分布式日志处理(ELK)
目录
一、分布式日志方案
二、Logstash的使用
1.安装配置
2.插件
三、ELK演示案例
1.启动ELK
2.配置LogStatsh
3.配置项目
4.kibana查看日志
一、分布式日志方案
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被称为Elastic Stack。
Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。
Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
通过上面对ELK简单的介绍,我们知道了ELK字面意义包含的每个开源框架的功能。市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。

二、Logstash的使用
1.安装配置
下载 Download Logstash Free | Get Started Now | Elastic
可以使用资料中已下载好的压缩包,上传到服务器
解压
tar -xzf logstash-6.8.10.tar.gz进入到logstash目录
执行下面的命令
bin/logstash -e 'input { stdin { } } output { stdout {} }'这里是从控制台输入,然后输出到控制台,启动成功后输入字符,可以看到输出
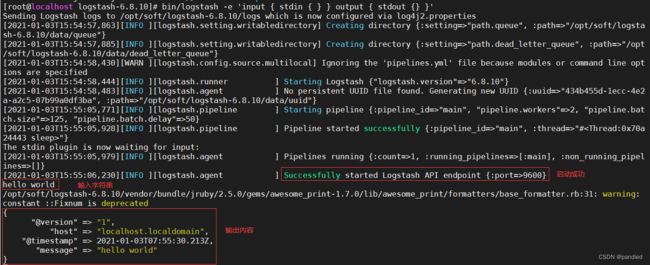 2.插件
2.插件
案例:当向某个文件输入内容是,触发logstash。将新增的内容,传递到es中
logstash 支持多种输入及多种输出,可以从官网查看
输入插件:Input plugins | Logstash Reference [8.4] | Elastic
输出插件:Output plugins | Logstash Reference [8.4] | Elastic
典型的应用场景,从各个应用的日志中收集数据,发送到ElasticSearch,那么可以使用File input plugin和Elasticsearch output plugin
输入插件
先来配置File input plugin
在服务器上新建一个日志目录 /opt/app/logs
mkdir -p /opt/app/logs
# 进入日志目录
cd /opt/app/logs
# 新建一个日志文件
touch 1.log接下来配置Elasticsearch output plugin
修改上面的配置文件
input {
file {
# 插件编号,如果不指定,会自动生成一个,主要用于监控时区分
id => "my_file_plugin_1"
# 监控的文件路径,这里监控目录下的所有文件
path => "/opt/app/logs/*"
}
}
output{
elasticsearch{
# elasticsearch集群地址,多个地址以逗号分隔
hosts=>["192.168.136.150:9200"]
# 创建索引
index=>"app-1-logs"
}
}
//启动logstash
bin/logstash -f config/file.conf
//跳转log目录
cd /opt/app/logs
echo "hello world" >> 1.log同样往1.log中发送日志,可以在ElasticSearch中查看
打开head插件
 这里需要注意,如果出现下面的错误
这里需要注意,如果出现下面的错误
![]()
一般是因为ES的存储空间不足,当磁盘的使用率超过95%时,Elasticsearch为了防止节点耗尽磁盘空间,自动将索引设置为只读模式。
更改elasticsearch.yml配置文件,在config/elasticsearch.yml中增加下面配置
# 禁用磁盘分配决策程序
cluster.routing.allocation.disk.threshold_enabled: false重新启动ES即可,在生产环境一定要关注ES的磁盘使用率.
三、ELK演示案例
1.启动ELK
下载整合了ES Kibana LogStatsh的镜像
docker pull sebp/elk:771 创建容器并启动
docker run -d --name elk -p 5601:5601 -p 9200:9200 -p 5044:5044 sebp/elk:771端口说明
5601 - Kibana web 接口
9200 - Elasticsearch JSON 接口
5044 - Logstash 日志接收接口查看启动日志
docker logs -f elk可能出现的错误
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p
然后,重新启动elk,即可启动成功。
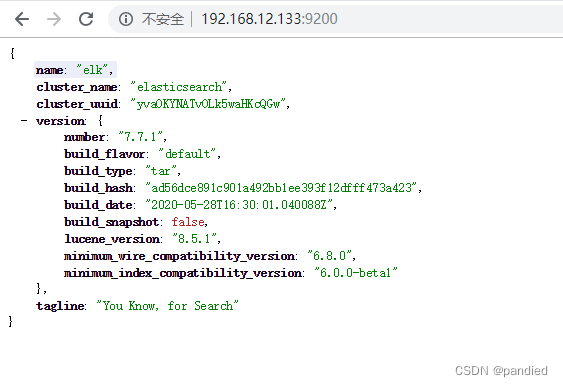
docker start elk输入: http://192.168.12.133:9200 查看下面画面代表es启动成功
输入: http://192.168.12.133:5601 查看下面画面代表kibana启动成功
2.配置LogStatsh
启动成功后 我们需要做下简单的配置,首先是LogStatsh的配置.
进入到容器中
docker exec -it -u root elk bash编辑logStatsh的配置
vim /etc/logstash/conf.d/02-beats-input.conf覆盖配置
input为输入的配置,output为输出的配置
input {
tcp {
port => 5044
mode => "server"
type => json
}
}
output{
elasticsearch {
hosts => ["localhost:9200"]
action => "index"
codec => rubydebug
index => "log4j2-%{+YYYY.MM.dd}"
}
}
修改完毕后exit退出,然后重启容器
docker restart elk3.配置项目
项目中添加依赖
net.logstash.logback
logstash-logback-encoder
5.2
添加日志配置文件logback.xml
4.kibana查看日志
点击Management
创建索引匹配格式: 2填写*即可
 设置匹配格式log*
设置匹配格式log*
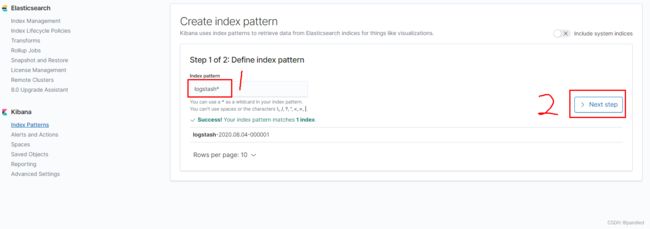 1下拉框选择@timestamp 以时间戳排序
1下拉框选择@timestamp 以时间戳排序
 创建后 在发现中心查看日志
创建后 在发现中心查看日志


1. 是需要显示的字段
2. 是可选过滤字段
3. 日志的显示区域在启动另一个微服务 查看日志情况吧
