grpc系列:负载均衡及grpc负载均衡相关整理
一、负载均衡
负载均衡(LB)在微服务架构演进中具有非常重要的意义,负载均衡是高可用网络基础架构的关键组件,我们的期望是调用是平均分配在所有的服务器服务器上的,通常用于将工作负载分布到多个服务器来提高网站、应用、数据库或其他服务的性能和可靠性。

1.1 负载均衡三种技术方案
目前市面上最常见的负载均衡技术方案主要有三种:
-
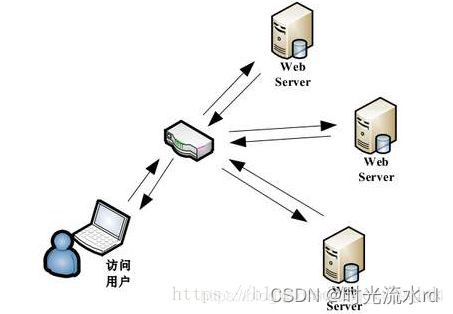
基于DNS负载均衡
在这里插入图片描述

-
基于硬件负载均衡
硬件的负载均衡那就比较牛逼了,比如大名鼎鼎的 F5 Network Big-IP,也就是我们常说的 F5,它是一个网络设备,你可以简单的理解成类似于网络交换机的东西,完全通过硬件来抗压力,性能是非常的好,每秒能处理的请求数达到百万级,即 几百万/秒 的负载,当然价格也就非常非常贵了,十几万到上百万人民币都有。
因为这类设备一般用在大型互联网公司的流量入口最前端,以及政府、国企等不缺钱企业会去使用。一般的中小公司是不舍得用的。
采用 F5 这类硬件做负载均衡的话,主要就是省心省事,买一台就搞定,性能强大,一般的业务不在话下。而且在负载均衡的算法方面还支持很多灵活的策略,同时还具有一些防火墙等安全功能。但是缺点也很明显,一个字:贵。
-
基于软件负载均衡

软件负载均衡是指使用软件的方式来分发和均衡流量。软件负载均衡,分为7层协议 和 4层协议。
网络协议有七层,基于第四层传输层来做流量分发的方案称为4层负载均衡,例如 LVS,而基于第七层应用层来做流量分发的称为7层负载均衡,例如 Nginx。这两种在性能和灵活性上是有些区别的。
基于4层的负载均衡性能要高一些,一般能达到 几十万/秒 的处理量,而基于7层的负载均衡处理量一般只在 几万/秒 。
基于软件的负载均衡的特点也很明显,便宜。在正常的服务器上部署即可,无需额外采购,就是投入一点技术去优化优化即可,因此这种方式是互联网公司中用得最多的一种方式。
主要有以下几种
- HAProxy
- Nginx
upstream apigateway {
server 127.0.0.1:8080 max_fails=1 fail_timeout=10s weight=100;
server localhost:8080 max_fails=1 fail_timeout=5s weight=20;
server in-prod-common-goserver-2 backup;
server in-prod-common-goserver-4 backup;
server in-prod-common-goserver-5 backup;
server in-prod-common-goserver-7 backup;
server in-prod-common-goserver-8 backup;
#server in-prod-common-goserver-2 max_fails=1 fail_timeout=2s weight=1;
#server in-prod-common-goserver-4 max_fails=1 fail_timeout=2s weight=1;
#server in-prod-common-goserver-5 max_fails=1 fail_timeout=2s weight=1;
#server in-prod-common-goserver-7 max_fails=1 fail_timeout=2s weight=1;
keepalive 1024; #保持连接
}
location / {
proxy_pass http://apigateway;
proxy_redirect default;
client_max_body_size 20M;
}
- weight=number设定服务器的权重,默认是1。
- max_fails=number设定Nginx与服务器通信的尝试失败的次数。在fail_timeout参数定义的时间段内,如果失败的次数达到此值,Nginx就认为服务器不可用。在下一个fail_timeout时间段,服务器不会再被尝试。 失败的尝试次数默认是1。设为0就会停止统计尝试次数,认为服务器是一直可用的。 你可以通过指令proxy_next_upstream、 fastcgi_next_upstream和memcached_next_upstream来配置什么是失败的尝试。 默认配置时,http_404状态不被认为是失败的尝试。
- fail_timeout=time设定
- 默认情况下,该超时时间是10秒。backup标记为备用服务器。当主服务器不可用以后,请求会被传给这些服务器。down标记服务器永久不可用,可以跟ip_hash指令一起使用。
- keepalive connections;:激活对上游服务器的连接进行缓存。
- least_conn:指定服务器组的负载均衡方法,根据其权重值,将请求发送到活跃连接数最少的那台服务器。 如果这样的服务器有多台,那就采取有权重的轮转法进行尝试。
- ip_hash; :指定服务器组的负载均衡方法,请求基于客户端的IP地址在服务器间进行分发。
- down:如果其中一个服务器想暂时移除,应该加上down参数。这样可以保留当前客户端IP地址散列分布。
- LVS
- ipvs k8s负载组件kube-proxy使用ipvs
1.2 负载均衡策略
- ipvs k8s负载组件kube-proxy使用ipvs
- 轮询策略
轮询策略其实很好理解,就是当用户请求来了之后,「负载均衡器」将请求轮流的转发到后端不同的业务服务器上。无需关注后端服务的状态,只要有请求,就往后端轮流转发,非常的简单、实用。
在实际应用中,轮询也会有多种方式,有按顺序轮询的、有随机轮询的、还有按照权重来轮询的。 - 负载度策略
负载度策略是指当「负载均衡器」往后端转发流量的时候,会先去评估后端每台服务器的负载压力情况,对于压力比较大的后端服务器转发的请求就少一些,对于压力比较小的后端服务器可以多转发一些请求给它。
这种方式就充分的结合了后端服务器的运行状态,来动态的分配流量了,比轮询的方式更为科学一些。
但是这种方式也带来了一些弊端,因为需要动态的评估后端服务器的负载压力,那这个「负载均衡器」除了转发请求以外,还要做很多额外的工作,比如采集 连接数、请求数、CPU负载指标、IO负载指标等等,通过对这些指标进行计算和对比,判断出哪一台后端服务器的负载压力较大。
因此这种方式带来了效果优势的同时,也增加了「负载均衡器」的实现难度和维护成本。 - 响应策略
响应策略是指,当用户请求过来的时候,「负载均衡器」会优先将请求转发给当前时刻响应最快的后端服务器。
也就是说,不管后端服务器负载高不高,也不管配置如何,只要觉得这个服务器在当前时刻能最快的响应用户的请求,那么就优先把请求转发给它,这样的话,对于用户而言,体验也最好。
那「负载均衡器」是怎么知道哪一台后端服务在当前时刻响应能力最佳呢?
这就需要「负载均衡器」不停的去统计每一台后端服务器对请求的处理速度了,比如一分钟统计一次,生成一个后端服务器处理速度的排行榜。然后「负载均衡器」根据这个排行榜去转发服务。
那么这里的问题就是统计的成本了,不停的做这些统计运算本身也会消耗一些性能,同时也会增加「负载均衡器」的实现难度和维护成本。 - 哈希策略
Hash策略也比较好理解,就是将请求中的某个信息进行hash计算,然后根据后端服务器台数取模,得到一个值,算出相同值的请求就被转发到同一台后端服务器中。
常见的用法是对用户的IP或者ID进行这个策略,然后「负载均衡器」就能保证同一个IP来源或者同一个用户永远会被送到同一个后端服务器上了,一般用于处理缓存、会话等功能的时候特别好用。
1.3 七层与四层负载均衡
所谓四层和七层负载均衡是按照网络层次OSI来划分的负载均衡类型(也可以按照其他的规则来分类,比如:应用的地理结构),简单来说:
- 四层负载均衡表示负载均衡器用ip+port接收请求,再直接转发到后端对应的服务上,工作在传输层( transport layer );
- 七层负载均衡表示负载均衡器根据虚拟的url或主机名来接收请求,经过处理后再转向相应的后端服务上,工作在应用层( application layer )。
下图表示了4层和7层负载均衡在建立TCP连接上的区别,从图中可以看出,四层负载均衡需要建立的TCP连接其实之有一个,它只做一次转发,client直接和server连接;而7层负载均衡则需要建立两次TCP连接,client到LB,LB根据消息中的内容( 比如URL或者cookie中的信息 )来做出负载均衡的决定,接着建立LB到server的连接。
7 层负载均衡有什么好处呢?
- 因为存在解包/封包的过程,比4层LB更加CPUintensive,但是却降低性能;
- 可以编写更加智能的负载均衡策略,比如根据URL、cookie中的信息等,甚至对接收到的内容做一些优化和修改,比如加密、压缩;
- 使用buffer的方式来缓解服务器连接慢的问题,从而提高性能
- 具有7层负载均衡功能的设备通常也被称为反向代理服务器(reverseproxy server)
1.4 代理 - 正向代理
正向代理是客户端和其他所有服务器(重点:所有)的代理者
一般的正向代理,比如,任何可以连接到该代理服务器的软件,就可以通过代理访问任何的其他服务器,然后把数据返回给客户端,这里代理服务器只对客户端负责
在使用VPS访问的时候,通常会使用一个本地的代理服务器,浏览器的网络包会先经过本地的代理服务器,代理服务器会通过远在异国它乡的电脑来访问并返回消息;
这就好比去附近的咖啡店要先问一下手机咖啡店在哪里一样,手机就是一个正向代理服务器。 - 反向代理
反向代理是客户端和所要代理的服务器之间的代理。
反向代理的话,如果他反向代理了两个服务,那么之后客户端访问这两个服务器的时候,该代理服务器才会给它代理,也就是说,这里的代理服务器只对该代理服务器所代理的服务器负责
这就好比你去朋友家做客,开门的却是个管家,问你找谁?这时候管家就是一个反向代理了。
其他OSI层也可以做反向代理
1.5 负载均衡算法
- 随机算法
- 轮询round_robin
- 加权轮询weighted round robin
- 最小连接
- fair(三方软件)
- Hash
- Ip Hash
- 取模hash
- 一致性hash
- etc
二、grpc负载均衡
grpc使用的是客户端负载均衡模式,每次新建连接的时候会根据负载均衡算法选出服务端的IP然后建立连接。早期grpc默认支持两种算法pick_first(第一次地址) 和 round_robin(轮询)
-
pick_first
pick_first每次都是尝试连接第一个地址,如果连接失败就会尝试下一个,直到连接成功为止,之后的RPC请求都会使用这个连接 -
round_robin
round_robin会对每个地址建立连接,之后的RPC请求会依次通过这些连接发送到后端
type rrPicker struct {
// subConns is the snapshot of the roundrobin balancer when this picker was
// created. The slice is immutable. Each Get() will do a round robin
// selection from it and return the selected SubConn.
subConns []balancer.SubConnmu sync.Mutex
next int
}
func (p *rrPicker) Pick(balancer.PickInfo) (balancer.PickResult, error) {
p.mu.Lock()
sc := p.subConns[p.next]
p.next = (p.next + 1) % len(p.subConns)
p.mu.Unlock()
return balancer.PickResult{SubConn: sc}, nil
}
- Grpclb:本质是两阶段轮询
// lbPicker does two layers of picks:
//
// First layer: roundrobin on all servers in serverList, including drops and backends.
// - If it picks a drop, the RPC will fail as being dropped.
// - If it picks a backend, do a second layer pick to pick the real backend.
//
// Second layer: roundrobin on all READY backends.
//
// It’s guaranteed that len(serverList) > 0.
type lbPicker struct {
mu sync.Mutex
serverList []*lbpb.Server
serverListNext int
subConns []balancer.SubConn // The subConns that were READY when taking the snapshot.
subConnsNext int
stats *rpcStats
}
func newLBPicker(serverList []*lbpb.Server, readySCs []balancer.SubConn, stats *rpcStats) *lbPicker {
return &lbPicker{
serverList: serverList,
subConns: readySCs,
subConnsNext: grpcrand.Intn(len(readySCs)),
stats: stats,
}
}
func (p *lbPicker) Pick(balancer.PickInfo) (balancer.PickResult, error) {
p.mu.Lock()
defer p.mu.Unlock()
// Layer one roundrobin on serverList.
s := p.serverList[p.serverListNext]
p.serverListNext = (p.serverListNext + 1) % len(p.serverList)
// If it’s a drop, return an error and fail the RPC.
if s.Drop {
p.stats.drop(s.LoadBalanceToken)
return balancer.PickResult{}, status.Errorf(codes.Unavailable, “request dropped by grpclb”)
}
// If not a drop but there’s no ready subConns.
if len(p.subConns) <= 0 {
return balancer.PickResult{}, balancer.ErrNoSubConnAvailable
}
// Return the next ready subConn in the list, also collect rpc stats.
sc := p.subConns[p.subConnsNext]
p.subConnsNext = (p.subConnsNext + 1) % len(p.subConns)
done := func(info balancer.DoneInfo) {
if !info.BytesSent {
p.stats.failedToSend()
} else if info.BytesReceived {
p.stats.knownReceived()
}
}
return balancer.PickResult{SubConn: sc, Done: done}, nil
}
// rrPicker does roundrobin on subConns. It’s typically used when there’s no
// response from remote balancer, and grpclb falls back to the resolved
// backends.
//
// It guaranteed that len(subConns) > 0.
type rrPicker struct {
mu sync.Mutex
subConns []balancer.SubConn // The subConns that were READY when taking the snapshot.
subConnsNext int
}
func newRRPicker(readySCs []balancer.SubConn) *rrPicker {
return &rrPicker{
subConns: readySCs,
subConnsNext: grpcrand.Intn(len(readySCs)),
}
}
func (p *rrPicker) Pick(balancer.PickInfo) (balancer.PickResult, error) {
p.mu.Lock()
defer p.mu.Unlock()
sc := p.subConns[p.subConnsNext]
p.subConnsNext = (p.subConnsNext + 1) % len(p.subConns)
return balancer.PickResult{SubConn: sc}, nil
}
- Rls: 递归最小二乘算法
三、grpc自定义负载均衡
- 设置方式
grpc.WithDefaultServiceConfig: 旧的版本可以通过grpc.RoundRobin(),和grpc.WithBalancer()来设置负载均衡,这个版本grpc.RoundRobin()已经取消了,grpc.WithBalancer()和grpc. 也WithBalancerName()标记为废弃。
可以这样设置BalancingPolicy
- 自定义设置:如咱们代码的使用
四、扩展点
-
在 Kubernetes 中 gRPC 负载均衡有问题?
gRPC 的 RPC 协议是基于 HTTP/2 标准实现的,HTTP/2 的一大特性就是不需要像 HTTP/1.1 一样,每次发出请求都要重新建立一个新连接,而是会复用原有的连接。
所以这将导致 kube-proxy 只有在连接建立时才会做负载均衡,而在这之后的每一次 RPC 请求都会利用原本的连接,那么实际上后续的每一次的 RPC 请求都跑到了同一个地方。
注:使用 k8s service 做负载均衡的情况下 -
k8s负载均衡
- NodePort
- LoadBlancer
- 四层负载均衡实现:kube-proxy
-
userspace 模式
v1.0及之前版本的默认模式;
在 userspace 模式下,service 的请求会先从用户空间进入内核 iptables,然后再回到用户空间,
由 kube-proxy 完成后端 Endpoints 的选择和代理工作,这样流量从用户空间进出内核带来的性能损耗是不可接受的。
请求到达 iptables 时会进入内核,而 kube-proxy 监听是在用户态,
这样请求就形成了从用户态到内核态再返回到用户态的传递过程, 降低了服务性能。
因此,userspace 性能差。 -
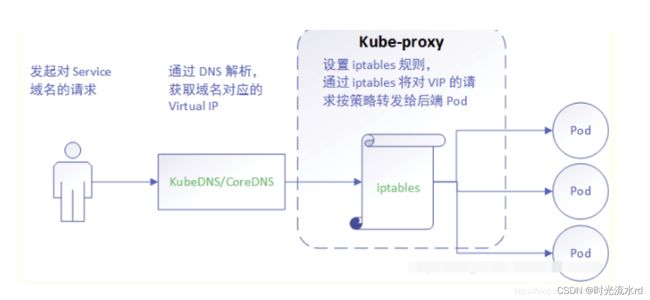
iptables 模式
v1.1 版本中开始增加了 iptables mode,并在 v1.2 版本中正式取代 userspace 成为默认模式;
通过 Iptables 实现一个四层 TCP NAT ;
kube_proxy 只负责创建 iptables 的 nat 规则,不负责流量转发。
iptables 模式虽然克服了 userspace 那种 内核态–用户态 之间反复传递的缺陷,
但是在集群规模大的情况下,iptables rules 过多会导致性能显著下降。
因此,iptables 性能勉强适中 。
-
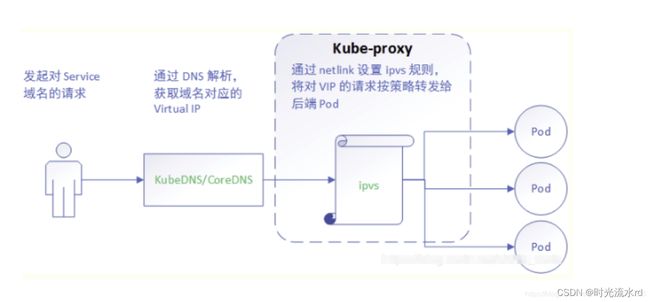
ipvs 模式
在 1.8 以上的版本中,kube-proxy 组件增加了 ipvs 模式;
-
ipvs 基于 NAT 实现,不创建反向代理, 也不创建 iptables 规则,通过 netlink 创建规则;
而 netlink 通过 hashtable 组织 service,其控制面和转发面的性能都是 O(1) 的,而且直接工作在内核态,因此在性能上比 userspace 和 iptables 都更优秀。
- 七层负载均衡实现: Ingress
Ingress 是 k8s 的一种资源对象,
该对象允许外部访问 k8s 服务, 通过创建规则集合来配置访问权限,这些规则定义了哪些入站连接可以访问哪些服务;
Ingress 仅支持 HTTP 和 HTTPS 协议;
ingress 可配置用于提供外部可访问的服务 url、负载均衡流量、SSL终端和提供虚拟主机名配置。
Ingress: balancer + Ingress Controller + yaml config
ingress-controller 是实现反向代理和负载均衡的程序,
通过监听 Ingress 这个 api 对象里的配置规则并转化成 Nginx 的配置 , 然后对外部提供服务
Ingress 对于上面提到的 “如何修改 Nginx 配置” 这个问题的解决方案是:
把 “修改 Nginx 配置各种域名对应哪个 Service ” 这些动作抽象为一个 Ingress 对象,
然后直接改 yml 创建/更新就行了,不用再修改 nginx 。
而 ingress-controller 通过与 k8s API 交互,动态感知集群中 Ingress 规则的变化并读取它,
然后按照模板生成一段 Nginx 配置,再写到 Nginx Pod 里,最后再 reload 一下生效。
大概的访问路径如下:
用户访问 --> LB --> ingress-nginx-service --> ingressController-ingress-nginx-pod --> ingress字段中调用的后端pod
注意后端 pod 的 service 只提供 pod 归类,
归类后 ingress 会将此 service 中的后端 pod 信息提取出来,
然后动态注入到 ingress-nginx-pod 中的 ingress 字段中,
如此,后端 pod 就能被调用了。
参考链接
https://github.com/grpc/grpc-go
https://www.bilibili.com/read/cv6653581
https://blog.csdn.net/y_xianjun/article/details/81327708
https://www.jianshu.com/p/9ce0e17f2941
https://zhuanlan.zhihu.com/p/32841479