python的scrapy爬取网站用法
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
1.
进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider2.
打开 mySpider 目录下的 items.py,创建一个 ItcastItem 类,和构建 item 模型(model)
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()3.
mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围,在当前目录下输入:
scrapy genspider itcast "itcast.cn"打开mySpider/spider目录里的 itcast.py
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["你要的网站,上下两个要同域名"]
start_urls = (
'你要的网站',
)
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
#如获取到空白的网站源代码,w换成wr或者wb都行
pass运行一下,在mySpider目录下执行:
scrapy crawl itcast修改 itcast.py 文件代码如下:
import scrapy
class Opp2Spider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.com']
start_urls = ['http://www.itcast.cn/']
def parse(self, response):
# 获取网站标题
context = response.xpath('/html/head/title/text()')
# 提取网站标题
title = context.extract_first()
print(title)
pass执行以下命令:
scrapy crawl itcast修改itcast:
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items管道处理:
import json
class ItcastJsonPipeline(object):
def __init__(self):
self.file = open('teacher.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
保存数据
scrapy crawl itcast -o teachers.csvBUG:引用mySpider/items.py 定义的 ItcastItem 类出现问题
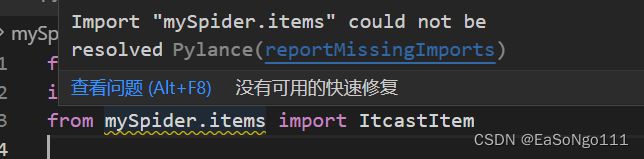
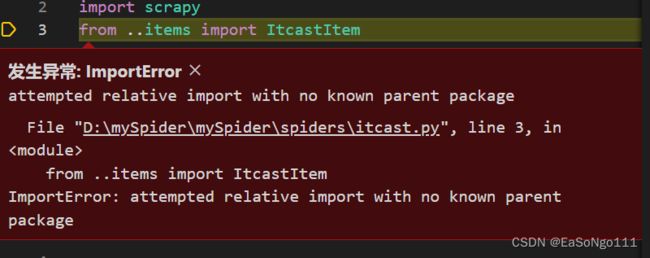
解决办法:
import sys
import os
sys.path.append(os.getcwd())
#用于返回当前工作目录原因:
pycharm给当前文件的解释位置是在open所在的文件。
而vscode则在打开的文件夹的根目录。
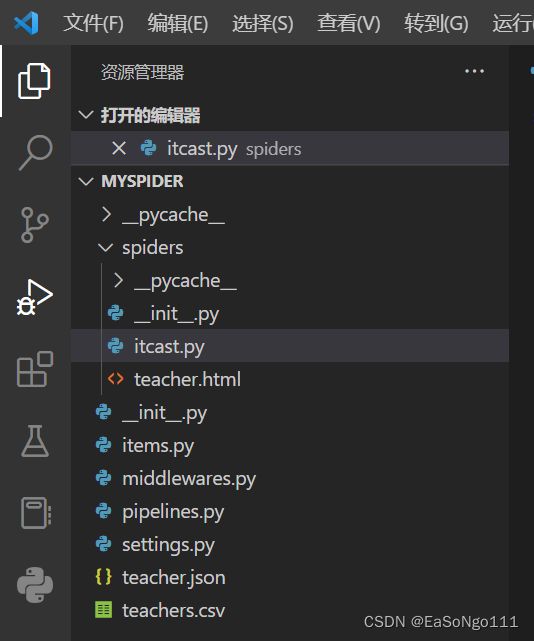
补充:也可以设置启动器
# coding=utf-8
from scrapy import cmdline
project_name = 'IPS'
# run project
def run_project():
cmdline.execute(['scrapy','crawl',f'{project_name}'])
# run project and save data
def save_data():
cmdline.execute(['scrapy','crawl',f'{project_name}','-o',f'{project_name}.csv'])
if __name__ == '__main__':
save_data()
AttributeError: ‘str’ object has no attribute ‘decode’
一般是因为str的类型本身不是bytes,所以不能解码 。
encode: 把普通字符串 转为 机器可识别的bytes
decode: 把bytes转为字符串
Python3的string(字符串) 默认不是bytes,所以不能直接decode,只能先encode转为bytes,再decode。