Python机器学习:决策树2
昨天主要就是对决策树和信息增益进行了了解,今天继续来看:
信息增益比:是信息增益与数据集再属性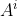 上的分布的熵
上的分布的熵![]() 的比值:
的比值:
![]()

如果一个属性的可能值数目多,那么使用信息增益进行特征选择的时候会获得跟大的收益,用信息增益比进行特诊选择会在一定程度上缓解这个问题,C4.5算法就是用信息增益比进行特征选择,确定好选择方法之后,决策树的生成算法(ID3为例)如下:
Struct Node{//定义树的结点,包含了样本集合,当前节点的标记、从属性值到样本集合的映射
samples;
label;
next;
}
Node node={
//生成一个新的节点,D中的所有样本放入节点中,并且置其标签为-1(不属于如何类别)
samples=D;
label=-1;
next=Null;
}
//判断是否需要建树,不需要就直接返回,需要的话就继续递归建树,
if(D=NUll){
return node;
}
else if(y1=y2=...=ym){
node.label=y1;
return node;
}
else if(A=NUll){
node.label=arg max(sum(I{yi=ck}));
return node;
}
//计算按照每个属性进行划分的信息增益,一增益最大的属性生成子树。
for each j in {1,2,....,ki}:
D[j]={(xi,yi)|x[i*]=a[*j],i=1,2,3,...,m};
node.next(a[*j]=DecisionTree(D[j],A-A*);
end for
return node;好的,大致了解了之后,我们来看看决策树生成算法CART:
CART是一种常见的决策树算法,其核心是使用基尼指数作为特征选择指标。
基尼指数:给定数据集D,其中共有K个类别,用频率代替概率,数据集的概率分布:
![]()
对于数据分布p或者二数据集D,其基尼指数定义为:

样本均匀分布的时候,Gini指数最大,Gini(D)的值反映了样本集合的纯度,均匀分布的时候,纯度最低,Gini(D)最大,所有样本均只属于一个类别的时候,此时的纯度数最高,Gini(D)=0。
样本集合的基尼指数值越低,集合的纯度越高。
样本集合D关于属性的基尼指数定义为:

CART算法用于分类决策树生成的时候,特征选择阶段使用的就是基尼指数,对所有可用属性进行遍历,选择能够使样本集合划分后基尼指数最小的属性进行子树生成。
注意;CART算法生成的是一个二叉树。
决策树剪枝:
训练集上生成的决策树往往任意产生过拟合问题,为了解决这个问题,可以对决策树进行剪枝处理,来降低模型的负责度,提高模型的泛化能力,剪枝的方法有预剪枝、后剪枝,其中,预剪枝是在构建决策树的过程中进行,后剪枝则是在决策树构建完成之后进行。
预剪枝:
一般通过验证进行辅助,每次选择信息增益最大的属性进行划分的时候,首先要在验证集上对模型进行测试,如果划分之后能够提高验证集的准确率,就进行划分,否则当前节点作为叶子节点,并以当前节点包含的样本中出现最多的样本作为当前节点的预测值。
预剪枝容易造成决策树过拟合。
后剪枝:
我们将一棵树的代价函数定义为经验损失和结构损失两部分,经验损失是对模型性能的度量,结构损失是对模型复杂的的度量,决策树的性能应尽可能的搞,复杂度应尽可能的低,经验损失可以用每个叶节点上的样本分布的熵值之和来描述,结构损失可以用叶结点的个数来表述。在从低向上的剪枝过程汇总,对所有子节点均是叶子结点的子树,如果将某个子树进行剪枝后能够是的代价函数最小,就把这个子树给剪掉,重复这个剪枝过程,知道代价函数不再变小为止。
我们看一下书上给出的,基于决策树实现的葡萄酒分类:
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
if __name__=='__main__':
wine=load_wine()
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target)
clf=DecisionTreeClassifier(criterion="entropy")
clf.fit(x_train,y_train)
train_score=clf.score(x_train,y_train)
test_score=clf.score(x_test,y_test)
print("train_score:",train_score)
print("test_score:",test_score) 图1:决策树实现红葡萄酒分类
图1:决策树实现红葡萄酒分类
可以从结果看到,训练集上的准确率是1,测试集上的准确率是0.93(书上是0.98,这是因为:train_test_split函数在划分数据集时,有一定的随机性,所以会出现不一样的准确率)。
决策树的每个非叶节点包含了五个数据:决策条件、熵、样本数、每个类别中样本的个数、类别名称,因为每个叶节点再无需进行决策,所以只有四个数据。
好了,到这里决策树的内容大概就是这些了,但是,还是要抽时间多看看自己的博客,多复习复习,不然,每天的抄书活动就显得没啥意义了。