大型电商架构亿级流量电商详情页系统--实战 缓存同步,热点key统计 降级
35
我们之前的三十讲,主要是在讲解redis如何支撑海量数据、高并发读写、高可用服务的架构,redis架构
redis架构,在我们的真正类似商品详情页读高并发的系统中,redis就是底层的缓存存储的支持
从这一讲开始,我们正式开始做业务系统的开发
亿级流量以上的电商网站的商品详情页的系统,商品详情页系统,大量的业务,十几个人做一两年,堆出来复杂的业务系统
几十个小时的课程,讲解复杂的业务
把整体的架构给大家讲解清楚,然后浓缩和精炼里面的业务,提取部分业务,做一些简化,把整个详情页系统的流程跑出来
架构,骨架,有少量的业务,血和肉,把整个项目串起来,在业务背景下,去学习架构
讲解商品详情页系统,缓存架构,90%大量的业务代码(没有什么技术含量),10%的最优技术含量的就是架构,上亿流量,每秒QPS几万,上十万的,读并发
读并发,缓存架构
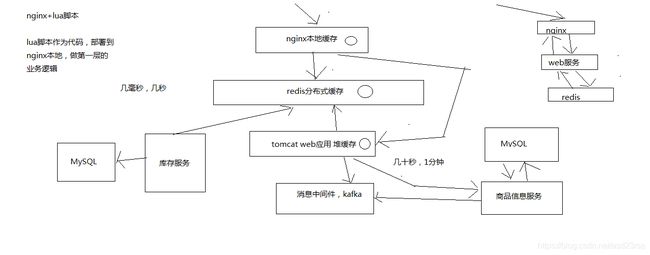
1、上亿流量的商品详情页系统的多级缓存架构
很多人以为,做个缓存,其实就是用一下redis,访问一下,就可以了,简单的缓存
做复杂的缓存,支撑电商复杂的场景下的高并发的缓存,遇到的问题,非常非常之多,绝对不是说简单的访问一下redsi就可以了
采用三级缓存:nginx本地缓存+redis分布式缓存+tomcat堆缓存的多级缓存架构
时效性要求非常高的数据:库存
一般来说,显示的库存,都是时效性要求会相对高一些,因为随着商品的不断的交易,库存会不断的变化
当然,我们就希望当库存变化的时候,尽可能更快将库存显示到页面上去,而不是说等了很长时间,库存才反应到页面上去
时效性要求不高的数据:商品的基本信息(名称、颜色、版本、规格参数,等等)
时效性要求不高的数据,就还好,比如说你现在改变了商品的名称,稍微晚个几分钟反应到商品页面上,也还能接受
商品价格/库存等时效性要求高的数据,而且种类较少,采取相关的服务系统每次发生了变更的时候,直接采取数据库和redis缓存双写的方案,这样缓存的时效性最高
商品基本信息等时效性不高的数据,而且种类繁多,来自多种不同的系统,采取MQ异步通知的方式,写一个数据生产服务,监听MQ消息,然后异步拉取服务的数据,更新tomcat jvm缓存+redis缓存
nginx+lua脚本做页面动态生成的工作,每次请求过来,优先从nginx本地缓存中提取各种数据,结合页面模板,生成需要的页面
如果nginx本地缓存过期了,那么就从nginx到redis中去拉取数据,更新到nginx本地
如果redis中也被LRU算法清理掉了,那么就从nginx走http接口到后端的服务中拉取数据,数据生产服务中,现在本地tomcat里的jvm堆缓存中找,ehcache,如果也被LRU清理掉了,那么就重新发送请求到源头的服务中去拉取数据,然后再次更新tomcat堆内存缓存+redis缓存,并返回数据给nginx,nginx缓存到本地
图种右上角 耗费多次请求链路,nginx到tomcat,tomcat到redis来回
2、多级缓存架构中每一层的意义
nginx本地缓存,抗的是热数据的高并发访问,一般来说,商品的购买总是有热点的,比如每天购买iphone、nike、海尔等知名品牌的东西的人,总是比较多的
这些热数据,利用nginx本地缓存,由于经常被访问,所以可以被锁定在nginx的本地缓存内
大量的热数据的访问,就是经常会访问的那些数据,就会被保留在nginx本地缓存内,那么对这些热数据的大量访问,就直接走nginx就可以了
那么大量的访问,直接就可以走到nginx就行了,不需要走后续的各种网络开销了
redis分布式大规模缓存,抗的是很高的离散访问,支撑海量的数据,高并发的访问,高可用的服务
redis缓存最大量的数据,最完整的数据和缓存,1T+数据; 支撑高并发的访问,QPS最高到几十万; 可用性,非常好,提供非常稳定的服务
nginx本地内存有限,也就能cache住部分热数据,除了各种iphone、nike等热数据,其他相对不那么热的数据,可能流量会经常走到redis那里
利用redis cluster的多master写入,横向扩容,1T+以上海量数据支持,几十万的读写QPS,99.99%高可用性,那么就可以抗住大量的离散访问请求
tomcat jvm堆内存缓存,主要是抗redis大规模灾难的,如果redis出现了大规模的宕机,导致nginx大量流量直接涌入数据生产服务,那么最后的tomcat堆内存缓存至少可以再抗一下,不至于让数据库直接裸奔
同时tomcat jvm堆内存缓存,也可以抗住redis没有cache住的最后那少量的部分缓存
36
最经典的缓存+数据库读写的模式,cache aside pattern
1、Cache Aside Pattern
(1)读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应
(2)更新的时候,先删除缓存,然后再更新数据库
2、为什么是删除缓存,而不是更新缓存呢?
原因很简单,很多时候,复杂点的缓存的场景,因为缓存有的时候,不简单是数据库中直接取出来的值
商品详情页的系统,修改库存,只是修改了某个表的某些字段,但是要真正把这个影响的最终的库存计算出来,可能还需要从其他表查询一些数据,然后进行一些复杂的运算,才能最终计算出
现在最新的库存是多少,然后才能将库存更新到缓存中去
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据,并进行运算,才能计算出缓存最新的值的
更新缓存的代价是很高的
是不是说,每次修改数据库的时候,都一定要将其对应的缓存去跟新一份?也许有的场景是这样的,但是对于比较复杂的缓存数据计算的场景,就不是这样了
如果你频繁修改一个缓存涉及的多个表,那么这个缓存会被频繁的更新,频繁的更新缓存
但是问题在于,这个缓存到底会不会被频繁访问到???
举个例子,一个缓存涉及的表的字段,在1分钟内就修改了20次,或者是100次,那么缓存跟新20次,100次; 但是这个缓存在1分钟内就被读取了1次,有大量的冷数据
28法则,黄金法则,20%的数据,占用了80%的访问量
实际上,如果你只是删除缓存的话,那么1分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低
每次数据过来,就只是删除缓存,然后修改数据库,如果这个缓存,在1分钟内只是被访问了1次,那么只有那1次,缓存是要被重新计算的,用缓存才去算缓存
其实删除缓存,而不是更新缓存,就是一个lazy计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算
mybatis,hibernate,懒加载,思想
查询一个部门,部门带了一个员工的list,没有必要说每次查询部门,都里面的1000个员工的数据也同时查出来啊
80%的情况,查这个部门,就只是要访问这个部门的信息就可以了
先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询1000个员工
37
马上开始去开发业务系统
从哪一步开始做,从比较简单的那一块开始做,实时性要求比较高的那块数据的缓存去做
实时性比较高的数据缓存,选择的就是库存的服务
库存可能会修改,每次修改都要去更新这个缓存数据; 每次库存的数据,在缓存中一旦过期,或者是被清理掉了,前端的nginx服务都会发送请求给库存服务,去获取相应的数据
库存这一块,写数据库的时候,直接更新redis缓存
实际上没有这么的简单,这里,其实就涉及到了一个问题,数据库与缓存双写,数据不一致的问题
围绕和结合实时性较高的库存服务,把数据库与缓存双写不一致问题以及其解决方案,给大家讲解一下
数据库与缓存双写不一致,很常见的问题,大型的缓存架构中,第一个解决方案
大型的缓存架构全部讲解完了以后,整套架构是非常复杂,架构可以应对各种各样奇葩和极端的情况
也有一种可能,不是说,来讲课的就是超人,万能的
讲课,就跟写书一样,很可能会写错,也可能有些方案里的一些地方,我没考虑到
也可能说,有些方案只是适合某些场景,在某些场景下,可能需要你进行方案的优化和调整才能适用于你自己的项目
大家觉得对这些方案有什么疑问或者见解,都可以找我,沟通一下
如果的确我觉得是我讲解的不对,或者有些地方考虑不周,那么我可以在视频里补录,更新到网站上面去
多多包涵
1、最初级的缓存不一致问题以及解决方案
问题:先修改数据库,再删除缓存,如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据出现不一致
解决思路
先删除缓存,再修改数据库,如果删除缓存成功了,如果修改数据库失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致
因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中
2、比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改
一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中
数据变更的程序完成了数据库的修改
完了,数据库和缓存中的数据不一样了。。。。
3、为什么上亿流量高并发场景下,缓存会出现这个问题?
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题
其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就1万次,那么很少的情况下,会出现刚才描述的那种不一致的场景
但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况
高并发了以后,问题是很多的
4、数据库与缓存更新与读取操作进行异步串行化(工程eshop-inventory)
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个jvm内部的队列中
读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个jvm内部的队列中
一个队列对应一个工作线程
每个工作线程串行拿到对应的操作,然后一条一条的执行
这样的话,一个数据变更的操作,先执行,删除缓存,然后再去更新数据库,但是还没完成更新
此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回; 如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值
5、高并发的场景下,该解决方案要注意的问题
(1)读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回
该解决方案,最大的风险点在于说,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库
务必通过一些模拟真实的测试,看看更新数据的频繁是怎样的
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作
如果一个内存队列里居然会挤压100个商品的库存修改操作,每隔库存修改操作要耗费10ms区完成,那么最后一个商品的读请求,可能等待10 * 100 = 1000ms = 1s后,才能得到数据
这个时候就导致读请求的长时阻塞
一定要做根据实际业务系统的运行情况,去进行一些压力测试,和模拟线上环境,去看看最繁忙的时候,内存队列可能会挤压多少更新操作,可能会导致最后一个更新操作对应的读请求,会hang多少时间,如果读请求在200ms返回,如果你计算过后,哪怕是最繁忙的时候,积压10个更新操作,最多等待200ms,那还可以的
如果一个内存队列可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少
其实根据之前的项目经验,一般来说数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的
针对读高并发,读缓存架构的项目,一般写请求相对读来说,是非常非常少的,每秒的QPS能到几百就不错了
一秒,500的写操作,5份,每200ms,就100个写操作
单机器,20个内存队列,每个内存队列,可能就积压5个写操作,每个写操作性能测试后,一般在20ms左右就完成
那么针对每个内存队列中的数据的读请求,也就最多hang一会儿,200ms以内肯定能返回了
写QPS扩大10倍,但是经过刚才的测算,就知道,单机支撑写QPS几百没问题,那么就扩容机器,扩容10倍的机器,10台机器,每个机器20个队列,200个队列
大部分的情况下,应该是这样的,大量的读请求过来,都是直接走缓存取到数据的
少量情况下,可能遇到读跟数据更新冲突的情况,如上所述,那么此时更新操作如果先入队列,之后可能会瞬间来了对这个数据大量的读请求,但是因为做了去重的优化,所以也就一个更新缓存的操作跟在它后面
等数据更新完了,读请求触发的缓存更新操作也完成,然后临时等待的读请求全部可以读到缓存中的数据
(2)读请求并发量过高
这里还必须做好压力测试,确保恰巧碰上上述情况的时候,还有一个风险,就是突然间大量读请求会在几十毫秒的延时hang在服务上,看服务能不能抗的住,需要多少机器才能抗住最大的极限情况的峰值
但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大
按1:99的比例计算读和写的请求,每秒5万的读QPS,可能只有500次更新操作
如果一秒有500的写QPS,那么要测算好,可能写操作影响的数据有500条,这500条数据在缓存中失效后,可能导致多少读请求,发送读请求到库存服务来,要求更新缓存
一般来说,1:1,1:2,1:3,每秒钟有1000个读请求,会hang在库存服务上,每个读请求最多hang多少时间,200ms就会返回
在同一时间最多hang住的可能也就是单机200个读请求,同时hang住
单机hang200个读请求,还是ok的
1:20,每秒更新500条数据,这500秒数据对应的读请求,会有20 * 500 = 1万
1万个读请求全部hang在库存服务上,就死定了
(3)多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过nginx服务器路由到相同的服务实例上
(4)热点商品的路由问题,导致请求的倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能造成某台机器的压力过大
就是说,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是特别大
但是的确可能某些机器的负载会高一些
38 安装数据库
后面写的各种代码,还是要基于mysql去做一些开发的,因为缓存的底层的数据存储肯定是数据库
mysql数据库,还是要部署一下的
eshop-cache04
先用yum安装mysql server
yum install -y mysql-server
service mysqld start
chkconfig mysqld on
yum install -y mysql-connector-java
39
1、pom.xml
maven下载这些依赖的时候,会非常非常的慢,根据不同人的网络环境,也不一样
你就在eclipse里面,观察每个依赖的下载的情况
如果说觉得下载的很慢,就是卡在一个地方,好长时间不能下载,进度条都不动了
那就手动下载maven依赖,mysql connector java maven,进到maven中央依赖库里面,去手动下载对应版本的jar包,可以用迅雷,会比较快速一些
你需要手动将jar包拷贝到你本地的maven仓库的对应的目录中去
可能对应的目录不存在,那就自己手动创建; 可能对应的目录已经存在,那么需要你将里面的东西先删除,然后拷贝自己下载的jar包进去
然后需要执行mvn install命令,手动安装依赖
mvn install:install-file -Dfile=F:\apache-maven-3.0.5\mvn_repo\redis\clients\jedis\2.5.2\jedis-2.5.2.jar -DgroupId=redis.clients -DartifactId=jedis -Dversion=2.5.2 -Dpackaging=jar
可能需要将eclipse强制关闭,任务管理器里面,直接强制结束任务,关闭eclipse,重新打开
右击工程,强制重新更新maven的依赖
然后就会继续去下载接下来的依赖包
我大概手动下载了将近10个依赖,然后才顺利的下载完了所有的依赖
2、com.roncoo.eshop.inventory.Application
我们是直接讲解项目的,项目中遇到的一些技术,比如说redis,是缓存架构topic里面非常重要的一个环节,那我们当然会花费很大的篇幅去仔细讲解
但是比如spring boot、mybatis、zookeeper、storm
有些技术,是默认大家要会的,spring boot,mybatis,你说你都不会,不行,自己去学一下
zookeeper,kafka,技术,直接带着大家部署,简单介绍一下,就开始用了,如果真的是要用这个技术,做项目,还是得上网自己去查阅一些资料,学习这个技术
storm,会带着大家把20%的核心基础知识学习一下,作为java程序员,可以开发就行了
一个项目课程,涉及了十几种技术,我不可能全都给你按照从入门到精通的方式,全部讲解一遍
@EnableAutoConfiguration
@SpringBootApplication
@ComponentScan
@MapperScan("com.roncoo.eshop.inventory.mapper")
public class Application {
@Bean
@ConfigurationProperties(prefix="spring.datasource")
public DataSource dataSource() {
return new org.apache.tomcat.jdbc.pool.DataSource();
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean() throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource());
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mybatis/*.xml"));
return sqlSessionFactoryBean.getObject();
}
@Bean
public PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
3、com.roncoo.eshop.inventory.model.User
4、com.roncoo.eshop.inventory.mapper.UserMapper
public interface UserMapper {
public User findUserInfo();
}
5、com.roncoo.eshop.inventory.service.UserService
6、UserController
@Controller
public class UserController {
@Autowired
private UserService userService;
@RequestMapping("/getUserInfo")
@ResponseBody
public User getUserInfo() {
User user = userService.getUserInfo();
return user;
}
}
7、resources/Application.properties
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/test
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
8、resources/mybatis/UserMapper.xml
9、测试spring boot+mybatis的整合
在数据库中创建一个eshop database,创建一个eshop账号和密码,创建一个user表,里面插入一条数据,张三和25岁
create database if not exists eshop;
grant all privileges on eshop.* to 'eshop'@'%' identified by 'eshop';
create table user(name varchar(255), age int)
insert into user values('张三', 25)
启动Application程序,访问getUserInfo接口,能否从mysql中查询数据,并返回到页面上
如果可以,说明spring boot+mybatis整合成功
10、整合Jedis Cluster
Application
@Bean
public JedisCluster JedisClusterFactory() {
Set
jedisClusterNodes.add(new HostAndPort("192.168.31.19", 7003));
jedisClusterNodes.add(new HostAndPort("192.168.31.19", 7004));
jedisClusterNodes.add(new HostAndPort("192.168.31.227", 7006));
JedisCluster jedisCluster = new JedisCluster(jedisClusterNodes);
return jedisCluster;
}
@Repository("redisDAO")
public class RedisDAOImpl implements RedisDAO {
@Resource
private JedisCluster jedisCluster;
@Override
public void set(String key, String value) {
jedisCluster.set(key, value);
}
@Override
public String get(String key) {
return jedisCluster.get(key);
}
}
UserServiceImpl
@Override
public User getCachedUserInfo() {
redisDAO.set("cached_user", "{\"name\": \"zhangsan\", \"age\": 25}") ;
String json = redisDAO.get("cached_user");
JSONObject jsonObject = JSONObject.parseObject(json);
User user = new User();
user.setName(jsonObject.getString("name"));
user.setAge(jsonObject.getInteger("age"));
return user;
}
UserController
@RequestMapping("/getCachedUserInfo")
@ResponseBody
public User getCachedUserInfo() {
User user = userService.getCachedUserInfo();
return user;
}
39-43_在库存服务中实现缓存与数据库双写一致性保障方案(四)
见 43中代码
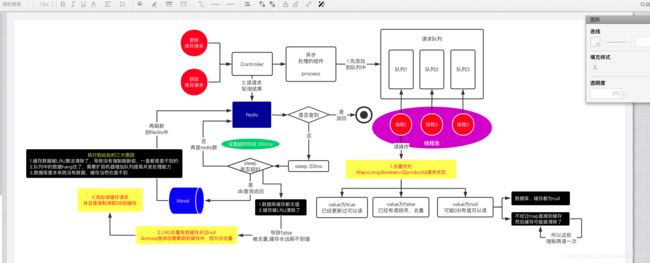
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个jvm内部的队列中
读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个jvm内部的队列中
一个队列对应一个工作线程
每个工作线程串行拿到对应的操作,然后一条一条的执行
这样的话,一个数据变更的操作,先执行,删除缓存,然后再去更新数据库,但是还没完成更新
此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回; 如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
(queueNum - 1) & hash
1、线程池+内存队列初始化
@Bean
public ServletListenerRegistrationBean servletListenerRegistrationBean(){
ServletListenerRegistrationBean servletListenerRegistrationBean = new ServletListenerRegistrationBean();
servletListenerRegistrationBean.setListener(new InitListener());
return servletListenerRegistrationBean;
}
java web应用,做系统的初始化,一般在哪里做呢?
ServletContextListener里面做,listener,会跟着整个web应用的启动,就初始化,类似于线程池初始化的构建
spring boot应用,Application,搞一个listener的注册
2、两种请求对象封装
3、请求异步执行Service封装
4、请求处理的工作线程封装
5、两种请求Controller接口封装
6、读请求去重优化
如果一个读请求过来,发现前面已经有一个写请求和一个读请求了,那么这个读请求就不需要压入队列中了
因为那个写请求肯定会更新数据库,然后那个读请求肯定会从数据库中读取最新数据,然后刷新到缓存中,自己只要hang一会儿就可以从缓存中读到数据了
7、空数据读请求过滤优化
可能某个数据,在数据库里面压根儿就没有,那么那个读请求是不需要放入内存队列的,而且读请求在controller那一层,直接就可以返回了,不需要等待
如果数据库里都没有,就说明,内存队列里面如果没有数据库更新的请求的话,一个读请求过来了,就可以认为是数据库里就压根儿没有数据吧
如果缓存里没数据,就两个情况,第一个是数据库里就没数据,缓存肯定也没数据; 第二个是数据库更新操作过来了,先删除了缓存,此时缓存是空的,但是数据库里是有的
但是的话呢,我们做了之前的读请求去重优化,用了一个flag map,只要前面有数据库更新操作,flag就肯定是存在的,你只不过可以根据true或false,判断你前面执行的是写请求还是读请求
但是如果flag压根儿就没有呢,就说明这个数据,无论是写请求,还是读请求,都没有过
那这个时候过来的读请求,发现flag是null,就可以认为数据库里肯定也是空的,那就不会去读取了
或者说,我们也可以认为每个商品有一个最最初始的库存,但是因为最初始的库存肯定会同步到缓存中去的,有一种特殊的情况,就是说,商品库存本来在redis中是有缓存的
但是因为redis内存满了,就给干掉了,但是此时数据库中是有值得
那么在这种情况下,可能就是之前没有任何的写请求和读请求的flag的值,此时还是需要从数据库中重新加载一次数据到缓存中的
8、深入的去思考优化代码的漏洞
我的一些思考,如果大家发现了其他的漏洞,随时+我Q跟我交流一下
一个读请求过来,将数据库中的数刷新到了缓存中,flag是false,然后过了一会儿,redis内存满了,自动删除了这个额缓存
下一次读请求再过来,发现flag是false,就不会去执行刷新缓存的操作了
而是hang在哪里,反复循环,等一会儿,发现在缓存中始终查询不到数据,然后就去数据库里查询,就直接返回了
这种代码,就有可能会导致,缓存永远变成null的情况
最简单的一种,就是在controller这一块,如果在数据库中查询到了,就刷新到缓存里面去,以后的读请求就又可以从缓存里面读了
队列
对一个商品的库存的数据库更新操作已经在内存队列中了
然后对这个商品的库存的读取操作,要求读取数据库的库存数据,然后更新到缓存中,多个读
这多个读,其实只要有一个读请求操作压到队列里就可以了
其他的读操作,全部都wait那个读请求的操作,刷新缓存,就可以读到缓存中的最新数据了
如果读请求发现redis缓存中没有数据,就会发送读请求给库存服务,但是此时缓存中为空,可能是因为写请求先删除了缓存,也可能是数据库里压根儿没这条数据
如果是数据库中压根儿没这条数据的场景,那么就不应该将读请求操作给压入队列中,而是直接返回空就可以了
都是为了减少内存队列中的请求积压,内存队列中积压的请求越多,就可能导致每个读请求hang住的时间越长,也可能导致多个读请求被hang住
这边跟大家提前说一下,打个招呼
我的风格,跟其他一些人不太一样,我都是课上纯实时手写代码的,没有说提前自己先练个10遍(也没那时间),也不是说预先写好,然后放ppt,课程里就copy粘贴
我就是思路梳理出来,然后边讲课边写代码
就是跟真实的开发的时候是一样的,可能会犯各种各样的错误,可能会写出来bug
有可能有些错误,或者是疏忽的地方,自己课程上就发现了,然后就纠正了; 也可能我没发现自己一些遗漏的地方,QQ+我,然后跟我反馈
视频随时可以补充进去,纠错的一些东西
talk is cheap, show me the code
写代码,还有一个问题,我们是课程上现场写代码,第一遍写代码,写出来的代码,面向对象的设计,设计模式的运用,然后代码结构的设置,都不是太完美,甚至可能是有点粗糙
公司里做项目,其实那个代码会改来改去,重构,代码会变得越来越规整
课程里没办法,大家如果觉得我的代码写的不太好,比如说觉得我哪里本来应该用个设计模式,结果没有用
很重要的废话
这套课程,主要还是讲解架构的,面向架构
架构,很虚,说说说
架构还是得落地,落地还是要写代码的,不管大家是什么层级的人,开发,高工,架构师,技术总监,项目经理
所有的代码跟着一点一点写一下
如果你后面发现了任何的解决方案有一些场景下的漏洞,或者是代码的性能或者效率不好,那么可以直接给我反馈意见
我这里跟大家说一下,龙果也有一套课程,是讲解分布式事务的解决方案,很多同学提出,这些方案有一些不完美的地方,或者是一些漏洞
但是我想说的是,没有一种完美的方案,任何方案都是会根据具体的业务,去进行适当的调整的
所以说没有任何一个方案是100%一样的,我这里讲解的方案,更多的是通用的一个思路,也许有一些漏洞,但是有些漏洞,可能站在我之前工作的时候,场景和环境下,不是太大的问题
但是也许放在其他的场景和环境下,就是一个严重的问题
45
我们讲解过,咱们的整个缓存的技术方案,分成两块
第一块,是做实时性比较高的那块数据,比如说库存,销量之类的这种数据,我们采取的实时的缓存+数据库双写的技术方案,双写一致性保障的方案
第二块,是做实时性要求不高的数据,比如说商品的基本信息,等等,我们采取的是三级缓存架构的技术方案,就是说由一个专门的数据生产的服务,去获取整个商品详情页需要的各种数据,经过处理后,将数据放入各级缓存中,每一级缓存都有自己的作用
我们先来看看一下,所谓的这种实时性要求不高的数据,在商品详情页中,都有哪些
1、大型电商网站中的商品详情页的数据结构分析
商品的基本信息
标题:【限时直降】Apple/苹果 iPhone 7 128G 全网通4G智能手机正品
短描述:限时优惠 原封国行 正品保障
颜色:
存储容量
图片列表
规格参数
其他信息:店铺信息,分类信息,等等,非商品维度的信息
商品介绍:放缓存,看一点,ajax异步从缓存加载一点,不放我们这里讲解
实时信息:实时广告推荐、实时价格、实时活动推送,等等,ajax加载
我们不是带着大家用几十讲的时间去做一套完整的商品详情页的系统,电商网站的话,都几百个人做好几年的
将商品的各种基本信息,分类放到缓存中,每次请求过来,动态从缓存中取数据,然后动态渲染到模板中
数据放缓存,性能高,动态渲染模板,灵活性好
2、大型缓存全量更新问题
(1)网络耗费的资源大
(2)每次对redis都存取大数据,对redis的压力也比较大
(3)大家记不记得,之前我给大家提过,redis的性能和吞吐量能够支撑到多大,基本跟数据本身的大小有很大的关系
如果数据越大,那么可能导致redis的吞吐量就会急剧下降
3、缓存维度化解决方案
维度:商品维度,商品分类维度,商品店铺维度
不同的维度,可以看做是不同的角度去观察一个东西,那么每个商品详情页中,都包含了不同的维度数据
我就跟大家举个例子,如果不维度化,就导致多个维度的数据混合在一个缓存value中
但是不同维度的数据,可能更新的频率都大不一样
比如说,现在只是将1000个商品的分类批量调整了一下,但是如果商品分类的数据和商品本身的数据混杂在一起
那么可能导致需要将包括商品在内的大缓存value取出来,进行更新,再写回去,就会很坑爹,耗费大量的资源,redis压力也很大
但是如果我们队对缓存进行围堵维度化
唯独化:将每个维度的数据都存一份,比如说商品维度的数据存一份,商品分类的数据存一份,商品店铺的数据存一份
那么在不同的维度数据更新的时候,只要去更新对应的维度就可以了
包括我们之前讲解的那种实时性较高的数据,也可以理解为一个维度,那么维度拆分后
46_缓存数据生产服务的工作流程分析以及工程环境搭建
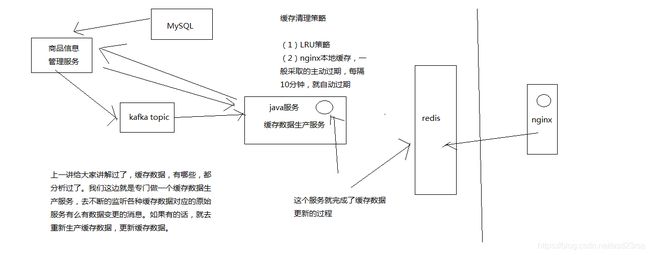
接下来要做这个多级缓存架构,从底往上做,先做缓存数据的生产这一块
我们画图来简单介绍一下整个缓存数据生产服务的一个工作流程
1、商品详情页缓存数据生产服务的工作流程分析
(1)监听多个kafka topic,每个kafka topic对应一个服务(简化一下,监听一个kafka topic)
(2)如果一个服务发生了数据变更,那么就发送一个消息到kafka topic中
(3)缓存数据生产服务监听到了消息以后,就发送请求到对应的服务中调用接口以及拉取数据,此时是从mysql中查询的
(4)缓存数据生产服务拉取到了数据之后,会将数据在本地缓存中写入一份,就是ehcache中
(5)同时会将数据在redis中写入一份
2、spring boot+mybatis+redis框架整合搭建
(1)依赖
(2)Application
@EnableAutoConfiguration
@SpringBootApplication
@ComponentScan
@MapperScan("com.roncoo.eshop.inventory.mapper")
public class Application {
@Bean
@ConfigurationProperties(prefix="spring.datasource")
public DataSource dataSource() {
return new org.apache.tomcat.jdbc.pool.DataSource();
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean() throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource());
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mybatis/*.xml"));
return sqlSessionFactoryBean.getObject();
}
@Bean
public PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
(3)resources/Application.properties
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/test
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
(4)resources/mybatis
(5)整合Jedis Cluster
Application
@Bean
public JedisCluster JedisClusterFactory() {
Set
jedisClusterNodes.add(new HostAndPort("192.168.31.19", 7003));
jedisClusterNodes.add(new HostAndPort("192.168.31.19", 7004));
jedisClusterNodes.add(new HostAndPort("192.168.31.227", 7006));
JedisCluster jedisCluster = new JedisCluster(jedisClusterNodes);
return jedisCluster;
}
47_完成spring boot整合ehcache的搭建以支持服务本地堆缓存
因为之前跟大家提过,三级缓存,多级缓存,服务本地堆缓存 + redis分布式缓存 + nginx本地缓存组成的
每一层缓存在高并发的场景下,都有其特殊的用途,需要综合利用多级的缓存,才能支撑住高并发场景下各种各样的特殊情况
服务本地堆缓存,作用,预防redis层的彻底崩溃,作为缓存的最后一道防线,避免数据库直接裸奔
服务本地堆缓存,我们用什么来做缓存,难道我们自己手写一个类或者程序去管理内存吗???java最流行的缓存的框架,ehcache
所以我们也是用ehcache来做本地的堆缓存
spring boot + ehcache整合起来,演示一下是怎么使用的
spring boot整合ehcache
(1)依赖
(2)缓存配置管理类
@Configuration
@EnableCaching
public class CacheConfiguration {
@Bean
public EhCacheManagerFactoryBean ehCacheManagerFactoryBean(){
EhCacheManagerFactoryBean cacheManagerFactoryBean = new EhCacheManagerFactoryBean();
cacheManagerFactoryBean.setConfigLocation(new ClassPathResource("ehcache.xml"));
cacheManagerFactoryBean.setShared(true);
return cacheManagerFactoryBean;
}
@Bean
public EhCacheCacheManager ehCacheCacheManager(EhCacheManagerFactoryBean bean){
return new EhCacheCacheManager(bean.getObject());
}
}
(3)ehcache.xml
updateCheck="false">
maxElementsInMemory="1000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="0"
timeToLiveSeconds="0"
memoryStoreEvictionPolicy="LRU" />
eternal="false"
maxElementsInMemory="1000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="0"
timeToLiveSeconds="0"
memoryStoreEvictionPolicy="LRU" />
(4)CacheService
@Service("cacheService")
public class CacheServiceImpl implements CacheService {
public static final String CACHE_NAME = "local";
@Cacheable(value = CACHE_NAME, key = "'key_'+#id")
public ProductInfo findById(Long id){
return null;
}
@CachePut(value = CACHE_NAME, key = "'key_'+#productInfo.getId()")
public ProductInfo saveProductInfo(ProductInfo productInfo) {
return productInfo;
}
}
(5)写一个Controller测试一下ehcache的整合
@Controller
public class CacheTestController {
@Resource
private CacheService cacheService;
@RequestMapping("/testPutCache")
@ResponseBody
public void testPutCache(ProductInfo productInfo) {
System.out.println(productInfo.getId() + ":" + productInfo.getName());
cacheService.saveProductInfo(productInfo);
}
@RequestMapping("/testGetCache")
@ResponseBody
public ProductInfo testGetCache(Long id) {
ProductInfo productInfo = cacheService.findById(id);
System.out.println(productInfo.getId() + ":" + productInfo.getName());
return productInfo;
}
}
ehcache已经整合进了我们的系统,spring boot
封装好了对ehcache本地缓存进行添加和获取的方法和service
48 redis lru算法
之前给大家讲解过,多级缓存架构,缓存数据生产服务,监听各个数据源服务的数据变更的消息,得到消息之后,然后调用接口拉去数据
将拉去到的数据,写入本地ehcache缓存一份,spring boot整合,演示过
数据写入redis分布式缓存中一份,你不断的将数据写入redis,写入redis,然后redis的内存是有限的,每个redis实例最大一般也就是设置给10G
那如果你不断的写入数据,当数据写入的量超过了redis能承受的范围之后,改该怎么玩儿呢???
redis是会在数据达到一定程度之后,超过了一个最大的限度之后,就会将数据进行一定的清理,从内存中清理掉一些数据
只有清理掉一些数据之后,才能将新的数据写入内存中
1、LRU算法概述
redis默认情况下就是使用LRU策略的,因为内存是有限的,但是如果你不断地往redis里面写入数据,那肯定是没法存放下所有的数据在内存的
所以redis默认情况下,当内存中写入的数据很满之后,就会使用LRU算法清理掉部分内存中的数据,腾出一些空间来,然后让新的数据写入redis缓存中
LRU:Least Recently Used,最近最少使用算法
将最近一段时间内,最少使用的一些数据,给干掉。比如说有一个key,在最近1个小时内,只被访问了一次; 还有一个key在最近1个小时内,被访问了1万次
这个时候比如你要将部分数据给清理掉,你会选择清理哪些数据啊?肯定是那个在最近小时内被访问了1万次的数据
2、缓存清理设置
redis.conf
maxmemory,设置redis用来存放数据的最大的内存大小,一旦超出这个内存大小之后,就会立即使用LRU算法清理掉部分数据
如果用LRU,那么就是将最近最少使用的数据从缓存中清除出去
对于64 bit的机器,如果maxmemory设置为0,那么就默认不限制内存的使用,直到耗尽机器中所有的内存为止; 但是对于32 bit的机器,有一个隐式的闲置就是3GB
maxmemory-policy,可以设置内存达到最大闲置后,采取什么策略来处理
(1)noeviction: 如果内存使用达到了maxmemory,client还要继续写入数据,那么就直接报错给客户端
(2)allkeys-lru: 就是我们常说的LRU算法,移除掉最近最少使用的那些keys对应的数据
(3)volatile-lru: 也是采取LRU算法,但是仅仅针对那些设置了指定存活时间(TTL)的key才会清理掉
(4)allkeys-random: 随机选择一些key来删除掉
(5)volatile-random: 随机选择一些设置了TTL的key来删除掉
(6)volatile-ttl: 移除掉部分keys,选择那些TTL时间比较短的keys
在redis里面,写入key-value对的时候,是可以设置TTL,存活时间,比如你设置了60s。那么一个key-value对,在60s之后就会自动被删除
redis的使用,各种数据结构,list,set,等等
allkeys-lru
这边拓展一下思路,对技术的研究,一旦将一些技术研究的比较透彻之后,就喜欢横向对比底层的一些原理
storm,科普一下
玩儿大数据的人搞得,领域,实时计算领域,storm
storm有很多的流分组的一些策略,按shuffle分组,global全局分组,direct直接分组,fields按字段值hash后分组
分组策略也很多,但是,真正公司里99%的场景下,使用的也就是shuffle和fields,两种策略
redis,给了这么多种乱七八糟的缓存清理的算法,其实真正常用的可能也就那么一两种,allkeys-lru是最常用的
3、缓存清理的流程
(1)客户端执行数据写入操作
(2)redis server接收到写入操作之后,检查maxmemory的限制,如果超过了限制,那么就根据对应的policy清理掉部分数据
(3)写入操作完成执行
4、redis的LRU近似算法
科普一个相对来说稍微高级一丢丢的知识点
redis采取的是LRU近似算法,也就是对keys进行采样,然后在采样结果中进行数据清理
redis 3.0开始,在LRU近似算法中引入了pool机制,表现可以跟真正的LRU算法相当,但是还是有所差距的,不过这样可以减少内存的消耗
redis LRU算法,是采样之后再做LRU清理的,跟真正的、传统、全量的LRU算法是不太一样的
maxmemory-samples,比如5,可以设置采样的大小,如果设置为10,那么效果会更好,不过也会耗费更多的CPU资源
49_zookeeper+kafka集群的安装部署以及如何简单使用的介绍
多级缓存的架构
主要是用来解决什么样的数据的缓存的更新的啊???
时效性不高的数据,比如一些商品的基本信息,如果发生了变更,假设在5分钟之后再更新到页面中,供用户观察到,也是ok的
时效性要求不高的数据,那么我们采取的是异步更新缓存的策略
时效性要求很高的数据,库存,采取的是数据库+缓存双写的技术方案,也解决了双写的一致性的问题
缓存数据生产服务,监听一个消息队列,然后数据源服务(商品信息管理服务)发生了数据变更之后,就将数据变更的消息推送到消息队列中
缓存数据生产服务可以去消费到这个数据变更的消息,然后根据消息的指示提取一些参数,然后调用对应的数据源服务的接口,拉去数据,这个时候一般是从mysql库中拉去的
消息队列是什么东西?采取打的就是kafka
我工作的时候,很多项目是跟大数据相关的,当然也有很多是纯java系统的架构,最近用kafka用得比较多
kafka比较简单易用,讲课来说,很方便
解释一下,我们当然是不可能对课程中涉及的各种技术都深入浅出的讲解的了,kafka,花上20个小时给你讲解一下,不可能的
所以说呢,在这里,一些技术的组合,用什么都ok
笑傲江湖中的风清扬,手中无剑胜有剑,还有任何东西都可以当做兵器,哪怕是一根草也可以
搞技术,kafka和activemq肯定有区别,但是说,在有些场景下,其实可能没有那么大的区分度,kafka和activemq其实是一样的
生产者+消费者的场景,kafka+activemq都ok
涉及的这种架构,对时效性要求高和时效性要求低的数据,分别采取什么技术方案?数据库+缓存双写一致性?异步+多级缓存架构?大缓存的维度化拆分?
你要关注的,是一些架构上的东西和思想,而不是具体的什么mq的使用
activemq的课程,书籍,资料
kafka集群,zookeeper集群,先搭建zookeeper集群,再搭建kafka集群
kafka另外一个原因:kafka,本来就要搭建zookeeper,zookeeper这个东西,后面我们还要用呢,缓存的分布式并发更新的问题,分布式锁解决
zookeeper + kafka的集群,都是三节点
java高级工程师的思想,在干活儿,在思考,jvm,宏观的思考,通盘去考虑整个架构,还有未来的技术规划,业务的发展方向,架构的演进方向和路线
把课程里讲解的各种技术方案组合成、修改成你需要的适合你的业务的缓存架构
1、zookeeper集群搭建
将课程提供的zookeeper-3.4.5.tar.gz使用WinSCP拷贝到/usr/local目录下。
对zookeeper-3.4.5.tar.gz进行解压缩:tar -zxvf zookeeper-3.4.5.tar.gz。
对zookeeper目录进行重命名:mv zookeeper-3.4.5 zk
配置zookeeper相关的环境变量
vi ~/.bashrc
export ZOOKEEPER_HOME=/usr/local/zk
export PATH=$ZOOKEEPER_HOME/bin
source ~/.bashrc
cd zk/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改:dataDir=/usr/local/zk/data
新增:
server.0=eshop-cache01:2888:3888
server.1=eshop-cache02:2888:3888
server.2=eshop-cache03:2888:3888
cd zk
mkdir data
cd data
vi myid
0
在另外两个节点上按照上述步骤配置ZooKeeper,使用scp将zk和.bashrc拷贝到eshop-cache02和eshop-cache03上即可。唯一的区别是标识号分别设置为1和2。
分别在三台机器上执行:zkServer.sh start。
检查ZooKeeper状态:zkServer.sh status,应该是一个leader,两个follower
jps:检查三个节点是否都有QuromPeerMain进程
2、kafka集群搭建
scala,我就不想多说了,就是一门编程语言,现在比较火,很多比如大数据领域里面的spark(计算引擎)就是用scala编写的
将课程提供的scala-2.11.4.tgz使用WinSCP拷贝到/usr/local目录下。
对scala-2.11.4.tgz进行解压缩:tar -zxvf scala-2.11.4.tgz。
对scala目录进行重命名:mv scala-2.11.4 scala
配置scala相关的环境变量
vi ~/.bashrc
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin
source ~/.bashrc
查看scala是否安装成功:scala -version
按照上述步骤在其他机器上都安装好scala。使用scp将scala和.bashrc拷贝到另外两台机器上即可。
将课程提供的kafka_2.9.2-0.8.1.tgz使用WinSCP拷贝到/usr/local目录下。
对kafka_2.9.2-0.8.1.tgz进行解压缩:tar -zxvf kafka_2.9.2-0.8.1.tgz。
对kafka目录进行改名:mv kafka_2.9.2-0.8.1 kafka
配置kafka
vi /usr/local/kafka/config/server.properties
broker.id:依次增长的整数,0、1、2,集群中Broker的唯一id
zookeeper.connect=192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181
安装slf4j
将课程提供的slf4j-1.7.6.zip上传到/usr/local目录下
unzip slf4j-1.7.6.zip
把slf4j中的slf4j-nop-1.7.6.jar复制到kafka的libs目录下面
解决kafka Unrecognized VM option 'UseCompressedOops'问题
vi /usr/local/kafka/bin/kafka-run-class.sh
if [ -z "$KAFKA_JVM_PERFORMANCE_OPTS" ]; then
KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseCompressedOops -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true"
fi
去掉-XX:+UseCompressedOops即可
按照上述步骤在另外两台机器分别安装kafka。用scp把kafka拷贝到其他机器即可。
唯一区别的,就是server.properties中的broker.id,要设置为1和2
在三台机器上的kafka目录下,分别执行以下命令:nohup bin/kafka-server-start.sh config/server.properties &
使用jps检查启动是否成功
使用基本命令检查kafka是否搭建成功
bin/kafka-topics.sh --zookeeper 192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181 --topic test --replication-factor 1 --partitions 1 --create
bin/kafka-console-producer.sh --broker-list 192.168.31.181:9092,192.168.31.19:9092,192.168.31.227:9092 --topic test
bin/kafka-console-consumer.sh --zookeeper 192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181 --topic test --from-beginning
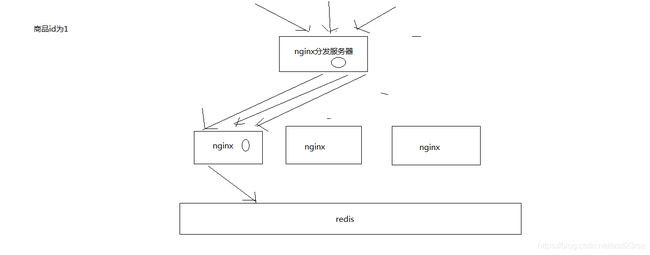
51_基于“分发层+应用层”双层nginx架构提升缓存命中率方案分析
1、缓存命中率低
缓存数据生产服务那一层已经搞定了,相当于三层缓存架构中的本地堆缓存+redis分布式缓存都搞定了
就要来做三级缓存中的nginx那一层的缓存了
如果一般来说,你默认会部署多个nginx,在里面都会放一些缓存,就默认情况下,此时缓存命中率是比较低的
2、如何提升缓存命中率
分发层+应用层,双层nginx
分发层nginx,负责流量分发的逻辑和策略,这个里面它可以根据你自己定义的一些规则,比如根据productId去进行hash,然后对后端的nginx数量取模
将某一个商品的访问的请求,就固定路由到一个nginx后端服务器上去,保证说只会从redis中获取一次缓存数据,后面全都是走nginx本地缓存了
后端的nginx服务器,就称之为应用服务器; 最前端的nginx服务器,被称之为分发服务器
看似很简单,其实很有用,在实际的生产环境中,可以大幅度提升你的nginx本地缓存这一层的命中率,大幅度减少redis后端的压力,提升性能
52 安装openresty
我们这里玩儿nginx,全都会在nginx里去写lua脚本,因为我们需要自定义一些特殊的业务逻辑
比如说,流量分发,自己用lua去写分发的逻辑,在分发层nginx里去写的
再比如说,要用lua去写多级缓存架构存取的控制逻辑,在应用层nginx里去写的
后面还要做热点数据的自动降级机制,也是用lua脚本去写降级机制的,在分发层nginx里去写的
因为我们要用nginx+lua去开发,所以会选择用最流行的开源方案,就是用OpenResty
nginx+lua打包在一起,而且提供了包括redis客户端,mysql客户端,http客户端在内的大量的组件
我们这一讲是去部署应用层nginx,会采用OpenResty的方式去部署nginx,而且会带着大家写一个nginx+lua开发的一个hello world
1、部署第一个nginx,作为应用层nginx(192.168.31.187那个机器上)
(1)部署openresty
mkdir -p /usr/servers
cd /usr/servers/
yum install -y readline-devel pcre-devel openssl-devel gcc
wget http://openresty.org/download/ngx_openresty-1.7.7.2.tar.gz
tar -xzvf ngx_openresty-1.7.7.2.tar.gz
cd /usr/servers/ngx_openresty-1.7.7.2/
cd bundle/LuaJIT-2.1-20150120/
make clean && make && make install
ln -sf luajit-2.1.0-alpha /usr/local/bin/luajit
cd bundle
wget https://github.com/FRiCKLE/ngx_cache_purge/archive/2.3.tar.gz
tar -xvf 2.3.tar.gz
cd bundle
wget https://github.com/yaoweibin/nginx_upstream_check_module/archive/v0.3.0.tar.gz
tar -xvf v0.3.0.tar.gz
cd /usr/servers/ngx_openresty-1.7.7.2
./configure --prefix=/usr/servers --with-http_realip_module --with-pcre --with-luajit --add-module=./bundle/ngx_cache_purge-2.3/ --add-module=./bundle/nginx_upstream_check_module-0.3.0/ -j2
make && make install
cd /usr/servers/
ll
/usr/servers/luajit
/usr/servers/lualib
/usr/servers/nginx
/usr/servers/nginx/sbin/nginx -V
启动nginx: /usr/servers/nginx/sbin/nginx
(2)nginx+lua开发的hello world
vi /usr/servers/nginx/conf/nginx.conf
在http部分添加:
lua_package_path "/usr/servers/lualib/?.lua;;";
lua_package_cpath "/usr/servers/lualib/?.so;;";
/usr/servers/nginx/conf下,创建一个lua.conf
server {
listen 80;
server_name _;
}
在nginx.conf的http部分添加:
include lua.conf;
验证配置是否正确:
/usr/servers/nginx/sbin/nginx -t
在lua.conf的server部分添加:
location /lua {
default_type 'text/html';
content_by_lua 'ngx.say("hello world")';
}
/usr/servers/nginx/sbin/nginx -t
重新nginx加载配置
/usr/servers/nginx/sbin/nginx -s reload
访问http: http://192.168.31.187/lua
vi /usr/servers/nginx/conf/lua/test.lua
ngx.say("hello world");
修改lua.conf
location /lua {
default_type 'text/html';
content_by_lua_file conf/lua/test.lua;
}
查看异常日志
tail -f /usr/servers/nginx/logs/error.log
(3)工程化的nginx+lua项目结构
项目工程结构
hello
hello.conf
lua
hello.lua
lualib
*.lua
*.so
放在/usr/hello目录下
/usr/servers/nginx/conf/nginx.conf
worker_processes 2;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type text/html;
lua_package_path "/usr/hello/lualib/?.lua;;";
lua_package_cpath "/usr/hello/lualib/?.so;;";
include /usr/hello/hello.conf;
}
/usr/hello/hello.conf
server {
listen 80;
server_name _;
location /lua {
default_type 'text/html';
lua_code_cache off;
content_by_lua_file /usr/example/lua/test.lua;
}
}
2、如法炮制,在另外一个机器上,也用OpenResty部署一个nginx
大家可能会发现说,有的人可能对nginx也不是太懂,对lua也没什么了解
对于我的课程来说,主要还是关注,关注的是我们核心的topic,缓存,缓存,缓存,缓存的各种解决方案,大型缓存的架构
那么对于课程里涉及到的各种技术来说,比如nginx,lua脚本
你说让我给你讲成nginx从入门到精通,也不太现实; 讲一个lua脚本开发从入门到精通,也不太现实
我只能说,跟着整个项目的思路去走,把项目里涉及的相关技术的知识给你讲解一下,然后保证说,带着你手把手的去做,让你至少可以学会项目里讲解的这些知识,可以做出来
如果你后面真的是要自己去用nginx+lua去做项目,其实个人建议你还是得去查询和学习一些更多的资料,nginx的一些知识,lua的一些语法
龙果,最受欢迎的一套课程,就是dubbo实战课程,里面也是dubbo整合了各种技术,active mq,zookeeper,redis 3.0分布式集群,mysql读写分离
但是有个问题,每个课程,我相信一个好的课程,它总是可以让你学到很多知识的
但是任何一个好的课程,它都不是万能的,dubbo,zookeeper,注册中心,zookeeper分布式锁,分布式协调,分布式选举,等等技术,你学到吗?
dubbo它也不可能说是给你把zookeeper,redis,mysql全部讲解到从入门到精通这样子
topic,主题,基于dubbo复杂的分布式系统的通用架构,分布式系统,dubbo rpc的调用,服务的开发; zookeeper注册中心; redis分布式集群; mysql读写分离; tomcat集群; hudson持续集成
它告诉你的是一个通用的分布式系统的架构
我这里的也会带着你做nginx的部署,openresty,nginx+lua的开发,redis集群/高可用/高并发/读写分离/持久化/数据备份恢复,zookeeper分布式锁,kafka去做消息通信,hystrix去做限流
但是任何一个技术都不可能给你从入门到精通讲解完
大家可以去关注一下我的es的课程,你如果录一套课程,基本选择方向就两个,要不就是讲解技术本身,大量案例实战贯穿,把技术本身讲解的很细致
我之前有两个es顶尖高手系列的课程,技术课程,把es这个技术讲解的非常非常的细致
像我们现在这个课程,大规模缓存,支撑高并发,高性能,海量数据,类似之前dubbo实战课程,它讲解的还是一种架构课程,那么就关注点在整个架构的整体,整合,架构方案,架构设计,架构思想
里面涉及的技术是不可能给你去深入讲解的
53_部署分发层nginx以及基于lua完成基于商品id的定向流量分发策略
大家可以自己按照上一讲讲解的内容,基于OpenResty在另外两台机器上都部署一下nginx+lua的开发环境
我已经在eshop-cache02和eshop-cache03上都部署好了
我这边的话呢,是打算用eshop-cache01和eshop-cache02作为应用层nginx服务器,用eshop-cache03作为分发层nginx
在eshop-cache03,也就是分发层nginx中,编写lua脚本,完成基于商品id的流量分发策略
当然了,我们这里主要会简化策略,简化业务逻辑,实际上在你的公司中,你可以随意根据自己的业务逻辑和场景,去制定自己的流量分发策略
1、获取请求参数,比如productId
2、对productId进行hash
3、hash值对应用服务器数量取模,获取到一个应用服务器
4、利用http发送请求到应用层nginx
5、获取响应后返回
这个就是基于商品id的定向流量分发的策略,lua脚本来编写和实现
我们作为一个流量分发的nginx,会发送http请求到后端的应用nginx上面去,所以要先引入lua http lib包
cd /usr/hello/lualib/resty/
wget https://raw.githubusercontent.com/pintsized/lua-resty-http/master/lib/resty/http_headers.lua
wget https://raw.githubusercontent.com/pintsized/lua-resty-http/master/lib/resty/http.lua
代码:
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local host = {"192.168.31.19", "192.168.31.187"}
local hash = ngx.crc32_long(productId)
hash = (hash % 2) + 1
backend = "http://"..host[hash]
local method = uri_args["method"]
local requestBody = "/"..method.."?productId="..productId
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri(backend, {
method = "GET",
path = requestBody
})
if not resp then
ngx.say("request error :", err)
return
end
ngx.say(resp.body)
httpc:close()
/usr/servers/nginx/sbin/nginx -s reload
基于商品id的定向流量分发策略的lua脚本就开发完了,而且也测试过了
我们就可以看到,如果你请求的是固定的某一个商品,那么就一定会将流量打到固定的一个应用nginx上面去
54_基于nginx+lua+java完成多级缓存架构的核心业务逻辑(一)
分发层nginx,lua应用,会将商品id,商品店铺id,都转发到后端的应用nginx
/usr/servers/nginx/sbin/nginx -s reload
1、应用nginx的lua脚本接收到请求
2、获取请求参数中的商品id,以及商品店铺id
3、根据商品id和商品店铺id,在nginx本地缓存中尝试获取数据
4、如果在nginx本地缓存中没有获取到数据,那么就到redis分布式缓存中获取数据,如果获取到了数据,还要设置到nginx本地缓存中
但是这里有个问题,建议不要用nginx+lua直接去获取redis数据
因为openresty没有太好的redis cluster的支持包,所以建议是发送http请求到缓存数据生产服务,由该服务提供一个http接口
缓存数生产服务可以基于redis cluster api从redis中直接获取数据,并返回给nginx
cd /usr/hello/lualib/resty/
wget https://raw.githubusercontent.com/pintsized/lua-resty-http/master/lib/resty/http_headers.lua
wget https://raw.githubusercontent.com/pintsized/lua-resty-http/master/lib/resty/http.lua
5、如果缓存数据生产服务没有在redis分布式缓存中没有获取到数据,那么就在自己本地ehcache中获取数据,返回数据给nginx,也要设置到nginx本地缓存中
6、如果ehcache本地缓存都没有数据,那么就需要去原始的服务中拉去数据,该服务会从mysql中查询,拉去到数据之后,返回给nginx,并重新设置到ehcache和redis中
这里先不考虑,后面要专门讲解一套分布式缓存重建并发冲突的问题和解决方案
7、nginx最终利用获取到的数据,动态渲染网页模板
cd /usr/hello/lualib/resty/
wget https://raw.githubusercontent.com/bungle/lua-resty-template/master/lib/resty/template.lua
mkdir /usr/hello/lualib/resty/html
cd /usr/hello/lualib/resty/html
wget https://raw.githubusercontent.com/bungle/lua-resty-template/master/lib/resty/template/html.lua
在hello.conf的server中配置模板位置
set $template_location "/templates";
set $template_root "/usr/hello/templates";
mkdir /usr/hello/templates
vi product.html
product id: {* productId *}
product name: {* productName *}
product picture list: {* productPictureList *}
product specification: {* productSpecification *}
product service: {* productService *}
product color: {* productColor *}
product size: {* productSize *}
shop id: {* shopId *}
shop name: {* shopName *}
shop level: {* shopLevel *}
shop good cooment rate: {* shopGoodCommentRate *}
8、将渲染后的网页模板作为http响应,返回给分发层nginx
hello.conf中:
lua_shared_dict my_cache 128m; 应该放在nginx.conf全局配置文件中
lua脚本中:
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local shopId = uri_args["shopId"]
local cache_ngx = ngx.shared.my_cache
local productCacheKey = "product_info_"..productId
local shopCacheKey = "shop_info_"..shopId
local productCache = cache_ngx:get(productCacheKey)
local shopCache = cache_ngx:get(shopCacheKey)
if productCache == "" or productCache == nil then
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri("http://192.168.31.179:8080",{ //此处也可以按商品id路由到不同服务接口,kafka给缓存服务发消息时可以群发,缓存服务本地缓存有的才更新本地缓存(或者缓存服务根据商品id hash后是在本机上才更新)
method = "GET",
path = "/getProductInfo?productId="..productId
})
productCache = resp.body
cache_ngx:set(productCacheKey, productCache, 10 * 60)
end
if shopCache == "" or shopCache == nil then
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri("http://192.168.31.179:8080",{
method = "GET",
path = "/getShopInfo?shopId="..shopId
})
shopCache = resp.body
cache_ngx:set(shopCacheKey, shopCache, 10 * 60)
end
local cjson = require("cjson")
local productCacheJSON = cjson.decode(productCache)
local shopCacheJSON = cjson.decode(shopCache)
local context = {
productId = productCacheJSON.id,
productName = productCacheJSON.name,
productPrice = productCacheJSON.price,
productPictureList = productCacheJSON.pictureList,
productSpecification = productCacheJSON.specification,
productService = productCacheJSON.service,
productColor = productCacheJSON.color,
productSize = productCacheJSON.size,
shopId = shopCacheJSON.id,
shopName = shopCacheJSON.name,
shopLevel = shopCacheJSON.level,
shopGoodCommentRate = shopCacheJSON.goodCommentRate
}
local template = require("resty.template")
template.render("product.html", context)
55_基于nginx+lua+java完成多级缓存架构的核心业务逻辑(二)
/usr/servers/nginx/sbin/nginx -s reload
lua_shared_dict my_cache 128m;
商品id: {* productId *}
商品名称: {* productName *}
商品图片列表: {* productPictureList *}
商品规格: {* productSpecification *}
商品售后服务: {* productService *}
商品颜色: {* productColor *}
商品大小: {* productSize *}
店铺id: {* shopId *}
店铺名称: {* shopName *}
店铺评级: {* shopLevel *}
店铺好评率: {* shopGoodCommentRate *}
57_分布式缓存重建并发冲突问题以及zookeeper分布式锁解决方案
整个三级缓存的架构已经走通了
我们还遇到一个问题,就是说,如果缓存服务在本地的ehcache中都读取不到数据,那就恩坑爹了
这个时候就意味着,需要重新到源头的服务中去拉去数据,拉取到数据之后,赶紧先给nginx的请求返回,同时将数据写入ehcache和redis中
分布式重建缓存的并发冲突问题
重建缓存:比如我们这里,数据在所有的缓存中都不存在了(LRU算法弄掉了),就需要重新查询数据写入缓存,重建缓存
分布式的重建缓存,在不同的机器上,不同的服务实例中,去做上面的事情,就会出现多个机器分布式重建去读取相同的数据,然后写入缓存中
分布式重建缓存的并发冲突问题。。。。。。
1、流量均匀分布到所有缓存服务实例上
应用层nginx,是将请求流量均匀地打到各个缓存服务实例中的,可能咱们的eshop-cache那个服务,可能会部署多实例在不同的机器上
2、应用层nginx的hash,固定商品id,走固定的缓存服务实例
分发层的nginx的lua脚本,是怎么写的,怎么玩儿的,搞一堆应用层nginx的地址列表,对每个商品id做一个hash,然后对应用nginx数量取模
将每个商品的请求固定分发到同一个应用层nginx上面去
在应用层nginx里,发现自己本地lua shared dict缓存中没有数据的时候,就采取一样的方式,对product id取模,然后将请求固定分发到同一个缓存服务实例中去
这样的话,就不会出现说多个缓存服务实例分布式的去更新那个缓存了
留个作业,大家去做吧,这个东西,之前已经讲解果了,lua脚本几乎都是一模一样的,我们就不去做了,节省点时间
3、源信息服务发送的变更消息,需要按照商品id去分区,固定的商品变更走固定的kafka分区,也就是固定的一个缓存服务实例获取到
缓存服务,是监听kafka topic的,一个缓存服务实例,作为一个kafka consumer,就消费topic中的一个partition
所以你有多个缓存服务实例的话,每个缓存服务实例就消费一个kafka partition
所以这里,一般来说,你的源头信息服务,在发送消息到kafka topic的时候,都需要按照product id去分区
也就时说,同一个product id变更的消息一定是到同一个kafka partition中去的,也就是说同一个product id的变更消息,一定是同一个缓存服务实例消费到的
我们也不去做了,其实很简单,kafka producer api,里面send message的时候,多加一个参数就可以了,product id传递进去,就可以了
4、问题是,自己写的简易的hash分发,与kafka的分区,可能并不一致!!!
我们自己写的简易的hash分发策略,是按照crc32去取hash值,然后再取模的
关键你又不知道你的kafka producer的hash策略是什么,很可能说跟我们的策略是不一样的
拿就可能导致说,数据变更的消息所到的缓存服务实例,跟我们的应用层nginx分发到的那个缓存服务实例也许就不在一台机器上了
这样的话,在高并发,极端的情况下,可能就会出现冲突(发送广播消息,本地缓存有的服务才更新,若lru掉的,让他们读取时再缓存)
5、分布式的缓存重建并发冲突问题发生了。。。
6、基于zookeeper分布式锁的解决方案
分布式锁,如果你有多个机器在访问同一个共享资源,那么这个时候,如果你需要加个锁,让多个分布式的机器在访问共享资源的时候串行起来
那么这个时候,那个锁,多个不同机器上的服务共享的锁,就是分布式锁
分布式锁当然有很多种不同的实现方案,redis分布式锁,zookeeper分布式锁
zk,做分布式协调这一块,还是很流行的,大数据应用里面,hadoop,storm,都是基于zk去做分布式协调
zk分布式锁的解决并发冲突的方案
(1)变更缓存重建以及空缓存请求重建,更新redis之前,都需要先获取对应商品id的分布式锁
(2)拿到分布式锁之后,需要根据时间版本去比较一下,如果自己的版本新于redis中的版本,那么就更新,否则就不更新
(3)如果拿不到分布式锁,那么就等待,不断轮询等待,直到自己获取到分布式的锁
58_缓存数据生产服务中的zk分布式锁解决方案的代码实现
zk分布式锁的代码封装
zookeeper java client api去封装连接zk,以及获取分布式锁,还有释放分布式锁的代码
先简单介绍一下zk分布式锁的原理
我们通过去创建zk的一个临时node,来模拟给摸一个商品id加锁
zk会给你保证说,只会创建一个临时node,其他请求过来如果再要创建临时node,就会报错,NodeExistsException
那么所以说,我们的所谓上锁,其实就是去创建某个product id对应的一个临时node
如果临时node创建成功了,那么说明我们成功加锁了,此时就可以去执行对redis立面数据的操作
如果临时node创建失败了,说明有人已经在拿到锁了,在操作reids中的数据,那么就不断的等待,直到自己可以获取到锁为止
基于zk client api,去封装上面的这个代码逻辑
释放一个分布式锁,去删除掉那个临时node就可以了,就代表释放了一个锁,那么此时其他的机器就可以成功创建临时node,获取到锁
即使是用zk去实现一个分布式锁,也有很多种做法,有复杂的,也有简单的
应该说,我演示的这种分布式锁的做法,是非常简单的一种,但是很实用,大部分情况下,用这种简单的分布式锁都能搞定
/**
* ZooKeeperSession
* @author Administrator
*
*/
public class ZooKeeperSession {
private static CountDownLatch connectedSemaphore = new CountDownLatch(1);
private ZooKeeper zookeeper;
public ZooKeeperSession() {
// 去连接zookeeper server,创建会话的时候,是异步去进行的
// 所以要给一个监听器,说告诉我们什么时候才是真正完成了跟zk server的连接
try {
this.zookeeper = new ZooKeeper(
"192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181",
50000,
new ZooKeeperWatcher());
// 给一个状态CONNECTING,连接中
System.out.println(zookeeper.getState());
try {
// CountDownLatch
// java多线程并发同步的一个工具类
// 会传递进去一些数字,比如说1,2 ,3 都可以
// 然后await(),如果数字不是0,那么久卡住,等待
// 其他的线程可以调用coutnDown(),减1
// 如果数字减到0,那么之前所有在await的线程,都会逃出阻塞的状态
// 继续向下运行
connectedSemaphore.await();
} catch(InterruptedException e) {
e.printStackTrace();
}
System.out.println("ZooKeeper session established......");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取分布式锁
* @param productId
*/
public void acquireDistributedLock(Long productId) {
String path = "/product-lock-" + productId;
try {
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("success to acquire lock for product[id=" + productId + "]");
} catch (Exception e) {
// 如果那个商品对应的锁的node,已经存在了,就是已经被别人加锁了,那么就这里就会报错
// NodeExistsException
int count = 0;
while(true) {
try {
Thread.sleep(20);
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e2) {
e2.printStackTrace();
count++;
continue;
}
System.out.println("success to acquire lock for product[id=" + productId + "] after " + count + " times try......");
break;
}
}
}
/**
* 释放掉一个分布式锁
* @param productId
*/
public void releaseDistributedLock(Long productId) {
String path = "/product-lock-" + productId;
try {
zookeeper.delete(path, -1);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 建立zk session的watcher
* @author Administrator
*
*/
private class ZooKeeperWatcher implements Watcher {
public void process(WatchedEvent event) {
System.out.println("Receive watched event: " + event.getState());
if(KeeperState.SyncConnected == event.getState()) {
connectedSemaphore.countDown();
}
}
}
/**
* 封装单例的静态内部类
* @author Administrator
*
*/
private static class Singleton {
private static ZooKeeperSession instance;
static {
instance = new ZooKeeperSession();
}
public static ZooKeeperSession getInstance() {
return instance;
}
}
/**
* 获取单例
* @return
*/
public static ZooKeeperSession getInstance() {
return Singleton.getInstance();
}
/**
* 初始化单例的便捷方法
*/
public static void init() {
getInstance();
}
}
59_缓存数据生产服务中的zk分布式锁解决方案的代码实现(二)
1、主动更新
监听kafka消息队列,获取到一个商品变更的消息之后,去哪个源服务中调用接口拉取数据,更新到ehcache和redis中
先获取分布式锁,然后才能更新redis,同时更新时要比较时间版本
2、被动重建
直接读取源头数据,直接返回给nginx,同时推送一条消息到一个队列,后台线程异步消费
后台现成负责先获取分布式锁,然后才能更新redis,同时要比较时间版本
61_Java程序员、缓存架构以及Storm大数据实时计算之间的关系
接下来,我们是要讲解这个商品详情页缓存架构,缓存预热问题和解决方案,缓存热点数据可能导致整个系统崩溃的问题,以及解决方案
缓存,热,预热,热数据
解决方案,和架构设计中,会引入大数据的实时计算的技术,storm
为什么要引入这个storm,难道必须是storm吗?我们后面去讲解那个解决方案的时候再说
java工程师,storm的关系是什么呢,缓存架构和storm的关系
缓存架构和storm的关系,因为有些热点数据相关的一些实时处理的一些方案,比如快速预热,热点数据的实时感知和快速降级,全部要用到storm
因为我们可能需要实时的去计算出热点缓存数据,实时计算,亿级流量,高并发,大量的请求过来
这个时候,你要做一些实时的计算,那么必须涉及到分布式的一些技术,分布式的技术,才能处理高并发,大量的请求
目前在时候计算的领域,最成熟的大数据的技术,就是storm
storm分布式的大数据实时计算的技术/系统
java工程师,我跟storm之间的关系是什么?
1、介绍,我自己本身这么多年,一直在大公司,BAT公司,一线的大互联网公司,我认识的很多的java工程师
java开发和架构,后来开始大数据的架构
大公司里的很多java工程师,都是会用一些大数据的一些技术的,比如storm,或者hbase,或者zookeeper,或者hive,spark
因为在大公司里,容易遇到一些复杂的挑战和场景,比如高并发,海量数据,场景
你做一些java先关的项目,和系统,可能也会遇到这种问题,很多时候,直接用大数据的一些技术,实时计算,你是自己去写个系统,还是用现成的storm
更好的选择时用storm,成熟
我也只是说部分java的人,但是也有很多搞java的工程师就是纯java技术栈
2、java系统跟大数据技术的关系
(1)大数据不仅仅只是大数据工程师要关注的东西
(2)大数据也是Java程序员在构建各类系统的时候一种全新的思维,以及架构理念,比如Storm,Hive,Spark,ZooKeeper,HBase,Elasticsearch,等等
(3)举例说明
Storm:实时缓存热点数据统计->缓存预热->缓存热点数据自动降级
Hive:Hadoop生态栈里面,做数据仓库的一个系统,高并发访问下,海量请求日志的批量统计分析,日报周报月报,接口调用情况,业务使用情况,等等
我所知,在一些大公司里面,是有些人是将海量的请求日志打到hive里面,做离线的分析,然后反过来去优化自己的系统
Spark:离线批量数据处理,比如从DB中一次性批量处理几亿数据,清洗和处理后写入Redis中供后续的系统使用,大型互联网公司的用户相关数据
ZooKeeper:分布式系统的协调,分布式锁,分布式选举->高可用HA架构,轻量级元数据存储
用java开发了分布式的系统架构,你的整套系统拆分成了多个部分,每个部分都会负责一些功能,互相之间需要交互和协调
服务A说,我在处理某件事情的时候,服务B你就别处理了
服务A说,我一旦发生了某些状况,希望服务B你立即感知到,然后做出相应的对策
HBase:海量数据的在线存储和简单查询,替代MySQL分库分表,提供更好的伸缩性
java底层,对应的是海量数据,然后要做一些简单的存储和查询,同时数据增多的时候要快速扩容
mysql分库分表就不太合适了,mysql分库分表扩容,还是比较麻烦的
Elasticsearch:海量数据的复杂检索以及搜索引擎的构建,支撑有大量数据的各种企业信息化系统的搜索引擎,电商/新闻等网站的搜索引擎,等等
mysql的like "%xxxx%",更加合适一些,性能更加好
大家不要说觉得来听课程,就必须每堂课都是代码,代码,代码,就不喜欢听我这些废话
我告诉大家,这些还真不是废话,代码很重要,手写代码,copy。我可能做为一个过来人,很多项目都做过,很多技术都用过,也做过。
比较我的角度,去给大家讲一讲,行业,一些技术领域的问题
62_讲给Java工程师的史上最通俗易懂Storm教程:大白话介绍
这块给大家解释一下,就是说,有些技术我们可能就是简单带着大家去用一下就好了
nginx,java,一般都会一些
kafka,zookeeper,lua,我觉得,那些东西的话,主要是讲解基于他们的一些架构,和解决方案的设计还有开发
redis:跟我们的这个topic是很有关系的,大型缓存架构,高并发高性能高可用的缓存架构的底层支持,redis,细致的去讲解,那块redis技术和知识是本套课程的一个重点
数据库+缓存双写,多级缓存架构,大家重点去理解里面的方案设计和架构思想
热数据的处理,缓存雪崩 --> storm,hystrix
对于这两个技术,都是关键性的会去影响你的热数据,缓存雪崩时的系统可用性和稳定性
对这两个技术,storm,hystrix,都很重要
会类似redis,花费较多的篇幅去给大家讲解一下,让大家可以把这两个技术同时也学习的非常好
正好跟着我们的大的项目实战在走,学完以后,直接可以学以致用,用到我们的系统架构中去
kafka,消息队列,用起来很简单,而且搞java得一般来说,对消息队列都有一些了解吧,而且到了真实的生产环境中,kafka你是可以换成其他的技术,Active MQ,Rabbit MQ,Rocket MQ
zookeeper,分布式锁,分布式锁,搞java一般也会知道一些,zk去做,redis去做锁也是可以的
lua,大家后面真的是要用到lua,觉得课程里讲解的东西不够,可以自己去网上查一些lua的语法可以了,语法是最最简单的
storm,说句实话,在做热数据这块,如果要做复杂的热数据的统计和分析,亿流量,高并发的场景下,我还真觉得,最合适的技术就是storm,没有其他
缓存架构,热数据先关的架构设计,热数据相关的架构中最重要的唯一的可选技术,storm,好好的去讲一下的
hystrix,分布式系统的高可用性的限流,熔断,降级,等等,一些措施,缓存雪崩的方案,限流的技术
讲给Java工程师的史上最通俗易懂Storm教程
讲给Java工程师:我知道你没什么大数据的背景和经验,基础,那么我就把你当做一个大数据小白,主要是java背景和基础
史上最通俗易懂:市面上其他的storm视频课程,或者是一些书籍,我告诉,storm还是挺难的,事务,云里雾里,云里雾里
搞storm大数据的,连这个并行度和流分组的本质它都说不清楚,因为市面上的资料也说不清楚
会把你当做小白,用最最通俗易懂的语言,给你去讲解这块的知识,画图
一、Storm到底是什么?
1、mysql,hadoop与storm
mysql:事务性系统,面临海量数据的尴尬
hadoop:离线批处理
storm:实时计算
2、我们能不能自己搞一套storm?
来一条数据,我理解就算一条,来一条,算一条
坑,海量高并发大数据,高并发的请求数据,分布式的系统,流式处理的分布式系统
如果自己搞一套实时流系统出来,也是可以的,但是。。。。
(1)花费大量的时间在底层技术细节上:如何部署各种中间队列,节点间的通信,容错,资源调配,计算节点的迁移和部署,等等
(2)花费大量的时间在系统的高可用上问题上:如何保证各种节点能够高可用稳定运行
(3)花费大量的时间在系统扩容上:吞吐量需要扩容的时候,你需要花费大量的时间去增加节点,修改配置,测试,等等
5万/s,10万/s,扩容
国内,国产的实时大数据计算系统,唯一做出来的,做得好的,做得影响力特别大,特别牛逼的,就是JStorm,阿里
阿里,技术实力,世界一流,顶尖,国内顶尖,一流
JStorm,clojure编程预压,Java重新写了一遍,Galaxy流式计算的系统,百度,腾讯,也都自己做了,也能做得很好
3、storm的特点是什么?
(1)支撑各种实时类的项目场景:实时处理消息以及更新数据库,基于最基础的实时计算语义和API(实时数据处理领域);对实时的数据流持续的进行查询或计算,同时将最新的计算结果持续的推送给客户端展示,同样基于最基础的实时计算语义和API(实时数据分析领域);对耗时的查询进行并行化,基于DRPC,即分布式RPC调用,单表30天数据,并行化,每个进程查询一天数据,最后组装结果
storm做各种实时类的项目都ok
(2)高度的可伸缩性:如果要扩容,直接加机器,调整storm计算作业的并行度就可以了,storm会自动部署更多的进程和线程到其他的机器上去,无缝快速扩容
扩容起来,超方便
(3)数据不丢失的保证:storm的消息可靠机制开启后,可以保证一条数据都不丢
数据不丢失,也不重复计算
(4)超强的健壮性:从历史经验来看,storm比hadoop、spark等大数据类系统,健壮的多的多,因为元数据全部放zookeeper,不在内存中,随便挂都不要紧
特别的健壮,稳定性和可用性很高
(5)使用的便捷性:核心语义非常的简单,开发起来效率很高
用起来很简单,开发API还是很简单的
63讲给Java工程师的史上最通俗易懂Storm教程:大白话讲集群架构与核心概念
大白话讲解
二、Storm的集群架构以及核心概念
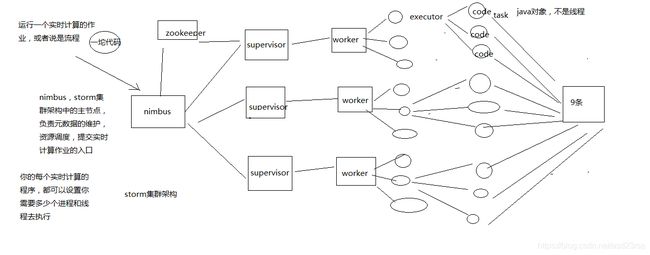
1、Storm的集群架构
Nimbus,Supervisor,ZooKeeper,Worker,Executor,Task
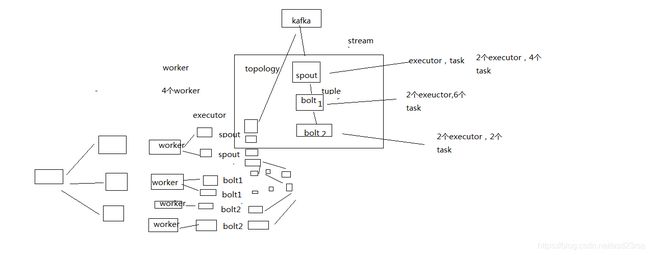
2、Storm的核心概念
Topology,Spout,Bolt,Tuple,Stream
拓扑:务虚的一个概念
Spout:数据源的一个代码组件,就是我们可以实现一个spout接口,写一个java类,在这个spout代码中,我们可以自己尝试去数据源获取数据,比如说从kafka中消费数据
bolt:一个业务处理的代码组件,spout会将数据传送给bolt,各种bolt还可以串联成一个计算链条,java类实现了一个bolt接口
一堆spout+bolt,就会组成一个topology,就是一个拓扑,实时计算作业,spout+bolt,一个拓扑涵盖数据源获取/生产+数据处理的所有的代码逻辑,topology
tuple:就是一条数据,每条数据都会被封装在tuple中,在多个spout和bolt之间传递
stream:就是一个流,务虚的一个概念,抽象的概念,源源不断过来的tuple,就组成了一条数据流
64讲给Java工程师的史上最通俗易懂Storm教程:大白话讲并行度和流分组
三、Storm的并行度以及流分组
因为我们在这里,是讲给java工程师的storm教程
所以我期望的场景是,你们所在的公司,基本上来说,已经有大数据团队,有人在维护storm集群
我觉得,对于java工程师来说,先不说精通storm
至少说,对storm的核心的基本原理,门儿清,你都很清楚,集群架构、核心概念、并行度和流分组
接下来,掌握最常见的storm开发范式,spout消费kafka,后面跟一堆bolt,bolt之间设定好流分组的策略
在bolt中填充各种代码逻辑
了解如何将storm拓扑打包后提交到storm集群上去运行
掌握如何能够通过storm ui去查看你的实时计算拓扑的运行现状
你在一个公司里,如果说,需要在你的java系统架构中,用到一些类似storm的大数据技术,如果已经有人维护了storm的集群
那么此时你就可以直接用,直接掌握如何开发和部署即可
但是,当然了,如果说,恰巧没人负责维护storm集群,也没什么大数据的团队,那么你可能需要说再去深入学习一下storm
当然了,如果你的场景不是特别复杂,整个数据量也不是特别大,其实自己主要研究一下,怎么部署storm集群
你自己部署一个storm集群,也ok
好多年前,我第一次接触storm的时候,真的,我觉得都没几个人能彻底讲清楚,用一句话讲清楚什么是并行度,什么是流分组
很多时候,你以外你明白了,其实你不明白
比如我经常面试一些做过storm的人过来,我就问一个问题,就知道它的水深水浅,流分组的时候,数据在storm集群中的流向,你画一下
比如你自己随便设想一个拓扑结果出来,几个spout,几个bolt,各种流分组情况下,数据是怎么流向的,要求具体画出集群架构中的流向
worker,executor,task,supervisor,流的
几乎没几个人能画对,为什么呢,很多人就没搞明白这个并行度和流分组到底是什么
并行度:Worker->Executor->Task,没错,是Task
流分组:Task与Task之间的数据流向关系
Shuffle Grouping:随机发射,负载均衡
Fields Grouping:根据某一个,或者某些个,fields,进行分组,那一个或者多个fields如果值完全相同的话,那么这些tuple,就会发送给下游bolt的其中固定的一个task
你发射的每条数据是一个tuple,每个tuple中有多个field作为字段
比如tuple,3个字段,name,age,salary
{"name": "tom", "age": 25, "salary": 10000} -> tuple -> 3个field,name,age,salary
All Grouping
Global Grouping
None Grouping
Direct Grouping
Local or Shuffle Grouping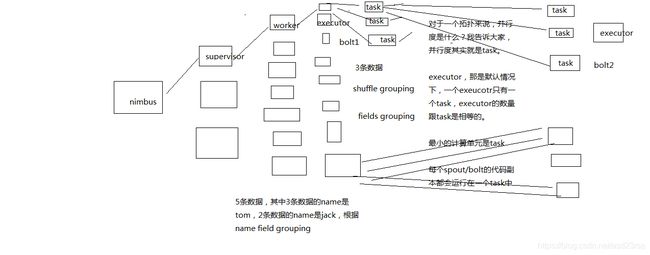
65_讲给Java工程师的史上最通俗易懂Storm教程:纯手敲WordCount程序
storm核心的基本原理,都了解了
写一下代码,去体验一下,storm的程序是怎么开发的,通过了解了代码之后,再回头,你去看一下之前讲解的一些基本原理,就很清楚了
大数据,入门程序,wordcount,单词计数
你可以认为,storm源源不断的接收到一些句子,然后你需要实时的统计出句子中每个单词的出现次数
(1)搭建工程环境
(2)编写代码
package com.roncoo.eshop.storm;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 单词计数拓扑
*
* 我认识很多java工程师,都是会一些大数据的技术的,不会太精通,没有那么多的时间去研究
* storm的课程,我就只是讲到,最基本的开发,就够了,java开发广告计费系统,大量的流量的引入和接入,就是用storm做得
* 用storm,主要是用它的成熟的稳定的易于扩容的分布式系统的特性
* java工程师,来说,做一些简单的storm开发,掌握到这个程度差不多就够了
*
* @author Administrator
*
*/
public class WordCountTopology {
/**
* spout
*
* spout,继承一个基类,实现接口,这个里面主要是负责从数据源获取数据
*
* 我们这里作为一个简化,就不从外部的数据源去获取数据了,只是自己内部不断发射一些句子
*
* @author Administrator
*
*/
public static class RandomSentenceSpout extends BaseRichSpout {
private static final long serialVersionUID = 3699352201538354417L;
private static final Logger LOGGER = LoggerFactory.getLogger(RandomSentenceSpout.class);
private SpoutOutputCollector collector;
private Random random;
/**
* open方法
*
* open方法,是对spout进行初始化的
*
* 比如说,创建一个线程池,或者创建一个数据库连接池,或者构造一个httpclient
*
*/
@SuppressWarnings("rawtypes")
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
// 在open方法初始化的时候,会传入进来一个东西,叫做SpoutOutputCollector
// 这个SpoutOutputCollector就是用来发射数据出去的
this.collector = collector;
// 构造一个随机数生产对象
this.random = new Random();
}
/**
* nextTuple方法
*
* 这个spout类,之前说过,最终会运行在task中,某个worker进程的某个executor线程内部的某个task中
* 那个task会负责去不断的无限循环调用nextTuple()方法
* 只要的话呢,无限循环调用,可以不断发射最新的数据出去,形成一个数据流
*
*/
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{"the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"};
String sentence = sentences[random.nextInt(sentences.length)];
LOGGER.info("【发射句子】sentence=" + sentence);
// 这个values,你可以认为就是构建一个tuple
// tuple是最小的数据单位,无限个tuple组成的流就是一个stream
collector.emit(new Values(sentence));
}
/**
* declareOutputFielfs这个方法
*
* 很重要,这个方法是定义一个你发射出去的每个tuple中的每个field的名称是什么
*
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}
/**
* 写一个bolt,直接继承一个BaseRichBolt基类
*
* 实现里面的所有的方法即可,每个bolt代码,同样是发送到worker某个executor的task里面去运行
*
* @author Administrator
*
*/
public static class SplitSentence extends BaseRichBolt {
private static final long serialVersionUID = 6604009953652729483L;
private OutputCollector collector;
/**
* 对于bolt来说,第一个方法,就是prepare方法
*
* OutputCollector,这个也是Bolt的这个tuple的发射器
*
*/
@SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* execute方法
*
* 就是说,每次接收到一条数据后,就会交给这个executor方法来执行
*
*/
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words) {
collector.emit(new Values(word));
}
}
/**
* 定义发射出去的tuple,每个field的名称
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
public static class WordCount extends BaseRichBolt {
private static final long serialVersionUID = 7208077706057284643L;
private static final Logger LOGGER = LoggerFactory.getLogger(WordCount.class);
private OutputCollector collector;
private Map
@SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = wordCounts.get(word);
if(count == null) {
count = 0L;
}
count++;
wordCounts.put(word, count);
LOGGER.info("【单词计数】" + word + "出现的次数是" + count);
collector.emit(new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
public static void main(String[] args) {
// 在main方法中,会去将spout和bolts组合起来,构建成一个拓扑
TopologyBuilder builder = new TopologyBuilder();
// 这里的第一个参数的意思,就是给这个spout设置一个名字
// 第二个参数的意思,就是创建一个spout的对象
// 第三个参数的意思,就是设置spout的executor有几个
builder.setSpout("RandomSentence", new RandomSentenceSpout(), 2);
builder.setBolt("SplitSentence", new SplitSentence(), 5)
.setNumTasks(10)
.shuffleGrouping("RandomSentence");
// 这个很重要,就是说,相同的单词,从SplitSentence发射出来时,一定会进入到下游的指定的同一个task中
// 只有这样子,才能准确的统计出每个单词的数量
// 比如你有个单词,hello,下游task1接收到3个hello,task2接收到2个hello
// 5个hello,全都进入一个task
builder.setBolt("WordCount", new WordCount(), 10)
.setNumTasks(20)
.fieldsGrouping("SplitSentence", new Fields("word"));
Config config = new Config();
// 说明是在命令行执行,打算提交到storm集群上去
if(args != null && args.length > 0) {
config.setNumWorkers(3);
try {
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
} else {
// 说明是在eclipse里面本地运行
config.setMaxTaskParallelism(20);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCountTopology", config, builder.createTopology());
Utils.sleep(60000);
cluster.shutdown();
}
}
}
66_讲给Java工程师的史上最通俗易懂Storm教程:纯手工集群部署
讲了手写了storm wordcount程序
蕴含了很多的知识点
(1)Spout
(2)Bolt
(3)OutputCollector,Declarer
(4)Topology
(5)设置worker,executor,task,流分组
storm的核心基本原理,基本的开发,学会了
storm集群部署,怎么将storm的拓扑扔到storm集群上去跑
六、部署一个storm集群
(1)安装Java 7和Pythong 2.6.6
(2)下载storm安装包,解压缩,重命名,配置环境变量
vi .bashrc
(3)修改storm配置文件
mkdir /var/storm
conf/storm.yaml
storm.zookeeper.servers:
- "111.222.333.444"
- "555.666.777.888"
storm.local.dir: "/mnt/storm"
nimbus.seeds: ["111.222.333.44"]
slots.ports,指定每个机器上可以启动多少个worker,一个端口号代表一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
(4)启动storm集群和ui界面
一个节点,storm nimbus >/dev/null 2>&1 &
三个节点,storm supervisor >/dev/null 2>&1 &
三个节点,storm ui >/dev/null 2>&1 &
需要启动日志 storm logviewer >/dev/null 2>&1 &
(5)访问一下ui界面,8080端口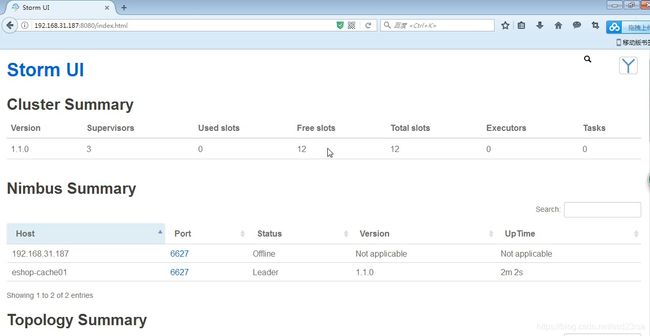
67_讲给Java工程师的史上最通俗易懂Storm教程:基于集群运行计算拓扑
七、提交作业到storm集群来运行
将eclipse中的工程,进行打包
(1)提交作业到storm集群
storm jar path/to/allmycode.jar org.me.MyTopology arg1 arg2 arg3
(2)在storm ui上观察storm作业的运行
(3)kill掉某个storm作业
storm kill topology-name
缓存冷启动的问题
新系统第一次上线,此时在缓存里可能是没有数据的
系统在线上稳定运行着,但是突然间重要的redis缓存全盘崩溃了,而且不幸的是,数据全都无法找回来
系统第一次上线启动,系统在redis故障的情况下重新启动,在高并发的场景下
69_缓存预热解决方案:基于storm实时热点统计的分布式并行缓存预热
0、缓存预热
缓存冷启动,redis启动后,一点数据都没有,直接就对外提供服务了,mysql就裸奔
(1)提前给redis中灌入部分数据,再提供服务
(2)肯定不可能将所有数据都写入redis,因为数据量太大了,第一耗费的时间太长了,第二根本redis容纳不下所有的数据
(3)需要根据当天的具体访问情况,实时统计出访问频率较高的热数据
(4)然后将访问频率较高的热数据写入redis中,肯定是热数据也比较多,我们也得多个服务并行读取数据去写,并行的分布式的缓存预热
(5)然后将灌入了热数据的redis对外提供服务,这样就不至于冷启动,直接让数据库裸奔了
1、nginx+lua将访问流量上报到kafka中
要统计出来当前最新的实时的热数据是哪些,我们就得将商品详情页访问的请求对应的流浪,日志,实时上报到kafka中
2、storm从kafka中消费数据,实时统计出每个商品的访问次数,访问次数基于LRU内存数据结构的存储方案
优先用内存中的一个LRUMap去存放,性能高,而且没有外部依赖
我之前做过的一些项目,不光是这个项目,还有很多其他的,一些广告计费类的系统,storm
否则的话,依赖redis,我们就是要防止redis挂掉数据丢失的情况,就不合适了; 用mysql,扛不住高并发读写; 用hbase,hadoop生态系统,维护麻烦,太重了
其实我们只要统计出最近一段时间访问最频繁的商品,然后对它们进行访问计数,同时维护出一个前N个访问最多的商品list即可
热数据,最近一段时间,可以拿到最近一段,比如最近1个小时,最近5分钟,1万个商品请求,统计出最近这段时间内每个商品的访问次数,排序,做出一个排名前N的list
计算好每个task大致要存放的商品访问次数的数量,计算出大小
然后构建一个LRUMap,apache commons collections有开源的实现,设定好map的最大大小,就会自动根据LRU算法去剔除多余的数据,保证内存使用限制
即使有部分数据被干掉了,然后下次来重新开始计数,也没关系,因为如果它被LRU算法干掉,那么它就不是热数据,说明最近一段时间都很少访问了
3、每个storm task启动的时候,基于zk分布式锁,将自己的id写入zk同一个节点中
4、每个storm task负责完成自己这里的热数据的统计,每隔一段时间,就遍历一下这个map,然后维护一个前3个商品的list,更新这个list
5、写一个后台线程,每隔一段时间,比如1分钟,都将排名前3的热数据list,同步到zk中去,存储到这个storm task对应的一个znode中去
6、我们需要一个服务,比如说,代码可以跟缓存数据生产服务放一起,但是也可以放单独的服务
服务可能部署了很多个实例
每次服务启动的时候,就会去拿到一个storm task的列表,然后根据taskid,一个一个的去尝试获取taskid对应的znode的zk分布式锁
如果能获取到分布式锁的话,那么就将那个storm task对应的热数据的list取出来
然后将数据从mysql中查询出来,写入缓存中,进行缓存的预热,多个服务实例,分布式的并行的去做,基于zk分布式锁做了协调了,分布式并行缓存的预热
70_基于nginx+lua完成商品详情页访问流量实时上报kafka的开发
在nginx这一层,接收到访问请求的时候,就把请求的流量上报发送给kafka
这样的话,storm才能去消费kafka中的实时的访问日志,然后去进行缓存热数据的统计
用得技术方案非常简单,从lua脚本直接创建一个kafka producer,发送数据到kafka
wget https://github.com/doujiang24/lua-resty-kafka/archive/master.zip
yum install -y unzip
unzip lua-resty-kafka-master.zip
cp -rf /usr/local/lua-resty-kafka-master/lib/resty /usr/hello/lualib
nginx -s reload
vi product.lua
local cjson = require("cjson")
local producer = require("resty.kafka.producer")
local broker_list = {
{ host = "192.168.31.187", port = 9092 },
{ host = "192.168.31.19", port = 9092 },
{ host = "192.168.31.227", port = 9092 }
}
local log_json = {}
log_json["headers"] = ngx.req.get_headers()
log_json["uri_args"] = ngx.req.get_uri_args()
log_json["body"] = ngx.req.read_body()
log_json["http_version"] = ngx.req.http_version()
log_json["method"] =ngx.req.get_method()
log_json["raw_reader"] = ngx.req.raw_header()
log_json["body_data"] = ngx.req.get_body_data()
local message = cjson.encode(log_json);
local productId = ngx.req.get_uri_args()["productId"]
local async_producer = producer:new(broker_list, { producer_type = "async" })
local ok, err = async_producer:send("access-log", productId, message)
if not ok then
ngx.log(ngx.ERR, "kafka send err:", err)
return
end
两台机器上都这样做,才能统一上报流量到kafka
bin/kafka-topics.sh --zookeeper 192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181 --topic access-log --replication-factor 1 --partitions 1 --create
bin/kafka-console-consumer.sh --zookeeper 192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181 --topic access-log --from-beginning
(1)kafka在187上的节点死掉了,可能是虚拟机的问题,杀掉进程,重新启动一下
nohup bin/kafka-server-start.sh config/server.properties &
(2)需要在nginx.conf中,http部分,加入resolver 8.8.8.8;
(3)需要在kafka中加入advertised.host.name = 192.168.31.187,重启三个kafka进程
(4)需要启动eshop-cache缓存服务,因为nginx中的本地缓存可能不在了
71_基于storm+kafka完成商品访问次数实时统计拓扑的开发
maven构建出的一些问题,直接从maven中央仓库可能下载不到jar包,自己去百度一下jar,下载下来
根据错误提示,拷贝到maven本地仓库对应的目录中去,然后手工安装一下
1、kafka consumer spout
单独的线程消费,写入队列
nextTuple,每次都是判断队列有没有数据,有的话再去获取并发射出去,不能阻塞
2、日志解析bolt
3、商品访问次数统计bolt
基于LRUMap完成统计
72_基于storm完成LRUMap中topn热门商品列表的算法讲解与编写
1、storm task启动的时候,基于分布式锁将自己的taskid累加到一个znode中
2、开启一个单独的后台线程,每隔1分钟算出top3热门商品list
3、每个storm task将自己统计出的热数据list写入自己对应的znode中
73_基于storm+zookeeper完成热门商品列表的分段存储
1、task初始化
2、热门商品list保存
74_基于双重zookeeper分布式锁完成分布式并行缓存预热的代码开发
1、服务启动的时候,进行缓存预热
2、从zk中读取taskid列表
3、依次遍历每个taskid,尝试获取分布式锁,如果获取不到,快速报错,不要等待,因为说明已经有其他服务实例在预热了
4、直接尝试获取下一个taskid的分布式锁
5、即使获取到了分布式锁,也要检查一下这个taskid的预热状态,如果已经被预热过了,就不再预热了
6、执行预热操作,遍历productid列表,查询数据,然后写ehcache和redis
7、预热完成后,设置taskid对应的预热状态
76_热点缓存问题:促销抢购时的超级热门商品可能导致系统全盘崩溃的场景
热数据 -> 热数据的统计 -> redis中缓存的预热 -> 避免新系统刚上线,或者是redis崩溃数据丢失后重启,redis中没有数据,redis冷启动 -> 大量流量直接到数据库
redis启动前,必须确保其中是有部分热数据的缓存的
瞬间的缓存热点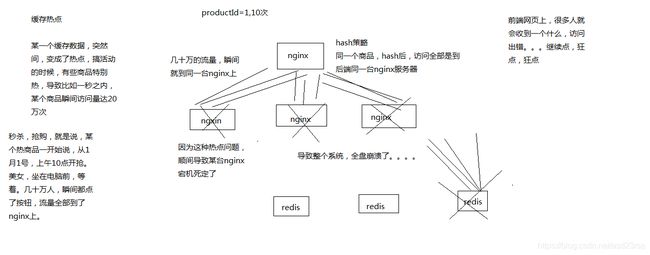
77_基于nginx+lua+storm的热点缓存的流量分发策略自动降级解决方案
1、在storm中,实时的计算出瞬间出现的热点
有很多种算法,给大家介绍一种我们的比较简单的算法
某个storm task,上面算出了1万个商品的访问次数,LRUMap
频率高一些,每隔5秒,去遍历一次LRUMap,将其中的访问次数进行排序,统计出往后排的95%的商品访问次数的平均值
1000
999
888
777
666
50
60
80
100
120
比如说,95%的商品,访问次数的平均值是100
然后,从最前面开始,往后遍历,去找有没有瞬间出现的热点数据
1000,95%的平均值(100)的10倍,这个时候要设定一个阈值,比如说超出95%平均值得n倍,5倍
我们就认为是瞬间出现的热点数据,判断其可能在短时间内继续扩大的访问量,甚至达到平均值几十倍,或者几百倍
当遍历,发现说第一个商品的访问次数,小于平均值的5倍,就安全了,就break掉这个循环
热点数据,热数据,不是一个概念
有100个商品,前10个商品比较热,都访问量在500左右,其他的普通商品,访问量都在200左右,就说前10个商品是热数据
统计出来
预热的时候,将这些热数据放在缓存中去预热就可以了
热点,前面某个商品的访问量,瞬间超出了普通商品的10倍,或者100倍,1000倍,热点
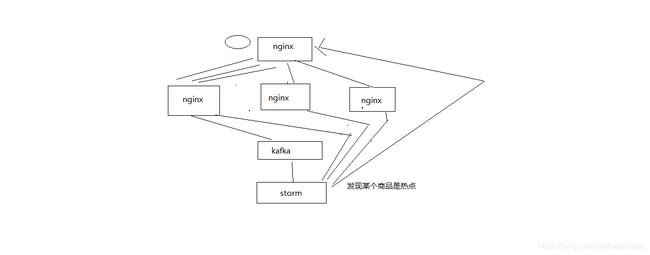
2、storm这里,会直接发送http请求到nginx上,nginx上用lua脚本去处理这个请求
storm会将热点本身对应的productId,发送到流量分发的nginx上面去,放在本地缓存中
storm会将热点对应的完整的缓存数据,发送到所有的应用nginx服务器上去,直接放在本地缓存中
3、流量分发nginx的分发策略降级
流量分发nginx,加一个逻辑,就是每次访问一个商品详情页的时候,如果发现它是个热点,那么立即做流量分发策略的降级
hash策略,同一个productId的访问都同一台应用nginx服务器上
降级成对这个热点商品,流量分发采取随机负载均衡发送到所有的后端应用nginx服务器上去
瞬间将热点缓存数据的访问,从hash分发,全部到一台nginx,变成了,负载均衡发送到多台nginx上去
避免说大量的流量全部集中到一台机器,50万的访问量到一台nginx,5台应用nginx,每台就可以承载10万的访问量
4、storm还需要保存下来上次识别出来的热点list
下次去识别的时候,这次的热点list跟上次的热点list做一下diff,看看可能有的商品已经不是热点了
热点的取消的逻辑,发送http请求到流量分发的nginx上去,取消掉对应的热点数据,从nginx本地缓存中,删除
78_在storm拓扑中加入热点缓存实时自动识别和感知的
79_在storm拓扑中加入nginx反向推送缓存热点与缓存数据的代码逻辑
80_在流量分发+后端应用双层nginx中加入接收热点缓存数据的接口
流量分发
新开nginx接口
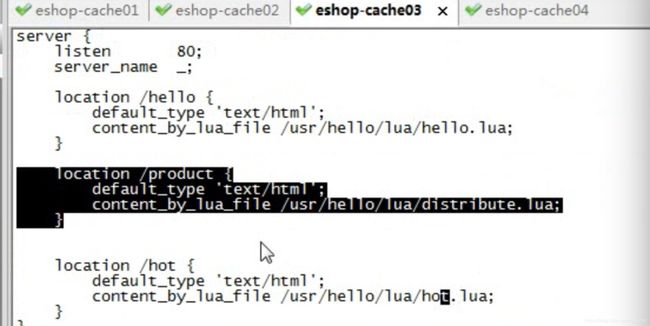
vi hot.lua
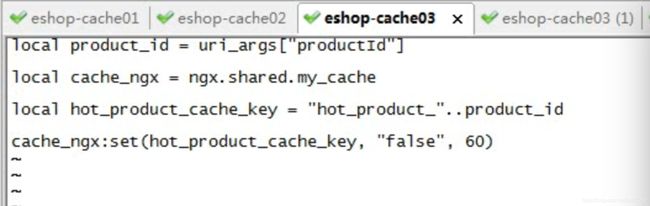
local uri_args = ngx.req.get_uri_args()
local product_id = uri_args["productId"]
local cache_ngx = ngx.shared.my_cache
local hot_product_cache_key = "hot_product_"..product_id
cache_ngx:set(hot_product_cache_key, "true", 60 * 60)
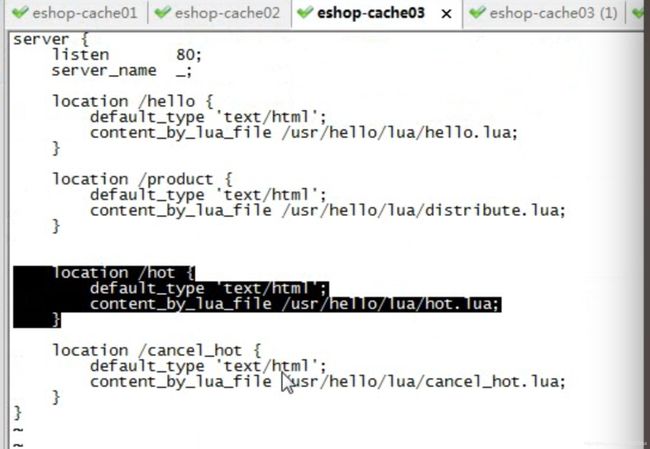
后端应用
local uri_args = ngx.req.get_uri_args()
local product_id = uri_args["productId"]
local product_info = uri_args["productInfo"]
local product_cache_key = "product_info_"..product_id
local cache_ngx = ngx.shared.my_cache
cache_ngx:set(product_cache_key,product_info,60 * 60)
81_在nginx+lua中实现热点缓存自动降级为负载均衡流量分发策略的逻辑
流量分发nginx
math.randomseed(tostring(os.time()):reverse():sub(1, 7))
math.random(1, 2)
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local shopId = uri_args["shopId"]
local hosts = {"192.168.31.187", "192.168.31.19"}
local backend = ""
local hot_product_key = "hot_product_"..productId
local cache_ngx = ngx.shared.my_cache
local hot_product_flag = cache_ngx:get(hot_product_key)
if hot_product_flag == "true" then
math.randomseed(tostring(os.time()):reverse():sub(1, 7))
local index = math.random(1, 2)
backend = "http://"..hosts[index]
else
local hash = ngx.crc32_long(productId)
local index = (hash % 2) + 1
backend = "http://"..hosts[index]
end
local requestPath = uri_args["requestPath"]
requestPath = "/"..requestPath.."?productId="..productId.."&shopId="..shopId
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri(backend,{
method = "GET",
path = requestPath
})
if not resp then
ngx.say("request error: ", err)
return
end
ngx.say(resp.body)
httpc:close()
82_在storm拓扑中加入热点缓存消失的实时自动识别和感知的代码逻辑
1、storm中打印日志
2、重新部署storm拓扑
3、nginx中修改html模板
4、手动构造出一个热点缓存出来,看热点缓存能否进行负载均衡
5、手动让热点缓存消失,看热点缓存能否自动小时,重新进行hash分发
http://192.168.31.187/hot?productId=15&productInfo={"id":15,"name":"iphone7手机","price":5599.0,"pictureList":"a.jpg,b.jpg","specification":"iphone7的规格","service":"iphone7的售后服务","color":"红色,白色,黑色","size":"5.5","shopId":1,"modifiedTime":"2017-01-01 12:01:00"}