【云原生 | Kubernetes 实战】08、零故障升级之 Pod 健康探测——启动、存活、就绪探测
目录
一、Pod容器健康探测
1.1 为什么要对容器做探测?
默认的健康检查
探测类型
检查机制
探测结果
Pod 探针相关的属性
两种探针区别
1.2 启动探测 startupprobe
exec 模式
tcpsocket 模式
httpget 模式
1.3 存活性探测 livenessProbe
通过 exec 方式做健康探测
通过 HTTP 方式做健康探测
通过 TCP 方式做健康探测
1.4 就绪性探测 readinessProbe
1.5 ReadinessProbe + LivenessProbe + StartupProbe 配合使用
一、Pod容器健康探测
1.1 为什么要对容器做探测?
在 Kubernetes 中 Pod 是最小的计算单元,而一个 Pod 又由多个容器组成,相当于每个容器就是一个应用,应用在运行期间,可能因为某些意外情况致使程序挂掉。那么如何监控这些容器状态稳定性,保证服务在运行期间不会发生问题,发生问题后进行重启等机制,就成为了重中之重的事情,考虑到这点 kubernetes 推出了活性探针机制。
有了存活性探针能保证程序在运行中如果挂掉能够自动重启,但是还有个经常遇到的问题,比如说,在Kubernetes 中启动Pod,显示明明Pod已经启动成功,且能访问里面的端口,但是却返回错误信息。还有就是在执行滚动更新时候,总会出现一段时间,Pod对外提供网络访问,但是访问却发生404,这两个原因,都是因为Pod已经成功启动,但是 Pod 的的容器中应用程序还在启动中导致,考虑到这点Kubernetes推出了就绪性探针机制。
默认的健康检查
Kubernetes 默认的健康检查机制: 每个容器启动时都会执行一个进程, 此进程由 Dockerfile的 CMD 或 ENTRYPOINT 指定。 如果进程退出时返回码非零,则认为容器发生故障, Kubernetes 就会根据 restartPolicy 策略决定是否重启容器。
[root@k8s-master01 pod-yaml]# vim check.yaml
apiVersion: v1
kind: Pod
metadata:
name: check
namespace: default
labels:
app: check
spec:
containers:
- name: check
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- sleep 10;exit
[root@k8s-master01 pod-yaml]# kubectl apply -f check.yaml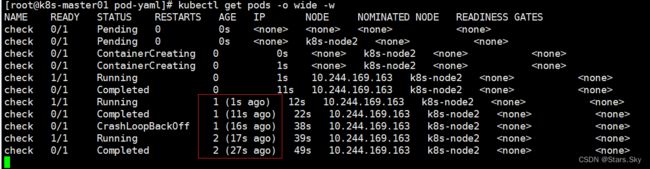
在上面的例子中,容器进程返回值非零,Kubernetes则认为容器发生故障,需要重启。有不少情况是发生了故障,但进程并不会退出。 比如访问Web服务器时显示500内部错误,可能是系统超载,也可能是资源死锁,此时httpd进程并没有异常退出,在这种情况下重启容器可能是最直接、最有效的解决方案。
探测类型
针对运行中的容器,k8s 可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
- startupProbe:探测容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功 Success。
- livenessprobe:用指定的方式(exec、tcp、http)检测 pod 中的容器是否正常运行,如果检测失败,则认为容器不健康,那么Kubelet将根据Pod中设置的 restartPolicy策略来判断 Pod 是否要进行重启操作,如果容器配置中没有配置 livenessProbe,Kubelet 将认为存活探针探测一直为 success(成功)状态。
- readnessprobe:就绪性探针,用于检测容器中的应用是否可以接受请求,当探测成功后才使 Pod对外提供网络访问,将容器标记为就绪状态,可以加到 pod 前端负载,如果探测失败,则将容器标记为未就绪状态,会把 pod 从前端负载移除。
可以自定义在pod启动时是否执行这些检测,如果不设置,则检测结果均默认为通过,如果设置,则顺序为 startupProbe>readinessProbe和livenessProbe,readinessProbe 和 livenessProbe是并发关系。
检查机制
使用探针来检查容器有四种不同的方法。 每个探针都必须准确定义为这四种机制中的一种:
- exec:在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
- TCPSocket:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
- HTTPGet:通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器健康。
grpc:使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC健康检查。 如果响应的状态是 "SERVING",则认为诊断成功。 gRPC 探针是一个 Alpha 特性,只有在你启用了 "GRPCContainerProbe" 特性门控时才能使用。
探测结果
每次探测都将获得以下三种结果之一:
- Success:表示通过检测。
- Failure:表示未通过检测。
- Unknown:表示检测没有正常进行。
Pod 探针相关的属性
探针(Probe)有许多可选字段,可以用来更加精确的控制 Liveness 和 Readiness 两种探针的行为:
- initialDelaySeconds:容器启动后要等待多少秒后探针开始工作,单位“秒”,默认是 0 秒,最小值是 0
- periodSeconds: 执行探测的时间间隔(单位是秒),默认为 10s,单位“秒”,最小值是1。
- timeoutSeconds: 探针执行检测请求后,等待响应的超时时间,默认为1,单位“秒”。
- successThreshold:连续探测几次成功,才认为探测成功,默认为 1,在 Liveness 探针中必须为1,最小值为1。
- failureThreshold: 探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod会被标记为未就绪,默认为 3,最小值为 1
两种探针区别
ReadinessProbe 和 livenessProbe 可以使用相同探测方式,只是对 Pod 的处置方式不同:
- readinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
- livenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施。
参考文档:
- Pod 的生命周期 | Kubernetes
- Pod | Kubernetes
1.2 启动探测 startupprobe
exec 模式
许多长时间运行的应用最终会进入损坏状态,除非重新启动,否则无法被恢复。 Kubernetes 提供了存活探针来发现并处理这种情况。
# 查看帮助命令
[root@k8s-master01 pod-yaml]# kubectl explain pods.spec.containers
[root@k8s-master01 pod-yaml]# kubectl explain pods.spec.containers.startupProbe
[root@k8s-master01 pod-yaml]# kubectl explain pods.spec.containers.startupProbe.exec
[root@k8s-master01 pod-yaml]# vim startup-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: startupprobe
spec:
containers:
- name: startup
image: tomcat:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
startupProbe:
exec:
command:
- "/bin/sh"
- "-c"
- "ps aux | grep tomcat"
initialDelaySeconds: 20 #容器启动后多久(20s)开始探测
periodSeconds: 20 #执行探测的时间间隔(每20秒探测一次)
timeoutSeconds: 10 #探针执行检测请求后,等待响应的超时时间
successThreshold: 1 #成功多少次才算成功
failureThreshold: 3 #失败多少次才算失败
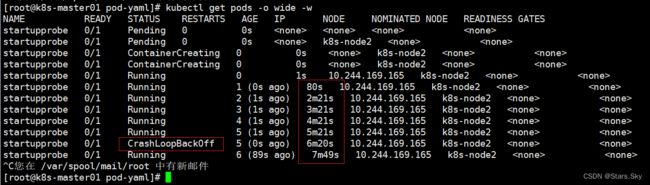
[root@k8s-master01 pod-yaml]# kubectl apply -f startup-exec.yaml 探测过程如下:

# 修改 startup-exec.yaml 文件,使其探测命令失效,无法探测,修改如下部分:
command:
- "/bin/sh"
- "-c"
- "aa ps aux | grep tomcat" # 让这个命令失效
[root@k8s-master01 pod-yaml]# kubectl delete pods startupprobe
[root@k8s-master01 pod-yaml]# kubectl apply -f startup-exec.yaml可以看到,基本上每隔一分钟重启一次:
tcpsocket 模式
第二种类型的存活探测是使用 TCP 套接字。 使用这种配置时,kubelet 会尝试在指定端口和容器建立套接字链接。 如果能建立连接,这个容器就被看作是健康的,如果不能则这个容器就被看作是有问题的。
# 删除前面创建的 pod
[root@k8s-master01 pod-yaml]# kubectl delete pods startupprobe
# 查看帮助命令
[root@k8s-master01 pod-yaml]# kubectl explain pods.spec.containers.startupProbe
[root@k8s-master01 pod-yaml]# kubectl explain pods.spec.containers.startupProbe.tcpSocket
[root@k8s-master01 pod-yaml]# vim startup-tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:
name: startupprobe
spec:
containers:
- name: startup
image: billygoo/tomcat8-jdk8:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
startupProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20 #容器启动后多久开始探测
periodSeconds: 20 #执行探测的时间间隔
timeoutSeconds: 10 #探针执行检测请求后,等待响应的超时时间
successThreshold: 1 #成功多少次才算成功
failureThreshold: 3 #失败多少次才算失败
[root@k8s-master01 pod-yaml]# kubectl apply -f startup-tcpsocket.yaml 上面这个例子使用启动探针。kubelet 会在容器启动 20 秒后发送第一个就绪探针。 探针会尝试连接 tomcat 容器的 8080 端口。 如果探测成功,这个 Pod 会被标记为就绪状态,kubelet 将继续每隔 20 秒运行一次探测。

httpget 模式
另外一种类型的存活探测方式是使用 HTTP GET 请求。 下面是一个 Pod 的配置文件,其中运行一个基于 billygoo/tomcat8-jdk8 镜像的容器。
[root@k8s-master01 pod-yaml]# vim startup-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: startupprobe
spec:
containers:
- name: startup
image: billygoo/tomcat8-jdk8:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
startupProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 20 #容器启动后多久开始探测
periodSeconds: 20 #执行探测的时间间隔
timeoutSeconds: 10 #探针执行检测请求后,等待响应的超时时间
successThreshold: 1 #成功多少次才算成功
failureThreshold: 3 #失败多少次才算失败
[root@k8s-master01 pod-yaml]# kubectl delete pods startupprobe
[root@k8s-master01 pod-yaml]# kubectl apply -f startup-httpget.yaml 在这个配置文件中,你可以看到 Pod 只有一个容器。 periodSeconds 字段指定了 kubelet 每隔 20 秒执行一次存活探测。 initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 20 秒。 kubelet 会向容器内运行的服务(服务在监听 8080 端口)发送一个 HTTP GET 请求来执行探测。 如果服务器上 / 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。 如果处理程序返回失败代码,则 kubelet 会杀死这个容器并将其重启。
返回大于或等于 200 并且小于 400 的任何代码都标示成功,其它返回代码都标示失败。

1.3 存活性探测 livenessProbe
通过 exec 方式做健康探测
[root@k8s-master01 pod-yaml]# vim liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
labels:
app: liveness
spec:
containers:
- name: liveness
image: busybox:1.28
imagePullPolicy: IfNotPresent
args: # 创建测试探针探测的文件
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
initialDelaySeconds: 10 # 延迟检测时间
periodSeconds: 5 # 检测时间间隔
exec:
command:
- cat
- /tmp/healthy
[root@k8s-master01 pod-yaml]# kubectl apply -f liveness-exec.yaml容器启动设置执行的命令:/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"。容器在初始化后,首先创建一个 /tmp/healthy 文件,然后执行睡眠命令,睡眠 30 秒,到时间后执行删除 /tmp/healthy 文件命令。而设置的存活探针检检测方式为执行 shell 命令,用 cat 命令输出 healthy 文件的内容,如果能成功执行这条命令,存活探针就认为探测成功,否则探测失败。在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。

通过 HTTP 方式做健康探测
[root@k8s-master01 pod-yaml]# vim liveness-http.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-http
labels:
test: liveness
spec:
containers:
- name: liveness
image: mydlqclub/springboot-helloworld:0.0.1
imagePullPolicy: IfNotPresent
livenessProbe:
initialDelaySeconds: 20 # 延迟加载时间
periodSeconds: 5 # 重试时间间隔
timeoutSeconds: 10 # 超时时间设置
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
[root@k8s-master01 pod-yaml]# kubectl delete pods liveness-exec
pod "liveness-exec" deleted
[root@k8s-master01 pod-yaml]# kubectl apply -f liveness-http.yaml 上面 Pod 中启动的容器是一个 SpringBoot 应用,其中引用了 Actuator 组件,提供了 /actuator/health 健康检查地址,存活探针可以使用 HTTPGet 方式向服务发起请求,curl 请求 8081 端口的 /actuator/health 路径来进行存活判断:
- 任何大于或等于200且小于400的代码表示探测成功。
- 任何其他代码表示失败。

![]()
如果探测失败,则会杀死 Pod 进行重启操作。
httpGet 探测方式有如下可选的控制字段:
- scheme: 用于连接host的协议,默认为HTTP。
- host:要连接的主机名,默认为Pod IP,可以在http request head中设置host头部。
- port:容器上要访问端口号或名称。
- path:http服务器上的访问URI。
- httpHeaders:自定义HTTP请求headers,HTTP允许重复headers。
通过 TCP 方式做健康探测
[root@k8s-master01 pod-yaml]# vim liveness-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp
labels:
app: liveness
spec:
containers:
- name: liveness
image: nginx:latest
imagePullPolicy: IfNotPresent
livenessProbe:
initialDelaySeconds: 15
periodSeconds: 20
tcpSocket:
port: 80
[root@k8s-master01 pod-yaml]# kubectl delete pods liveness-http
[root@k8s-master01 pod-yaml]# kubectl apply -f liveness-tcp.yaml
# 进入容器内部停止 nginx
[root@k8s-master01 pod-yaml]# kubectl exec -it liveness-tcp -- bash
root@liveness-tcp:/# nginx -s stop
TCP 检查方式和 HTTP 检查方式非常相似,在容器启动 initialDelaySeconds 参数设定的时间后,kubelet 将发送第一个 livenessProbe 探针,尝试连接容器的 80 端口,如果连接失败则将杀死 Pod 重启容器。

1.4 就绪性探测 readinessProbe
有时候,应用会暂时性地无法为请求提供服务。 例如,应用在启动时可能需要加载大量的数据或配置文件,或是启动后要依赖等待外部服务。 在这种情况下,既不想杀死应用,也不想给它发送请求。 Kubernetes 提供了就绪探针来发现并缓解这些情况。 容器所在 Pod 上报还未就绪的信息,并且不接受通过 Kubernetes Service 的流量。
Pod 的ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,唯一区别就是要使用 readinessProbe 字段,而不是 livenessProbe 字段。只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。这里用一个 Springboot 项目,设置 ReadinessProbe 探测 SpringBoot 项目的 8081 端口下的 /actuator/health 接口,如果探测成功则代表内部程序以及启动,就开放对外提供接口访问,否则内部应用没有成功启动,暂不对外提供访问,直到就绪探针探测成功。
[root@k8s-master01 pod-yaml]# vim readiness-exec.yaml
apiVersion: v1
kind: Service
metadata:
name: springboot
labels:
app: springboot
spec:
type: NodePort
ports:
- name: server
port: 8080
targetPort: 8080 # 关联容器的端口
nodePort: 31180 # 物理机端口
- name: management
port: 8081
targetPort: 8081
nodePort: 31181
selector:
app: springboot # 关联容器的标签
---
apiVersion: v1
kind: Pod
metadata:
name: springboot
labels:
app: springboot
spec:
containers:
- name: springboot
image: mydlqclub/springboot-helloworld:0.0.1
imagePullPolicy: IfNotPresent
ports:
- name: server
containerPort: 8080
- name: management
containerPort: 8081
readinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
[root@k8s-master01 pod-yaml]# kubectl apply -f readiness-exec.yaml
[root@k8s-master01 pod-yaml]# kubectl describe svc springboot 当 springboot 就绪了(running)才会显示关联ip:
当 springboot 就绪了(running)才会显示关联ip:

1.5 ReadinessProbe + LivenessProbe + StartupProbe 配合使用
一般程序中需要设置三种探针结合使用,并且也要结合实际情况,来配置初始化检查时间和检测间隔,下面列一个简单的 SpringBoot 项目的例子。
[root@k8s-master01 pod-yaml]# vim start-read-live.yaml
apiVersion: v1
kind: Service
metadata:
name: springboot-live
labels:
app: springboot
spec:
type: NodePort
ports:
- name: server
port: 8080
targetPort: 8080
nodePort: 31180
- name: management
port: 8081
targetPort: 8081
nodePort: 31181
selector:
app: springboot
---
apiVersion: v1
kind: Pod
metadata:
name: springboot-live
labels:
app: springboot
spec:
containers:
- name: springboot
image: mydlqclub/springboot-helloworld:0.0.1
imagePullPolicy: IfNotPresent
ports:
- name: server
containerPort: 8080
- name: management
containerPort: 8081
readinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
livenessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
startupProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
[root@k8s-master01 pod-yaml]# kubectl delete pods springboot
[root@k8s-master01 pod-yaml]# kubectl delete svc springboot
[root@k8s-master01 pod-yaml]# kubectl apply -f start-read-live.yaml
# 进入容器内部杀掉进程
[root@k8s-master01 pod-yaml]# kubectl exec -it springboot-live -- /bin/sh
/ # kill 1先启动启动探测。就绪和存活探测可以在同一个容器上并行使用。 两者共同使用,可以确保流量不会发给还未就绪的容器,当这些探测失败时容器会被重新启动。

参考官方文档:配置存活、就绪和启动探针 | Kubernetes
上一篇文章:【云原生 | Kubernetes 实战】07、Pod 高级实战:Pod 生命周期、启动钩子、停止钩子_Stars.Sky的博客-CSDN博客
下一篇文章:【云原生 | Kubernetes 实战】09、K8s 控制器 Replicaset 入门到企业实战应用