深入分析基于Micrometer和Prometheus实现度量和监控的方案
深入分析基于Micrometer和Prometheus实现度量和监控的方案
前提#
最近线上的项目使用了spring-actuator做度量统计收集,使用Prometheus进行数据收集,Grafana进行数据展示,用于监控生成环境机器的性能指标和业务数据指标。一般,我们叫这样的操作为"埋点"。SpringBoot中的依赖spring-actuator中集成的度量统计API使用的框架是Micrometer,官网是micrometer.io。在实践中发现了业务开发者滥用了Micrometer的度量类型Counter,导致无论什么情况下都只使用计数统计的功能。这篇文章就是基于Micrometer分析其他的度量类型API的作用和适用场景。
Micrometer提供的度量类库#
Meter是指一组用于收集应用中的度量数据的接口,Meter单词可以翻译为"米"或者"千分尺",但是显然听起来都不是很合理,因此下文直接叫Meter,直接当成一个专有名词,理解它为度量接口即可。Meter是由MeterRegistry创建和保存的,可以理解MeterRegistry是Meter的工厂和缓存中心,一般而言每个JVM应用在使用Micrometer的时候必须创建一个MeterRegistry的具体实现。Micrometer中,Meter的具体类型包括:Timer,Counter,Gauge,DistributionSummary,LongTaskTimer,FunctionCounter,FunctionTimer和TimeGauge。下面分节详细介绍这些类型的使用方法和实战使用场景。而一个Meter具体类型需要通过名字和Tag(这里指的是Micrometer提供的Tag接口)作为它的唯一标识,这样做的好处是可以使用名字进行标记,通过不同的Tag去区分多种维度进行数据统计。
MeterRegistry#
MeterRegistry在Micrometer是一个抽象类,主要实现包括:
- 1、
SimpleMeterRegistry:每个Meter的最新数据可以收集到SimpleMeterRegistry实例中,但是这些数据不会发布到其他系统,也就是数据是位于应用的内存中的。 - 2、
CompositeMeterRegistry:多个MeterRegistry聚合,内部维护了一个MeterRegistry的列表。 - 3、全局的
MeterRegistry:工厂类io.micrometer.core.instrument.Metrics中持有一个静态final的CompositeMeterRegistry实例globalRegistry。
当然,使用者也可以自行继承MeterRegistry去实现自定义的MeterRegistry。SimpleMeterRegistry适合做调试的时候使用,它的简单使用方式如下:
MeterRegistry registry = new SimpleMeterRegistry();
Counter counter = registry.counter("counter");
counter.increment();
CompositeMeterRegistry实例初始化的时候,内部持有的MeterRegistry列表是空的,如果此时用它新增一个Meter实例,Meter实例的操作是无效的:
CompositeMeterRegistry composite = new CompositeMeterRegistry();
Counter compositeCounter = composite.counter("counter");
compositeCounter.increment(); // <- 实际上这一步操作是无效的,但是不会报错
SimpleMeterRegistry simple = new SimpleMeterRegistry();
composite.add(simple); // <- 向CompositeMeterRegistry实例中添加SimpleMeterRegistry实例
compositeCounter.increment(); // <-计数成功
全局的MeterRegistry的使用方式更加简单便捷,因为一切只需要操作工厂类Metrics的静态方法:
Metrics.addRegistry(new SimpleMeterRegistry());
Counter counter = Metrics.counter("counter", "tag-1", "tag-2");
counter.increment();
Tag与Meter的命名#
Micrometer中,Meter的命名约定使用英文逗号(dot,也就是".")分隔单词。但是对于不同的监控系统,对命名的规约可能并不相同,如果命名规约不一致,在做监控系统迁移或者切换的时候,可能会对新的系统造成破坏。Micrometer中使用英文逗号分隔单词的命名规则,再通过底层的命名转换接口NamingConvention进行转换,最终可以适配不同的监控系统,同时可以消除监控系统不允许的特殊字符的名称和标记等。开发者也可以覆盖NamingConvention实现自定义的命名转换规则:registry.config().namingConvention(myCustomNamingConvention);。在Micrometer中,对一些主流的监控系统或者存储系统的命名规则提供了默认的转换方式,例如当我们使用下面的命名时候:
MeterRegistry registry = ...
registry.timer("http.server.requests");
对于不同的监控系统或者存储系统,命名会自动转换如下:
- 1、Prometheus - http_server_requests_duration_seconds。
- 2、Atlas - httpServerRequests。
- 3、Graphite - http.server.requests。
- 4、InfluxDB - http_server_requests。
其实NamingConvention已经提供了5种默认的转换规则:dot、snakeCase、camelCase、upperCamelCase和slashes。
另外,Tag(标签)是Micrometer的一个重要的功能,严格来说,一个度量框架只有实现了标签的功能,才能真正地多维度进行度量数据收集。Tag的命名一般需要是有意义的,所谓有意义就是可以根据Tag的命名可以推断出它指向的数据到底代表什么维度或者什么类型的度量指标。假设我们需要监控数据库的调用和Http请求调用统计,一般推荐的做法是:
MeterRegistry registry = ...
registry.counter("database.calls", "db", "users")
registry.counter("http.requests", "uri", "/api/users")
这样,当我们选择命名为"database.calls"的计数器,我们可以进一步选择分组"db"或者"users"分别统计不同分组对总调用数的贡献或者组成。一个反例如下:
MeterRegistry registry = ...
registry.counter("calls", "class", "database", "db", "users");
registry.counter("calls", "class", "http", "uri", "/api/users");
通过命名"calls"得到的计数器,由于标签混乱,数据是基本无法分组统计分析,这个时候可以认为得到的时间序列的统计数据是没有意义的。可以定义全局的Tag,也就是全局的Tag定义之后,会附加到所有的使用到的Meter上(只要是使用同一个MeterRegistry),全局的Tag可以这样定义:
MeterRegistry registry = ...
registry.config().commonTags("stack", "prod", "region", "us-east-1");
// 和上面的意义是一样的
registry.config().commonTags(Arrays.asList(Tag.of("stack", "prod"), Tag.of("region", "us-east-1")));
像上面这样子使用,就能通过主机,实例,区域,堆栈等操作环境进行多维度深入分析。
还有两点点需要注意:
- 1、
Tag的值必须不为NULL。 - 2、
Micrometer中,Tag必须成对出现,也就是Tag必须设置为偶数个,实际上它们以Key=Value的形式存在,具体可以看io.micrometer.core.instrument.Tag接口:
public interface Tag extends Comparable<Tag> {
String getKey();
String getValue();
static Tag of(String key, String value) {
return new ImmutableTag(key, value);
}
default int compareTo(Tag o) {
return this.getKey().compareTo(o.getKey());
}
}
当然,有些时候,我们需要过滤一些必要的标签或者名称进行统计,或者为Meter的名称添加白名单,这个时候可以使用MeterFilter。MeterFilter本身提供一些列的静态方法,多个MeterFilter可以叠加或者组成链实现用户最终的过滤策略。例如:
MeterRegistry registry = ...
registry.config()
.meterFilter(MeterFilter.ignoreTags("http"))
.meterFilter(MeterFilter.denyNameStartsWith("jvm"));
表示忽略"http"标签,拒绝名称以"jvm"字符串开头的Meter。更多用法可以参详一下MeterFilter这个类。
Meter的命名和Meter的Tag相互结合,以命名为轴心,以Tag为多维度要素,可以使度量数据的维度更加丰富,便于统计和分析。
Meters#
前面提到Meter主要包括:Timer,Counter,Gauge,DistributionSummary,LongTaskTimer,FunctionCounter,FunctionTimer和TimeGauge。下面逐一分析它们的作用和个人理解的实际使用场景(应该说是生产环境)。
Counter#
Counter是一种比较简单的Meter,它是一种单值的度量类型,或者说是一个单值计数器。Counter接口允许使用者使用一个固定值(必须为正数)进行计数。准确来说:Counter就是一个增量为正数的单值计数器。这个举个很简单的使用例子:
MeterRegistry meterRegistry = new SimpleMeterRegistry();
Counter counter = meterRegistry.counter("http.request", "createOrder", "/order/create");
counter.increment();
System.out.println(counter.measure()); // [Measurement{statistic='COUNT', value=1.0}]
使用场景:
Counter的作用是记录XXX的总量或者计数值,适用于一些增长类型的统计,例如下单、支付次数、HTTP请求总量记录等等,通过Tag可以区分不同的场景,对于下单,可以使用不同的Tag标记不同的业务来源或者是按日期划分,对于HTTP请求总量记录,可以使用Tag区分不同的URL。用下单业务举个例子:
//实体
@Data
public class Order {
private String orderId;
private Integer amount;
private String channel;
private LocalDateTime createTime;
}
public class CounterMain {
private static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd");
static {
Metrics.addRegistry(new SimpleMeterRegistry());
}
public static void main(String[] args) throws Exception {
Order order1 = new Order();
order1.setOrderId("ORDER_ID_1");
order1.setAmount(100);
order1.setChannel("CHANNEL_A");
order1.setCreateTime(LocalDateTime.now());
createOrder(order1);
Order order2 = new Order();
order2.setOrderId("ORDER_ID_2");
order2.setAmount(200);
order2.setChannel("CHANNEL_B");
order2.setCreateTime(LocalDateTime.now());
createOrder(order2);
Search.in(Metrics.globalRegistry).meters().forEach(each -> {
StringBuilder builder = new StringBuilder();
builder.append("name:")
.append(each.getId().getName())
.append(",tags:")
.append(each.getId().getTags())
.append(",type:").append(each.getId().getType())
.append(",value:").append(each.measure());
System.out.println(builder.toString());
});
}
private static void createOrder(Order order) {
//忽略订单入库等操作
Metrics.counter("order.create",
"channel", order.getChannel(),
"createTime", FORMATTER.format(order.getCreateTime())).increment();
}
}
控制台输出:
name:order.create,tags:[tag(channel=CHANNEL_A), tag(createTime=2018-11-10)],type:COUNTER,value:[Measurement{statistic='COUNT', value=1.0}]
name:order.create,tags:[tag(channel=CHANNEL_B), tag(createTime=2018-11-10)],type:COUNTER,value:[Measurement{statistic='COUNT', value=1.0}]
上面的例子是使用全局静态方法工厂类Metrics去构造Counter实例,实际上,io.micrometer.core.instrument.Counter接口提供了一个内部建造器类Counter.Builder去实例化Counter,Counter.Builder的使用方式如下:
public class CounterBuilderMain {
public static void main(String[] args) throws Exception{
Counter counter = Counter.builder("name") //名称
.baseUnit("unit") //基础单位
.description("desc") //描述
.tag("tagKey", "tagValue") //标签
.register(new SimpleMeterRegistry());//绑定的MeterRegistry
counter.increment();
}
}
FunctionCounter#
FunctionCounter是Counter的特化类型,它把计数器数值增加的动作抽象成接口类型ToDoubleFunction,这个接口JDK1.8中对于Function的特化类型接口。FunctionCounter的使用场景和Counter是一致的,这里介绍一下它的用法:
public class FunctionCounterMain {
public static void main(String[] args) throws Exception {
MeterRegistry registry = new SimpleMeterRegistry();
AtomicInteger n = new AtomicInteger(0);
//这里ToDoubleFunction匿名实现其实可以使用Lambda表达式简化为AtomicInteger::get
FunctionCounter.builder("functionCounter", n, new ToDoubleFunction<AtomicInteger>() {
@Override
public double applyAsDouble(AtomicInteger value) {
return value.get();
}
}).baseUnit("function")
.description("functionCounter")
.tag("createOrder", "CHANNEL-A")
.register(registry);
//下面模拟三次计数
n.incrementAndGet();
n.incrementAndGet();
n.incrementAndGet();
}
}
FunctionCounter使用的一个明显的好处是,我们不需要感知FunctionCounter实例的存在,实际上我们只需要操作作为FunctionCounter实例构建元素之一的AtomicInteger实例即可,这种接口的设计方式在很多主流框架里面可以看到。
Timer#
Timer(计时器)适用于记录耗时比较短的事件的执行时间,通过时间分布展示事件的序列和发生频率。所有的Timer的实现至少记录了发生的事件的数量和这些事件的总耗时,从而生成一个时间序列。Timer的基本单位基于服务端的指标而定,但是实际上我们不需要过于关注Timer的基本单位,因为Micrometer在存储生成的时间序列的时候会自动选择适当的基本单位。Timer接口提供的常用方法如下:
public interface Timer extends Meter {
...
void record(long var1, TimeUnit var3);
default void record(Duration duration) {
this.record(duration.toNanos(), TimeUnit.NANOSECONDS);
}
<T> T record(Supplier<T> var1);
<T> T recordCallable(Callable<T> var1) throws Exception;
void record(Runnable var1);
default Runnable wrap(Runnable f) {
return () -> {
this.record(f);
};
}
default <T> Callable<T> wrap(Callable<T> f) {
return () -> {
return this.recordCallable(f);
};
}
long count();
double totalTime(TimeUnit var1);
default double mean(TimeUnit unit) {
return this.count() == 0L ? 0.0D : this.totalTime(unit) / (double)this.count();
}
double max(TimeUnit var1);
...
}
实际上,比较常用和方便的方法是几个函数式接口入参的方法:
Timer timer = ...
timer.record(() -> dontCareAboutReturnValue());
timer.recordCallable(() -> returnValue());
Runnable r = timer.wrap(() -> dontCareAboutReturnValue());
Callable c = timer.wrap(() -> returnValue());
使用场景:
根据个人经验和实践,总结如下:
- 1、记录指定方法的执行时间用于展示。
- 2、记录一些任务的执行时间,从而确定某些数据来源的速率,例如消息队列消息的消费速率等。
这里举个实际的例子,要对系统做一个功能,记录指定方法的执行时间,还是用下单方法做例子:
public class TimerMain {
private static final Random R = new Random();
static {
Metrics.addRegistry(new SimpleMeterRegistry());
}
public static void main(String[] args) throws Exception {
Order order1 = new Order();
order1.setOrderId("ORDER_ID_1");
order1.setAmount(100);
order1.setChannel("CHANNEL_A");
order1.setCreateTime(LocalDateTime.now());
Timer timer = Metrics.timer("timer", "createOrder", "cost");
timer.record(() -> createOrder(order1));
}
private static void createOrder(Order order) {
try {
TimeUnit.SECONDS.sleep(R.nextInt(5)); //模拟方法耗时
} catch (InterruptedException e) {
//no-op
}
}
}
在实际生产环境中,可以通过spring-aop把记录方法耗时的逻辑抽象到一个切面中,这样就能减少不必要的冗余的模板代码。上面的例子是通过Mertics构造Timer实例,实际上也可以使用Builder构造:
MeterRegistry registry = ...
Timer timer = Timer
.builder("my.timer")
.description("a description of what this timer does") // 可选
.tags("region", "test") // 可选
.register(registry);
另外,Timer的使用还可以基于它的内部类Timer.Sample,通过start和stop两个方法记录两者之间的逻辑的执行耗时。例如:
Timer.Sample sample = Timer.start(registry);
// 这里做业务逻辑
Response response = ...
sample.stop(registry.timer("my.timer", "response", response.status()));
FunctionTimer#
FunctionTimer是Timer的特化类型,它主要提供两个单调递增的函数(其实并不是单调递增,只是在使用中一般需要随着时间最少保持不变或者说不减少):一个用于计数的函数和一个用于记录总调用耗时的函数,它的建造器的入参如下:
public interface FunctionTimer extends Meter {
static <T> Builder<T> builder(String name, T obj, ToLongFunction<T> countFunction,
ToDoubleFunction<T> totalTimeFunction,
TimeUnit totalTimeFunctionUnit) {
return new Builder<>(name, obj, countFunction, totalTimeFunction, totalTimeFunctionUnit);
}
...
}
官方文档中的例子如下:
IMap<?, ?> cache = ...; // 假设使用了Hazelcast缓存
registry.more().timer("cache.gets.latency", Tags.of("name", cache.getName()), cache,
c -> c.getLocalMapStats().getGetOperationCount(), //实际上就是cache的一个方法,记录缓存生命周期初始化的增量(个数)
c -> c.getLocalMapStats().getTotalGetLatency(), // Get操作的延迟时间总量,可以理解为耗时
TimeUnit.NANOSECONDS
);
按照个人理解,ToDoubleFunction用于统计事件个数,ToDoubleFunction用于记录执行总时间,实际上两个函数都只是Function函数的变体,还有一个比较重要的是总时间的单位totalTimeFunctionUnit。简单的使用方式如下:
public class FunctionTimerMain {
public static void main(String[] args) throws Exception {
//这个是为了满足参数,暂时不需要理会
Object holder = new Object();
AtomicLong totalTimeNanos = new AtomicLong(0);
AtomicLong totalCount = new AtomicLong(0);
FunctionTimer.builder("functionTimer", holder, p -> totalCount.get(),
p -> totalTimeNanos.get(), TimeUnit.NANOSECONDS)
.register(new SimpleMeterRegistry());
totalTimeNanos.addAndGet(10000000);
totalCount.incrementAndGet();
}
}
LongTaskTimer#
LongTaskTimer是Timer的特化类型,主要用于记录长时间执行的任务的持续时间,在任务完成之前,被监测的事件或者任务仍然处于运行状态,任务完成的时候,任务执行的总耗时才会被记录下来。LongTaskTimer适合用于长时间持续运行的事件耗时的记录,例如相对耗时的定时任务。在Spring(Boot)应用中,可以简单地使用@Scheduled和@Timed注解,基于spring-aop完成定时调度任务的总耗时记录:
@Timed(value = "aws.scrape", longTask = true)
@Scheduled(fixedDelay = 360000)
void scrapeResources() {
//这里做相对耗时的业务逻辑
}
当然,在非Spring体系中也能方便地使用LongTaskTimer:
public class LongTaskTimerMain {
public static void main(String[] args) throws Exception{
MeterRegistry meterRegistry = new SimpleMeterRegistry();
LongTaskTimer longTaskTimer = meterRegistry.more().longTaskTimer("longTaskTimer");
longTaskTimer.record(() -> {
//这里编写Task的逻辑
});
//或者这样
Metrics.more().longTaskTimer("longTaskTimer").record(()-> {
//这里编写Task的逻辑
});
}
}
Gauge#
Gauge(仪表)是获取当前度量记录值的句柄,也就是它表示一个可以任意上下浮动的单数值度量Meter。Gauge通常用于变动的测量值,测量值用ToDoubleFunction参数的返回值设置,如当前的内存使用情况,同时也可以测量上下移动的"计数",比如队列中的消息数量。官网文档中提到Gauge的典型使用场景是用于测量集合或映射的大小或运行状态中的线程数。一般情况下,Gauge适合用于监测有自然上界的事件或者任务,而Counter一般使用于无自然上界的事件或者任务的监测,所以像HTTP请求总量计数应该使用Counter而非Gauge。MeterRegistry中提供了一些便于构建用于观察数值、函数、集合和映射的Gauge相关的方法:
List<String> list = registry.gauge("listGauge", Collections.emptyList(), new ArrayList<>(), List::size);
List<String> list2 = registry.gaugeCollectionSize("listSize2", Tags.empty(), new ArrayList<>());
Map<String, Integer> map = registry.gaugeMapSize("mapGauge", Tags.empty(), new HashMap<>());
上面的三个方法通过MeterRegistry构建Gauge并且返回了集合或者映射实例,使用这些集合或者映射实例就能在其size变化过程中记录这个变更值。更重要的优点是,我们不需要感知Gauge接口的存在,只需要像平时一样使用集合或者映射实例就可以了。此外,Gauge还支持java.lang.Number的子类,java.util.concurrent.atomic包中的AtomicInteger和AtomicLong,还有Guava提供的AtomicDouble:
AtomicInteger n = registry.gauge("numberGauge", new AtomicInteger(0));
n.set(1);
n.set(2);
除了使用MeterRegistry创建Gauge之外,还可以使用建造器流式创建:
//一般我们不需要操作Gauge实例
Gauge gauge = Gauge
.builder("gauge", myObj, myObj::gaugeValue)
.description("a description of what this gauge does") // 可选
.tags("region", "test") // 可选
.register(registry);
使用场景:
根据个人经验和实践,总结如下:
- 1、有自然(物理)上界的浮动值的监测,例如物理内存、集合、映射、数值等。
- 2、有逻辑上界的浮动值的监测,例如积压的消息、(线程池中)积压的任务等,其实本质也是集合或者映射的监测。
举个相对实际的例子,假设我们需要对登录后的用户发送一条短信或者推送,做法是消息先投放到一个阻塞队列,再由一个线程消费消息进行其他操作:
public class GaugeMain {
private static final MeterRegistry MR = new SimpleMeterRegistry();
private static final BlockingQueue<Message> QUEUE = new ArrayBlockingQueue<>(500);
private static BlockingQueue<Message> REAL_QUEUE;
static {
REAL_QUEUE = MR.gauge("messageGauge", QUEUE, Collection::size);
}
public static void main(String[] args) throws Exception {
consume();
Message message = new Message();
message.setUserId(1L);
message.setContent("content");
REAL_QUEUE.put(message);
}
private static void consume() throws Exception {
new Thread(() -> {
while (true) {
try {
Message message = REAL_QUEUE.take();
//handle message
System.out.println(message);
} catch (InterruptedException e) {
//no-op
}
}
}).start();
}
}
上面的例子代码写得比较糟糕,只为了演示相关使用方式,切勿用于生产环境。
TimeGauge#
TimeGauge是Gauge的特化类型,相比Gauge,它的构建器中多了一个TimeUnit类型的参数,用于指定ToDoubleFunction入参的基础时间单位。这里简单举个使用例子:
public class TimeGaugeMain {
private static final SimpleMeterRegistry R = new SimpleMeterRegistry();
public static void main(String[] args) throws Exception {
AtomicInteger count = new AtomicInteger();
TimeGauge.Builder<AtomicInteger> timeGauge = TimeGauge.builder("timeGauge", count,
TimeUnit.SECONDS, AtomicInteger::get);
timeGauge.register(R);
count.addAndGet(10086);
print();
count.set(1);
print();
}
private static void print() throws Exception {
Search.in(R).meters().forEach(each -> {
StringBuilder builder = new StringBuilder();
builder.append("name:")
.append(each.getId().getName())
.append(",tags:")
.append(each.getId().getTags())
.append(",type:").append(each.getId().getType())
.append(",value:").append(each.measure());
System.out.println(builder.toString());
});
}
}
//输出
name:timeGauge,tags:[],type:GAUGE,value:[Measurement{statistic='VALUE', value=10086.0}]
name:timeGauge,tags:[],type:GAUGE,value:[Measurement{statistic='VALUE', value=1.0}]
DistributionSummary#
Summary(摘要)主要用于跟踪事件的分布,在Micrometer中,对应的类是DistributionSummary(分布式摘要)。它的使用方式和Timer十分相似,但是它的记录值并不依赖于时间单位。常见的使用场景:使用DistributionSummary测量命中服务器的请求的有效负载大小。使用MeterRegistry创建DistributionSummary实例如下:
DistributionSummary summary = registry.summary("response.size");
通过建造器流式创建如下:
DistributionSummary summary = DistributionSummary
.builder("response.size")
.description("a description of what this summary does") // 可选
.baseUnit("bytes") // 可选
.tags("region", "test") // 可选
.scale(100) // 可选
.register(registry);
使用场景:
根据个人经验和实践,总结如下:
- 1、不依赖于时间单位的记录值的测量,例如服务器有效负载值,缓存的命中率等。
举个相对具体的例子:
public class DistributionSummaryMain {
private static final DistributionSummary DS = DistributionSummary.builder("cacheHitPercent")
.register(new SimpleMeterRegistry());
private static final LoadingCache<String, String> CACHE = CacheBuilder.newBuilder()
.maximumSize(1000)
.recordStats()
.expireAfterWrite(60, TimeUnit.SECONDS)
.build(new CacheLoader<String, String>() {
@Override
public String load(String s) throws Exception {
return selectFromDatabase();
}
});
public static void main(String[] args) throws Exception {
String key = "doge";
String value = CACHE.get(key);
record();
}
private static void record() throws Exception {
CacheStats stats = CACHE.stats();
BigDecimal hitCount = new BigDecimal(stats.hitCount());
BigDecimal requestCount = new BigDecimal(stats.requestCount());
DS.record(hitCount.divide(requestCount, 2, BigDecimal.ROUND_HALF_DOWN).doubleValue());
}
}
基于SpirngBoot、Prometheus、Grafana集成#
集成了Micrometer框架的JVM应用使用到Micrometer的API收集的度量数据位于内存之中,因此,需要额外的存储系统去存储这些度量数据,需要有监控系统负责统一收集和处理这些数据,还需要有一些UI工具去展示数据,一般情况下大佬或者老板只喜欢看炫酷的仪表盘或者动画。常见的存储系统就是时序数据库,主流的有Influx、Datadog等。比较主流的监控系统(主要是用于数据收集和处理)就是Prometheus(一般叫普罗米修斯,下面就这样叫吧)。而展示的UI目前相对用得比较多的就是Grafana。另外,Prometheus已经内置了一个时序数据库的实现,因此,在做一套相对完善的度量数据监控的系统只需要依赖目标JVM应用,Prometheus组件和Grafana组件即可。下面花一点时间从零开始搭建一个这样的系统,之前写的一篇文章基于Windows系统,操作可能跟生产环境不够接近,这次使用CentOS7。
SpirngBoot中使用Micrometer#
SpringBoot中的spring-boot-starter-actuator依赖已经集成了对Micrometer的支持,其中的metrics端点的很多功能就是通过Micrometer实现的,prometheus端点默认也是开启支持的,实际上actuator依赖的spring-boot-actuator-autoconfigure中集成了对很多框架的开箱即用的API,其中prometheus包中集成了对Prometheus的支持,使得使用了actuator可以轻易地让项目暴露出prometheus端点,使得应用作为Prometheus收集数据的客户端,Prometheus(服务端软件)可以通过此端点收集应用中Micrometer的度量数据。

我们先引入spring-boot-starter-actuator和spring-boot-starter-web,实现一个Counter和Timer作为示例。依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-dependenciesartifactId>
<version>2.1.0.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-aopartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.16.22version>
dependency>
<dependency>
<groupId>io.micrometergroupId>
<artifactId>micrometer-registry-prometheusartifactId>
<version>1.1.0version>
dependency>
dependencies>
接着编写一个下单接口和一个消息发送模块,模拟用户下单之后向用户发送消息:
//实体
@Data
public class Message {
private String orderId;
private Long userId;
private String content;
}
@Data
public class Order {
private String orderId;
private Long userId;
private Integer amount;
private LocalDateTime createTime;
}
//控制器和服务类
@RestController
public class OrderController {
@Autowired
private OrderService orderService;
@PostMapping(value = "/order")
public ResponseEntity<Boolean> createOrder(@RequestBody Order order) {
return ResponseEntity.ok(orderService.createOrder(order));
}
}
@Slf4j
@Service
public class OrderService {
private static final Random R = new Random();
@Autowired
private MessageService messageService;
public Boolean createOrder(Order order) {
//模拟下单
try {
int ms = R.nextInt(50) + 50;
TimeUnit.MILLISECONDS.sleep(ms);
log.info("保存订单模拟耗时{}毫秒...", ms);
} catch (Exception e) {
//no-op
}
//记录下单总数
Metrics.counter("order.count", "order.channel", order.getChannel()).increment();
//发送消息
Message message = new Message();
message.setContent("模拟短信...");
message.setOrderId(order.getOrderId());
message.setUserId(order.getUserId());
messageService.sendMessage(message);
return true;
}
}
@Slf4j
@Service
public class MessageService implements InitializingBean {
private static final BlockingQueue<Message> QUEUE = new ArrayBlockingQueue<>(500);
private static BlockingQueue<Message> REAL_QUEUE;
private static final Executor EXECUTOR = Executors.newSingleThreadExecutor();
private static final Random R = new Random();
static {
REAL_QUEUE = Metrics.gauge("message.gauge", Tags.of("message.gauge", "message.queue.size"), QUEUE, Collection::size);
}
public void sendMessage(Message message) {
try {
REAL_QUEUE.put(message);
} catch (InterruptedException e) {
//no-op
}
}
@Override
public void afterPropertiesSet() throws Exception {
EXECUTOR.execute(() -> {
while (true) {
try {
Message message = REAL_QUEUE.take();
log.info("模拟发送短信,orderId:{},userId:{},内容:{},耗时:{}毫秒", message.getOrderId(), message.getUserId(),
message.getContent(), R.nextInt(50));
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
});
}
}
//切面类
@Component
@Aspect
public class TimerAspect {
@Around(value = "execution(* club.throwable.smp.service.*Service.*(..))")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
Signature signature = joinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature) signature;
Method method = methodSignature.getMethod();
Timer timer = Metrics.timer("method.cost.time", "method.name", method.getName());
ThrowableHolder holder = new ThrowableHolder();
Object result = timer.recordCallable(() -> {
try {
return joinPoint.proceed();
} catch (Throwable e) {
holder.throwable = e;
}
return null;
});
if (null != holder.throwable) {
throw holder.throwable;
}
return result;
}
private class ThrowableHolder {
Throwable throwable;
}
}
yaml的配置如下:
server:
port: 9091
management:
server:
port: 10091
endpoints:
web:
exposure:
include: '*'
base-path: /management
注意多看spring官方文档关于Actuator的详细描述,在SpringBoot2.x之后,配置Web端点暴露的权限控制和SpringBoot1.x有很大的不同。总结一下就是:除了shutdown端点之外,其他端点默认都是开启支持的(这里仅仅是开启支持,并不是暴露为Web端点,端点必须暴露为Web端点才能被访问),禁用或者开启端点支持的配置方式如下:
management.endpoint.${端点ID}.enabled=true/false
可以查看actuator-api文档查看所有支持的端点的特性,这个是2.1.0.RELEASE版本的官方文档,不知道日后链接会不会挂掉。端点只开启支持,但是不暴露为Web端点,是无法通过http://{host}:{management.port}/{management.endpoints.web.base-path}/{endpointId}访问的。暴露监控端点为Web端点的配置是:
management.endpoints.web.exposure.include=info,health
management.endpoints.web.exposure.exclude=prometheus
management.endpoints.web.exposure.include用于指定暴露为Web端点的监控端点,指定多个的时候用英文逗号分隔。management.endpoints.web.exposure.exclude用于指定不暴露为Web端点的监控端点,指定多个的时候用英文逗号分隔。
management.endpoints.web.exposure.include默认指定的只有info和health两个端点,我们可以直接指定暴露所有的端点:management.endpoints.web.exposure.include=*,如果采用YAML配置,记得要在星号两边加上英文单引号。暴露所有Web监控端点是一件比较危险的事情,如果需要在生产环境这样做,请务必先确认http://{host}:{management.port}不能通过公网访问(也就是监控端点访问的端口只能通过内网访问,这样可以方便后面说到的Prometheus服务端通过此端口收集数据)。
Prometheus的安装和配置#
Prometheus目前的最新版本是2.5,鉴于笔者当前没深入玩过Docker,这里还是直接下载它的压缩包解压安装。
wget https://github.com/prometheus/prometheus/releases/download/v2.5.0/prometheus-2.5.0.linux-amd64.tar.gz
tar xvfz prometheus-*.tar.gz
cd prometheus-*
先编辑解压出来的目录下的Prometheus配置文件prometheus.yml,主要修改scrape_configs节点的属性:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
# 这里配置需要拉取度量信息的URL路径,这里选择应用程序的prometheus端点
metrics_path: /management/prometheus
static_configs:
# 这里配置host和port
- targets: ['localhost:10091']
配置拉取度量数据的路径为localhost:10091/management/metrics,此前记得把前一节提到的应用在虚拟机中启动。接着启动Prometheus应用:
# 可选参数 --storage.tsdb.path=存储数据的路径,默认路径为./data
./prometheus --config.file=prometheus.yml
Prometheus引用的默认启动端口是9090,启动成功后,日志如下:

此时,访问http://${虚拟机host}:9090/targets就能看到当前Prometheus中执行的Job:

访问http://${虚拟机host}:9090/graph可以查找到我们定义的度量Meter和spring-boot-starter-actuator中已经定义好的一些关于JVM或者Tomcat的度量Meter。我们先对应用的/order接口进行调用,然后查看一下监控前面在应用中定义的order_count_total和method_cost_time_seconds_sum:
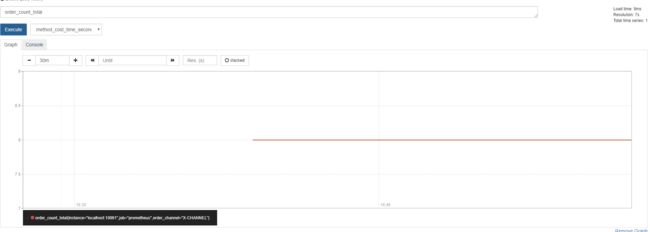
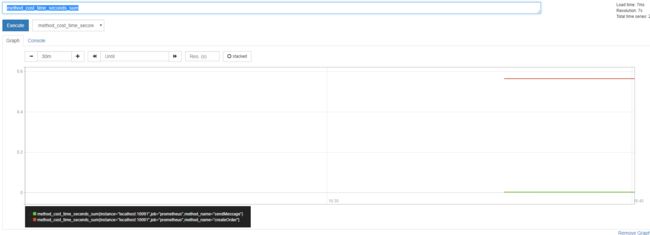
可以看到,Meter的信息已经被收集和展示,但是显然不够详细和炫酷,这个时候就需要使用Grafana的UI做一下点缀。
Grafana的安装和使用#
Grafana的安装过程如下:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.3.4-1.x86_64.rpm
sudo yum localinstall grafana-5.3.4-1.x86_64.rpm
安装完成后,通过命令service grafana-server start启动即可,默认的启动端口为3000,通过http://${host}:3000访问即可。初始的账号密码都为admin,权限是管理员权限。接着需要在Home面板添加一个数据源,目的是对接Prometheus服务端从而可以拉取它里面的度量数据。数据源添加面板如下:
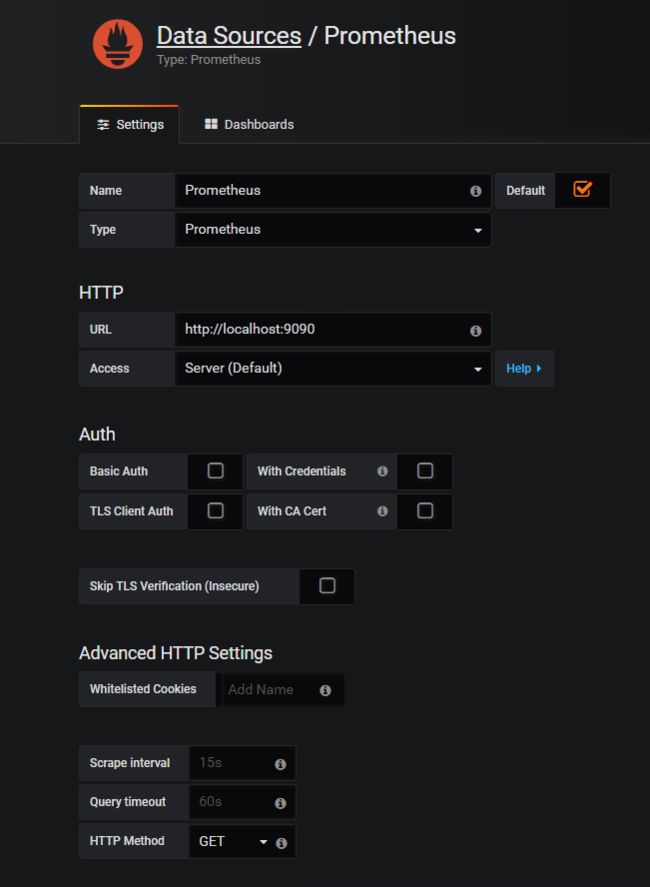
其实就是指向Prometheus服务端的端口就可以了。接下来可以天马行空地添加需要的面板,就下单数量统计的指标,可以添加一个Graph的面板:

配置面板的时候,需要在基础(General)中指定Title:
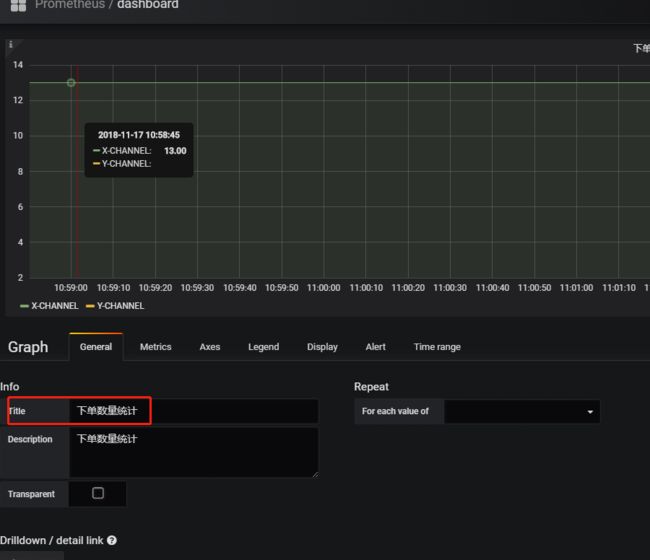
接着比较重要的是Metrics的配置,需要指定数据源和Prometheus的查询语句:
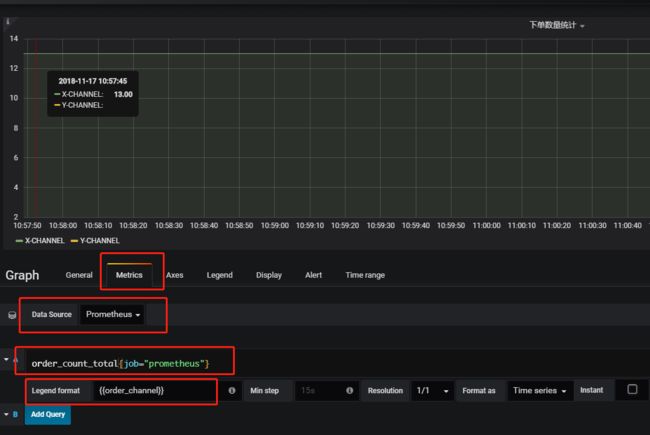
最好参考一下Prometheus的官方文档,稍微学习一下它的查询语言PromQL的使用方式,一个面板可以支持多个PromQL查询。前面提到的两项是基本配置,其他配置项一般是图表展示的辅助或者预警等辅助功能,这里先不展开,可以去Grafana的官网挖掘一下使用方式。然后我们再调用一下下单接口,过一段时间,图表的数据就会自动更新和展示:

接着添加一下项目中使用的Timer的Meter,便于监控方法的执行时间,完成之后大致如下:

上面的面板虽然设计相当粗糙,但是基本功能已经实现。设计面板并不是一件容易的事,如果有需要可以从Github中搜索一下grafana dashboard关键字找现成的开源配置使用或者二次加工后使用。
小结#
常言道:工欲善其事,必先利其器。Micrometer是JVM应用的一款相当优异的度量框架,它提供基于Tag和丰富的度量类型和API便于多维度地进行不同角度度量数据的统计,可以方便地接入Prometheus进行数据收集,使用Grafana的面板进行炫酷的展示,提供了天然的spring-boot体系支持。但是,在实际的业务代码中,度量类型Counter经常被滥用,一旦工具被不加思考地滥用,就反而会成为混乱或者毒瘤。因此,这篇文章就是对Micrometer中的各种Meter的使用场景基于个人的理解做了调研和分析,后面还会有系列的文章分享一下这套方案在实战中的经验和踩坑经历。