网络爬虫简单概述
网络爬虫
1、概念
网络爬虫本质上就是一个程序 或者 脚本, 网络爬虫按照一定规则获取互联网中信息(数据), 一般来说爬虫被分为三大模块: 获取数据 解析数据 保存数据。
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
2、爬虫价值
-
爬虫的价值本质就是获取数据的价值. 数据的价值越高, 爬虫的价值越高
-
数据的价值: 一切皆为数据
-
例如: 获取到了大量的用户信息(基本信息, 购物信息, 浏览信息):
- 广告推荐 用户行为分析(用户画像)
-
例如: 获取到了大量的商品的信息(基本信息, 价格):
- 比价网
3、爬虫的分类
常见分类有两种:
-
通用爬虫: 指的获取互联网中所有的数据, 不局限于网站, 行业, 分类
-
百度 谷歌
-
垂直爬虫: 指的获取互联网中某一个网站, 某一个行业, 某一个分类下的数据
-
慢慢买 笔趣阁
实际开发中: 一般书写那种爬虫:垂直爬虫(数据分析处理)
4、爬虫的开发流程
-
爬虫的执行流程:
-
确定首页URL
-
发送请求, 获取数据
-
解析数据
-
保存数据
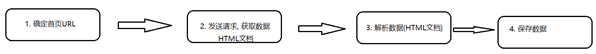
5、爬虫三大模块
5.1、第一大模块:发送请求获取数据
5.1.1、关于Http请求
-
请求相关内容:
- 请求行 : 请求方式 请求的URL 协议版本
- get 和 post 区别:
- get将请求参数放置在url的后面, 而 post将请求参数放置请求体中
- get请求不能无限制的拼接参数, post是没有限制的
- post相对而言要比get安全
- 请求头:
- user-agent : 指定浏览器的内核版本
- cookie : 携带当前网站在浏览器中保存的cookie信息
- referer : 防盗链
- 请求体
- 只有post才有请求体, 请求参数
-
响应相关内容:
- 响应行: 状态码
- 200
- 302
- 304
- 404
- 500
- 响应头 :
- set-cookie : 服务器向浏览器写入cookie信息
- location : 指定重定向的URL路径
- 响应体
- 爬虫获取数据就是获取的响应体的内容
- 响应行: 状态码
5.1.2、使用HttpClient发送Get请求
HttpClient 是Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
httpClient专为java发送http请求而生的, 如果要httpClient ,需要先进行导包
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.6version>
dependency>
java发送请求代码
public class HttpClientGet {
public static void main(String[] args) throws IOException {
//使用httpclient发送get请求
//请求的url
String url = "http://www.ujiuye.com/";
//获取httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建发送方式对象
HttpGet get = new HttpGet(url);
//设置请求头
//get.setHeader("accept-language","zh-CN,zh;q=0.9");
//发送请求
CloseableHttpResponse response = httpClient.execute(get);
//打印响应状态码
System.out.println(response.getStatusLine().getStatusCode());
if (response.getStatusLine().getStatusCode() == 200){
//响应体
HttpEntity entity = response.getEntity();
//获取响应头
//response.getHeaders("status");
//通过工具类获取响应体(读取数据)
//jdk解码方式:gb2312
String res = EntityUtils.toString(entity, "gb2312");
System.out.println(res);
}
}
}
5.1.3、使用HttpClient发送Post请求
首先还是需要导包
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.6version>
dependency>
java代码
public class HttpClientPost {
public static void main(String[] args) throws IOException {
//使用httpclient的post请求发送请求
//url地址
String url = "https://www.chsi.com.cn/";
//获取httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建请求方式对象
HttpPost httpPost = new HttpPost(url);
//提交请求参数就是设置请求体对象
List<BasicNameValuePair> list = new ArrayList<BasicNameValuePair>();
list.add(new BasicNameValuePair("username","rose"));
list.add(new BasicNameValuePair("password","123456"));
HttpEntity reqEntity = new UrlEncodedFormEntity(list);
httpPost.setEntity(reqEntity);
//发送post请求
CloseableHttpResponse response = httpClient.execute(httpPost);
if (response.getStatusLine().getStatusCode() == 200){
//获取响应对象
HttpEntity entity = response.getEntity();
//解析响应体
String res = EntityUtils.toString(entity, "UTF-8");
System.out.println(res);
}
//关闭请求
httpClient.close();
}
}
5.2、第二大模块:解析数据
5.2.1、JSoup解析方式
JSoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
5.2.2、使用流程
导入依赖
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.11.3version>
dependency>
java代码
public class JSoupTest {
/*
解析html
*/
@Test
public void test1() throws Exception{
//获取一个document对象
Document document = Jsoup.parse("\n" +
"\n" +
"\n" +
" \n" +
" 这是一段HTML字符串 \n" +
"\n" +
"\n" +
"\n" +
"\n" +
"");
//通过标签名获取元素
Elements elements = document.getElementsByTag("title");
Element element = elements.get(0);
String text = element.text();
System.out.println(text);
}
/*
解析代码片段
*/
@Test
public void test2() throws Exception{
//获取一个document对象
Document document = Jsoup.parseBodyFragment("这是一个HTML代码片段");
Element element = document.getElementById("span");
System.out.println(element.text());
}
/*
解析file对象
*/
@Test
public void test3() throws Exception{
//获取一个document对象
File file = new File("F:/test.html");
Document document = Jsoup.parse(file, "UTF-8");
Elements elements = document.getElementsByTag("title");
Element element = elements.get(0);
System.out.println(element.text());
}
}
5.2.3、小案例
获取中公有就业官网上提供的课程名称
- 首先还是需要导入HttpClient和JSoup依赖
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.6version>
dependency>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.11.3version>
dependency>
- java代码解析
public class GetCourse {
//JS方式
@Test
public void test1() throws IOException {
//获取优就业官网所有的课程的名字
String url = "http://www.ujiuye.com/";
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = httpClient.execute(get);
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String res = EntityUtils.toString(entity, "gb2312");
Document document = Jsoup.parse(res);
//获取ul标签
Elements elements = document.getElementsByClass("nav_left");
//获取ul标签下的li标签
Element UlEle = elements.get(0);
Elements lis = UlEle.getElementsByTag("li");
//遍历li获取a标签并获取标签内容
for (Element li : lis) {
Element a = li.getElementsByTag("a").get(0);
System.out.println(a.text());
}
}
}
//JQuery方式
@Test
public void test2() throws IOException {
//获取有就业官网所有的课程的名字
String url = "http://www.ujiuye.com/";
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = httpClient.execute(get);
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String res = EntityUtils.toString(entity, "gb2312");
Document document = Jsoup.parse(res);
Elements elements = document.select(".nav_left>li>a>span");
for (Element element : elements) {
System.out.println(element.text());
}
}
}
}
5.2.4、解析JSON字符串获取有价值信息
- 导入依赖
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.6version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.58version>
dependency>
- 部分核心代码
public class GetNews {
@Autowired
private NewsServiceImpl service;
@Test
public void test() throws IOException, ParseException {
int page = 0;
while (true){
//从腾讯娱乐网上,获取娱乐新闻信息
String url = "https://pacaio.match.qq.com/irs/rcd?cid=146&token=49cbb2154853ef1a74ff4e53723372ce&ext=ent&page="+page+"&callback=__jp6";
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpClient.execute(httpGet);
//解析出有价值的信息
if (response.getStatusLine().getStatusCode() == 200){
//获取响应的数据
String res = EntityUtils.toString(response.getEntity(), "utf-8");
//转化成为Json字符串
res = toJsonString(res);
//解析json字符串
HashMap map = JSON.parseObject(res, HashMap.class);
Integer integer = (Integer)map.get("datanum");
if (integer == 0){
return;
}
//获取Map中所有新闻数据的集合
List<News> newsList = getNewsList(map);
for (News news : newsList) {
//将有价值的数据保存到MySQL数据库
service.saveNews(news);
}
}
System.out.println("已经获取第"+page+"页新闻");
page++;
}
}
/**
* 转化为Json字符串
* @param src
* @return
*/
public static String toJsonString(String src){
String res = src;
Integer begin = res.indexOf("{");
Integer end = res.lastIndexOf(")");
res = res.substring(begin, end);
return res;
}
public static List<News> getNewsList(Map map) throws ParseException {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
List<News> list = new ArrayList<News>();
//所有的新闻对应的JSON的数组对象
JSONArray data = (JSONArray)map.get("data");
for (Object object : data) {
//一条新闻的JSON对应的Map对象
Map newsMap = (Map) object;
News news = new News();
news.setTitle(newsMap.get("title").toString());
news.setIntro(newsMap.get("intro").toString());
news.setSource(newsMap.get("source").toString());
news.setUrl(newsMap.get("url").toString());
String publishTimeString = newsMap.get("publish_time").toString();
Date date = format.parse(publishTimeString);
news.setPublishTime(date);
list.add(news);
}
return list;
}
}
5.3、第三大模块:保存数据
解决前面两部分之后,第三部分比较简单,利用三层架构完成数据增添即可。