计算机组成实验-实验RIJ型的CPU设计
计算机组成实验(十)–实现RIJ型的CPU设计
因为在网上找到的相关实验顺序都是直接从代码开始,后来才开始介绍IP核,当时把我搞得一头雾水,个人认为先准备好初始化IP核要的数据文件,再开始写代码节奏会更好一点。所以写了这篇博客,记录从头到尾的实验顺序,方便大家学习。
实验目的
1、掌握MIPS R-I-J型指令的数据通路设计,掌握指令流和数据流的控制方法。
2、掌握完整的单周期CPU顶层模块的设计方法。
3、实现MIPS R-I-J型指令功能。
实验原理
R型指令集

I型指令集

J型指令集
j,jal均为无条件跳转指令。
j操作结果:{(PC+4)高四位,address(26位),2b’00(两位二进制00)} -> PC
jal操作结果:在执行完上述指令 j 的过程后,PC+4 -> $R31 (再将下一条指令地址指向31寄存器)

R-I-J型指令数据通路
采用哈佛结构(一个指令存储器和一个数据存储器)。
通常执行一条指令的流程是:根据PC(存放指令地址)到指令存储器里取地址 -> 取出地址后进行指令译码(译码及控制单元)-> 寄存器取数据 -> ALU运算 -> 送结果。

实验环境
操作系统:Win10
所用软件:ISE DesignSuite14.7、pcspim
操作步骤
本实验默认读者已经明白MIPS R-I-J型CPU的基本原理,旨在对实验的复刻进行指导。
1、指令测试,将内存0开始的10个数据复制到20号单元开始的数据。在任意位置处创建文本文件test.asm(这段汇编代码,计组实验指导书上面有),以便得到初始化指令寄存器的机器码,这些机器码可以保存在lnst.coe文件(自建一个文件)里。
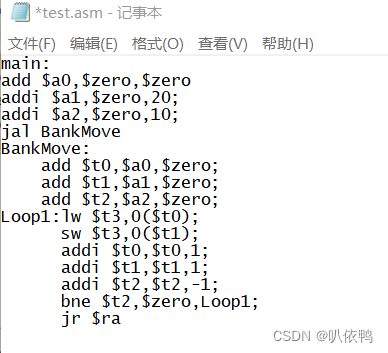
main:
add $a0,$zero,$zero
addi $a1,$zero,20;
addi $a2,$zero,10;
jal BankMove
BankMove:
add $t0,$a0,$zero;
add $t1,$a1,$zero;
add $t2,$a2,$zero;
Loop1:lw $t3,0($t0);
sw $t3,0($t1);
addi $t0,$t0,1;
addi $t1,$t1,1;
addi $t2,$t2,-1;
bne $t2,$zero,Loop1;
jr $ra
2、准备初始化指令存储器的文件lnst.coe。
用pcspim软件(下载链接:上百度网盘链接)执行上面的汇编代码文件,直接在pcspim主页的file中选取test.asm文件即可,执行完毕后,将如图所示的红框区域内的机器码复制下来保存到自建的lnst.coe文件里。

注:因为计算机只认识01比特串,所以借助pcspim将需要执行的汇编代码对应到机器能识别的二进制机器码,即可执行对应功能,在本实验中体现为lnst.coe文件初始化指令寄存器后,系统将会依次从指令寄存器中取指令并执行,从而实现步骤1中的指令测试。
lnst.coe文件内容如下:
memory_initialization_radix=16;
memory_initialization_vector=00002020,20050014,2006000a,0c100013,00804020,00a04820,00c05020,8d0b0000,ad2b0000,21080004,21290004,214affff,1540fffa,03e00008;
3、准备初始化数据存储器的文件data.coe
数据存储器里面的数据一般在读取内存时才会用到,所以随便填充。
memory_initialization_radix=16;
memory_initialization_vector=88888888,99999999,00010fff,20006789,FFFF0000,0000FFFF,88888888,99999999,
aaaaaaaa,bbbbbbbb,00000820,00632020,00010fff,20006789,FFFF0000,0000FFFF,88888888,99999999,aaaaaaaa,bbbbbbbb,00000820,00632020,00010fff,
20006789,FFFF0000,0000FFFF,88888888,99999999,aaaaaaaa,bbbbbbbb,00000820,00632020,00010fff,20006789,FFFF0000,0000FFFF,88888888,99999999,aaaaaaaa,bbbbbbbb,
00000820,00632020,00010fff,20006789,FFFF0000,0000FFFF,88888888,99999999,aaaaaaaa,bbbbbbbb,12345678,23456789,3456789a,6789abcd;
4、创建ip核(ISE DesignSuite14.7)
首先创建指令存储器的ip核。
在工程目录下任意位置右键,选择new source,在弹出的对话框中选择IP,并命名为rom(指令存储器为只读存储器)。

next,接着选择如图所示的内容
next,finish,创建rom.xco需要几分钟,耐心等待。
上述步骤完成后,进入Memory IP核参数设置。前两页默认设置,点击next。
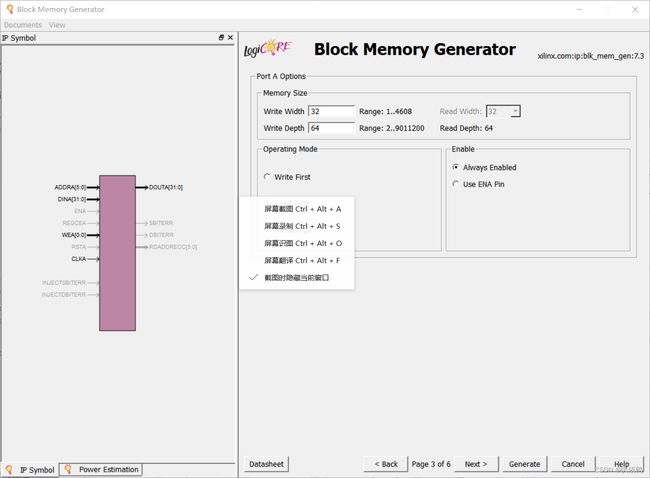
第三页配置为如下图所示(读优先,也可以写优先,width=32,depth=64,代表指令字长为32,指令存储器共能存储64条指令):
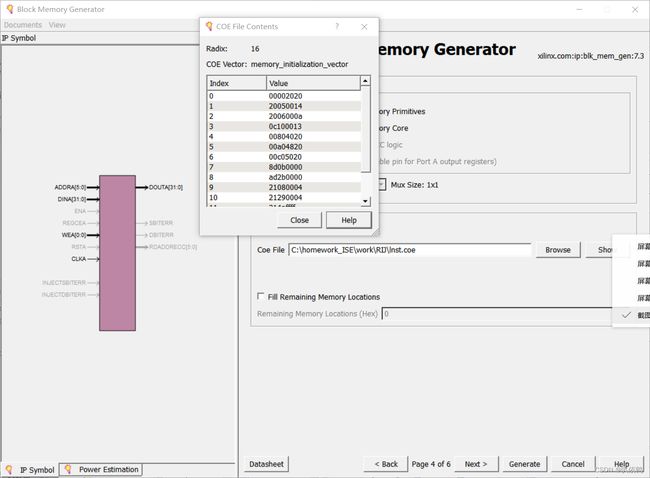
第四页配置为如下图所示(点击Browse,选择刚才创建的lnst.coe文件,点击show查看是否正确加载文件):
接着直接点击generate即可,生成ip核的过程需要几分钟,耐心等待。
生成完毕后,就会出现小灯泡样式的文件。
数据存储器的ip核生成过程类似,在选择存储器类型时选择ram(因为数据存储器可读可写),第四页配置为data.coe,接着generate即可。
5、代码实现
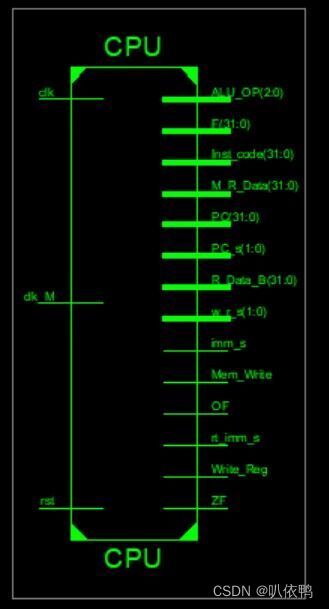
module R_I_J_CPU( //顶层模块,将各个部件通过函数调用联系起来,组成数据通路
clk,rst,clk_m,
Inst_code,PC,
opcode,rs,rt,rd,shamt,func,imm,offset,
ALU_F,ZF,OF,ALU_OP,
imm_s,rt_imm_s,
ALU_B,R_Data_A,W_Addr,W_Data,imm_kz,R_Data_B,M_R_Data,Write_Reg,Mem_Write,Mem_Addr,
PC_s,PC_next,w_r_s,wr_data_s
);
input clk;//时钟
input rst;//清零
input clk_m;//clk_m是数据存储器的时钟脉冲,至少是CPU脉冲clk的2倍
output reg [31:0]PC;//地址
output reg [31:0]PC_next;
wire [31:0]PC_new;
output [31:0]Inst_code;//取出的指令
output [5:0]opcode,func;//指令分段
output [4:0]rs,rt,rd,shamt;//指令分段
output [15:0]imm,offset;//指令分段
wire [25:0]address;//指令分段
output [31:0] ALU_F;//ALU结果
output reg [2:0] ALU_OP;//ALU结果
output ZF,OF;
output reg Write_Reg;
output reg Mem_Write;
output [31:0]R_Data_A;
output [31:0]R_Data_B;
output [31:0]M_R_Data;
output [7:0]Mem_Addr;
output reg imm_s;
output reg rt_imm_s;
output [4:0]W_Addr;
output [31:0]ALU_B;
output [31:0]W_Data;
output reg [31:0]imm_kz;
output reg [1:0]PC_s;
output reg[1:0]w_r_s;
output reg[1:0]wr_data_s;
initial PC = 32'h00000000;
assign PC_new = PC + 4;
Rom_J ROM1 ( //指令存储器,只读
.clka(clk), // input clka
.addra(PC[7:2]), // input [5 : 0] addra
.douta(Inst_code) // output [31 : 0] douta
);
always @(*)
case (PC_s) //根据PC_s ,赋值PC_next
2'b00: PC_next = PC_new;
2'b01: PC_next = R_Data_A;
2'b10: PC_next = PC_new + (imm_kz<<2);
2'b11: PC_next = {PC_new[31:28],address,2'b00};
endcase
always @(negedge clk or posedge rst)
begin
if (rst)
PC = 32'h00000000; //PC复位;
else
PC = PC_next; //PC更新为PC+4;
end;
assign opcode = Inst_code[31:26];
assign rs = Inst_code[25:21];
assign rt = Inst_code[20:16];
assign rd= Inst_code[15:11];
assign shamt = Inst_code[10:6];
assign func = Inst_code[5:0];
assign imm= Inst_code[15:0];
assign offset= Inst_code[15:0];
assign address = Inst_code[25:0];
always @(*)
begin
ALU_OP = 3'b100; //默认做加法
imm_s = 1'b0; //默认对立即数/偏移量进行0扩展
rt_imm_s = 1'b0; //默认读出rt寄存器的数据送ALU_B
Write_Reg = 1'b1; //默认写寄存器
Mem_Write = 1'b0; //默认不写存储器
PC_s = 2'b00;
w_r_s = 2'b00;
wr_data_s = 2'b00;
if (opcode==6'b000000) //R指令
begin
case (func) //指定不同运算对应不同的func值
6'b100000:begin ALU_OP=3'b100;end //add
6'b100010:begin ALU_OP=3'b101;end //sub
6'b100100:begin ALU_OP=3'b000;end //and
6'b100101:begin ALU_OP=3'b001;end //or
6'b100110:begin ALU_OP=3'b010;end //xor
6'b100111:begin ALU_OP=3'b011;end //nor
6'b101011:begin ALU_OP=3'b110;end //stlu
6'b000100:begin ALU_OP=3'b111;end //sllv
6'b001000:begin Write_Reg=0;Mem_Write=0;PC_s = 2'b01; end //jr
endcase
end
else
begin
case(opcode) //指定不同运算所对应的一系列控制信号
6'b001000:begin w_r_s=2'b01;imm_s=1;rt_imm_s=1;ALU_OP=3'b100;end //addi
6'b001100:begin w_r_s=2'b01;rt_imm_s=1;ALU_OP=3'b000; end //andi
6'b001110:begin w_r_s=2'b01;rt_imm_s=1;ALU_OP=3'b010;end //xori
6'b001011:begin w_r_s=2'b01;rt_imm_s=1;ALU_OP=3'b110; end //sltiu
6'b100011:begin w_r_s=2'b01;imm_s=1;rt_imm_s=1;wr_data_s=2'b01;ALU_OP=3'b100; end //lw
6'b101011:begin imm_s=1;rt_imm_s=1;ALU_OP=3'b100;Write_Reg=0;Mem_Write=1; end //sw
6'b000100:begin ALU_OP=3'b101;PC_s = (ZF)?2'b10:2'b00; Write_Reg = 1'b0;end //beq
6'b000101:begin ALU_OP=3'b101;PC_s = (ZF)?2'b00:2'b10; Write_Reg = 1'b0;end //bne
6'b000010:begin Write_Reg=0;Mem_Write=0;PC_s = 2'b11; end //j
6'b000011:begin w_r_s=2'b10;wr_data_s=2'b10;Write_Reg=1;Mem_Write=0;PC_s = 2'b11; end //jal
endcase
end
end;
always @(*)
begin
if(imm_s==1'b0)
begin
imm_kz={{16{1'b0}},imm};
end
if(imm_s==1'b1)
begin
case(imm[15])
1'b1:imm_kz={{16{1'b1}},imm};
1'b0:imm_kz={{16{1'b0}},imm};
endcase
end
end;
REGS REGS_1(R_Data_A,R_Data_B,W_Data,rs,rt,W_Addr,Write_Reg,rst,~clk);
ALU ALU_1(ALU_OP,R_Data_A,ALU_B,ALU_F,ZF,OF);
RAM_B RAM1 (
.clka(clk_m), // input clka
.wea(Mem_Write), // input [0 : 0] wea
.addra(Mem_Addr[7:2]), // input [5 : 0] addra
.dina(R_Data_B), // input [31 : 0] dina
.douta(M_R_Data) // output [31 : 0] douta
);
assign W_Addr=(w_r_s[1]) ? 5'b11111 : ((w_r_s[0])?rt:rd);
assign ALU_B=(rt_imm_s)?imm_kz:R_Data_B;
assign Mem_Addr=ALU_F[7:0];
assign W_Data = (wr_data_s[1])?PC_new :((wr_data_s[0])? M_R_Data:ALU_F);
endmodule
module REGS(R_Data_A,R_Data_B,W_Data,R_Addr_A,R_Addr_B,W_Addr,Write_Reg,rst,clk);
input clk;//写入时钟信号
input rst;//清零信号
input Write_Reg;//写控制信号
input [4:0]R_Addr_A;//A端口读寄存器地址
input [4:0]R_Addr_B;//B端口读寄存器地址
input [4:0]W_Addr;//写寄存器地址
input [31:0]W_Data;//写入数据
output [31:0]R_Data_A;//A端口读出数据
output [31:0]R_Data_B;//B端口读出数据
integer i;
reg [31:0] REG_Files[0:31];
initial
for(i=0;i<32;i=i+1) REG_Files[i]<=0;
always@(posedge clk or posedge rst)
begin
if(rst)
for(i=0;i<32;i=i+1) REG_Files[i]<=0;
else
if(Write_Reg&&W_Addr!=32'd0) REG_Files[W_Addr]<=W_Data;
end
assign R_Data_A=REG_Files[R_Addr_A];
assign R_Data_B=REG_Files[R_Addr_B];
endmodule
module ALU(ALU_OP,A,B,F,ZF,OF);
input [2:0] ALU_OP;
input [31:0] A;
input [31:0] B;
output [31:0] F;
output ZF;
output OF;
reg [31:0] F;
reg C,ZF;
always@(*)
begin
C=0;
case(ALU_OP) //指定不同运算所对应的ALU操作码
3'b000:begin F=A&B; end
3'b001:begin F=A|B; end
3'b010:begin F=A^B; end
3'b011:begin F=~(A|B); end
3'b100:begin {C,F}=A+B; end
3'b101:begin {C,F}=A-B; end
3'b110:begin F=A<B; end
3'b111:begin F=B<<A; end
endcase
ZF = F==0;
end
assign OF = ((ALU_OP==3'b100)||(ALU_OP==3'b101))&&(A[31] ^ B[31] ^ F[31] ^ C);
endmodule
#测试代码
always #13 clk_m=~clk_m;
always #47 clk=~clk;
initial begin
clk = 0;
rst = 1;
clk_m = 0;
#3;
rst=0;
end
endmodule
实验结果记录
仿真时序及波形图
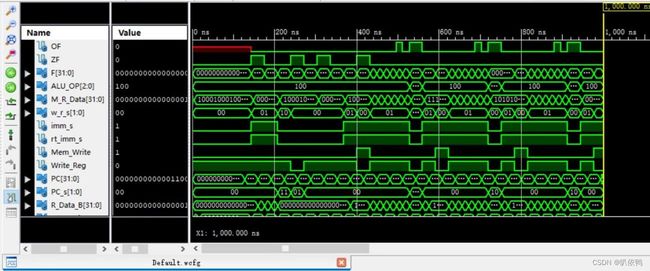
顶层模块

总结
实验过程中可能会遇到各种各样的问题,大佬们如果出现错误,可以自行百度,一般都能解决。在此分享我在实验的时候碰到的最大问题:memory IP核无法生成。经过百度明白是因为上一个IP核生成还没有结束,我就开始了下一个IP核的生成,造成了死锁,最后通过任务管理器关闭了正在运行的与ISE相关所有的进程,接着又删除了第一次做的IP核文件,重新做了一遍,才解决掉这个问题。
关于知识点的总结:
1、本实验完成的是MIPS 单周期RIJ型CPU数据通路的设计,单周期的特点是:要在一个时钟周期内完成一条指令(指令周期>机器周期>时钟周期)。所以设计的时候要搞清楚哪些操作需要时钟脉冲同步,哪些操作不需要时钟脉冲。指令存储器的读操作、PC值的更新、寄存器的写操作及标志寄存器的更新需要clk(可以理解为需要一个信号刺激才能完成);而寄存器的读操作、ALU运算不需要clk。
所以:clk上升沿,依据PC取指令;在clk高电平持续期间,完成PC自增、指令译码、寄存器读、ALU运算;clk下降沿,目的寄存器写、PC更新、标志寄存器更新。
2、从R型指令集到R-I型指令集的变化:
(1)目的寄存器可选。
(2)16位立即数imm需要扩展成32位才能与rs进行运算,且imm扩展又分为符号扩展(高16位直接填充符号值,0正1负;与有符号数进行运算就进行符号扩展,比如加减运算,或者作为地址偏移量时也是有正有负)和0扩展(高16位直接填充0,逻辑运算类的,比如异或)。
(3)ALU运算的数据来源B端多了一种选择,可以是符号扩展来的数据,也可以是从寄存器取出来的数据R_Data_B。
(4)因为有读写存储器的两条指令,所以要加上数据存储器。
(5)寄存器堆的写端口又多了一个选择:地址可以是rt/rd的值;写数据可以是ALU运算的结果,也可以是从存储器里读出的数据。
(6)sw指令:直接将从寄存器堆B端口读出的数据送到存储器数据端口。
补充一个小知识:对数据存储器的读/写都要与clk脉冲同步。但是如果CPU的clk和数据存储器的clk是同一个,则在clk的正边沿到来时,指令还未读出,存储器的有效地址还未计算出来,那读/写存储器就不可能得到正确结果。所以,使用频率更高的时钟作为数据存储器的clk,频率至少是CPU频率的2倍以上。
3、R-I型指令到R-I-J型指令的变化:
(1)添加了PC四选一的数据通道。
、、 PC=PC_new;
、、 PC=R_Data_A;
、、PC=PC_new+offset*4;
、、PC={PC_new高四位,address,00};
(2)添加了一个转移地址加法器和两个移位器。对于条件转移指令beq、bne,若满足条件,则PC_new+offset4 -> PC,在二进制中,左移一位就是乘2,右移一位就是除以2。还有一个移位器设在PC四选一处,作用类似,address后面加2个0凑成28位的数据与直接左移扩大两倍效果一样。
4、如何分辨是R型指令、I型指令还是J型指令
R型指令的op全0;J型指令只有j和jal(识别两个对应的op+func);其他的都是I型指令。
5、如何验证你做的数据通路是正确的
通过仿真时序波形图观察不同时间的取值,若跟汇编代码所实现的结果一致,则代表实验正确。