大数据训练营课程大纲&项目简介
文章目录
- 课程大纲
- 模块一:大数据的“三驾马车”:HDFS、MapReduce/YARN、HBase
- 模块二:大数据时代数据仓库实践:Hive
- 模块三:更快的数据处理引擎:Spark
- 模块四:重构现代化数据仓库:Spark SQL
- 模块五:OLAP 之争:Presto、Kylin、ClickHouse
- 模块七:数据开发体系:ETL、Data Visualization
- 模块九:Hadoop、Spark 核心源码讲解
- 模块十:面试通关:如何成为卓越的大数据开发工程师
- 实战项目
- 项目一:Hadoop 集群云主机搭建和健康管理
- 项目二:数据可视化和交互式自助分析平台建设
- 项目三:利用 Spark 对大型电商用户数据进行分析
- 项目四:Hadoop、Spark 源码学习
课程大纲
模块一:大数据的“三驾马车”:HDFS、MapReduce/YARN、HBase
教学目标:
Hadoop 是大数据平台体系的基石,本模块通过对 Hadoop 生态“三驾马车”的学习,带你:
- 从存储、计算角度掌握分布式系统框架;
- 掌握如何搭建、管理、使用和监控集群;
- 了解如何高效地解决大数据问题;
- 通过学习 HDFS、MapReduce、YARN 的优秀设计和源码,掌握如何设计和实现一个分布式系统。
学习和工作中的痛点:
- 对 Hadoop 技术生态理解不深,不知道哪些场景会出现问题,也不知道如何避坑、如何优化系统;
- 水平停留在使用层面,没有能力设计和实现出稳定的分布式系统;
- Hadoop 生态体系复杂,涉及的组件多,代码量大,学习无从下手;
- 自学效率低,看过的知识容易忘,理解不深,也没法直击重点,做到学以致用。
通过学习掌握的核心能力:
- 全面了解大数据数据处理的框架和模型;
- 对 HDFS、MapReduce、YARN 的架构进行系统学习,了解块存储、读写分离、调度器、有限状态自动机、WAL 等技术原理;
- 学习 HDFS 和 YARN 的体系架构,HA 模型,Federation 架构等;
- 掌握对 Hadoop 进行 trouble-shooting 的思路和技巧,了解如何选用适合的架构,如何监控和管理平台;
- 掌握分布式系统的设计原理,通过学习 Hadoop 的优秀源码,设计和实现自己的分布式系统;
- 学完能够胜任 Hadoop 大数据平台工程师和运维工程师角色。
详细内容:导入型课程(2 课时)+ 13 课时
- Hadoop 发展历程和生态体系概述;
- 分布式文件系统 HDFS 概述,包括其功能、作用、优势、应用现状和发展趋势等;
- 详解 HDFS 的核心关键技术、设计精髓以及基本工作原理,包括系统架构、文件存储模式、存储扩容与吞吐性能扩展等;
- 数据并行技术 MapReduce 概述,并详解其工作机制、底层原理、性能调优技巧等;
- 大数据平台中的并行计算处理思路与函数式编程技术原理解析;
- MapReduce 并行处理平台的系统架构、核心功能模块、MapReduce 编程应用开发实践;
- 学习资源调度器 YARN 的架构和多种调度算法;
- 讲解 YARN 的容灾机制、多租户模型等;
- 案例:以某公司大数据平台为例,分享 PB 级别容量集群的实际配置方案,并给出集群机房实际部署拓扑推荐。
模块二:大数据时代数据仓库实践:Hive
教学目标:
Hive 已经成为大数据体系下数据仓库的标准,也已经成为各大互联网公司数据仓库建设的必选方案,
本模块将带你:
- 重学 Hive 的基础与背后原理;
- 深入解析 Hive 的使用方式;
- 掌握 HQL 语法以及常用的仓库模式设计;
- 掌握 Hive 优化方法;
- 了解 Hive 的高级特性和未来的发展趋势;
- 通过案例实践巩固学习内容。
学习和工作中的痛点:
- 业务方只会写 SQL,但不知晓 SQL 底层实现细节,无法写出高效的 SQL;
- 平台方看不懂 SQL,无法帮助业务进行 SQL 优化,导致平台资源浪费;
- SQL 报错看不懂,跑的慢只会甩锅资源不足,无法找出根本原因。
通过学习掌握的核心能力:
- 掌握 Hive 的基本原理;
- 掌握 Hive 的基本使用;
- 掌握 HiveQL 的基本语法和常用优化措施;
- 了解 Hive 数据仓库设计的方法能够胜任大多数互联网场景下的大数据分析和数据开发任务。
详细内容:10 课时
- Hive 的版本演进与目前现状,Hive 的安装部署,HiveServer 与 JDBC/ODBC,Hive 的基本架构;
- Hive 支持的基本数据类型,Hive 支持的文件格式与优劣对比,Hive 的常用模式设计;
- HiveQL 的数据定义、数据操作和数据查询(Select/Where/Group By/Join/OrderBy/SortBy/Cl By/Join/OrderBy/SortBy/ClusterBy/DistributeBy);
- Hive 调优,Explain 查看执行计划,控制 Map/Reduce 数;
- Hive 推测执行机制,Join 优化策略,数据倾斜问题的通用解决,动态分区优化;
- 案例:通过广告用户行为分析实践,融汇贯通本模块所学内容。
模块三:更快的数据处理引擎:Spark
教学目标:
Spark 作为新一代的大数据处理引擎,是众多互联网公司进行离线数据处理的首选,它同时也被广泛应用在实时计算、机器学习等领域,本模块将带你:
- 了解和掌握 Spark 基础概念和底层原理;
- 掌握 Spark 实战技巧,能进行数据处理分析、数据开发等任务;
- 结合企业级案例掌握性能调优、大数据迁移等知识;
- 激发出运用大数据解决实际问题的兴趣。
学习和工作中的痛点:
- 不了解 Scala 语言,不会使用 Spark API;
- 对 Spark 编程模式不了解,无法将 MR 作业转成 Spark 作业;
- 对 Spark 各个组件的底层工作原理不清楚,无法灵活使用 Spark 进行数据分析,或者不清楚 Spark 任务跑得慢的原因;
- Spark 任务经常 OOM,资源使用率低,大作业情况下跑得慢,但却无法快速定位原因、优化 Spark 任务。
通过学习掌握的核心能力:
- 理解 Spark 设计原理、工作原理和各类基本组件的使用、部署方式;
- 掌握如何查询 Spark 的 API,如何利用文档开发自己的 Spark 应用;
- 掌握通过查看 Spark 作业运行时状态和参数,找出性能瓶颈的能力,并进行针对性的分析和优化;
- 具备解决企业级复杂大数据问题的初步思路与技能;
- 学完能够胜任数据开发工程师、数据应用开发工程师的角色。
详细内容:5 课时
- 什么是 Spark,Spark 的应用场景与思路;
- Spark 基础概念如编程模型、RDD、数据处理流程、数据存储格式、资源分配算法等;
- Spark 比 Hive 快 100 倍的原因;
- 如何搭建 Spark 集群环境,如何做好监控;
- Spark 作业的生命周期管理和性能优化;
- Spark API 详解和编写 Spark 程序实战;
- Spark 调度器,Spark Shuffle 优化;
- 了解 Spark 机器学习和 Spark 流计算。
模块四:重构现代化数据仓库:Spark SQL
教学目标:
Spark SQL 是 Spark 最重要的模块,超过 80% 的 Spark 使用场景是 SQL,同时凭借其对 HiveQL 的兼容,正逐渐取代 Hive 在数据仓库中的地位,本模块将带你:
- 重学 SQL 基本概念与背后原理;
- 掌握 Spark SQL 语法、常用仓库模式设计等实战技巧;
- 掌握 Spark SQL 优化思路与方法;
- 掌握 Spark SQL 的高级特性和 Spark 3.0 新功能。
学习和工作中的痛点:
- 会写 SQL 的数据分析师不了解 Spark SQL 的原理,SQL 跑得慢或者跑不出来;
- “坏 SQL”造成平台资源浪费甚至应用 OOM;
- 面对复杂的 SQL 执行计划无从下手,不知道瓶颈在哪,也不知道如何解决;
- 对 Spark 有一定开发基础,但看不懂 Spark SQL 的源码,不知道怎么去修复 Bug。
通过学习掌握的核心能力:
- 掌握 SQL 基础概念与底层原理;
- 掌握 Spark SQL 实战调优技巧与背后原理;
- 能快速定位 SQL 执行慢的原因,并能写出更快的 SQL;
- 对 Spark SQL 的逻辑计划优化、物理计划和代码生成都有一定认识,并能自己添加简单规则进行 SQL 优化器的改造;
- 具备搭建和优化数仓引擎的能力;
- 能进行内核的二次开发和改造,构建出更稳定、吞吐量更大的平台;
- 学完能够胜任 SQL 优化和高级数据开发任务。
详细内容:10 课时
- SQL 基本概念,表连接方式;
- Spark SQL 逻辑计划优化和物理计划优化;
- Spark 数据倾斜的优化;
- Spark 3.0 新特性;
- Spark SQL 最佳实践;
- 实践:PB 级商用数据仓库如何平稳迁移至 Spark;
- Spark TPC 基准测试;
- Spark Web UI Debug;
- 案例:Spark 作业管理企业案例;
- 案例:Spark 数仓迁移企业案例。
模块五:OLAP 之争:Presto、Kylin、ClickHouse
教学目标:
OLAP 技术是大数据分析领域非常重要的部分,存在着许多优秀的计算引擎,如何选型就成了一大难题,本模块将带你:
- 在 Spark SQL 的基础上,对 OLAP 的知识体系进行拓展;
- 对常用的三个 OLAP 引擎:Presto、Kylin、ClickHouse 进行学习;
- 对比学习这三个 OLAP 引擎的应用场景、背后原理与选型要点。
学习和工作中的痛点:
- 平台提供多种 OLAP 技术,但不清楚该使用哪种;
- 不懂引擎之间的差异,容易产生部分查询快速、全部查询都快的误区;
- 技术栈太多,学了就忘,没有横向对比和系统总结。
通过学习掌握的核心能力:
- 掌握 OLAP 技术的基础;
- 掌握 Presto、Kylin、ClickHouse 三个引擎的基本工作原理;
- 理解不同引擎的使用场景和优劣势对比;
- 能在多种 OLAP 引擎中把握共性和特性,在实践中更好地选型与使用;
- 理解 OLAP 技术未来的发展方向和核心问题。
详细内容:7 课时
- OLAP 是什么以及常见操作;
- Presto、Kylin、ClickHouse 三者的架构体系解析;
- Presto、Kylin、ClickHouse 查询优化器介绍和执行流程解析;
- 横向对比这三个 OLAP 引擎的特点和使用场景,掌握其共性和特性;
- 掌握 OLAP 引擎技术方案选型要点。
模块六:流式处理和实时计算:Kafka、Flink
教学目标:
当规模计算已经不是当下核心问题的时候,实时性要求便成为大数据领域的一个发展重点,本模块将带你:
- 掌握流式处理技术的典型代表 Kafka 的应用实践和背后原理;
- 掌握热门实时计算引擎 Flink 的应用实践和背后原理;
- 从细节中脱身,掌握实时计算系统的工作原理和系统本质。
学习和工作中的痛点:
- 如何才能开发好实时应用,满足业务指标;
- 遇到“抖动”怎么办,如何做好容灾和应用降级;
- 平台如何保障高性能和可靠性;
- 针对实时高的场景,该如何用好实时计算引擎。
通过学习掌握的核心能力:
- 掌握 Kafka 和 Flink 的基本原理;
- 掌握实时应用的开发流程;
- 对实时应用和系统本身进行监控和告警;
- 通过学习实时计算的企业应用实践,能设计自己的实时应用并形成最佳实践。
详细内容:5 课时
- 什么是 Kafka,Kafka 的应用场景与思路;
- Kafka 高性能和可靠性背后的设计原理;
- Kafka API 的使用技巧,如何用 Kafka API 做好程序开发;
- Kafka 的监控、运维和性能优化;
- Flink 的基本原理和架构;
- Flink API 的使用思路,如何用 Flink API 做好程序开发;
- Flink 多应用场景实践,在实践中用好 Flink。
模块七:数据开发体系:ETL、Data Visualization
教学目标:
数据开发体系是大数据领域不可或缺的重要组成部分,涉及的知识点众多,其中最基础且重要的就是 ETL 和数据可视化两个方向,本模块将带你:
- 掌握 ETL 应用实践和选型思路;
- 掌握 ETL的设计原则和运作原理;
- 掌握数据可视化的应用技巧和平台搭建实践;
- 与之前模块融会贯通,掌握大数据应用闭环开发的能力。
学习和工作中的痛点:
- 如何更好地选用和订制化开发 ETL 框架;
- 如何优化调度系统和任务依赖;
- 元数据管理如何设计;
- 数据可视化如何和应用结合;
- 如何简化数据可视化的开发成本;
- 如何通过数据可视化降低数据开发成本。
通过学习掌握的核心能力:
- 掌握 ETL 的调度系统运作原理和任务依赖设计原则;
- 对多个开源调度系统根据自身业务需求进行选型;
- 了解 ETL 中任务模版化的设计和元数据管理技术;
- 掌握如何进行数据可视化展示,结合案例搭建数据可视化平台;
- 学完能胜任完成整个大数据平台的构建闭环。
详细内容:3 课时
- ETL 中调度系统选择,Oozie、Azkaban、Airflow 等调度系统介绍;
- ETL 中任务调度系统设计,定时任务设计以及处理方案;
- 调度系统如何做到 ETL 任务依赖关系自动解析;
- ETL 的任务设计、数据抽取、加载工具的实现;
- ETL 任务模板的实现,元数据设计;
- 数据可视化工具介绍;
- HUE 搭建以及使用;
- 案例:Airbnb 开发的 Superset 架构介绍及其使用案例。
模块八:数据湖,大数据的下一次变革:DeltaLake、Hudi、Iceberg
教学目标:
数据湖技术是最近两年大数据领域的最热门的技术之一,它很有可能改变目前企业对数据的整体规划,也优化了目前数仓体系,本模块将带你:
- 了解数据湖的知识体系,对比掌握数据仓库和数据湖之间的区别;
- 掌握目前三个优秀的数据湖软件:DeltaLake、Hudi、Iceberg 的基本原理和应用实践;
- 掌握技术选型的关键要点,在数据湖开发实践中更好的使用和优化。
学习和工作中的痛点:
- 停留在概念上,不了解数据湖技术的本质;
- 裸用数据湖软件造成的性能下降;
- 对新技术的排斥,滥用和错误使用;
- 无法将前面学习的知识、系统和数据湖技术进行有效结合。
通过学习掌握的核心能力:
- 了解数据湖的本质和数仓的区别;
- 掌握 DeltaLake、Hudi、Iceberg 的基本原理;
- 能合适的选用不同的数据湖软件;
- 能对数据湖软件进行二次开发;
- 能结合 Spark、Flink 和数据湖软件构建数据湖应用。
详细内容:5~10 课时
- 介绍数据湖和数据仓库的本质和区别;
- 分别对 DeltaLake、Hudi、Iceberg 进行架构分析和对比;
- 实践:应用 Spark + DeltaLake 构建数据湖应用;
- 实践:应用 Flink + Hudi/Iceberg 构建数据湖应用;
- DeltaLake 的性能优化和二次开发实践。
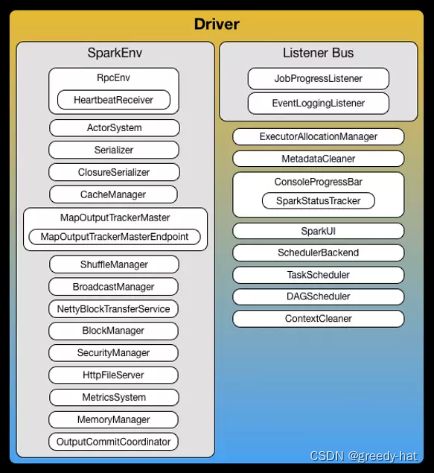
模块九:Hadoop、Spark 核心源码讲解
教学目标:
Hadoop 和 Spark 是整个大数据体系的基石,而源码学习会让我们更深刻地理解它们的底层设计原理,也能提升自己的开发能力和系统架构能力,本模块将:
- 对 Hadoop 和 Spark 的核心源码进行讲解,带你学习如何进行二次开发;
- 对 Hadoop、Spark 进行 Debug,助力你的开发能力得到进阶和突破。
学习和工作中的痛点:
- 渴望学习新项目但面对大量代码不知道从何开始学习;
- 捋不清代码逻辑,总是陷入细节;
- 不知道怎么对开源代码 Debug,不知道怎么贡献社区;
- 不会用 Git,对源码的二次开发不规范。
通过学习掌握的核心能力:
- 了解 Hadoop、Spark 核心源码的结构,能快速定位源码问题;
- 重点理解并掌握 Spark SQL 的代码原理;
- 学会如何使用 Git 进行代码的二次开发;
- 学会如何往社区贡献 Patch,参与社区工作。
详细内容:3 课时
- 介绍 Git 的使用和技巧;
- 获取源代码并准备好代码环境,解决一些依赖问题;
- 对 Hadoop 的代码结构和体系进行介绍,重点模块走读;
- 对 Spark 的代码结构和体系进行介绍,SQL 模块走读;
- 如何往 Hadoop、Spark 开源社区进行 Patch 提交,如何参与社区工作等。
模块十:面试通关:如何成为卓越的大数据开发工程师
教学目标:
大数据领域变化日新月异,新的技术栈层出不穷,所以对大数据开发者的要求不同于传统应用开发或软件开发,它要求开发者具备更卓越的学习能力和钻研精神,本模块将带你:
- 了解大数据工程师必备的硬技能、软实力和成长路径;
- 掌握关于大数据实用的学习方法,以及成长和避坑经验;
- 培养真正的大数据思维,写出更高效可用的代码。
学习和工作中的痛点:
- 信奉“拿来主义”,习惯“复制粘贴”,结果挖了不少坑;
- 缺乏大数据思维,总是错误估计问题规模,代码看似没问题,一上生产环境就崩溃;
- 经常没有学习的方向,不知道下一步需要做什么,缺乏研究精神;
- 容易陷入大数据繁冗的技术栈中,不知道如何定位问题,确定解决思路;
- 缺乏大数据实践经验,不知道该如何在大数据方向的面试中脱颖而出。
通过学习掌握的核心能力:
- 真正的大数据开发思维;定位问题并解决问题的思路;
- 快速研究并掌握新技术的方法论;
- 如何从老技术中获取养分;
- 如何阅读文献资料;
- 如何用理论实际结合的方式解决生产问题。
详细内容:2 课时
- 概览大数据领域的历史、发展历程和未来方向;
- 提炼归纳大数据领域的未来趋势和职业方向;
- 大数据工程师必备的软技能和成长避坑经验;
- 大数据技术思维养成经验分享;
- 如何从会解决大数据问题到会提出问题;
- 如何搜索和阅读文献,如何从论文到实现;
- 面试大数据开发需要的技能树和技巧。


实战项目
项目一:Hadoop 集群云主机搭建和健康管理
实践目标:
大数据平台工程师基本技能,通过云主机的集群搭建能加深对开源大数据组件的认识和理解,了解各个模块的运作原理,掌握基础的同时,了解一些高级的知识实践例如 HA、Federation、RBF 等。
核心要点:
- 分别基于阿里云服务器和 Docker 容器,完成 Hadoop 集群和相关组件的搭建;
- 通过以上搭建实践,了解整个 Hadoop 平台模块之间的关系和作用,通过学习集群的各种指标了解集群的健康度;
- 通过该集群,学习数据平台的流程和企业大数据平台自动化工作;
- 涉及技术:HDFS、MapReduce、YARN、Docker、Hive、Spark、Prometheus。
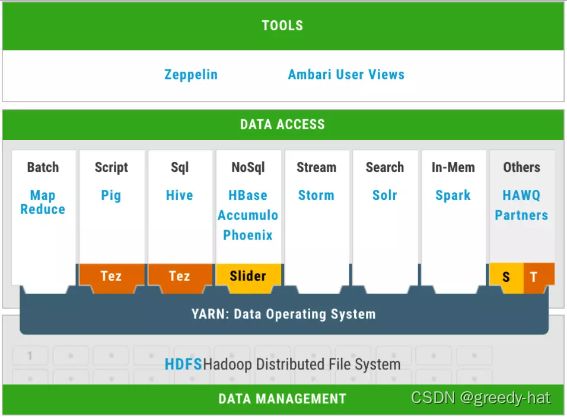
项目二:数据可视化和交互式自助分析平台建设
实践目标:
大数据平台工程师基本技能,学习如何搭建交互式自助分析平台和数据可视化服务,如何提供高可用性高性能的查询服务。
核心要点:
- 完成交互式分析平台的建设;
- 使用 Spark SQL、Presto、Kylin 等 OLAP 引擎构建离线分析平台;
- 使用 Airflow 进行作业流管理;
- 使用 ThriftServer、JDBC 等进行 Session 管理;
- 使用 HUE、Tableau 等搭建数据可视化应用;
- 涉及技术:Presto、ClickHouse、Kylin、Spark SQL、Airflow、Superset、HUE、ThriftServer、HiveServer2。
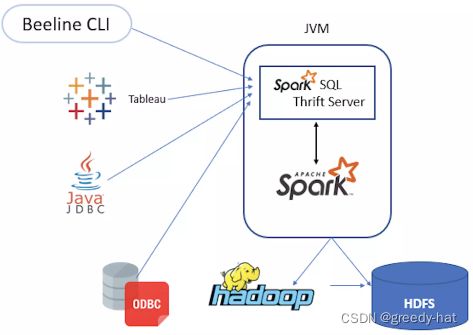
项目三:利用 Spark 对大型电商用户数据进行分析
实践目标:
数据开发和数据分析师利用 Spark 计算引擎,在实践中掌握大数据分析方法。通过 JDBC 方式,学习 SQL 的使用和优化,性能问题的发现和改进等。
核心要点:
- 使用 Kafka、Spark Streaming、Flink、Spark SQL、Hive 等计算引擎对真实的大型电商用户数据进行分析;
- 模拟真实企业在大数据领域的使用场景,通过编写程序或 SQL ,完成相应的数据分析任务。
- 涉及技术:Spark SQL、Hive、JDBC。
项目四:Hadoop、Spark 源码学习
实践目标:
对核心的源码进行讲解,学习如何进行二次开发,对 Hadoop、Spark 进行 Debug,帮助学员对开发能力进行进阶和突破。
核心要点:
- 对 Hadoop、Spark 的核心源码进行学习,着重讲解 Spark SQL 源码的结构;
- 通过学习 Spark SQL 源码结构,引申出数据库体系结构和设计模式,以此为基础学习更多复杂系统,特别是数据系统的底层设计语言;
- 涉及技术:Hadoop、Spark Internals。