模型涨点的思路,深度学习训练的tricks-计算机视觉
-
一项机器学习任务时常常有以下的几个重要步骤,
-
首先是数据的预处理,其中重要的步骤包括数据格式的统一、异常数据的消除和必要的数据变换;
-
然后划分训练集、验证集、测试集,常见的方法包括:按比例随机选取,KFold方法(我们可以使用sklearn带的test_train_split函数、kfold来实现)。
-
选择模型,并设定损失函数和优化方法,以及对应的超参数(当然可以使用sklearn这样的机器学习库中模型自带的损失函数和优化器)。
-
最后用模型去拟合训练集数据,并在验证集/测试集上计算模型表现。
-
-
深度学习和机器学习在流程上类似,但在代码实现上有较大的差异。首先,由于深度学习所需的样本量很大,一次加载全部数据运行可能会超出内存容量而无法实现;同时还有批(batch)训练等提高模型表现的策略,需要每次训练读取固定数量的样本送入模型中训练,因此深度学习在数据加载上需要有专门的设计。
-
在模型实现上,深度学习和机器学习也有很大差异。由于深度神经网络层数往往较多,同时会有一些用于实现特定功能的层(如卷积层、池化层、批正则化层、LSTM层等),因此深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来。这种“定制化”的模型构建方式能够充分保证模型的灵活性。
-
上述步骤完成后就可以开始训练了。我们前面介绍了GPU的概念和GPU用于并行计算加速的功能,不过程序默认是在CPU上运行的,因此在代码实现中,需要把模型和数据“放到”GPU上去做运算,同时还需要保证损失函数和优化器能够在GPU上工作。如果使用多张GPU进行训练,还需要考虑模型和数据分配、整合的问题。此外,后续计算一些指标还需要把数据“放回”CPU。这里涉及到了一系列有关于GPU的配置和操作。
-
深度学习中训练和验证过程最大的特点在于读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
-
对于一个PyTorch项目,我们需要导入一些Python常用的包来帮助我们快速实现功能。常见的包有os、numpy等,此外还需要调用PyTorch自身一些模块便于灵活使用,比如torch、torch.nn、torch.utils.data.Dataset、torch.utils.data.DataLoader、torch.optimizer等等。
-
import os import numpy as np import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader import torch.optim as optimizer # 根据前面我们对深度学习任务的梳理,有如下几个超参数可以统一设置,方便后续调试时修改: batch_size = 16 # 批次的大小 lr = 1e-4 # 优化器的学习率 max_epochs = 100 # 制定GPU 方案一: os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指明调用的GPU为0,1号 # 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可 device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号
-
-
PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。可以定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
-
__init__: 用于向类中传入外部参数,同时定义样本集 -
__getitem__: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据 -
__len__: 用于返回数据集的样本数 -
给出一个例子,其中图片存放在一个文件夹,另外有一个csv文件给出了图片名称对应的标签。这种情况下需要自己来定义Dataset类:
-
class MyDataset(Dataset): def __init__(self, data_dir, info_csv, image_list, transform=None): """ Args: data_dir: path to image directory. info_csv: path to the csv file containing image indexes with corresponding labels. image_list: path to the txt file contains image names to training/validation set transform: optional transform to be applied on a sample. """ label_info = pd.read_csv(info_csv) image_file = open(image_list).readlines() self.data_dir = data_dir self.image_file = image_file self.label_info = label_info self.transform = transform def __getitem__(self, index): """ Args: index: the index of item Returns: image and its labels """ image_name = self.image_file[index].strip('\n') raw_label = self.label_info.loc[self.label_info['Image_index'] == image_name] label = raw_label.iloc[:,0] image_name = os.path.join(self.data_dir, image_name) image = Image.open(image_name).convert('RGB') if self.transform is not None: image = self.transform(image) return image, label def __len__(self): return len(self.image_file)
-
-
构建好Dataset后,就可以使用DataLoader来按批次读入数据了,实现代码如下:
-
from torch.utils.data import DataLoader train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True) val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False) -
-
batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数
-
num_workers:有多少个进程用于读取数据,Windows下该参数设置为0,Linux下常见的为4或者8,根据自己的电脑配置来设置
-
shuffle:是否将读入的数据打乱,一般在训练集中设置为True,验证集中设置为False
-
drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
-
AI performance = data(70%) + model(CNN、RNN、Transformer、Bert、GPT 20%) + trick(loss、warmup、optimizer、attack-training etc 10%) 记住:数据决定了AI的上线,模型和trick只是去逼近这个上线,还是那句老话:garbage in, garbage out。—昆特Alex
-
-
尝试模型初始化方法,不同的分布,分布参数。
-
在深度学习模型的训练中,权重的初始值极为重要。一个好的初始值,会使模型收敛速度提高,使模型准确率更精确。一般情况下,我们不使用全0初始值训练网络。为了利于训练和减少收敛时间,我们需要对模型进行合理的初始化。PyTorch也在
torch.nn.init中为我们提供了常用的初始化方法。torch.nn.init — PyTorch 1.13 documentation -
众所周知,训练的开始(即前几次迭代)非常重要。 如果做得不当,你会得到不好的结果 - 有时候,网络根本就不会学到任何东西! 因此,初始化神经网络权重的方式是良好训练的关键因素之一。
-
神经网络训练基本上包括重复以下两个步骤:
-
一个前向步骤,包括权重和输入/激活函数之间的大量矩阵乘法(我们称激活函数为一个层的输出,它将成为下一层的输入,即隐藏层的激活函数结果)
-
反向传播步骤,包括更新网络权重以最小化损失函数(使用参数的梯度)
-
-
“Xavier初始化”,2010年在论文“Understanding the difficulty of training deep feedforward neural networks”中提出,Xavier的初始化是通过从标准正态分布中选择权重来完成的,每个元素都要除以输入维度大小的平方根。Xavier的初始化工作相当好,对于对称非线性,如sigmoid和Tanh。然而,对于目前最常用的非线性函数ReLu,它的工作效果并不理想。xavier初始化方法中服从均匀分布U(−a,a) ,分布的参数a = gain * sqrt(6/fan_in+fan_out),这里有一个gain,增益的大小是依据激活函数类型来设定
-
for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): nn.init.xavier_uniform_(m.weight) # 也可以使用 gain 参数来自定义初始化的标准差来匹配特定的激活函数: for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): nn.init.xavier_uniform_(m.weight(), gain=nn.init.calculate_gain('relu'))
-
-
2015年在“Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”一文中提出的“Kaiming初始化”
-
for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): nn.init.kaiming_normal_(m.weight, mode='fan_in')
-
-
实际上,这两种方案非常相似:“主要”区别在于Kaiming初始化考虑了每次矩阵乘法后的ReLU激活函数。
-
正交初始化(Orthogonal Initialization),主要用以解决深度网络下的梯度消失、梯度爆炸问题,在RNN中经常使用的参数初始化方法。
-
for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): nn.init.orthogonal(m.weight)
-
-
模型初始化
-
def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv2d') != -1: nn.init.xavier_normal_(m.weight.data) nn.init.constant_(m.bias.data, 0.0) elif classname.find('Linear') != -1: nn.init.xavier_normal_(m.weight) nn.init.constant_(m.bias, 0.0) net = Net() net.apply(weights_init) #apply函数会递归地搜索网络内的所有module并把参数表示的函数应用到所有的module上。 # 常常将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。(自定义初始化函数) # 这段代码流程是遍历当前模型的每一层,然后判断各层属于什么类型,然后根据不同类型层,设定不同的权值初始化方法。 def initialize_weights(self): for m in self.modules(): # 判断是否属于Conv2d if isinstance(m, nn.Conv2d): torch.nn.init.xavier_normal_(m.weight.data) # 判断是否有偏置 if m.bias is not None: torch.nn.init.constant_(m.bias.data,0.3) elif isinstance(m, nn.Linear): torch.nn.init.normal_(m.weight.data, 0.1) if m.bias is not None: torch.nn.init.zeros_(m.bias.data) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zeros_() # 模型的定义,可尝试初始化下面的MLP网络 class MLP(nn.Module): # 声明带有模型参数的层,这里声明了两个全连接层 def __init__(self, **kwargs): # 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数 super(MLP, self).__init__(**kwargs) self.hidden = nn.Conv2d(1,1,3) self.act = nn.ReLU() self.output = nn.Linear(10,1) # 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出 def forward(self, x): o = self.act(self.hidden(x)) return self.output(o) mlp = MLP() print(list(mlp.parameters())) print("-------初始化-------") initialize_weights(mlp) print(list(mlp.parameters()))
-
-
Mishkin等人在2016年的一篇论文《All you need is a good Init》中介绍了LSUV。LSUV Init是一种数据驱动的方法,它具有最小的计算量和非常低的计算开销。初始化是一个2部分的过程,首先初始化标准正交矩阵的权值(与高斯噪声相反,它只是近似正交)。下一部分是迭代一个小批处理并缩放权重,以便激活的方差为1。作者断言,在大范围内,小批量大小对方差的影响可以忽略不计。
-
使用单位方差将权重初始化为高斯噪声。
-
使用SVD或QR将它们分解为正交坐标。
-
使用第一个微型批处理在网络中进行迭代,并在每次迭代比例时权重以使输出方差接近1。重复直到输出方差为1或发生最大迭代。
-
-
上文的gain值是可以通过torch.nn.init.calculate_gain(nonlinearity, param=None)计算的,关于计算增益如下表:
-
1 . torch.nn.init.uniform_(tensor, a=0.0, b=1.0) 2 . torch.nn.init.normal_(tensor, mean=0.0, std=1.0) 3 . torch.nn.init.constant_(tensor, val) 4 . torch.nn.init.ones_(tensor) 5 . torch.nn.init.zeros_(tensor) 6 . torch.nn.init.eye_(tensor) 7 . torch.nn.init.dirac_(tensor, groups=1) 8 . torch.nn.init.xavier_uniform_(tensor, gain=1.0) 9 . torch.nn.init.xavier_normal_(tensor, gain=1.0) 10 . torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan__in', nonlinearity='leaky_relu') 11 . torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu') 12 . torch.nn.init.orthogonal_(tensor, gain=1) 13 . torch.nn.init.sparse_(tensor, sparsity, std=0.01) 14 . torch.nn.init.calculate_gain(nonlinearity, param=None) -
可以发现这些函数除了
calculate_gain,所有函数的后缀都带有下划线,意味着这些函数将会直接原地更改输入张量的值。
-
-
warmup cosine lr scheduler,先热身(学习率逐渐攀升),再进行余弦衰减。
-
学习率的选择是深度学习中一个困扰人们许久的问题,学习速率设置过小,会极大降低收敛速度,增加训练时间;学习率太大,可能导致参数在最优解两侧来回振荡。但是当我们选定了一个合适的学习率后,经过许多轮的训练后,可能会出现准确率震荡或loss不再下降等情况,说明当前学习率已不能满足模型调优的需求。此时我们就可以通过一个适当的学习率衰减策略来改善这种现象,提高我们的精度。这种设置方式在PyTorch中被称为scheduler。torch.optim — PyTorch 1.13 documentation
-
Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。pytorch提供的学习率调整策略分为三大类,
-
有序调整:等间隔调整(Step),多间隔调整(MultiStep),指数衰减(Exponential),余弦退火(CosineAnnealing);
-
自适应调整:依训练状况伺机而变,通过监测某个指标的变化情况(loss、accuracy),当该指标不怎么变化时,就是调整学习率的时机(ReduceLROnPlateau);
-
自定义调整:通过自定义关于epoch的lambda函数调整学习率(LambdaLR)。
-
-
在训练神经网络的过程中,学习率是最重要的超参数之一,作为当前较为流行的深度学习框架,PyTorch已经在
torch.optim.lr_scheduler为我们封装好了一些动态调整学习率的方法供我们使用,如下面列出的这些scheduler。 -
lr_scheduler.LambdaLR -
lr_scheduler.MultiplicativeLR -
lr_scheduler.StepLR -
lr_scheduler.MultiStepLR -
lr_scheduler.ExponentialLR -
lr_scheduler.CosineAnnealingLR -
lr_scheduler.ReduceLROnPlateau -
lr_scheduler.CyclicLR -
lr_scheduler.OneCycleLR -
lr_scheduler.CosineAnnealingWarmRestarts -
# 选择一种优化器 optimizer = torch.optim.Adam(...) # 选择上面提到的一种或多种动态调整学习率的方法 scheduler1 = torch.optim.lr_scheduler.... scheduler2 = torch.optim.lr_scheduler.... schedulern = torch.optim.lr_scheduler.... # 进行训练 for epoch in range(100): train(...) validate(...) optimizer.step() # 需要在优化器参数更新之后再动态调整学习率 # scheduler的优化是在每一轮后面进行的 scheduler1.step() schedulern.step() -
在使用官方给出的
torch.optim.lr_scheduler时,需要将scheduler.step()放在optimizer.step()后面进行使用。 -
虽然PyTorch官方给我们提供了许多的API,但是在实验中也有可能碰到需要我们自己定义学习率调整策略的情况,而我们的方法是自定义函数
adjust_learning_rate来改变param_group中lr的值,在下面的叙述中会给出一个简单的实现。 -
假设我们现在正在做实验,需要学习率每30轮下降为原来的1/10,假设已有的官方API中没有符合我们需求的,那就需要自定义函数来实现学习率的改变。
-
def adjust_learning_rate(optimizer, epoch): lr = args.lr * (0.1 ** (epoch // 30)) for param_group in optimizer.param_groups: param_group['lr'] = lr def adjust_learning_rate(optimizer,...): ... optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9) for epoch in range(10): train(...) validate(...) adjust_learning_rate(optimizer,epoch) -
批量越大,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,相应地,可以设置较大的学习率。批量较小时,需要设置较小的学习率,否则会影响模型收敛。学习率通常要随着批量大小的增大而相应地增大。线性缩放规则:当批量大小增加m倍,学习率增大m倍
-
-
对抗训练提升模型鲁棒性,方法有很多,我常用的是对抗权重扰动(AWP, AdversarialWeight Perturbation)。
-
对抗训练(Adversarial Training)最初由 Ian Goodfellow 等人提出,作为一种防御对抗攻击的方法,其思路非常简单直接,将生成的对抗样本加入到训练集中去,做一个数据增强,让模型在训练的时候就先学习一遍对抗样本。
-
2018年,Anish Athalye 等人对ICLR中展示的11种对抗防御方法进行了评估,最后他们只在基于对抗训练的两种方法上没有发现混淆梯度的迹象,自此之后,对抗训练成为对抗防御研究的主流。
-
对抗训练本身有两个显著的问题,一个问题是速度极慢,假设针对每个样本进行10次PGD对抗攻击来获得对抗样本,那么一个训练迭代就对梯度多进行了10次反向传播,训练用时至少是正常训练的十倍(因此最初才会使用FGSM等快速攻击方法来加快对抗训练)
-
另一个问题则是精度较低,一方面是模型在正常样本上的精度降低了,原来可以达到95%以上的分类精度的模型,进行对抗训练之后,往往只能达到80%~90%(这意味着模型可能要在稳健性和精确度之间取舍);另一方面模型在对抗攻击下的精度(Robust Accuracy)也不高,目前最好的结果依然不超过70%。
-
但对抗攻击是一个存在问题——只需要针对大部分样本都能够生成一个能够欺骗模型的对抗样本,这个攻击方法就是成功的,而对抗防御则是一个任意问题——一个对抗稳健的模型,需要能够正确识别所有潜在攻击方法生成的对抗样本,使用对抗攻击来证明对抗稳健性本身就是不靠谱的,得到的只是模型对抗稳健性的上界,因此另有一系列研究(Provable Defense)从对抗训练出发,转而追求模型对抗稳健性的下界。
-
-
-
随机权重平均(Stochastic Weight Averaging,SWA),通过对训练过程中的模型权重进行Avg融合,提升模型鲁棒性,PyTorch有官方实现。SWA是一种通过随机梯度下降改善深度学习模型泛化能力的方法,而且这种方法不会为训练增加额外的消耗,这种方法可以嵌入到Pytorch中的任何优化器类中。主要还是用于稳定模型的训练。
-
在优化的末期取k个优化轨迹上的checkpoints,平均他们的权重,得到最终的网络权重,这样就会使得最终的权重位于flat曲面更中心的位置,缓解权重震荡问题,获得一个更加平滑的解,相比于传统训练有更泛化的解。
-
在EMA指数滑动平均(Exponential Moving Average)我们讨论了指数滑动平均,可以发现SWA和EMA是有相似之处:都是在训练之外的操作,不影响训练过程。与集成学习类似,都是一种权值的平均,EMA是一种指数平均,会赋予近期更多的权重,SWA则是平均赋权重。
-
EMA指数移动平均:shadow权重是通过历史的模型权重指数加权平均数来累积的,每次shadow权重的更新都会受上一次shadow权重的影响,所以shadow权重的更新都会带有前几次模型权重的惯性,历史权重越久远,其重要性就越小,这样可以使得权重更新更加平滑。
-
import torch import torch.nn as nn def apply_swa(model: nn.Module, checkpoint_list: list, weight_list: list, strict: bool = True): """ :param model: :param checkpoint_list: 要进行swa的模型路径列表 :param weight_list: 每个模型对应的权重 :param strict: 输入模型权重与checkpoint是否需要完全匹配 :return: """ checkpoint_tensor_list = [torch.load(f, map_location='cpu') for f in checkpoint_list] for name, param in model.named_parameters(): try: param.data = sum([ckpt['model'][name] * w for ckpt, w in zip(checkpoint_tensor_list, weight_list)]) except KeyError: if strict: raise KeyError(f"Can't match '{name}' from checkpoint") else: print(f"Can't match '{name}' from checkpoint") return model # 创建EMA平滑的shadow权重(对应EMA对象初始化和register方法) # 按照正常的训练流程,反向传播更新模型权重 # 更新模型权重之后,再执行EMA平滑,更新shadow权重(对应update方法) # 重复2-3步,直到valid阶段 # 备份模型权重,加载shadow权重,使用shadow权重进行模型的valid工作(对应apply_shadow方法) # 使用shadow权重作为模型权重,保存模型 # 恢复模型权重(对应restore方法),继续重复以上步骤2-7。 import torch import torch.nn as nn from torch.utils.data import DataLoader class EMA: def __init__(self, model: nn.Module, decay: float = 0.999): self.model = model self.decay = decay self.shadow = {} self.backup = {} def register(self): """创建shadow权重""" for name, param in self.model.named_parameters(): if param.requires_grad: self.shadow[name] = param.data.clone() def update(self): """EMA平滑操作,更新shadow权重""" for name, param in self.model.named_parameters(): if param.requires_grad: assert name in self.shadow new_average = (1.0 - self.decay) * param.data + self.decay * self.shadow[name] self.shadow[name] = new_average.clone() def apply_shadow(self): """使用shadow权重作为模型权重,并创建原模型权重备份""" for name, param in self.model.named_parameters(): if param.requires_grad: assert name in self.shadow self.backup[name] = param.data param.data = self.shadow[name] def restore(self): """恢复模型权重""" for name, param in self.model.named_parameters(): if param.requires_grad: assert name in self.backup param.data = self.backup[name] self.backup = {} # EMA需要在每步训练时,同步更新shadow权重,但其计算量与模型的反向传播相比,成本很小,因此实际上并不会拖慢很对模型的训练进度; # SWA可以在训练结束,进行手动加权,完全不增加额外的训练成本; # 实际使用两者可以配合使用,可以带来一点模型性能提升。
-
-
数据增强:resize、crop、flip、ratate、blur、HSV变化、affine(仿射)、perspective(透视)、Mixup、cutout、cutmix、Random Erasing(随机擦除)、Mosaic(马赛克)、CopyPaste、GANs domain transfer等)
-
在机器学习/深度学习中,我们经常会遇到模型过拟合的问题,为了解决过拟合问题,我们可以通过加入正则项或者减少模型学习参数来解决,但是最简单的避免过拟合的方法是增加数据,但是在许多场景我们无法获得大量数据,例如医学图像分析。数据增强技术的存在是为了解决这个问题,这是针对有限数据问题的解决方案。数据增强一套技术,可提高训练数据集的大小和质量,以便我们可以使用它们来构建更好的深度学习模型。 在计算视觉领域,生成增强图像相对容易。即使引入噪声或裁剪图像的一部分,模型仍可以对图像进行分类,数据增强有一系列简单有效的方法可供选择,有一些机器学习库来进行计算视觉领域的数据增强,比如:imgaug 官网它封装了很多数据增强算法,给开发者提供了方便。
-
imgaug是计算机视觉任务中常用的一个数据增强的包,相比于torchvision.transforms,它提供了更多的数据增强方法,因此在各种竞赛中,人们广泛使用imgaug来对数据进行增强操作Readthedocs:imgaug -
imgaug仅仅提供了图像增强的一些方法,但是并未提供图像的IO操作,因此我们需要使用一些库来对图像进行导入,建议使用imageio进行读入,如果使用的是opencv进行文件读取的时候,需要进行手动改变通道,将读取的BGR图像转换为RGB图像。除此以外,当我们用PIL.Image进行读取时,因为读取的图片没有shape的属性,所以我们需要将读取到的img转换为np.array()的形式再进行处理。因此官方的例程中也是使用imageio进行图片读取。官方提供notebook例程:notebook
-
关于PyTorch中如何使用imgaug每一个人的模板是不一样的,我在这里也仅仅给出imgaug的issue里面提出的一种解决方案,大家可以根据自己的实际需求进行改变。 具体链接:how to use imgaug with pytorch
-
import numpy as np from imgaug import augmenters as iaa from torch.utils.data import DataLoader, Dataset from torchvision import transforms # 构建pipline tfs = transforms.Compose([ iaa.Sequential([ iaa.flip.Fliplr(p=0.5), iaa.flip.Flipud(p=0.5), iaa.GaussianBlur(sigma=(0.0, 0.1)), iaa.MultiplyBrightness(mul=(0.65, 1.35)), ]).augment_image, # 不要忘记了使用ToTensor() transforms.ToTensor() ]) # 自定义数据集 class CustomDataset(Dataset): def __init__(self, n_images, n_classes, transform=None): # 图片的读取,建议使用imageio self.images = np.random.randint(0, 255,(n_images, 224, 224, 3),dtype=np.uint8) self.targets = np.random.randn(n_images, n_classes) self.transform = transform def __getitem__(self, item): image = self.images[item] target = self.targets[item] if self.transform: image = self.transform(image) return image, target def __len__(self): return len(self.images) def worker_init_fn(worker_id): imgaug.seed(np.random.get_state()[1][0] + worker_id) custom_ds = CustomDataset(n_images=50, n_classes=10, transform=tfs) custom_dl = DataLoader(custom_ds, batch_size=64, num_workers=4, pin_memory=True, worker_init_fn=worker_init_fn)
-
-
关于num_workers在Windows系统上只能设置成0,但是当我们使用Linux远程服务器时,可能使用不同的num_workers的数量,这是我们就需要注意worker_init_fn()函数的作用了。它保证了我们使用的数据增强在num_workers>0时是对数据的增强是随机的。
-
-
知识蒸馏
-
在训练的时候,我们可以去花费一切的资源和算力去训练模型,得到的结果也是非常好的,但是在应用落地的时候,也就是需要在一些嵌入式设备使用的时候,那么这么庞大的模型肯定是不能够在手机端或者其他设备上运行的,或者需要的推理时间非常长,那么这个模型就只能在实验室待着了。为了解决这样的现象,就提出了知识蒸馏的算法理论,就是将庞大的教师模型的重要的东西让学生模型来逼近和训练,让参数量少的学生模型能够和教师模型的效果差不多,或者比老师模型效果更好。这就是知识蒸馏的简单原理。
-
在说到知识蒸馏之前,首先说一下标签问题,在我们刚学习分类任务的时候,比如手写数字集,它的标签就是0,1-9,或者直接就是用独热编码的形式来作为标签。那么这样的做法到底好不好呢,对于这样的问题就有人说这样的标签容易让网络训练的过于绝对化,其实马也有一部分像驴,或者说驴也有一部分像马,如果将马的标签变成1,驴和汽车都是0,那么是不是就让驴和汽车的概率等同了,或者说驴和马的潜在关系直接被网络 忽略了。所以就又提出了soft targets。就是把标签要保持驴和马的潜在关系。这样的话这个网络就能够学到更多的潜在知识。
-
import torch import torch.nn as nn import torch.nn.functional as F import torchvision from torchvision import transforms from torch.utils.data import DataLoader from torchinfo import summary # 准备数据集 #设置随机种子 torch.manual_seed(0) device=torch.device("cuda" if torch.cuda.is_available() else "cpu") #使用cuda进行加速卷积运算 torch.backends.cudnn.benchmark=True #载入训练集 train_dataset=torchvision.datasets.MNIST(root="dataset/",train=True,transform=transforms.ToTensor(),download=True) test_dateset=torchvision.datasets.MNIST(root="dataset/",train=False,transform=transforms.ToTensor(),download=True) train_dataloder=DataLoader(train_dataset,batch_size=32,shuffle=True) test_dataloder=DataLoader(test_dateset,batch_size=32,shuffle=True) ## 构建教师网络 class Teacher_model(nn.Module): def __init__(self,in_channels=1,num_class=10): super(Teacher_model, self).__init__() self.fc1=nn.Linear(784,1200) self.fc2=nn.Linear(1200,1200) self.fc3=nn.Linear(1200,10) self.relu=nn.ReLU() self.dropout=nn.Dropout(0.5) def forward(self,x): x=x.view(-1,784) x=self.fc1(x) x=self.dropout(x) x=self.relu(x) x = self.fc2(x) x = self.dropout(x) x = self.relu(x) x = self.fc3(x) return x model=Teacher_model() model=model.to(device) #损失函数和优化器 loss_function=nn.CrossEntropyLoss() optim=torch.optim.Adam(model.parameters(),lr=0.0001) # 教师网络训练 epoches=6 for epoch in range(epoches): model.train() for image,label in train_dataloder: image,label=image.to(device),label.to(device) optim.zero_grad() out=model(image) loss=loss_function(out,label) loss.backward() optim.step() model.eval() num_correct=0 num_samples=0 with torch.no_grad(): for image,label in test_dataloder: image=image.to(device) label=label.to(device) out=model(image) pre=out.max(1).indices num_correct+=(pre==label).sum() num_samples+=pre.size(0) acc=(num_correct/num_samples).item() model.train() print("epoches:{},accurate={}".format(epoch,acc)) teacher_model=model #构建学生模型 class Student_model(nn.Module): def __init__(self,in_channels=1,num_class=10): super(Student_model, self).__init__() self.fc1 = nn.Linear(784, 20) self.fc2 = nn.Linear(20, 20) self.fc3 = nn.Linear(20, 10) self.relu = nn.ReLU() #self.dropout = nn.Dropout(0.5) def forward(self, x): x = x.view(-1, 784) x = self.fc1(x) #x = self.dropout(x) x = self.relu(x) x = self.fc2(x) #x = self.dropout(x) x = self.relu(x) x = self.fc3(x) return x model=Student_model() model=model.to(device) #损失函数和优化器 loss_function=nn.CrossEntropyLoss() optim=torch.optim.Adam(model.parameters(),lr=0.0001) # 学生网络训练及预测 epoches=6 for epoch in range(epoches): model.train() for image,label in train_dataloder: image,label=image.to(device),label.to(device) optim.zero_grad() out=model(image) loss=loss_function(out,label) loss.backward() optim.step() model.eval() num_correct=0 num_samples=0 with torch.no_grad(): for image,label in test_dataloder: image=image.to(device) label=label.to(device) out=model(image) pre=out.max(1).indices num_correct+=(pre==label).sum() num_samples+=pre.size(0) acc=(num_correct/num_samples).item() model.train() print("epoches:{},accurate={}".format(epoch,acc)) # 知识蒸馏参数设置 开始进行知识蒸馏算法 teacher_model.eval() model=Student_model() model=model.to(device) #蒸馏温度 T=7 hard_loss=nn.CrossEntropyLoss() alpha=0.3 soft_loss=nn.KLDivLoss(reduction="batchmean") optim=torch.optim.Adam(model.parameters(),lr=0.0001) # 学生网络的训练和预测结果 epoches=5 for epoch in range(epoches): model.train() for image,label in train_dataloder: image,label=image.to(device),label.to(device) with torch.no_grad(): teacher_output=teacher_model(image) optim.zero_grad() out=model(image) loss=hard_loss(out,label) ditillation_loss=soft_loss(F.softmax(out/T,dim=1),F.softmax(teacher_output/T,dim=1)) # 老师教学生重点 loss_all=loss*alpha+ditillation_loss*(1-alpha) loss.backward() optim.step() model.eval() num_correct=0 num_samples=0 with torch.no_grad(): for image,label in test_dataloder: image=image.to(device) label=label.to(device) out=model(image) pre=out.max(1).indices num_correct+=(pre==label).sum() num_samples+=pre.size(0) acc=(num_correct/num_samples).item() model.train() print("epoches:{},accurate={}".format(epoch,acc)) -
知识蒸馏Pytorch代码实战_哔哩哔哩_bilibili
-
-
结构重参数化
-
结构重参数化(structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。在现实场景中,训练资源一般是相对丰富的,我们更在意推理时的开销和性能,因此我们想要训练时的结构较大,具备好的某种性质(更高的精度或其他有用的性质,如稀疏性),转换得到的推理时结构较小且保留这种性质(相同的精度或其他有用的性质)。换句话说,“结构重参数化”这个词的本意就是:用一个结构的一组参数转换为另一组参数,并用转换得到的参数来参数化(parameterize)另一个结构。只要参数的转换是等价的,这两个结构的替换就是等价的。
-
ACNet (ICCV-2019):Reparam(KxK) = KxK-BN + 1xK-BN + Kx1-BN。这一记法表示用三个平行分支(KxK,1xK,Kx1)的加和来替换一个KxK卷积。注意三个分支各跟一个BN,三个分支分别过BN之后再相加。这样做可以提升卷积网络的性能。
-
RepVGG (CVPR-2021):Reparam(3x3) = 3x3-BN + 1x1-BN + BN。对每个3x3卷积,在训练时给它构造并行的恒等和1x1卷积分支,并各自过BN后相加。我们简单堆叠这样的结构得到形成了一个VGG式的直筒型架构。推理时的这个架构仅有一路3x3卷积夹ReLU,连分支结构都没有,可以说“一卷到底”,效率很高。这样简单的结构在ImageNet上可以达到超过80%的准确率,比较精度和速度可以超过或打平RegNet等SOTA模型。
-
重参数其实就是在测试的时候对训练的网络结构进行压缩。比如三个并联的卷积(kernel size相同)结果的和,其实就等于用求和之后的卷积核进行一次卷积的结果。所以,在训练的时候可以用三个卷积来提高模型的学习能力,但是在测试部署的时候,可以无损压缩为一次卷积,从而减少参数量和计算量。
-
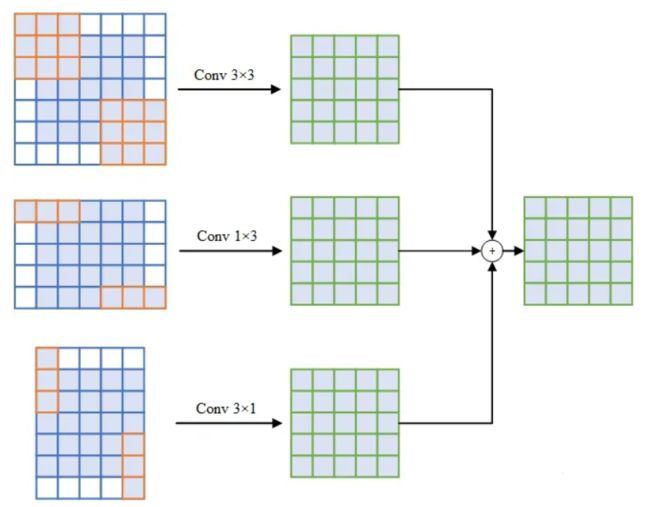
-
在步长(stride)为1的情况下,对于3×3卷积,需要对它的四周进行大小为1的padding(白色部分);对于1×3卷积,对它的左右两边进行大小为1的padding(白色部分);对于3×1卷积,对它的上下两边进行大小为1的padding(白色部分)。这样三个卷积的输出大小一致,可以直接相加。
-
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', use_affine=True, bias=True): super(ACBlock, self).__init__() # 表示模型处于非部署模式(训练阶段) self.deploy = False # 非部署模式,定义一个3×3卷积、一个3×1卷积和一个1×3卷积 # 首先定义3×3卷积 self.square_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(kernel_size, kernel_size), stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias, padding_mode=padding_mode) self.square_bn = nn.BatchNorm2d( num_features=out_channels, affine=use_affine) # 计算3×1卷积和1×3卷积的padding大小 # 对于k×k卷积,当希望保持输出尺寸时, # 一般采用 kernel_size // 2作为padding的大小. # 例如,对3×3卷积,padding大小为1; # 对于5×5卷积,padding大小为2,以此类推。 # 当padding的大小能够保持或增大输出尺寸时, # 计算1×3卷积和3×1卷积的padding if padding - kernel_size // 2 >= 0: self.crop = 0 hor_padding = [padding - kernel_size // 2, padding] ver_padding = [padding, padding - kernel_size // 2] else: raise Exception("No support for negative padding!") # 定义3×1卷积 self.ver_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(kernel_size, 1), stride=stride, padding=ver_padding, dilation=dilation, groups=groups, bias=bias, padding_mode=padding_mode) # 定义1×3卷积 self.hor_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(1, kernel_size), stride=stride, padding=hor_padding, dilation=dilation, groups=groups, bias=bias, padding_mode=padding_mode) self.ver_bn = nn.BatchNorm2d( num_features=out_channels, affine=use_affine) self.hor_bn = nn.BatchNorm2d( num_features=out_channels, affine=use_affine) def forward(self, input): if self.deploy: return self.fused_conv(input) else: square_outputs = self.square_conv(input) square_outputs = self.square_bn(square_outputs) ver_input = input hor_input = input vertical_outputs = self.ver_conv(ver_input) vertical_outputs = self.ver_bn(vertical_outputs) horizontal_outputs = self.hor_conv(hor_input) horizontal_outputs = self.hor_bn(horizontal_outputs) result = square_outputs + vertical_outputs + horizontal_outputs return result -
然后实现一个switch_to_deploy方法来对block进行重参数化:
-
# 因为我们是要将三个卷积重参数化为一个卷积,所以 # 只需要计算出重参数化后新卷积的参数即可, # 即卷积层的weight和bias参数. # 新的weight和bias由get_equivalent_kernel_bias() # 方法计算得到. deploy_k, deploy_b = self.get_equivalent_kernel_bias() # 将部署模式设为True, # 这样forward会使用重参数化后的卷积 self.deploy = True # 定义一个新的卷积用来保存重参数化的参数 self.fused_conv = nn.Conv2d(in_channels=self.square_conv.in_channels, out_channels=self.square_conv.out_channels, kernel_size=self.square_conv.kernel_size, stride=self.square_conv.stride, padding=self.square_conv.padding, dilation=self.square_conv.dilation, groups=self.square_conv.groups, bias=True, padding_mode=self.square_conv.padding_mode) # 删除原来三条分支的卷积和BN self.__delattr__('square_conv') self.__delattr__('square_bn') self.__delattr__('hor_conv') self.__delattr__('hor_bn') self.__delattr__('ver_conv') self.__delattr__('ver_bn') # 将重参数化的参数送进新的卷积 self.fused_conv.weight.data = deploy_k self.fused_conv.bias.data = deploy_b -
然后来看get_equivalent_kernel_bias方法的实现:
-
def get_equivalent_kernel_bias(self): # 重参数化卷积和BN层 # 具体方法在上一篇DBBNet文中介绍了 #(重参数化方法一:卷积层与BN层的合并) hor_k, hor_b = self._fuse_bn_tensor(self.hor_conv, self.hor_bn) ver_k, ver_b = self._fuse_bn_tensor(self.ver_conv, self.ver_bn) square_k, square_b = self._fuse_bn_tensor(self.square_conv, self.square_bn) # 将不同尺寸卷积进行重参数化 # 具体方法在上一篇DBBNet文中介绍了 # (重参数化方法六:多尺度卷积) self._add_to_square_kernel(square_k, hor_k) self._add_to_square_kernel(square_k, ver_k) return square_k, hor_b + ver_b + square_b # 重参数化卷积和BN层 def _fuse_bn_tensor(self, conv, bn): std = (bn.running_var + bn.eps).sqrt() t = (bn.weight / std).reshape(-1, 1, 1, 1) return conv.weight * t, bn.bias - bn.running_mean * bn.weight / std # 将不同尺寸卷积进行重参数化 def _add_to_square_kernel(self, square_kernel, asym_kernel): asym_h = asym_kernel.size(2) asym_w = asym_kernel.size(3) square_h = square_kernel.size(2) square_w = square_kernel.size(3) square_kernel[:, :, square_h // 2 - asym_h // 2: square_h // 2 - asym_h // 2 + asym_h, square_w // 2 - asym_w // 2: square_w // 2 - asym_w // 2 + asym_w] += asym_kernel -
深度学习理论与实践—重参数化卷积神经网络:ACNet & RepVGG - 知乎 (zhihu.com)
-
-
Stochastic Depth
- 随机深度文章是发表于ECCV2016,这篇文章早于DenseNet.,DenseNet也是因为随机深度网络受到启发,才提出来。Deep Network with Stochastic depth,在训练过程中,随机去掉很多层,并没有影响算法的收敛性,说明了ResNet具有很好的冗余性。而且去掉中间几层对最终的结果也没什么影响,说明ResNet每一层学习的特征信息都非常少,也说明了ResNet具有很好的冗余性。
- 深的网络在现在表现出了十分强大的能力,但是也存在许多问题。即使在现代计算机上,梯度会消散、前向传播中信息的不断衰减、训练时间也会非常缓慢等问题。
- ResNet的强大性能在很多应用中已经得到了证实,尽管如此,ResNet还是有一个不可忽视的缺陷——更深层的网络通常需要进行数周的训练——因此,把它应用在实际场景下的成本非常高。为了解决这个问题,作者们引入了一个“反直觉”的方法,即在我们可以在训练过程中任意地丢弃一些层,并在测试过程中使用完整的网络。
- 随机深度网络的精度比ResNet更高,证明了其具有更好的泛化能力,这是为什么呢?论文中的解释是,不激活一部分残差模块事实上提现了一种模型融合的思想(和dropout解释一致),由于训练时模型的深度随机,预测时模型的深度确定,实际是在测试时把不同深度的模型融合了起来。
- 还有一种解释是,在深度确定时,信息随着网络一层层被提取被过滤,当信息到达网络的高层时已经不是非常informative了,高层网络面对这样的信息难以得到有效的训练。不激活一部分block,使得高层的block能接收到更多来自底层的信息,能得到更加充分的训练,因而模型有了更好的表达能力。在预测时,深度确定并且给各个block加权,也事实上是一种模型融合。
- 随机深度的代码实现非常简单,对于一个批次的数据,通过伯努利分布来随机挑选一部分的数据跳过连接。为了让函数可倒,我们将连接层前向的输出矩阵乘上一个因子来控制连接的概率。和dropout其实是有异曲同工的作用,但是实际的作用,在不同数据集和不同的网络中表现应该也是不同的,就像dropout很多时候并不一定能提高网络的性能,具体还得在特定场景进行实验,从作者的实验结果中来看,对于层数越多的网络,随机深度性能越好,同时drop率也要相应增加。
-
def drop_path(x, drop_prob: float = 0., training: bool = False): """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is the same as the DropConnect impl I created for EfficientNet, etc networks, however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument. """ if drop_prob == 0. or not training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) random_tensor.floor_() # binarize output = x.div(keep_prob) * random_tensor return output class DropPath(nn.Module): """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). """ def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training) # 在block的前向传播中,在最后的链接处使用 def forward(self, x): shortcut = x if self.conv_exp is not None: x = self.conv_exp(x) x = self.conv_dw(x) if self.se is not None: x = self.se(x) x = self.act_dw(x) x = self.conv_pwl(x) if self.drop_path is not None: # 是否使用随机深度 x = self.drop_path(x) if self.use_shortcut: x[:, 0:self.in_channels] += shortcut return x
-
使用argparse进行调参
-
在深度学习中时,超参数的修改和保存是非常重要的一步,尤其是当我们在服务器上跑我们的模型时,如何更方便的修改超参数是我们需要考虑的一个问题。这时候,要是有一个库或者函数可以解析我们输入的命令行参数再传入模型的超参数中该多好。到底有没有这样的一种方法呢?答案是肯定的,这个就是 Python 标准库的一部分:Argparse。
-
argsparse是python的命令行解析的标准模块,内置于python,不需要安装。这个库可以让我们直接在命令行中就可以向程序中传入参数。我们可以使用
python file.py来运行python文件。而argparse的作用就是将命令行传入的其他参数进行解析、保存和使用。在使用argparse后,我们在命令行输入的参数就可以以这种形式python file.py --lr 1e-4 --batch_size 32来完成对常见超参数的设置。 -
总的来说,我们可以将argparse的使用归纳为以下三个步骤。
-
创建
ArgumentParser()对象 -
调用
add_argument()方法添加参数 -
使用
parse_args()解析参数 。
-
-
# demo.py import argparse # 创建ArgumentParser()对象 parser = argparse.ArgumentParser() # 添加参数 parser.add_argument('-o', '--output', action='store_true', help="shows output") # action = `store_true` 会将output参数记录为True # type 规定了参数的格式 # default 规定了默认值 parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3') parser.add_argument('--batch_size', type=int, required=True, help='input batch size') # 使用parse_args()解析函数 args = parser.parse_args() if args.output: print("This is some output") print(f"learning rate:{args.lr} ") -
argparse的参数主要可以分为可选参数和必选参数。可选参数就跟我们的
lr参数相类似,未输入的情况下会设置为默认值。必选参数就跟我们的batch_size参数相类似,当我们给参数设置required =True后,我们就必须传入该参数,否则就会报错。看到我们的输入格式后,我们可能会有这样一个疑问,我输入参数的时候不使用–可以吗?当我们不实用–后,将会严格按照参数位置进行解析。 -
通常情况下,为了使代码更加简洁和模块化,我一般会将有关超参数的操作写在
config.py,然后在train.py或者其他文件导入就可以。具体的config.py可以参考如下内容。 -
import argparse def get_options(parser=argparse.ArgumentParser()): parser.add_argument('--workers', type=int, default=0, help='number of data loading workers, you had better put it 4 times of your gpu') parser.add_argument('--batch_size', type=int, default=4, help='input batch size, default=64') parser.add_argument('--niter', type=int, default=10, help='number of epochs to train for, default=10') parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3') parser.add_argument('--seed', type=int, default=118, help="random seed") parser.add_argument('--cuda', action='store_true', default=True, help='enables cuda') parser.add_argument('--checkpoint_path',type=str,default='', help='Path to load a previous trained model if not empty (default empty)') parser.add_argument('--output',action='store_true',default=True,help="shows output") opt = parser.parse_args() if opt.output: print(f'num_workers: {opt.workers}') print(f'batch_size: {opt.batch_size}') print(f'epochs (niters) : {opt.niter}') print(f'learning rate : {opt.lr}') print(f'manual_seed: {opt.seed}') print(f'cuda enable: {opt.cuda}') print(f'checkpoint_path: {opt.checkpoint_path}') return opt if __name__ == '__main__': opt = get_options() -
随后在
train.py等其他文件,我们就可以使用下面的这样的结构来调用参数。-
# 导入必要库 import config opt = config.get_options() manual_seed = opt.seed num_workers = opt.workers batch_size = opt.batch_size lr = opt.lr niters = opt.niters checkpoint_path = opt.checkpoint_path # 随机数的设置,保证复现结果 def set_seed(seed): torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) random.seed(seed) np.random.seed(seed) torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True if __name__ == '__main__': set_seed(manual_seed) for epoch in range(niters): train(model,lr,batch_size,num_workers,checkpoint_path) val(model,lr,batch_size,num_workers,checkpoint_path)
-
-
argparse给我们提供了一种新的更加便捷的方式,而在一些大型的深度学习库中人们也会使用json、dict、yaml等文件格式去保存超参数进行训练。argparse 官方教程
-
-
添加注意力机制(SE,CBAM,ECA,CA…)
