轻量,快速,稳定,可编排的组件式流程引擎 LiteFlow(你值得拥有)
前言
在2001年的第一场雪下来的时候,产品告诉你,咱们要卖个羽绒服,这羽绒服春天200,夏天100,秋天210,冬天500,做为一名优秀的程序猿,简单
if else 大法

搞定
过了2002年,产品又告诉你,今年咱们玩法又换了,不仅仅是分春夏秋冬了,还分了个春分,冬至,在大框架下各个时节我们的价格也不一样,难度+1
这下不好整了,咱们常规操作下的if else 大法失效
现在我们使用策略模式,以防止未来可能增加的各种变化,这下你难不到我了吧

最后,时间一转,已经到了2021年,各种产品,各种程序员已经在上面不知道提了多少需求和代码,整个逻辑耦合复杂,整不动了,
这时候,新的需求来到了你手里
产品说: 我们现在的产品 不仅仅分时节,还分优惠活动,参不参加,参加力度怎么样,参加的优惠减免,针对不同端(网页)活动流程还不一样,这下,抓瞎了
这个时候,LiteFlow 就出来了
LiteFlow(基础篇)
轻量,快速,稳定,可编排的组件式流程引擎
LiteFlow框架的作用
LiteFlow就是为解耦复杂逻辑而生,如果你要对复杂业务逻辑进行新写或者重构,用LiteFlow最合适不过。它是一个轻量,快速的组件式流程引擎框架,组件编排,帮助解耦业务代码,让每一个业务片段都是一个组件,并支持热加载规则配置,实现即时修改。
使用LiteFlow,你需要去把复杂的业务逻辑按代码片段拆分成一个个小组件,并定义一个规则流程配置。这样,所有的组件,就能按照你的规则配置去进行复杂的流转。
LiteFlow的设计原则
LiteFlow是基于工作台模式进行设计的,何谓工作台模式?
n个工人按照一定顺序围着一张工作台,按顺序各自生产零件,生产的零件最终能组装成一个机器,每个工人只需要完成自己手中零件的生产,而无需知道其他工人生产的内容。每一个工人生产所需要的资源都从工作台上拿取,如果工作台上有生产所必须的资源,则就进行生产,若是没有,就等到有这个资源。每个工人所做好的零件,也都放在工作台上。
这个模式有几个好处:
每个工人无需和其他工人进行沟通。工人只需要关心自己的工作内容和工作台上的资源。这样就做到了每个工人之间的解耦和无差异性。
即便是工人之间调换位置,工人的工作内容和关心的资源没有任何变化。这样就保证了每个工人的稳定性。
如果是指派某个工人去其他的工作台,工人的工作内容和需要的资源依旧没有任何变化,这样就做到了工人的可复用性。
因为每个工人不需要和其他工人沟通,所以可以在生产任务进行时进行实时工位更改:替换,插入,撤掉一些工人,这样生产任务也能实时的被更改。这样就保证了整个生产任务的灵活性。
这个模式映射到LiteFlow框架里,工人就是组件,工人坐的顺序就是流程配置,工作台就是上下文,资源就是参数,最终组装的这个机器就是这个业务。正因为有这些特性,所以LiteFlow能做到统一解耦的组件和灵活的装配。
LiteFlow适用于哪些场景
LiteFlow适用于拥有复杂逻辑的业务,比如说价格引擎,下单流程等,这些业务往往都拥有很多步骤,这些步骤完全可以按照业务粒度拆分成一个个独立的组件,进行装配复用变更。使用LiteFlow,你会得到一个灵活度高,扩展性很强的系统。因为组件之间相互独立,也也可以避免改一处而动全身的这样的风险。
而针对基于角色流转,比如工单系统,OA 审批等,就很不合时,推荐老牌的 flowable(https://flowable.com/open-source/),activiti(Open Source Business Automation | Activiti)
LiteFlow支持如何使用
SpringBoot 集成
Spring 集成
无Spring 场景
组件手动注册
ZooKeeper注册
规则文件格式
xml 为例

更多基础使用的技巧包括接入方式,请查看liteFlow 官方文档 规则文件格式 | LiteFlow
LiteFlow (技术篇)
以上是对liteFlow 做了一个简单的概况解读,现在,我们来深入的看一下,他的底层,到底是怎么运转的?(这大概是大家比较感兴趣的)
LiteFlow的架构

我们来简单的看一下整体的架构
分为 几个核心的部分
FlowBus: 流程(chain)和节点(node)的元信息
Parse: 解析器(配置文件和chain,node的桥梁)
flow.xml:配置文件(流程和节点信息都在这里)
DataBus(Slot管理器):管理Slot,用以分配和回收
FlowExecutor:流程执行器
Slot:数据槽(单次请求隔离,底层是couurentHashMap)
Chain:流程(包含condition:then,when两种,nodeList:节点集合,底层执行时候也是node)
Node(Component):节点 可执行节点
核心流程
1 在启动的时候,预先通过解析器 解析 flow.xml
2 FlowBus,DateBus 根据配置文件完成数据的初始化和元信息的储藏
3 流程执行器执行,根据原信息,依次调用对应的可执行逻辑完成任务
再细节一点点
下图以xml配置文件,SpringBoot 依赖为例,绿色为启动阶段,白色为执行阶段操作的大体流程(细节太多,画不出来,推荐阅读源码)
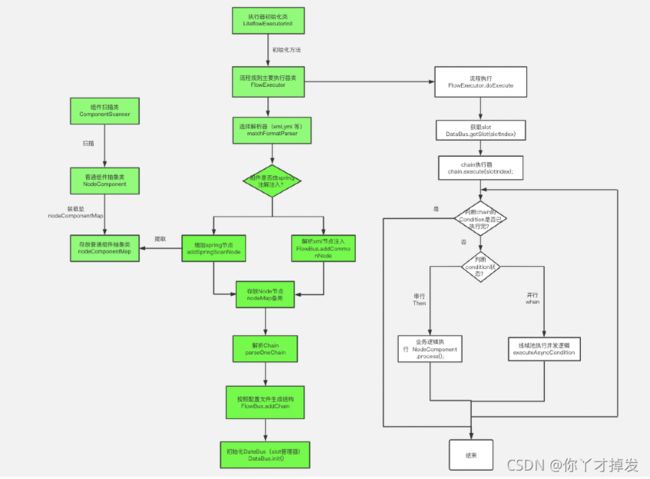
简单解读(建议配合源码看图)
1 spring boot 启动阶段(绿色方框)
核心: 初始化阶段加载对应的node 和chain 节点,并通过解析器存储关键信息
2 程序运行时(白色方框)
核心:按照解析器配置的规则进行逐一的执行,核心是按照chain 的内部结构一层一层执行
细节解读
下面我会以类为维度,进行源码的部分解读
DataBus

这里对为什么使用ConcurrentHashMap进行了解释,
那么我的理解就是每一个slot 都储存在ConcurrentHashMap中,换个说法也就是每一个请求对应的slot 都是存放在这里的,也就是完成了数据请求的隔离
![]()
上面的QUEUE 这里的 ConcurrentLinkedQueue 指代的其实是slot 使用的个数,Integer 是索引,用这个来统计使用的slot 数量
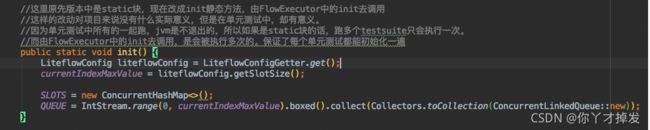
这里其实是一个很巧妙的点,也就是说有时候初始化的静态处理在static 里并不一定好,完成的目的一样
但如果做上述的处理是可以作为init,在完成test里是比较好的一种方式(单测的时候其实是只跑一个,但有时候为了流程严谨,上线前是需要走一遍所有单测的,就会很有用)

这里的代码显示了扩容逻辑,确实隐藏的逻辑就是我们在扩容的时候会不会扩的太大了?对应的其实并没有缩小的逻辑
但单机的QPS,4核8G的处理器 我以前做过测试,简单的查询逻辑,可支撑的QPS 也就在1500左右,所以,最大其实也就是扩容一到2次.这倒是我们设计的时候务必要考虑的点。
ComponentScanner

spring 自动加载类 实现了 BeanPostProcessor
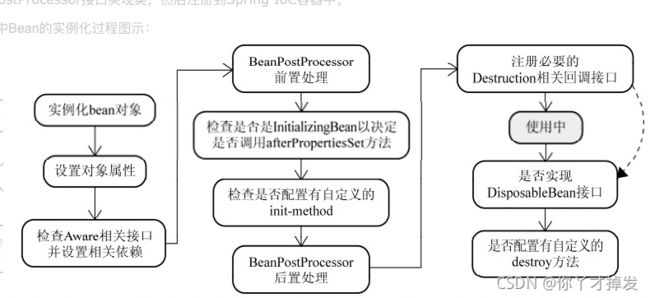
如果我们想在Spring容器中完成bean实例化、配置以及其他初始化方法前后要添加一些自己逻辑处理。我们需要定义一个或多个BeanPostProcessor接口实现类,然后注册到Spring IoC容器中。
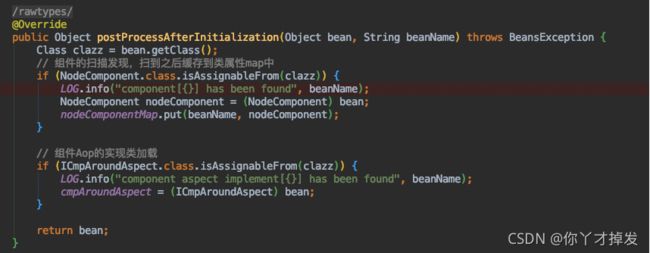
那么继承在此之后,liteFlow 在初始化的时候进行一些操作
NodeComponent.class.isAssignableFrom(clazz)
判断spring 扫描的子类是不是 NodeComponet 的子类,而NodeComponet 是所有node 节点类的父类
也就是扫描到是node 类 加载进入到 nodeComponentMap(HashMap)中 为解析任务做准备、

以上是
![]()
的解析任务,中间会判断 nodeComponentMap 中的数据是否 存在于FlowBus 中的 nodeMap

如果存在 返回 不存在的话 会调用 addSpringScanNode 方法 把当前的node 刷到 nodeMap 里
也就是完成了从spring 本身加载的类NodeComponent ------->liteflow 本身的FlowBus 中 Node (实现的执行器) 的核心处理逻辑。
而这是2个时间节点,一个是ComponentScanner 是在spring 加载的时候完成的
第二个则是在FlowExecutor 中的init中完成的
FlowBus

这有2个核心的参数,一个是 chainMap 一个是nodeMap,
一个是存储正常的执行节点
一个是存储执行中的链条信息

核心方法拿这个举例,调用 addSpringScanNode 方法 将ComponentScanner 中的nodeCompent 存储在nodeMap 中
而调用的方法是在xml 解析器里使用(FlowExectuor.init ---->对应解析器解析 xml-------->添加Node 节点 到nodeMap 里 或者chain 到chainMap 里);
(个人理解也就是在初始化的时候把大家需要的东西都安排好)
FlowExecutor
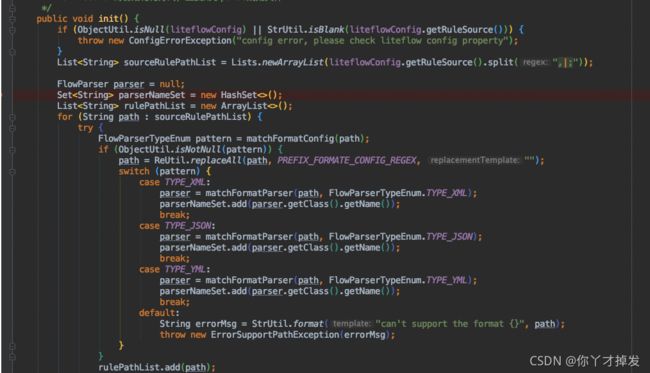
在初始化的时候回进行init() 他的正常启动是在
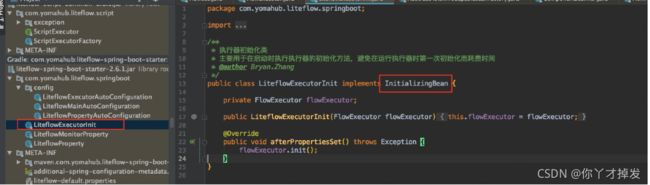
实现 InitializingBean 接口完成的 在spring 初始化的时候进行初始化
1 判断配置文件的类型生成对应的解析器
2 初始化DataBus

真正实行的方方法是doExecute方法
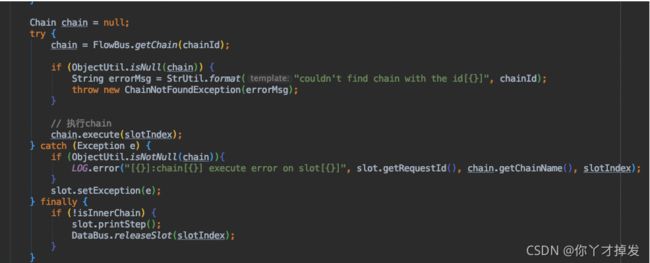
除去一些前序校验类的方法
核心带入如上 调用chain 的执行方法,入参是slotIndex 也就是slot 的索引,指代真正的数据 以方便后续调用
Chain

chain的核心方法 execute
这里其实是每个chain 里存在着conditionList ,conditionList 中的每个 condition 里的 nodeList 存放着再这里的链条
然后循环遍历每个condition 在执行每个condition 中nodeList 每个node 的方法
真正主程序

如上图所示
conditionList 中存放着很多的 condition 这里的condition 就是 6个then 和 一个when
再接着就是执行每一个 then 或者 when 里的逻辑代码
例如第一行 就是执行 checkCmp slotInitCmp priceStepInitCmp 中的代码逻辑

在Condition 为when 的逻辑里这里就是使用了一个 CountDownLatch 进行了并行的线程池操作
默认的超时时间是15秒
根据设置的 errorResume 字段,判断在并行的时候报错是否阻断流程
Node

node 节点是一个核心的可执行器,那么真实的业务逻辑也就是在这里触发的
代码中的instance 是我们 NodeComponent 也就是我们写代码中定义节点时候需要写的 继承的 类

除此之外,上图中标注的红色内容是框架自带的类,分别是 node 的选择节点(也就是常规我们if else 判断的店) 以及脚本类型的节点 和脚本选择节点
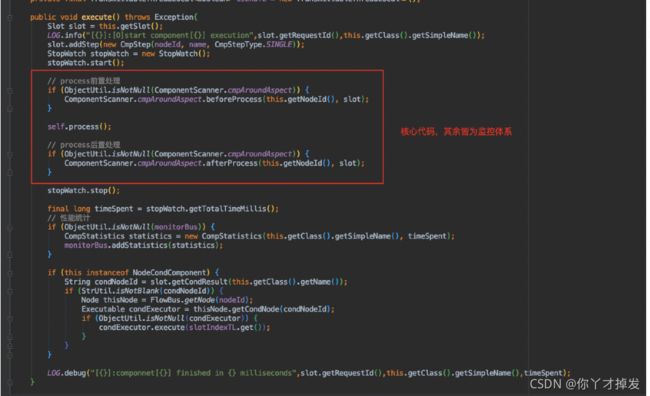
那么 这里实际调用的是
self,process

这里作者对为什么使用self 和 不用this 进行了解释

这里这块代码单独的拉出来说一下
当我们的节点是一个选择节点 也就是继承NodeCondComponent
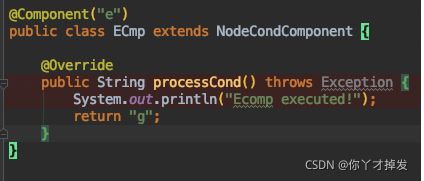
他会执行实例节点的processCond 方法
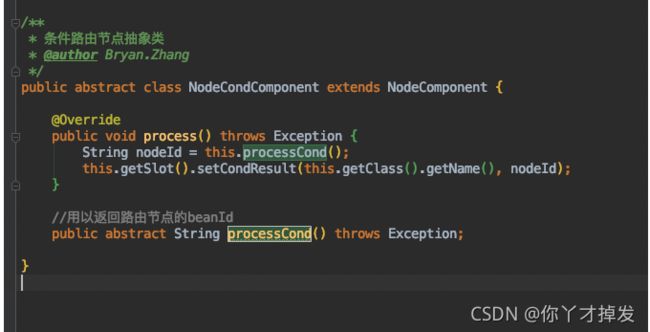
转到抽象类的方法,执行process 方法,其实也就是把选择出来的节点名称直接被放到slot 的CondResult 中
那么就回到上图了
![]()
这行代码 拿去对应的condNodeId ,再次进行execute 方法执行
真实选择结束之后的实例

举例,也就是运行到e 的时候,执行e 的processCond 方法,返回g ,然后在去执行g 中的正确方法。
解析流程
这里还有一个重点是在解析流程,也就是在初始化的时候,会进行xml 或者其他文件的解析,那么到了这了,就需要简单来看一下解析整个文件的流程

1 选择合适的解析器出现,按照配置的文件类型选择合适的解析器

2 调用真正的parseMain 方法
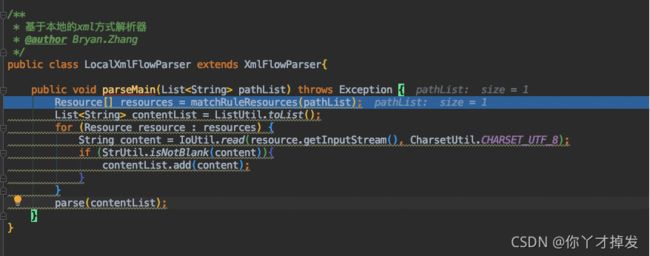
3 调用某一个子类的解析任务 放入所有文件内容

4 使用 org.dom4j
![]()
将内容转换成一个Document 对象传入
5 按照初始化中的每一个实例 由 NodeComponent --> Node

然后 如果在配置文件里配置了node ,一下是解析代码


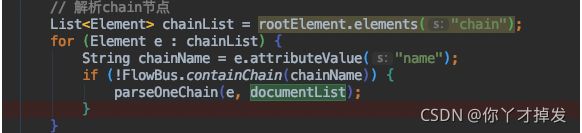
然后这里就是常规case 下解析单链的逻辑
都在parseOneChain 中
这里也就是把parseOneChain 的作用是把页面上解析的东西按照逻辑进行排好,让后续使用

最终调用addChain 方法进入chainMap
chainMap 中chain的结构如下
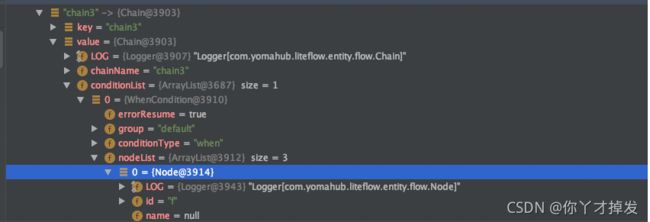
chain 包含condition ,condition 包含nodeList 里面则是各个node
最终把所有数据在chainMap
和nodeMap 中完成准备工作