大数据技术之Spark(五)——RDD持久化
一、什么是RDD持久化
以wordCount为例,我们希望实现两个功能,最后一步不需要聚合操作,将mapRDD的结果放在不同的组中。
object Spark01_RDD_Persist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val list = List("hello scala","hello spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map((_,1))
val reduceRDD = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("==============================")
val rdd1 = sc.makeRDD(list)
val flatRDD1 = rdd1.flatMap(_.split(" "))
val mapRDD1 = flatRDD1.map((_,1))
val groupRDD = mapRDD1.groupByKey()
groupRDD.collect().foreach(println)
// 将重复部分去除,重用mapRDD对象
println("==============================")
val groupRDD2 = mapRDD.groupByKey()
groupRDD2.collect().foreach(println)
sc.stop()
}
}
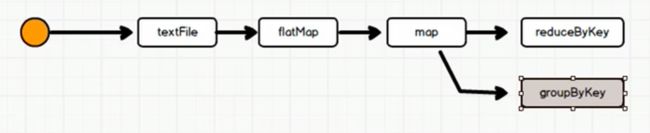
按照上面的流程,数据的处理流程如下图所示:
我们发现流程图中很多功能是相同的。我们希望实现对象的重用,相同的部分不重复计算,流程图如下图所示:
但是由于RDD中不存储数据,只保留计算逻辑。map中的数据执行完map之后传给了reduceByKey,map中没有数据,就无法将数据传递给groupByKey
如果一个RDD需要重复使用,那么只能从头开始,重新运行来获取数据。上面的代码中只是对象重用了,但数据并没有重用。

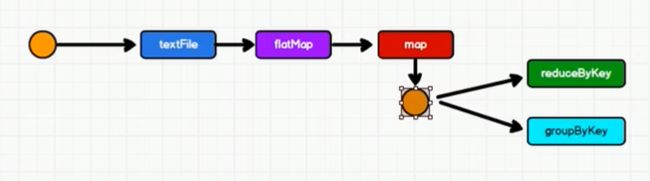
综上所述,数据会被重复读取。如果想要提高性能,需要数据不被重复读取。那么就需要在数据传输给reduceByKey之前,先将数据放到一个缓存(文件)中,这样就可以不用重复读了。如下图所示:我们把这种操作称为持久化操作。
二、RDD持久化操作:cache 和 persist
RDD对象的持久化操作不一定是为了重用。在数据执行较长,或数据比较重要的场合也可以采用持久化操作。
object Spark01_RDD_Persist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val list = List("hello scala","hello spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map((_,1))
// 持久化操作
mapRDD.cache() // 数据缓存
mapRDD.persist() // 可以更改存储级别
mapRDD.persist(StorageLevel.DISK_ONLY)
val reduceRDD = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("==============================")
val groupRDD2 = mapRDD.groupByKey()
groupRDD2.collect().foreach(println)
sc.stop()
}
}
2.1 存储级别
persist可以设置存储级别,默认将数据保存到内存中StorageLevel.MEMORY_ONLY如果想要保存到磁盘文件,需要更改存储级别。
cache默认持久化的操作,只能将数据保存到内存中StorageLevel.MEMORY_ONLY。
| 存储级别 | 介绍 |
| MEMORY_ONLY | 将 RDD 存储为JVM 中的反序列化 Java 对象。如果内存不够,部分分区就不会被缓存,并且在每次需要这些分区的时候都会被动态地重新计算。此为默认级别 |
| MEMORY_ONLY_2 | 与 MEMORY ONLY 相同,只是每个持久化的分区都会复制一份副本,存储在其他节点上。这种机制主要用于容错,一旦持久化数据丢失,可以使用副本数据,而不需要重新计算 |
| MEMORY_AND_DISK | 将 RDD 存储为JVM 中的反序列化 Java 对象。如果内存不够,就将未缓存的分区存储在磁盘上,并在需要这些分区时从磁盘读取 |
| MEMORY_AND_DISK_2 | 与MEMORY_AND_DISK 相同,只是每个持化的分区都会复制一份副本,存储在其他节点上。这种机制主要用于容错,一旦持久化数据丢失,可以使用副本数据,而不需要重新计算 |
| MEMORY_ONLY_SER | 将 RDD 存储为序列化的 Java 对象(每个分区一个字节数组)。这通常比反序列化对象更节省空间,特别是在使用快速序列化时,但读取时会增加 CPU负担 |
| MEMORY_AND_DISK_SER | 类似于 MEMORY_ONLY_ SER,但是溢出的分区将写到磁盘,而不是每次需要对其动态地重新计算 |
| DISK_ONLY | 只在磁盘上存储 RDD 分区 |
三、RDD CheckPoint检查点
所谓的检查点,就是将RDD中间结果写入磁盘,需要指定检查点保存路径。
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错。如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少开销。
对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
// 设置检查点路径
sc.setCheckpointDir("./checkpoint1")
// 数据检查点:针对 wordToOneRdd 做检查点计算
wordToOneRdd.checkpoint()checkpoint 需要落盘,需要指定检查点保存路径
检查点路径中保存的文件,当作业执行完毕后,不会被删除。
一般保存路径都是在分布式存储系统:HDFS
object Spark01_RDD_Persist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
sc.setCheckpointDir("hdfs://192.168.153.139:9000/tmp")
val list = List("hello scala","hello spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map({
println("++++++++++")
(_,1)
})
// checkpoint 需要落盘,需要指定检查点保存路径
// 检查点路径中保存的文件,当作业执行完毕后,不会被删除。
// 一般保存路径都是在分布式存储系统:HDFS
mapRDD.checkpoint()
val reduceRDD = mapRDD.reduceByKey(_+_)
reduceRDD.collect().foreach(println)
println("==============================")
val rdd1 = sc.makeRDD(list)
val flatRDD1 = rdd1.flatMap(_.split(" "))
val mapRDD1 = flatRDD1.map((_,1))
val groupRDD = mapRDD1.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}三、缓存和检查点的区别
cache和persisit、checkpoint都可以把数据保存起来,为了提高效率可以通用。那么它们之间有什么区别呢?
cache:将数据临时存储在内存中进行数据重用。
缺点:容易引发数据丢失、内存溢出、数据移除等问题,数据不安全。
persist:存在存储级别,将数据临时存储在磁盘文件中进行数据重用。
缺点:涉及到磁盘IO,性能较低,但是数据安全。如果作业执行完毕,临时保存的数据文件就会丢失。
checkpoint:将数据长久地保存在磁盘文件中,进行数据的重用。
缺点:涉及到磁盘IO,性能较低,但是数据安全。为了保证数据安全,所以一般情况下,会独立执行作业。当行动算子触发执行的时候,checkpoint会产生新的作业。
总结:
(1)cache缓存只是将数据保存起来,不切断血缘依赖。会在血缘关系中添加新的依赖,一旦出现问题,可以从头读取数据。
checkpoint检查点切断血缘依赖,重新建立新的血缘关系。checkpoint等同于改变数据源。
(2)cache缓存的数据通常存储在磁盘、内存等地,可靠性低。checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高
(3)为了能够提高效率,一般情况下需要和cache联合使用,对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存 中读取数据即可,否则需要再从头计算一次 RDD。
val mapRDD = flatRDD.map(word=>{ (word,1) }) mapRDD.cache() mapRDD.checkpoint()
| 区别 | 持久化 | 检查点 |
|---|---|---|
| 存储位置 | 保存在本地的内存或磁盘 | 保存在可靠的存储系统(HDFS)中 |
| 生命周期 | 程序结束后会被清除或者调用unpersist方法清除 | 程序结束后依然存在,只能手动清除 |
| 依赖关系 | 保存的是RDD,会保留RDD的血脉关系 | 保存的是RDD的数据,不包含血脉关系 |