文章作者:刘知远 (原载于知乎:NLP日知录)课件来自于学堂在线直播:
在微博和知乎上关注自然语言处理(NLP)技术的朋友,应该都对#NLP太难了#、#自然语言理解太难了#两个话题标签不陌生,其下汇集了各种不仅难煞计算机、甚至让人也发懵的费解句子或歧义引起的笑话。然而,这些例子只是让人直觉计算机理解人类语言太难了,NLP到底难在哪里,还缺少通俗易懂的介绍。最近刚做完会议投稿,这里花些时间总结下我对这个问题的认识,期望对那些感兴趣NLP的同学有些帮助。欢迎批评意见和建议,未来争取不断更新。

此小号非彼小号
自然语言理解本质是结构预测

要搞清楚自然语言理解难在哪儿,先看自然语言理解任务的本质是什么。作为人工智能关注的三大信息类型(语音、视觉、语言)之一,自然语言文本是典型的无结构数据,由语言符号(如汉字)序列构成。要实现对自然语言的表意的理解,需要建立对该无结构文本背后的语义结构的预测。因此,自然语言理解的众多任务,包括并不限于中文分词、词性标注、命名实体识别、共指消解、句法分析、语义角色标注等,都是在对文本序列背后特定语义结构进行预测。例如,中文分词就是在原本没有空格分隔的句子中增加空格或其他标识,将句子中每个词的边界标记出来,相当于添加了某些结构化语义信息到这个文本序列上。
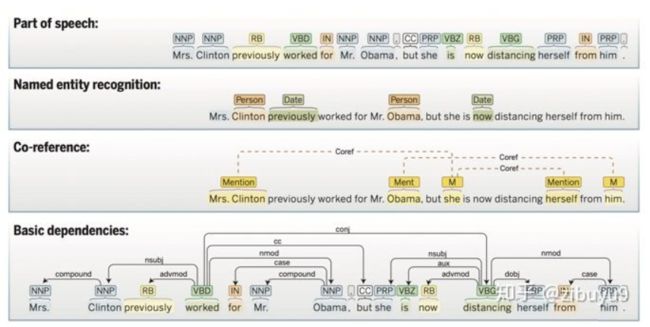
NLP典型任务:词性标注、命名实体识别、共指消解、句法分析 [1]
面向不同NLP任务,人们制定不同的待预测的语义结构空间:文本分类是最简单的情形,即预定义的类别体系,最常见的如情感分类是postive、neutral、negative三类;中文分词是词边界的标记;词性标注是句子中每个词的词性标签(如名词、动词、形容词、副词、连词、介词等);命名实体识别是标记哪些词(或多词)是实体名及其实体类型(如人名、地名、机构名等);共指消解是标记哪些词在做指代以及指代的是前面出现的哪个概念或实体;句法分析则是将句子背后的句法树结构或依存结构预测出来。
自然语言理解的关键是语义表示
不过,以上NLP任务都只是在不断“逼近”对文本的理解,是对文本语义的局部表示。要实现对文本的完整理解,需要建立更完备的语义结构表示空间,这种更完备的语义表示经常成为上述NLP任务进行结构预测的依据。
在统计学习时代,一般采用符号表示(Symbol-based Representation)方案,即每个词都看做互相独立的符号。例如,词袋模型(Bag-of-Words,BOW)是最常用的文本表示方案,忽略文本中词的出现顺序信息,广泛用于文本分类、信息检索等任务。N-Gram也是基于符号表示的语言模型,与BOW模型相比,将句子中词的出现顺序考虑了进来,曾在机器翻译、文本生成、信息检索等任务中广泛使用。
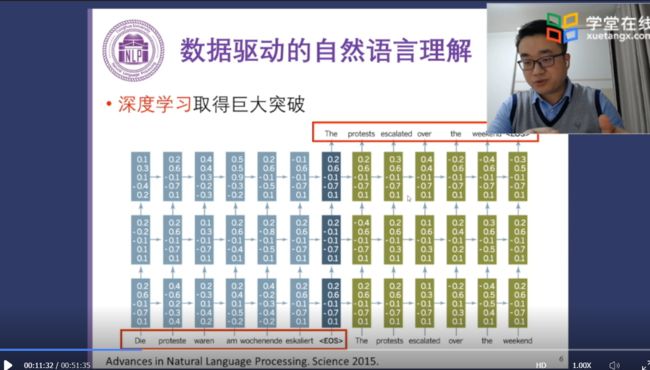

到深度学习时代,一般采用分布式表示(Distributed Representation或Embeddings)方案,每个语言单元(包括但不限于字、词、短语、句子、文档)都用一个低维稠密向量来表示它们的语义信息。分布式表示是深度学习和神经网络的关键技术。分布式表示方案是受到了人脑神经机制的启发,基本思想是[2]:
Each entity is represented by a pattern of activity distributed over many computing elements , and each computing element is involved in representing many different entities.
很大程度上,这种表示方案与索绪尔对语言符号的任意性和结构主义的观点不谋而合。从计算角度来看,NLP很多应用任务就是在判定两个语言单元间的语义相似度,如信息检索是在短语(查询词)和文档之间,文档摘要是在句子和文档之间,分布式表示也为在不同语言单元之间计算语义相似度提供了统一的语义表示基础。
由于忽略了对词语内部语义或词序信息的考量,基于符号表示的词袋模型或N-Gram失之粗略,也受到数据稀疏问题的影响;基于分布式表示的深度学习虽然极大提升NLP性能,却更多只能作为NLP内部表示,可解释性不够。实际上,也有很多学者提出Semantic Parsing任务,探索各类对文本语义更完整的表示和建模方案,仍未得到令人满意的结果。
总之,自然语言理解任务的本质是结构预测,关键则是对语言单元的语义表示能力。那么,自然语言理解为什么难呢,这需要我们先看一下,自然语言都有哪些特点。
自然语言有哪些特点
自然语言是人类在认识世界和改造世界的过程中产生的,归根到底是自然界的产物,因此被称为自然语言。自然语言本身受到人脑语言能力的支配,伴随着人类社会而演化,作为人类使用的最庞杂的符号系统,有很多特点。
创新性
作为人类信息交流的工具,自然语言需要具有强大的创新活力,随时引入对最新概念、表述和意义的表达能力。这方面最常见的就是新词以及旧词新意的出现。例如,有个笑话就是母女二人对“潮”和“晒”产生的不同理解,女儿本意是让母亲帮忙在太阳下晒发潮的被子;而母亲却理解为在朋友圈“晒”女儿的被子让大家看是不是很“潮”。可见,这位母亲大人本人还是很“潮”的,熟练掌握了两个词的的最新意思。
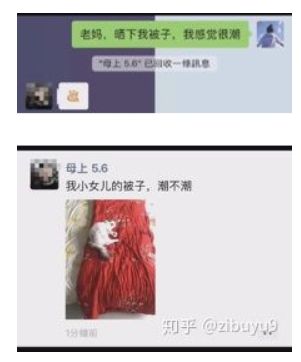
潮和晒
人类语言的创新活力伴随着互联网发展和在线交流的日益密切而更加明显。北京大学邵燕君等学者主编的《破壁书》应该是近年这方面的集大成之作,有兴趣的读者可以读下。我理解,这个书名“破壁书”,也算化用《三体》“破壁人”的一个新词。

解码二次元新词的《破壁书》
新词和旧词新意等都扩展了人类语言的表意空间,也扩展了自然语言理解进行结构预测的语义空间。而这种扩展,带有较强的随意性,缺少严格的描述信息或足够的数据支持,从而为自然语言理解带来挑战。
递归性

以语言学巨擘乔姆斯基为代表的学者认为,递归性(recursion)是人类语言的最重要的特性[4],这也是乔姆斯基提出转换生成文法的内在动机。虽然,递归性是否为人脑先天具备的语言能力有很多争论,至少从汉语英语两大语言来看,语言表现出的递归性特点不言而喻。
例如最近中美之间出现的这则有意思的表述,就集中反映了语言递归性:S1=”美国干涉中国内政“是一个拥有完整主谓宾结构的句子,被作为另外一个句子S2=”中国 抗议 x的法案“中”法案“的定语x;而S2又被作为了S3=”美国 抗议 y 是在干涉内政“中”抗议“的宾语y。
递归性带来的语言套娃现象-1: 抗议

递归性带来的语言套娃现象-2:吉尼斯世界纪录
正是这种递归性,为语言带来精准而强大的表述信息和思想的能力,随便翻翻那些著名的哲学著作,充满着带有复杂递归结构的长句。不过,这种精确表达能力是以理解更加费力为代价的,而且递归性也为一句话带来更多的语义理解的可能性,例如”咬死猎人的狗“,到底是咬死了猎人,还是咬死了狗,至少有两种可能的理解。
也可以看到,一旦句子包含了多层嵌套,对人而言理解起来就变得十分困难,很少有人会用这么复杂的结构说话。例如,政府部门层层转发通知导致的”通知的通知的通知“的标题,读起来就非常费力。所以,在自然语言理解实践中,单纯由于递归性造成的困难并不是那么大。

红头文件的语言套娃现象
多义性

自然语言是一个信息传递系统,需要兼顾信号发出者(说话人、作者)和信号接收者(听话人、读者)的效率。如果人类大脑中每个事物都要对应一个独一无二的字词符号,无疑会大幅提高人们的学习、记忆和使用语言的成本。因此,语言中存在大量同音字和一词多义的现象,即一个字或词往往兼顾多个词义,当然,也对应地需要人们根据话语或文本的语境进行消歧处理,才能正确理解其语义。这种多义性,也成为各类语言幽默的主要来源。
自然语言有不同粒度的语言单元,如字、词、短语、句子、语篇,乃至文档互联形成的万维网。多义性普遍存在于各粒度的语言单元上。例如,上面例子中的”潮“和”晒“两字就有两种意思,”小号“则是典型的一词多义,短语层面如”metal fan“也至少有两个意思。

Metal Fan
句子层面的多义性也不少见,如”能穿多少穿多少“,在夏天和冬天各有截然相反的意思。类似形式的语言笑话还不少:
单身的原因有两个,一是谁都看不上,二是谁都看不上。
女孩给男朋友打电话:如果你到了,我还没到,你就等着吧;如果我到了,你还没到,你就等着吧。
单身的原因:原来是喜欢一个人,现在是喜欢一个人。

字面意思的”我想开了“。
自然语言作为人们日常交流的主要方式,相信每个人都有在交流中出现误会闹出笑话甚至冲突的经历,很多时候就是由于歧义造成双方理解产生误差导致的。

“你好不好意思啊“还是”你好,不好意思啊”
主观性

即使语言的多义性得到了正确消歧,语言的字面意思得到了准确理解,同样的话语或文本,仍然会导致人们产生不同的理解,引发不同的思绪。这是因为,每个人都是在认识世界和与外界交互的具体过程中习得语言的,所以人们对语言的理解不可避免受到个人经历和认知水平的影响,带有强烈的主观性。
这种主观性反映在很多方面,以作者与读者间的理解差异为例,常说”一千个读者就有一千个哈姆雷特“,莎士比亚在写这个剧本时,他心目中恐怕有一个确切的哈姆雷特形象以及他希望表达的思想;但读者在阅读时,则不可避免会受到自身经历和认知的影响,而产生不同的理解。这有如一个正态分布,也许作者要传递的信息就在均值附近,而读者的理解则会各有偏差。这也是为什么,同样一部世界名著,有的人就会引起共鸣,有的人觉得索然无味。
中文世界也常说,言有尽而意无穷,特别是在诗歌中,往往寥寥数字,作者也许本意有限,而不同读者会产生不同层次的解读。这也是为什么。再如下面融合多种元素的诗歌:无人机系荔枝来,字面意思正如图所画,而读者如果了解杜牧原诗以及广东人容易将ZHI、SHI发音为JI、XI的特点,则更能会心一笑。

在人们日常对话交流中,这种主观性比比皆是。例如,同样是说”今天好冷啊”,字面意思没有任何难解之处,但如果是女朋友刚进屋说的,那就得赶紧打开空调;如果是宿舍同学说的,恐怕就要嘲笑他为啥穿这么少了。所以,恋爱关系、外交辞令、商务谈判都是需要清醒洞悉对方“言外之意”的危险地区呀。

这都是什么意思?
心理语言学等领域的很多研究表明,人的心理状态(如性格等)会反映在语言表达的蛛丝马迹中。对此有兴趣可以阅读美国学者James Pennebaker的相关成果,他甚至构建了一个词典Linguistic Inquiry and Word Count(LIWC)尝试建立人们使用词语与心理状态的对应关系 [5]。

社会性

人类是社会动物,社会性既是人类的特性,也深刻反映在人类语言中。语言并非固定不变,而是经历了漫长演化。人类的集体生产和生活,对信息交流和记录产生的需求,不断改造着人类语言。全世界的人类早期聚居于不同大洲和地区,互相隔绝,各自的社会形态和生活特点,深刻地影响了不同语言的产生和演化,产生了现在形态各异的人类语言,例如英语等是典型的拼音语言,而汉语则是音义兼顾语言的代表。现代语言学也是从研究总结不同语言体系的特点而发展起来的。作为语言学的分支,演化语言学就在研究人类语言在发音、字形、词法、句法等多个方面的演化过程,而社会语言学则重在研究社会形态与人类语言之间的互相影响的规律。
语言系统受到社会发展的塑造。随着互联网和移动设备的广泛应用,人类之间的交流和联系,比以往任何一个时代都更加紧密,这也反映在人类语言的高速演化,新词和旧词新意层出不穷。不同学科的高速发展,也为语言注入大量专业术语。使用不同语言的人们紧密联系,也为语言引入大量音译等形式的外来词。
语言使用也深刻反映社会形态。人们在不同的社交场合会切换不同的语言风格,如在做公开报告时和在朋友聚会时,语言风格明显不同,庄谐相异。在社交场合,人们也会将有些让人恐惧厌恶或者不雅晦气的概念作为禁忌或避讳词语,进而使用委婉曲折的说法,例如大便改叫出恭或解手,死亡改叫作古归西或见马克思等,中外皆同。
社会语言学还有一个有趣的话题,是探究语言使用与社会地位之间的关系,曾提出语言协调理论(Language coordination),即不同社会地位的人在相互交流时,地位低的人会从语言风格上适应地位高的人,而地位高的人则不会主动调整自己的语言风格适应别人,这个理论在2012年得到了定量验证 [6]。
最近的定量研究也表明,大规模文本中含有人类社会存在的刻板印象、政治偏见等问题,侧面反映了人类社会对语言的影响 [7]。美国著名认知语言学家莱考夫甚至认为,不同党派的政治家甚至会通过语言使用来影响政治议题的设置 [8]。


自然语言理解难在哪
正是由于其创造性、递归性、多义性、主观性和社会性等特点,既让人类语言具备强大的表达力和生命力,同时呈现出非常复杂而难以捉摸的图景。单从让计算机理解人类语言的角度来考虑,问题难点也许可以归结为如下几个方面。
结构语义表示空间构建
很多学者通过世界、心智和语言的三角形来表述语言的地位,这在索绪尔提出的能指和所指的概念中已初见端倪,哲学中的认识论和语言哲学也是探讨这三者的关系。自然语言理解还没有能力考虑哲学关心的这些问题,不过也能看出,语言作为人类认识世界的产物和工具,必然不是对客观世界的简单映射,而带有人类主观认识的色彩,也受到人脑机能的影响和约束。

各种语义三角
让计算机理解人类语言,需要建构结构化的语义表示空间,只有这个空间的语义表示能力能够与人类心智相媲美,才有可能将人类通过语言要表达的意义进行完美表示和解读。同时,这个语义表示空间还要接受客观世界的校正,消除人类认知中存在的偏见和缺陷,让人工智能更好地服务人类社会。
现在的语义表示方案中,符号表示过于粗略,无法考虑语言符号背后反映的丰富语义信息;而分布式表示虽然具有更强大的表示能力和自由度,但目前只能通过特定任务下的数据学习,只能建立满足特定需求的语义表示,一方面缺少可解释性,鲁棒性差,另一方面通用性和迁移性不足。这些与人脑展现的语义表示能力相比,还有千里之遥。
未来,需要探索更强大的结构化语义表示空间。例如,是否可以将分布式表示与符号表示相结合,既保留分布式表示的泛化能力,又兼顾模块化和层次化符号表示带来的抽象能力。也许这是下一轮自然语言理解取得革命进展的突破口之一。
我们课题组正在致力于构建和利用各类型知识图谱的研究,也算是在这个方向上的努力。通过构建常识知识、语言知识、世界知识、认知知识、领域知识等各类型知识图谱,希望建立起更强大的结构化语义表示空间。

不同类型知识是理解人类语言的钥匙
多模态复杂语境的理解
人类并非孤立地使用语言,语言使用需要考虑其复杂的语境。以语言的多义性为例,存在多义的语言单元,总需要其外部的复杂语境信息进行消歧:字的多义性至少需要所组成的词来消歧;词的歧义性至少需要所在的句子来消歧;句子的意思至少要放在语篇或对话语境中,甚至需要复杂的世界知识来帮助理解。

语言单元的多义性需要其外部复杂语境信息进行消歧
这种语境往往是开放的,也是多模态的,如上下文句子的文本信号、对话者的语气等语音信号、所处环境的视觉信号、甚至其他无法名状的各类信息。实际上,很多歧义产生的笑话,在实际语境下并不会让人产生错误理解。例如下图”三餐二楼欢迎新老师生前来就餐“,虽然从句意上有”欢迎 新老师 生前 来 就餐“这种理解的可能性,但在这个场景下其实不可能是这个意思。

三餐二楼欢迎新老师生前来就餐
再如”无线电法国别研究“,虽然从句意上有”无线电 法国 别研究“这种理解的可能性,但作为一本专著的书名,只可能是”无线电法 国别 研究“这种理解。

无线电法国别研究
只是对于计算机而言,如何有效理解语言所处的开放复杂语境,从而实现对语言语义的准确理解,仍是挑战性难题。这既与尚未建立有效的结构语义表示空间有关,也与计算机还不能像人那样进行跨模态的高效学习和理解有关。如何有效识别语言理解所需的语境信息,并建立跨模态多通道的建模,依然任重道远。
小结
这里总结了我对自然语言理解到底难在哪儿的看法。自然语言理解作为人工智能的核心问题,正引起越来越多研究者的兴趣,在各类任务上努力探索,自然语言处理最重要的国际学术年会ACL 2020共有3000多篇投稿,受关注程度可见一斑。
自然语言理解大致有不同的层次,我总结研究路径可以大致为:字斟句酌,实现句级消歧和精准理解;瞻前顾后,初步实现文本内的复杂语境建模,建立篇章或对话理解;博学多识,引入更多外部知识,实现跨模态更复杂语境的理解;善解人意,考虑语言的社会性和主观性因素,实现更有”人性“的自然语言理解;冥思苦想,将语言作为思想工具,实现从语言理解到语言使用的跨越,实现创作和规划的能力。
语言是人类文明的象征,是人类智能的集中体现,因此得到非常多学科从不同角度的思考和关注,如语言学中对句法、语义等问题建立的理论,心理语言学对人类语言习得的探讨,语言哲学对语言与世界关系的探讨,认知语言学对隐喻和范畴等问题的探讨,神经语言学对人脑的语言功能的研究,汉语言学界对于汉语流水句、”王冕七岁上死了父亲“等语言现象的研究,等等。这些,都对人类语言不同侧面的特点进行了卓有成效的考察。
自然语言理解的目标是让计算机掌握人类语言能力,需要充分了解和融合这些对人类语言的已有探索成果,以逼近人类语言的本质,才能更好地设计结构化语义表示空间,实现多模态复杂语境的理解,像人那样智能地理解和使用语言。希望有朝一日,计算机也能读懂#NLP太难了#、#自然语言理解太难了#两个话题标签下的那些话。

自然语言理解也不会



参考文献
[1] Julia Hirschberg and Christopher D. Manning. Advances in Natural Language Processing. Science, 2015.
[2] Hinton, Geoffrey E., James L. McClelland, and David E. Rumelhart. Distributed Representations. Pittsburgh, PA: Carnegie-Mellon University, 1984.
[3] 索绪尔[瑞士]. 普通语言学教程. 北京: 商务印书馆, 1980.
[4] Marc D. Hauser, Noam Chomsky, and W. Tecumseh Fitch. The Faculty of Language: What Is It, Who Has It, and How Did It Evolve?. Science, 2002: 1569-1579.
[5] James W. Pennebaker. The Secret Life of Pronouns: What Our Words Say About Us. NY: Bloomsbury, 2011.
[6] Cristian Danescu-Niculescu-Mizil, Lillian Lee, Bo Pang, Jon Kleinberg. Echoes of power: Language effects and power differences in social interaction. WWW, 2012.
[7] Aylin Caliskan, Joanna J. Bryson, and Arvind Narayanan. Semantics Derived Automatically from Language Corpora Contain Human-like Biases. Science, 2017.
[8] 乔治.莱考夫[美]. 别想那只大象. 浙江人民出版社, 2013.####