Paddle OCR Win 11下的安装和简单使用教程
Paddle OCR Win 11下的安装和简单使用教程
对于中文的识别,可以考虑直接使用Paddle OCR,识别准确率和部署都相对比较方便。
环境搭建
目前PaddlePaddle 发布到v2.4,先下载paddlepaddle,再下载paddleocr。根据自己设备操作系统进行下载安装。paddle官网地址:https://www.paddlepaddle.org.cn

pip install paddlepaddle-gpu==2.4.2.post112 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
如果需要CPU版本:
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
paddleocr 推荐环境
PaddlePaddle >= 2.1.2
Python 3.7
CUDA 10.1 / CUDA 10.2
CUDNN 7.6
可参考paddle官方出的环境搭建进行,地址:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/environment.md
安装paddle ocr
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
对于直接pip shapely库可能出现的问题[winRrror 126],建议下载shapely安装包完成安装。地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely
使用教程
在环境搭建好之后,就可以愉快的直接使用了。话说,两年没用paddle,跟torch越来越像了。
import paddle
import paddleocr
from paddleocr import PaddleOCR
import numpy as np
import cv2
import matplotlib.pyplot as plt
import os
from PIL import Image
import glob
import random
import re
import json
print(paddle.__version__)
#2.4.1
print(paddleocr.__version__)
#2.6.1.3
使用PaddleOCR,默认使用的是PP-OCRv3,轻量级模型。
源代码:
SUPPORT_DET_MODEL = ['DB']
VERSION = '2.6.1.0'
SUPPORT_REC_MODEL = ['CRNN', 'SVTR_LCNet']
BASE_DIR = os.path.expanduser("~/.paddleocr/")
DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv3'
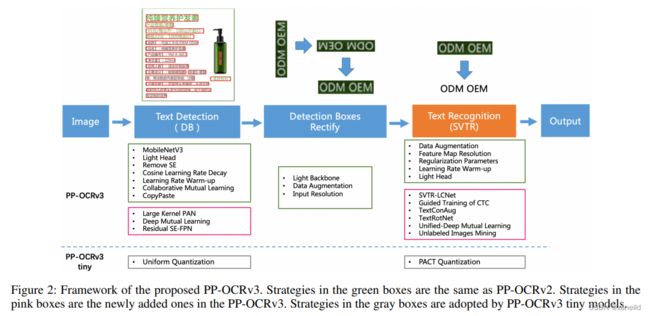
OCR model用的PP-OCRv3,根据论文,检测用的DB,识别用的SVTR。相比PP-OCRv2,模型框架如下图:
ocr = PaddleOCR(use_angles_cls=True, use_gpu=False)
def draw_img(img_path,boxes):
save_root = 'data/resocr/'
img_name = img_path.split('\\')[1]
img = cv2.imread(img_path)
for box in boxes:
box = np.reshape(np.array(box),[-1,1,2]).astype(np.int64)
img = cv2.polylines(np.array(img), [box], True, (255,0,0),2)
plt.figure(figsize=(10,10))
save_file = save_root+img_name
plt.imshow(img)
plt.savefig(save_file)
imgp = 'data\\idcard1.png'
print(ocr.args)
res = ocr.ocr(imgp)
print(res)
boxes = []
texts = []
for j in range(len(res[0])):
boxes.append(res[0][j][0])
texts.append(res[0][j][1][0])
draw_img(imgp,boxes)
网上随便找了一张发票奥巴马身份证(身份证图片过不了,虽然是伪造的奥巴马。。。) ,得到的结果如下:(写了才发现,包自带了一个draw_ocr的函数)
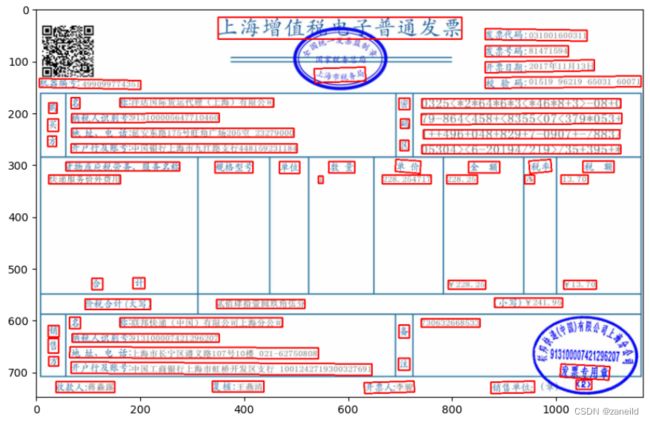
部分结果:
[[[[[350.0, 16.0], [819.0, 16.0], [819.0, 58.0], [350.0, 58.0]],
('上海增值税电子普通发票', 0.9431300759315491)],
[[[864.0, 38.0], [1060.0, 41.0], [1060.0, 62.0], [864.0, 59.0]],
('发票代码:031001600311', 0.9889101982116699)],
[[[864.0, 71.0], [1024.0, 71.0], [1024.0, 92.0], [864.0, 92.0]],
('发票号码:81471594', 0.9445592164993286)],
[[[864.0, 102.0], [1074.0, 98.0], [1074.0, 119.0], [864.0, 123.0]],
('开票日期:2017年11月13日', 0.9694705009460449)],
[[[535.0, 115.0], [633.0, 112.0], [634.0, 139.0], [536.0, 142.0]],
('上海市税务局', 0.9940652847290039)],
[[[6.0, 134.0], [201.0, 138.0], [201.0, 155.0], [6.0, 151.0]],
('机器编号:499099774351', 0.9102509021759033)],
[[[864.0, 132.0], [1164.0, 129.0], [1164.0, 150.0], [864.0, 153.0]],
('校验码:01519962196503160071', 0.9772385954856873)]]]
可以看到基本该拿的信息都拿了。可以通过调节超参对检测框阈值和比例进行调节。根据utility.py参数初始化设置如下:
# DB parmas
parser.add_argument("--det_db_thresh", type=float, default=0.3) #二值化输出图的阈值
parser.add_argument("--det_db_box_thresh", type=float, default=0.6) #过滤检测框阈值
parser.add_argument("--det_db_unclip_ratio", type=float, default=1.5) #检测框扩张的系数
ocr = PaddleOCR(use_angles_cls=True, use_gpu=False, det_db_thresh=0.3,det_db_unclip_ratio=2.5, det_db_box_thresh=0.8)
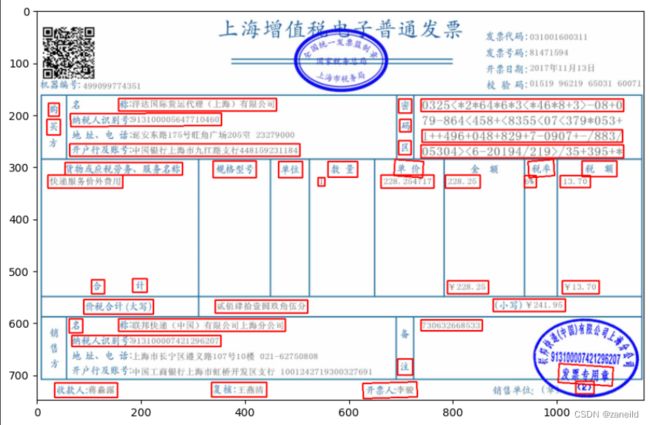
更改参数后看看结果:
过滤掉了一些检测框。
参数可以根据自己所处的任务进行调节,也可以选择其他模型进行增加识别率。
paddle现在跟torch很像,也就减少了学习成本。
官方出了一个Dive into OCR的教程,有点儿狗的是,中文版要进群后才能领取。英文版则大方给出来了,地址如下:https://paddleocr.bj.bcebos.com/ebook/Dive_into_OCR.pdf