并发编程之Future&ForkJoin框架原理分析
并发编程之Future&ForkJoin框架原理分析
- 1、Future
-
- 1.1、Future是什么?
- 1.2、Future的submit方法示例
- 2、ForkJoin
-
- 2.1、什么是ForkJoin?
- 2.2、ForkJoin工作模型
- 2.3、ForkJoin特性
- 2.4、ForkJoin工作窃取
- 2.5、ForkJoin应用场景
- 2.6、ForkJoin工作图
- 2.7、ForkJoin工作提交整体流程图
- 3、ForkJoin的使用
-
- 3.1、RecursiveAction
- 3.2、RecursiveTask
- 3.3、CountedCompleter
- 10、辅助知识
-
- 10.1、任务性质类型分类
-
- 10.1.1、CPU密集型(CPU-bound)
- 10.1.2、IO密集型(I/O bound)
- 10.2、分治思维
1、Future
1.1、Future是什么?
在我们使用线程池提交线程的时候,往往使用的是execute方法,提交完成之后只能是知道自己提交了,但是却不知线程的执行结果如何,在这里如果我们使用submit方法,就可以得到线程返回的一个Future接口对象,当我们使用Future接口对象get方法去获取返回结果的时候,会发生异步阻塞,当然是可以设置超时时间的。
总结:Future接口对象可以接收线程执行完成之后的结果。
1.2、Future的submit方法示例
public static <RestTemplate> void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(5);
// 这里执行submit到最后就会把队列中的节点unpark()
Future<?> submit = executor.submit(() -> {
System.out.println("this woker start do work");
Thread.sleep(3000);
return 1;
});
try {
// 如果执行到这里上面的异步线程还没有执行完,则会阻塞,也叫异步阻塞
// 如果超过了下面的2s,则会抛出异常
// submit的结果也会进行排队,如果有多个线程去阻塞的话
// 这里的get,会去判断如果线程没有执行完成,则会park()
System.out.println(submit.get(2,TimeUnit.SECONDS));
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
System.out.println("has got the result");
}
2、ForkJoin
2.1、什么是ForkJoin?
概念:Fork/Join 框架是 Java7 提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。 主要针对的就是CPU密集型作业。
Fork 就是把一个大任务切分为若干子任务并行的执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计 算1+2+…+10000,可以分割成 10 个子任务,每个子任务分别对 1000 个数进行求和,最终汇总这 10 个子任务的结果。如下图所示:
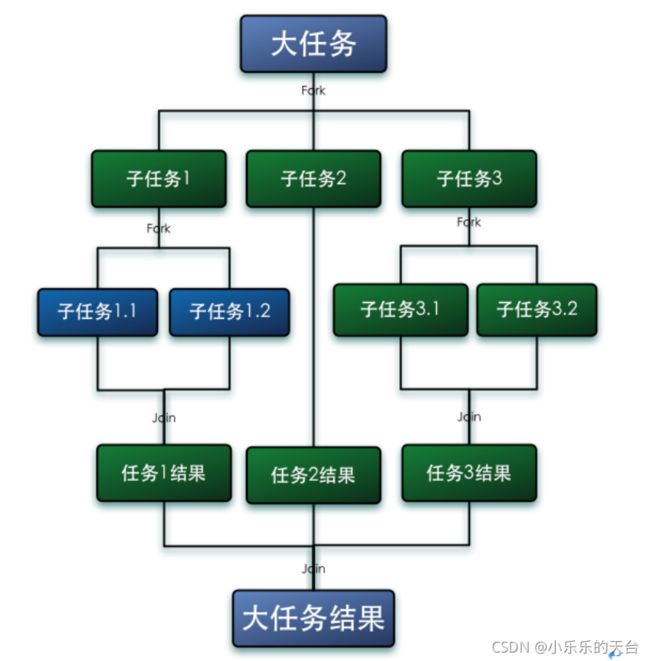
2.2、ForkJoin工作模型
ForkJoin一般情况下会以计算机的核数来创建工作线程,每一个工作线程都有一个自己的队列(Deque双端队列),先把任务拆分给每个队列,如果未达到标准,会在每个队列中再次拆分任务,然后放到队列中,直至拆分到指定的小分子,再进行计算。大致如下图所示:

2.3、ForkJoin特性
1、ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。
2、 ForkJoinPool 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数,例如 quick sort 等。
3、 ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配 合使用 ManagedBlocker。
2.4、ForkJoin工作窃取
概况:ForkJoin工作窃取是指在多个工作线程同时工作的情况下,有的线程执行的比较快,提前执行完成了,它就可以去把帮助其它线程执行任务,这里说的是偷取到其它现线程的任务。如下图所示:
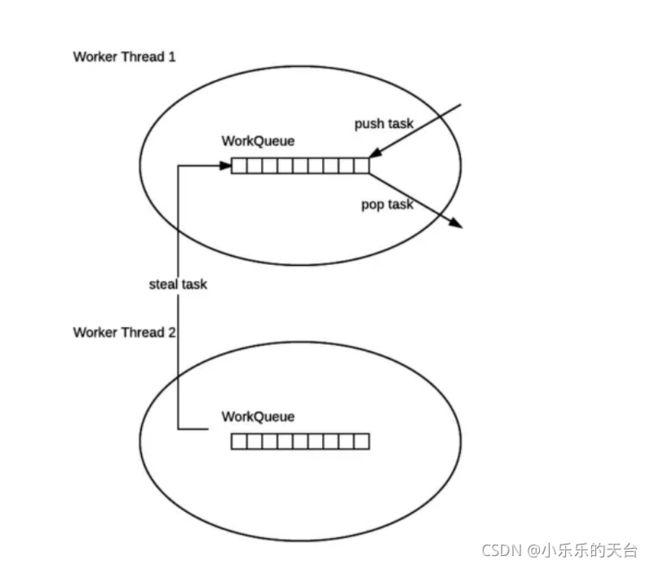
特点:
1、 ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务 (ForkJoinTask)。
2、每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
3、每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线 程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
4、 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
5、在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
2.5、ForkJoin应用场景
但都得有一个前提就是数据量特别大的场景下。
1、数据清洗。
2、排序。
3、查找。
2.6、ForkJoin工作图
只有基数队列有线程,偶数队列是对外围线程提交进来任务的缓存。
自己执行任务从队尾去取,也就是上面。
执行其它线程的任务是从对头去取,也就是下面。
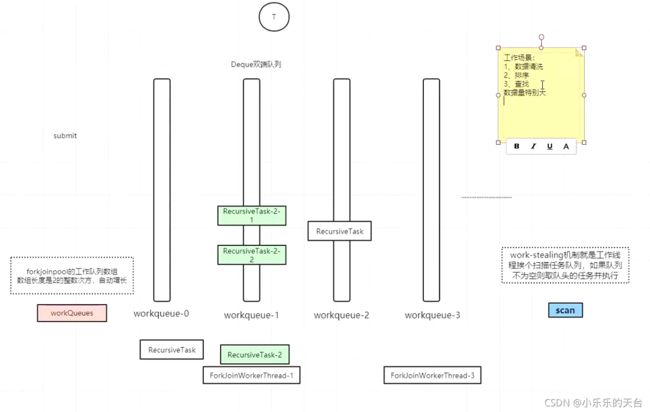
2.7、ForkJoin工作提交整体流程图

3、ForkJoin的使用
ForkJoin的使用最常用的有三种方式,下来分别介绍一下:
3.1、RecursiveAction
没有返回值
继承 RecursiveAction 并重写 compute() 方法即可。
代码示例如下:
public class PrintNumMain {
public static void main(String[] args) throws InterruptedException {
// 创建一个 ForkJoinPool 线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 提交一个可分解的Task任务,这里是0-1000的段
forkJoinPool.submit(new PrintNumAction(0, 1000));
//这里的意思是异步阻塞直到上面所有的任务都执行结束
// 然后再睡眠两秒
forkJoinPool.awaitTermination(2, TimeUnit.SECONDS);
// 关闭线程池
forkJoinPool.shutdown();
}
}
public class PrintNumAction extends RecursiveAction {
/**
* 每个最小的Task,最大范围为20
*/
private static final int MAX = 20;
private int start;
private int end;
public PrintNumAction(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected void compute() {
// 当分下来的最小任务小于 MAX 时,则执行真正逻辑
if((end-start) < MAX) {
for(int i= start; i<end;i++) {
System.out.println("工作线程:" + Thread.currentThread().getName() + ",打印次数:" + i);
}
}else {
// 将大的Task一分为二
int middle = (start + end) / 2;
// 将左边的一部分递归继续分解
PrintNumAction left = new PrintNumAction(start, middle);
// 将右边的一部分递归继续分解
PrintNumAction right = new PrintNumAction(middle + 1, end);
// 将左边的部分fork进队列
left.fork();
// 将右边的部分fork进队列
right.fork();
}
}
}
执行之后的结果如下图所示:
然而发现每一次打印的结果都不一致,说明不是一个线程在执行

3.2、RecursiveTask
有返回值
继承 RecursiveTask 并重写 compute() 方法即可。
代码示例如下:
public class SumNumMain {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 创建一个 ForkJoinPool 线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 提交一个可分解的Task任务,这里是0-1000的段
ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(new SumNumAction(0, 40));
//这里的意思是异步阻塞直到上面所有的任务都执行结束
// 然后再睡眠两秒
forkJoinPool.awaitTermination(2, TimeUnit.SECONDS);
System.out.println("RecursiveTask 结果是:" + forkJoinTask.get());
// 关闭线程池
forkJoinPool.shutdown();
}
}
public class SumNumAction extends RecursiveTask<Integer> {
/**
* 每个最小的Task,最大范围为20
*/
private static final int MAX = 20;
private int start;
private int end;
public SumNumAction(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
// 当分下来的最小任务小于 MAX 时,则执行真正逻辑
if((end-start) < MAX) {
Integer sum = 0;
for(int index = start; index <= end; index++) {
sum += index;
}
return sum;
}else {
// 将大的Task一分为二
int middle = (start + end) / 2;
// 将左边的一部分递归继续分解
SumNumAction left = new SumNumAction(start, middle);
// 将右边的一部分递归继续分解
SumNumAction right = new SumNumAction(middle + 1, end);
// 将左边的部分fork进队列
left.fork();
// 将右边的部分fork进队列
right.fork();
// 等待子任务执行完,并得到其结果
int leftSum = left.join();
int rightSum = right.join();
// 合并子任务
return leftSum + rightSum;
}
}
}
执行结果如下:
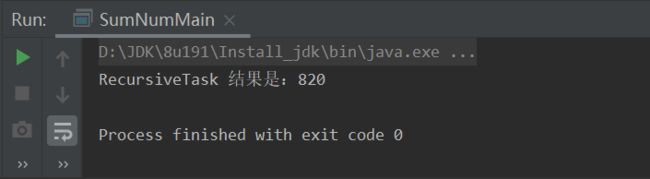
3.3、CountedCompleter
包含一个钩子方法
继承 CountedCompleter 并重写 compute() 和 onCompletion() 方法即可。
代码示例如下:
public class PrintMain {
public static void main(String[] args) throws InterruptedException {
// 创建一个 ForkJoinPool 线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 提交一个可分解的Task任务,这里是0-1000的段
forkJoinPool.submit(new PrintAction(0,40));
//这里的意思是异步阻塞直到上面所有的任务都执行结束
// 然后再睡眠两秒
forkJoinPool.awaitTermination(2, TimeUnit.SECONDS);
// 关闭线程池
forkJoinPool.shutdown();
}
}
public class PrintAction extends CountedCompleter<Void> {
/**
* 每个最小的Task,最大范围为20
*/
private static final int MAX = 20;
private int start;
private int end;
public PrintAction(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public void compute() {
// 当分下来的最小任务小于 MAX 时,则执行真正逻辑
if((end-start) < MAX) {
for(int i= start; i < end;i++) {
System.out.println("工作线程:" + Thread.currentThread().getName() + ",打印次数:" + i);
}
}else {
// 将大的Task一分为二
int middle = (start + end) / 2;
// 将左边的一部分递归继续分解
PrintNumAction left = new PrintNumAction(start, middle);
// 将右边的一部分递归继续分解
PrintNumAction right = new PrintNumAction(middle + 1, end);
// 将左边的部分fork进队列
left.fork();
// 将右边的部分fork进队列
right.fork();
}
// 回调钩子函数 onCompletion
tryComplete();
}
@Override
public void onCompletion(CountedCompleter<?> caller) {
System.out.println("1111111111111111111");
}
}
执行结果如下图:

10、辅助知识
10.1、任务性质类型分类
任务类型分类一般分为 CPU密集型(CPU-bound)和 IO密集型(I/O bound),根据两种不同的场景下,为我们对并发线程池的参数设置也是不同的。往往任务一般就分为这两种。
10.1.1、CPU密集型(CPU-bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
线程数一般设置为: 线程数 = CPU核数+1 (现代CPU支持超线程)
10.1.2、IO密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
线程数一般设置为: 线程数 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
10.2、分治思维
分治思维就是把大任务拆分成小任务,可以充分的利用我们的CPU多核多线程,一个CPU执行完自己的任务后可以给其他人帮忙,也叫任务窃取。