页面预加载优化实践

概述
在客户端开发中,列表类型页面大多都依赖网络请求,需要等网络数据请求下来后再刷新页面。但遇到网络请求慢的场景,就会导致页面加载很慢甚至加载失败。
我负责会员的商品列表页面,在业务场景中,页面元素比较复杂,并且涉及多个接口。最开始涉及十个左右的接口,经过我推动聚合后还有三个接口。所以,在进入商品列表页面时,需要等三个接口都请求完成才能刷新页面,这样会导致进入页面速度很慢。
总体思路
对于页面加载慢甚至失败的情况,可以对页面进行预加载,预加载也细化为prefetch和preload两部分,这两部分在方案中都包括。
方案先通过缓存数据将页面进行渲染,进入商品列表页后,再根据请求下来的服务器数据,决定是否用服务器数据对页面进行刷新。并且,用服务器的数据替换本地数据,供下次使用。看似比较简单,实际上做起来有很多细节需要处理和优化。后面的文章,将商品列表页统称为商品页。
prefetch
接口缓存
目前进入商品页有三个接口,接口数据请求下来后,会通过SVRequest网络库自带的缓存功能,对页面数据进行缓存。下次进入页面时,会先读取本地缓存数据,如果本地有缓存数据,会先用缓存数据刷新页面。刷新后,等网络数据请求下来,会判断网络数据和本地数据的一致性,根据结果决定是否用网络数据进行reload。
[self startRequestWithType:SVRequestTypeGet requestURL:requestURL cacheable:YES params:params cacheBlock:^(SVNetworkCache * _Nullable cache, SVRequestControl * _Nonnull requestControl) {
if (cache.cacheObj && [Reachability currentNetworkType] == NotReachable) {
[requestControl stop];
} else {
[requestControl goOn];
}
[self parseData:data successBlock:cacheBlock];
} successBlock:^(id _Nonnull responseObject) {
if (successBlock) {
NSDictionary *data = [responseObject as:[NSDictionary class]];
[self parseData:data successBlock:successBlock];
}
} failureBlock:^(SVRequestError * _Nonnull error, id _Nonnull responseObject) {
if (failedBlock) {
failedBlock(error, responseObject);
}
}];新用户
但是,对于新安装的用户,或者旧版本升级上来的用户,他们并没有本地缓存数据,之前版本也没有开启缓存功能。这样第一次进入商品页,依然要等待网络数据请求下来后,再刷新页面。
为了提升这一部分用户的体验,在商品页的主要入口的位置,在入口页面显示后,会在后台现成check缓存数据状态。如果没有缓存数据,则会预先请求服务器数据,并写入本地缓存,这样可以保证进入商品页,页面不会为空。由于仅针对新用户和旧版本升级上来的用户,所以请求数量增加有限,不会导致过多的后台压力。
并且,由于是多个接口,所以做的是每个接口的按需加载,只有没缓存数据的接口才会请求。一般,一个接口没数据其他两个也都没数据。但是,这个策略是避免浏览入口页面时,其中有一个接口请求失败,但没进入商品页,下次再浏览到入口页面还会继续请求,提高了缓存命中率。
preload
布局
为了保证push进入页面时,用户看到的就是已经渲染好的页面,所以需要对页面进行preload并渲染,时机选在初始化页面时进行。在初始化页面后,会根据本地读取的cacheData对页面进行layout,并且会调用layoutIfNeeded强制触发图形树中每个节点的布局。
这个过程相对比较顺滑,根据页面FPS的监测,并没有出现明显的FPS下降。并且,为了避免preload的过程影响埋点的准确性,将埋点和preload的过程进行剥离,当页面真正显示的时候才会进行上报。
从性能的角度,如果想在preload过程中保持比较高的FPS,应该避免发生离屏渲染和复杂的布局,这两项都是比较消耗CPU的,CPU消耗的增加就会影响主线程的运行,从而导致卡顿。而系统渲染操作是通过GPU进行的,不会过多消耗CPU性能,并且渲染操作相对于animation和交互式的gesture所带来的性能消耗,会少很多。
渲染原理
上面讲到了preload的话题,这里正好简单剖析下页面渲染的原理。
先简单说明一些常见的关键词,UIView负责布局和事件响应,CALayer负责页面的渲染。先对视图进行绘制,例如三角型、纹理的计算,最后再渲染成bitmap交给帧缓冲区,绘制和渲染是一个先后顺序。
iOS系统上采用双缓冲区机制,frame buffer前帧缓冲区,以及back buffer后帧缓冲区。CALayer不会直接跟frame buffer打交道,一般都是提交给back buffer。
渲染的过程,总的来说分为三步。
当收到
VSync信号后,App会通过CPU在主线程,计算显示内容,例如视图的创建和布局。随后将计算结果提交到
GPU,进行变换、合成、渲染等操作,GPU会将渲染后的结果交给back buffer。视频控制器收到下一个
VSync信号后,会将上次渲染的back buffer中的bitmap显示到屏幕上。但如果CPU和GPU没有计算完成,这一阵就会被丢弃,从而导致掉帧。
上述渲染逻辑对应到iOS系统上就是如下逻辑。
当
VSync信号到来时,视频控制器会从CALayer的contents中取走bitmap,并显示在屏幕上。contents的bitmap计算逻辑如下。UIView负责布局,当页面布局发生改变后,由UIView的layoutSubviews来完成计算,这个过程是通过CPU进行的。布局完成后,
UIView会调用setNeedsDisplay,并且调用CALayer的同名方法setNeedsDisplay,这个过程相当于做一个标记,下次runloop循环会进行渲染。CALayer的display方法会判断是否实现了displayLayer:方法,在方法中我们可以实现异步绘制方法,没有实现则进入系统默认绘制方法。CALayer会通过CGContextRef创建一个backing store,后续的绘制都在这个context上进行,包括自定义的drawRect。调用
drawInContext:方法进行系统绘制,由Core Graphics的API在context上完成绘制操作。将绘制的结果渲染后的
bitmap存储在contents属性中,bitmap也就是一张位图。
reload
刷新逻辑
为了保证用户体验,用缓存数据展示页面后,当网络数据请求下来,会对网络数据进行比对,如果网络数据不同则用网络数据刷新页面,以保证页面的准确性。如果网络数据和本地数据相同,则没必要进行一次无谓的刷新,会带来额外的性能消耗,以及不好的用户体验。
但是,商品页和其他业务还不太一样,并不是单一数据接口,所以设计一套灵活且适用于多个接口,进行hash比对的manager就比较重要。为了解决这个问题,设计了一套简单的多接口hash比对的方案。
多接口hash
方案用SVPCacheManager类来实现,可以对多个接口的hash进行管理。主要有几个职责,收集缓存hash、收集网络数据hash、多个hash的比对。整体是通过两个数组实现的,cacheHash负责收集缓存数据hash的,netHash负责收集接口数据hash。由于涉及多个接口,所以采用数组的设计,每个接口对应一个index,相同接口的缓存和网络数据计算的hash,收集时对应同一个index,即可保证顺序的问题。
为了保证通用性,也可以应用在其他接口的处理上,所以在初始化数组时是通过config配置count的。
@objc Members class SVPCacheManager: NSObject {
var cacheHash: [String]?
var netHash: [String]?
@objc static let shared = SVPCacheManager()
func config(count: Int) {
cacheHash = [String](repeating: "", count: count)
netHash = [String](repeating: "", count: count)
}
func appendCache(index: Int, hash: String) {
if hash.length > 0 {
cacheHash?[index] = hash
}
}
func appendNet(index: Int, hash: String) {
if hash.length > 0 {
netHash?[index] = hash
}
}
func isEqual() -> Bool {
return cacheHash == netHash
}
}易变参数
商品页接口有很多容易发生改变的字段,例如活动模版会有和时间相关的expire time时间戳,或者H5页面用的html标签字符串,以及一些用不到的play count format。这些字段都很容易发生变化,并且会导致cacheManager的hash值匹配失败。
为了增加匹配度,对于缓存数据和网络数据中,这些没用的易变参数,通过KVC的方式去掉。对处理后的Dictionary计算hash,这样可以使网络数据和缓存的匹配率大大提升,提升用户体验。
有序字典
字典是一个无序的数据结构,在生成hash时,是通过接口数据去除易变参数后,对Dictionary字符串生成的md5作为hash。但由于系统对json转换Dictionary的过程并不稳定,导致每次key的先后顺序都是不同的,并且这个过程没有规律。
下面就是一个相同接口,两次不同请求转为Dictionary后,key、value的对比。这样的顺序,相同的数据基本每次比对都会导致匹配失败,最后计算的hash值也是不同的。
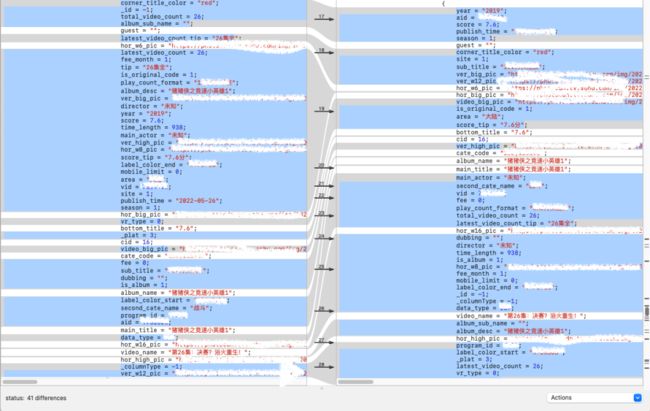
这时候重要的就是把无序的字典变为“有序”,做法是自定义字典的遍历方式,定义一个可变字符串,从根节点出发,一层一层进行递归遍历。
先对根节点的key数组进行排序,并将排序结果转为字符串后,append给可变字符串。再通过有序key数组取出对应的value,先将非字典和数组value,逐个append到可变字符串上,随后再递归调用该方法,并将value为字典和数组的值传入。如果传入的是数组对象,则先遍历非字典和数组的value,逐个append到可变字符串上,再进行递归调用并传入参数。
一直递归重复上面的动作,直到叶子节点为止,总体思路就是通过可变字符串,一层层拼接排序后的key和value,最后用拼接后的可变字符串计算md5作为hash。为了保证结果的准确性,不能只对value进行遍历,因为要考虑相同value但取值逻辑不同的情况。
analyze
为了方便进行数据分析,在之前的版本中已经对接口请求速度增加了埋点,统计规则是接口开始请求前,到三个接口都请求结束的时间,来计算请求接口总计消耗的时间。由于做了数据缓存后,刚进入页面时不需要请求完数据再展示页面,而是直接从本地读取数据。所以,这个统计点的数值基本为0。
我认为,优化后应该关注的,应该是缓存匹配度的问题。如果用本地数据刷新页面后,网络数据和本地匹配,进入页面后没有reload也就是二次刷新的问题,这样对于用户体验就是好的,优化目的也是为了有更好的用户体验。
参考链接
iOS 页面渲染 - UIView & CALayer