Mysql进阶

这次的博客主要讲的是视图、存储过程、函数、触发器
进阶功能:
视图
定义:视图就是一条SELECT语句执行成功后返回的结果集
创建视图:
create view 视图名 as select 列1,列2... from 表名使用视图:
select * from 视图名删除视图:
drop view 视图名存储过程
定义:事先经过编译并存储在数据库中的一段SQL语句的集合,调用的过程可以简化开发人员的很多工作,减少对数据库的访问,对提高数据处理效率有好处(in out inout)
创建存储过程:
create procedure 存储过程名([int 变量名 类型,out 参数2,...])
#存储过程的参数分为in,out,inout三种类型
#in代表输入参数,out代表输出参数,inout代表又是输入又是输出参数
#存储过程必须在begin~end之间
begin
[declare 变量名 类型 [DEFAULT 值]];
#declare中用来声明变量,用default来进行赋值,用set进行给变量金晓明重新赋值 set 变量=值
存储过程语句块;
end;例如:
DELIMITER $$
USE `map`$$
DROP PROCEDURE IF EXISTS `admin`$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `admin`()
BEGIN
DECLARE v_num INT DEFAULT 0;
SET v_num=10;
SELECT v_num;
END$$
DELIMITER ;
#CALL admin() #调用存储过程函数
函数语法:
#若函数没有入参,需要配置
#SET GLOBAL log_bin_trust_function_creators=TRUE;
create function 函数名([参数表列表])returns 数据类型
#参数列表包含两部分:参数名 参数类型
begin
declare 变量;
sql语句;
return 值;#必须要有return语句
end
#删除函数
#DROP FUNCTION 函数名;例如:
DELIMITER $$
CREATE
FUNCTION `map`.`findadminByid`(p_id INT)
RETURNS VARCHAR(20)
BEGIN
DECLARE v_name VARCHAR(20);#定义变量
SELECT account INTO v_name FROM admin WHERE id=p_id;//Sql语句
RETURN v_name;#返回查询到的名字
END$$
DELIMITER ;触发器
定义:是一种特殊的存储结构,特殊性在于它并不需要用户直接调用,而是对表添加、修改、删除之前或者之后自动执行的存储过程
语法:
CREATE TRIGGER触发器名称 触发时机 触发事件
#触发器名称:用来标识触发器的,由用户定义
#触发时机:before或者是after
#触发事件:insert update delete
#表名称:建立触发器的表名
#语句:触发器程序体
ON 表名称
FOR
EACH ROW
-- 行级触发
BEGIN
语句
END;
#与表相关联
#自动激活触发器
#不能直接调用
#作为事务的一部分例如:
用户删除时,自动删除用户对应用户角色关系
DELIMITER $$
CREATE
TRIGGER `map`.`delete_admin_role` BEFORE DELETE
ON `map`.`admin`
FOR EACH ROW
BEGIN
DELETE FROM admin_role WHERE adminid=old.id;
END$$
DELIMITER ;用户添加时,自动在另外一张表中添加用户名称以及添加时间
DELIMITER $$
CREATE
TRIGGER `map`.`add_admin_logs` AFTER INSERT
ON `map`.`admin`
FOR
EACH ROW BEGIN
INSERT INTO LOGS (account,oper_time)VALUES(new.id,new.account,NOW());
END$$
DELIMITER ;Mysql架构:

连接层:负责进行接收客户端的连接请求,可以进行认证
服务层:接收Sql语言解析,优化并缓存
引擎层:引擎层是真正落地实现的具体方式,不同的存储引擎特点不同
物理文件村存储:使用各种文件用来存储数据以及各种日志文件
存储的引擎类型
功能 |
MYISAM |
Memory |
InnoDB |
Archive |
存储限制 |
256TB |
RAM |
64TB |
None |
支持事务 |
No |
No |
YES |
No |
支持全文索引 |
YES |
No |
No |
No |
支持树索引 |
YES |
YES |
YES |
No |
支持哈希索引 |
No |
YES |
No |
No |
支持数据缓存 |
No |
N/A |
YES |
No |
支持外键 |
No |
No |
YES |
No |
InnoDB:是一个事务型的存储引擎,有行级锁和外键约束,支持全文检索,会在内存中建立缓存池,
用于缓存数据和索引,支持主键自增,不存储表的总行数
MyISAM:无事务支持,也不支持行级锁和外键,当对数据库中的表进行插入、修改、更新时,会显得效率较低,支持全文检索,会存储表的总行数
索引
定义:比较高效的获取数据的数据结构(排好序的快速查找的数据结构),在数据库中,除了需要维护数据,还要维护着一些特定的数据结构,这些数据结构以某种方式指向数据,这种数据结构就是数据
原理:通过不断的缩小范围,找到想要找到的数据,把随机的事件变成顺序的事件(相当于书的目录)
优势:1.降低数据库IO的成本,提高查询效率
2.对数据进行排序,降低了数据排序的成本,降低了CPU的消耗
劣势:1.占用磁盘空间
2.降低更新表的速度,在更新数据的时候,也要对索引进行维护
索引分类:
主键索引: 设定为主键后数据库自动建立索引
alter table 表名 add primary key 表名(列名);删除主键索引:
alter table 表名 drop primary key;单值索引:一个索引只包含单列
CREATE INDEX 索引名 ON 表名(列名);
删除索引:
DROP INDEX 索引名;#创建一个单值索引
CREATE INDEX abstract1_index ON newsinf(abstract1)
唯一索引:索引列的值必须唯一,允许为null
CREATE UNIQUE INDEX 索引名 ON 表名(列名);
删除索引
DROP INDEX 索引名 ON 表名;组合索引(复合索引):
当一个表中需要用到多个列进行查询的时候,复合索引比单值索引所需要的开销更小
创建复合索引:
CREATE INDEX 索引名 ON 表名(列 1,列 2...);
删除索引:
DROP INDEX 索引名 ON 表名;组合索引最左前缀原则:
在使用组合索引的时候,必须要出现做左侧列为条件,否则组合索引不生效
比如:
a |
b |
c |
select * from table where a=’’and b=’’索引生效
select * from table where b=’’and a=’’索引生效
select * from table where a=’’and c=’’索引生效
select * from table where b=’’and c=’’索引不生效全文索引:
需要进行模糊查询的时候,只有全文索引才有效
CREATE FULLTEXT INDEX 索引名 ON 表名(字段名) WITH PARSER ngram;#创建全文索引
SELECT 结果 FROM 表名 WHERE MATCH(列名) AGAINST(‘搜索词')#全文索引进行模糊查询索引创建原则:
需创建索引:
主键自动建立唯一索引
频繁作为查询条件的字段应该建立索引
查询与其他关联的字段,外键关系建立索引
查询中排序的字段
分组中的字段
无需创建索引:
表中数据少
经常进行增删改查的表
where条件中用不到的字段不创建索引
数据重复且分布平均的表字段
索引数据结构:
InnoDB存储引擎就是用的是B+Tree实现其索引结构
在这里先要了解什么是B树,什么是B+树?
B树:

B+树:

B+树数据之间又维护了一个链表,便于数据的查询,高度不是太高,可以更好的进行全表扫描
一个节点可以存储多个数据
非叶子节点不存储数据,主存储索引,可以放更多的索引
数据记录都存放在叶子节点中
所有的叶子节点之间都有一个链指针
聚簇索引和非聚簇索引
聚簇索引:找到索引就能找到数据
非聚簇索引:找到索引但没有找到数据,需要回表查询才能找到数据
这里我给id设置了默认自增的主键,account设置了唯一索引
假设,我直接根据主键查询获取其他字段的数据,此时主键就是聚簇索引
假设我根据account查询account和password时,因为account本身就是一个唯一索引,但是查询的列表不仅仅是account,当命中索引时,索引节点上的数据存储的是主键ID,需要根据id再进行查询,才能得到想要的数据,所以account就是非聚簇索引
假设我根据account查询account,这种命中索引查询时,直接返回编号,因为需要返回的就是索引本身,不需要回表查询,故这种场景下account就是聚簇索引
事务
事务是数据为了保证数据操作的原子性、持久性、隔离性、一致性,数据库提供能一套机制,在同一事务中,如果有多条SQL执行,事务确保执行的可靠性
ACID:
原子性:一个事务中多条SQL要么一起执行要么都不执行
持久性:一旦事务提交,数据就持久保存在硬盘上
隔离性:很多事务同时对数据进行操作,需要不同的隔离机制来进行控制,防止数据不完整
一致性:数据经过很多操作,最终的结果要与预期的结果一致,保证数据的完整性,原子性、隔离性、持久性都是为了保证数据的一致性
事务的隔离性:
创建一张案例表,同时开启两个事务进行案例演示
CREATE TABLE WORK(
id INT PRIMARY KEY AUTO_INCREMENT KEY,
account VARCHAR(20),
age INT
)
SET GLOBAL autocommit=0;#关闭自动提交
SHOW GLOBAL VARIABLES LIKE 'autocommit';#查看是否注定提交状态读 -未提交:
B事务读到了A事务未提交的数据
问题:产生脏读(垃圾数据,因为A事务可能会回滚)
解决办法:设置隔离级别为读 已提交
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED#设置全局变量 ——读 未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED#设置局部变量 ——读 未提交
#读 未提交--->脏读
BEGIN
INSERT INTO works(account,age)VALUES("张三",20)
ROLLBACK#回滚
COMMIT
END2.读 已提交:
B事务读到了A事务已经提交的事务
问题:不可重复读(B事务在开启后的两次相同的查询中,中间A事务进行了一次修改操作,结果在同一个事务中两次查询结果不一样)
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED#设置局部变量--读已提交
#读已提交-->不可重复读
BEGIN
INSERT INTO works(account,age)VALUES("张三",20)
UPDATE works SET age=18
COMMIT
END3.可重复读:
B事务在同一事务开启后的两次查询中,两次查询结果是相同的
产生问题:幻读(一般不会出现幻读,但是在特定的实例中也是可以出现幻读的-->Select * from 表名 for update)
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ#设置局部变量-->可重复读
BEGIN
UPDATE works SET age=21
COMMIT4.串行化
A事务在操作某一行数据时,会给该行加锁,B事务就不能对该行进行读写操作(等待)
串行化不会发生脏读、不可重复读、幻读等问题
事务实现的原理:
ACID:原子性(undolog)、持久性(redolog)、隔离性(锁 MVCC)、一致性(前三个性质一起保证了一致性)
原子性(undolog):在事务对数据库操作时,会在redolog中进行记录,但是在事务回滚的时候,redolog会自动执行反向操作,比如我们在对数据库添加一条insert操作时,在进行回滚的时候,redolog中会自动给我们执行一条delete操作
持久性(redolog):redolog叫做重做日志,保持事务一致性的重要保证,在进行事务添加操作的时候,并不会及时把数据存入硬盘,因为操作一条存一条的话对资源浪费比较大,所以在添加的时候,会优先在redolog中存入日志,在宕机或者是一些突发情况下数据也可以由redolog进行数据恢复
隔离级别实现原理(MVCC)
MVCC(多版本并发控制 Multi-Version Concurrent Control),是MySQL提高性能的一种方式,配合Undo log和版本链,让不同的事务的读-写、写-读操作可以并发执行,从而提升系统性能。
MVCC使得数据库读不会对数据加锁,普通Select 请求不会加锁,提高了数据库的并发处理能力,借助MVCC,数据库可以实现READ COMMITTED ,REPEATABLE READ等隔离级别。
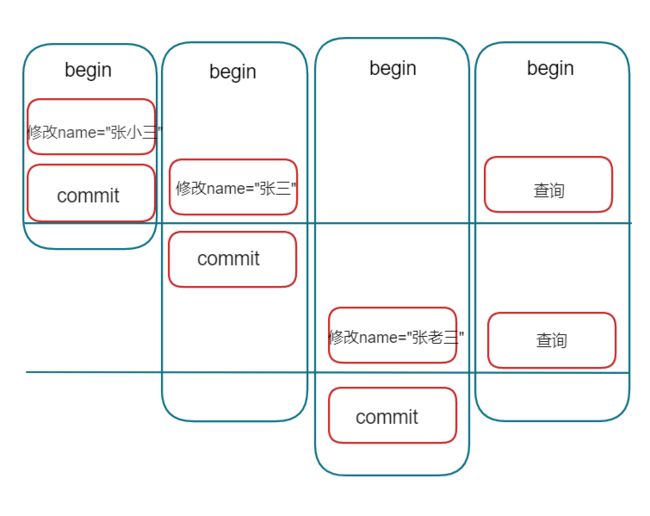
可重复读:两次都查询到的是张小三
读已提交:第一次是张小三 ,第二次是张三
InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现的,一个是事务ID(TRX_ID),一个是保存了回滚指针(ROLL_PT)
TRX_ID:每次对某条记录进行改动时,都会把对应的事务id赋给TRX_ID中
ROLL_PT:每次对记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列相当于是一个指针,可以通过它来找到该记录修改前的信息
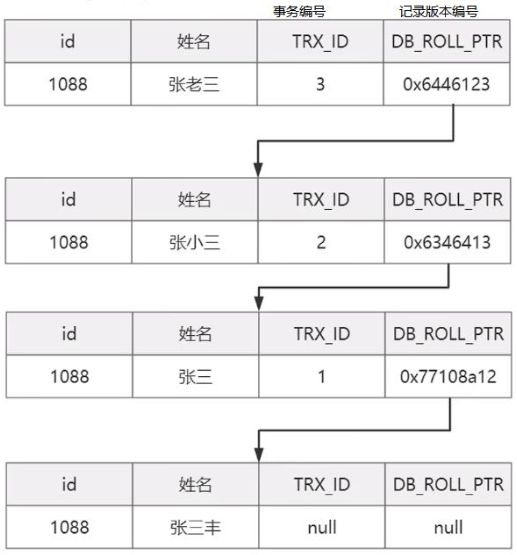
随着更新次数的增多,所有的版本都会被ROLL_PT属性连接成一个链表,我们把这个叫做版本链,头结点记录着当前最新的值,每个版本中包含该版本对应的事务id,便于查询
ReadView
ReadView俗称快照,MVCC提取数据的依据
ReadView 是一个数据结构,包含 4 个字段
m_ids:当前活跃的事务编号集合
min_trx_id:最小活跃事务编号
max_trx_id:预分配事务编号,当前最大事务编号+1
creator_trx_id:ReadView 创建者的事务编号
读已提交:称为当前读,每个事务每次读取时,会自动生成一个ReadView,每次读取都是最新的内容
可重复读:称为快照读,当第一次查询的时候,会生成一个ReadView,第二次查询还是在当前的ReadView进行查询数据
锁机制
为了实现隔离性,InnoDB通过锁机制来保证这一点
锁的种类:
行锁:单行操作(开销大,加锁慢,会出现死锁)
间隙锁:范围操作
表锁:整张表操作(开销小,加锁快,不会出现死锁)
共享锁:读锁,允许其他事务进行读操作,不允许别的事务进行加排他锁,自己也不能对该对象进行修改操作
排他锁:写锁,不允许其他事务进行读写操作,自己可以对该对象进行读写操作
如果加排他锁可以使用 select …for update 语句,加共享锁
可以使用 select … lock in share mode 语句。
Sql优化
尽量使用具体字段进行设计(查询)
避免在where子句中使用or来连接条件(使用union进行结果合并)
尽量使用数值代表字符串类型
使用varchar来代替char
在where及orderby涉及的列上建立索引
应尽量避免索引失效
(1)对字段进行null值判断
(2)避免where子句中使用or连接
(3)in 、not in会导致全表扫描
(4)模糊查询(like)
(5)在where中使用函数操作
7.优先使用inner join
8.提高group by 语句的效率
9.清空表时优先使用truncate 表名
10.表连接不宜过多,索引不宜太多,一般在5个以内
11.避免索引使用内置函数
12.使用example分析SQL执行计划