Kubernetes容器
目录
容器操作
两地三中心
四层服务发现
五种Pod共享资源
六个CNI常用插件
七层负载均衡
八种隔离维度
九个网络模型原则
十类IP地址
容器操作
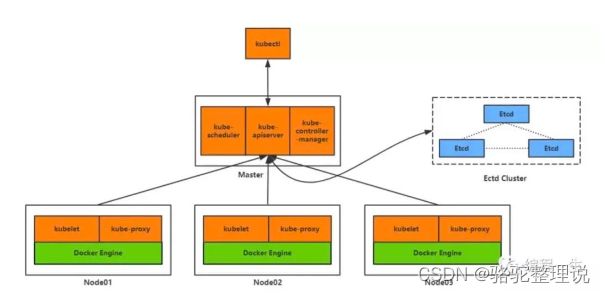
Kubernetes(k8s)是自动化容器操作的开源平台。容器操作包括部署、调度和节点集群扩展。具体功能:自动化容器部署和复制,实时弹性收缩容器规模,容器编排成组并提供容器间的负载均衡。调度:容器在哪个机器上运行。
组成:
kubectl:客户端命令行工具,作为整个系统的操作入口。
kube-apiserver:以REST API服务形式提供接口,作为整个系统的控制入口。
kube-controller-manager:执行整个系统的后台任务,包括节点状态状况、Pod个数、Pods和Service的关联等。
kube-scheduler:负责节点资源管理,接收来自kube-apiserver创建Pods任务,并分配到某个节点。
etcd:负责节点间的服务发现和配置共享。
kube-proxy:运行在每个计算节点上,负责Pod网络代理。定时从etcd获取到service信息来做相应的策略。
kubelet:运行在每个计算节点上,作为agent,接收分配该节点的Pods任务及管理容器,周期性获取容器状态,反馈给kube-apiserver。
DNS:一个可选的DNS服务,用于为每个Service对象创建DNS记录,这样所有的Pod就可以通过DNS访问服务了
K8s的架构拓扑图
两地三中心
两地三中心包括本地生产中心、本地灾备中心、异地灾备中心。
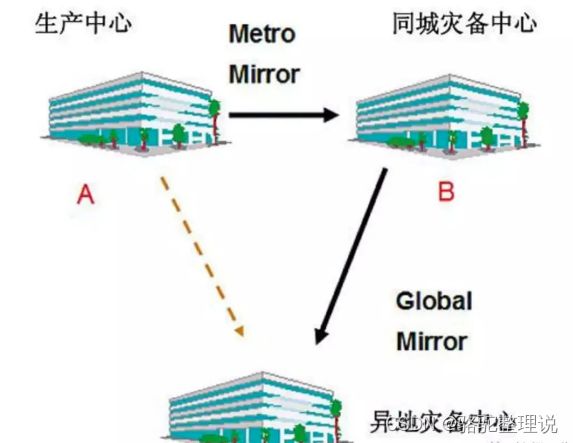
两地三中心要解决的一个重要问题就是数据一致性问题。k8s使用etcd组件作为一个高可用、强一致性的服务发现存储仓库。用于配置共享和服务发现。
它作为一个受到Zookeeper和doozer启发而催生的项目。除了拥有他们的所有功能之外,还拥有以下4个特点:
简单:基于http+json的api让你用curl命令就可以轻松使用。
安全:可选SSL客户认证机制。
快速:每个实例每秒支持一千次写操作。
可信:使用Raft算法充分实现了分布式。
四层服务发现
网络七层协议

k8s提供了两种方式进行服务发现:
环境变量:当创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。需要注意的是,要想一个Pod中注入某个Service的环境变量,则必须Service要先比该Pod创建。这一点,几乎使得这种方式进行服务发现不可用。
比如,一个ServiceName为redis-master的Service,对应的ClusterIP:Port为10.0.0.11:6379,则对应的环境变量为:

DNS:可以通过cluster add-on的方式轻松的创建KubeDNS来对集群内的Service进行服务发现。
以上两种方式,一个是基于tcp,众所周知,DNS是基于UDP的,它们都是建立在四层协议之上。
五种Pod共享资源
Pod是K8s最基本的操作单元,包含一个或多个紧密相关的容器,一个Pod可以被一个容器化的环境看作应用层的“逻辑宿主机”;一个Pod中的多个容器应用通常是紧密耦合的,Pod在Node上被创建、启动或者销毁;每个Pod里运行着一个特殊的被称之为Volume挂载卷,因此他们之间通信和数据交换更为高效,在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中。

同一个Pod里的容器之间仅需通过localhost就能互相通信。
一个Pod中的应用容器共享五种资源:
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
UTS命名空间:Pod中的多个容器共享一个主机名。
Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的Volumes。
Pod的生命周期通过Replication Controller来管理;通过模板进行定义,然后分配到一个Node上运行,在Pod所包含容器运行结束后,Pod结束。
Kubernetes为Pod设计了一套独特的网络配置,包括:为每个Pod分配一个IP地址,使用Pod名作为荣期间通信的主机名等。
六个CNI常用插件
CNI(Container Network Interface)容器网络接口,是Linux容器网络配置的一组标准和库,用户需要根据这些标准和库来开发自己的容器网络插件。CNI只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架,所以CNI可以支持大量不同的网络模式,并且容易实现。
下面用一张图表示六个CNI常用插件:

七层负载均衡
提负载均衡就不得不先提服务器之间的通信。
IDC(Internet Data Center),也可称 数据中心、机房,用来放置服务器。IDC网络是服务器间通信的桥梁。
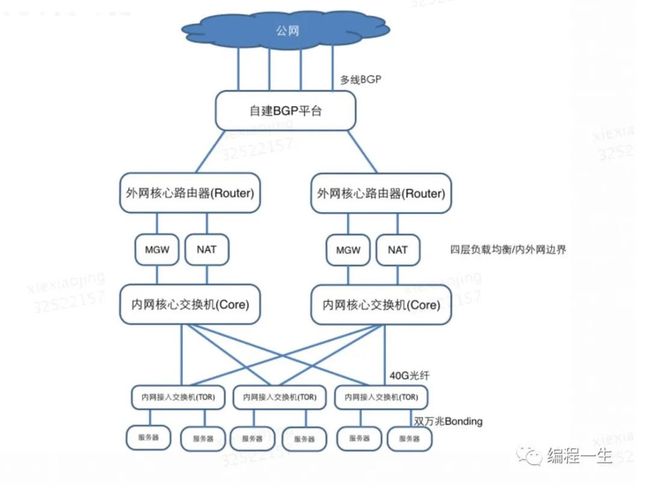
上图里画了很多网络设备,它们都是干啥用的呢?
路由器、交换机、MGW/NAT都是网络设备,按照性能、内外网划分不同的角色。
内网接入交换机:也称为TOR(top of rack),是服务器接入网络的设备。每台内网接入交换机下联40-48台服务器,使用一个掩码为/24的网段作为服务器内网网段。
内网核心交换机:负责IDC内各内网接入交换机的流量转发及跨IDC流量转发。
MGW/NAT:MGW即LVS用来做负载均衡,NAT用于内网设备访问外网时做地址转换。
外网核心路由器:通过静态互联运营商或BGP互联美团统一外网平台。
各层负载均衡:
二层负载均衡:基于MAC地址的二层负载均衡。
三层负载均衡:基于IP地址的负载均衡。
四层负载均衡:基于IP+端口的负载均衡。
七层负载均衡:基于URL等应用层信息的负载均衡。
四层和七层负载均衡的区别:

上面四层服务发现讲的主要是k8s原生的kube-proxy方式。K8s关于服务的暴露主要是通过NodePort方式,通过绑定minion主机的某个端口,然后进行pod的请求转发和负载均衡,但这种方式有下面的缺陷:
-
Service可能有很多个,如果每个都绑定一个node主机端口的话,主机需要开放外围的端口进行服务调用,管理混乱。
-
无法应用很多公司要求的防火墙规则。
理想的方式是通过一个外部的负载均衡器,绑定固定的端口,比如80,然后根据域名或者服务名向后面的Service ip转发,Nginx很好的解决了这个需求,但问题是如果有的心得服务加入,如何去修改Nginx的配置,并且加载这些配置?Kubernetes给出的方案就是Ingress。这是一个基于7层的方案。
八种隔离维度
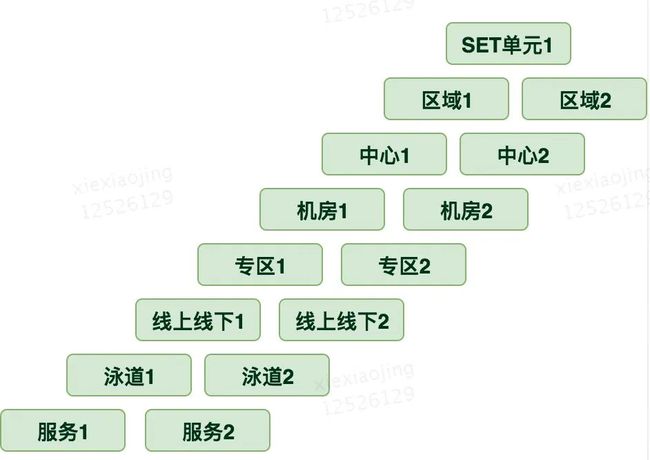
K8s集群调度这边需要对上面从上到下从粗粒度到细粒度的隔离做相应的调度策略。
九个网络模型原则
K8s网络模型要符合4个基础原则,3个网络要求原则,1个架构原则,1个IP原则。
每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的、扁平的网络空间中,不管是否运行在同一Node上都可以通过Pod的IP来访问。
K8s中的Pod的IP是最小粒度IP。同一个Pod内所有的容器共享一个网络堆栈,该模型称为IP-per-Pod模型。
-
Pod由docker0实际分配的IP
-
Pod内部看到的IP地址和端口与外部保持一致
-
同一个Pod内的不同容器共享网络,可以通过localhost来访问对方的端口,类似同一个VM内不同的进程。
IP-per-Pod模型从端口分配、域名解析、服务发现、负载均衡、应用配置等角度看,Pod可以看做是一台独立的VM或物理机。
-
所有容器都可以不用NAT的方式同别的容器通信。
-
所有节点都可以在不同NAT方式下同所有容器心痛,反之亦然。
-
容器的地址和别人看到的地址是同一个地址。
要符合下面的架构:

由上图架构引申出来IP概念从集群外部到集群内部

十类IP地址
大家都知道IP地址分为ABCDE类,另外还有5类特殊用途的IP。
第一类
A 类:1.0.0.0-1226.255.255.255,默认子网掩码/8,即255.0.0.0。
B 类:128.0.0.0-191.255.255.255,默认子网掩码/16,即255.255.0.0。
C 类:192.0.0.0-223.255.255.255,默认子网掩码/24,即255.255.255.0。
D 类:224.0.0.0-239.255.255.255,一般用于组播。
E 类:240.0.0.0-255.255.255.255(其中255.255.255.255为全网广播地址)。E 类地址一般用于研究用途。
第二类
0.0.0.0
严格来说,0.0.0.0 已经不是一个真正意义上的 IP 地址了。它表示的是这样一个集合:所有不清楚的主机和目的网络。这里的不清楚是指在本机的路由表里没有特定条目指明如何到达。作为缺省路由。
127.0.0.1 本机地址。
第三类
224.0.0.1 组播地址。
如果你的主机开启了IRDP(internet路由发现,使用组播功能),那么你的主机路由表中应该有这样一条路由。
第四类
169.254.x.x
使用了 DHCP 功能自动获取了 IP 的主机,DHCP 服务器发生故障,或响应时间太长而超出了一个系统规定的时间,系统会为你分配这样一个 IP,代表网络不能正常运行。
第五类
10.xxx、172.16.x.x~172.31.x.x、192.168.x.x 私有地址。
大量用于企业内部。保留这样的地址是为了避免亦或是哪个接入公网时引起地址混乱。