使用安装AidLux的安卓手机,部署落地智慧社区AI应用
《使用安装AidLux的安卓手机,部署落地智慧社区AI应用》
-
- 1. 引言
- 2. 智慧社区场景1:高空抛物检测
-
- 2.1 高空抛物场景的背景
- 2.2 算法设计
- 2.3 算法实现
-
- 2.3.1 去抖动
- 2.3.2 背景建模
- 2.3.3 形态学处理
- 2.3.4 目标检测
- 2.3.5 目标追踪
- 2.4 安卓端部署
-
- 2.4.1 下载安装AidLux软件
- 2.4.2 上传代码到AidLux
- 3. 智慧社区场景2:车牌识别
-
- 3.1 车牌数据集的下载和整理
-
- 3.1.1 车牌检测数据集制作
- 3.1.1 车牌识别数据集制作
- 3.2 训练测试环境搭建;
- 3.3 车牌识别模型的移动端部署
-
- 3.3.1 车牌检测+识别模型的onnx序列化
- 3.1.2 车牌检测+识别模型的tflite的轻量化
- 3.3.3 车牌检测+识别的andorid端部署
- 4. 课堂大作业
- 5 学习心得
1. 引言
该项目来源于Aidlux智慧社区AI实战训练营,由张大刀老师主讲,从智慧社区的定义、算法场景、开发流程、项目指标等多个角度,带大家了解算法工程师在AI开发过程中需要考虑的方方面面。除了分享经验之外,主要讲解利用边缘设备AidLux完成智慧社区里面的两个典型场景:高空抛物和车牌识别的算法开发,以及在边缘设备上的部署。
欢迎大家加入训练营,课程链接:https://mp.weixin.qq.com/s/ASnaFA7D4jfHWoO_IqQ6aQ
2. 智慧社区场景1:高空抛物检测
2.1 高空抛物场景的背景
高空抛物是智慧社区的重要部分之一,主要为主动识别高空中抛下的物体,一般场景为以监看和事后取证为主。
2.2 算法设计
高空抛物的场景主要是识别出抛出来的物体,有以下几种识别方式:
- 使用传统的动态目标检测,如光流检测和帧差法;
- 使用目标检测+目标追踪算法,对抛出的物体先做目标检测,并对检测到的物体做追踪;
- 使用物体追踪+过滤算法;
- 使用视频分类的算法。
本次训练营课程中,因为涉及到高空抛物数据集的缺乏,所以在上面的四种方法中,主要选择第一种方法。大家在做项目有数据集支撑的情况下,建议选择第三种或者第四种方法。第二种方法目标检测+追踪的方式,对上游任务目标检测的要求较高,实际情况下的小目标容易漏检和误检,不建议使用。
第一种方法的实现流程如下图所示:

2.3 算法实现
首先分享一下智慧社区AI实战训练营物料包
百度云盘链接:https://pan.baidu.com/s/147gi2MLqC6KiBGHyzSsbkw
提取码:aid3
算法的整体流程是先在PC端完成算法的实现后,再移植到安卓端。所以大家可以看到我们的百度网盘里面的代码有两个文件夹,highthrow_b文件夹为在PC端运行的代码,aidlux_highBuildingThrow为在android端运行的代码。
2.3.1 去抖动
背景建模的前提是保证摄像机拍摄位置不变,保证背景是基本不发生变化的。
所以这里我们防止相机镜头发生抖动,可以加上去抖动的算法,通过匹配算法实现,在第二节课代码的highthrow_b/adjuster.py下:
去抖动后的效果如下:

其主要的原理是通过每张图的特征,找到两个图片的关键点,并基于关键点获得变换矩阵后,将原图通过变换矩阵变换后,与第一张原始图片对齐。
2.3.2 背景建模
背景建模主要是为了检测运动物体,输出前景图片。在获得图片的差分图后,将差分图放入背景建模中,获取前景运动图。
背景建模在opencv中主要包含knn建模和高斯建模(MOG2)两种方法,这里我们选择的是KNN的方法,在knnDetector.py文件下: 其中history表示影响背景模型的历史帧数,dist2Threshold 表示像素和样本之间平方距离的阈值,当大于阈值的话,则为前景。
获得结果如下:

大家会发现通过knn的方法对后面的背景中的光线变化敏感,但是也不太容易丢失掉小物体,这里高空抛物的目标一般为小目标,所以选择这个算法。这里大家可以试试高斯混合建模、MOG2等其他方法。
2.3.3 形态学处理
从上图中可以看到,前景的mask 中存在很多的干扰,如灯光的干扰等,再通过形态学处理将干扰项移除。首先通过开运算将前景中的毛刺过滤掉,在knnDetector.py代码中。之后再通过膨胀操作,将目标项变大,方便后面的目标追踪:
获得效果如下:

2.3.4 目标检测
在形态学处理过滤掉干扰过后,找到目标的外接轮廓,同时过滤掉小的斑点干扰后,提取目标的外接矩形,至此,基于传统视觉的目标检测完成。
在knnDetector.py文件下
stop = time.time()
print("open contours cast {} ms".format(stop - start))
start = time.time()
contours, hierarchy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 基于mask提取轮廓
stop = time.time()
print("find contours cast {} ms".format(stop - start))
i = 0
bboxs = []
start = time.time()
for c in contours:
i += 1
if cv2.contourArea(c) < self.minArea: # 过滤
continue
bboxs.append(cv2.boundingRect(c)) # 基于轮廓 寻找外接矩形
stop = time.time()
print("select cast {} ms".format(stop - start))
return mask, bboxs
2.3.5 目标追踪
因为动态目标检测出来的是一个个的目标块,这个时候根本不知道上一帧与下一帧的目标对应关系,也就谈不上移动距离。因此需要跟踪算法,将目标一一对应起来。本次训练营中选择SORT算法进行目标追踪。
2.4 安卓端部署
本次课程中把高空抛物部署在android端需要借助AidLux平台
AidLux主打的是基于ARM架构的跨生态(Android/鸿蒙+Linux)一站式AIOT应用开发平台。AidLux将其中的整个开发流程,全部打通,通过Aidlux平台,可以将PC端编写的代码,快速应用到Android系统上。
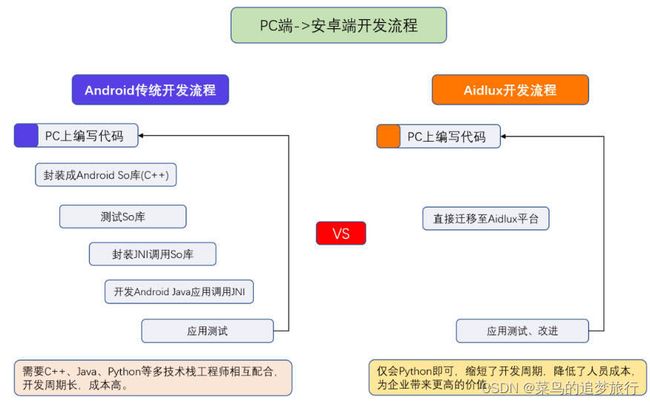
2.4.1 下载安装AidLux软件
AidLux软件使用非常方便,可以安装在手机、PAD、ARM开发板等边缘端设备上。而且使用Aidlux开发的过程中,既支持在边缘设备的本机开发,也支持通过Web浏览器访问边缘端桌面进行开发。
而在本文中,采用手机边缘端和Web端两种方法结合的方式,进行开发。
(1)下载AidLux软件
首先在安卓手机上下载一个AidLux软件,在手机的应用商城中搜索“aidlux”,即可安装下载。
(2)将手机的wifi网络和电脑的网络连接到一起,打开安装好的手机上的AidLux软件,点击第一排第二个Cloud_ip。可以看到,手机界面上会跳出可以在电脑上登录的IP网址。
在电脑的浏览器上,随便输入一个IP,即可将手机的系统投影到电脑上,任何操作和代码编写都是完全数据共通的,这样我们就可以将PC端的操作,直接应用到Aidlux的App中了。

(3)输入IP后,在电脑端的浏览器中,可以跳出Aidlux的登录页面,默认登录密码是“aidlux”。
需要注意的是,使用aidlux的PC端的时候,手机的aidlux软件也要相应的打开,保持联通状态。

2.4.2 上传代码到AidLux
我们首先打开手机版的aidlux,并投影到电脑网页上。然后第一步先将物料包中lesson2的aidlux_highBuildingThrow的所有代码上传到aidlux的平台里面。
点击电脑端页面菜单栏的第一个,文件浏览器,打开文件管理页面。

然后找到home文件夹,并双击进入此文件夹。
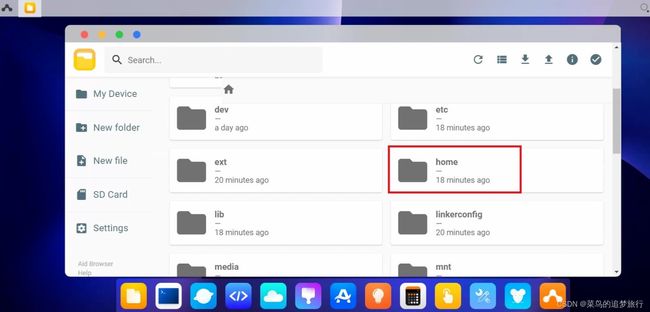
点击右上角往上的箭头“upload”,再选择Folder,将前面Yolov5的文件夹上传到home文件夹内。
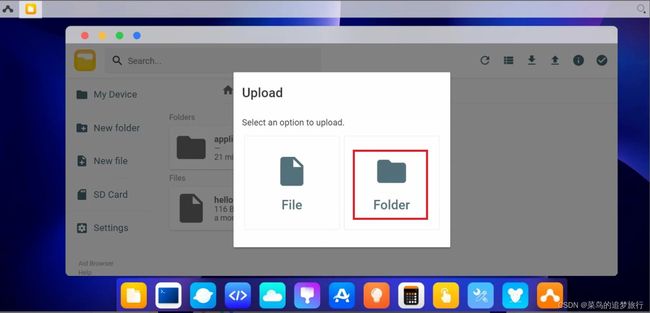
选择物料包中的aidlux_highBuildingThrow文件夹,然后点击选择上传。
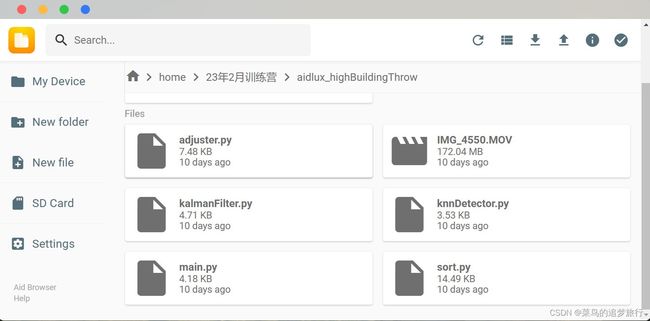
其中main.py是主函数文件,在电脑端AidLux的终端运行python main.py
可以看到高空抛物算法的Demo效果


AidLux的使用说明和详细操作实例,大家可以看一下大白老师之前的课程文档:
https://docs.qq.com/doc/DWEdSV2ZwdHVEQWJv
3. 智慧社区场景2:车牌识别
车牌识别的方案主要有两种:
一种是粗粒度的:车牌检测+车牌识别;
另外一种细粒度的:车牌检测+车牌矫正+车牌识别。
后一种方法相对于前一种方法增加车牌矫正的部分,这部分主要考虑在场景中车牌在区域中出现的角度变化,如果是车牌与相机是相对平行的,则不需要矫正。如果角度过大,则需矫正,这里面一般车牌的水平度和垂直度超过15°,建议增加矫正环节。
这里考虑到智慧社区的车与相机位置可以相对平行固定,故采用前一种方法,而其他如加油站场景中,摄像头因为要兼顾多种场景,不一定能做到平行,需要对车牌矫正后识别,效果更好。

3.1 车牌数据集的下载和整理
训练模型,首先要准备数据集,考虑到智慧社区中,在社区内很少出现工程车辆,所以只需要覆盖大部分的蓝牌和绿牌的场景即可。最普遍的开源车牌数据集是中科大的CCPD数据集,官网链接是:https://github.com/detectRecog/CCPD
中科大车牌数据集有CCPD2019和CCPD2020,其中CCPD2019主要为蓝牌,CCPD2020为绿牌。其中蓝牌是燃油车,绿牌是电动车。
这里主要用CCPD2019的蓝牌来作为训练时使用的数据集。
3.1.1 车牌检测数据集制作
对于检测任务,考虑数据集庞大和防止出错,大刀老师将其分成两个步骤。
(1)简单验证:先将几张图片标签转成yolo文件,并通过yolo转成voc xml格式,用labelimg打开校验。
(2)批量转换:确认转换的方式没有问题后,将所有标签直接转换成yolo格式保存。
其中转成yolo格式的代码如下,在物料包中的车牌识别(lesson3、4)/车牌识别训练测试/code_plate_detection_recognization/tools/ParaseData.py
整个代码不需要调整,主要修改代码中的图片和txt的路径:
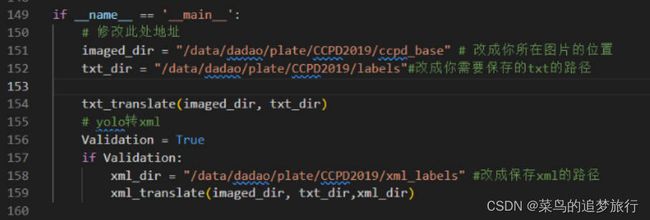
3.1.1 车牌识别数据集制作
对于车牌识别任务,需对车牌号码做解析,在tools/ccpd2lpr.py文件下,将路径换成自己的路径:

运行python ccpd2lpr.py 后:
则表示已经完成数据集的整理。
在image_rec文件夹下生成以车牌号为文件名的图片集。
3.2 训练测试环境搭建;
在对数据集完成预处理后,对于检测模型,我们选用工业界比较常用的yolov5框架,对车牌识别,选用比较成熟的LPRNet架构。
如果有GPU,就可以使用自己的设备训练,没有GPU训练,可以在AutoDL平台上使用云服务器。官网地址为:https://www.autodl.com/home
具体的环境搭建和模型训练这里不再赘述,大家可以跟着训练营中大刀老师的教程走。
3.3 车牌识别模型的移动端部署
将车牌检测和识别的pt模型训练出来后,整个车牌识别任务的pipeline就打通了,但想把模型移植到Android端的话,需要将模型转换成Android端适配的模型。一般android移动端需要轻量化模型,轻量化模型如ncnn,tflite, paddlelite等,这里选择的tflite模型,不过pytorch直接转tflite的工具不齐全,一般都会转成序列化成onnx,再轻量化模型,以pytorch->onnx->tflite 方式。
3.3.1 车牌检测+识别模型的onnx序列化
ONNX模型是基于Protobuf二进制格式,初始由微软和Facebook推出,后面得到了各大厂商和框架的支持。所以本节课,我们首先将车牌检测+识别模型导出成onnx模型。
1. 车牌检测onnx导出
车牌检测使用的是yolov5算法,其代码中自带导出代码,修改export_yolov5.py中的配置代码:

修改里面的权重文件路径,运行export_yolov5.py ,生成onnx格式的权重

2. 车牌识别模型的onnx导出
第二步是导出车牌识别的onnx 模型,导出onnx模型的主要步骤是:搭建算法网络→导入算法模型→确认输入输出维度→通过torch.onnx.export导出。
如下:车牌识别onnx导出的代码,即export_lprnet.py。将以下模型的地址修改成自己对应的地址即可。

3.1.2 车牌检测+识别模型的tflite的轻量化
因为模型需要部署在移动端,所以还需要将模型轻量化,同时考虑后面我们使用的aidlux对tflite的支持,所以选用tflite框架,对模型轻量化。在模型转换之前,需要对onnx转tflite的环境提前安装:
pip install onnx-tf
1. 车辆检测模型的tflite轻量化
Yolov5对tflite的转换比较成熟:修改对应的路径, 运行python export_tflite.py即可。
from onnx_tf.backend import prepare
import onnx
TF_PATH = "weights/LPRNet_Simplified.pb" # where the representation of tensorflow model will be stored
ONNX_PATH = "weights/LPRNet_Simplified.onnx" # path to my existing ONNX model
onnx_model = onnx.load(ONNX_PATH) # load onnx model
tf_rep = prepare(onnx_model) # creating TensorflowRep object
tf_rep.export_graph(TF_PATH)
import tensorflow as tf
TF_PATH = "weights/LPRNet_Simplified.pb"
TFLITE_PATH = "weights/LPRNet_Simplified.tflite"
converter = tf.lite.TFLiteConverter.from_saved_model(TF_PATH)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tf_lite_model = converter.convert()
with open(TFLITE_PATH, 'wb') as f:
f.write(tf_lite_model)
yolov5会将onnx模型先转换成pb模型后,再转换成tflite模型得到模型。
2. 车牌识别模型的tflite轻量化
同理车牌识别模型,修改对应的路径,运行python export_tflite.py,得到tflite模型。
![]()
3. 车牌识别tflite的前向推理
基于onnx的pipeline推理代码,修改tflite的代码,其主要修改的点在于模型的加载,detect_tflite_pipeline.py文件中将onnx模型加载改成tflite模型的加载。
# load detection and classfication onnx model
#2.加载TFLite模型,具体模型文件根据模型的网络结构为主,解码不唯一,这个其中一种方法
det_interpreter = tf.lite.Interpreter(model_path=det_weights)
det_interpreter.allocate_tensors()
#3.获取模型输入、输出的数据的信息
det_input_details = det_interpreter.get_input_details()
det_output_details = det_interpreter.get_output_details()
det_input_shape = det_input_details[0]['shape']
# print("det_output_details",det_output_details)
recog_interpreter = tf.lite.Interpreter(model_path= clas_weights)
recog_interpreter.allocate_tensors()
#3.获取模型输入、输出的数据的信息
recog_input_details = recog_interpreter.get_input_details()
recog_output_details = recog_interpreter.get_output_details()
# print("recog_input_shape",recog_input_shape)
# print("recog_output_details",recog_output_details)
# print("recog_output_details[0]['index']", recog_output_details[0]['index'])
并修改对应的配置参数如下:
修改检测和识别的权重文件路径,以及输入图片路径和保存图片路径、
运行 python detect_tflite_pipeline.py,成功输出结果图片:

3.3.3 车牌检测+识别的andorid端部署
大体上和本文2.4 安卓端部署相似,具体的做法大家可以跟着大刀老师的课程资料。
4. 课堂大作业
以上就是车牌识别项目,从车牌检测到识别的部分在手机移动端做迁移的整体流程,希望对大家在做其他项目时有帮助。课程的最后,大刀老师布置了个大作业,作业要求如下:
1.课程中pipeline都是以图片级别实现的,尝试将其改成视频读取的方式,并拍个路边车牌的视频,或者找个车辆行驶的视频,使用课程的pipeline实现视频的车牌识别功能。
2.课程的pipeline检测结果出现了中文乱码,修复中文显示。
对于作业要求1,修改了code_plate_detection_recognization/aidlux下的det_recog_aidlux_inference.py文件
原先图像读取的代码如下
for img_name in os.listdir(source):
print(img_name)
image_ori = cv2.imread(os.path.join(source, img_name))
然后修改为视频读取的方式,完整代码如下。
# aidlux相关
from cvs import *
import aidlite_gpu
from utils import *
import time
import cv2
import os
anchor = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
source ="/home/code_plate_detection_recognization/demo/images"
det_model_path = "/home/code_plate_detection_recognization/weights/yolov5.tflite"
recog_model_path = "/home/code_plate_detection_recognization/weights/LPRNet_Simplified.tflite"
save_dir = "/home/code_plate_detection_recognization/demo/output"
video_path = "/home/code_plate_detection_recognization/aidlux/car2.mp4"
imgsz =640
# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
# Aidlite模型路径
# 定义输入输出shape
# 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.set_g_index(0)
in_shape0 = [1 * 3* 640 * 640 * 4]
out_shape0 = [1 * 3*40*40 * 6 * 4,1 * 3*20*20 * 6 * 4,1 * 3*80*80 * 6 * 4]
aidlite.ANNModel(det_model_path, in_shape0, out_shape0, 4, 0)
# 识别模型
aidlite.set_g_index(1)
inShape1 =[1 * 3 * 24 *94*4]
outShape1= [1 * 68*18*4]
aidlite.ANNModel(recog_model_path,inShape1,outShape1,4,-1)
# for img_name in os.listdir(source):
# print(img_name)
# image_ori = cv2.imread(os.path.join(source, img_name))
# # frame = cv2.imread("/home/code_plate_detection_recognization_1/demo/images/003748802682-91_84-220&469_341&511-328&514_224&510_224&471_328&475-10_2_5_22_31_31_27-103-12.jpg")
# # img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
cap = cvs.VideoCapture(video_path)
while True:
image_ori = cap.read()
if image_ori is None:
print("视频帧已完成读取!")
break
img, scale, left, top = det_preprocess(image_ori, imgsz=640)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.set_g_index(0)
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
outputs = [0,0,0]
for i in range(len(anchor)):
pred = aidlite.getOutput_Float32(i)
# 数据维度转换
if pred.shape[0] ==28800:
pred = pred.reshape(1, 3,40,40, 6)
outputs[1] = pred
if pred.shape[0] ==7200:
pred = pred.reshape(1, 3,20,20, 6)
outputs[0] = pred
if pred.shape[0]==115200:
pred = pred.reshape(1,3,80,80, 6)
outputs[2] = pred
# 模型推理后处理
boxes, confs, classes = det_poseprocess(outputs, imgsz, scale, left, top,conf_thresh=0.3, iou_thresh =0.5)
pred = np.hstack((boxes, confs,classes)).astype(np.float32, copy=False)
for i, det in enumerate(pred): # detections per image
if len(det):
xyxy,conf, cls= det[:4],det[4],det[5:]
if xyxy.min()<0:
continue
# filter
xyxy = np.reshape(xyxy, (1, 4))
xyxy_ = np.copy(xyxy).tolist()[0]
xyxy_ = [int(i) for i in xyxy_]
if (xyxy_[2] -xyxy_[0])/(xyxy_[3]-xyxy_[1])>6 or (xyxy_[2] -xyxy_[0])<100:
continue
# image_crop = np.array(image_ori[xyxy_[1]:xyxy_[3], xyxy_[0]:xyxy_[2]])
# image_crop = np.asarray(image_crop)
img_crop = np.array(image_ori[xyxy_[1]:xyxy_[3], xyxy_[0]:xyxy_[2]])
image_recog = reg_preprocess(img_crop)
print(image_recog.max(), image_recog.min(),type(image_recog),image_recog.shape)
# recognization inference
aidlite.set_g_index(1)
aidlite.setInput_Float32(image_recog,94,24)
aidlite.invoke()
#取得模型的输出数据
probs = aidlite.getOutput_Float32(0)
print(probs.shape)
probs = np.reshape(probs, (1, 68, 18))
print("------",probs)
# proprocess
probs = reg_postprocess(probs)
# print("pred_str", probs)
for prob in probs:
lb = ""
for i in prob:
lb += CHARS[i]
cls = lb
# result show
label = f'{[str(cls)]} {conf:.2f}'
print(label)
# plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
# plot_one_box_class(xyxy_, image_ori, label=label, predstr=cls, color=None, line_thickness=3)
# image_ori = plot_one_box_class(xyxy_, image_ori, label=label, predstr=cls, line_thickness=3)
image_ori = plot_one_box(xyxy_, image_ori, color = None, label = label, predstr=cls, line_thickness=3)
# Save results (image with detections)
# img_path = os.path.join(save_dir, img_name)
# cv2.imwrite(img_path, image_ori)
cvs.imshow(image_ori)
cap.release()
对于作业要求2,修改了课程物料包中第4节课中的代码,具体修改位置如下。
code_plate_detection_recognization/aidlux/utils.py中的plot_one_box函数
修复中文显示可以用PIL画出识别的车牌号,修改后的代码如下所示。
中文字体下载链接:http://xiazaiziti.com/210356.html
如何在linux系统中安装中文字体,可以参考这篇博客文章:
https://blog.csdn.net/wahahaha116/article/details/127314055
def plot_one_box(x, img, label=None, predstr=None, color=None, line_thickness=3):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [np.random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
if predstr:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(predstr, 0, fontScale=tl / 3, thickness=tf)[0]
# font_size = t_size[1]
font = ImageFont.truetype('/usr/share/fonts/simhei.ttf', 30)
t_size = font.getsize(predstr)
c2 = c1[0] + t_size[0], c1[1] - t_size[1]
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
img_PIL = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_PIL)
img_draw = draw.text((c1[0], c2[1]), predstr, (255, 255, 255), font=font)
return cv2.cvtColor(np.array(img_PIL), cv2.COLOR_RGB2BGR)
手机端AidLux显示的demo效果如下:

视频识别的展示可以看这里:https://www.bilibili.com/video/BV1iY4y117Sp/
5 学习心得
通过基于AidLux平台的智慧社区AI实战训练营学习,笔者对智慧社区AI算法的应用部署有了一定的认知,课程中通过代码实践和在安卓端AidLux软件的部署,实现了高空抛物检测和车牌的识别。本次训练营,笔者受益良多,在此感谢成都阿加犀公司提供的学习平台,感谢张大刀老师的授课。