第一次线上面试总结(2022.9.9)
文章目录
- 2022年9月9号 第一次线上面试
-
- 面试题总结
-
- 1.内部类的作用?
- 2.深拷贝和浅拷贝的区别?
- 3.什么叫垃圾回收?
- 4.常见的垃圾回收算法
- 5.怎么判断一个对象是否应该被回收?
- 6.产生死锁的条件?
- 7.一个线程如果出现运行时异常应该怎么解决?
2022年9月9号 第一次线上面试
下午两点十分开始通过微信视频面试,面了二十三分钟。
前十五分钟问个人情况、学习状况、职业规划、期望薪资、到岗时间。
最后问了七道面试题,面试结束,下面是对面试题的总结,希望当下次再被问到时能对答如流。
第一次线上面试比较紧张,有些知道的知识回答的也没有那么流畅,当被问到知识盲区,还能及时去学习补充,持续提升自己。
很喜欢的一句话:万般皆下品,惟有读书高。
加油!!!
面试题总结
1.内部类的作用?
定义:放在一个类的内部的类,就叫做内部类
作用:
1)内部类可以很好的实现隐藏:一般的非内部类,是不允许有private与protected权限的,但内部类可以
2)内部类拥有外围类的所有元素的访问权限
3)可以实现多重继承
4)可以避免修改接口而实现同一个类中的两种同名方法的调用
2.深拷贝和浅拷贝的区别?
浅克隆:当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制
深克隆:除了对象本身被复制外,对象所包含的所有成员变量也将复制
浅拷贝(Shallow Copy):1.对于数据类型是基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。因为是两份不同的数据,所以对其中一个对象的该成员变量值进行修改,不会影响另一个对象拷贝得到的数据。2.对于数据类型是引用数据类型的成员变量,比如说成员变量是某个数组、某个类的对象等,那么浅拷贝会进行引用传递,也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象。因为实际上两个对象的该成员变量都指向同一个实例。在这种情况下,在一个对象中修改该成员变量会影响到另一个对象的该成员变量值
深拷贝:对于深拷贝来说,不仅要复制对象的所有基本数据类型的成员变量值,还要为所有引用数据类型的成员变量申请存储空间,并复制每个引用数据类型成员变量所引用的对象,直到该对象可达的所有对象。也就是说,对象进行深拷贝要对整个对象图进行拷贝
简单地说,深拷贝对引用数据类型的成员变量的对象图中所有的对象都开辟了内存空间;而浅拷贝只是传递地址指向,新的对象并没有对引用数据类型创建内存空间
3.什么叫垃圾回收?
Java的垃圾回收是指Java虚拟机提供的能力,用于在空闲时间以不定时的方式动态回收无任何引用的对象占据的内存空间。垃圾回收回收的是无任何引用的对象占据的内存空间而表示对象本身。垃圾回收器的运行时间是不确定的,由JVM决定,在运行时是间歇执行的。虽然可以通过系统来强制回收垃圾,但是这个命令下达后无法保证JVM会立即响应执行,但经验表明,下达命令后,会在短期内执行你的请求,系统通常会感到内存紧缺的时候去执行垃圾回收操作。垃圾回收过于频繁会导致性能下降,过于稀疏会导致内存紧缺。
4.常见的垃圾回收算法
四种垃圾回收算法
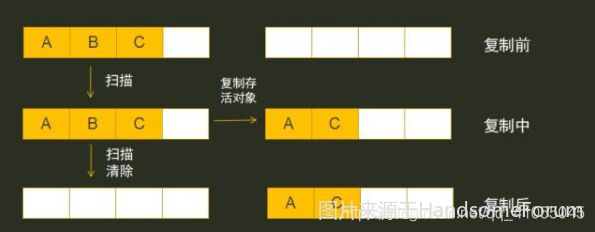
1.复制算法(Copying)
jvm扫描所有对象,通过可达性分析算法标记被引用的对象,之后会申请新的内存空间,将标记的对象复制到新的内存空间里,存活的对象复制完,会清空原来的内存空间,将新的内存最为jvm的对象存储空间。这样虽然解决了内存内存碎片问题,但是如果对象很多,重新申请新的内存空间会很大,在内存不足的场景下,会对jvm运行造成很大的影响
优点:不会产生内存碎片
缺点:需要浪费额外的内存空间


2.标记-清除算法(Mark-Sweep)
jvm会扫描所有的对象实例,通过可达性分析算法,将活跃对象进行标记,jvm再一次扫描所有对象,将未标记的对象进行清除,只有清除动作,不作任何的处理,这样导致的结果会存在很多的内存碎片
缺点:效率低、会造成内存碎片

3.标记-整理算法(Mark-Compact)
标记整理实际上是在标记清除算法上的优化,执行完标记清除全过程之后,再一次对内存进行整理,将所有存活对象统一向一端移动,这样解决了内存碎片问题。
优点:不会产生内存碎片
缺点:效率低


4.分代收集算法
目前jvm常用回收算法就是分代回收,年轻代以复制算法为主,老年代以标记整理算法为主。原因是年轻代对象比较多,每次垃圾回收都有很多的垃圾对象回收,而且要尽可能快的减少生命周期短的对象,存活的对象较少,这时候复制算法比较适合,只要将有标记的对象复制到另一个内存区域,其余全部清除,并且复制的数量较少,效率较高;而老年代是年轻代筛选出来的对象,被标记比较高,需要删除的对象比较少,显然采用标记整理效率较高。

5.怎么判断一个对象是否应该被回收?
1.引用计数法:
给对象增加一个引用计数器,每当有一个地方引用他时,计数器就+1;当引用失效时,计数器就-1;任何时刻计数器为0的对象就是不可能再次被使用的,即对象已“死”。
引用计数法实现简单,判定效率也比较高,在大部分情况下都是一个不错的算法。但是,在主流的JVM中没有选用引用计数法来管理内存,最主要的原因就是引用计数法无法解决对象的循环引用问题。
2.可达性分析算法
通过一系列称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称之为“引用链”,当一个对象到GC Roots没有任何的引用链相连时(从GC Roots到这个对象不可达),证明此对象是不可用的。

对象object5,object6,object7虽然互相有关联,但是它们到GC Roots是不可达的,所以它们将会被判定为是可回收对象。
GC用的可达性分析算法中,哪些对象可以作为GC Roots对象
虚拟机栈中引用的对象
本地方法栈中引用的对象
方法区中静态成员或常量引用的对象
6.产生死锁的条件?
1.产生死锁的必要条件:
(1)互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
(2)请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
(3)不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
2.预防死锁:
(1)资源一次性分配:一次性分配所有资源,这样就不会再有请求了:(破坏请求条件)
(2)只要有一个资源得不到分配,也不给这个进程分配其他的资源:(破坏请保持条件)
(3)可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源(破坏不可剥夺条件)
(4)资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
7.一个线程如果出现运行时异常应该怎么解决?
一 、线程类型
Java程序使用的线程分为两类:
手动创建的线程
线程池管理的线程
二 异常默认处理
对于手动创建的线程,线程运行过程中抛出未捕获的异常的默认行为如下:
1 线程终止,异常信息及堆栈输出到标准错误流(System.err())
2 阻塞线程(Thread.join())正常执行
对于线程池管理的线程,线程运行过程中抛出未捕获的异常的默认行为根据发起任务的方式分为两种情况:
Executor.execute()
1 线程终止,异常信息及堆栈输出到标准错误流(System.err())
2 阻塞线程(Executor.awaitTermination())正常执行
Executor.submit()
1.线程终止,无异常信息输出
2.阻塞线程(Executor.awaitTermination())正常执行
3.阻塞线程(Future.get())抛出异常信息
三 异常处理
异常处理有两种方式,推荐方式1
1.在任务中捕获异常并处理
2.对于手动创建的线程及线程池Executor.execute()处理线程,可在新建线程时通过Thread.setUncaughtExceptionHandler()指定处理方法。该方法对Executor.submit()处理线程无效,须在阻塞线程主动调用Future.get(),再捕获异常