Golang常见面试题及解答
Golang常见面试题及解答
- 注意
- 1、Golang的Slice【切片】、数组
- 2、Golang函数去重【代码】
- 3、Golang的channel关闭【代码】
- 4、Golang`反转链表`【代码】
- 5、Golang交替打印【代码】
- 6、 goroutine(协程)调度原理
- 7、goroutine与线程区别
- 8、Golang的并发实现方式
- 9、Golang的垃圾回收机制
- 10、Protobuf 2和3的区别
- 11、Protobuf中每个字段后的序号作用?
- 12、protobuf和json对比
- 13、Golang里的结构体可以直接使用双等号作比较吗?
- 14、Golang里有Set结构体吗?如果没有怎么设计一个Set结构体?
- 15、golang里面两个interface可以比较吗?
- 16、golang里面interface可以和nil比较吗?
- 17、二叉树的最近公共祖先【代码】
- 18、删除链表的倒数第N个节点【代码】
- 19、给一个二叉树,找出它的最大深度
- 20、超时的实现【代码】
- 21、并发控制,使goroutine数目保持在10个【代码】
- 22、golang的runtime
- 23、gorm遇到过的坑
- 24、golang中的context
- 25、golang的channel
- 26、golang死锁的场景及解决办法
- 27、golang的僵尸进程
- 28、往一个只声明未初始化的channel里写入数据会怎样?
- 29、Golang的map底层结构讲解?
- 30、比较版本的大小【代码】
- 31、Golang的进程能启动多少个协程?
- 32、Golang的goroutine【协程】之间并发安全是如何处理的?
- 33、往一个关闭的channel读写会怎样?
- 34、关闭两次channel会怎样?
- 35、Golang函数的入参是值传递还是引用传递?
- 36、Golang的map如何判断是否并发写?
- 37、Gin里面的中间件?
- 38、Gorm更新数据为零值?
- 39、Gorm的自动建表有使用过吗?
- 40、实现一个快速排序【代码】
- 41、GRPC某个服务的接口能通过浏览器访问吗?
- 42、对微服务的生态有了解吗?
- 43、都知道哪些注册中心,有什么区别?
- 44、Consul和Etcd有什么区别?
- 45、golang微服务的健康检查?
- 46、golang的引用类型有哪几种?
- 47、golang的make和new的区别?
- 48、Golang的map并发安全吗?
- 49、Golang的channel使用场景?
- 50、sync.map的底层实现?
- 52、sync.Map使用场景
- 52、sync.map与map的区别?
- 53、Golang的map并发读写会panic吗?
- 54、Golang的map怎么变得有序?
- 55、Golang的defer和return的执行顺序?
- 56、Golang的defer能否修改return的值?
- 57、Golang的select语句的功能?
- 58、Golang的select语句多个case满足条件时,执行哪一个?
- 59、
注意
本文仅供各位参考,后续会整理发布一篇更完整的。
1、Golang的Slice【切片】、数组
参考1:https://topgoer.cn/docs/golang/chapter03-11
参考2:https://blog.csdn.net/qq_39382769/article/details/122505632
扩展的看参考2。
切片和数组对比:
- 在 Go 中,数组是值类型,赋值和函数传参操作都会复制整个数组数据。在数据量非常大时,每次传参都用数组,那么每次数组都要被复制一遍。这样会消耗掉大量的内存。所以函数传参用改为使用数组的指针。
- 但是传递数组指针会有一个弊端,万一原数组的指针指向更改了,那么函数里面的指针指向都会跟着更改。
- 切片的优势也就表现出来了,切片是引用传递,所以它们不需要使用额外的内存并且比使用数组更有效率。用切片传数组参数,既可以达到节约内存的目的,也可以达到合理处理好共享内存的问题。
切片的数据结构
type slice struct {
array unsafe.Pointer
len int
cap int
}
-
切片的结构体由3部分构成,Pointer 是指向一个数组的指针,len 代表当前切片的长度,cap 是当前切片的容量。cap 总是大于等于 len 的。
-
slice本身并不是动态数组或者数组指针,它的内部实现是通过指针引用底层数组,设置相关的属性,将数据的读写操作限定在指定的区域内。
-
slice本身是一个只读读写,修改的是底层数组,而不是slice本身,其工作机制类似于数组指针的一种封装。
-
slice是对数组中一个连续片段的引用,所以slice是一个引用类型。
切片扩容的策略:
如果切片的容量小于 1024 个元素,于是扩容的时候就翻倍增加容量。一旦元素个数超过 1024 个元素,那么增长因子就变成 1.25 ,即每次增加原来容量的四分之一。
注意:扩容扩大的容量都是针对原来的容量而言的,而不是针对原来数组的长度而言的。
2、Golang函数去重【代码】
写一个函数,给定一个[]string变量,返回该切片去重之后的切片。举个例子,如果给定的是[1,2,3,2,2,1],返回[1,2,3],顺序不重要。
答:可以利用map来实现去重的功能。
package main
import "fmt"
func main() {
//写一个函数,给定一个[]string变量,返回该切片去重之后的切片。
//举个例子,如果给定的是[1,2,3,2,2,1],返回[1,2,3],顺序不重要。
oldStr := []string{"1", "2", "3", "2", "2", "1"}
fmt.Println("oldStr:", oldStr)
mapString := make(map[string]bool)
for _, num := range oldStr {
mapString[num] = true
}
newStr := []string{}
for key, _ := range mapString {
newStr = append(newStr, key)
}
fmt.Println("newStr:", newStr)
}
3、Golang的channel关闭【代码】
写一段从在从channel中不断读取数据,并打印出来的程序。当channel被关闭时,需要打印“Channel is closed”并结束程序。
package main
import (
"fmt"
)
func main() {
ch := make(chan int, 5)
listenCh := make(chan int)
go readNum(ch, listenCh)
for i := 0; i <= 4; i++ {
ch <- i
if i == 4 {
close(ch)
}
}
<-listenCh
}
func readNum(ch chan int, listenCh chan int) {
for {
if num, ok := <-ch; !ok {
fmt.Println("Channel is closed")
listenCh <- 0
} else {
fmt.Println("num:", num)
}
}
}
4、Golang反转链表【代码】
请使用Golang语言,实现一个反转链表的功能。需要实现的关键点如下:
- 实现一个链表结构体,自行定义必要的结构体方法。链表节点的值类型可以自行设定。
- 实现一个函数,传入一个链表结构体的指针,返回一个链表结构体的指针,返回的链表为输入链表的反转。
- 实现一个主函数,对上面反转函数进行验证。
- 对主函数的运行结果进行截图,并从截图角度证实上面的实现是正确的。
package main
import "fmt"
type Node struct {
Data int
Next *Node
}
func main() {
head := new(Node)
head.Data = 1
node2 := new(Node)
node2.Data = 2
node3 := new(Node)
node3.Data = 3
node4 := new(Node)
node4.Data = 4
head.Next = node2
node2.Next = node3
node3.Next = node4
fmt.Println("翻转前:")
printNum(head)
result := reverse(head)
fmt.Println("翻转后:")
printNum(result)
}
//反转
func reverse(currentNode *Node) *Node {
if currentNode == nil {
return nil
}
var preNode *Node
for currentNode != nil {
temp := currentNode.Next
currentNode.Next = preNode
preNode = currentNode
currentNode = temp
}
return preNode
}
func printNum(currentNode *Node) {
if currentNode != nil {
fmt.Print(currentNode.Data)
if currentNode.Next != nil {
fmt.Print(",")
printNum(currentNode.Next)
}else {
fmt.Println()
}
}
}
5、Golang交替打印【代码】
golang两个协程,要求实现交替打印的效果,go1 => 1 3 5 7;go2 => 2 4 6 8 ;整体输出是 go1和go2交替打印。
package main
import (
"fmt"
"sync"
)
//使用两个 goroutine 交替打印序列,
// 一个 goroutine 打印数字,
// 另外一个 goroutine 打印字母,
// 最终效果如下:
//
//12AB34CD56EF
func main() {
wg := sync.WaitGroup{}
wg.Add(2)
arr1 := []int{1, 2, 3, 4, 5, 6}
arr2 := []string{"A", "B", "C", "D", "E", "F"}
c := make(chan int, 1)
d := make(chan string, 1)
go func() {
i := 0
for i < 6 {
//此处是打印两个元素,所以后面是 i += 2
fmt.Print(arr1[i])
fmt.Print(arr1[i+1])
c <- 1
i += 2
<-d
}
wg.Done()
}()
go func() {
i := 0
for i < 6 {
<-c
//此处是打印两个元素,所以后面是 i += 2
fmt.Print(arr2[i])
fmt.Print(arr2[i+1])
i += 2
d <- "1"
}
wg.Done()
}()
wg.Wait()
fmt.Println()
fmt.Println("hello world!")
}
6、 goroutine(协程)调度原理
参考1:https://zhuanlan.zhihu.com/p/323271088
只看 二、Goroutine调度器的GMP模型的设计思想 往后的即可。
golang的调度是通过 GMP模型 实现的。
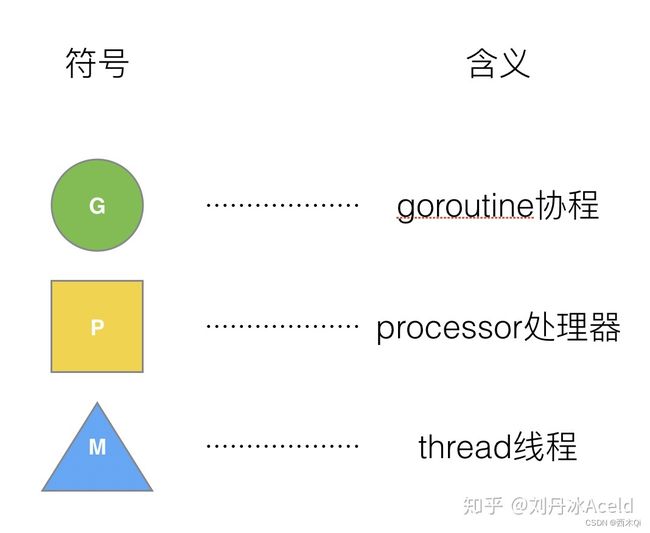
- G:goroutine 协程;
- P:processor处理器;
- M:thread线程;
Processor,它包含了运行goroutine的资源,如果线程想运行goroutine,必须先获取P,P中还包含了可运行的G队列。
GMP模型细节
在Go中,线程是最终运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上。
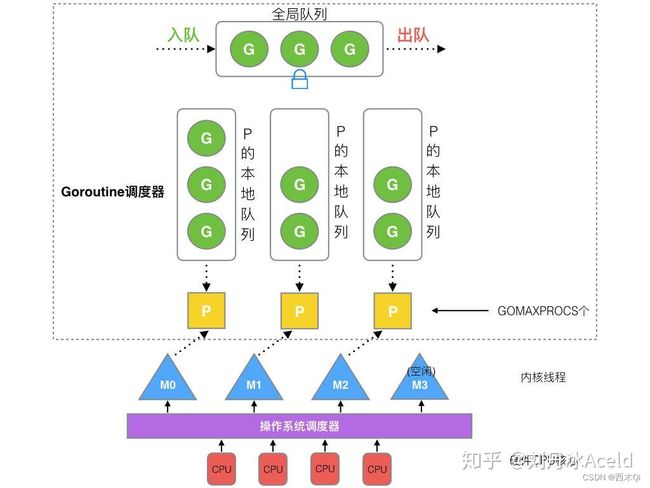
- 全局队列(Global Queue):存放等待运行的G。
- P的本地队列:同全局队列类似,存放的也是等待运行的Goroutine协程,存的数量有限,不超过256个。新建G’时,G’优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。
- P列表:所有的P都在程序启动时创建,并保存在数组中,最多有GOMAXPROCS(可配置)个。
- M:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去。
Goroutine调度器和操作系统的调度器是通过M结合起来的,每个M都代表了1个内核线程,操作系统的调度器负责把内核线程分配到CPU的核上执行。
有关P和M的个数问题
P的数量:
由启动时环境变量
$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()方法决定。这意味着在程序执行的任意时刻都只有$GOMAXPROCS个goroutine在同时运行。
M的数量:
- go语言本身的限制:go程序启动时,会设置M的最大数量,默认10000.但是内核很难支持这么多的线程数,所以这个限制可以忽略。
- runtime/debug中的SetMaxThreads函数,设置M的最大数量
- 一个M阻塞了,会创建新的M。
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来。
P和M何时会被创建
-
P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P。
-
M何时创建:没有足够的M来关联P并运行其中的可运行的G。比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M。
7、goroutine与线程区别
-
内存占用
创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容。创建一个 thread 则需要消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离。 -
创建和销毁
Thread 创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池。而 goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。 -
切换
当 threads 切换时,需要保存各种寄存器,以便将来恢复。
而 goroutines 切换只需保存三个寄存器:Program Counter, Stack Pointer and BP。
一般而言,线程切换会消耗 1000-1500 纳秒,一个纳秒平均可以执行 12-18 条指令。所以由于线程切换,执行指令的条数会减少 12000-18000。Goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。
因此,goroutines 切换成本比 threads 要小得多。
8、Golang的并发实现方式
参考1:https://www.jb51.net/article/243510.htm
一共四种:
- goroutine:Golang 在语言层面对并发编程进行了支持, 使用go关键字来使用协程。
- Channel:Channel 中 Go语言在语言级别提供了对 goroutine 之间通信的支持,我们可以使用 channel 在两个或者多个goroutine之间进行信息传递,能过 channel 传递对像的过程和调用函数时的参数传递行为一样,可以传递普通参数和指针。
- Select:当我们在实际开发中,我们一般同时处理两个或者多个 channel 的数据,我们想要完成一个那个 channel 先来数据,我们先来处理个那 channel ,避免等待。
- 传统的并发控制:sync.Mutex加锁和sync.WaitGroup等待组。
9、Golang的垃圾回收机制
参考1:https://www.cnblogs.com/yinbiao/p/15736301.html
参考2:https://cloud.tencent.com/developer/article/2108449
按 参考1 讲述。
10、Protobuf 2和3的区别
- protoful文件的第一行需要指定您正在使用proto3语法:如果不这样做,protocol buffer编译器将假定使用的是proto2。这必须是文件的第一个非空、非注释行。
- proto3取消了proto2的required,而proto3的singular就是proto2的optional。
- proto3 repeated标量数值类型默认packed,而proto2默认不开启。
- proto3增加了Kotlin,Ruby,Objective-C,C#,Dart的支持。
- proto2可以选填default,而proto3只能使用系统默认的。(序列化后如果是默认值是不会占用空间的,对于proto2来说处理就很麻烦了)
- proto3必须有一个零值,以便我们可以使用 0 作为数字默认值。零值需要是第一个元素,以便与proto2语义兼容,其中第一个枚举值始终是默认值。proto2则没有这项要求。
- proto3在3.5版本之前会丢弃未知字段。但在 3.5 版本中,重新引入了未知字段的保留以匹配 proto2 行为。在 3.5 及更高版本中,未知字段在解析过程中保留并包含在序列化输出中。
- proto3移除了proto2的扩展,新增了Any(仍在开发中)和JSON映射。
11、Protobuf中每个字段后的序号作用?
参考1:深入解析protobuf 1-proto3 使用及编解码原理介绍
字段编号
- 每个字段有唯一编号,在二进制流中标识字段,可以看后面protobuf 编解码原理去了解字段的作用。
- 消息被使用了,字段就不能改了,改了会造成数据错乱(常见坑),服务器和客户端很多bug,是proto buffer 文件更改,未使用更改后的协议导致。
- 1 到 15 范围内的字段编号需要一个字节进行编码,编码结果将同时包含编号和类型
- 16 到 2047 范围内的字段编号占用两个字节。因此,非常频繁出现的 message 元素保留字段编号 1 到 15。
- 字段最小数字为1,最大字段数为2^29 - 1。(原因在编码原理那章讲解过,字段数字会作为key,key最后三位是类型)
- 19000 through 19999 (FieldDescriptor::kFirstReservedNumber through FieldDescriptor::kLastReservedNumber这些数字不能用,这些是保留字段,如果使用会编译器会报错。
12、protobuf和json对比
参考1:protobuf和json的对比

13、Golang里的结构体可以直接使用双等号作比较吗?
参考1:Golang = 比较与赋值
参考2:golang中如何比较struct,slice,map是否相等以及几种对比方法的区别
- 结构体只能比较是否相等,但是不能比较大小。
- 相同类型的结构体才能够进行比较,结构体是否相同不但与属性类型有关,还与属性顺序相关,sn3 与 sn1 就是不同的结构体;
- 如果 struct 的所有成员都可以比较,则该 struct 就可以通过 == 或 != 进行比较是否相等,比较时逐个项进行比较,如果每一项都相等,则两个结构体才相等,否则不相等;(像切片、map、函数等是不能比较的)
14、Golang里有Set结构体吗?如果没有怎么设计一个Set结构体?
参考1:Golang数据结构实现(二)集合Set
//定义1个set结构体 内部主要是使用了map
type set struct {
elements map[interface{}]bool
}
15、golang里面两个interface可以比较吗?
参考1:golang中接口值(interface)的比较
Go 语言中,interface 的内部实现包含了 2 个字段,类型 T 和 值 V,interface 可以使用 == 或 != 比较。
2个interface 相等有以下 2 种情况:
- 两个 interface 均等于 nil(此时 V 和 T 都处于 unset 状态)
- 类型 T 相同,且对应的值 V 相等。
16、golang里面interface可以和nil比较吗?
参考1:Go 神坑 1 —— interface{} 与 nil 的比较
当对interface变量进行判断是否为nil时 , 只有当动态类型和动态值都是nil , 这个变量才是nil。
17、二叉树的最近公共祖先【代码】
参考1:【leetcode】236. 二叉树的最近公共祖先
参考2:二叉搜索树的最近公共祖先的golang实现
解题思路:
- 要获取两个节点的最近公共祖先,其实就是获取两个节点到root的路径中,最早相遇的地方,但是我们从p或者q到root的路径是比较麻烦的,除非我们有一个父亲指针。
- 那我们其实可以从root开始找,判断左子树或者右子树是否有p或者q。
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
if root == nil || root == p || root == q {
return root
}
left := lowestCommonAncestor(root.Left, p, q)
right := lowestCommonAncestor(root.Right, p, q)
if left == nil {
return right
} else if right == nil {
return left
} else {
return root
}
}
18、删除链表的倒数第N个节点【代码】
参考1:删除链表的倒数第N个结点(go语言)
方法一:计算链表长度。
思路:先将 head 的长度计算出来,接着遍历链表,要删除倒数第二个,那么就是删除第length-n+1 个。代码如下:
func GetLength(head *ListNode) (length int) {
len:=0
for head!=nil {
head=head.Next
len++
}
return len
}
func removeNthFromEnd(head *ListNode, n int) *ListNode {
length:= GetLength(head)
newList:=&ListNode{0,head}
cur:=newList//相当于是一个游标
for i := 0; i < length-n; i++ {
cur=cur.Next//让游标一个一个往下走
}
cur.Next=cur.Next.Next
return newList.Next
}
方法二: 栈的思想,使用切片实现,代码如下:
//方法二:栈
func removeNthFromEnd(head *ListNode, n int) *ListNode {
nodes := []*ListNode{}
dummy := &ListNode{0, head}
for node := dummy; node != nil; node = node.Next {
nodes = append(nodes, node)
}
prev := nodes[len(nodes)-1-n]
prev.Next = prev.Next.Next
return dummy.Next
}
19、给一个二叉树,找出它的最大深度
参考1:leetcode之104二叉树的最大深度Golang
思路:采用深度优先遍历,对于求整棵树的深度,就是根节点的左子树的深度或者根结点的右子树的深度加1,那么,使用递归的方式就是:
depth(root)=1+max(depth(root.Left),depth(root.Right))
二叉树结构体:
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
算法:
func maxDepth(root *TreeNode) int {
if root == nil {
return 0
}
leftDepth := maxDepth(root.Left)
rightDepth := maxDepth(root.Right)
if leftDepth >= rightDepth {
return 1 + leftDepth
}
return 1 + rightDepth
}
20、超时的实现【代码】
参考1:golang超时控制 代码
日常开发中我们大概率会遇到超时控制的场景,比如一个批量耗时任务、网络请求等;一个良好的超时控制可以有效的避免一些问题(比如 goroutine 泄露、资源不释放等)。
两种方案:
- 在 go 中实现超时控制的方法非常简单,首先第一种方案是 Time.After(d Duration)。
- 第二种方案是利用 context。
21、并发控制,使goroutine数目保持在10个【代码】
参考1:golang控制goroutine数量以及获取处理结果
参考2:go并发控制–控制goroutine数量 代码
使用channel实现,设定size为10:
- 设定channel长度,循环开始每生成一个goroutine则写入一次channel
- channel写满则阻塞
- goroutine执行完毕,释放channel
- for循环中继续写入channel,保证同时执行的goroutine只有10个
22、golang的runtime
参考1:说说Golang的runtime
runtime包含Go运行时的系统交互的操作,例如控制goruntine的功能。还有debug,pprof进行排查问题和运行时性能分析,tracer来抓取异常事件信息,如 goroutine的创建,加锁解锁状态,系统调用进入推出和锁定还有GC相关的事件,堆栈大小的改变以及进程的退出和开始事件等等;race进行竞态关系检查以及CGO的实现。总的来说运行时是调度器和GC
23、gorm遇到过的坑
参考1:如何解决Go gorm踩过的坑
- 使用gorm.Model后无法查询数据
Scan error on column index 1, name “created_at”
//提示:
Scan error on column index 1, name “created_at”: unsupported Scan, storing driver.Value type []uint8
//解决办法:打开数据库的时候加上parseTime=true
root:123456@tcp(127.0.0.1:3306)/mapdb?charset=utf8&parseTime=true
24、golang中的context
参考1:golang中的context
context使用场景:
- 传递数据。
- 控制生命周期。
25、golang的channel
参考1:golang 系列:channel 全面解析
参考2:Golang “不要通过共享内存来通信,要通过通信来共享内存”
1、使用共享内存的话在多线程的场景下为了处理竞态,需要加锁,使用起来比较麻烦。另外使用过多的锁,容易使得程序的代码逻辑艰涩难懂,并且容易使程序死锁,死锁了以后排查问题相当困难,特别是很多锁同时存在的时候。
2、go语言的channel保证同一个时间只有一个goroutine能够访问里面的数据,为开发者提供了一种优雅简单的工具,所以go原生的做法就是使用channle来通信,而不是使用共享内存来通信。
26、golang死锁的场景及解决办法
参考1:Golang死锁场景总结
情形:
1、无缓存能力的管道,自己写完自己读。
2、协程来晚了。
3、管道读写时,相互要求对方先读/写。
4、读写锁相互阻塞,形成隐形死锁。
27、golang的僵尸进程
参考1:Go Exec 僵尸与孤儿进程
僵尸进程(zombie process)指:完成执行(通过exit系统调用,或运行时发生致命错误或收到终止信号所致),但在操作系统的进程表中仍然存在其进程控制块,处于"终止状态"的进程。
28、往一个只声明未初始化的channel里写入数据会怎样?
参考1:对未初始化的的chan进行读写,会怎么样?为什么?
答:读写未初始化的 chan 都会阻塞。
报 fatal error: all goroutines are asleep - deadlock!
为什么对未初始化的 chan 就会阻塞呢?
- 对于写的情况
- 未初始化的 chan 此时是等于 nil,当它不能阻塞的情况下,直接返回 false,表示写 chan 失败。
- 当 chan 能阻塞的情况下,则直接阻塞 gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2), 然后调用 throw(s string) 抛出错误,其中 waitReasonChanSendNilChan 就是刚刚提到的报错 “chan send (nil chan)”。
- 对于读的情况
- 未初始化的 chan 此时是等于 nil,当它不能阻塞的情况下,直接返回 false,表示读 chan 失败
- 当 chan 能阻塞的情况下,则直接阻塞 gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2), 然后调用 throw(s string) 抛出错误,其中 waitReasonChanReceiveNilChan 就是刚刚提到的报错 “chan receive (nil chan)”。
29、Golang的map底层结构讲解?
参考1:Golang源码探究 — map
Golang的map底层是用hmap结构体,其中包含了很多字段,buckets是一个数组。看参考1。
无序:golang 中没有专门的 map 排序函数,且 map 默认是无序的,也就是你写入的顺序和打印的顺序是不一样的。
30、比较版本的大小【代码】
参考1:版本号比较、排序。
思路:将版本号转成数组,两两对应比较。
31、Golang的进程能启动多少个协程?
自己理解,理论上应该是无限制,但是因为系统资源有限,所以需要根据实际情况,限制协程的数量,避免系统崩溃。
32、Golang的goroutine【协程】之间并发安全是如何处理的?
自己理解,加锁,比如sync.mutx,sync.WaitGroup{}等。
33、往一个关闭的channel读写会怎样?
参考1:Golang 关闭的Channel读写问题
可读不可写:
- 向一个已关闭的channel发送元素会引起 panic: send on closed channel。
- 在发送端关闭Channel,接收端还会继续接收到通道中的元素。但读取完chan的数据后再读取会返回false和默认值。
34、关闭两次channel会怎样?
自己理解,会引发死锁。
35、Golang函数的入参是值传递还是引用传递?
参考1:Golang函数参数的值传递和引用传递
值传递和引用传递都有,看入参的类型。
值传递:是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
引用传递:引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数,由于引用类型(slice、map、interface、channel)自身就是指针,所以这些类型的值拷贝给函数参数,函数内部的参数仍然指向它们的底层数据结构。
36、Golang的map如何判断是否并发写?
参考1:Golang的Map并发性能以及原理分析
并发写会报错:fatal error: concurrent map read and map write,解决办法是加锁,比如读写锁等。
37、Gin里面的中间件?
参考1:Gin框架—中间件
参考2:gin中间件
Gin中的中间件实际上还是一个Gin中的 gin.HandlerFunc。中间都是需要注册后才能启用的。
中间件分类:
全局中间件:全局中间件设置之后对全局的路由都起作用。
路由组中间件:路由组中间件仅对该路由组下面的路由起作用。
单个路由中间件:单个路由中间件仅对一个路由起作用。
38、Gorm更新数据为零值?
参考1:Gorm 更新零值问题
通过结构体变量更新字段值, gorm库会忽略零值字段。就是字段值等于0, nil, “”, false这些值会被忽略掉,不会更新。如果想更新零值,可以使用map类型替代结构体。
39、Gorm的自动建表有使用过吗?
参考1:(十三)GORM 自动建表(Migration特性)
GORM支持Migration特性,支持根据Go Struct结构自动生成对应的表结构。如果表已经存在不会重复创建。
注意:GORM 的AutoMigrate函数,仅支持建表,不支持修改字段和删除字段,避免意外导致丢失数据。
40、实现一个快速排序【代码】
参考1:https://www.jianshu.com/p/0e5c6bc4360e
分治法:快速排序是对冒泡排序的一种改进。基本思想是通过一趟排序将要排序的数据分割成独立的两部分,其中的一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
代码:
package main
import "fmt"
//left表示数组左边的下标
//right表示数组右边的下标
func QuickSort(left int, right int, array []int) {
l := left
r := right
// pivot 表示中轴
pivot := array[(left+right)/2]
//for循环的目标是将比pivot小的数放到左边,比pivot大的数放到右边
for l < r {
//从pivot左边找到大于等于pivot的值
for array[l] < pivot {
l++
}
//从pivot右边找到大于等于pivot的值
for array[r] > pivot {
r--
}
//交换位置
array[l], array[r] = array[r], array[l]
//优化
if l == r {
l++
r--
}
//向左递归
if left < r {
QuickSort(left, r, array)
}
//向左递归
if right > l {
QuickSort(l, right, array)
}
}
}
func main() {
arr := []int{48, 84, -34, 8, 38, 75}
QuickSort(0, len(arr)-1, arr)
fmt.Println(arr)
}
41、GRPC某个服务的接口能通过浏览器访问吗?
参考1:GRPC简介
当下,不可能直接从浏览器调用gRPC服务。gRPC大量使用HTTP/2功能,没有浏览器提供支持gRPC客户机的Web请求所需的控制级别。例如,浏览器不允许调用者要求使用的HTTP/2,或者提供对底层HTTP/2框架的访问。
42、对微服务的生态有了解吗?
参考1:简述GoLang优势与生态
43、都知道哪些注册中心,有什么区别?
参考1:注册中心对比Zookeeper、Eureka、Nacos、Consul和Etcd
etcd 是一个 Go 言编写的分布式、高可用的一致性键值存储系统,用于提供可靠的分布式键值存储、配置共享和服务发现等功能。
特点:
- 易使用:基于 HTTP+JSON 的 API 让你用 curl 就可以轻松使用。
- 易部署:使用 Go 语言编写,跨平台,部署和维护简单。
- 强一致:使用 Raft 算法充分保证了分布式系统数据的强一致性。
- 高可用:具有容错能力,假设集群有 n 个节点,当有 (n-1)/2 节点发送故障,依然能提供服务。
- 持久化:数据更新后,会通过 WAL 格式数据持久化到磁盘,支持 Snapshot 快照。
- 快速:每个实例每秒支持一千次写操作,极限写性能可达 10K QPS。
- 安全:可选 SSL 客户认证机制。
44、Consul和Etcd有什么区别?
consul提供了原生的分布式锁、健康检查、服务发现机制支持,让业务可以更省心,同时也对多数据中心进行了支持;- 当然 etcd 也能很好的进行支持,但是这两者不支持多数据中心;
- etcd 因为是 go 语言开发的,所以如果本身就是 go 的技术栈,使用这个也是个不错的选择,Consul 在国外应用比较多,中文文档及实践案例相比 etcd 较少;
45、golang微服务的健康检查?
使用的etcd实现的。【自己理解】
46、golang的引用类型有哪几种?
参考1:引用类型介绍
Golang的引用类型包括 slice、map 和 channel。
47、golang的make和new的区别?
参考1:https://www.cnblogs.com/koeln/p/15192376.html
参考2:https://blog.csdn.net/nyist_zxp/article/details/111567784
new只能用来分配内存。
make只能用于slice、map以及channel等引用类型的初始化。
48、Golang的map并发安全吗?
不安全,只读是线程安全的,主要是不支持并发写操作的,原因是 map 写操作不是并发安全的,当尝试多个 Goroutine 操作同一个 map,会产生报错:fatal error: concurrent map writes。所以map适用于读多写少的场景。
解决办法:要么加锁,要么使用sync包中提供了并发安全的map,也就是sync.Map,其内部实现上已经做了互斥处理。
49、Golang的channel使用场景?
参考1:https://blog.csdn.net/itopit/article/details/125460420
- 超时处理
- 定时任务
- 解耦生产者和消费者
- 控制并发数
50、sync.map的底层实现?
参考1:源码解读 Golang 的 sync.Map 实现原理
sync.map数据结构如下:
type Map struct {
// 加锁作用,保护 dirty 字段
mu Mutex
// 只读的数据,实际数据类型为 readOnly
read atomic.Value
// 最新写入的数据
dirty map[interface{}]*entry
// 计数器,每次需要读 dirty 则 +1
misses int
}
sync.Map 的实现原理可概括为:
- 通过 read 和 dirty 两个字段将读写分离,读的数据存在只读字段 read 上,将最新写入的数据则存在 dirty 字段上。
- 读取时会先查询 read,不存在再查询 dirty,写入时则只写入 dirty。
- 读取 read 并不需要加锁,而读或写 dirty 都需要加锁。
- 另外有 misses 字段来统计 read 被穿透的次数(被穿透指需要读 dirty 的情况),超过一定次数则将 dirty 数据同步到 read 上。
- 对于删除数据则直接通过标记来延迟删除。
52、sync.Map使用场景
参考1:Golang同步机制之sync.Map
sync.Map适用于读多写少的场景,因为写的次数过多会导致read map缓存失效,需要加锁,进而导致冲突变多;而且由于未命中read map次数过多,导致dirty map提升为read map,这是一个O(n)的操作,会进一步降低性能。
52、sync.map与map的区别?
区别是根据sync.map底层原理,实现了并发安全。
53、Golang的map并发读写会panic吗?
并发写会,报错:fatal error: concurrent map writes。所以map适用于读多写少的场景。
54、Golang的map怎么变得有序?
可以通过切片,按顺序往切片中存入Key。
55、Golang的defer和return的执行顺序?
参考1:go defer、return的执行顺序
return返回值的运行机制:return并非原子操作,共分为赋值、返回值两步操作。
defer、return、返回值三者的执行是:return最先执行,先将结果写入返回值中(即赋值);接着defer开始执行一些收尾工作;最后函数携带当前返回值退出(即返回值)。
56、Golang的defer能否修改return的值?
参考1:go defer、return的执行顺序
-
不带命名返回值
不会影响返回值,如果函数的返回值是无名的(不带命名返回值),则go语言会在执行return的时候会执行一个类似创建一个临时变量作为保存return值的动作。 -
有名返回值
有名返回值的函数,由于返回值在函数定义的时候已经将该变量进行定义,在执行return的时候会先执行返回值保存操作,而后续的defer函数会改变这个返回值(虽然defer是在return之后执行的,但是由于使用的函数定义的变量,所以执行defer操作后对该变量的修改会影响到return的值。
57、Golang的select语句的功能?
参考1:https://blog.csdn.net/anzhenxi3529/article/details/123644425
select语句:就是用来监听和channel有关的IO操作,当IO操作发生时,触发相应的case动作。有了 select语句,可以实现main主线程与goroutine线程之间的互动。
注意事项:
- select语句只能用于channel信道的IO操作,每个case都必须是一个信道。
- 如果不设置 default条件,当没有IO操作发生时,select语句就会一直阻塞;
- 如果有一个或多个IO操作发生时,Go运行时会随机选择一个case执行,但此时将无法保证执行顺序;
- 对于case语句,如果存在信道值为nil的读写操作,则该分支将被忽略,可以理解为相当于从select语句中删除了这个case;
- 对于空的 select语句,会引起死锁;
- 对于在 for中的select语句,不能添加 default,否则会引起cpu占用过高的问题;
58、Golang的select语句多个case满足条件时,执行哪一个?
参考 19.7注意事项的第三个。
如果有一个或多个IO操作发生时,Go运行时会随机选择一个case执行,但此时将无法保证执行顺序;