Pod控制器(二)Deployment、 DaemonSet、Job、CronJob
目录
1.Deployment控制器
1.1创建Deployment
1.2 更新策略
1.3 升级Deployment
1.4 金丝雀发布
1.5 回滚Deployment控制器下的应用发布
1.6 扩容和缩容
2. DaemonSet控制器
2.1 创建DaemonSet资源对象
2.2 更新DaemonSet对象
3. Job控制器
3.1 创建Job对象
3.2 并行式Job
4. CronJob控制器
4.1 创建CronJob对象
5. 小结
1.Deployment控制器
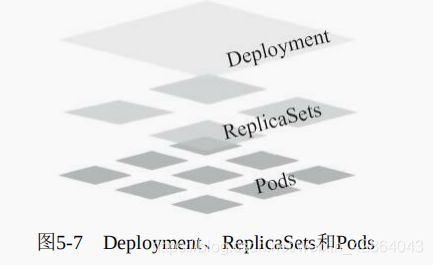
- 回滚:升级操作完成后发现问题时,支持使用回滚机制将应用返回到前一个或由用户指定的历史记录中的版本上。
- 版本记录:对Deployment对象的每一次操作都予以保存,以供后续可能执行的回滚操作使用。
- 暂停和启动:对于每一次升级,都能够随时暂停和启动。
- 多种自动更新方案:一是Recreate,即重建更新机制,全面停止、删除旧有的Pod后用新版本替代;另一个是RollingUpdate,即滚动升级机制,逐步替换旧有的Pod至新的版本
1.1创建Deployment
Deployment是标准的Kubernetes API资源,它建构于ReplicaSet资源之上,于是其spec字段中嵌套使用的字段包含了ReplicaSet控制器支持的replicas、selector、template和minReadySeconds,它也正是利用这些信息完成了其二级资源ReplicaSet对象的创建。下面是一个Deployment控制器资源的配置清单示例:
[root@master chapter5]# vim myapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- containerPort: 80
name: http
[root@master chapter5]# kubectl apply -f myapp-deploy.yaml --record
deployment.apps/myapp-deploy created
[root@master ~]# kubectl get deployment myapp-deploy
NAME READY UP-TO-DATE AVAILABLE AGE
myapp-deploy 3/3 3 3 15h
[root@master ~]# kubectl get replicasets -l app=myapp
NAME DESIRED CURRENT READY AGE
myapp-deploy-7ffb5fd5ff 3 3 3 16h
[root@master ~]# kubectl get pods -l app=myapp
NAME READY STATUS RESTARTS AGE
myapp-deploy-7ffb5fd5ff-f9d6s 1/1 Running 0 16h
myapp-deploy-7ffb5fd5ff-fgh9z 1/1 Running 0 16h
myapp-deploy-7ffb5fd5ff-wc526 1/1 Running 0 16h
1.2 更新策略
如前所述,ReplicaSet控制器的应用更新需要手动分成多步并以特定的次序进行,过程繁杂且容易出错,而Deployment却只需要由用户指定在Pod模板中要改动的内容,例如容器镜像文件的版本,余下的步骤可交由其自动完成。同样,更新应用程序的规模也只需要修改期望的副本数量,余下的事情交给Deployment控制器即可。
[root@master ~]# kubectl describe deployments myapp-deploy
Name: myapp-deploy
Namespace: default
CreationTimestamp: Mon, 16 Nov 2020 18:32:37 +0800
Labels:
Annotations: deployment.kubernetes.io/revision: 1
kubernetes.io/change-cause: kubectl apply --filename=myapp-deploy.yaml --record=true
Selector: app=myapp
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=myapp
Containers:
myapp:
Image: ikubernetes/myapp:v1
Port: 80/TCP
Host Port: 0/TCP
Environment:
Mounts:
Volumes:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets:
NewReplicaSet: myapp-deploy-7ffb5fd5ff (3/3 replicas created)
Events:
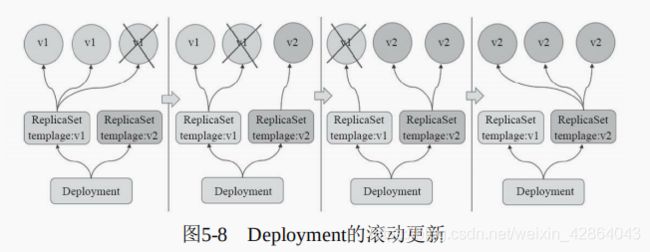
Deployment控制器支持两种更新策略:滚动更新(rolling update)和重新创建(recreate),默认为滚动更新。重新创建更新类似于前文中ReplicaSet的第一种更新方式,即首先删除现有的Pod对象,而后由控制器基于新模板重新创建出新版本资源对象。通常,只应该在应用的新旧版本不兼容(如依赖的后端数据库的schema不同且无法兼容)时运行时才会使用recreate策略,因为它会导致应用替换期间暂时不可用,好处在于它不存在中间状态,用户访问到的要么是应用的新版本,要么是旧版本。
滚动升级是默认的更新策略,它在删除一部分旧版本Pod资源的同时,补充创建一部分新版本的Pod对象进行应用升级,其优势是升级期 间,容器中应用提供的服务不会中断,但要求应用程序能够应对新旧版本同时工作的情形,例如新旧版本兼容同一个数据库方案等。不过,更新操作期间,不同客户端得到的响应内容可能会来自不同版本的应用。
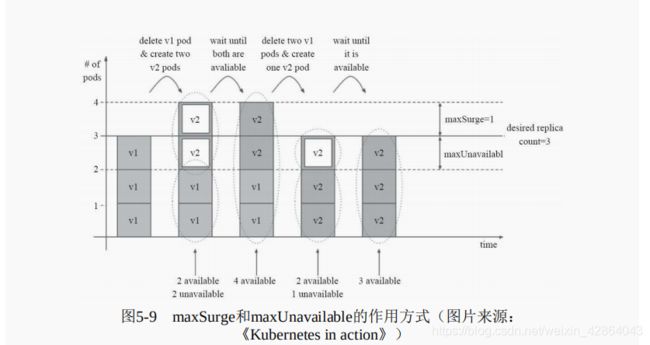
- maxSurge:指定升级期间存在的总Pod对象数量最多可超出期望值的个数,其值可以是0或正整数,也可以是一个期望值的百分比;如,如果期望值为3,当前的属性值为1,则表示Pod对象的总数不能超过4个
- maxUnavailable:升级期间正常可用的Pod副本数(包括新旧版本)最多不能低于期望数值的个数,其值可以是0或正整数,也可以是一个期望值的百分比;默认值为1,该值意味着如果期望值是3,则升级期间至少要有两个Pod对象处于正常提供服务的状态。
1.3 升级Deployment
[root@master ~]# kubectl patch deployments myapp-deploy -p '{"spec":{"minReadySeconds":5}}'
deployment.apps/myapp-deploy patched
[root@master ~]# kubectl set image deployments myapp-deploy myapp=ikubernetes/myapp:v2
deployment.apps/myapp-deploy image updated
[root@master ~]# kubectl rollout status deployments myapp-deploy
Waiting for deployment "myapp-deploy" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "myapp-deploy" rollout to finish: 1 old replicas are pending termination...
deployment "myapp-deploy" successfully rolled out
[root@master ~]# kubectl get deployments myapp-deploy --watch
NAME READY UP-TO-DATE AVAILABLE AGE
myapp-deploy 3/3 3 3 20h
[root@master ~]# kubectl get replicasets -l app=myapp
NAME DESIRED CURRENT READY AGE
myapp-deploy-7ffb5fd5ff 0 0 0 20h
myapp-deploy-d79f57d9d 3 3 3 24m
[root@master ~]# kubectl get pods -l app=myapp
NAME READY STATUS RESTARTS AGE
myapp-deploy-d79f57d9d-5ppns 1/1 Running 0 26m
myapp-deploy-d79f57d9d-vczft 1/1 Running 0 26m
myapp-deploy-d79f57d9d-w4xg6 1/1 Running 0 26m
[root@master ~]# curl $(kubectl get pods myapp-deploy-d79f57d9d-5ppns -o go-template={{.status.podIP}})
Hello MyApp | Version: v2 | Pod Name
1.4 金丝雀发布
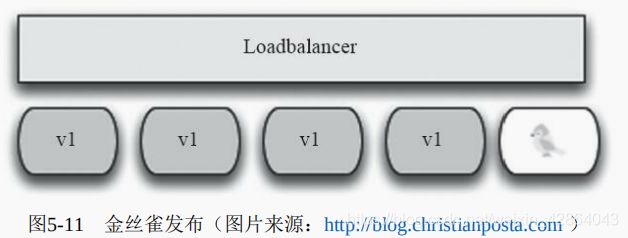
[root@master ~]# kubectl patch deployments myapp-deploy -p '{"spec": {"strategy":{"rollingUpdate": {"maxSurge": 1, "maxUnavailable": 0}}}}'
deployment.apps/myapp-deploy patched
[root@master ~]# kubectl set image deployments myapp-deploy myapp=ikubernetes/myapp:v3 && kubectl rollout pause deployments myapp-deploy
deployment.apps/myapp-deploy image updated
deployment.apps/myapp-deploy paused
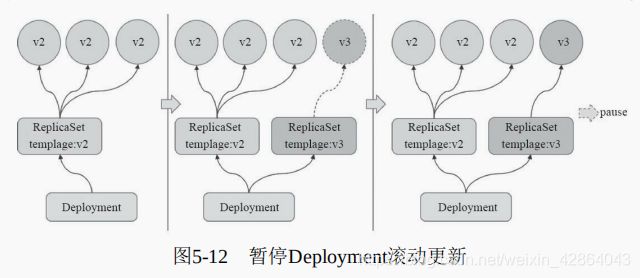
[root@master ~]# kubectl rollout status deployments myapp-deploy
Waiting for deployment "myapp-deploy" rollout to finish: 1 out of 3 new replicas have been updated...
[root@master ~]# kubectl rollout resume deployments myapp-deploy
deployment.apps/myapp-deploy resumed
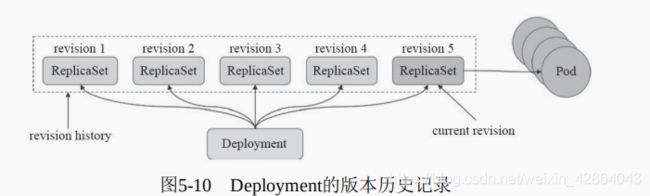
1.5 回滚Deployment控制器下的应用发布
[root@master ~]# kubectl rollout undo deployments myapp-deploy
deployment.apps/myapp-deploy rolled back
[root@master ~]# kubectl rollout history deployments myapp-deploy
deployment.apps/myapp-deploy
REVISION CHANGE-CAUSE
1 kubectl apply --filename=myapp-deploy.yaml --record=true
3 kubectl apply --filename=myapp-deploy.yaml --record=true
4 kubectl apply --filename=myapp-deploy.yaml --record=true
[root@master ~]# kubectl rollout undo deployments myapp-deploy --to-revision=3
deployment.apps/myapp-deploy rolled back
1.6 扩容和缩容
2. DaemonSet控制器
DaemonSet是Pod控制器的又一种实现,用于在集群中的全部节点上同时运行一份指定的Pod资源副本,后续新加入集群的工作节点也会自动创建一个相关的Pod对象,当从集群移除节点时,此类Pod对象也将被自动回收而无须重建。管理员也可以使用节点选择器及节点标签指定仅在部分具有特定特征的节点上运行指定的Pod对象。
- 运行集群存储的守护进程,如在各个节点上运行glusterd或ceph。
- 在各个节点上运行日志收集守护进程,如fluentd和logstash。
- 在各个节点上运行监控系统的代理守护进程,如Prometheus NodeExporter、collectd、Datadog agent、New Relic agent或Ganglia gmond等。
2.1 创建DaemonSet资源对象
[root@master chapter5]# vim filebeat-ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-ds
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
name: filebeat
spec:
containers:
- name: filebeat
image: ikubernetes/filebeat:5.6.5-alpine
env:
- name: REDIS_HOST
value: db.ikubernetes.io:6379
- name: LOG_LEVEL
value: info
[root@master chapter5]# kubectl apply -f filebeat-ds.yaml
daemonset.apps/filebeat-ds created
[root@master chapter5]# kubectl describe daemonsets filebeat-ds
Name: filebeat-ds
Selector: app=filebeat
Node-Selector:
Labels: app=filebeat
Annotations: deprecated.daemonset.template.generation: 1
Desired Number of Nodes Scheduled: 2
Current Number of Nodes Scheduled: 2
Number of Nodes Scheduled with Up-to-date Pods: 2
Number of Nodes Scheduled with Available Pods: 2
Number of Nodes Misscheduled: 0
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=filebeat
Containers:
filebeat:
Image: ikubernetes/filebeat:5.6.5-alpine
Port:
Host Port:
Environment:
REDIS_HOST: db.ikubernetes.io:6379
LOG_LEVEL: info
Mounts:
Volumes:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 3m51s daemonset-controller Created pod: filebeat-ds-pqmmk
Normal SuccessfulCreate 3m51s daemonset-controller Created pod: filebeat-ds-q6vxt
[root@master chapter5]# kubectl get pods -l app=filebeat
NAME READY STATUS RESTARTS AGE
filebeat-ds-pqmmk 1/1 Running 0 7m44s
filebeat-ds-q6vxt 1/1 Running 0 7m44s[root@master chapter5]# kubectl get pods -l app=filebeat -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
filebeat-ds-pqmmk 1/1 Running 0 14m 10.244.1.20 node1
filebeat-ds-q6vxt 1/1 Running 0 14m 10.244.2.25 node2
2.2 更新DaemonSet对象
DaemonSet自Kubernetes 1.6版本起也开始支持更新机制,相关配置定义在spec.update-Strategy嵌套字段中。目前,它支持RollingUpdate(滚动更新)和OnDelete(删除时更新)两种更新策略,滚动更新为默认的更新策略,工作逻辑类似于Deployment控制,不过仅 支持使用maxUnavailabe属性定义最大不可用Pod资源副本数(默认值为1),而删除时更新的方式则是在删除相应节点的Pod资源后重建并更新为新版本。
[root@master ~]# kubectl set image daemonsets filebeat-ds filebeat=ikubernetes/filebeat:5.6.6-alpine
daemonset.apps/filebeat-ds image updated
[root@master ~]# kubectl describe daemonsets filebeat-ds
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 27m daemonset-controller Created pod: filebeat-ds-pqmmk
Normal SuccessfulCreate 27m daemonset-controller Created pod: filebeat-ds-q6vxt
Normal SuccessfulDelete 4m44s daemonset-controller Deleted pod: filebeat-ds-pqmmk
Normal SuccessfulCreate 4m42s daemonset-controller Created pod: filebeat-ds-xdp5p
Normal SuccessfulDelete 2m40s daemonset-controller Deleted pod: filebeat-ds-xdp5p
Normal SuccessfulCreate 2m38s daemonset-controller Created pod: filebeat-ds-d6x2m
Normal SuccessfulDelete 2m20s daemonset-controller Deleted pod: filebeat-ds-q6vxt
Normal SuccessfulCreate 2m18s daemonset-controller Created pod: filebeat-ds-jw5p2或者也可以在执行kubectl set image daemonsets filebeat-ds filebeat=ikubernetes/filebeat:5.6.6-alpine命令时重新打开一个终端查看镜像得更新情况
[root@master chapter5]# kubectl get pods -l app=filebeat -w
NAME READY STATUS RESTARTS AGE
filebeat-ds-pqmmk 1/1 Running 0 21m
filebeat-ds-q6vxt 1/1 Running 0 21m
filebeat-ds-pqmmk 1/1 Terminating 0 22m
filebeat-ds-pqmmk 0/1 Terminating 0 22m
filebeat-ds-pqmmk 0/1 Terminating 0 22m
filebeat-ds-pqmmk 0/1 Terminating 0 22m
filebeat-ds-xdp5p 0/1 Pending 0 0s
filebeat-ds-xdp5p 0/1 Pending 0 0s
filebeat-ds-xdp5p 0/1 ContainerCreating 0 0s
filebeat-ds-xdp5p 0/1 ErrImagePull 0 14s
filebeat-ds-xdp5p 0/1 ImagePullBackOff 0 26s
filebeat-ds-xdp5p 0/1 ErrImagePull 0 50s
filebeat-ds-xdp5p 0/1 ImagePullBackOff 0 62s
filebeat-ds-xdp5p 0/1 ErrImagePull 0 82s
filebeat-ds-xdp5p 0/1 ImagePullBackOff 0 95s
filebeat-ds-xdp5p 0/1 Terminating 0 2m2s
filebeat-ds-xdp5p 0/1 Terminating 0 2m4s
filebeat-ds-xdp5p 0/1 Terminating 0 2m4s
filebeat-ds-d6x2m 0/1 Pending 0 0s
filebeat-ds-d6x2m 0/1 Pending 0 0s
filebeat-ds-d6x2m 0/1 ContainerCreating 0 0s
filebeat-ds-d6x2m 1/1 Running 0 18s
filebeat-ds-q6vxt 1/1 Terminating 0 24m
filebeat-ds-q6vxt 0/1 Terminating 0 24m
filebeat-ds-q6vxt 0/1 Terminating 0 25m
filebeat-ds-q6vxt 0/1 Terminating 0 25m
filebeat-ds-jw5p2 0/1 Pending 0 0s
filebeat-ds-jw5p2 0/1 Pending 0 0s
filebeat-ds-jw5p2 0/1 ContainerCreating 0 0s
filebeat-ds-jw5p2 1/1 Running 0 18s
[root@master ~]# kubectl get ds -o wide
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR
filebeat-ds 2 2 2 2 231m filebeat ikubernetes/filebeat:5.6.6-alpine app=filebeat
3. Job控制器
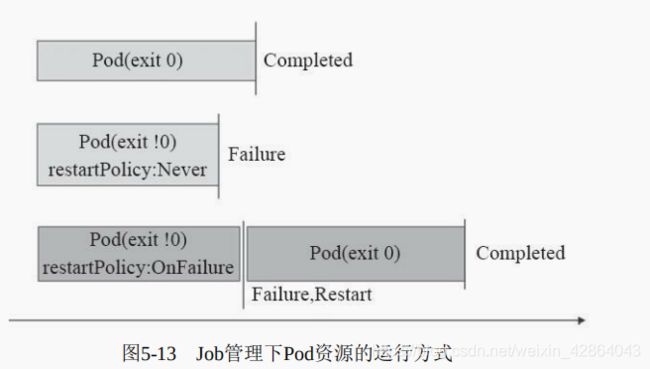
- 单工作队列(work queue)的串行式Job:即以多个一次性的作业方式串行执行多次作业,直至满足期望的次数,如图5-14所示;这次Job也可以理解为并行度为1的作业执行方式,在某个时刻仅存在一个Pod资源对象。

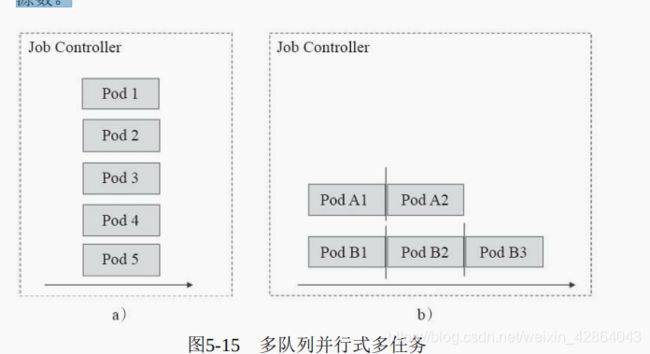
- 多工作队列的并行式Job:这种方式可以设置工作队列数,即作业数,每个队列仅负责运行一个作业,如图5-15a所示;也可以用有限的工作队列运行较多的作业,即工作队列数少于总作业数,相当于运行多个串行作业队列。如图5-15b所示,工作队列数即为同时可运行的Pod资源数。
3.1 创建Job对象
[root@master chapter5]# vim job-example.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-example
spec:
template:
metadata:
labels:
app: myjob
spec:
containers:
- name: myjob
image: alpine
command: ["/bin/sh", "-c", "sleep 120"]
restartPolicy: Never
[root@master chapter5]# kubectl apply -f job-example.yaml
job.batch/job-example created[root@master ~]# kubectl get jobs job-example
NAME COMPLETIONS DURATION AGE
job-example 1/1 2m6s 2m12s
[root@master ~]# kubectl get pods -l job-name=job-example
NAME READY STATUS RESTARTS AGE
job-example-hm6lg 0/1 Completed 0 10m
3.2 并行式Job
[root@master chapter5]# vim job-multi.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-multi
spec:
completions: 5
parallelism: 2 #两路并行
template:
metadata:
labels:
app: myjob
spec:
containers:
- name: myjob
image: alpine
command: ["/bin/sh", "-c", "sleep 20"]
restartPolicy: Never
[root@master chapter5]# kubectl apply -f job-multi.yaml
job.batch/job-multi created
[root@master ~]# kubectl get pods -l job-name=job-multi -w
NAME READY STATUS RESTARTS AGE
job-multi-76vbf 1/1 Running 0 8s
job-multi-h9nmh 0/1 ContainerCreating 0 8s
job-multi-h9nmh 1/1 Running 0 8s
job-multi-76vbf 0/1 Completed 0 25s
job-multi-sd6ql 0/1 Pending 0 0s
job-multi-sd6ql 0/1 Pending 0 0s
job-multi-sd6ql 0/1 ContainerCreating 0 0s
job-multi-h9nmh 0/1 Completed 0 28s
job-multi-rl2n4 0/1 Pending 0 0s
job-multi-rl2n4 0/1 Pending 0 0s
job-multi-rl2n4 0/1 ContainerCreating 0 0s
job-multi-sd6ql 1/1 Running 0 5s
job-multi-rl2n4 1/1 Running 0 10s
spec:
completions: 5
parallelism: 2 #两路并行
4. CronJob控制器
- 在未来某时间点运行作业一次。
- 在指定的时间点重复运行作业。
4.1 创建CronJob对象
- jobTemplate:Job控制器模板,用于为CronJob控制器生成Job对象;必选字段。
- jobTemplate:Job控制器模板,用于为CronJob控制器生成Job对象;必选字段。
- concurrencyPolicy
:并发执行策略,可用值有“Allow”(允许)、“Forbid”(禁止)和“Replace”(替换),用于定义前一次作业运 行尚未完成时是否以及如何运行后一次的作业。
- failedJobHistoryLimit
:为失败的任务执行保留的历史记录数,默认为1。
- successfulJobsHistoryLimit
:为成功的任务执行保留的历史记录数,默认为3。
- startingDeadlineSeconds
:因各种原因缺乏执行作业的时间点所导致的启动作业错误的超时时长,会被记入错误历史记录。
- suspend
:是否挂起后续的任务执行,默认为false,对运行中的作业不会产生影响。
[root@master chapter5]# vim cronjob-example.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cronjob-example
labels:
app: mycronjob
spec:
schedule: "*/2 * * * *"
jobTemplate:
metadata:
labels:
app: mycronjob-jobs
spec:
parallelism: 2
template:
spec:
containers:
- name: myjob
image: alpine
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster; sleep 10
restartPolicy: OnFailure
[root@master chapter5]# kubectl apply -f cronjob-example.yaml
cronjob.batch/cronjob-example created
[root@master chapter5]# kubectl get cronjobs cronjob-example
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob-example */2 * * * * False 015s
5. 小结
- 工作负载类型的控制器根据业务需求管控Pod资源的生命周期。
- ReplicaSet可以确保守护进程型的Pod资源始终具有精确的、处于运行状态的副本数量,并支持Pod规模的伸缩机制;它是新一代的ReplicationController控制器,不过用户通常不应该直接使用ReplicaSet,而是要使用Deployment。
- Deployment是建构在ReplicaSet上的更加抽象的工作负载型控制器,支持多种更新策略及发布机制。
- Job控制器能够控制相应的作业任务得以正常完成并退出,支持并行式多任务。
- CronJob控制器用于控制周期性作业任务,其功能类似于Linux操作系统上的Crontab。
- PodDisruptionBudget资源对象为Kubernetes系统上的容器化应用提供了高可用能力。
#kubectl describe node node1命令参数得解释
[root@master chapter5]# kubectl describe node node1
Name: node1
Roles:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=node1
kubernetes.io/os=linux
Annotations: flannel.alpha.coreos.com/backend-data: {"VtepMAC":"8a:5b:b5:cc:b2:0d"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 172.21.96.13
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Thu, 05 Nov 2020 17:46:59 +0800
Taints:
Unschedulable: false
Lease:
HolderIdentity: node1
AcquireTime:
RenewTime: Wed, 18 Nov 2020 15:07:34 +0800
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable #网络压力 False Thu, 05 Nov 2020 17:55:42 +0800 Thu, 05 Nov 2020 17:55:42 +0800 FlannelIsUp Flannel is running on this node
MemoryPressure #内存压力 False Wed, 18 Nov 2020 15:05:29 +0800 Thu, 05 Nov 2020 17:46:59 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure #磁盘压力 False Wed, 18 Nov 2020 15:05:29 +0800 Thu, 05 Nov 2020 17:46:59 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure #PID压力 False Wed, 18 Nov 2020 15:05:29 +0800 Thu, 05 Nov 2020 17:46:59 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready #就绪 True Wed, 18 Nov 2020 15:05:29 +0800 Thu, 05 Nov 2020 17:55:51 +0800 KubeletReady kubelet is posting ready status
Addresses: #显示地址
InternalIP: 172.21.96.13 #本地私网地址
Hostname: node1 #节点名称
Capacity: #容量
cpu: 2 #当前节点有几个cpu
ephemeral-storage: 51474024Ki #有多少个临时存储空间可以用
hugepages-1Gi: 0 #最大内存页 所谓内存页就是Linux节点在使用时一般时按照业面也使用得一般是4K 大于4K得就是页
hugepages-2Mi: 0
memory: 3915456Ki #一共有多大
pods: 110 #最多可容纳多少个pod
Allocatable: #可分配得资源
cpu: 2 #可分配得CPU
ephemeral-storage: 47438460440
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3813056Ki
pods: 110
System Info: #
Machine ID: 735fbcd856b697dbc8d6deb1a11dd712
System UUID: AF0CC1A9-0B2D-4791-8DBE-233B5F9A610C
Boot ID: 1d136904-0fee-456e-8882-8182c4355a2f
Kernel Version: 3.10.0-693.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://19.3.13
Kubelet Version: v1.19.3
Kube-Proxy Version: v1.19.3
PodCIDR: 10.244.1.0/24
PodCIDRs: 10.244.1.0/24
Non-terminated Pods: (14 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default filebeat-ds-d6x2m 0 (0%) 0 (0%) 0 (0%) 0 (0%) 4h8m
default liveness-http 0 (0%) 0 (0%) 0 (0%) 0 (0%) 7d3h
default myapp-deploy-77dcc456d9-5hpg7 0 (0%) 0 (0%) 0 (0%) 0 (0%) 23h
default myapp-pod 0 (0%) 0 (0%) 0 (0%) 0 (0%) 7d
default rs-example-cwxgh 0 (0%) 0 (0%) 0 (0%) 0 (0%) 46h
default rs-example-jdp8k 0 (0%) 0 (0%) 0 (0%) 0 (0%) 45h
default rs-example-qnvjt 0 (0%) 0 (0%) 0 (0%) 0 (0%) 45h
develop pod-demo 0 (0%) 0 (0%) 0 (0%) 0 (0%) 9d
kube-system coredns-6c76c8bb89-425s2 100m (5%) 0 (0%) 70Mi (1%) 170Mi (4%) 12d
kube-system kube-flannel-ds-pb69v 100m (5%) 100m (5%) 50Mi (1%) 50Mi (1%) 12d
kube-system kube-proxy-2lx79 0 (0%) 0 (0%) 0 (0%) 0 (0%) 12d
prod myapp-rs-428nc 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d3h
prod myapp-rs-4nn8r 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d3h
prod pod-demo-2 0 (0%) 0 (0%) 0 (0%) 0 (0%) 8d
Allocated resources: #已分配得资源
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 200m (10%) 100m (5%) #cpu
memory 120Mi (3%) 220Mi (5%) #内存
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: