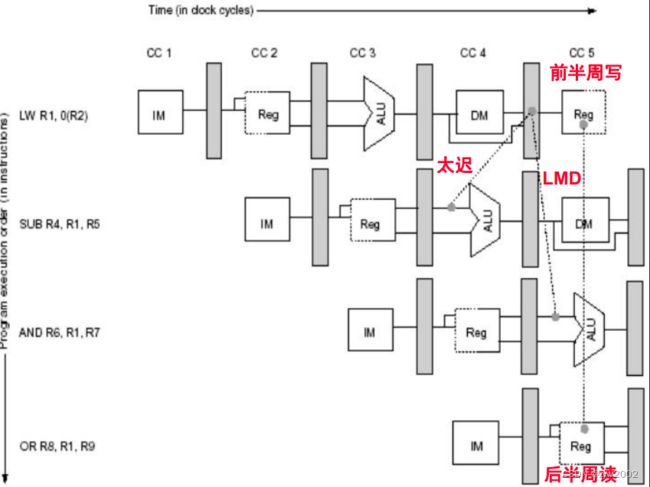
流水线互锁: 加入的硬件。检测、阻塞流水线直至冒险消失。CPI的增加就是阻塞的大小
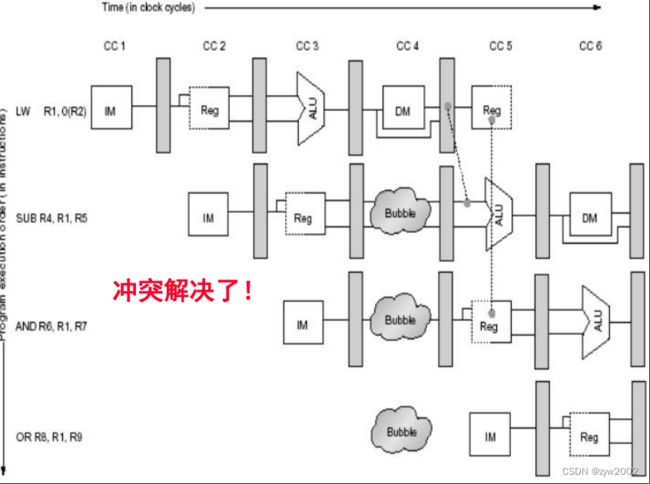
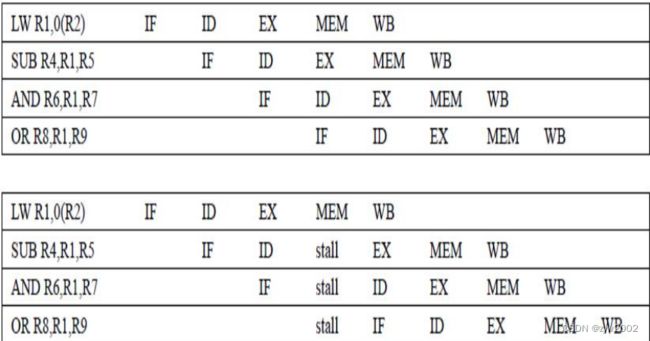
Load冲突的影响:


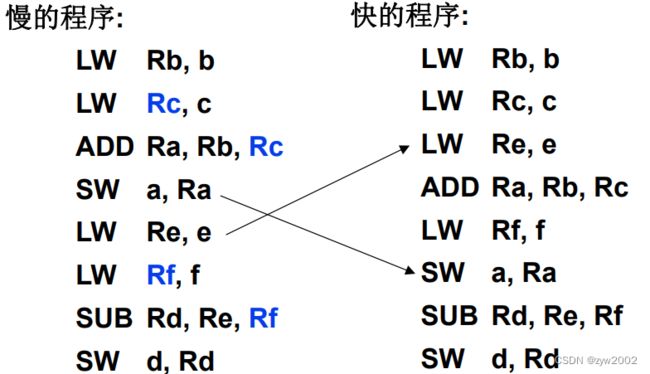
数据冒险的编译调度

通过调度来解决冲突:重新安排代码顺序, 以消除冒险,避免出现:load紧后面的指令需要load的结果


实现对DLX流水线的控制
发射: ID->EX
对DLX整数流水线, 所有冒险都可在ID阶段检测出来
如果有冒险, 就在发射之前停顿
在ID阶段还确定需要的前送,并在需要时施加相应的控制
两种策略:
早解决: 不用将指令悬挂起来, 降低硬件复杂性
在使用操作数的周期才检测冒险或前送
如何实现load互锁:
在ID检测
在EX阶段前送到ALU的输入
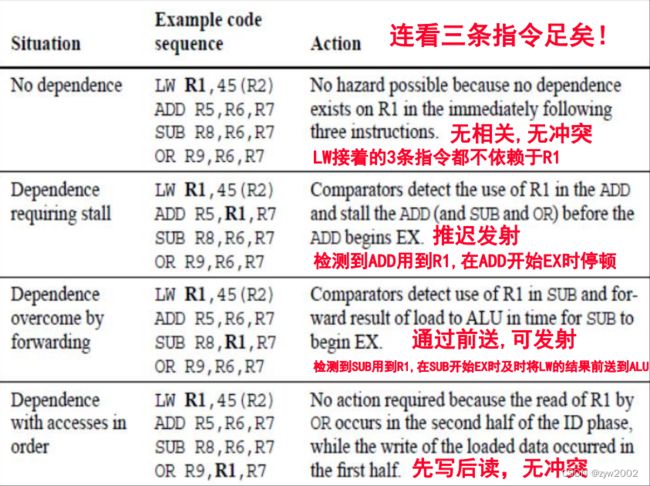

如何实现阻塞:
所有控制信息都在流水线寄存器中
冒险时, 插入停顿, 阻止IF和ID中的指令继续前进
ID/EX流水线寄存器的控制部分全置零,全零对应于no-op, 就是什么也不做
IF/ID寄存器内容循环, 保持的停顿指令
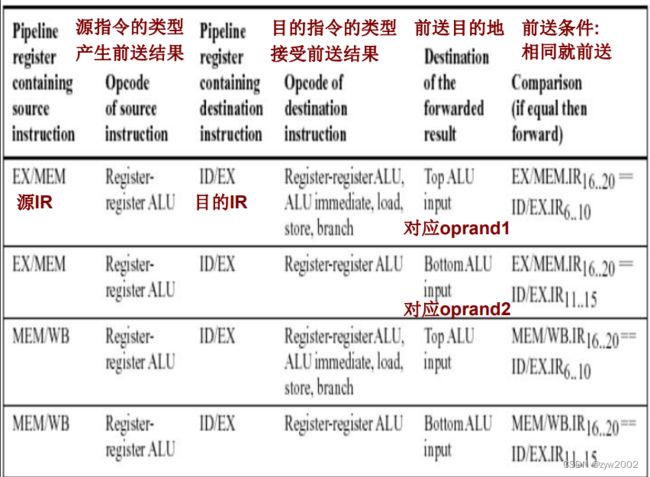
如何实现前送:
所有信息都在流水线寄存器中
前送的数据、源寄存器域、目的寄存器域都在流水线寄存器中

比较及可能前送操作:对于当前在EX中的指令, 前送的目标是ALU的一个输入
零检测单元: 也是一个前送目的地, 前送路径与当目标指令是ALU immediate时相同
多路选择器需要扩大
3.5 控制冒险
控制冲突: 可能比数据冒险造成的性能损失更大
转移如果成功,PC直到MEM结束(更新完地址)才改变
如何解决:
最简单的办法:检测到分支指令就阻塞 -> 直至其到达MEM计算出新PC
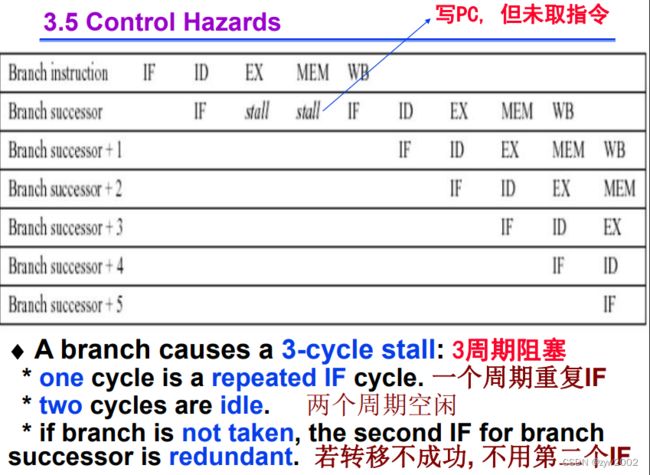
如何减少停顿周期数:
尽早确定是否转移,尽早计算出转移地址, 即PC的新值
对于DLX的具体做法:从原来的EXE中挪到ID中(将转移目标计算和转移条件测试挪到ID中;在IF写PC, 用ID阶段计算出的目标地址或者IF阶段计算出的递增PC.)
修正后的流水线在遇到转移指令时只有一个周期停顿

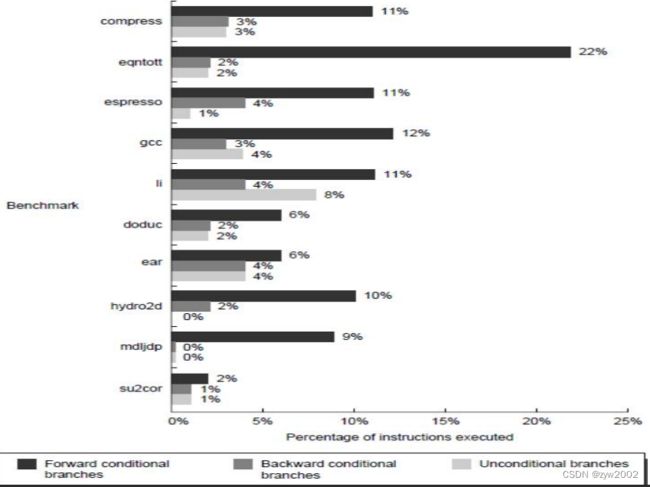
程序中的转移行为
控制流操作的总体频率


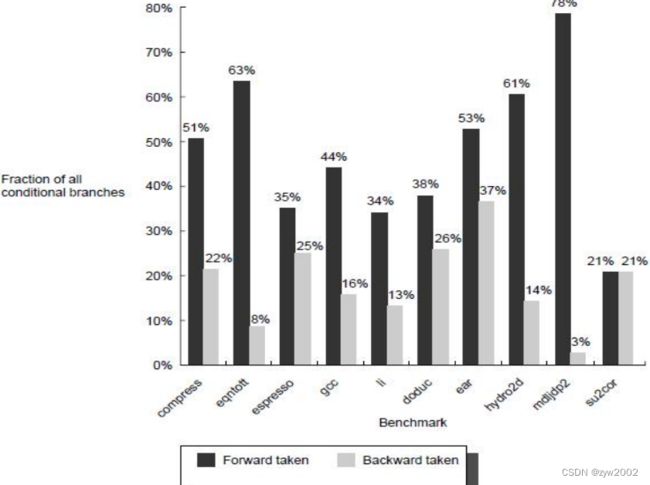
降低流水线中的转移造成的惩罚
利用硬件设计方案和转移行为来最小化转移惩罚
方案1: 冻结(freeze)或泄放(flush)
保持或删除转移指令后的指令,直至转移目的地址已知
方案2: 预测为转移不成功
继续,就好像没有执行转移语句。必须小心,不能改变机器状态,直到完全知道转移结果。如果是成功转移, 将已取出的指令变为no-op, 并重新取指。
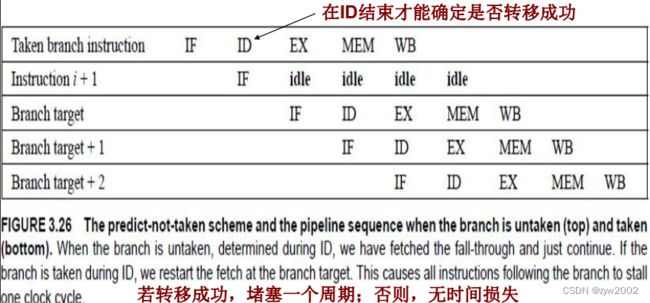
方案3: 预测为转移成功
解码并计算出目标地址后,就假设转移成功并从目标处取指和执行
方案4: 延迟转移
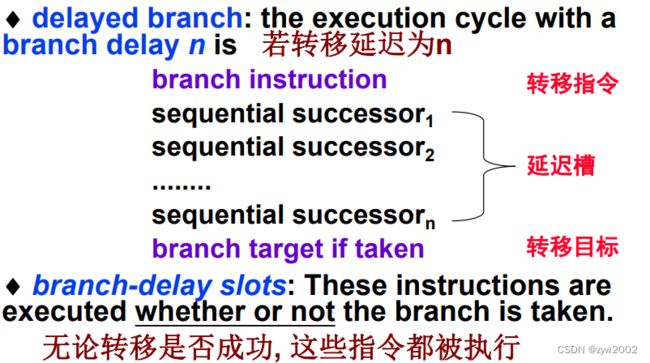
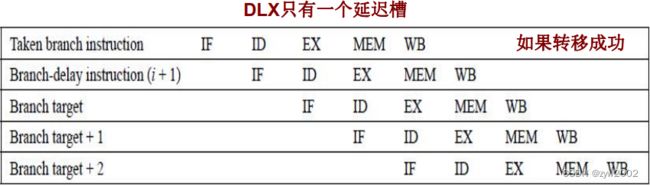
编译器的任务:
要求:使转移指令后面的指令(即延迟槽中的指令)正确且有用
三种分支延迟的调度方法
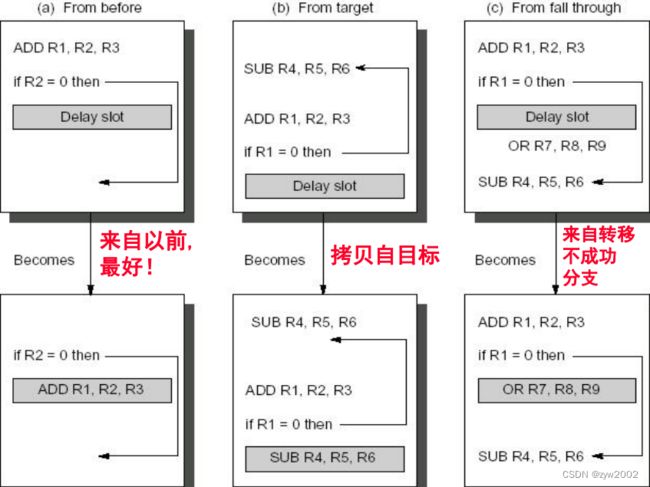
各种调度方案的不同约束, 以及能改进的情况

延迟转移的制约因素:对被调度指令的限制;预测能力
延迟转移优点:能用简单的编译器调度来降低转移惩罚
转移方案的性能

静态转移预测:采用编译器技术
准确预测是重要的:延迟转移的有效性取决于我们能否正确地猜测出转移方向;精确预测对调度数据冒险也有益
预测依据:考察程序行为;采用profile信息
预测方案:最简单方案: 预测为转移成功;另一种方案: 根据转移方向进行预测;更精确技术:根据早期运行的profile信息来预测
3.6 扩展DLX流水线→处理多周期操作
多周期操作: 流水线中如何解决?
DLX浮点操作在一个周期内完成不现实,会导致慢的时钟,FP单元中大量的逻辑
对FP流水线做两个变化:EX可重复很多次完成;可有多个浮点单元
扩展DLX: 带多周期功能单元
4种功能单元:整数单元,整数单元,浮点加法器, 浮点和整数除法器
前面指令离开EX之前, 后面使用单元的指令不能发射;如果一条指令不能前进到EX, 则后面的流水线将停顿
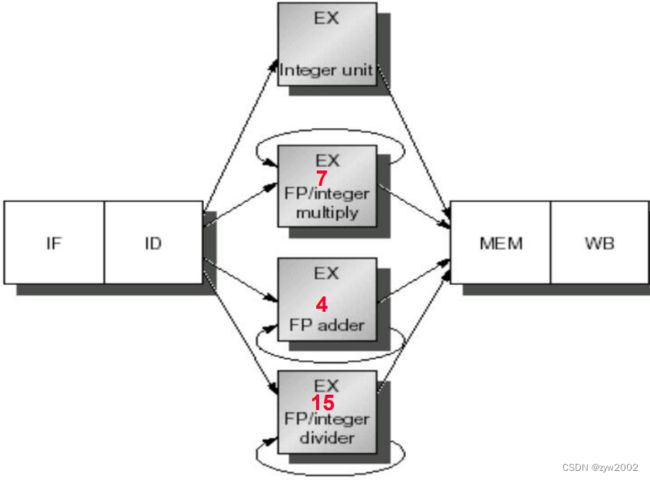
流水化, 使得多个操作同时执行
latency: 从产生结果到能使用结果之间的周期数
发射两个给定类型操作之间必须经过的周期数




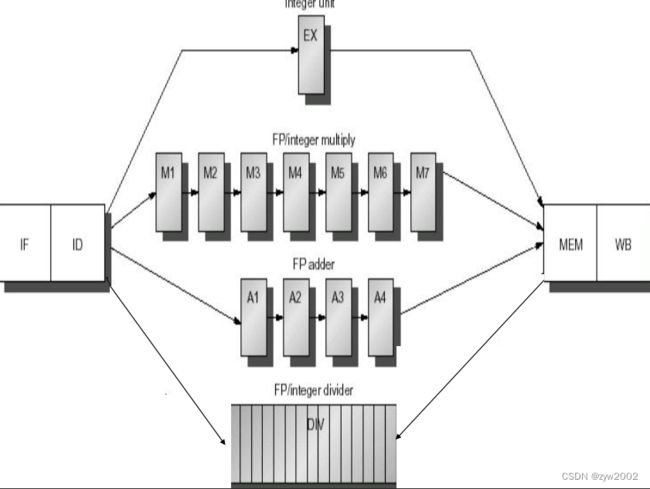


长延迟流水线的冒险和前送:
除法单元未充分流水化, 可能导致结构冲突, 需要检测,并使指令发射停顿。
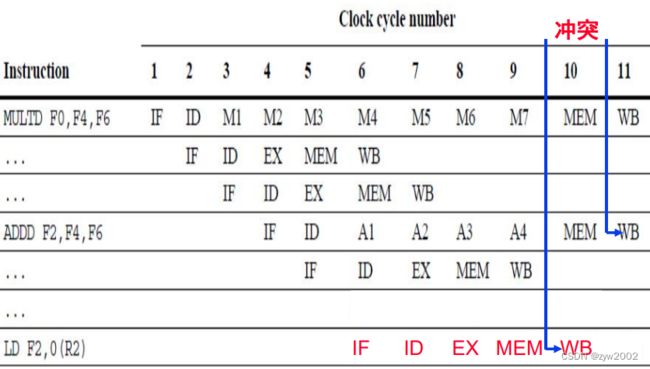
指令运行时间不同, 会导致同一个周期有多个寄存器写操作, 形成结构冲突
指令不再按序到达WB,可能导致WAW冒险,寄存器读总在ID发生,所以不会有WAR冒险
操作的长延迟,导致RAW冲突更频繁
长流水线大大增加了阻塞的频率。一般,同一个周期不能同时有两个指令处于MEM阶段
而EXE段有多种操作单元的情况下可并行进行。
FP寄存器文件有一个写端口, 序列的FP操作会为此产生冲突
在第11周期, 3条指令都到了WB阶段并要写寄存器文件, 从而导致结构冲突
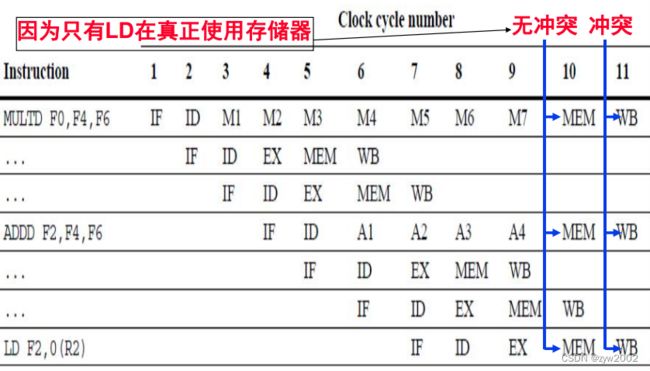
方案:增加端口作为结构冲突解决
若只有一个写端口, 就必须使指令串行化;可增加写端口数, 但没有吸引力, 因为增加的端口很少使用
如何解决结构冲突:两种途径
1)早解决: 在ID阶段跟踪写端口的使用, 并在发射之前阻塞指令
如果检测到处于ID的指令与早先发射的指令在同一周期使用寄存器文件, 则该指令阻塞一个周期
跟踪操作用移位寄存器实现, 每个周期移一位
优点: 在ID阶段就完成互锁检测和阻塞插入; 成本: 要加入移位寄存器和写冲突逻辑
到时候再解决: 在冲突指令要进入MEM或WB时阻塞之
优先考虑具有最长潜伏期的指令, 这些指令最有可能引起其他指令阻塞
优点: 直到MEM或WB才检测冲突, 因此容易
缺点: 使流水线控制复杂化, 因为可从两个地方插入阻塞




3.7 动态方法解决数据相关
迄今解决冲突的途径:没有冒险, 或者可以前送,则发射;否则, 阻塞,直至依赖关系解除
编译器技术;静态调度
动态调度:
硬件重新安排指令执行, 以降低阻塞
优点:能处理在编译时不知道的依赖关系, 简化了编译器;使得在一个流水线上编译的代码, 在另一个流水线上也能高效运行
动态和静态调度对比:
动态调度:不是消除数据依赖关系, 而是在存在依赖关系时试图避免阻塞
静态调度:试图分开依赖的指令, 使得不会导致冒险
动态调度的思想
按序发射的问题:一个指令被阻塞,其后续的无关指令也别阻塞
乱序执行:希望一但得到操作数, 指令就执
ID分解成两个阶段:
发射: 指令解码, 检测结构冒险
读操作数: 等待, 直到无数据冒险
Fetch将指令读到锁存器或队列中, 然后从那里发射,可能需要多个周期
动态调度的Tomasulo方法

保留站:WAW和WAR冒险由保留站的功能消除。保留站缓冲待发射指令的操作数
只要操作数可用, 保留站就取来并缓冲, 从而避免从寄存器取操作数
悬挂的指令指定为其提供操作数的保留站
重命名: 当指令发射时, 未定的操作数被重命名为保留站的名字
发射逻辑和保留站提供重命名功能, 消除了WAW和WAR冒险
由于保留站比寄存器多,所以能消除编译器不能消除的冒险
保留站的内容:
指令:已发射,在等待执行
操作数或操作数源
指令执行时用于控制的信息
Load和store缓冲器的内容: 装载 来自/去往 存储
浮点寄存器以一对总线连接到功能单元, 以一个总线连接到Store缓冲器。来自功能单元和存储器的所有结果都送到公共数据总线, 并由此送到除load缓冲器外的各处。
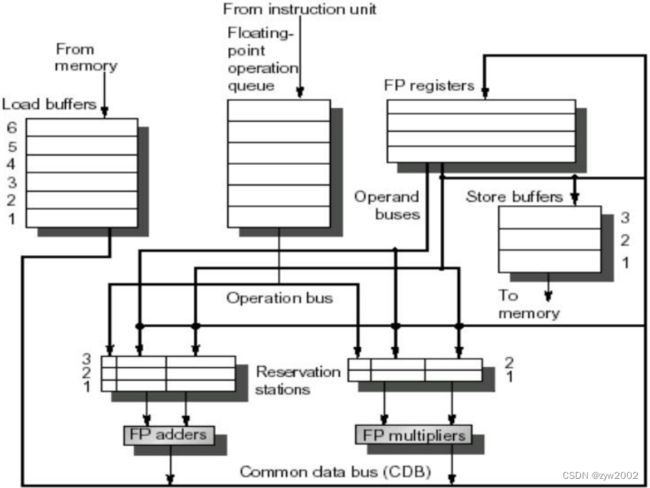
采用Tomasulo算法的DLX FP单元的基本结构:
浮点操作在发射时从指令单元进入队列
保留站包括操作及操作数, 以及用于检测和解决冒险的信息
Load缓冲器: 装载尚未完成的load的结果, 在等待CDB
Store缓冲器: 装载尚未完成store的目标地址, 在等待操作数
所有来自FP单元或load单元的结果都放到CDB上, 从这里去往FP寄存器文件以及保留站和store缓冲器
指令经历的步骤:3个步骤





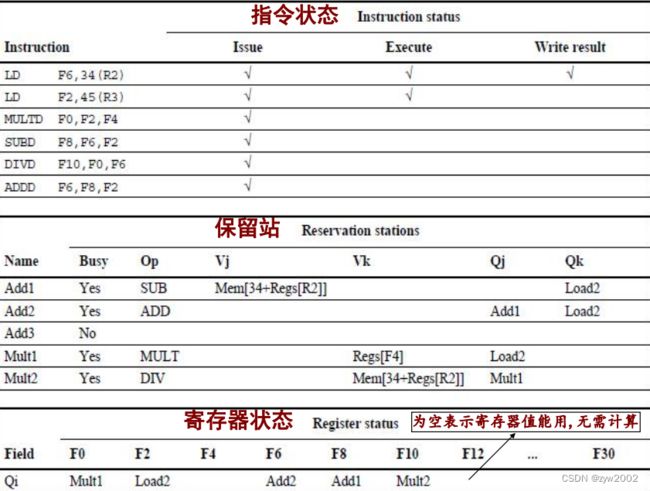
附加add、mult、及load的数字代表相应保留站的标签(用于重命名)
Tomasulo算法的主要优点:
冒险检测逻辑的分布化(指RAW)
消除了由WAW和WAR冒险造成的堵塞
第一个优点:来自于分布式保留站和CDB的采用
若多个指令等待一个结果(它们的另一个操作数已有);结果一经算出, 可通过CDB传播, 从而同时释放所有指令
第二个优点(消除了WAW和WAR): 来自于以下两点:
用保留站对寄存器重命名; 数据一得到即送入保留站
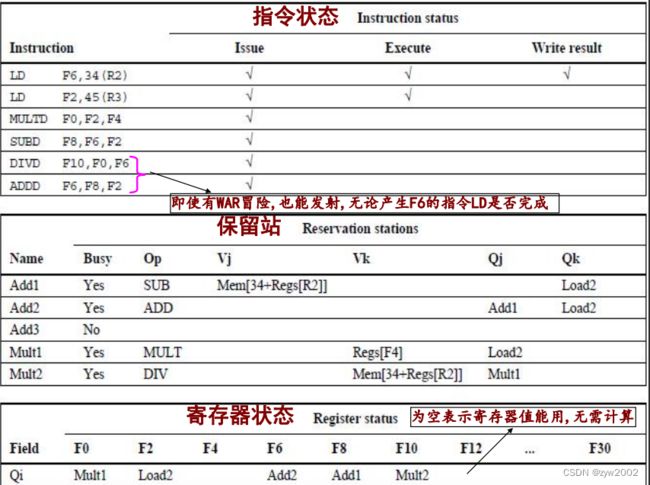
Tomasulo算法的缺点:
复杂性, 需要大量硬件;特别是, 需要大量高速存储以及复杂控制逻辑
最后, 性能的改进受到CDB限制. 虽可再加CDB, 但每个CDB都必须与所有硬件相互作用
Tomasulo算法总结:
用更大量虚拟的寄存器(即保留站)对寄存器进行重命名(用来解决操作数还未计算出来时的WAR冒险)
对来自寄存器的源操作数进行缓冲(用来解决操作数已在寄存器中可用时的WAR冒险)


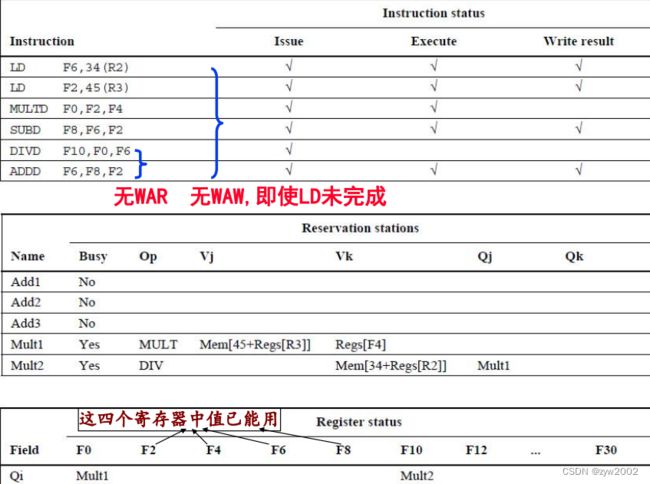

每条指令要经历的步骤:
发射: (D:目标(即需要这条指令计算结果的寄存器); S1,S2: 源寄存器号; r: 对D赋值的保留站或缓冲器; RS: 保留站的数据结构
保留站或load单元返回的值称为结果(result)
Register是寄存器的数据结构, Store是store缓冲器的数据结构
‘Ri’的意思是寄存器Ri, 而不是Ri的内容
当指令发射时, 其目标寄存器的Qi置为该指令的缓冲器或保留站的号
若操作数已在寄存器中, 就将其存到V域中; 否则, 就将Q域设置为产生这个结果的保留站
保留站中指令等待, 直至其两个操作数都可用(Q域为零).
当指令完成, 并且CDB可用时, 就写回结果
所有其Qi或Qk与刚完成的保留站相同的缓冲器、寄存器、保留站均从CDB更新其值, 并标记Q域(为零)以指示值已得到
CDB能在一个时钟周期内将其结果广播到很多目标. 那些等待操作数的指令就能在下一个时钟周期开始执行
3.8 利用硬件对转移进行动态预测
静态和动态预测:
静态: 采取的动作不取决于转移的动态行为
用硬件, 动态预测转移的结果. 转移行为改变, 则预测改变
这里要做的事情:
提出一个简单的预测方案, 然后考察提高精确性的方法;考虑更精致的方案, 以求更早地找到转移后的指令
基本转移预测和转移预测缓冲器
预测缓冲器或转移历史表: 最简单的动态转移预测方案
用转移指令的低地址部分所索引的一小块存储区,位: 表示最近该转移是否发生
1位预测的缺点:即使分支总是执行, 也可能预测错误两次(而不是一次).


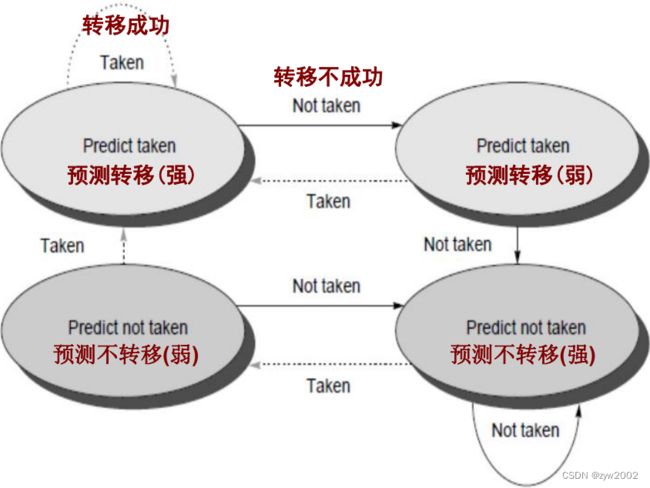
N位预测方案:
计数器可取值0到2n-1. 当 >=(2n–1)/2时, 预测转移; 否则, 预测不转移
计数器: 当转移时递增,不转移时递减
2位预测器就已经很好了, 因此多数系统用2位预测器
进一步降低控制停顿—转移目标缓冲器
为进一步降低转移惩罚, 需要在IF末知道取指地址
这意味着必须知道: 还没有解码的指令是不是转移指令;如果是,NPC应是什么
转移目标缓冲器: 存储所预测的转移后下条指令的地址
转移目标缓冲器优于转移预测缓冲器:
转移预测缓冲器: 在ID阶段访被问。在ID末才知道转移目标地址, 不转移时的地址, 以及预测结果。才能取出预测的下一条指令。
转移目标缓冲器: 在IF用取来指令的地址访问缓冲器。若命中, 就能在IF末知道预测地址, 比转移预测缓冲器早一个周期
被取来指令的PC与存储在第一列的一组地址(是一些已知的转移地址)进行匹配
如果匹配一个, 则正被取指的指令就被预测为一个成功的转移, 第二个域就包含着转移后的下一个PC, 取指就立即在那里进行
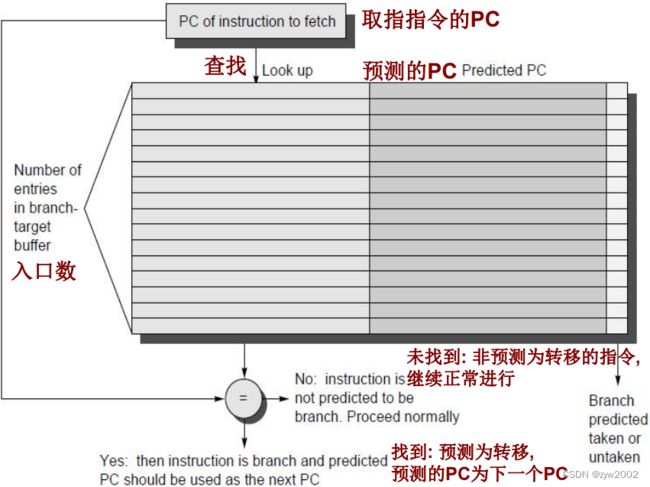
在转移目标缓冲器中, 只需存储预测为成功转移的转移,因为未成功的转移遵循与非转移指令相同的策略(即取下一条指令)。
采用转移目标缓冲器的步骤
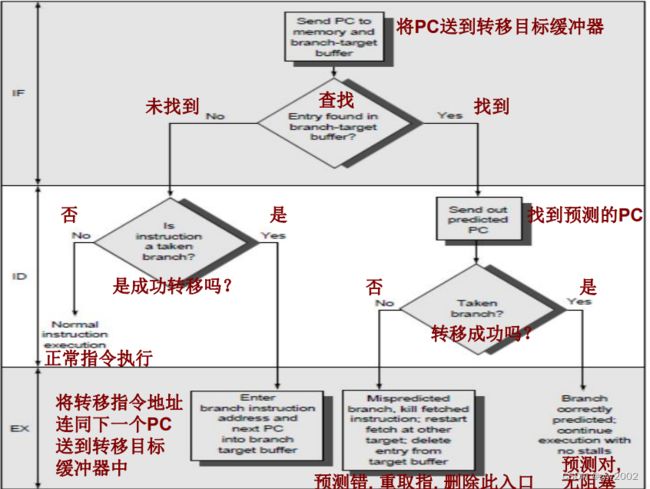
步骤:
如果在缓冲器中找到PC, 则该指令必是一个转移并且预测为成功转移。这样, 在ID段就立即从预测的PC处取指
如果未找到, 但接下来发现该指令是一个转移成功的指令, 就将该指令连同目标地址(在ID段末知道)送入缓冲器
如果找到, 但发现该指令不是一个成功的转移, 则将其从缓冲器中移除。
如果是转移, 找到, 且预测准确, 则执行无耽搁
如果预测不对, 则因取错指令耽误1个周期, 又因在一个周期后才能重取指令而耽误1个周期, 故总的错误预测惩罚为2个周期
如果未找到, 且发现是转移, 则按照预测不转移的策略处理。惩罚取决于实际是否转移
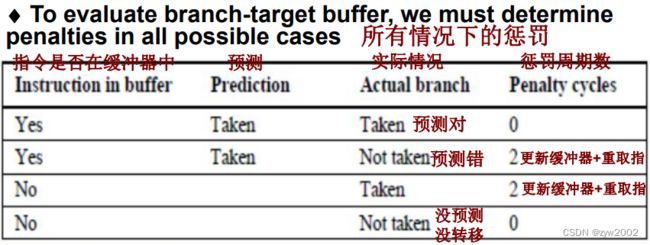

3.9 借助多发射提高指令级并行
多发射处理器(multiple-issue processor): 允许在一个周期发射多条指令. 有两类
- 超标量处理器(superscalar processors)
每个周期发射不同数量的指令; 可用编译器进行静态调度, 或者采用Tomasulo进行动态调度
2)超长指令字处理器 (VLIW (very long instruction word) processor)
发射固定数量的指令, 格式化成一个大指令(固定指令包)当然用调度器进行静态调度
DLX的超标量型式
超标量:
硬件可在一个周期发射1到8条指令
这些指令必须独立, 并满足一些约束(例如: 每个周期不能发射多于一次的存储器访问)
否则, 只能发射那条指令前面的指令, 因此发射率是变化的
超长指令字:
编译器完全负责打包, 硬件不动态做任何决策;因此, 超标量处理器有动态发射能力, 而VLIW处理器有静态发射能力
DLX 处理器作为超标量看待是怎么样的?
假设每个周期发射两条指令. 一条指令可能是load, store, branch, 或ALU,另一条指令可能是FP操作
同时发射一条整数指令和一条浮点指令, 简单, 要求低
需要指令成对
硬件动态做出决策, 如果条件不满足就只发射前一条指令





3.10 指令级和线程级并行
ILP和TLP: 指令集并行和线程级并行
TLP: 同时运行多个线程
线程:程序将自身分解成多个同时运行的任务的方式
在标量处理器上,多线程通常通过时分多路选择实现
Interleaved multithreading (IMT);交错式多线程: 在每个处理器周期, 其它线程的指令都被取出并送入执行的流水线
Blocked multithreading (BIT):阻塞式多线程:线程的指令连续执行直至一个会引起延迟的事件发生。
4. 存储体系
4.1 简介
本章讨论帮助程序员建立一个虚拟无限的快速存储器
局部性原理
借助局部性原理实现存储体系,局部性有两种体现:
时间局部性:被访问的内容在不久还会被访问
空间局部性:与被访问的内容临近的内容很快也会被访问
例如:大部分程序中都有循环,循环内的指令和数据反复的被访问体现了时
间局部性。指令通常是顺序的被访问的,反映了空间局部性。
存储器的层次结构
存储体系中包含了不同速度、不同容量的多级存储器,最快的存储器通常价格最高,容量最小。目前有三种主要的存储技术用来实现存储体系,主存用 DRAM 实现,与 cpu最近的 CACHE 用 SRAM 实现,存储层次中最大容量、最慢速度的那一级用磁盘实现。
目标:存储层次的目的是为用户提供最大容量、最低价格、最快速度的快速存储器。
存储体系中包含多级存储器,数据每次只在相邻的两级间被拷贝,靠近处理器的为上一级存储器(upper level),远离处理器的为下一级存储器(lower level)。
最靠近处理器的层次是其它更低层次的子集, 所有数据都存储在最低层次
数据只能在相邻层次间拷贝
上层比下层容量小, 但速度快
层次中信息的最小单位, 称为块
存储器的性能参数
- 基本术语
命中: 需要的数据出现在高层某块中
缺失: 数据在高层未找到. 需要访问底层来寻找包含所需数据的块
命中率:数据在高层找到的比率
缺失率: 数据在高层找不到的比率
命中时间: 访问高层的时间,包括确定该访问是命中还是缺失所需时间
缺失惩罚: 用低层块替换高层块, 再加上将块送到处理器所需时间
4.2 cache 基本知识
4.2.1 访问cache
-
如何提高存储性能?
利用时间局部性: 将最近访问数据项放到接近处理器的地方
利用空间局部性: 将包含多个连续数据的块移到高层 -
如何知道数据是否在cache中? 如果在, 如何找到?
- 直接映像 (direct mapped)
每个存储器位置精确地映射到cache中的一个位置。
( 块 地 址 ) m o d ( 缓 存 中 的 块 数 ) (块地址) mod (缓存中的块数) (块地址)mod(缓存中的块数)
Tag: 标记: 附加在Cache中, 指示cache中的数据是否对应于所需要的字。 只需包含地址的高位部分(就是没用于索引cache的部分)
Valid bit: 有效位: 指示某入口是否包含有效的地址. 若未置位, 表示没有匹配的模块
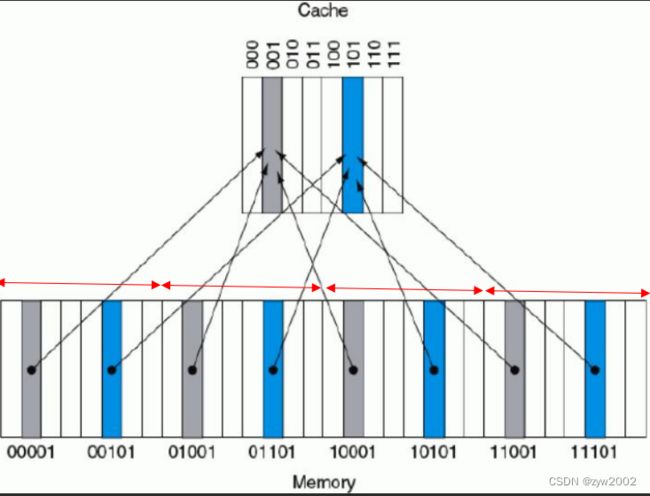
如上图,cache一共有8块( 8 = 2 3 8=2^3 8=23) , 因此后三位相等的被映射到缓存的同一个块中。Tag对应的是前两位。

地址的低部分用来选择cache入口
cache的tag与地址高部分比较, 用来确定该cache入口是否对应于所需的地址
Cache有210个字, 块大小为一个字. 10位用来索引cache, 剩下的32-10-2位就用来与tag比较
如果tag与高20位相等, 则命中, 能取得数据到CPU; 否则, 缺失。
对于一个32位的地址,采用直接映射,缓存的大小为 2 n 2^n 2n,一个块的大小为1个字(相当于4个字节),需要的tag的位数为 32 − ( n + 2 ) 32-(n+2) 32−(n+2) ,其中2bits是用来标志字节索引,n bits是用来索引。总共的位数= 2 n ( b l o c k s i z e + t a g s i z e + v a l i d f i e l d s i z e ) = 2 n ∗ ( 32 + ( 32 − n − 2 ) + 1 ) = 2 n ∗ ( 63 − n ) 2^n(block size + tag size + valid field size)=2^n*(32+(32-n-2)+1)=2^n*(63-n) 2n(blocksize+tagsize+validfieldsize)=2n∗(32+(32−n−2)+1)=2n∗(63−n)
- 直接映像 (direct mapped)
4.2.2 cache 缺失/失效处理
如何解决指令Cache缺失?
1)将原来的PC值(当前PC-4)送到存储器
2)执行存储器读操作
3)写入cache: 将从存储器读来的数据送到数据部分, 高位地址送到tag域, 将valid置位。
4) 重新执行指令, 重取指, 并在cache中能找到
数据catch失效时,可采用类似的措施
4.2.3 写直达和写返回
读的步骤
1)将地址送到cache(对于读指令). 地址或者来自PC, 或者来自ALU(对于访问数据
2)命中: 得到所需要的字
缺失: 将地址送到存储器, 取来数据, 写入cache
写的步骤
不一致(inconsiitent): 在向cache写后, 存储器与cache中值不一致
写直达(write-through): 总是将数据同时写入存储器和cache
写缺失
只需将数据写入cache, 更新tag和数据
1)用地址的15-2位索引cache
2)将地址的31-16位写入tag, 将数据字写入到数据部分, 将valid位置位
3)也将字写入主存
通写的劣势
虽然处理简单, 但效率不高。每次写cache都同时导致数据写入主存. 写主存需要长时间, 大大减慢机器速度
写缓冲器(write buffer)
在写入cache和buffer后,处理器能继续执行
当写存储器完成后, 就释放写缓冲器的相应入口
如果buffer满, 而处理器又要写, 则必须阻塞以便得到空位置
如果处理器完成写的速率低于处理器产生写的速率, 多少缓冲器也不够用,因此要增大buffer的深度
写反回(write back)
当发生写时, 新值只写入cache块
被修改的catch块只有在被替换时才被写入低层
当处理器生成写的速度等于或快于主存处理写的速度时, 尤能提高性
写回比通写实现起来更复杂
4.2.4 利用空间局部性
为了充分利用空间局部性,可将 cache 块的长度增大,当发生 cache 失效时,取多个字构成的 cache 块。
如图块内索引字段用于控制多路选择器。从被索引的块中选择所需要的word。
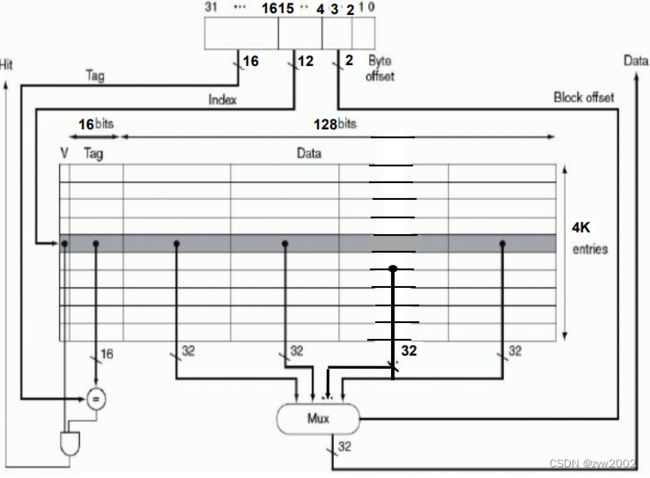
上图展示了一个可以存储64KB大小的缓存,每一个块包含4字(16个字节)
tag field: 16bits
index field: 12 bits,
index blockfield: 2-bit (bit 3-2)
select word: 4-to-1 multiple
对于多字块长的 cache 而言,tag 和 valid 所占位数减少,这种多个字共享 tag 更能改善 cache 存储空间的利用率(可保存更多有效的内容)。
例子:
假设缓存中一共有64个块,块大小为16个字节。请问字节1200映射到的那个块地址。
1200/16 下取整=75
75 mod 64=11
对于多字块的读失效和单字块的读失效处理方法相同,即将整个失效块从下一级读至 cache。但对于写失效,处理方法则不同。多字块的写失效需从存储器中将多字块读入 cache,再去修改。单字块的写失效直接将内容写入 cache。
多字块的缺失处理:
读缺失时要取回整个块
写命中和缺失时, 不能只写tag和数据
例子:
存储地址X和Y都映射到cache块C. cache目前存的是Y
现在用X覆写C的数据和tag
写完后, C就将
有X的tag, 但C的数据部分包含一个字的X和3个的Y
写缺失解决方法:
如果地址tag和cache入口tag相等, 则命中,可继续
如果不相等, 则是写缺失,必须从存储器中取回整个块, 然后再重写导致缺失的字到cache
4.2.5 增大主存——cache带宽
如果增大从主存到 cache 的带宽就可以降低缺失损失时间。
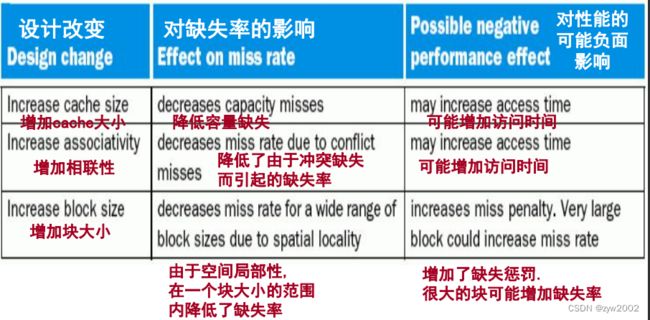
块大小的影响:一般情况: 块增大, 缺失率下降
但是, 总是这样吗?事实并非如此:块增大, cache中块数减少, 则块间竞争激烈, 则块频繁调入/调出cache(其中很多字还没有被访问前), 则缺失率上升
块增大的另一个影响:缺失成本增大
缺失成本由从下一级取块所需时间所决定。分成两部分: 传输第1个字的时间, 传输块的其余部分的时间
传输时间随块增大而增加
块增加得较大时, 缺失率的改进开始减小
结果就是缺失惩罚的增加淹没了大块所降低的缺失率
降低取第一个字的时间是困难的, 但可通过提高存储器到cache的带宽来降低缺失惩罚
这就可采用较大块且仍保持低的缺失惩罚
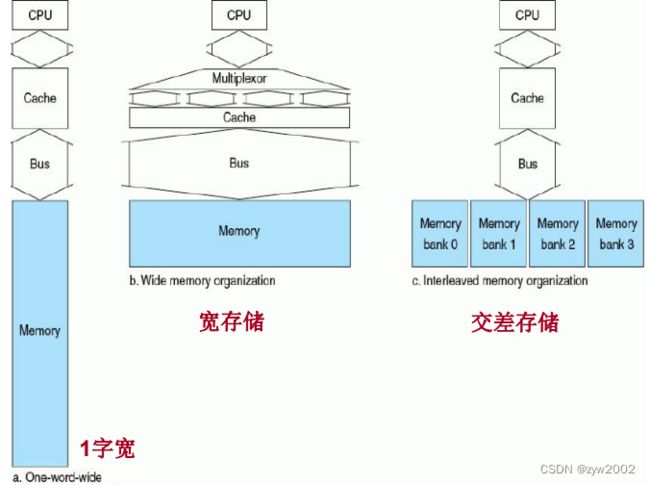
设计存储系统有3种选择
-
存储器一个字宽, 所有访问顺序进行

-
通过加宽存储器和总线来增加带宽, 允许对块的所有字并行访问

-
通过加宽存储器(但不加宽总线)来增加带宽. 这样, 在传输每个字时仍付出代价, 但避免了多次访问延迟的代价

总结:
根据空间局部性, 块大于1个字时, 会降低缺失率, 也降低Tag的存储。但用大块会增加缺失惩罚,导致低性能。为避免, 可增加带宽. 2个常用方法是: 存储器加宽和交差存储
两种提高cache性能的技术:
- 通过降低两个存储块竞争同一个cache位置的概率来降低缺失率。(后面将要讲到组相联和全相联)
- 通过向层次结构中再增加额外的层次来降低缺失惩罚, 称为多级cache
4.3 衡量/提高cache性能
本节讨论关于如何分析及衡量 cache 性能,同时提出两种不同的技术改进cache 性能,即通过降低失效率来减少存储器块对同一 cache 块位置的争用,以及通过设立多级 cache 来减少失效开销
4.3.1 衡量cache性能
通常假设 cache 命中时的访问时间是正常的 cpu 执行周期的一部分。因此
C P U t i m e = ( C P U 执 行 周 期 + m e m o r y 停 顿 周 期 ) ∗ 时 钟 周 期 时 间 CPUtime=(CPU 执行周期+memory 停顿周期)*时钟周期时间 CPUtime=(CPU执行周期+memory停顿周期)∗时钟周期时间
存储器停顿主要由 cache 缺失引起,可以定义为读停顿周期加上写停顿周期:即
m e m o r y 停 顿 周 期 = 读 停 顿 周 期 + 写 停 顿 周 期 memory 停顿周期=读停顿周期+写停顿周期 memory停顿周期=读停顿周期+写停顿周期
可以将读写合并为一,即
m e m o r y 停 顿 周 期 = ( 访 存 次 数 / 每 程 序 ) ∗ 失 效 率 ∗ 失 效 开 销 memory 停顿周期=(访存次数/每程序)*失效率*失效开销 memory停顿周期=(访存次数/每程序)∗失效率∗失效开销
也可以表示为:
m e m o r y 停 顿 周 期 = ( 指 令 数 / 每 程 序 ) ∗ ( 失 效 次 数 / 每 条 指 令 ) ∗ 失 效 开 销 memory 停顿周期=(指令数/每程序)*(失效次数/每条指令)*失效开销 memory停顿周期=(指令数/每程序)∗(失效次数/每条指令)∗失效开销
读 停 顿 周 期 = ( 读 次 数 / 每 程 序 ) ∗ 读 失 效 率 ∗ 读 停 顿 周 期 读停顿周期=(读次数/ 每程序)* 读失效率*读停顿周期 读停顿周期=(读次数/每程序)∗读失效率∗读停顿周期
写直达的阻塞:
写缺失:通常要取来块后再继续写
写缓冲器阻塞: 写发生时写缓冲器已满
写 停 顿 周 期 = ( 写 次 数 / 每 程 序 ) ∗ 写 失 效 率 ∗ 写 停 顿 周 期 + 写 缓 冲 停 顿 周 期 写停顿周期=(写次数/ 每程序)* 写失效率*写停顿周期+ 写缓冲停顿周期 写停顿周期=(写次数/每程序)∗写失效率∗写停顿周期+写缓冲停顿周期
写缓冲器阻塞: 不能给出一个简单的公式计算出来。
如果缓冲器深度合理, 存储器足够块,写缓冲器阻塞可忽略
写返回阻塞
写回阻塞: 替换时会发生阻塞(要将cache块写回存储器)





同时改进时钟频率和CPI会如何?
较低的CPI意味着阻塞周期影响更大, 如果存储器访问时间不变, 更高的CPU频率导致更大的缺失惩罚.因此, 对于低CPI和高时钟频率, cache性能更重要
如果处理器的进度提高,但存储器的速度保持不变,那么相对于整个的执行时间而言,花在存储器等待的时间比例将增大。即 cache 失效开销相对度大。如果计算机在 CPI 与时钟速率都改进的情况下,cache 失效开销的相对损失更大。因此不能忽视对 cache 性能的改进。
如果 cache 的命中时间增加,就会导致处理器周期时间的增大,从某种意义上说,大容量 cache 的命中时间也会增大,如果这一因素超过了对命中率的改进给机器带来的好处,就会导致处理器性能的下降。借助更灵活的块的摆放来减少 cache缺失。
4.3.2 借助块放置方式降低cache失效率
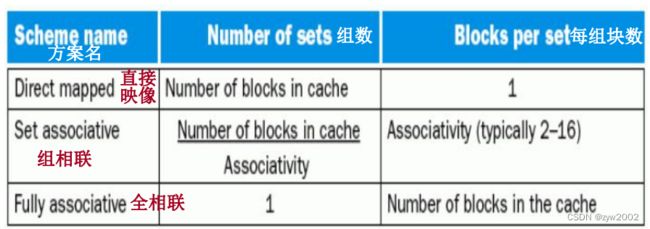
关于块的摆放模式有一系列的方法,直接映像是其中一个特殊的方法,即一个块在上一级存储区中只有一个存放的位置。另一个也很特别的模式是全相联映像,存储器中的一个块可以放在 cache 中的任一个位置上。在全相联 cache 中查找一个块必须搜索所有的块,通常使用比较器并行地进行,这也显著地带来了硬件成本的增加,因此这种全相联映像只使用与小容量 cache。
介于全相联和直接映像中间的策略是组相联映像。对于组相联映像的 cache,主存块有几个位置可供选择,有 n 个可供选择的位量就成为 n 路组相联。N 路组相联的 cache 包含若干个组,每个组内有 n 块。每个存储器的块映像到 cache 的唯
一个组,但可以放到这个组内的任意一个块位置上。
组 号 = ( 存 储 器 块 号 ) m o d u l o ( c a c h e 组 数 ) 组号=(存储器块号)modulo(cache 组数) 组号=(存储器块号)modulo(cache组数)
对于组相联 cache 的查找,组内的所有块都被搜索。对于全相联 cache 的查找,cache 的所有块都将被搜索。可将所有的关于块的摆放策略看成是组相联映像方式的变型,直接映像是一路组相联映像,每个组中只含一个 cache 块。M 个块的全相联 cache 也是 m 路组相联,它只有一组,但组内有 m 个块。
增加相联度可以降低失效率,主要的不足就是会增加命中时间。
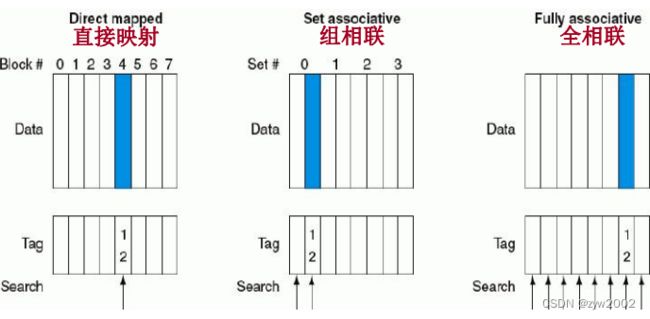
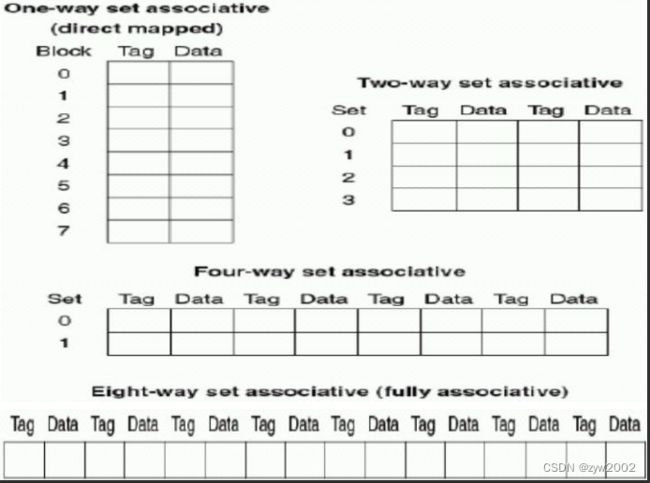
4.3.3 在cache中定位一个块
我们考虑在组相联 cache 中如何定位(即找出)一个块。图 4.18 给出组相联cache 的解析地址。Index 用来选择组,组内所有的 tag 都要被搜索。考虑到速度的影响,采用并行的方式搜索组内所有的 tag。在总容量一定的情况下,增大相联度可以增大每组内的块数,也增大了同时比较的数量。相联度每提高 2 倍,组内的块数也加了 2 倍,组数减少了一半,随之而来 index 区减少了一位,tag 区域扩大了一位。全相联 cache 没有 index 区,整个地址(除去块内偏移)都作为 tag,因此全相联映像没有索引过程,全部是 tag比较。直接映像 cache,只需一个比较器。图 4.19 的 4 路组相联 cache 需要 4 个比较器,这增加了硬件成本,同时,在组中进行选择时,也增大可时间开销。因此,在存储体系中关于映像方式的选择问题上,要综合考虑缺失影响,时间和硬件开销。
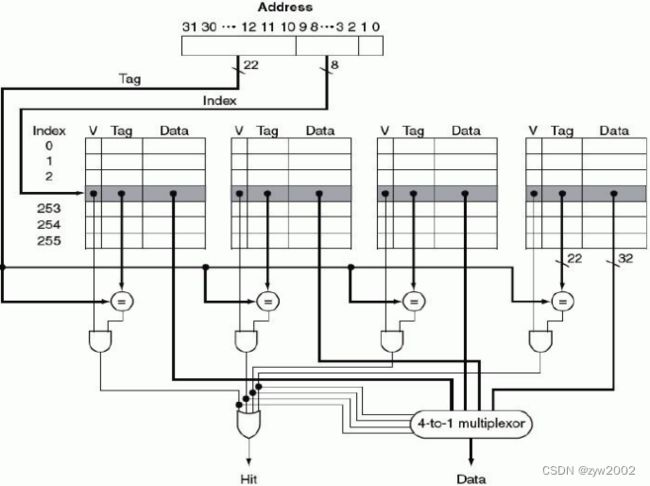
4.3.4替换原则
对于直接映像 cache,没有替换选择的问题。对于组相联和全相联 cache 都有替换选择的问题。
最常用的替换机制就是 LRU(近期最少使用),必须跟踪块的使用情况
4.3.5 利用多级cache减少失效开销
为了进一步弥补现代高频处理器和 DRAM 访问的时间过长的差距,采用再增
加一级 cache 的策略,即二级 cache。
在访问主 cache 缺失的情况下,访问二级 cache,这样一级 cache 的失效开销就是访问二级 cache 的时间,而不是访主存的时间。
对于两级 cache 结构来说,通常主 cache 的设计目标是减少命中时间,使 CPU有更短的时钟周期。二级 cache 的设计目标是降低缺失率,减少访主存的开销。
由于二级 cache 的出现,可以大大减少一级 cache 的失效开销。相对于单级 cache 而言,多级 cache 的主 cache 容量可以比单级 cache 的容量小cache 块的容量也可以小。而二级 cache 的容量要比单级 cache 的容量大,且cache块的容量也比单级 cache 块的容量要大。



二级cache的设计考虑:
初级专注于最小化命中时间, 二级专注于命中率(以降低惩罚)
初级: 由于缺失惩罚大幅降低, 使得初级cache可以更小, 有更高的缺失率
二级: 访问时间变不重要, 因为它影响初级的缺失惩罚, 而不是直接影响初级的命中时间
变化的影响:
与单级cache相比, 初级cache通常较小
初级cache通常采用较小的块, 较小的cache, 以及较低的缺失惩罚
二级cache较大, 因为二级的访问时间较不重要
总结:
三个主题: cache性能, 采用相联性降低缺失率, 多级cache降低缺失惩罚
存储系统可对性能有很大影响
处理器越快, 存储器阻塞的相对影响就越大
存储器阻塞周期数依赖于缺失率和缺失惩罚
挑战: 在不大幅影响其他因素的情况下降低一个因素
相联性:
要降低缺失率,就要在cache中采用更灵活的布局策略
全相联:块可置于任何位置, cache中的每个块都被搜索, 每个cache块都有比较器进行并行搜索,成本高,不现实
组相联:现实的选择,只需在由索引选择出的一组块中进行搜索,命中率改进, 但稍
多级cache用于降低缺失惩罚, 这通过较大的二级cache来处理对初级cache的缺失来实现
因此, 缺失惩罚是二级的访问时间, 而不是存储器的访问时间
4.4 虚拟存储器
虚拟存储器的定义:主存也可以作为辅存的“cache”
虚拟存储器有两个目标:一个是允许多道程序有效,安全的共享主存,另一个目的是使得程序设计不再受主存容量的限制。
主存只需要包含多道程序的活跃部分,而 cache 只包含一道程序的活跃部分,当程序进行编译时,还不知道哪些程序将共享主存。因此每道程序在编译期间有它自己的地址空间。虚拟存储器完成程序地址空间到物理地址的转换。这种转换就为不同程序地址空间提供了保护。虚拟地址存储器允许一道用户程序超出主存的容量,并自动的管理主存和辅存,而不再需要程序员对程序进行装入或换出(主存)。
虚拟存储器与 cache 使用不同的术语。虚存的块称为页面,缺失时称页面错误。带有虚存的系统,CPU 使用虚地址,需要软硬件共同转换为物理地址。这一过程称为存储器映射或地址转换。
当前的虚拟存储系统对程序进行运行期间的重定位不需要连续的主存块(页面)。图 4.21 示意了虚页号到实页号的转换。程序空间可以超出主存空间,故程序页号位数可以多于实页号位数。
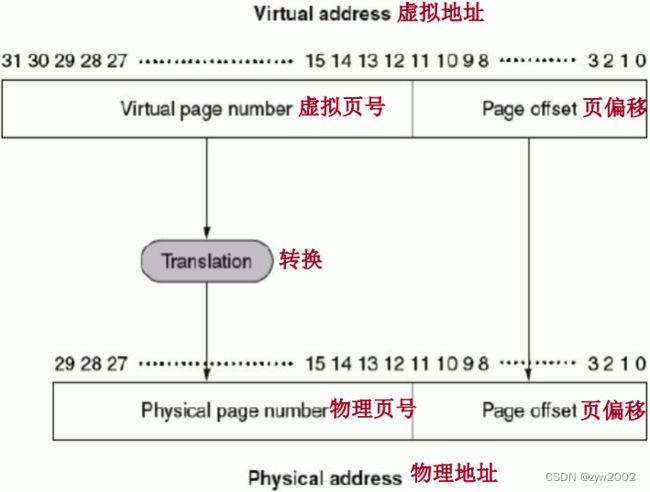
考虑到页面错误而带来的巨大的失效开销,虚拟存储系统在设计时,特别地注意以下关键部分:
页面应足够大、为降低页面错误率而采用全相联映像放置页面、用软件方法处理页面错误、采用写回法
4.4.1 放置和查找页面
全相联映像方法可以减少页面失效率。但是同时搜索是不实际的。虚拟存储器采用页表的方法保存全部虚页与实页的映像。页表放在主存中,用虚地址中的虚页号去索引页表。每道程序都有自己的页表。在硬件上设立页表寄存器指向页表在主存中的起始地址。假设页表在固定连续的主存区域内。

图 4.22 示意了页表寄存器的虚地址,页表及实地址之间的关系。由于页表包含了全部虚页的映像,因此,页表内无 tag。页表、程序计数器、寄存器指明了程序的状态,我们把这一状态称为进程。进程的地址空间由驻留在主存的页表定义。为了节省整个页表所占的空间,操作系统可将页表寄存器指向进程正使用的页表部分。如果页表中一个虚页所对应的有效位为 0,就发生了页面错误(即页面失效),此时,操作系统将接管控制,到下一级去寻找所需的页面并决定应该放到主存的什么位置上。
虚拟地址并不能立即告诉我们页面在硬盘的位置,需要追踪硬盘上虚拟地址空间每个页面的定位。操作系统通常在硬盘上为要执行的进程创建硬盘空间,同时也创建一个数据结构用来记录每一个虚页在硬盘的位置。这个数据结构可以是页表的一部分或者是作为一种辅助的数据结构与页表使用同样的索引方法。
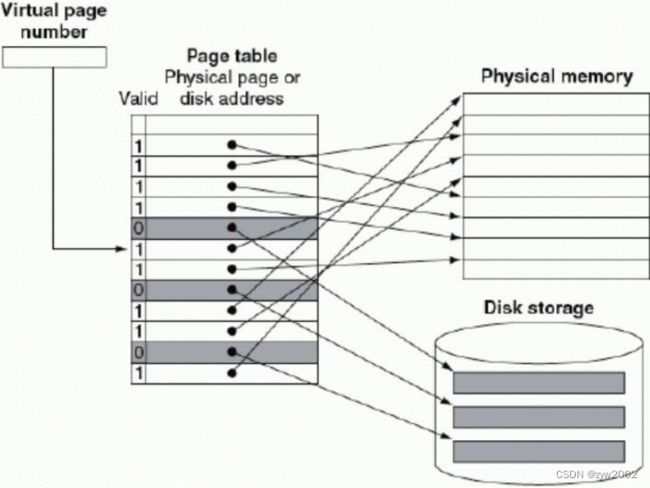
图4.23给出了一个单一表结构,既保存实页号也保存硬盘地址。操作系统也创建一种数据结构追踪哪一个进程哪一个虚地址使用的每一个主存实页。当发生页面失效时,如果主存中所有的页都在使用中,操作系统选择一页进行替换。通常采用 LRU 策略。
有一系列技术用于减少页表所占用的存储空间。
- 设计界限寄存器来限制给定进程页表的大小。这种允许进程消耗更多空间时逐步加大页表。这一技术要求地址空间是向单方向增长的。
- 大多数语言需要两个可扩张的区域,一个区域作为 stack,另一个区域作为 heap。这意味着需要 2 个分离的页表,及 2 个界限。这种方法在地址空间不连续时效果不是很好。
- 反转页表(inverted page table)
页表只保存主存实页数量的页面对应关系。查找转页表的过程比较复杂,不能简单的对页表进行索引。要应用 hash 函数对虚地址进行变换。 - 多级页表 这种方法允许使用不连续的地址空间,不必为整个页表分配连续空间,但地址变换比较复杂。
- 将页表分页 允许页表驻留在虚拟空间中。
Cache 与主存的访问时间相差几十倍。虚拟存储体系向硬盘写需要花上百万个时钟周期,因此写策略采用写回方式。虚拟存储系统必须采用写回, 即在向存储器写页时,并且在页在存储器中被替换时写回磁盘。该技术也叫回拷贝(copy back)。另外,由于硬盘传送时间要小于访问时间,因此将整页拷回也要比写回个别一些字有效的多。为了记录被读入到主存的页面是否被修改过,可以在页表中设立 dirty 位作为写标志。
4.4.2 用TLB加快地址变换
由于页表被存在主存中,因此程序每次访存都要花 2 倍的时间即:一次访存获得物理地址,再一次访存获得数据。改进访问性能的关键依赖于页表访问的局部性。当某一个虚页号的转换被使用时就可能在近期仍再此需要被使用,因为对该页面中的 words 访问具有时间和空间局部性。
因而,现代计算机包含了一个特殊的 cache,用来保存近期被使用的地址转换。这种特殊的地址变换 cache 被称为 TLB(Translation Lookaside Buffer)。
TLB 是一个只保存页表映像的 cache。因此 TLB 的每一个 tag 项保存虚页号,每个 data 项保存物理页号。这样可以不再每次访问页表,而是访问 TLB,TLB 也将包括一些其它的位,如 reference 位,dirty 位等。图 4.24 示意了 TLB 作为页表访问的 cache 的原理。
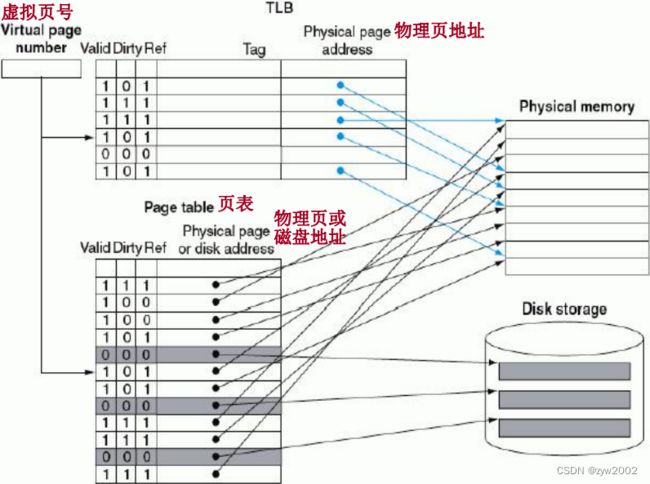
对于每次访存,都要在 TLB 中找虚位号。如果找到,就将物理页号读出用来生成访存地址,相应的reference 位置位。如果处理器执行的是写操作,也要将 dirty 位置位。
如果 TLB 产生缺失,需要判断是页面缺失,还是 TLB 缺失。如果页面已经在主存中,TLB 缺失只意味者这个地址转换失效。在这种情况下,可以将页表中的这个地址转换到 TLB。如果页面不在主存中,那么这个 TLB缺失就意味着真正的页面缺失。此时,CPU 产生异常,通知操作系统。因为 TLB能保存的映像远小于主存中的页面数,因此 TLB 缺失要比页面缺失来得更频繁一些。
TLB 缺失既可用硬件处理与可用软件处理。reference 与 dirty 位是 TLB 中唯一可被改写的位。采用写回策略。一些计算机采用小容量全相联 TLB。另一些系统采用大容量,直接映象或相联度较小的 TLB。由于硬件实现 LRU 机制成本高昂,且 TLB 缺失比页面缺失次数多,也不能像页面缺失时采用的复杂的软件方法,因此,很多系统采用随机法作为替换原则。
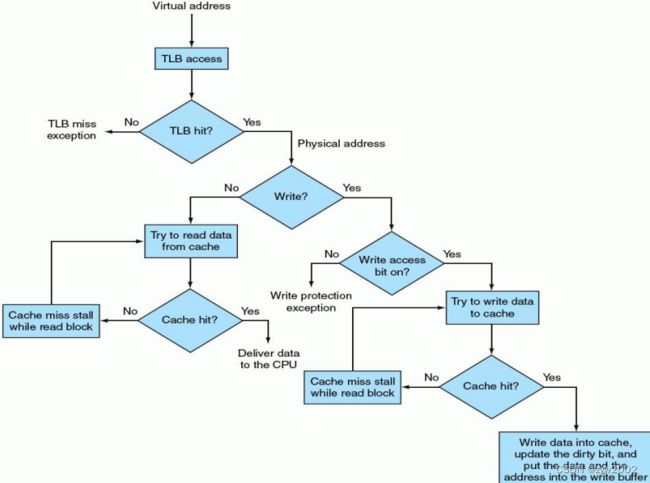
4.4.3 虚拟存储器,TLB和cache的统一
在最理想情况下,虚地址由 TLB 翻译后指向 Cache,并且在 Cache 中可以找到 CPU 所需信息。最坏情况是访问 TLB 失效,访页表失效,访 Cache 失效。
3类缺失: cache缺失, TLB缺失, 页故障
| TLB | 页表 | 缓存 | 是否可能,在何种情况下 |
|---|---|---|---|
| 命中 | 命中 | 缺失 | 可能,如果TLB命中的话,就永远不会去页表中检查 |
| 缺失 | 命中 | 命中 | TLB缺失,但是在页表中可能找到入口。该转换放到TLB后,重新访问找到该物理地址,然后在cache中找到数据 |
| 缺失 | 命中 | 缺失 | TLB缺失,但是在页表中可能找到入口,该转换放到TLB后,重新访问找到该物理地址,但是数据在cache中缺失 |
| 缺失 | 缺失 | 缺失 | TLB缺失,继而发现是页故障,继而将数据从磁盘调入主存,但是数据必然在cache中缺失 |
| 命中 | 缺失 | 缺失 | 不可能,页若不在主存中,转换就不可能在TLB中 |
| 命中 | 缺失 | 命中 | 不可能,页若不在主存中,转换就不可能在TLB中 |
| 缺失 | 缺失 | 命中 | 页若不在主存中,数据不可能在cache中 |
图 4.27 示意了 TLB,虚存,Cache 三种部件所产生的可能事件的组合。
数据除非在主存中出现,才有可能在 Cache 中出现。操作系统在维护虚拟层次和 Cache 层次的协同问题上起了重要作用。
当操作系统要将页面迁回硬盘的时候也将该页面的内容从 Cache 中清除,同时操作系统修改页表及 TLB ,因此,访问该页面的任何数据都将导致页面失效。
图 4.27 假设在访问 Cache 之前,所有虚地址都被变换为实地址;图 4.25 示意了存储系统的组织结构。在这种结构中,Cache 是物理地址索引,同时用物理地址标识(即 physically indexed and physically tagged)。在这样的系统中,假设 Cache命中,访问时间由访问 TLB 和访问 Cache 构成,这一过程可以被流水化实现。
也可以用虚地址来索引 Cache,标志 Cache(即 virtually indexed and virtually tagged)。在这种情况下,如果 Cache 命中,不需要 TLB 地址转换。但当 Cache 失效时,处理器需要将虚地址转化为物理地址,以便从主存中读取 Cache 块。当用虚地址访问 Cache,并且程序之间共享页面时,就存在了别名的问题。这时,一个目标有了两个名字,两个虚地址映射到同一个物理页面上。这种二义性会使得这个页面中的字对应两个不同的虚地址。这就会带来当一个程序改写数据而另一个程序还一无所知。完全的虚拟寻址 Cache 会带来 Cache 与 TLB 减小别名设计的限制问题,或要求操作系统,甚至是用户采取措施,确保别名不再产生。一个常见的折中方法就是用虚地址索引 Cache(实际上用页内偏移部分索引),但用物理地址标志 Cache。Cache 与 TLB 的访问并行进行,用 Cache 的 TAG 与 TLB得出的物理地址进行比较。(这称为 virtualy indexed but physically tagged)
4.4.4 虚拟存储器的保护
虚拟存储器的最重要功能之一就是允许多个进程共享单一的主存,并且为进程和操作系统之间提供存储保护。这种保护机制应该确保一个用户进程不能改写另一个用户进程或者是操作系统地址空间。TLB 中的写访问位能防止页面被改写。同样,也需要防止一个进程去读另一个进程的数据。由于每个进程都有其自己的虚拟地址空间。如果操作系统确保彼此无关的虚页映像到不连续的物理页面,一个进程就不可能访问其他进程的数据。当然这要求用户进程不能修改页表映像。如果能防止用户修改其自身的页表,操作系统就是安全的。当然操作系统一定有权修改页表。
为了使操作系统能实现虚拟存储系统的保护,硬件至少提供三种基本的能力:
- 支持至少两种模式的表示,指明当前运行的进程是用户进程还是特权进程。
- 提供 CPU 部分状态,如用户进程可读但不能写。这其中包括用户/特权模式位,页表指针,TLB。对这些元素的写入需要操作系统在特权模式下用特殊的指令完成。
3.提供 cpu 可在用户模式与特权模式间相互转换的机制。可用系统调用指令将控制传送到超级用户代码空间的指定位置。如同其他的异常处理,处于系统调用的程序计数器被保存起来,cpu 处于特权模式。用RFE 指令从异常处返回并恢复产生异常的进程状态。任何决定页面访问权限的位一定要在页面和 TLB 中都包括,这里因为只有当 TLB失效时才访问页表。当操作系统决定从进程 p1 切换到进程 p2 时,要确保进程 p2 不能访问到进程 p1的页表。如果不存在 TLB,就只需改变页表寄存器的内容指向 p2 的页表。如果存在 TLB,就一定将属于 p1 的 TLB 项清除。如果进程的切换频率较高,这就不是很有效。一种解决办法就是扩大虚拟地址空间,考虑进程号。进程号与 TLB 的 tag 部分合并在一起,只有当虚页号与进程号两者都匹配时,TLB 才算命中。这样就不必清空 TLB。
4.4.5 页面失效和TLB失效的处理
TLB 失效可用硬件处理也可用软件处理,只需要较少的操作将主存中有效的页表项拷入 TLB。
页面失效需要异常机制中断活跃的进程,将控制转交操作系统,之后恢复中断进程的执行。需要将产生页面失效的指令地址保存在 EPC 中(exception program counter)。
OS知道导致页故障的虚拟地址后,必须完成3个步骤:
- 用虚拟地址找到页表入口,并在磁盘上找到被引用页的地址
- 选择要替换的物理页.如果选择的页脏,就必须先写回磁盘.
- 将该页从磁盘读到选择的物理页中
- 最后一个步骤需要数百万个周期, 所以OS通常选择另一个进程执行直至磁盘访问完成
从磁盘读完后,OS恢复导致页故障进程的状态,执行从异常返回的指令。用户进程重新执行故障的指令, 成功地访问所需的页, 并继续执行。
页面失效异常一定要在产生存储器访问周期结束时发出,这样在下一个周期就可以开始处理异常,而不是正常指令的执行。如果页面失效不能在这个周期被明确发出,load 指令将会改写寄存器,这在恢复指令重新执行时将会产生错误。
例 lw $1,o($1):一定要防止写回$1 的操作产生,否则由于$1 内容的破坏,将无法正确恢复 lw 指令。关于 store 指令也存在类似问题。当存在页面失效时,一定要防止向存储器写的操作完成,这可通过撤销写控制信号实现。恢复指令的执行过程需要保存一些特殊的状态,处理异常,恢复状态。通常需要操作系统的异常处理程序与硬件之间有严谨,细微的协同工作
总结:
虚拟存储器管理的是主存储器与磁盘之间的缓存层次结构
虚拟存储器允许一个程序扩展其地址空间, 突破了主存储器的界限
虚拟存储支持多程序, 多活动进程共享主存, 而这些程序和进程总共需要的比主存大得多的空间
为支持共享,虚拟存储器也提供存储保护机制
管理存储层次有挑战性, 因为页故障的高成本
降低缺失率的若干技术:
采用大的块(页)以利用空间局部性,虚拟和物理地址间的映射用页表实现,采用全相联,OS采用如LRU和访问位来选择要替换的页
向磁盘写也昂贵,所以虚拟存储器采用回写方案,并追踪页是否被改变(用脏位)
虚拟存储机制也提供从虚拟地址到物理地址空间的转换
地址转换使得可以实现对存储器的保护性共享
为确保进程互相间的隔离保护,要求只有OS能改变地址转换,不让用户程序改变页表
进程间对页的可控共享可借助OS和页表的访问位来实现,访问位指出用户程序对一个页有读还是写访问
如果为了对每个访问进行转换,CPU必须要访问驻留存储器中的页表,虚拟存储器则有过大的开销
TLB是作为页表中转换的cache,那么,就采用TLB中的转换来将虚拟地址转换成物理地址
块放到哪里?
一系列的方案: 从直接映像,到组相联,到全相联
都是组相联的变型: 组数和每组内块数变化
提高相联性的优势是通常降低缺失率
缺失率的改进来自于对同一位置竞争引起的缺失降低
随着cache大小增加,来自相联性的改进是恒定的或者略微增加
相联性的潜在劣势是成本增加和访问时间变慢
取决于块布局方案
虚拟存储器: 用页表来索引存储器
为什么采用全相联和用额外的页表?
缺失处理非常昂贵,能实现复杂的替换方案, 索引,无需硬件和搜索,由于页很大,页表大小开销相对小
通写:信息同时写入cache的块和更低层次的块
回写:信息只写入cache的块,只有块被替换时才将块写入更低层次
回写的优势: 写得快, 对一块的多次写,但只需写到更低层1次, 写回时, 可有效地利用高带宽传送
通写的优势: 缺失的情况简单和便宜,不需要将整个块写回低层次;易于实现,虽然为现实起见,需要使用写缓冲器
在虚拟存储器中, 只有回写是现实的, 因为向磁盘写所用时间长
当CPU性能持续增加时, 处理器产生写的速率超过了存储系统能处理的速度。因此,cache也越来越多地用写回
3C:理解存储层次行为的直觉模型
强制缺失(Compusory misses): 第一次,从未进入cache
容量缺失 (Capacity misses):Cache不能容纳程序运行中的所有模块
冲突缺失(Confict misses): 多模块在一个组内竞争
可通过改变cache设计来解决:
对于冲突缺失:由于冲突缺失由竞争引起,可通过增加相联性来降低;但这种方法减慢了访问时间, 导致整体性能降低
对于容量缺失: 可通过加大cache来降低,但也加大了访问时间
对于强制缺失:主要方法是增大块尺寸;. 这将降低访问次数, 因为模块数少了。但是, 但对性能有负面作用, 因为缺失惩罚增加了,因为缺失率增加。