Java算法:LeetCode算法Java版合集513-1110题
513. 找树左下角的值
题目描述
给定一个二叉树,在树的最后一行找到最左边的值。
示例 1:
输入:
2
/ \
1 3
输出:
1
示例 2:
输入:
1
/ \
2 3
/ / \
4 5 6
/
7
输出:
7
注意: 您可以假设树(即给定的根节点)不为 NULL。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
int max = -1;
int value = 0;
public int findBottomLeftValue(TreeNode root) {
dfs(root, 0);
return value;
}
private void dfs(TreeNode root, int d) {
if (root == null) {
return;
}
d++;
if (max < d) {
max = d;
value = root.val;
}
dfs(root.left, d);
dfs(root.right, d);
}
}
515. 在每个树行中找最大值
题目描述
您需要在二叉树的每一行中找到最大的值。
示例:
输入:
1
/ \
3 2
/ \ \
5 3 9
输出: [1, 3, 9]
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
// 深度遍历
public List<Integer> largestValues(TreeNode root) {
List<Integer> list = new ArrayList<>();
dfs(list, root, 0);
return list;
}
private void dfs(List<Integer> list, TreeNode root, int level) {
if (root == null) {
return;
}
// 每深入一层,先把那一层的第一个节点加入返回 list中
if (list.size() == level) {
list.add(root.val);
}
// 此时 size > level ,那么就是开始遍历每一层 的 其他节点(不包括最左边的节点),
// 直接比较list的对应下标(index)的值与当前值就好
else {
list.set(level, Math.max(list.get(level), root.val));
}
// 左右子树,深度要+1
dfs(list, root.left, level + 1);
dfs(list, root.right, level + 1);
}
}
518. 零钱兑换 II
题目描述
给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
示例 1:
输入: amount = 5, coins = [1, 2, 5] 输出: 4 解释: 有四种方式可以凑成总金额: 5=5 5=2+2+1 5=2+1+1+1 5=1+1+1+1+1
示例 2:
输入: amount = 3, coins = [2] 输出: 0 解释: 只用面额2的硬币不能凑成总金额3。
示例 3:
输入: amount = 10, coins = [10] 输出: 1
注意:
你可以假设:
- 0 <= amount (总金额) <= 5000
- 1 <= coin (硬币面额) <= 5000
- 硬币种类不超过 500 种
- 结果符合 32 位符号整数
解法
Java
class Solution {
public int change(int amount, int[] coins) {
int[] f = new int[amount + 1];
f[0] = 1;
for (int coin : coins) {
for (int i = coin; i <= amount; ++i) {
f[i] += f[i - coin];
}
}
return f[amount];
}
}
520. 检测大写字母
题目描述
给定一个单词,你需要判断单词的大写使用是否正确。
我们定义,在以下情况时,单词的大写用法是正确的:
- 全部字母都是大写,比如"USA"。
- 单词中所有字母都不是大写,比如"leetcode"。
- 如果单词不只含有一个字母,只有首字母大写, 比如 "Google"。
否则,我们定义这个单词没有正确使用大写字母。
示例 1:
输入: "USA" 输出: True
示例 2:
输入: "FlaG" 输出: False
注意: 输入是由大写和小写拉丁字母组成的非空单词。
解法
Java
class Solution {
public boolean detectCapitalUse(String word) {
char[] cs = word.toCharArray();
int upper = 0;
int lower = 0;
for (int i = 0; i < cs.length; i++) {
if (cs[i] >= 'a') {
lower++;
} else {
upper++;
}
}
if (upper == cs.length) {
return true;
}
if (lower == cs.length) {
return true;
}
if (upper == 1 && cs[0] < 'a') {
return true;
}
return false;
}
}
521. 最长特殊序列 Ⅰ
题目描述
给定两个字符串,你需要从这两个字符串中找出最长的特殊序列。最长特殊序列定义如下:该序列为某字符串独有的最长子序列(即不能是其他字符串的子序列)。
子序列可以通过删去字符串中的某些字符实现,但不能改变剩余字符的相对顺序。空序列为所有字符串的子序列,任何字符串为其自身的子序列。
输入为两个字符串,输出最长特殊序列的长度。如果不存在,则返回 -1。
示例 :
输入: "aba", "cdc" 输出: 3 解析: 最长特殊序列可为 "aba" (或 "cdc")
说明:
- 两个字符串长度均小于100。
- 字符串中的字符仅含有 'a'~'z'。
解法
Java
class Solution {
public int findLUSlength(String a, String b) {
if (a.equals(b))
return -1;
return Math.max(a.length(), b.length());
}
}
522. 最长特殊序列 II
题目描述
给定字符串列表,你需要从它们中找出最长的特殊序列。最长特殊序列定义如下:该序列为某字符串独有的最长子序列(即不能是其他字符串的子序列)。
子序列可以通过删去字符串中的某些字符实现,但不能改变剩余字符的相对顺序。空序列为所有字符串的子序列,任何字符串为其自身的子序列。
输入将是一个字符串列表,输出是最长特殊序列的长度。如果最长特殊序列不存在,返回 -1 。
示例:
输入: "aba", "cdc", "eae" 输出: 3
提示:
- 所有给定的字符串长度不会超过 10 。
- 给定字符串列表的长度将在 [2, 50 ] 之间。
解法
Java
class Solution {
public int findLUSlength(String[] strs) {
int res = -1;
if (strs == null || strs.length == 0) {
return res;
}
if (strs.length == 1) {
return strs[0].length();
}
// 两两比较
// 1、存在子串,直接不比较后面的字符串
// 2、不存在子串,判断当前字符串是否是最长的字符串
for (int i = 0, j; i < strs.length; i++) {
for (j = 0; j < strs.length; j++) {
if (i == j) {
continue;
}
// 根据题意,子串 可以 不是 原字符串中 连续的子字符串
if (isSubsequence(strs[i], strs[j])) {
break;
}
}
if (j == strs.length) {
res = Math.max(res, strs[i].length());
}
}
return res;
}
public boolean isSubsequence(String x, String y) {
int j = 0;
for (int i = 0; i < y.length() && j < x.length(); i++) {
if (x.charAt(j) == y.charAt(i))
j++;
}
return j == x.length();
}
}
523. 连续的子数组和
题目描述
给定一个包含非负数的数组和一个目标整数 k,编写一个函数来判断该数组是否含有连续的子数组,其大小至少为 2,总和为 k 的倍数,即总和为 n*k,其中 n 也是一个整数。
示例 1:
输入: [23,2,4,6,7], k = 6 输出: True 解释: [2,4] 是一个大小为 2 的子数组,并且和为 6。
示例 2:
输入: [23,2,6,4,7], k = 6 输出: True 解释: [23,2,6,4,7]是大小为 5 的子数组,并且和为 42。
说明:
- 数组的长度不会超过10,000。
- 你可以认为所有数字总和在 32 位有符号整数范围内。
解法
Java
class Solution {
public boolean checkSubarraySum(int[] nums, int k) {
for (int start = 0; start < nums.length; start++) {
int check = 0;
for (int i = start; i < nums.length; i++) {
check += nums[i];
if (i > start) {
if (k != 0) {
if (check % k == 0) {
return true;
}
} else {
if (check == k) {
return true;
}
}
}
}
}
return false;
}
}
525. 连续数组
题目描述
给定一个二进制数组, 找到含有相同数量的 0 和 1 的最长连续子数组(的长度)。
示例 1:
输入: [0,1] 输出: 2 说明: [0, 1] 是具有相同数量0和1的最长连续子数组。
示例 2:
输入: [0,1,0] 输出: 2 说明: [0, 1] (或 [1, 0]) 是具有相同数量0和1的最长连续子数组。
注意: 给定的二进制数组的长度不会超过50000。
解法
Java
class Solution {
public int findMaxLength(int[] nums) {
Map<Integer, Integer> map = new HashMap<>();
map.put(0, -1);
int res = 0;
int s = 0;
for (int i = 0; i < nums.length; ++i) {
s += nums[i] == 1 ? 1 : -1;
if (map.containsKey(s)) {
res = Math.max(res, i - map.get(s));
} else {
map.put(s, i);
}
}
return res;
}
}
526. 优美的排列
题目描述
假设有从 1 到 N 的 N 个整数,如果从这 N 个数字中成功构造出一个数组,使得数组的第 i 位 (1 <= i <= N) 满足如下两个条件中的一个,我们就称这个数组为一个优美的排列。条件:
- 第 i 位的数字能被 i 整除
- i 能被第 i 位上的数字整除
现在给定一个整数 N,请问可以构造多少个优美的排列?
示例1:
输入: 2 输出: 2 解释: 第 1 个优美的排列是 [1, 2]: 第 1 个位置(i=1)上的数字是1,1能被 i(i=1)整除 第 2 个位置(i=2)上的数字是2,2能被 i(i=2)整除 第 2 个优美的排列是 [2, 1]: 第 1 个位置(i=1)上的数字是2,2能被 i(i=1)整除 第 2 个位置(i=2)上的数字是1,i(i=2)能被 1 整除
说明:
- N 是一个正整数,并且不会超过15。
解法
Java
class Solution {
public int countArrangement(int N) {
int maxn = 1 << N;
int[] f = new int[maxn];
f[0] = 1;
for (int i = 0; i < maxn; ++i) {
int s = 1;
for (int j = 0; j < N; ++j) {
s += (i >> j) & 1;
}
for (int j = 1; j <= N; ++j) {
if (((i >> (j - 1) & 1) == 0) && (s % j == 0 || j % s == 0)) {
f[i | (1 << (j - 1))] += f[i];
}
}
}
return f[maxn - 1];
}
}
530. 二叉搜索树的最小绝对差
题目描述
给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。
示例:
输入:
1
\
3
/
2
输出:
1
解释:
最小绝对差为 1,其中 2 和 1 的差的绝对值为 1(或者 2 和 3)。
提示:
- 树中至少有 2 个节点。
- 本题与 783 https://leetcode-cn.com/problems/minimum-distance-between-bst-nodes/ 相同
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int getMinimumDifference(TreeNode root) {
Integer res = Integer.MAX_VALUE, prev = Integer.MAX_VALUE;
Stack<TreeNode> stack = new Stack<>();
while (true) {
while (root != null) {
stack.push(root);
root = root.left;
}
if (stack.isEmpty()) break;
TreeNode node = stack.pop();
res = Math.min(res, Math.abs(node.val - prev));
prev = node.val;
root = node.right;
}
return res;
}
}
538. 把二叉搜索树转换为累加树
题目描述
给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和。
例如:
输入: 原始二叉搜索树:
5
/ \
2 13
输出: 转换为累加树:
18
/ \
20 13
注意:本题和 1038: https://leetcode-cn.com/problems/binary-search-tree-to-greater-sum-tree/ 相同
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
int add = 0;
public TreeNode convertBST(TreeNode root) {
if (root != null) {
convertBST(root.right);
root.val += add;
add = root.val;
convertBST(root.left);
}
return root;
}
}
541. 反转字符串 II
题目描述
给定一个字符串和一个整数 k,你需要对从字符串开头算起的每个 2k 个字符的前k个字符进行反转。如果剩余少于 k 个字符,则将剩余的所有全部反转。如果有小于 2k 但大于或等于 k 个字符,则反转前 k 个字符,并将剩余的字符保持原样。
示例:
输入: s = "abcdefg", k = 2 输出: "bacdfeg"
要求:
- 该字符串只包含小写的英文字母。
- 给定字符串的长度和 k 在[1, 10000]范围内。
解法
Java
class Solution {
public String reverseStr(String s, int k) {
if (k < 2) return s;
StringBuilder sb = new StringBuilder();
int length = s.length(), index = 0;
while (index < length) {
if (index + 2 * k <= length) {
sb.append(reverse(s, index, index + k));
sb.append(s.substring(index + k, index + 2 * k));
index += 2 * k;
} else if (index + k <= length){
sb.append(reverse(s, index, index + k));
sb.append(s.substring(index + k));
break;
} else {
sb.append(reverse(s, index, length));
break;
}
}
return sb.toString();
}
private StringBuffer reverse(String s, int index, int end) {
return new StringBuffer(s.substring(index, end)).reverse();
}
}
542. 01 矩阵
题目描述
给定一个由 0 和 1 组成的矩阵,找出每个元素到最近的 0 的距离。
两个相邻元素间的距离为 1 。
示例 1:
输入:
0 0 0 0 1 0 0 0 0
输出:
0 0 0 0 1 0 0 0 0
示例 2:
输入:
0 0 0 0 1 0 1 1 1
输出:
0 0 0 0 1 0 1 2 1
注意:
- 给定矩阵的元素个数不超过 10000。
- 给定矩阵中至少有一个元素是 0。
- 矩阵中的元素只在四个方向上相邻: 上、下、左、右。
解法
Java
class Solution {
public int[][] updateMatrix(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
int[][] res = new int[m][n];
for (int[] arr : res) {
Arrays.fill(arr, -1);
}
class Position {
int x, y;
public Position(int x, int y) {
this.x = x;
this.y = y;
}
}
Queue<Position> queue = new ArrayDeque<>();
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (matrix[i][j] == 0) {
res[i][j] = 0;
queue.offer(new Position(i, j));
}
}
}
int[] dirs = new int[]{-1, 0, 1, 0, -1};
while (!queue.isEmpty()) {
Position pos = queue.poll();
for (int i = 0; i < 4; ++i) {
int x = pos.x + dirs[i], y = pos.y + dirs[i + 1];
if (x >= 0 && x < m && y >= 0 && y < n && res[x][y] == -1) {
res[x][y] = res[pos.x][pos.y] + 1;
queue.offer(new Position(x, y));
}
}
}
return res;
}
}
543. 二叉树的直径
题目描述
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
示例 :
给定二叉树
1
/ \
2 3
/ \
4 5
返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
注意:两结点之间的路径长度是以它们之间边的数目表示。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
int ans = 1;
public int diameterOfBinaryTree(TreeNode root) {
depth(root);
return ans - 1;
}
public int depth(TreeNode node) {
if (node == null) return 0;
int L = depth(node.left);
int R = depth(node.right);
ans = Math.max(ans, L + R + 1);
return Math.max(L, R) + 1;
}
}
554. 砖墙
题目描述
你的面前有一堵方形的、由多行砖块组成的砖墙。 这些砖块高度相同但是宽度不同。你现在要画一条自顶向下的、穿过最少砖块的垂线。
砖墙由行的列表表示。 每一行都是一个代表从左至右每块砖的宽度的整数列表。
如果你画的线只是从砖块的边缘经过,就不算穿过这块砖。你需要找出怎样画才能使这条线穿过的砖块数量最少,并且返回穿过的砖块数量。
你不能沿着墙的两个垂直边缘之一画线,这样显然是没有穿过一块砖的。
示例:
输入: [[1,2,2,1],
[3,1,2],
[1,3,2],
[2,4],
[3,1,2],
[1,3,1,1]]
输出: 2
解释:

提示:
- 每一行砖块的宽度之和应该相等,并且不能超过 INT_MAX。
- 每一行砖块的数量在 [1,10,000] 范围内, 墙的高度在 [1,10,000] 范围内, 总的砖块数量不超过 20,000。
解法
Java
class Solution {
public int leastBricks(List<List<Integer>> wall) {
Map<Integer, Integer> map = new HashMap<>();
for (List<Integer> list : wall) {
int s = 0;
for (int i = 0; i < list.size() - 1; ++i) {
s += list.get(i);
map.put(s, map.getOrDefault(s, 0) + 1);
}
}
int max = map.values().stream().max(Integer::compare).orElse(0);
return wall.size() - max;
}
}
556. 下一个更大元素 III
题目描述
给定一个32位正整数 n,你需要找到最小的32位整数,其与 n 中存在的位数完全相同,并且其值大于n。如果不存在这样的32位整数,则返回-1。
示例 1:
输入: 12 输出: 21
示例 2:
输入: 21 输出: -1
解法
Java
class Solution {
public int nextGreaterElement(int n) {
if (n < 12) {
return -1;
}
char[] cs = String.valueOf(n).toCharArray();
int i = cs.length - 2;
while (i >= 0 && cs[i] >= cs[i + 1]) {
--i;
}
if (i < 0) {
return -1;
}
int j = cs.length - 1;
while (cs[i] >= cs[j]) {
--j;
}
swap(cs, i, j);
reverse(cs, i + 1, cs.length - 1);
long res = 0;
for (char c : cs) {
res = res * 10 + c - '0';
}
return res <= Integer.MAX_VALUE ? (int) res : -1;
}
private void reverse(char[] cs, int i, int j) {
while (i < j) {
swap(cs, i++, j--);
}
}
private void swap(char[] cs, int i, int j) {
char tmp = cs[i];
cs[i] = cs[j];
cs[j] = tmp;
}
}
557. 反转字符串中的单词 III
题目描述
给定一个字符串,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
示例 1:
输入: "Let's take LeetCode contest" 输出: "s'teL ekat edoCteeL tsetnoc"
注意:在字符串中,每个单词由单个空格分隔,并且字符串中不会有任何额外的空格。
解法
Java
class Solution {
public String reverseWords(String s) {
String flag = " ";
StringBuilder result = new StringBuilder();
for (String temp : s.split(flag)) {
for (int i = temp.length() - 1; i >= 0; i--) {
result.append(temp.charAt(i));
}
result.append(flag);
}
return result.toString().substring(0, s.length());
}
}
560. 和为 K 的子数组
题目描述
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
示例 1 :
输入:nums = [1,1,1], k = 2 输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。
说明 :
- 数组的长度为 [1, 20,000]。
- 数组中元素的范围是 [-1000, 1000] ,且整数 k 的范围是 [-1e7, 1e7]。
解法
Java
class Solution {
public int subarraySum(int[] nums, int k) {
Map<Integer, Integer> map = new HashMap<>();
map.put(0, 1);
int res = 0;
int s = 0;
for (int i = 0; i < nums.length; ++i) {
s += nums[i];
res += map.getOrDefault(s - k, 0);
map.put(s, map.getOrDefault(s, 0) + 1);
}
return res;
}
}
561. 数组拆分 I
题目描述
给定长度为 2n 的数组, 你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从1 到 n 的 min(ai, bi) 总和最大。
示例 1:
输入: [1,4,3,2] 输出: 4 解释: n 等于 2, 最大总和为 4 = min(1, 2) + min(3, 4).
提示:
- n 是正整数,范围在 [1, 10000].
- 数组中的元素范围在 [-10000, 10000].
解法
先排序,然后求相邻的两个元素的最小值,得到的总和即为结果。
Java
class Solution {
public int arrayPairSum(int[] nums) {
Arrays.sort(nums);
int res = 0;
for (int i = 0, n = nums.length; i < n; i += 2) {
res += nums[i];
}
return res;
}
}
563. 二叉树的坡度
题目描述
给定一个二叉树,计算整个树的坡度。
一个树的节点的坡度定义即为,该节点左子树的结点之和和右子树结点之和的差的绝对值。空结点的的坡度是0。
整个树的坡度就是其所有节点的坡度之和。
示例:
输入:
1
/ \
2 3
输出: 1
解释:
结点的坡度 2 : 0
结点的坡度 3 : 0
结点的坡度 1 : |2-3| = 1
树的坡度 : 0 + 0 + 1 = 1
注意:
- 任何子树的结点的和不会超过32位整数的范围。
- 坡度的值不会超过32位整数的范围。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
int sum = 0;
public int findTilt(TreeNode root) {
traverse(root);
return sum;
}
public int traverse(TreeNode root) {
if (root == null) return 0;
int left = traverse(root.left);
int right = traverse(root.right);
sum += Math.abs(left - right);
return left + right + root.val;
}
}
566. 重塑矩阵
题目描述
在MATLAB中,有一个非常有用的函数 reshape,它可以将一个矩阵重塑为另一个大小不同的新矩阵,但保留其原始数据。
给出一个由二维数组表示的矩阵,以及两个正整数r和c,分别表示想要的重构的矩阵的行数和列数。
重构后的矩阵需要将原始矩阵的所有元素以相同的行遍历顺序填充。
如果具有给定参数的reshape操作是可行且合理的,则输出新的重塑矩阵;否则,输出原始矩阵。
示例 1:
输入: nums = [[1,2], [3,4]] r = 1, c = 4 输出: [[1,2,3,4]] 解释: 行遍历nums的结果是 [1,2,3,4]。新的矩阵是 1 * 4 矩阵, 用之前的元素值一行一行填充新矩阵。
示例 2:
输入: nums = [[1,2], [3,4]] r = 2, c = 4 输出: [[1,2], [3,4]] 解释: 没有办法将 2 * 2 矩阵转化为 2 * 4 矩阵。 所以输出原矩阵。
注意:
- 给定矩阵的宽和高范围在 [1, 100]。
- 给定的 r 和 c 都是正数。
解法
Java
class Solution {
public int[][] matrixReshape(int[][] nums, int r, int c) {
int m = nums.length, n = nums[0].length;
if (m * n != r * c) return nums;
int[][] res = new int[r][c];
for (int i = 0; i < m * n; ++i) {
res[i / c][i % c] = nums[i / n][i % n];
}
return res;
}
}
572. 另一个树的子树
题目描述
给定两个非空二叉树 s 和 t,检验 s 中是否包含和 t 具有相同结构和节点值的子树。s 的一个子树包括 s 的一个节点和这个节点的所有子孙。s 也可以看做它自身的一棵子树。
示例 1:
给定的树 s:
3
/ \
4 5
/ \
1 2
给定的树 t:
4 / \ 1 2
返回 true,因为 t 与 s 的一个子树拥有相同的结构和节点值。
示例 2:
给定的树 s:
3
/ \
4 5
/ \
1 2
/
0
给定的树 t:
4 / \ 1 2
返回 false。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSubtree(TreeNode s, TreeNode t) {
if (t == null) return true;
if (s == null) return false;
if (s.val != t.val){
return isSubtree(s.left, t) || isSubtree(s.right, t);
}
return isSameTree(s, t) || isSubtree(s.left, t) || isSubtree(s.right, t);
}
private boolean isSameTree(TreeNode root1, TreeNode root2){
if(root1 == null && root2 == null) return true;
if(root1 == null || root2 == null) return false;
if(root1.val != root2.val) return false;
return isSameTree(root1.left, root2.left) && isSameTree(root1.right, root2.right);
}
}
576. 出界的路径数
题目描述
给定一个 m × n 的网格和一个球。球的起始坐标为 (i,j) ,你可以将球移到相邻的单元格内,或者往上、下、左、右四个方向上移动使球穿过网格边界。但是,你最多可以移动 N 次。找出可以将球移出边界的路径数量。答案可能非常大,返回 结果 mod 109 + 7 的值。
示例 1:
输入: m = 2, n = 2, N = 2, i = 0, j = 0 输出: 6 解释:
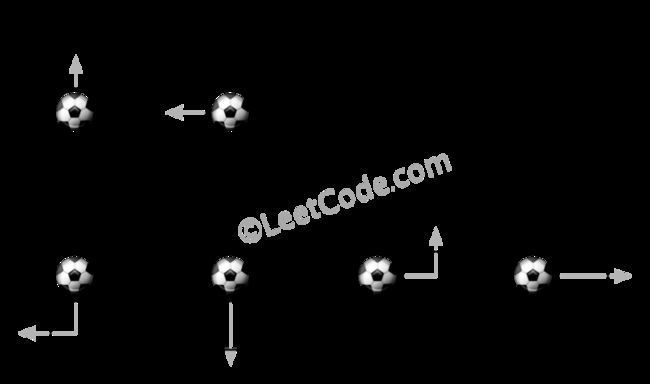
示例 2:
输入: m = 1, n = 3, N = 3, i = 0, j = 1 输出: 12 解释:

说明:
- 球一旦出界,就不能再被移动回网格内。
- 网格的长度和高度在 [1,50] 的范围内。
- N 在 [0,50] 的范围内。
解法
Java
class Solution {
public int findPaths(int m, int n, int N, int i, int j) {
final int MOD = (int) (1e9 + 7);
final int[] dirs = new int[]{-1, 0, 1, 0, -1};
int[][] f = new int[m][n];
f[i][j] = 1;
int res = 0;
for (int step = 0; step < N; ++step) {
int[][] temp = new int[m][n];
for (int x = 0; x < m; ++x) {
for (int y = 0; y < n; ++y) {
for (int k = 0; k < 4; ++k) {
int tx = x + dirs[k], ty = y + dirs[k + 1];
if (tx >= 0 && tx < m && ty >= 0 && ty < n) {
temp[tx][ty] += f[x][y];
temp[tx][ty] %= MOD;
} else {
res += f[x][y];
res %= MOD;
}
}
}
}
f = temp;
}
return res;
}
}
581. 最短无序连续子数组
题目描述
给定一个整数数组,你需要寻找一个连续的子数组,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。
你找到的子数组应是最短的,请输出它的长度。
示例 1:
输入: [2, 6, 4, 8, 10, 9, 15] 输出: 5 解释: 你只需要对 [6, 4, 8, 10, 9] 进行升序排序,那么整个表都会变为升序排序。
说明 :
- 输入的数组长度范围在 [1, 10,000]。
- 输入的数组可能包含重复元素 ,所以升序的意思是<=。
解法
Java
class Solution {
public int findUnsortedSubarray(int[] nums) {
int n = nums.length;
if (n == 1) {
return 0;
}
int[] res = new int[n];
for (int i = 0; i < n; ++i) {
res[i] = nums[i];
}
Arrays.sort(res);
int p = 0;
for (; p < n; ++p) {
if (res[p] != nums[p]) {
break;
}
}
int q = n - 1;
for (; q >= 0; --q) {
if (res[q] != nums[q]) {
break;
}
}
return p == n ? 0 : q - p + 1 ;
}
}
589. N 叉树的前序遍历
题目描述
给定一个 N 叉树,返回其节点值的前序遍历。
例如,给定一个 3叉树 :

返回其前序遍历: [1,3,5,6,2,4]。
说明: 递归法很简单,你可以使用迭代法完成此题吗?
解法
Java
class Solution {
public List<Integer> preorder(Node root) {
List<Integer> res = new ArrayList<>();
if (root == null) {
return res;
}
Deque<Node> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
Node node = stack.pop();
res.add(node.val);
List<Node> children = node.children;
for (int i = children.size() - 1; i >= 0; --i) {
stack.push(children.get(i));
}
}
return res;
}
}
590. N 叉树的后序遍历
题目描述
给定一个 N 叉树,返回其节点值的后序遍历。
例如,给定一个 3叉树 :

返回其后序遍历: [5,6,3,2,4,1].
说明: 递归法很简单,你可以使用迭代法完成此题吗?
解法
Java
class Solution {
public List<Integer> postorder(Node root) {
List<Integer> res = new ArrayList<>();
if (root == null) {
return res;
}
Deque<Node> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
Node node = stack.pop();
res.add(0, node.val);
for (Node child : node.children) {
stack.push(child);
}
}
return res;
}
}
605. 种花问题
题目描述
假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给定一个花坛(表示为一个数组包含0和1,其中0表示没种植花,1表示种植了花),和一个数 n 。能否在不打破种植规则的情况下种入 n 朵花?能则返回True,不能则返回False。
示例 1:
输入: flowerbed = [1,0,0,0,1], n = 1 输出: True
示例 2:
输入: flowerbed = [1,0,0,0,1], n = 2 输出: False
注意:
- 数组内已种好的花不会违反种植规则。
- 输入的数组长度范围为 [1, 20000]。
- n 是非负整数,且不会超过输入数组的大小。
解法
Java
class Solution {
public boolean canPlaceFlowers(int[] flowerbed, int n) {
int len = flowerbed.length;
int cnt = 0;
for (int i = 0; i < len; ++i) {
if (flowerbed[i] == 0 && (i == 0 || flowerbed[i - 1] == 0) && (i == len - 1 || flowerbed[i + 1] == 0)) {
++cnt;
flowerbed[i] = 1;
}
}
return cnt >= n;
}
}
606. 根据二叉树创建字符串
题目描述
你需要采用前序遍历的方式,将一个二叉树转换成一个由括号和整数组成的字符串。
空节点则用一对空括号 "()" 表示。而且你需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
示例 1:
输入: 二叉树: [1,2,3,4]
1
/ \
2 3
/
4
输出: "1(2(4))(3)"
解释: 原本将是“1(2(4)())(3())”,
在你省略所有不必要的空括号对之后,
它将是“1(2(4))(3)”。
示例 2:
输入: 二叉树: [1,2,3,null,4]
1
/ \
2 3
\
4
输出: "1(2()(4))(3)"
解释: 和第一个示例相似,
除了我们不能省略第一个对括号来中断输入和输出之间的一对一映射关系。
解法
Java
class Solution {
public String tree2str(TreeNode t) {
if (t == null) {
return "";
}
if (t.right != null) {
return t.val + "(" + tree2str(t.left) + ")" + "(" + tree2str(t.right) + ")";
}
if (t.left != null) {
return t.val + "(" + tree2str(t.left) + ")";
}
return t.val + "";
}
}
611. 有效三角形的个数
题目描述
给定一个包含非负整数的数组,你的任务是统计其中可以组成三角形三条边的三元组个数。
示例 1:
输入: [2,2,3,4] 输出: 3 解释: 有效的组合是: 2,3,4 (使用第一个 2) 2,3,4 (使用第二个 2) 2,2,3
注意:
- 数组长度不超过1000。
- 数组里整数的范围为 [0, 1000]。
解法
Java
class Solution {
public int triangleNumber(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
int res = 0;
for (int i = n - 1; i >= 2; --i) {
int l = 0, r = i - 1;
while (l < r) {
if (nums[l] + nums[r] > nums[i]) {
res += r - l;
--r;
} else {
++l;
}
}
}
return res;
}
}
617. 合并二叉树
题目描述
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:
输入:
Tree 1 Tree 2
1 2
/ \ / \
3 2 1 3
/ \ \
5 4 7
输出:
合并后的树:
3
/ \
4 5
/ \ \
5 4 7
注意: 合并必须从两个树的根节点开始。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode mergeTrees(TreeNode t1, TreeNode t2) {
if (t1 == null) return t2;
if (t2 == null) return t1;
t1.val = t1.val + t2.val;
t1.left = mergeTrees(t1.left, t2.left);
t1.right = mergeTrees(t1.right, t2.right);
return t1;
}
}
622. 设计循环队列
题目描述
设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
你的实现应该支持如下操作:
MyCircularQueue(k): 构造器,设置队列长度为 k 。Front: 从队首获取元素。如果队列为空,返回 -1 。Rear: 获取队尾元素。如果队列为空,返回 -1 。enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。isEmpty(): 检查循环队列是否为空。isFull(): 检查循环队列是否已满。
示例:
MyCircularQueue circularQueue = new MycircularQueue(3); // 设置长度为 3 circularQueue.enQueue(1); // 返回 true circularQueue.enQueue(2); // 返回 true circularQueue.enQueue(3); // 返回 true circularQueue.enQueue(4); // 返回 false,队列已满 circularQueue.Rear(); // 返回 3 circularQueue.isFull(); // 返回 true circularQueue.deQueue(); // 返回 true circularQueue.enQueue(4); // 返回 true circularQueue.Rear(); // 返回 4
提示:
- 所有的值都在 0 至 1000 的范围内;
- 操作数将在 1 至 1000 的范围内;
- 请不要使用内置的队列库。
解法
Java
class MyCircularQueue {
private Integer[] nums;
private int head;
private int tail;
private int size;
/** Initialize your data structure here. Set the size of the queue to be k. */
public MyCircularQueue(int k) {
this.nums = new Integer[k];
this.head = -1;
this.tail = -1;
this.size = 0;
}
/** Insert an element into the circular queue. Return true if the operation is successful. */
public boolean enQueue(int value) {
if (isFull()) {
return false;
} else if(this.head == this.tail && this.tail == -1){
this.head++;
this.tail++;
nums[this.tail] = value;
} else {
this.tail = (this.tail + 1) % nums.length;
this.nums[this.tail] = value;
}
this.size++;
return true;
}
/** Delete an element from the circular queue. Return true if the operation is successful. */
public boolean deQueue() {
if (isEmpty()) {
return false;
} else if (this.head == this.tail) {
this.head = -1;
this.tail = -1;
} else {
this.head = (this.head + 1) % this.nums.length;
}
this.size--;
return true;
}
/** Get the front item from the queue. */
public int Front() {
if (isEmpty()) {
return -1;
} else {
return this.nums[this.head];
}
}
/** Get the last item from the queue. */
public int Rear() {
if (isEmpty()) {
return -1;
} else {
return this.nums[this.tail];
}
}
/** Checks whether the circular queue is empty or not. */
public boolean isEmpty() {
if (this.size == 0) {
return true;
} else {
return false;
}
}
/** Checks whether the circular queue is full or not. */
public boolean isFull() {
if (this.size == this.nums.length) {
return true;
} else {
return false;
}
}
}
/**
* Your MyCircularQueue object will be instantiated and called as such:
* MyCircularQueue obj = new MyCircularQueue(k);
* boolean param_1 = obj.enQueue(value);
* boolean param_2 = obj.deQueue();
* int param_3 = obj.Front();
* int param_4 = obj.Rear();
* boolean param_5 = obj.isEmpty();
* boolean param_6 = obj.isFull();
*/
633. 平方数之和
题目描述
给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 a2 + b2 = c。
示例1:
输入: 5 输出: True 解释: 1 * 1 + 2 * 2 = 5
示例2:
输入: 3 输出: False
解法
Java
class Solution {
public boolean judgeSquareSum(int c) {
int i = 0, j = (int) Math.sqrt(c);
while (i <= j) {
int s = i * i + j * j;
if (s < c) {
++i;
} else if (s > c) {
--j;
} else {
return true;
}
}
return false;
}
}
637. 二叉树的层平均值
题目描述
给定一个非空二叉树, 返回一个由每层节点平均值组成的数组.
示例 1:
输入:
3
/ \
9 20
/ \
15 7
输出: [3, 14.5, 11]
解释:
第0层的平均值是 3, 第1层是 14.5, 第2层是 11. 因此返回 [3, 14.5, 11].
注意:
- 节点值的范围在32位有符号整数范围内。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<Double> averageOfLevels(TreeNode root) {
if (root == null) return null;
List<Double> res = new ArrayList<>();
LinkedList<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
double sum = 0, size = queue.size();
for (int i = 0; i < size; i ++) {
TreeNode node = queue.poll();
sum += node.val;
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
res.add(sum / size);
}
return res;
}
}
645. 错误的集合
题目描述
集合 S 包含从1到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个元素复制了成了集合里面的另外一个元素的值,导致集合丢失了一个整数并且有一个元素重复。
给定一个数组 nums 代表了集合 S 发生错误后的结果。你的任务是首先寻找到重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
示例 1:
输入: nums = [1,2,2,4] 输出: [2,3]
注意:
- 给定数组的长度范围是 [2, 10000]。
- 给定的数组是无序的。
解法
首先使用 1 到 n 的所有数字做异或运算,然后再与数组中的所有数字异或,得到的值就是缺失数字与重复的数字异或的结果。
接着计算中这个值中其中一个非零的位 pos。然后 pos 位是否为 1,将 nums 数组的元素分成两部分,分别异或;接着将 1~n 的元素也分成两部分,分别异或。得到的两部分结果分别为 a,b,即是缺失数字与重复数字。
最后判断数组中是否存在 a 或 b,若存在 a,说明重复数字是 a,返回 [a,b],否则返回 [b,a]。
Java
class Solution {
public int[] findErrorNums(int[] nums) {
int res = 0;
for (int num : nums) {
res ^= num;
}
for (int i = 1, n = nums.length; i < n + 1; ++i) {
res ^= i;
}
int pos = 0;
while ((res & 1) == 0) {
res >>= 1;
++pos;
}
int a = 0, b = 0;
for (int num : nums) {
if (((num >> pos) & 1) == 0) {
a ^= num;
} else {
b ^= num;
}
}
for (int i = 1, n = nums.length; i < n + 1; ++i) {
if (((i >> pos) & 1) == 0) {
a ^= i;
} else {
b ^= i;
}
}
for (int num : nums) {
if (num == a) {
return new int[]{a, b};
}
}
return new int[]{b, a};
}
}
650. 只有两个键的键盘
题目描述
最初在一个记事本上只有一个字符 'A'。你每次可以对这个记事本进行两种操作:
Copy All(复制全部) : 你可以复制这个记事本中的所有字符(部分的复制是不允许的)。Paste(粘贴) : 你可以粘贴你上一次复制的字符。
给定一个数字 n 。你需要使用最少的操作次数,在记事本中打印出恰好 n 个 'A'。输出能够打印出 n 个 'A' 的最少操作次数。
示例 1:
输入: 3 输出: 3 解释: 最初, 我们只有一个字符 'A'。 第 1 步, 我们使用 Copy All 操作。 第 2 步, 我们使用 Paste 操作来获得 'AA'。 第 3 步, 我们使用 Paste 操作来获得 'AAA'。
说明:
n的取值范围是 [1, 1000] 。
解法
Java
class Solution {
public int minSteps(int n) {
int res = 0;
for (int i = 2; n > 1; ++i) {
while (n % i == 0) {
res += i;
n /= i;
}
}
return res;
}
}
652. 寻找重复的子树
题目描述
给定一棵二叉树,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
两棵树重复是指它们具有相同的结构以及相同的结点值。
示例 1:
1
/ \
2 3
/ / \
4 2 4
/
4
下面是两个重复的子树:
2
/
4
和
4
因此,你需要以列表的形式返回上述重复子树的根结点。
解法
Java
class Solution {
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
List<TreeNode> res = new ArrayList<>();
dfs(root, new HashMap<>(), res);
return res;
}
private String dfs(TreeNode root, Map<String, Integer> map, List<TreeNode> res) {
if (root == null) {
return "";
}
String s = root.val + "_" + dfs(root.left, map, res) + "_" + dfs(root.right, map, res);
map.put(s, map.getOrDefault(s, 0) + 1);
if (map.get(s) == 2) {
res.add(root);
}
return s;
}
}
664. 奇怪的打印机
题目描述
有台奇怪的打印机有以下两个特殊要求:
- 打印机每次只能打印同一个字符序列。
- 每次可以在任意起始和结束位置打印新字符,并且会覆盖掉原来已有的字符。
给定一个只包含小写英文字母的字符串,你的任务是计算这个打印机打印它需要的最少次数。
示例 1:
输入: "aaabbb" 输出: 2 解释: 首先打印 "aaa" 然后打印 "bbb"。
示例 2:
输入: "aba" 输出: 2 解释: 首先打印 "aaa" 然后在第二个位置打印 "b" 覆盖掉原来的字符 'a'。
提示: 输入字符串的长度不会超过 100。
解法
Java
class Solution {
public int strangePrinter(String s) {
if (s.isEmpty()) {
return 0;
}
int n = s.length();
int[][] f = new int[n + 1][n + 1];
for (int i = 0; i < n; ++i) {
f[i][i] = 1;
}
for (int i = n - 2; i >= 0; --i) {
for (int j = i + 1; j < n; ++j) {
f[i][j] = 1 + f[i + 1][j];
for (int k = i + 1; k <= j; ++k) {
if (s.charAt(i) == s.charAt(k)) {
f[i][j] = Math.min(f[i][j], f[i + 1][k] + f[k + 1][j]);
}
}
}
}
return f[0][n - 1];
}
}
669. 修剪二叉搜索树
题目描述
给定一个二叉搜索树,同时给定最小边界L 和最大边界 R。通过修剪二叉搜索树,使得所有节点的值在[L, R]中 (R>=L) 。你可能需要改变树的根节点,所以结果应当返回修剪好的二叉搜索树的新的根节点。
示例 1:
输入:
1
/ \
0 2
L = 1
R = 2
输出:
1
\
2
示例 2:
输入:
3
/ \
0 4
\
2
/
1
L = 1
R = 3
输出:
3
/
2
/
1
解法
Java
class Solution {
public TreeNode trimBST(TreeNode root, int L, int R) {
if (root == null) return null;
if (root.val < L) return trimBST(root.right, L, R);
if (root.val > R) return trimBST(root.left, L, R);
root.left = trimBST(root.left, L, R);
root.right = trimBST(root.right, L, R);
return root;
}
}
671. 二叉树中第二小的节点
题目描述
给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 2 或 0。如果一个节点有两个子节点的话,那么这个节点的值不大于它的子节点的值。
给出这样的一个二叉树,你需要输出所有节点中的第二小的值。如果第二小的值不存在的话,输出 -1 。
示例 1:
输入:
2
/ \
2 5
/ \
5 7
输出: 5
说明: 最小的值是 2 ,第二小的值是 5 。
示例 2:
输入:
2
/ \
2 2
输出: -1
说明: 最小的值是 2, 但是不存在第二小的值。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int findSecondMinimumValue(TreeNode root) {
if (root == null || root.left == null) return -1;
int limit = Integer.MAX_VALUE;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
if (node.val != root.val) {
limit = Math.min(limit, node.val - root.val);
}
if (node.left != null) {
stack.push(node.left);
stack.push(node.right);
}
}
return limit == Integer.MAX_VALUE ? -1 : root.val + limit;
}
}
673. 最长递增子序列的个数
题目描述
给定一个未排序的整数数组,找到最长递增子序列的个数。
示例 1:
输入: [1,3,5,4,7] 输出: 2 解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, 3, 5, 7]。
示例 2:
输入: [2,2,2,2,2] 输出: 5 解释: 最长递增子序列的长度是1,并且存在5个子序列的长度为1,因此输出5。
注意: 给定的数组长度不超过 2000 并且结果一定是32位有符号整数。
解法
Java
class Solution {
public int findNumberOfLIS(int[] nums) {
if (nums == null || nums.length == 0) {
return 0;
}
int n = nums.length;
int[] dp = new int[n];
int[] f = new int[n];
Arrays.fill(dp, 1);
Arrays.fill(f, 1);
int max = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (nums[i] > nums[j]) {
if (dp[j] + 1 > dp[i]) {
dp[i] = dp[j] + 1;
f[i] = f[j];
} else if (dp[j] + 1 == dp[i]) {
f[i] += f[j];
}
}
}
max = Math.max(max, dp[i]);
}
int res = 0;
for (int i = 0; i < n; ++i) {
if (dp[i] == max) {
res += f[i];
}
}
return res;
}
}
674. 最长连续递增序列
题目描述
给定一个未经排序的整数数组,找到最长且连续的的递增序列。
示例 1:
输入: [1,3,5,4,7] 输出: 3 解释: 最长连续递增序列是 [1,3,5], 长度为3。 尽管 [1,3,5,7] 也是升序的子序列, 但它不是连续的,因为5和7在原数组里被4隔开。
示例 2:
输入: [2,2,2,2,2] 输出: 1 解释: 最长连续递增序列是 [2], 长度为1。
注意:数组长度不会超过10000。
解法
设 f(i) 表示将数组第 i 项作为最长连续递增子序列的最后一项时,子序列的长度。
那么,当 nums[i - 1] < nums[i],即 f(i) = f(i - 1) + 1,否则 f(i) = 1。问题转换为求 f(i) (i ∈ [0 ,n - 1]) 的最大值。
由于 f(i) 只与前一项 f(i - 1) 有关联,故不需要用一个数组存储。
Java
class Solution {
public int findLengthOfLCIS(int[] nums) {
int n;
if ((n = nums.length) < 2) return n;
int res = 1, f = 1;
for (int i = 1; i < n; ++i) {
f = 1 + (nums[i - 1] < nums[i] ? f : 0);
res = Math.max(res, f);
}
return res;
}
}
679. 24 点游戏
题目描述
你有 4 张写有 1 到 9 数字的牌。你需要判断是否能通过 *,/,+,-,(,) 的运算得到 24。
示例 1:
输入: [4, 1, 8, 7] 输出: True 解释: (8-4) * (7-1) = 24
示例 2:
输入: [1, 2, 1, 2] 输出: False
注意:
- 除法运算符
/表示实数除法,而不是整数除法。例如 4 / (1 - 2/3) = 12 。 - 每个运算符对两个数进行运算。特别是我们不能用
-作为一元运算符。例如,[1, 1, 1, 1]作为输入时,表达式-1 - 1 - 1 - 1是不允许的。 - 你不能将数字连接在一起。例如,输入为
[1, 2, 1, 2]时,不能写成 12 + 12 。
解法
Java
class Solution {
public boolean judgePoint24(int[] nums) {
return dfs(Arrays.stream(nums).boxed().map(Double::new).collect(Collectors.toList()));
}
private boolean dfs(List<Double> numList) {
if (numList.size() == 0) {
return false;
}
if (numList.size() == 1) {
return Math.abs(Math.abs(numList.get(0) - 24.0)) < 0.000001d;
}
for (int i = 0; i < numList.size(); i++) {
for (int j = i + 1; j < numList.size(); j++) {
boolean valid = dfs(getList(numList, i, j, 0)) || dfs(getList(numList, i, j, 1))
|| dfs(getList(numList, i, j, 2)) || dfs(getList(numList, i, j, 3))
|| dfs(getList(numList, i, j, 4)) || dfs(getList(numList, i, j, 5));
if (valid) {
return true;
}
}
}
return false;
}
private List<Double> getList(List<Double> numList, int i, int j, int operate) {
List<Double> candidate = new ArrayList<>();
for (int k = 0; k < numList.size(); k++) {
if (k == i || k == j) {
continue;
}
candidate.add(numList.get(k));
}
switch (operate) {
// a + b
case 0:
candidate.add(numList.get(i) + numList.get(j));
break;
// a - b
case 1:
candidate.add(numList.get(i) - numList.get(j));
break;
// b - a
case 2:
candidate.add(numList.get(j) - numList.get(i));
break;
// a * b
case 3:
candidate.add(numList.get(i) * numList.get(j));
break;
// a / b
case 4:
if (numList.get(j) == 0) {
return Collections.emptyList();
}
candidate.add(numList.get(i) / numList.get(j));
break;
// b / a
case 5:
if (numList.get(i) == 0) {
return Collections.emptyList();
}
candidate.add(numList.get(j) / numList.get(i));
break;
}
return candidate;
}
}
682. 棒球比赛
题目描述
你现在是棒球比赛记录员。
给定一个字符串列表,每个字符串可以是以下四种类型之一:
1.整数(一轮的得分):直接表示您在本轮中获得的积分数。
2. "+"(一轮的得分):表示本轮获得的得分是前两轮有效 回合得分的总和。
3. "D"(一轮的得分):表示本轮获得的得分是前一轮有效 回合得分的两倍。
4. "C"(一个操作,这不是一个回合的分数):表示您获得的最后一个有效 回合的分数是无效的,应该被移除。
每一轮的操作都是永久性的,可能会对前一轮和后一轮产生影响。
你需要返回你在所有回合中得分的总和。
示例 1:
输入: ["5","2","C","D","+"] 输出: 30 解释: 第1轮:你可以得到5分。总和是:5。 第2轮:你可以得到2分。总和是:7。 操作1:第2轮的数据无效。总和是:5。 第3轮:你可以得到10分(第2轮的数据已被删除)。总数是:15。 第4轮:你可以得到5 + 10 = 15分。总数是:30。
示例 2:
输入: ["5","-2","4","C","D","9","+","+"] 输出: 27 解释: 第1轮:你可以得到5分。总和是:5。 第2轮:你可以得到-2分。总数是:3。 第3轮:你可以得到4分。总和是:7。 操作1:第3轮的数据无效。总数是:3。 第4轮:你可以得到-4分(第三轮的数据已被删除)。总和是:-1。 第5轮:你可以得到9分。总数是:8。 第6轮:你可以得到-4 + 9 = 5分。总数是13。 第7轮:你可以得到9 + 5 = 14分。总数是27。
注意:
- 输入列表的大小将介于1和1000之间。
- 列表中的每个整数都将介于-30000和30000之间。
解法
栈实现。
Java
class Solution {
public int calPoints(String[] ops) {
Deque<Integer> stack = new ArrayDeque<>();
for (String op : ops) {
if ("C".equals(op)) {
stack.pop();
} else if ("D".equals(op)) {
stack.push(stack.peek() << 1);
} else if ("+".equals(op)) {
Integer a = stack.pop();
Integer b = stack.peek();
stack.push(a);
stack.push(a + b);
} else {
stack.push(Integer.valueOf(op));
}
}
int res = 0;
for (Integer score : stack) {
res += score;
}
return res;
}
}
684. 冗余连接
题目描述
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
示例 1:
输入: [[1,2], [1,3], [2,3]] 输出: [2,3] 解释: 给定的无向图为: 1 / \ 2 - 3
示例 2:
输入: [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
解释: 给定的无向图为:
5 - 1 - 2
| |
4 - 3
注意:
- 输入的二维数组大小在 3 到 1000。
- 二维数组中的整数在1到N之间,其中N是输入数组的大小。
更新(2017-09-26):
我们已经重新检查了问题描述及测试用例,明确图是无向 图。对于有向图详见冗余连接II。对于造成任何不便,我们深感歉意。
解法
Java
class Solution {
public int[] findRedundantConnection(int[][] edges) {
int n = edges.length;
int[] f = new int[n + 1];
for (int i = 1; i <= n; ++i) {
f[i] = i;
}
for (int[] edge : edges) {
int p = find(edge[0], f);
int q = find(edge[1], f);
if (p == q) {
return edge;
}
f[p] = q;
}
return null;
}
private int find(int x, int[] f) {
if (f[x] != x) {
f[x] = find(f[x], f);
}
return f[x];
}
}
687. 最长同值路径
题目描述
给定一个二叉树,找到最长的路径,这个路径中的每个节点具有相同值。 这条路径可以经过也可以不经过根节点。
注意:两个节点之间的路径长度由它们之间的边数表示。
示例 1:
输入:
5
/ \
4 5
/ \ \
1 1 5
输出:
2
示例 2:
输入:
1
/ \
4 5
/ \ \
4 4 5
输出:
2
注意: 给定的二叉树不超过10000个结点。 树的高度不超过1000。
解法
Java
class Solution {
public int longestUnivaluePath(TreeNode root) {
int[] res = new int[1];
dfs(root, res);
return res[0];
}
private int dfs(TreeNode root, int[] res) {
if (root == null) {
return 0;
}
int left = dfs(root.left, res);
int right = dfs(root.right, res);
left = root.left != null && root.left.val == root.val ? left + 1 : 0;
right = root.right != null && root.right.val == root.val ? right + 1 : 0;
res[0] = Math.max(res[0], left + right);
return Math.max(left, right);
}
}
690. 员工的重要性
题目描述
给定一个保存员工信息的数据结构,它包含了员工唯一的id,重要度 和 直系下属的id。
比如,员工1是员工2的领导,员工2是员工3的领导。他们相应的重要度为15, 10, 5。那么员工1的数据结构是[1, 15, [2]],员工2的数据结构是[2, 10, [3]],员工3的数据结构是[3, 5, []]。注意虽然员工3也是员工1的一个下属,但是由于并不是直系下属,因此没有体现在员工1的数据结构中。
现在输入一个公司的所有员工信息,以及单个员工id,返回这个员工和他所有下属的重要度之和。
示例 1:
输入: [[1, 5, [2, 3]], [2, 3, []], [3, 3, []]], 1 输出: 11 解释: 员工1自身的重要度是5,他有两个直系下属2和3,而且2和3的重要度均为3。因此员工1的总重要度是 5 + 3 + 3 = 11。
注意:
- 一个员工最多有一个直系领导,但是可以有多个直系下属
- 员工数量不超过2000。
解法
Java
/*
// Employee info
class Employee {
// It's the unique id of each node;
// unique id of this employee
public int id;
// the importance value of this employee
public int importance;
// the id of direct subordinates
public List subordinates;
};
*/
import java.util.*;
class Solution {
public int getImportance(List<Employee> employees, int id) {
Map<Integer, Employee> map = new HashMap<>();
for (Employee employee : employees) {
map.put(employee.id, employee);
}
return dfs(map, id);
}
private int dfs(Map<Integer, Employee> map, int id) {
Employee employee = map.get(id);
int ans = employee.importance;
for (Integer subordinate : employee.subordinates) {
ans += dfs(map, subordinate);
}
return ans;
}
}
695. 岛屿的最大面积
题目描述
给定一个包含了一些 0 和 1 的非空二维数组 grid 。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)
示例 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,1,1,0,1,0,0,0,0,0,0,0,0], [0,1,0,0,1,1,0,0,1,0,1,0,0], [0,1,0,0,1,1,0,0,1,1,1,0,0], [0,0,0,0,0,0,0,0,0,0,1,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,0,0,0,0,0,0,1,1,0,0,0,0]]
对于上面这个给定矩阵应返回 6。注意答案不应该是 11 ,因为岛屿只能包含水平或垂直的四个方向的 1 。
示例 2:
[[0,0,0,0,0,0,0,0]]
对于上面这个给定的矩阵, 返回 0。
注意: 给定的矩阵grid 的长度和宽度都不超过 50。
解法
Java
class Solution {
public int maxAreaOfIsland(int[][] grid) {
int res = 0;
int m = grid.length;
int n = grid[0].length;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
res = Math.max(res, dfs(grid, i, j, m, n));
}
}
return res;
}
private int dfs(int[][] grid, int i, int j, int m, int n) {
if (i < 0 || j < 0 || i >= m || j >= n || grid[i][j] == 0) {
return 0;
}
grid[i][j] = 0;
return 1
+ dfs(grid, i - 1, j, m, n)
+ dfs(grid, i + 1, j, m, n)
+ dfs(grid, i, j - 1, m, n)
+ dfs(grid, i, j + 1, m, n);
}
}
696. 计数二进制子串
题目描述
给定一个字符串 s,计算具有相同数量0和1的非空(连续)子字符串的数量,并且这些子字符串中的所有0和所有1都是组合在一起的。
重复出现的子串要计算它们出现的次数。
示例 1 :
输入: "00110011" 输出: 6 解释: 有6个子串具有相同数量的连续1和0:“0011”,“01”,“1100”,“10”,“0011” 和 “01”。 请注意,一些重复出现的子串要计算它们出现的次数。 另外,“00110011”不是有效的子串,因为所有的0(和1)没有组合在一起。
示例 2 :
输入: "10101" 输出: 4 解释: 有4个子串:“10”,“01”,“10”,“01”,它们具有相同数量的连续1和0。
注意:
s.length在1到50,000之间。s只包含“0”或“1”字符。
解法
Java
class Solution {
public int countBinarySubstrings(String s) {
int[] group = new int[s.length()];
int k = 0;
Arrays.fill(group , 0);
group[0] = 1;
for(int i = 1;i < s.length();i++) {
if(s.charAt(i) == s.charAt(i-1))
group[k]++;
else
group[++k] = 1;
}
int ans = 0;
for(int i = 1;i < s.length() && group[i] != 0;i++) {
ans += Math.min(group[i-1], group[i]);
}
return ans;
}
}
697. 数组的度
题目描述
给定一个非空且只包含非负数的整数数组 nums, 数组的度的定义是指数组里任一元素出现频数的最大值。
你的任务是找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。
示例 1:
输入: [1, 2, 2, 3, 1] 输出: 2 解释: 输入数组的度是2,因为元素1和2的出现频数最大,均为2. 连续子数组里面拥有相同度的有如下所示: [1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2] 最短连续子数组[2, 2]的长度为2,所以返回2.
示例 2:
输入: [1,2,2,3,1,4,2] 输出: 6
注意:
nums.length在1到50,000区间范围内。nums[i]是一个在0到49,999范围内的整数。
解法
遍历数组,用哈希表记录数组每个元素出现的次数,以及首次、末次出现的位置。然后遍历哈希表,获取元素出现次数最多(可能有多个)且首末位置差最小的数。
Java
class Solution {
public int findShortestSubArray(int[] nums) {
Map<Integer, int[]> mapper = new HashMap<>();
for (int i = 0, n = nums.length; i < n; ++i) {
if (mapper.containsKey(nums[i])) {
int[] arr = mapper.get(nums[i]);
++arr[0];
arr[2] = i;
} else {
int[] arr = new int[]{1, i, i};
mapper.put(nums[i], arr);
}
}
int maxDegree = 0, minLen = 0;
for (Map.Entry<Integer, int[]> entry : mapper.entrySet()) {
int[] arr = entry.getValue();
if (maxDegree < arr[0]) {
maxDegree = arr[0];
minLen = arr[2] - arr[1] + 1;
} else if (maxDegree == arr[0]) {
minLen = Math.min(minLen, arr[2] - arr[1] + 1);
}
}
return minLen;
}
}
700. 二叉搜索树中的搜索
题目描述
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
例如,
给定二叉搜索树:
4
/ \
2 7
/ \
1 3
和值: 2
你应该返回如下子树:
2
/ \
1 3
在上述示例中,如果要找的值是 5,但因为没有节点值为 5,我们应该返回 NULL。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
if (root == null) return null;
if (root.val == val) return root;
if (root.val < val) return searchBST(root.right, val);
else return searchBST(root.left, val);
}
}
701. 二叉搜索树中的插入操作
题目描述
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 保证原始二叉搜索树中不存在新值。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回任意有效的结果。
例如,
给定二叉搜索树:
4
/ \
2 7
/ \
1 3
和 插入的值: 5
你可以返回这个二叉搜索树:
4
/ \
2 7
/ \ /
1 3 5
或者这个树也是有效的:
5
/ \
2 7
/ \
1 3
\
4
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if(root == null){
root = new TreeNode(val);
}
if(val < root.val){
root.left = insertIntoBST(root.left, val);
}
else if(val > root.val){
root.right = insertIntoBST(root.right, val);
}
// return the unchanged pointer
return root;
}
}
703. 数据流中的第 K 大元素
题目描述
设计一个找到数据流中第K大元素的类(class)。注意是排序后的第K大元素,不是第K个不同的元素。
你的 KthLargest 类需要一个同时接收整数 k 和整数数组nums 的构造器,它包含数据流中的初始元素。每次调用 KthLargest.add,返回当前数据流中第K大的元素。
示例:
int k = 3; int[] arr = [4,5,8,2]; KthLargest kthLargest = new KthLargest(3, arr); kthLargest.add(3); // returns 4 kthLargest.add(5); // returns 5 kthLargest.add(10); // returns 5 kthLargest.add(9); // returns 8 kthLargest.add(4); // returns 8
说明:
你可以假设 nums 的长度≥ k-1 且k ≥ 1。
解法
Java
class KthLargest {
private PriorityQueue<Integer> minHeap;
private int size;
public KthLargest(int k, int[] nums) {
minHeap = new PriorityQueue<>(k);
size = k;
for (int e : nums) {
add(e);
}
}
public int add(int val) {
if (minHeap.size() < size) {
minHeap.add(val);
} else {
if (minHeap.peek() < val) {
minHeap.poll();
minHeap.add(val);
}
}
return minHeap.peek();
}
}
/**
* Your KthLargest object will be instantiated and called as such: KthLargest
* obj = new KthLargest(k, nums); int param_1 = obj.add(val);
*/
704. 二分查找
题目描述
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入:nums= [-1,0,3,5,9,12],target= 9 输出: 4 解释: 9 出现在nums中并且下标为 4
示例 2:
输入:nums= [-1,0,3,5,9,12],target= 2 输出: -1 解释: 2 不存在nums中因此返回 -1
提示:
- 你可以假设
nums中的所有元素是不重复的。 n将在[1, 10000]之间。nums的每个元素都将在[-9999, 9999]之间。
解法
Java
class Solution {
public int search(int[] nums, int target) {
int l = 0, r = nums.length - 1;
while (l <= r) {
int mid = l + r >>> 1;
if (nums[mid] < target) {
l = mid + 1;
} else if (nums[mid] > target) {
r = mid - 1;
} else {
return mid;
}
}
return -1;
}
}
707. 设计链表
题目描述
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
- get(index):获取链表中第
index个节点的值。如果索引无效,则返回-1。 - addAtHead(val):在链表的第一个元素之前添加一个值为
val的节点。插入后,新节点将成为链表的第一个节点。 - addAtTail(val):将值为
val的节点追加到链表的最后一个元素。 - addAtIndex(index,val):在链表中的第
index个节点之前添加值为val的节点。如果index等于链表的长度,则该节点将附加到链表的末尾。如果index大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。 - deleteAtIndex(index):如果索引
index有效,则删除链表中的第index个节点。
示例:
MyLinkedList linkedList = new MyLinkedList(); linkedList.addAtHead(1); linkedList.addAtTail(3); linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3 linkedList.get(1); //返回2 linkedList.deleteAtIndex(1); //现在链表是1-> 3 linkedList.get(1); //返回3
提示:
- 所有
val值都在[1, 1000]之内。 - 操作次数将在
[1, 1000]之内。 - 请不要使用内置的 LinkedList 库。
解法
定义虚拟头结点 dummy,count 记录当前链表结点个数。
Java
class MyLinkedList {
private class ListNode {
int val;
ListNode next;
ListNode(int val) {
this(val, null);
}
ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
}
private ListNode dummy;
private int count;
/** Initialize your data structure here. */
public MyLinkedList() {
dummy = new ListNode(0);
count = 0;
}
/** Get the value of the index-th node in the linked list. If the index is invalid, return -1. */
public int get(int index) {
if (index < 0 || index >= count) {
return -1;
}
ListNode cur = dummy.next;
while (index-- > 0) {
cur = cur.next;
}
return cur.val;
}
/** Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list. */
public void addAtHead(int val) {
addAtIndex(0, val);
}
/** Append a node of value val to the last element of the linked list. */
public void addAtTail(int val) {
addAtIndex(count, val);
}
/** Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted. */
public void addAtIndex(int index, int val) {
if (index > count) {
return;
}
ListNode pre = dummy;
while (index-- > 0) {
pre = pre.next;
}
pre.next = new ListNode(val, pre.next);
++count;
}
/** Delete the index-th node in the linked list, if the index is valid. */
public void deleteAtIndex(int index) {
if (index < 0 || index >= count) {
return;
}
ListNode pre = dummy;
while (index-- > 0) {
pre = pre.next;
}
ListNode t = pre.next;
pre.next = t.next;
t.next = null;
--count;
}
}
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList obj = new MyLinkedList();
* int param_1 = obj.get(index);
* obj.addAtHead(val);
* obj.addAtTail(val);
* obj.addAtIndex(index,val);
* obj.deleteAtIndex(index);
*/
718. 最长重复子数组
题目描述
给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
示例 1:
输入: A: [1,2,3,2,1] B: [3,2,1,4,7] 输出: 3 解释: 长度最长的公共子数组是 [3, 2, 1]。
说明:
- 1 <= len(A), len(B) <= 1000
- 0 <= A[i], B[i] < 100
解法
Java
class Solution {
public int findLength(int[] A, int[] B) {
int ans = 0;
int[][] dp = new int[A.length + 1][B.length + 1];
for (int i = 1;i <= A.length;i++) {
for (int j = 1;j <= B.length;j++) {
if (A[i - 1] == B[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
ans = Math.max(ans, dp[i][j]);
} else {
dp[i][j] = 0;
}
}
}
return ans;
}
}
724. 寻找数组的中心索引
题目描述
给定一个整数类型的数组 nums,请编写一个能够返回数组“中心索引”的方法。
我们是这样定义数组中心索引的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
示例 1:
输入: nums = [1, 7, 3, 6, 5, 6] 输出: 3 解释: 索引3 (nums[3] = 6) 的左侧数之和(1 + 7 + 3 = 11),与右侧数之和(5 + 6 = 11)相等。 同时, 3 也是第一个符合要求的中心索引。
示例 2:
输入: nums = [1, 2, 3] 输出: -1 解释: 数组中不存在满足此条件的中心索引。
说明:
nums的长度范围为[0, 10000]。- 任何一个
nums[i]将会是一个范围在[-1000, 1000]的整数。
解法
Java
class Solution {
public int pivotIndex(int[] nums) {
int sum = Arrays.stream(nums).sum();
int s = 0;
for (int i = 0; i < nums.length; ++i) {
if (s << 1 == sum - nums[i]) {
return i;
}
s += nums[i];
}
return -1;
}
}
725. 分隔链表
题目描述
给定一个头结点为 root 的链表, 编写一个函数以将链表分隔为 k 个连续的部分。
每部分的长度应该尽可能的相等: 任意两部分的长度差距不能超过 1,也就是说可能有些部分为 null。
这k个部分应该按照在链表中出现的顺序进行输出,并且排在前面的部分的长度应该大于或等于后面的长度。
返回一个符合上述规则的链表的列表。
举例: 1->2->3->4, k = 5 // 5 结果 [ [1], [2], [3], [4], null ]
示例 1:
输入: root = [1, 2, 3], k = 5 输出: [[1],[2],[3],[],[]] 解释: 输入输出各部分都应该是链表,而不是数组。 例如, 输入的结点 root 的 val= 1, root.next.val = 2, \root.next.next.val = 3, 且 root.next.next.next = null。 第一个输出 output[0] 是 output[0].val = 1, output[0].next = null。 最后一个元素 output[4] 为 null, 它代表了最后一个部分为空链表。
示例 2:
输入: root = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], k = 3 输出: [[1, 2, 3, 4], [5, 6, 7], [8, 9, 10]] 解释: 输入被分成了几个连续的部分,并且每部分的长度相差不超过1.前面部分的长度大于等于后面部分的长度。
提示:
root的长度范围:[0, 1000].- 输入的每个节点的大小范围:
[0, 999]. k的取值范围:[1, 50].
解法
Java
class Solution {
public ListNode[] splitListToParts(ListNode root, int k) {
ListNode[] res = new ListNode[k];
int n = getLength(root);
int len = n / k, left = n % k;
ListNode pre = null; // 记录链尾
for (int i = 0; i < k && root != null; ++i) {
res[i] = root;
int step = len;
if (left > 0) {
--left;
++step;
}
for (int j = 0; j < step; ++j) {
pre = root;
root = root.next;
}
pre.next = null; // 断链
}
return res;
}
private int getLength(ListNode root) {
int res = 0;
while (root != null) {
++res;
root = root.next;
}
return res;
}
}
739. 每日温度
题目描述
根据每日 气温 列表,请重新生成一个列表,对应位置的输入是你需要再等待多久温度才会升高超过该日的天数。如果之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
解法
栈实现,栈存放 T 中元素的的下标 i,结果用数组 res 存储。
遍历 T,遍历到 T[i] 时:
- 若栈不为空,并且栈顶元素小于
T[i]时,弹出栈顶元素 j,并且res[j]赋值为i - j。 - 然后将 i 压入栈中。
最后返回结果数组 res 即可。
Java
class Solution {
public int[] dailyTemperatures(int[] T) {
int n = T.length;
int[] res = new int[n];
Deque<Integer> s = new ArrayDeque<>();
for (int i = 0; i < n; ++i) {
while (!s.isEmpty() && T[s.peek()] < T[i]) {
int j = s.pop();
res[j] = i - j;
}
s.push(i);
}
return res;
}
}
740. 删除与获得点数
题目描述
给定一个整数数组 nums ,你可以对它进行一些操作。
每次操作中,选择任意一个 nums[i] ,删除它并获得 nums[i] 的点数。之后,你必须删除每个等于 nums[i] - 1 或 nums[i] + 1 的元素。
开始你拥有 0 个点数。返回你能通过这些操作获得的最大点数。
示例 1:
输入: nums = [3, 4, 2] 输出: 6 解释: 删除 4 来获得 4 个点数,因此 3 也被删除。 之后,删除 2 来获得 2 个点数。总共获得 6 个点数。
示例 2:
输入: nums = [2, 2, 3, 3, 3, 4] 输出: 9 解释: 删除 3 来获得 3 个点数,接着要删除两个 2 和 4 。 之后,再次删除 3 获得 3 个点数,再次删除 3 获得 3 个点数。 总共获得 9 个点数。
注意:
nums的长度最大为20000。- 每个整数
nums[i]的大小都在[1, 10000]范围内。
解法
核心思路: 一个数字要么不选,要么全选
首先计算出每个数字的总和 sums,并维护两个 dp 数组:select 和 nonSelect
- sums[i] 代表值为 i 的元素总和
- select[i] 代表如果选数字 i,从 0 处理到 i 的最大和
- nonSelect[i] 代表如果不选数字 i,从 0 处理到 i 的最大和
那么我们有以下逻辑: - 如果选 i,那么 i-1 肯定不能选;
- 如果不选 i,那么 i-1 选不选都可以,因此我们选择其中较大的选法
select[i] = nonSelect[i-1] + sums[i];
nonSelect[i] = Math.max(select[i-1], nonSelect[i-1]);
Java
class Solution {
public int deleteAndEarn(int[] nums) {
if (nums.length == 0) {
return 0;
}
int[] sums = new int[10010];
int[] select = new int[10010];
int[] nonSelect = new int[10010];
int maxV = 0;
for (int x : nums) {
sums[x] += x;
maxV = Math.max(maxV, x);
}
for (int i = 1; i <= maxV; i++) {
select[i] = nonSelect[i - 1] + sums[i];
nonSelect[i] = Math.max(select[i - 1], nonSelect[i - 1]);
}
return Math.max(select[maxV], nonSelect[maxV]);
}
}
746. 使用最小花费爬楼梯
题目描述
数组的每个索引做为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost[i](索引从0开始)。
每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯。
您需要找到达到楼层顶部的最低花费。在开始时,你可以选择从索引为 0 或 1 的元素作为初始阶梯。
示例 1:
输入: cost = [10, 15, 20] 输出: 15 解释: 最低花费是从cost[1]开始,然后走两步即可到阶梯顶,一共花费15。
示例 2:
输入: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] 输出: 6 解释: 最低花费方式是从cost[0]开始,逐个经过那些1,跳过cost[3],一共花费6。
注意:
cost的长度将会在[2, 1000]。- 每一个
cost[i]将会是一个Integer类型,范围为[0, 999]。
解法
Java
class Solution {
public int minCostClimbingStairs(int[] cost) {
int pre = 0, cur = 0;
for (int i = 1, n = cost.length; i < n; ++i) {
int t = Math.min(cost[i] + cur, cost[i - 1] + pre);
pre = cur;
cur = t;
}
return cur;
}
}
752. 打开转盘锁
题目描述
你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' 。每个拨轮可以自由旋转:例如把 '9' 变为 '0','0' 变为 '9' 。每次旋转都只能旋转一个拨轮的一位数字。
锁的初始数字为 '0000' ,一个代表四个拨轮的数字的字符串。
列表 deadends 包含了一组死亡数字,一旦拨轮的数字和列表里的任何一个元素相同,这个锁将会被永久锁定,无法再被旋转。
字符串 target 代表可以解锁的数字,你需要给出最小的旋转次数,如果无论如何不能解锁,返回 -1。
示例 1:
输入:deadends = ["0201","0101","0102","1212","2002"], target = "0202" 输出:6 解释: 可能的移动序列为 "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202"。 注意 "0000" -> "0001" -> "0002" -> "0102" -> "0202" 这样的序列是不能解锁的, 因为当拨动到 "0102" 时这个锁就会被锁定。
示例 2:
输入: deadends = ["8888"], target = "0009" 输出:1 解释: 把最后一位反向旋转一次即可 "0000" -> "0009"。
示例 3:
输入: deadends = ["8887","8889","8878","8898","8788","8988","7888","9888"], target = "8888" 输出:-1 解释: 无法旋转到目标数字且不被锁定。
示例 4:
输入: deadends = ["0000"], target = "8888" 输出:-1
提示:
- 死亡列表
deadends的长度范围为[1, 500]。 - 目标数字
target不会在deadends之中。 - 每个
deadends和target中的字符串的数字会在 10,000 个可能的情况'0000'到'9999'中产生。
解法
Java
class Solution {
public int openLock(String[] deadends, String target) {
Set<String> begins = new HashSet<>();
Set<String> deads = new HashSet<>(Arrays.asList(deadends));
int step = 0;
begins.add("0000");
if (begins.contains(target)) {
return step;
}
while (!begins.isEmpty()) {
if (begins.contains(target)) {
return step;
}
Set<String> temp = new HashSet<>();
for (String cur : begins) {
if (deads.contains(cur)) {
continue;
}
deads.add(cur);
StringBuffer s = new StringBuffer(cur);
for (int i = 0; i < 4; i++) {
char c = s.charAt(i);
String s1 = s.substring(0, i) + (char)(c == '9' ? '0' : c + 1) + s.substring(i + 1, 4);
String s2 = s.substring(0, i) + (char)(c == '0' ? '9' : c - 1) + s.substring(i + 1, 4);
if (!deads.contains(s1)) {
temp.add(s1);
}
if (!deads.contains(s2)) {
temp.add(s2);
}
}
}
step ++;
begins = temp;
}
return -1;
}
}
760. 找出变位映射
题目描述
给定两个列表 Aand B,并且 B 是 A 的变位(即 B 是由 A 中的元素随机排列后组成的新列表)。
我们希望找出一个从 A 到 B 的索引映射 P 。一个映射 P[i] = j 指的是列表 A 中的第 i 个元素出现于列表 B 中的第 j 个元素上。
列表 A 和 B 可能出现重复元素。如果有多于一种答案,输出任意一种。
例如,给定
A = [12, 28, 46, 32, 50] B = [50, 12, 32, 46, 28]
需要返回
[1, 4, 3, 2, 0]
P[0] = 1 ,因为 A 中的第 0 个元素出现于 B[1],而且 P[1] = 4 因为 A 中第 1 个元素出现于 B[4],以此类推。
注:
A, B有相同的长度,范围为[1, 100]。A[i], B[i]都是范围在[0, 10^5]的整数。
解法
Java
import java.util.*;
class Solution {
public int[] anagramMappings(int[] A, int[] B) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < B.length; i++) {
map.put(B[i], i);
}
int[] res = new int[B.length];
int j = 0;
for (int k : A) {
res[j++] = map.get(k);
}
return res;
}
}
766. 托普利茨矩阵
题目描述
如果一个矩阵的每一方向由左上到右下的对角线上具有相同元素,那么这个矩阵是托普利茨矩阵。
给定一个 M x N 的矩阵,当且仅当它是托普利茨矩阵时返回 True。
示例 1:
输入: matrix = [ [1,2,3,4], [5,1,2,3], [9,5,1,2] ] 输出: True 解释: 在上述矩阵中, 其对角线为: "[9]", "[5, 5]", "[1, 1, 1]", "[2, 2, 2]", "[3, 3]", "[4]"。 各条对角线上的所有元素均相同, 因此答案是True。
示例 2:
输入: matrix = [ [1,2], [2,2] ] 输出: False 解释: 对角线"[1, 2]"上的元素不同。
说明:
-
matrix是一个包含整数的二维数组。 matrix的行数和列数均在[1, 20]范围内。matrix[i][j]包含的整数在[0, 99]范围内。
进阶:
- 如果矩阵存储在磁盘上,并且磁盘内存是有限的,因此一次最多只能将一行矩阵加载到内存中,该怎么办?
- 如果矩阵太大以至于只能一次将部分行加载到内存中,该怎么办?
解法
遍历矩阵,若出现元素与其左上角的元素不等的情况,返回 false。
Java
class Solution {
public boolean isToeplitzMatrix(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
for (int i = 1; i < m; ++i) {
for (int j = 1; j < n; ++j) {
if (matrix[i][j] != matrix[i - 1][j - 1]) {
return false;
}
}
}
return true;
}
}
771. 宝石与石头
题目描述
给定字符串J 代表石头中宝石的类型,和字符串 S代表你拥有的石头。 S 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
J 中的字母不重复,J 和 S中的所有字符都是字母。字母区分大小写,因此"a"和"A"是不同类型的石头。
示例 1:
输入: J = "aA", S = "aAAbbbb" 输出: 3
示例 2:
输入: J = "z", S = "ZZ" 输出: 0
注意:
S和J最多含有50个字母。-
J中的字符不重复。
解法
Java
class Solution {
public int numJewelsInStones(String J, String S) {
Set<Character> set = new HashSet<>();
for (char ch : J.toCharArray()) {
set.add(ch);
}
int res = 0;
for (char ch : S.toCharArray()) {
res += (set.contains(ch) ? 1 : 0);
}
return res;
}
}
777. 在 LR 字符串中交换相邻字符
题目描述
在一个由 'L' , 'R' 和 'X' 三个字符组成的字符串(例如"RXXLRXRXL")中进行移动操作。一次移动操作指用一个"LX"替换一个"XL",或者用一个"XR"替换一个"RX"。现给定起始字符串start和结束字符串end,请编写代码,当且仅当存在一系列移动操作使得start可以转换成end时, 返回True。
示例 :
输入: start = "RXXLRXRXL", end = "XRLXXRRLX" 输出: True 解释: 我们可以通过以下几步将start转换成end: RXXLRXRXL -> XRXLRXRXL -> XRLXRXRXL -> XRLXXRRXL -> XRLXXRRLX
注意:
1 <= len(start) = len(end) <= 10000。start和end中的字符串仅限于'L','R'和'X'。
解法
Java
class Solution {
public boolean canTransform(String start, String end) {
if (start.length() != end.length()) {
return false;
}
int i = 0, j = 0;
while (true) {
while (i < start.length() && start.charAt(i) == 'X') {
++i;
}
while (j < end.length() && end.charAt(j) == 'X') {
++j;
}
if (i == start.length() && j == start.length()) {
return true;
}
if (i == start.length() || j == start.length() || start.charAt(i) != end.charAt(j)) {
return false;
}
if (start.charAt(i) == 'L' && i < j || start.charAt(i) == 'R' && i > j) {
return false;
}
++i;
++j;
}
}
}
783. 二叉搜索树结点最小距离
题目描述
给定一个二叉搜索树的根结点 root,返回树中任意两节点的差的最小值。
示例:
输入: root = [4,2,6,1,3,null,null]
输出: 1
解释:
注意,root是树结点对象(TreeNode object),而不是数组。
给定的树 [4,2,6,1,3,null,null] 可表示为下图:
4
/ \
2 6
/ \
1 3
最小的差值是 1, 它是节点1和节点2的差值, 也是节点3和节点2的差值。
注意:
- 二叉树的大小范围在
2到100。 - 二叉树总是有效的,每个节点的值都是整数,且不重复。
- 本题与 530:https://leetcode-cn.com/problems/minimum-absolute-difference-in-bst/ 相同
解法
Java
class Solution {
public int minDiffInBST(TreeNode root) {
TreeNode[] pre = new TreeNode[1];
int[] res = new int[]{Integer.MAX_VALUE};
dfs(root, pre, res);
return res[0];
}
private void dfs(TreeNode root, TreeNode[] pre, int[] res) {
if (root == null) {
return;
}
dfs(root.left, pre, res);
if (pre[0] != null) {
res[0] = Math.min(res[0], root.val - pre[0].val);
}
pre[0] = root;
dfs(root.right, pre, res);
}
}
784. 字母大小写全排列
题目描述
给定一个字符串S,通过将字符串S中的每个字母转变大小写,我们可以获得一个新的字符串。返回所有可能得到的字符串集合。
示例: 输入: S = "a1b2" 输出: ["a1b2", "a1B2", "A1b2", "A1B2"] 输入: S = "3z4" 输出: ["3z4", "3Z4"] 输入: S = "12345" 输出: ["12345"]
注意:
S的长度不超过12。S仅由数字和字母组成。
解法
Java
class Solution {
public List<String> letterCasePermutation(String S) {
char[] cs = S.toCharArray();
List<String> res = new ArrayList<>();
dfs(cs, 0, res);
return res;
}
private void dfs(char[] cs, int i, List<String> res) {
if (i == cs.length) {
res.add(String.valueOf(cs));
return;
}
dfs(cs, i + 1, res);
if (cs[i] >= 'A') {
cs[i] ^= 32;
dfs(cs, i + 1, res);
}
}
}
814. 二叉树剪枝
题目描述
给定二叉树根结点 root ,此外树的每个结点的值要么是 0,要么是 1。
返回移除了所有不包含 1 的子树的原二叉树。
( 节点 X 的子树为 X 本身,以及所有 X 的后代。)
示例1: 输入: [1,null,0,0,1] 输出: [1,null,0,null,1]
解释:
只有红色节点满足条件“所有不包含 1 的子树”。
右图为返回的答案。

示例2: 输入: [1,0,1,0,0,0,1] 输出: [1,null,1,null,1]
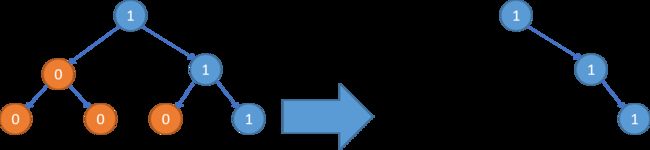
示例3: 输入: [1,1,0,1,1,0,1,0] 输出: [1,1,0,1,1,null,1]

说明:
- 给定的二叉树最多有
100个节点。 - 每个节点的值只会为
0或1。
解法
Java
class Solution {
public TreeNode pruneTree(TreeNode root) {
if (root == null) {
return null;
}
root.left = pruneTree(root.left);
root.right = pruneTree(root.right);
return root.val == 0 && root.left == null && root.right == null ? null : root;
}
}
817. 链表组件
题目描述
给定一个链表(链表结点包含一个整型值)的头结点 head。
同时给定列表 G,该列表是上述链表中整型值的一个子集。
返回列表 G 中组件的个数,这里对组件的定义为:链表中一段最长连续结点的值(该值必须在列表 G 中)构成的集合。
示例 1:
输入: head: 0->1->2->3 G = [0, 1, 3] 输出: 2 解释: 链表中,0 和 1 是相连接的,且 G 中不包含 2,所以 [0, 1] 是 G 的一个组件,同理 [3] 也是一个组件,故返回 2。
示例 2:
输入: head: 0->1->2->3->4 G = [0, 3, 1, 4] 输出: 2 解释: 链表中,0 和 1 是相连接的,3 和 4 是相连接的,所以 [0, 1] 和 [3, 4] 是两个组件,故返回 2。
注意:
- 如果
N是给定链表head的长度,1 <= N <= 10000。 - 链表中每个结点的值所在范围为
[0, N - 1]。 1 <= G.length <= 10000G是链表中所有结点的值的一个子集.
解法
Java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public int numComponents(ListNode head, int[] G) {
if (head == null || G == null) {
return 0;
}
Set<Integer> set = new HashSet<>();
for (int val : G) {
set.add(val);
}
int n = G.length;
ListNode cur = head;
int cnt = 0;
boolean flag = false;
while (cur != null) {
while (cur != null && set.contains(cur.val)) {
flag = true;
cur = cur.next;
}
if (flag) {
++cnt;
flag = false;
}
if (cur != null) {
cur = cur.next;
}
}
return cnt;
}
}
829. 连续整数求和
题目描述
给定一个正整数 N,试求有多少组连续正整数满足所有数字之和为 N?
示例 1:
输入: 5 输出: 2 解释: 5 = 5 = 2 + 3,共有两组连续整数([5],[2,3])求和后为 5。
示例 2:
输入: 9 输出: 3 解释: 9 = 9 = 4 + 5 = 2 + 3 + 4
示例 3:
输入: 15 输出: 4 解释: 15 = 15 = 8 + 7 = 4 + 5 + 6 = 1 + 2 + 3 + 4 + 5
说明: 1 <= N <= 10 ^ 9
解法
Java
class Solution {
public int consecutiveNumbersSum(int N) {
int res = 0;
for (int i = 1; i * (i - 1) / 2 < N; ++i) {
if ((N - i * (i - 1) / 2) % i == 0) {
++res;
}
}
return res;
}
}
832. 翻转图像
题目描述
给定一个二进制矩阵 A,我们想先水平翻转图像,然后反转图像并返回结果。
水平翻转图片就是将图片的每一行都进行翻转,即逆序。例如,水平翻转 [1, 1, 0] 的结果是 [0, 1, 1]。
反转图片的意思是图片中的 0 全部被 1 替换, 1 全部被 0 替换。例如,反转 [0, 1, 1] 的结果是 [1, 0, 0]。
示例 1:
输入: [[1,1,0],[1,0,1],[0,0,0]]
输出: [[1,0,0],[0,1,0],[1,1,1]]
解释: 首先翻转每一行: [[0,1,1],[1,0,1],[0,0,0]];
然后反转图片: [[1,0,0],[0,1,0],[1,1,1]]
示例 2:
输入: [[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]]
输出: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
解释: 首先翻转每一行: [[0,0,1,1],[1,0,0,1],[1,1,1,0],[0,1,0,1]];
然后反转图片: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
说明:
1 <= A.length = A[0].length <= 200 <= A[i][j] <= 1
解法
遍历矩阵每一行,利用双指针 p, q 进行水平交换翻转,顺便反转图像(1 变 0,0 变 1:1 ^ 1 = 0,0 ^ 1 = 1)。
Java
class Solution {
public int[][] flipAndInvertImage(int[][] A) {
int m = A.length, n = A[0].length;
for (int i = 0; i < m; ++i) {
int p = 0, q = n - 1;
while (p < q) {
int t = A[i][p] ^ 1;
A[i][p] = A[i][q] ^ 1;
A[i][q] = t;
++p;
--q;
}
if (p == q) {
A[i][p] ^= 1;
}
}
return A;
}
}
852. 山脉数组的峰顶索引
题目描述
我们把符合下列属性的数组 A 称作山脉:
A.length >= 3- 存在
0 < i < A.length - 1使得A[0] < A[1] < ... A[i-1] < A[i] > A[i+1] > ... > A[A.length - 1]
给定一个确定为山脉的数组,返回任何满足 A[0] < A[1] < ... A[i-1] < A[i] > A[i+1] > ... > A[A.length - 1] 的 i 的值。
示例 1:
输入:[0,1,0] 输出:1
示例 2:
输入:[0,2,1,0] 输出:1
提示:
3 <= A.length <= 10000- 0 <= A[i] <= 10^6
- A 是如上定义的山脉
解法
Java
class Solution {
public int peakIndexInMountainArray(int[] A) {
int l = 0, r = A.length - 1;
while (l < r) {
int mid = l + r >>> 1;
if (A[mid] > A[mid + 1]) r = mid;
else l = mid + 1;
}
return r;
}
}
856. 括号的分数
题目描述
给定一个平衡括号字符串 S,按下述规则计算该字符串的分数:
()得 1 分。AB得A + B分,其中 A 和 B 是平衡括号字符串。(A)得2 * A分,其中 A 是平衡括号字符串。
示例 1:
输入: "()" 输出: 1
示例 2:
输入: "(())" 输出: 2
示例 3:
输入: "()()" 输出: 2
示例 4:
输入: "(()(()))" 输出: 6
提示:
S是平衡括号字符串,且只含有(和)。2 <= S.length <= 50
解法
Java
class Solution {
public int scoreOfParentheses(String S) {
int res = 0;
for (int i = 0, d = 0; i < S.length(); ++i) {
if (S.charAt(i) == '(') {
++d;
} else {
--d;
if (S.charAt(i - 1) == '(') {
res += 1 << d;
}
}
}
return res;
}
}
857. 雇佣 K 名工人的最低成本
题目描述
有 N 名工人。 第 i 名工人的工作质量为 quality[i] ,其最低期望工资为 wage[i] 。
现在我们想雇佣 K 名工人组成一个工资组。在雇佣 一组 K 名工人时,我们必须按照下述规则向他们支付工资:
- 对工资组中的每名工人,应当按其工作质量与同组其他工人的工作质量的比例来支付工资。
- 工资组中的每名工人至少应当得到他们的最低期望工资。
返回组成一个满足上述条件的工资组至少需要多少钱。
示例 1:
输入: quality = [10,20,5], wage = [70,50,30], K = 2 输出: 105.00000 解释: 我们向 0 号工人支付 70,向 2 号工人支付 35。
示例 2:
输入: quality = [3,1,10,10,1], wage = [4,8,2,2,7], K = 3 输出: 30.66667 解释: 我们向 0 号工人支付 4,向 2 号和 3 号分别支付 13.33333。
提示:
1 <= K <= N <= 10000,其中N = quality.length = wage.length1 <= quality[i] <= 100001 <= wage[i] <= 10000- 与正确答案误差在
10^-5之内的答案将被视为正确的。
解法
Java
class Solution {
public double mincostToHireWorkers(int[] quality, int[] wage, int K) {
Worker[] workers = new Worker[quality.length];
for (int i = 0; i < quality.length; ++i) {
workers[i] = new Worker((double) wage[i] / quality[i], quality[i]);
}
Arrays.sort(workers);
double res = 1e9;
Queue<Integer> queue = new PriorityQueue<>(Comparator.reverseOrder());
int s = 0;
for (Worker worker : workers) {
s += worker.quality;
queue.offer(worker.quality);
if (queue.size() > K) {
s -= queue.poll();
}
if (queue.size() == K) {
res = Math.min(res, s * worker.x);
}
}
return res;
}
class Worker implements Comparable<Worker> {
double x;
int quality;
public Worker(double x, int quality) {
this.x = x;
this.quality = quality;
}
@Override
public int compareTo(Worker o) {
return Double.compare(x, o.x);
}
}
}
860. 柠檬水找零
题目描述
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
输入:[5,5,5,10,20] 输出:true 解释: 前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。 第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。 第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。 由于所有客户都得到了正确的找零,所以我们输出 true。
示例 2:
输入:[5,5,10] 输出:true
示例 3:
输入:[10,10] 输出:false
示例 4:
输入:[5,5,10,10,20] 输出:false 解释: 前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。 对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。 对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。 由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
0 <= bills.length <= 10000bills[i]不是5就是10或是20
解法
Java
class Solution {
public boolean lemonadeChange(int[] bills) {
int fives = 0, tens = 0;
for (int bill : bills) {
if (bill == 5) {
++fives;
} else if (bill == 10) {
++tens;
if (--fives < 0) {
return false;
}
} else {
if (tens >= 1 && fives >= 1) {
--tens;
--fives;
} else if (fives >= 3) {
fives -= 3;
} else {
return false;
}
}
}
return true;
}
}
862. 和至少为 K 的最短子数组
题目描述
返回 A 的最短的非空连续子数组的长度,该子数组的和至少为 K 。
如果没有和至少为 K 的非空子数组,返回 -1 。
示例 1:
输入:A = [1], K = 1 输出:1
示例 2:
输入:A = [1,2], K = 4 输出:-1
示例 3:
输入:A = [2,-1,2], K = 3 输出:3
提示:
1 <= A.length <= 50000-10 ^ 5 <= A[i] <= 10 ^ 51 <= K <= 10 ^ 9
解法
Java
class Solution {
public int shortestSubarray(int[] A, int K) {
int n = A.length;
int[] s = new int[n + 1];
for (int i = 0; i < n; ++i) {
s[i + 1] = s[i] + A[i];
}
Deque<Integer> deque = new ArrayDeque<>();
deque.offer(0);
int res = Integer.MAX_VALUE;
for (int i = 1; i <= n; ++i) {
while (!deque.isEmpty() && s[i] - s[deque.peekFirst()] >= K) {
res = Math.min(res, i - deque.pollFirst());
}
while (!deque.isEmpty() && s[i] <= s[deque.peekLast()]) {
deque.pollLast();
}
deque.offer(i);
}
return res != Integer.MAX_VALUE ? res : -1;
}
}
872. 叶子相似的树
题目描述
请考虑一颗二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。

举个例子,如上图所示,给定一颗叶值序列为 (6, 7, 4, 9, 8) 的树。
如果有两颗二叉树的叶值序列是相同,那么我们就认为它们是 叶相似 的。
如果给定的两个头结点分别为 root1 和 root2 的树是叶相似的,则返回 true;否则返回 false 。
提示:
- 给定的两颗树可能会有
1到100个结点。
解法
深度优先搜索。
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean leafSimilar(TreeNode root1, TreeNode root2) {
List<Integer> l1 = new ArrayList<>();
List<Integer> l2 = new ArrayList<>();
dfs(root1, l1);
dfs(root2, l2);
return l1.equals(l2);
}
private void dfs(TreeNode root, List<Integer> leaves) {
if (root == null) return;
if (root.left == null && root.right == null) {
leaves.add(root.val);
return;
}
dfs(root.left, leaves);
dfs(root.right, leaves);
}
}
875. 爱吃香蕉的珂珂
题目描述
珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。
珂珂可以决定她吃香蕉的速度 K (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 K 根。如果这堆香蕉少于 K 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
返回她可以在 H 小时内吃掉所有香蕉的最小速度 K(K 为整数)。
示例 1:
输入: piles = [3,6,7,11], H = 8 输出: 4
示例 2:
输入: piles = [30,11,23,4,20], H = 5 输出: 30
示例 3:
输入: piles = [30,11,23,4,20], H = 6 输出: 23
提示:
1 <= piles.length <= 10^4piles.length <= H <= 10^91 <= piles[i] <= 10^9
解法
Java
class Solution {
public int minEatingSpeed(int[] piles, int H) {
int l = 1, r = 1000000000;
while (l < r) {
int mid = l + r >>> 1;
if (check(piles, H, mid)) r = mid;
else l = mid + 1;
}
return r;
}
private boolean check(int[] piles, int h, int k) {
int cnt = 0;
for (int pile : piles) {
cnt += (pile - 1) / k + 1;
}
return cnt <= h;
}
}
876. 链表的中间结点
题目描述
给定一个带有头结点 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:
输入:[1,2,3,4,5] 输出:此列表中的结点 3 (序列化形式:[3,4,5]) 返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。 注意,我们返回了一个 ListNode 类型的对象 ans,这样: ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
示例 2:
输入:[1,2,3,4,5,6] 输出:此列表中的结点 4 (序列化形式:[4,5,6]) 由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。
提示:
- 给定链表的结点数介于
1和100之间。
解法
Java
public ListNode middleNode(ListNode head) {
ListNode low = head, first = head;
while (first != null && first.next != null) {
low = low.next;
first = first.next.next;
}
return low;
}
878. 第 N 个神奇数字
题目描述
如果正整数可以被 A 或 B 整除,那么它是神奇的。
返回第 N 个神奇数字。由于答案可能非常大,返回它模 10^9 + 7 的结果。
示例 1:
输入:N = 1, A = 2, B = 3 输出:2
示例 2:
输入:N = 4, A = 2, B = 3 输出:6
示例 3:
输入:N = 5, A = 2, B = 4 输出:10
示例 4:
输入:N = 3, A = 6, B = 4 输出:8
提示:
1 <= N <= 10^92 <= A <= 400002 <= B <= 40000
解法
Java
class Solution {
public int nthMagicalNumber(int N, int A, int B) {
long l = 1, r = Long.MAX_VALUE;
int lcm = A * B / gcd(A, B);
while (l < r) {
long mid = l + r >>> 1;
if (mid / A + mid / B - mid / lcm >= N) r = mid;
else l = mid + 1;
}
return (int) (r % 1000000007);
}
private int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
}
883. 三维形体投影面积
题目描述
在 N * N 的网格中,我们放置了一些与 x,y,z 三轴对齐的 1 * 1 * 1 立方体。
每个值 v = grid[i][j] 表示 v 个正方体叠放在单元格 (i, j) 上。
现在,我们查看这些立方体在 xy、yz 和 zx 平面上的投影。
投影就像影子,将三维形体映射到一个二维平面上。
在这里,从顶部、前面和侧面看立方体时,我们会看到“影子”。
返回所有三个投影的总面积。
示例 1:
输入:[[2]] 输出:5
示例 2:
输入:[[1,2],[3,4]] 输出:17 解释: 这里有该形体在三个轴对齐平面上的三个投影(“阴影部分”)。
示例 3:
输入:[[1,0],[0,2]] 输出:8
示例 4:
输入:[[1,1,1],[1,0,1],[1,1,1]] 输出:14
示例 5:
输入:[[2,2,2],[2,1,2],[2,2,2]] 输出:21
提示:
1 <= grid.length = grid[0].length <= 500 <= grid[i][j] <= 50
解法
Java
class Solution {
public int projectionArea(int[][] grid) {
int n = grid.length;
int res = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
res += grid[i][j] > 0 ? 1 : 0;
}
}
for (int i = 0; i < n; ++i) {
int max = 0;
for (int j = 0; j < n; ++j) {
max = Math.max(max, grid[i][j]);
}
res += max;
}
for (int j = 0; j < n; ++j) {
int max = 0;
for (int i = 0; i < n; ++i) {
max = Math.max(max, grid[i][j]);
}
res += max;
}
return res;
}
}
887. 鸡蛋掉落
题目描述
你将获得 K 个鸡蛋,并可以使用一栋从 1 到 N 共有 N 层楼的建筑。
每个蛋的功能都是一样的,如果一个蛋碎了,你就不能再把它掉下去。
你知道存在楼层 F ,满足 0 <= F <= N 任何从高于 F 的楼层落下的鸡蛋都会碎,从 F 楼层或比它低的楼层落下的鸡蛋都不会破。
每次移动,你可以取一个鸡蛋(如果你有完整的鸡蛋)并把它从任一楼层 X 扔下(满足 1 <= X <= N)。
你的目标是确切地知道 F 的值是多少。
无论 F 的初始值如何,你确定 F 的值的最小移动次数是多少?
示例 1:
输入:K = 1, N = 2 输出:2 解释: 鸡蛋从 1 楼掉落。如果它碎了,我们肯定知道 F = 0 。 否则,鸡蛋从 2 楼掉落。如果它碎了,我们肯定知道 F = 1 。 如果它没碎,那么我们肯定知道 F = 2 。 因此,在最坏的情况下我们需要移动 2 次以确定 F 是多少。
示例 2:
输入:K = 2, N = 6 输出:3
示例 3:
输入:K = 3, N = 14 输出:4
提示:
1 <= K <= 1001 <= N <= 10000
解法
Java
class Solution {
public int superEggDrop(int K, int N) {
int[] res = new int[K];
Arrays.fill(res, 1);
while (res[K - 1] < N) {
for (int i = K - 1; i >= 1; i--) {
res[i] = res[i] + res[i - 1] + 1;
}
res[0]++;
}
return res[0];
}
}
891. 子序列宽度之和
题目描述
给定一个整数数组 A ,考虑 A 的所有非空子序列。
对于任意序列 S ,设 S 的宽度是 S 的最大元素和最小元素的差。
返回 A 的所有子序列的宽度之和。
由于答案可能非常大,请返回答案模 10^9+7。
示例:
输入:[2,1,3] 输出:6 解释: 子序列为 [1],[2],[3],[2,1],[2,3],[1,3],[2,1,3] 。 相应的宽度是 0,0,0,1,1,2,2 。 这些宽度之和是 6 。
提示:
1 <= A.length <= 200001 <= A[i] <= 20000
解法
Java
class Solution {
public int sumSubseqWidths(int[] A) {
final int MOD = (int) (1e9 + 7);
Arrays.sort(A);
int n = A.length;
long res = 0;
long p = 1;
for (int i = 0; i < n; ++i) {
res = (res + (A[i] - A[n - 1 - i]) * p) % MOD;
p = (p << 1) % MOD;
}
return (int) ((res + MOD) % MOD);
}
}
892. 三维形体的表面积
题目描述
在 N * N 的网格上,我们放置一些 1 * 1 * 1 的立方体。
每个值 v = grid[i][j] 表示 v 个正方体叠放在对应单元格 (i, j) 上。
请你返回最终形体的表面积。
示例 1:
输入:[[2]] 输出:10
示例 2:
输入:[[1,2],[3,4]] 输出:34
示例 3:
输入:[[1,0],[0,2]] 输出:16
示例 4:
输入:[[1,1,1],[1,0,1],[1,1,1]] 输出:32
示例 5:
输入:[[2,2,2],[2,1,2],[2,2,2]] 输出:46
提示:
1 <= N <= 500 <= grid[i][j] <= 50
解法
Java
class Solution {
public int surfaceArea(int[][] grid) {
int n = grid.length;
int res = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
if (grid[i][j] > 0) {
res += 2 + grid[i][j] * 4;
if (i > 0) {
res -= Math.min(grid[i][j], grid[i - 1][j]) * 2;
}
if (j > 0) {
res -= Math.min(grid[i][j], grid[i][j - 1]) * 2;
}
}
}
}
return res;
}
}
897. 递增顺序查找树
题目描述
给你一个树,请你 按中序遍历 重新排列树,使树中最左边的结点现在是树的根,并且每个结点没有左子结点,只有一个右子结点。
示例 :
输入:[5,3,6,2,4,null,8,1,null,null,null,7,9]
5
/ \
3 6
/ \ \
2 4 8
/ / \
1 7 9
输出:[1,null,2,null,3,null,4,null,5,null,6,null,7,null,8,null,9]
1
\
2
\
3
\
4
\
5
\
6
\
7
\
8
\
9
提示:
- 给定树中的结点数介于
1和100之间。 - 每个结点都有一个从
0到1000范围内的唯一整数值。
解法
递归将左子树、右子树转换为左、右链表 left 和 right。然后将左链表 left 的最后一个结点的 right 指针指向 root,root 的 right 指针指向右链表 right,并将 root 的 left 指针值为空。
同面试题 17.12. BiNode。
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode increasingBST(TreeNode root) {
if (root == null) return null;
TreeNode left = increasingBST(root.left);
TreeNode right = increasingBST(root.right);
if (left == null) {
root.right = right;
return root;
}
TreeNode res = left;
while (left != null && left.right != null) left = left.right;
left.right = root;
root.right = right;
root.left = null;
return res;
}
}
898. 子数组按位或操作
题目描述
我们有一个非负整数数组 A。
对于每个(连续的)子数组 B = [A[i], A[i+1], ..., A[j]] ( i <= j),我们对 B 中的每个元素进行按位或操作,获得结果 A[i] | A[i+1] | ... | A[j]。
返回可能结果的数量。 (多次出现的结果在最终答案中仅计算一次。)
示例 1:
输入:[0] 输出:1 解释: 只有一个可能的结果 0 。
示例 2:
输入:[1,1,2] 输出:3 解释: 可能的子数组为 [1],[1],[2],[1, 1],[1, 2],[1, 1, 2]。 产生的结果为 1,1,2,1,3,3 。 有三个唯一值,所以答案是 3 。
示例 3:
输入:[1,2,4] 输出:6 解释: 可能的结果是 1,2,3,4,6,以及 7 。
提示:
1 <= A.length <= 500000 <= A[i] <= 10^9
解法
Java
class Solution {
public int subarrayBitwiseORs(int[] A) {
int maxVal = Arrays.stream(A).max().getAsInt();
int mask = (Integer.highestOneBit(maxVal) << 1) - 1;
Set<Integer> res = new HashSet<>();
for (int i = 0; i < A.length; ++i) {
int val = A[i];
res.add(val);
for (int j = i - 1; j >= 0 && val != mask; --j) {
val |= A[j];
res.add(val);
}
}
return res.size();
}
}
912. 排序数组
题目描述
给定一个整数数组 nums,将该数组升序排列。
示例 1:
输入:[5,2,3,1] 输出:[1,2,3,5]
示例 2:
输入:[5,1,1,2,0,0] 输出:[0,0,1,1,2,5]
提示:
1 <= A.length <= 10000-50000 <= A[i] <= 50000
解法
Java
class Solution {
void createHeap(int[] data, int n, int h) {
int i = h;
int j = 2 * i + 1;
int temp = data[i];
while (j < n) {
if (j + 1 < n && data[j] < data[j + 1]) j++;
if (temp > data[j]) {
break;
} else {
data[i] = data[j];
i = j;
j = 2 * i + 1;
}
}
data[i] = temp;
}
void initHeap(int[] data, int n) {
for (int i = (n - 2) / 2; i > -1; i--) {
createHeap(data, n, i);
}
}
void heapSort(int[] data, int n) {
initHeap(data, n);
for (int i = n - 1;i > -1;i--) {
int temp = data[i];
data[i] = data[0];
data[0] = temp;
createHeap(data, i, 0);
}
}
public int[] sortArray(int[] nums) {
heapSort(nums, nums.length);
return nums;
}
}
918. 环形子数组的最大和
题目描述
给定一个由整数数组 A 表示的环形数组 C,求 C 的非空子数组的最大可能和。
在此处,环形数组意味着数组的末端将会与开头相连呈环状。(形式上,当0 <= i < A.length 时 C[i] = A[i],而当 i >= 0 时 C[i+A.length] = C[i])
此外,子数组最多只能包含固定缓冲区 A 中的每个元素一次。(形式上,对于子数组 C[i], C[i+1], ..., C[j],不存在 i <= k1, k2 <= j 其中 k1 % A.length = k2 % A.length)
示例 1:
输入:[1,-2,3,-2] 输出:3 解释:从子数组 [3] 得到最大和 3
示例 2:
输入:[5,-3,5] 输出:10 解释:从子数组 [5,5] 得到最大和 5 + 5 = 10
示例 3:
输入:[3,-1,2,-1] 输出:4 解释:从子数组 [2,-1,3] 得到最大和 2 + (-1) + 3 = 4
示例 4:
输入:[3,-2,2,-3] 输出:3 解释:从子数组 [3] 和 [3,-2,2] 都可以得到最大和 3
示例 5:
输入:[-2,-3,-1] 输出:-1 解释:从子数组 [-1] 得到最大和 -1
提示:
-30000 <= A[i] <= 300001 <= A.length <= 30000
解法
Java
class Solution {
public int maxSubarraySumCircular(int[] A) {
int tot = 0;
int curMax = 0;
int maxSum = Integer.MIN_VALUE;
int curMin = 0;
int minSum = Integer.MAX_VALUE;
for (int x : A) {
tot += x;
curMax = Math.max(curMax + x, x);
maxSum = Math.max(maxSum, curMax);
curMin = Math.min(curMin + x, x);
minSum = Math.min(minSum, curMin);
}
return maxSum > 0 ? Math.max(maxSum, tot - minSum) : maxSum;
}
}
922. 按奇偶排序数组 II
题目描述
给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。
对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。
你可以返回任何满足上述条件的数组作为答案。
示例:
输入:[4,2,5,7] 输出:[4,5,2,7] 解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。
提示:
2 <= A.length <= 20000A.length % 2 == 00 <= A[i] <= 1000
解法
Java
class Solution {
public int[] sortArrayByParityII(int[] A) {
int j = 1, length = A.length;
for (int i = 0; i < length; i += 2) {
if ((A[i] & 1) != 0) {
while ((A[j] & 1) != 0) j += 2;
// Swap A[i] and A[j]
int tmp = A[i];
A[i] = A[j];
A[j] = tmp;
}
}
return A;
}
}
929. 独特的电子邮件地址
题目描述
每封电子邮件都由一个本地名称和一个域名组成,以 @ 符号分隔。
例如,在 [email protected]中, alice 是本地名称,而 leetcode.com 是域名。
除了小写字母,这些电子邮件还可能包含 '.' 或 '+'。
如果在电子邮件地址的本地名称部分中的某些字符之间添加句点('.'),则发往那里的邮件将会转发到本地名称中没有点的同一地址。例如,"[email protected]” 和 “[email protected]” 会转发到同一电子邮件地址。 (请注意,此规则不适用于域名。)
如果在本地名称中添加加号('+'),则会忽略第一个加号后面的所有内容。这允许过滤某些电子邮件,例如 [email protected] 将转发到 [email protected]。 (同样,此规则不适用于域名。)
可以同时使用这两个规则。
给定电子邮件列表 emails,我们会向列表中的每个地址发送一封电子邮件。实际收到邮件的不同地址有多少?
示例:
输入:["[email protected]","[email protected]","[email protected]"] 输出:2 解释:实际收到邮件的是 "[email protected]" 和 "[email protected]"。
提示:
1 <= emails[i].length <= 1001 <= emails.length <= 100- 每封
emails[i]都包含有且仅有一个'@'字符。
解法
Java
class Solution {
public int numUniqueEmails(String[] emails) {
Set<String> set = new HashSet<>();
for (String email : emails) {
int index = email.indexOf('@');
String local = email.substring(0, index);
String domain = email.substring(index);
index = local.indexOf('+');
if (index != -1) {
local = local.substring(0, index);
}
local = local.replace(".", "");
set.add(local + domain);
}
return set.size();
}
}
930. 和相同的二元子数组
题目描述
在由若干 0 和 1 组成的数组 A 中,有多少个和为 S 的非空子数组。
示例:
输入:A = [1,0,1,0,1], S = 2 输出:4 解释: 如下面黑体所示,有 4 个满足题目要求的子数组: [1,0,1,0,1] [1,0,1,0,1] [1,0,1,0,1] [1,0,1,0,1]
提示:
A.length <= 300000 <= S <= A.lengthA[i]为0或1
解法
Java
class Solution {
public int numSubarraysWithSum(int[] A, int S) {
int[] map = new int[A.length + 1];
map[0] = 1;
int res = 0;
int s = 0;
for (int a : A) {
s += a;
if (s >= S) {
res += map[s - S];
}
++map[s];
}
return res;
}
}
931. 下降路径最小和
题目描述
给定一个方形整数数组 A,我们想要得到通过 A 的下降路径的最小和。
下降路径可以从第一行中的任何元素开始,并从每一行中选择一个元素。在下一行选择的元素和当前行所选元素最多相隔一列。
示例:
输入:[[1,2,3],[4,5,6],[7,8,9]] 输出:12 解释: 可能的下降路径有:
[1,4,7], [1,4,8], [1,5,7], [1,5,8], [1,5,9][2,4,7], [2,4,8], [2,5,7], [2,5,8], [2,5,9], [2,6,8], [2,6,9][3,5,7], [3,5,8], [3,5,9], [3,6,8], [3,6,9]
和最小的下降路径是 [1,4,7],所以答案是 12。
提示:
1 <= A.length == A[0].length <= 100-100 <= A[i][j] <= 100
解法
Java
class Solution {
public int minFallingPathSum(int[][] A) {
int m = A.length, n = A[0].length;
for (int i = 1; i < m; ++i) {
for (int j = 0; j < n; ++j) {
int min = A[i - 1][j];
if (j > 0) min = Math.min(min, A[i - 1][j - 1]);
if (j < n - 1) min = Math.min(min, A[i - 1][j + 1]);
A[i][j] += min;
}
}
return Arrays.stream(A[m - 1]).min().getAsInt();
}
}
933. 最近的请求次数
题目描述
写一个 RecentCounter 类来计算最近的请求。
它只有一个方法:ping(int t),其中 t 代表以毫秒为单位的某个时间。
返回从 3000 毫秒前到现在的 ping 数。
任何处于 [t - 3000, t] 时间范围之内的 ping 都将会被计算在内,包括当前(指 t 时刻)的 ping。
保证每次对 ping 的调用都使用比之前更大的 t 值。
示例:
输入:inputs = ["RecentCounter","ping","ping","ping","ping"], inputs = [[],[1],[100],[3001],[3002]] 输出:[null,1,2,3,3]
提示:
- 每个测试用例最多调用
10000次ping。 - 每个测试用例会使用严格递增的
t值来调用ping。 - 每次调用
ping都有1 <= t <= 10^9。
解法
在第 1、100、3001、3002 这四个时间点分别进行了 ping 请求, 在 3001 秒的时候, 它前面的 3000 秒指的是区间 [1,3001], 所以一共是有 1、100、3001 三个请求, t = 3002 的前 3000 秒指的是区间 [2,3002], 所以有 100、3001、3002 三次请求。
可以用队列实现。每次将 t 进入队尾,同时从队头开始依次移除小于 t-3000 的元素。然后返回队列的大小 q.size() 即可。
Java
class RecentCounter {
private Deque<Integer> q;
public RecentCounter() {
q = new ArrayDeque<>();
}
public int ping(int t) {
q.offerLast(t);
while (q.peekFirst() < t - 3000) {
q.pollFirst();
}
return q.size();
}
}
/**
* Your RecentCounter object will be instantiated and called as such:
* RecentCounter obj = new RecentCounter();
* int param_1 = obj.ping(t);
*/
938. 二叉搜索树的范围和
题目描述
给定二叉搜索树的根结点 root,返回 L 和 R(含)之间的所有结点的值的和。
二叉搜索树保证具有唯一的值。
示例 1:
输入:root = [10,5,15,3,7,null,18], L = 7, R = 15 输出:32
示例 2:
输入:root = [10,5,15,3,7,13,18,1,null,6], L = 6, R = 10 输出:23
提示:
- 树中的结点数量最多为
10000个。 - 最终的答案保证小于
2^31。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private int res = 0;
public int rangeSumBST(TreeNode root, int L, int R) {
if (root == null) {
return res;
}
if (root.val < L) {
rangeSumBST(root.right, L, R);
} else if (root.val > R) {
rangeSumBST(root.left, L, R);
} else {
res += root.val;
rangeSumBST(root.left, L, R);
rangeSumBST(root.right, L, R);
}
return res;
}
}
946. 验证栈序列
题目描述
给定 pushed 和 popped 两个序列,每个序列中的 值都不重复,只有当它们可能是在最初空栈上进行的推入 push 和弹出 pop 操作序列的结果时,返回 true;否则,返回 false 。
示例 1:
输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1] 输出:true 解释:我们可以按以下顺序执行: push(1), push(2), push(3), push(4), pop() -> 4, push(5), pop() -> 5, pop() -> 3, pop() -> 2, pop() -> 1
示例 2:
输入:pushed = [1,2,3,4,5], popped = [4,3,5,1,2] 输出:false 解释:1 不能在 2 之前弹出。
提示:
0 <= pushed.length == popped.length <= 10000 <= pushed[i], popped[i] < 1000pushed是popped的排列。
解法
Java
import java.util.*;
class Solution {
public boolean validateStackSequences(int[] pushed, int[] popped) {
Stack<Integer> stack = new Stack<>();
int i = 0, k = 0;
while (i < popped.length) {
if (!stack.isEmpty() && popped[i] == stack.peek()) {
stack.pop();
i ++;
} else {
if (k < pushed.length) {
stack.push(pushed[k ++]);
} else return false;
}
}
return stack.isEmpty();
}
}
952. 按公因数计算最大组件大小
题目描述
给定一个由不同正整数的组成的非空数组 A,考虑下面的图:
- 有
A.length个节点,按从A[0]到A[A.length - 1]标记; - 只有当
A[i]和A[j]共用一个大于 1 的公因数时,A[i]和A[j]之间才有一条边。
返回图中最大连通组件的大小。
示例 1:
输入:[4,6,15,35] 输出:4

示例 2:
输入:[20,50,9,63] 输出:2

示例 3:
输入:[2,3,6,7,4,12,21,39] 输出:8
提示:
1 <= A.length <= 200001 <= A[i] <= 100000
解法
Java
class Solution {
public int largestComponentSize(int[] A) {
int n = A.length, num = 100000 + 1, max = 0;
Set<Integer> primes = findPrime(num);
int[] root = new int[n];
int[] size = new int[n];
int[] primeToNode = new int[num];
// 一开始 prime 没有和数组 A 中的 node 连在一起
Arrays.fill(primeToNode, -1);
// 初始化 root 和 size array
for (int i = 0; i < n; i++) {
root[i] = i;
size[i] = 1;
}
for (int i = 0; i < n; i++) {
int curr = A[i];
// find all of its prime factors
for (Integer prime: primes) {
if (primes.contains(curr)) {
prime = curr;
}
if (curr % prime == 0) {
// 我们为 curr 找到一个质因数,则需要将该节点加入该 prime 已经连接到的根节点上
if (primeToNode[prime] != -1) {
// 该 prime 已经与数组 A 中 node 相连
union(size, root, primeToNode[prime], i);
}
primeToNode[prime] = find(root, i);
while (curr % prime == 0) {
// 将质因数 prime 全部剔除
curr = curr / prime;
}
}
if (curr == 1) {
break;
}
}
}
for (int i = 0; i < n; i++) {
max = Math.max(size[i], max);
}
return max;
}
public Set<Integer> findPrime(int num) {
boolean[] isPrime = new boolean[num];
Arrays.fill(isPrime, true);
Set<Integer> primes = new HashSet<>();
for (int i = 2; i < isPrime.length; i++) {
if (isPrime[i]) {
primes.add(i);
for (int j = 0; i * j < isPrime.length; j++) {
isPrime[i * j] = false;
}
}
}
return primes;
}
public void union(int[] size, int[] root, int i, int j) {
int rootI = find(root, i);
int rootJ = find(root, j);
if (rootI == rootJ) {
// 它们已经属于同一个 root
return;
}
if (size[rootI] > size[rootJ]) {
root[rootJ] = rootI;
size[rootI] += size[rootJ];
} else {
root[rootI] = rootJ;
size[rootJ] += size[rootI];
}
}
public int find(int[] root, int i) {
// 当某节点的根不是他自己时,则需要继续找到其 root
List<Integer> records = new LinkedList<>();
while (root[i] != i) {
records.add(i);
i = root[i];
}
// 将这些节点均指向其 root
for (Integer record: records) {
root[record] = i;
}
return i;
}
}
955. 删列造序 II
题目描述
给定由 N 个小写字母字符串组成的数组 A,其中每个字符串长度相等。
选取一个删除索引序列,对于 A 中的每个字符串,删除对应每个索引处的字符。
比如,有 A = ["abcdef", "uvwxyz"],删除索引序列 {0, 2, 3},删除后 A 为["bef", "vyz"]。
假设,我们选择了一组删除索引 D,那么在执行删除操作之后,最终得到的数组的元素是按 字典序(A[0] <= A[1] <= A[2] ... <= A[A.length - 1])排列的,然后请你返回 D.length 的最小可能值。
示例 1:
输入:["ca","bb","ac"] 输出:1 解释: 删除第一列后,A = ["a", "b", "c"]。 现在 A 中元素是按字典排列的 (即,A[0] <= A[1] <= A[2])。 我们至少需要进行 1 次删除,因为最初 A 不是按字典序排列的,所以答案是 1。
示例 2:
输入:["xc","yb","za"] 输出:0 解释: A 的列已经是按字典序排列了,所以我们不需要删除任何东西。 注意 A 的行不需要按字典序排列。 也就是说,A[0][0] <= A[0][1] <= ... 不一定成立。
示例 3:
输入:["zyx","wvu","tsr"] 输出:3 解释: 我们必须删掉每一列。
提示:
1 <= A.length <= 1001 <= A[i].length <= 100
解法
Java
class Solution {
public int minDeletionSize(String[] A) {
if (A == null || A.length <= 1) {
return 0;
}
int len = A.length, wordLen = A[0].length(), res = 0;
boolean[] cut = new boolean[len];
search: for (int j = 0; j < wordLen; j++) {
// 判断第 j 列是否应当保留
for (int i = 0; i < len - 1; i++) {
if (!cut[i] && A[i].charAt(j) > A[i + 1].charAt(j)) {
res += 1;
continue search;
}
}
// 更新 cut 的信息
for (int i = 0; i < len - 1; i++) {
if (A[i].charAt(j) < A[i + 1].charAt(j)) {
cut[i] = true;
}
}
}
return res;
}
}
958. 二叉树的完全性检验
题目描述
给定一个二叉树,确定它是否是一个完全二叉树。
百度百科中对完全二叉树的定义如下:
若设二叉树的深度为 h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。(注:第 h 层可能包含 1~ 2h 个节点。)
示例 1:
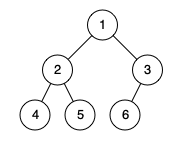
输入:[1,2,3,4,5,6]
输出:true
解释:最后一层前的每一层都是满的(即,结点值为 {1} 和 {2,3} 的两层),且最后一层中的所有结点({4,5,6})都尽可能地向左。
示例 2:

输入:[1,2,3,4,5,null,7] 输出:false 解释:值为 7 的结点没有尽可能靠向左侧。
提示:
- 树中将会有 1 到 100 个结点。
解法
Java
class Solution {
public boolean isCompleteTree(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (queue.peek() != null) {
TreeNode node = queue.poll();
queue.offer(node.left);
queue.offer(node.right);
}
while (!queue.isEmpty() && queue.peek() == null) {
queue.poll();
}
return queue.isEmpty();
}
}
961. 重复 N 次的元素
题目描述
在大小为 2N 的数组 A 中有 N+1 个不同的元素,其中有一个元素重复了 N 次。
返回重复了 N 次的那个元素。
示例 1:
输入:[1,2,3,3] 输出:3
示例 2:
输入:[2,1,2,5,3,2] 输出:2
示例 3:
输入:[5,1,5,2,5,3,5,4] 输出:5
提示:
4 <= A.length <= 100000 <= A[i] < 10000A.length为偶数
解法
Java
class Solution {
public int repeatedNTimes(int[] A) {
Set<Integer> set = new HashSet<>();
for (int e : A) {
if (set.contains(e)) {
return e;
}
set.add(e);
}
return 0;
}
}
973. 最接近原点的 K 个点
题目描述
我们有一个由平面上的点组成的列表 points。需要从中找出 K 个距离原点 (0, 0) 最近的点。
(这里,平面上两点之间的距离是欧几里德距离。)
你可以按任何顺序返回答案。除了点坐标的顺序之外,答案确保是唯一的。
示例 1:
输入:points = [[1,3],[-2,2]], K = 1 输出:[[-2,2]] 解释: (1, 3) 和原点之间的距离为 sqrt(10), (-2, 2) 和原点之间的距离为 sqrt(8), 由于 sqrt(8) < sqrt(10),(-2, 2) 离原点更近。 我们只需要距离原点最近的 K = 1 个点,所以答案就是 [[-2,2]]。
示例 2:
输入:points = [[3,3],[5,-1],[-2,4]], K = 2 输出:[[3,3],[-2,4]] (答案 [[-2,4],[3,3]] 也会被接受。)
提示:
1 <= K <= points.length <= 10000-10000 < points[i][0] < 10000-10000 < points[i][1] < 10000
解法
Java
import java.util.*;
/**
* @author Furaha Damien
*/
class Solution {
// Helper inner class
public class Point {
int x;
int y;
int distance;
public Point(int x, int y, int distance) {
this.x = x;
this.y = y;
this.distance = distance;
}
}
public int[][] kClosest(int[][] points, int K) {
PriorityQueue<Point> que = new PriorityQueue<Point>((a, b) -> (a.distance - b.distance));
int[][] res = new int[K][2];
for (int[] temp : points) {
int dist = (temp[0] * temp[0] + temp[1] * temp[1]);
que.offer(new Point(temp[0], temp[1], dist));
}
for (int i = 0; i < K; i++) {
Point curr = que.poll();
res[i][0] = curr.x;
res[i][1] = curr.y;
}
return res;
}
}
977. 有序数组的平方
题目描述
给定一个按非递减顺序排序的整数数组 A,返回每个数字的平方组成的新数组,要求也按非递减顺序排序。
示例 1:
输入:[-4,-1,0,3,10] 输出:[0,1,9,16,100]
示例 2:
输入:[-7,-3,2,3,11] 输出:[4,9,9,49,121]
提示:
1 <= A.length <= 10000-10000 <= A[i] <= 10000A已按非递减顺序排序。
解法
Java
class Solution {
public int[] sortedSquares(int[] A) {
for (int i = 0, n = A.length; i < n; ++i) {
A[i] = A[i] * A[i];
}
Arrays.sort(A);
return A;
}
}
978. 最长湍流子数组
题目描述
当 A 的子数组 A[i], A[i+1], ..., A[j] 满足下列条件时,我们称其为湍流子数组:
- 若
i <= k < j,当k为奇数时,A[k] > A[k+1],且当k为偶数时,A[k] < A[k+1]; - 或 若
i <= k < j,当k为偶数时,A[k] > A[k+1],且当k为奇数时,A[k] < A[k+1]。
也就是说,如果比较符号在子数组中的每个相邻元素对之间翻转,则该子数组是湍流子数组。
返回 A 的最大湍流子数组的长度。
示例 1:
输入:[9,4,2,10,7,8,8,1,9] 输出:5 解释:(A[1] > A[2] < A[3] > A[4] < A[5])
示例 2:
输入:[4,8,12,16] 输出:2
示例 3:
输入:[100] 输出:1
提示:
1 <= A.length <= 400000 <= A[i] <= 10^9
解法
Java
class Solution {
public int maxTurbulenceSize(int[] A) {
int res = 1;
int up = 1, down = 1;
for (int i = 1; i < A.length; ++i) {
if (A[i] > A[i - 1]) {
up = down + 1;
down = 1;
res = Math.max(res, up);
} else if (A[i] < A[i - 1]) {
down = up + 1;
up = 1;
res = Math.max(res, down);
} else {
up = 1;
down = 1;
}
}
return res;
}
}
987. 二叉树的垂序遍历
题目描述
给定二叉树,按垂序遍历返回其结点值。
对位于 (X, Y) 的每个结点而言,其左右子结点分别位于 (X-1, Y-1) 和 (X+1, Y-1)。
把一条垂线从 X = -infinity 移动到 X = +infinity ,每当该垂线与结点接触时,我们按从上到下的顺序报告结点的值( Y 坐标递减)。
如果两个结点位置相同,则首先报告的结点值较小。
按 X 坐标顺序返回非空报告的列表。每个报告都有一个结点值列表。
示例 1:
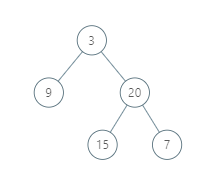输入:[3,9,20,null,null,15,7] 输出:[[9],[3,15],[20],[7]] 解释: 在不丧失其普遍性的情况下,我们可以假设根结点位于 (0, 0): 然后,值为 9 的结点出现在 (-1, -1); 值为 3 和 15 的两个结点分别出现在 (0, 0) 和 (0, -2); 值为 20 的结点出现在 (1, -1); 值为 7 的结点出现在 (2, -2)。
示例 2:
输入:[1,2,3,4,5,6,7] 输出:[[4],[2],[1,5,6],[3],[7]] 解释: 根据给定的方案,值为 5 和 6 的两个结点出现在同一位置。 然而,在报告 "[1,5,6]" 中,结点值 5 排在前面,因为 5 小于 6。
提示:
- 树的结点数介于
1和1000之间。 - 每个结点值介于
0和1000之间。
解法
Java
class Solution {
public List<List<Integer>> verticalTraversal(TreeNode root) {
List<int[]> list = new ArrayList<>();
dfs(root, 0, 0, list);
list.sort(new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
if (o1[0] != o2[0]) return Integer.compare(o1[0], o2[0]);
if (o1[1] != o2[1]) return Integer.compare(o2[1], o1[1]);
return Integer.compare(o1[2], o2[2]);
}
});
List<List<Integer>> res = new ArrayList<>();
int preX = 1;
for (int[] cur : list) {
if (preX != cur[0]) {
res.add(new ArrayList<>());
preX = cur[0];
}
res.get(res.size() - 1).add(cur[2]);
}
return res;
}
private void dfs(TreeNode root, int x, int y, List<int[]> list) {
if (root == null) {
return;
}
list.add(new int[]{x, y, root.val});
dfs(root.left, x - 1, y - 1, list);
dfs(root.right, x + 1, y - 1, list);
}
}
989. 数组形式的整数加法
题目描述
对于非负整数 X 而言,X 的数组形式是每位数字按从左到右的顺序形成的数组。例如,如果 X = 1231,那么其数组形式为 [1,2,3,1]。
给定非负整数 X 的数组形式 A,返回整数 X+K 的数组形式。
示例 1:
输入:A = [1,2,0,0], K = 34 输出:[1,2,3,4] 解释:1200 + 34 = 1234
示例 2:
输入:A = [2,7,4], K = 181 输出:[4,5,5] 解释:274 + 181 = 455
示例 3:
输入:A = [2,1,5], K = 806 输出:[1,0,2,1] 解释:215 + 806 = 1021
示例 4:
输入:A = [9,9,9,9,9,9,9,9,9,9], K = 1 输出:[1,0,0,0,0,0,0,0,0,0,0] 解释:9999999999 + 1 = 10000000000
提示:
1 <= A.length <= 100000 <= A[i] <= 90 <= K <= 10000- 如果
A.length > 1,那么A[0] != 0
解法
Java
class Solution {
public List<Integer> addToArrayForm(int[] A, int K) {
for (int i = A.length - 1; i >= 0 && K != 0; --i) {
K += A[i];
A[i] = K % 10;
K /= 10;
}
List<Integer> res = new ArrayList<>();
while (K != 0) {
res.add(K % 10);
K /= 10;
}
Collections.reverse(res);
for (int a : A) {
res.add(a);
}
return res;
}
}
999. 车的可用捕获量
题目描述
在一个 8 x 8 的棋盘上,有一个白色车(rook)。也可能有空方块,白色的象(bishop)和黑色的卒(pawn)。它们分别以字符 “R”,“.”,“B” 和 “p” 给出。大写字符表示白棋,小写字符表示黑棋。
车按国际象棋中的规则移动:它选择四个基本方向中的一个(北,东,西和南),然后朝那个方向移动,直到它选择停止、到达棋盘的边缘或移动到同一方格来捕获该方格上颜色相反的卒。另外,车不能与其他友方(白色)象进入同一个方格。
返回车能够在一次移动中捕获到的卒的数量。
示例 1:
输入:[[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".","R",".",".",".","p"],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."]] 输出:3 解释: 在本例中,车能够捕获所有的卒。
示例 2:

输入:[[".",".",".",".",".",".",".","."],[".","p","p","p","p","p",".","."],[".","p","p","B","p","p",".","."],[".","p","B","R","B","p",".","."],[".","p","p","B","p","p",".","."],[".","p","p","p","p","p",".","."],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."]] 输出:0 解释: 象阻止了车捕获任何卒。
示例 3:

输入:[[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".","p",".",".",".","."],["p","p",".","R",".","p","B","."],[".",".",".",".",".",".",".","."],[".",".",".","B",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".",".",".",".",".","."]] 输出:3 解释: 车可以捕获位置 b5,d6 和 f5 的卒。
提示:
board.length == board[i].length == 8board[i][j]可以是'R','.','B'或'p'- 只有一个格子上存在
board[i][j] == 'R'
解法
先找到 R 的位置,之后向“上、下、左、右”四个方向查找,累加结果。
Java
class Solution {
public int numRookCaptures(char[][] board) {
int[][] directions = { {-1, 0}, {1, 0}, {0, -1}, {0, 1} };
int res = 0;
for (int i = 0; i < 8; ++i) {
for (int j = 0; j < 8; ++j) {
if (board[i][j] == 'R') {
for (int[] direction : directions) {
res += search(board, i, j, direction);
}
return res;
}
}
}
return res;
}
private int search(char[][] board, int i, int j, int[] direction) {
while (i >= 0 && i < 8 && j >= 0 && j < 8) {
if (board[i][j] == 'B') return 0;
if (board[i][j] == 'p') return 1;
i += direction[0];
j += direction[1];
}
return 0;
}
}
1004. 最大连续 1 的个数 III
题目描述
给定一个由若干 0 和 1 组成的数组 A,我们最多可以将 K 个值从 0 变成 1 。
返回仅包含 1 的最长(连续)子数组的长度。
示例 1:
输入:A = [1,1,1,0,0,0,1,1,1,1,0], K = 2 输出:6 解释: [1,1,1,0,0,1,1,1,1,1,1] 粗体数字从 0 翻转到 1,最长的子数组长度为 6。
示例 2:
输入:A = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3 输出:10 解释: [0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1] 粗体数字从 0 翻转到 1,最长的子数组长度为 10。
提示:
1 <= A.length <= 200000 <= K <= A.lengthA[i]为0或1
解法
Java
class Solution {
public int longestOnes(int[] A, int K) {
int l = 0, r = 0;
while (r < A.length) {
if (A[r++] == 0) --K;
if (K < 0 && A[l++] == 0) ++K;
}
return r - l;
}
}
1008. 先序遍历构造二叉树
题目描述
返回与给定先序遍历 preorder 相匹配的二叉搜索树(binary search tree)的根结点。
(回想一下,二叉搜索树是二叉树的一种,其每个节点都满足以下规则,对于 node.left 的任何后代,值总 < node.val,而 node.right 的任何后代,值总 > node.val。此外,先序遍历首先显示节点的值,然后遍历 node.left,接着遍历 node.right。)
示例:
输入:[8,5,1,7,10,12] 输出:[8,5,10,1,7,null,12]
提示:
1 <= preorder.length <= 100- 先序
preorder中的值是不同的。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode bstFromPreorder(int[] preorder) {
if (preorder == null || preorder.length == 0) {
return null;
}
// 进入分治法的递归
return helper(preorder, 0, preorder.length - 1);
}
private TreeNode helper(int[] preorder, int start, int end) {
// System.out.println("start: " + start + " end: " + end);
// 确认递归结束的标志,当 start == end 时,表示该区间只剩下一个 subRoot 节点
if (start > end) {
return null;
}
if (start == end) {
return new TreeNode(preorder[start]);
}
// 前序遍历,首先遍历到的为根
TreeNode root = new TreeNode(preorder[start]);
int leftEnd = start;
while (leftEnd <= end) {
if (preorder[leftEnd] > preorder[start]) {
break;
}
leftEnd++;
}
// System.out.println("leftEnd:" + leftEnd + " num: " + preorder[leftEnd]);
root.left = helper(preorder, start + 1, leftEnd - 1);
root.right = helper(preorder, leftEnd, end);
return root;
}
}
1009. 十进制整数的反码
题目描述
每个非负整数 N 都有其二进制表示。例如, 5 可以被表示为二进制 "101",11 可以用二进制 "1011" 表示,依此类推。注意,除 N = 0 外,任何二进制表示中都不含前导零。
二进制的反码表示是将每个 1 改为 0 且每个 0 变为 1。例如,二进制数 "101" 的二进制反码为 "010"。
给你一个十进制数 N,请你返回其二进制表示的反码所对应的十进制整数。
示例 1:
输入:5 输出:2 解释:5 的二进制表示为 "101",其二进制反码为 "010",也就是十进制中的 2 。
示例 2:
输入:7 输出:0 解释:7 的二进制表示为 "111",其二进制反码为 "000",也就是十进制中的 0 。
示例 3:
输入:10 输出:5 解释:10 的二进制表示为 "1010",其二进制反码为 "0101",也就是十进制中的 5 。
提示:
0 <= N < 10^9- 本题与 476:https://leetcode-cn.com/problems/number-complement/ 相同
解法
Java
class Solution {
public int bitwiseComplement(int N) {
int ans = 0;
int index = -1;
if (N == 0) return 1;
if (N == 1) return 0;
while (N / 2 != 0) {
index++;
int temp = N % 2 == 0 ? 1 : 0;
if (temp == 1) {
ans += Math.pow(2, index);
}
N /= 2;
}
return ans;
}
}
1010. 总持续时间可被 60 整除的歌曲
题目描述
在歌曲列表中,第 i 首歌曲的持续时间为 time[i] 秒。
返回其总持续时间(以秒为单位)可被 60 整除的歌曲对的数量。形式上,我们希望索引的数字 i < j 且有 (time[i] + time[j]) % 60 == 0。
示例 1:
输入:[30,20,150,100,40] 输出:3 解释:这三对的总持续时间可被 60 整数: (time[0] = 30, time[2] = 150): 总持续时间 180 (time[1] = 20, time[3] = 100): 总持续时间 120 (time[1] = 20, time[4] = 40): 总持续时间 60
示例 2:
输入:[60,60,60] 输出:3 解释:所有三对的总持续时间都是 120,可以被 60 整数。
提示:
1 <= time.length <= 600001 <= time[i] <= 500
解法
Java
class Solution {
public int numPairsDivisibleBy60(int[] time) {
Arrays.sort(time);
int ans = 0;
for (int i = 0; i < time.length - 1; i++) {
int num = (time[i] + time[time.length - 1]) / 60;
while (num > 0) {
int key = num * 60;
int index = Arrays.binarySearch(time, i + 1, time.length, key - time[i]);
if (index >= 0) {
int temp = index;
ans++;
while (++temp < time.length && time[temp] == time[index]) {
ans++;
}
temp = index;
while (--temp > i && time[temp] == time[index]) {
ans++;
}
}
num--;
}
}
return ans;
}
}
十进制的反码
问题描述
每个非负整数 N 都有其二进制表示。例如, 5 可以被表示为二进制 "101",11 可以用二进制 "1011" 表示,依此类推。注意,除 N = 0 外,任何二进制表示中都不含前导零。
二进制的反码表示是将每个 1 改为 0 且每个 0 变为 1。例如,二进制数 "101" 的二进制反码为 "010"。
给定十进制数 N,返回其二进制表示的反码所对应的十进制整数。
示例 1:
输入:5
输出:2
解释:5 的二进制表示为 "101",其二进制反码为 "010",也就是十进制中的 2 。
示例 2:
输入:7
输出:0
解释:7 的二进制表示为 "111",其二进制反码为 "000",也就是十进制中的 0 。
示例 3:
输入:10
输出:5
解释:10 的二进制表示为 "1010",其二进制反码为 "0101",也就是十进制中的 5 。
提示:
0 <= N < 10^9
解法
求余数,取反(0 -> 1, 1 -> 0),累加结果。
注意 N = 0 的特殊情况。
class Solution {
public int bitwiseComplement(int N) {
if (N == 0) return 1;
int res = 0;
int exp = 0;
while (N != 0) {
int bit = N % 2 == 0 ? 1 : 0;
res += Math.pow(2, exp) * bit;
++exp;
N >>= 1;
}
return res;
}
}
1017. 负二进制转换
题目描述
给出数字 N,返回由若干 "0" 和 "1"组成的字符串,该字符串为 N 的负二进制(base -2)表示。
除非字符串就是 "0",否则返回的字符串中不能含有前导零。
示例 1:
输入:2 输出:"110" 解释:(-2) ^ 2 + (-2) ^ 1 = 2
示例 2:
输入:3 输出:"111" 解释:(-2) ^ 2 + (-2) ^ 1 + (-2) ^ 0 = 3
示例 3:
输入:4 输出:"100" 解释:(-2) ^ 2 = 4
提示:
0 <= N <= 10^9
解法
Java
class Solution {
public String baseNeg2(int N) {
if (N == 0) {
return "0";
}
StringBuilder sb = new StringBuilder();
while (N != 0) {
sb.append(N & 1);
N = -(N >> 1);
}
return sb.reverse().toString();
}
}
1019. 链表中的下一个更大节点
题目描述
给出一个以头节点 head 作为第一个节点的链表。链表中的节点分别编号为:node_1, node_2, node_3, ... 。
每个节点都可能有下一个更大值(next larger value):对于 node_i,如果其 next_larger(node_i) 是 node_j.val,那么就有 j > i 且 node_j.val > node_i.val,而 j 是可能的选项中最小的那个。如果不存在这样的 j,那么下一个更大值为 0 。
返回整数答案数组 answer,其中 answer[i] = next_larger(node_{i+1}) 。
注意:在下面的示例中,诸如 [2,1,5] 这样的输入(不是输出)是链表的序列化表示,其头节点的值为 2,第二个节点值为 1,第三个节点值为 5 。
示例 1:
输入:[2,1,5] 输出:[5,5,0]
示例 2:
输入:[2,7,4,3,5] 输出:[7,0,5,5,0]
示例 3:
输入:[1,7,5,1,9,2,5,1] 输出:[7,9,9,9,0,5,0,0]
提示:
- 对于链表中的每个节点,
1 <= node.val <= 10^9 - 给定列表的长度在
[0, 10000]范围内
解法
Java
class Solution {
public int[] nextLargerNodes(ListNode head) {
List<Integer> list = new ArrayList<>();
while (head != null) {
list.add(head.val);
head = head.next;
}
int[] res = new int[list.size()];
Deque<Integer> stack = new ArrayDeque<>();
for (int i = 0; i < list.size(); ++i) {
while (!stack.isEmpty() && list.get(i) > list.get(stack.peek())) {
res[stack.pop()] = list.get(i);
}
stack.push(i);
}
return res;
}
}
1021. 删除最外层的括号
题目描述
有效括号字符串为空 ("")、"(" + A + ")" 或 A + B,其中 A 和 B 都是有效的括号字符串,+ 代表字符串的连接。例如,"","()","(())()" 和 "(()(()))" 都是有效的括号字符串。
如果有效字符串 S 非空,且不存在将其拆分为 S = A+B 的方法,我们称其为原语(primitive),其中 A 和 B 都是非空有效括号字符串。
给出一个非空有效字符串 S,考虑将其进行原语化分解,使得:S = P_1 + P_2 + ... + P_k,其中 P_i 是有效括号字符串原语。
对 S 进行原语化分解,删除分解中每个原语字符串的最外层括号,返回 S 。
示例 1:
输入:"(()())(())" 输出:"()()()" 解释: 输入字符串为 "(()())(())",原语化分解得到 "(()())" + "(())", 删除每个部分中的最外层括号后得到 "()()" + "()" = "()()()"。
示例 2:
输入:"(()())(())(()(()))" 输出:"()()()()(())" 解释: 输入字符串为 "(()())(())(()(()))",原语化分解得到 "(()())" + "(())" + "(()(()))", 删除每隔部分中的最外层括号后得到 "()()" + "()" + "()(())" = "()()()()(())"。
示例 3:
输入:"()()" 输出:"" 解释: 输入字符串为 "()()",原语化分解得到 "()" + "()", 删除每个部分中的最外层括号后得到 "" + "" = ""。
提示:
S.length <= 10000S[i]为"("或")"S是一个有效括号字符串
解法
Java
class Solution {
public String removeOuterParentheses(String S) {
StringBuilder res = new StringBuilder();
int cnt = 0;
for (char c : S.toCharArray()) {
if (c == '(') {
if (++cnt > 1) {
res.append('(');
}
} else {
if (--cnt > 0) {
res.append(')');
}
}
}
return res.toString();
}
}
1022. 从根到叶的二进制数之和
题目描述
给出一棵二叉树,其上每个结点的值都是 0 或 1 。每一条从根到叶的路径都代表一个从最高有效位开始的二进制数。例如,如果路径为 0 -> 1 -> 1 -> 0 -> 1,那么它表示二进制数 01101,也就是 13 。
对树上的每一片叶子,我们都要找出从根到该叶子的路径所表示的数字。
以 10^9 + 7 为模,返回这些数字之和。
示例:
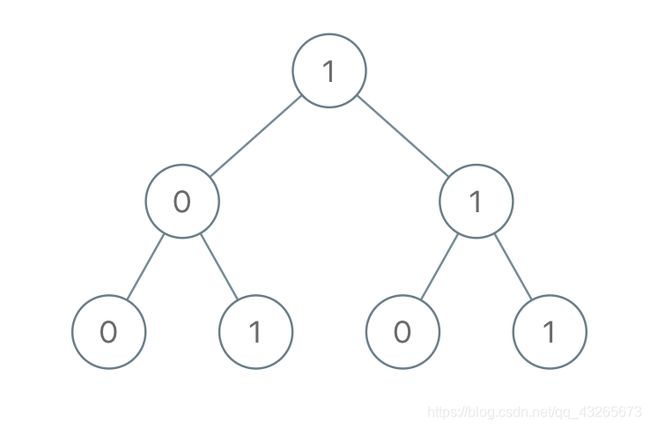
输入:[1,0,1,0,1,0,1] 输出:22 解释:(100) + (101) + (110) + (111) = 4 + 5 + 6 + 7 = 22
提示:
- 树中的结点数介于
1和1000之间。 - node.val 为
0或1。
解法
Java
class Solution {
public int sumRootToLeaf(TreeNode root) {
return dfs(root, 0);
}
private int dfs(TreeNode root, int s) {
if (root == null) {
return 0;
}
s = s << 1 | root.val;
if (root.left == null && root.right == null) {
return s;
}
return dfs(root.left, s) + dfs(root.right, s);
}
}
1025. 除数博弈
题目描述
爱丽丝和鲍勃一起玩游戏,他们轮流行动。爱丽丝先手开局。
最初,黑板上有一个数字 N 。在每个玩家的回合,玩家需要执行以下操作:
- 选出任一
x,满足0 < x < N且N % x == 0。 - 用
N - x替换黑板上的数字N。
如果玩家无法执行这些操作,就会输掉游戏。
只有在爱丽丝在游戏中取得胜利时才返回 True,否则返回 false。假设两个玩家都以最佳状态参与游戏。
示例 1:
输入:2 输出:true 解释:爱丽丝选择 1,鲍勃无法进行操作。
示例 2:
输入:3 输出:false 解释:爱丽丝选择 1,鲍勃也选择 1,然后爱丽丝无法进行操作。
提示:
1 <= N <= 1000
解法
Java
class Solution {
public boolean divisorGame(int N) {
return N % 2 == 0;
}
}
1026. 节点与其祖先之间的最大差值
题目描述
给定二叉树的根节点 root,找出存在于不同节点 A 和 B 之间的最大值 V,其中 V = |A.val - B.val|,且 A 是 B 的祖先。
(如果 A 的任何子节点之一为 B,或者 A 的任何子节点是 B 的祖先,那么我们认为 A 是 B 的祖先)
示例:

输入:[8,3,10,1,6,null,14,null,null,4,7,13] 输出:7 解释: 我们有大量的节点与其祖先的差值,其中一些如下: |8 - 3| = 5 |3 - 7| = 4 |8 - 1| = 7 |10 - 13| = 3 在所有可能的差值中,最大值 7 由 |8 - 1| = 7 得出。
提示:
- 树中的节点数在
2到5000之间。 - 每个节点的值介于
0到100000之间。
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int bfs(TreeNode root, int max, int min) {
if (root == null) {
return 0;
}
int res = Math.max(max - root.val, root.val - min);
int mx = Math.max(root.val, max);
int mn = Math.min(root.val, min);
res = Math.max(res, bfs(root.left, mx, mn));
res = Math.max(res, bfs(root.right, mx, mn));
return res;
}
public int maxAncestorDiff(TreeNode root) {
return bfs(root, root.val, root.val);
}
}
1029. 两地调度
题目描述
公司计划面试 2N 人。第 i 人飞往 A 市的费用为 costs[i][0],飞往 B 市的费用为 costs[i][1]。
返回将每个人都飞到某座城市的最低费用,要求每个城市都有 N 人抵达。
示例:
输入:[[10,20],[30,200],[400,50],[30,20]] 输出:110 解释: 第一个人去 A 市,费用为 10。 第二个人去 A 市,费用为 30。 第三个人去 B 市,费用为 50。 第四个人去 B 市,费用为 20。 最低总费用为 10 + 30 + 50 + 20 = 110,每个城市都有一半的人在面试。
提示:
1 <= costs.length <= 100costs.length为偶数1 <= costs[i][0], costs[i][1] <= 1000
解法
Java
class Solution {
public int twoCitySchedCost(int[][] costs) {
Arrays.sort(costs, (a, b) -> {
return a[0] - a[1] - (b[0] - b[1]);
});
int sum = 0;
for (int i = 0; i < costs.length; ++i) {
if (i < costs.length / 2) {
sum += costs[i][0];
} else {
sum += costs[i][1];
}
}
return sum;
}
}
1030. 距离顺序排列矩阵单元格
题目描述
给出 R 行 C 列的矩阵,其中的单元格的整数坐标为 (r, c),满足 0 <= r < R 且 0 <= c < C。
另外,我们在该矩阵中给出了一个坐标为 (r0, c0) 的单元格。
返回矩阵中的所有单元格的坐标,并按到 (r0, c0) 的距离从最小到最大的顺序排,其中,两单元格(r1, c1) 和 (r2, c2) 之间的距离是曼哈顿距离,|r1 - r2| + |c1 - c2|。(你可以按任何满足此条件的顺序返回答案。)
示例 1:
输入:R = 1, C = 2, r0 = 0, c0 = 0 输出:[[0,0],[0,1]] 解释:从 (r0, c0) 到其他单元格的距离为:[0,1]
示例 2:
输入:R = 2, C = 2, r0 = 0, c0 = 1 输出:[[0,1],[0,0],[1,1],[1,0]] 解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2] [[0,1],[1,1],[0,0],[1,0]] 也会被视作正确答案。
示例 3:
输入:R = 2, C = 3, r0 = 1, c0 = 2 输出:[[1,2],[0,2],[1,1],[0,1],[1,0],[0,0]] 解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2,2,3] 其他满足题目要求的答案也会被视为正确,例如 [[1,2],[1,1],[0,2],[1,0],[0,1],[0,0]]。
提示:
1 <= R <= 1001 <= C <= 1000 <= r0 < R0 <= c0 < C
解法
Java
class Solution {
class Node {
int r;
int c;
public Node(int r, int c) {
this.r = r;
this.c = c;
}
}
public int[][] allCellsDistOrder(int R, int C, int r0, int c0) {
int[][] ans = new int[R * C][2];
int[][] flag = new int[R][C];
int index = 0;
ans[index][0] = r0;
ans[index][1] = c0;
index++;
flag[r0][c0] = 1;
LinkedList<Node> queue = new LinkedList<>();
queue.add(new Node(r0, c0));
while (!queue.isEmpty()) {
Node node = queue.removeFirst();
// up
if (node.r - 1 >= 0 && flag[node.r - 1][node.c] != 1) {
queue.add(new Node(node.r - 1, node.c));
flag[node.r - 1][node.c] = 1;
ans[index][0] = node.r - 1;
ans[index][1] = node.c;
index++;
}
// down
if (node.r + 1 < R && flag[node.r + 1][node.c] != 1) {
queue.add(new Node(node.r + 1, node.c));
flag[node.r + 1][node.c] = 1;
ans[index][0] = node.r + 1;
ans[index][1] = node.c;
index++;
}
// left
if (node.c - 1 >= 0 && flag[node.r][node.c - 1] != 1) {
queue.add(new Node(node.r, node.c - 1));
flag[node.r][node.c - 1] = 1;
ans[index][0] = node.r;
ans[index][1] = node.c - 1;
index++;
}
// right
if (node.c + 1 < C && flag[node.r][node.c + 1] != 1) {
queue.add(new Node(node.r, node.c + 1));
flag[node.r][node.c + 1] = 1;
ans[index][0] = node.r;
ans[index][1] = node.c + 1;
index++;
}
}
return ans;
}
}
1033. 移动石子直到连续
题目描述
三枚石子放置在数轴上,位置分别为 a,b,c。
每一回合,我们假设这三枚石子当前分别位于位置 x, y, z 且 x < y < z。从位置 x 或者是位置 z 拿起一枚石子,并将该石子移动到某一整数位置 k 处,其中 x < k < z 且 k != y。
当你无法进行任何移动时,即,这些石子的位置连续时,游戏结束。
要使游戏结束,你可以执行的最小和最大移动次数分别是多少? 以长度为 2 的数组形式返回答案:answer = [minimum_moves, maximum_moves]
示例 1:
输入:a = 1, b = 2, c = 5 输出:[1, 2] 解释:将石子从 5 移动到 4 再移动到 3,或者我们可以直接将石子移动到 3。
示例 2:
输入:a = 4, b = 3, c = 2 输出:[0, 0] 解释:我们无法进行任何移动。
提示:
1 <= a <= 1001 <= b <= 1001 <= c <= 100a != b, b != c, c != a
解法
Java
class Solution {
public int[] numMovesStones(int a, int b, int c) {
int x = Math.min(a, Math.min(b, c));
int z = Math.max(a, Math.max(b, c));
int y = a + b + c - x - z;
int max = z - x - 2;
int min = y - x == 1 && z - y == 1 ? 0 : y - x <= 2 || z - y <= 2 ? 1 : 2;
return new int[]{min, max};
}
}
1034. 边框着色
题目描述
给出一个二维整数网格 grid,网格中的每个值表示该位置处的网格块的颜色。
只有当两个网格块的颜色相同,而且在四个方向中任意一个方向上相邻时,它们属于同一连通分量。
连通分量的边界是指连通分量中的所有与不在分量中的正方形相邻(四个方向上)的所有正方形,或者在网格的边界上(第一行/列或最后一行/列)的所有正方形。
给出位于 (r0, c0) 的网格块和颜色 color,使用指定颜色 color 为所给网格块的连通分量的边界进行着色,并返回最终的网格 grid 。
示例 1:
输入:grid = [[1,1],[1,2]], r0 = 0, c0 = 0, color = 3 输出:[[3, 3], [3, 2]]
示例 2:
输入:grid = [[1,2,2],[2,3,2]], r0 = 0, c0 = 1, color = 3 输出:[[1, 3, 3], [2, 3, 3]]
示例 3:
输入:grid = [[1,1,1],[1,1,1],[1,1,1]], r0 = 1, c0 = 1, color = 2 输出:[[2, 2, 2], [2, 1, 2], [2, 2, 2]]
提示:
1 <= grid.length <= 501 <= grid[0].length <= 501 <= grid[i][j] <= 10000 <= r0 < grid.length0 <= c0 < grid[0].length1 <= color <= 1000
解法
Java
class Solution {
private int[] dirs = new int[]{-1, 0, 1, 0, -1};
public int[][] colorBorder(int[][] grid, int r0, int c0, int color) {
boolean[][] vis = new boolean[grid.length][grid[0].length];
dfs(grid, r0, c0, color, vis);
return grid;
}
private void dfs(int[][] grid, int i, int j, int color, boolean[][] vis) {
vis[i][j] = true;
int oldColor = grid[i][j];
for (int k = 0; k < 4; ++k) {
int x = i + dirs[k], y = j + dirs[k + 1];
if (x >= 0 && x < grid.length && y >= 0 && y < grid[0].length) {
if (!vis[x][y]) {
if (grid[x][y] == oldColor) {
dfs(grid, x, y, color, vis);
} else {
grid[i][j] = color;
}
}
} else {
grid[i][j] = color;
}
}
}
}
1036. 逃离大迷宫
题目描述
在一个 10^6 x 10^6 的网格中,每个网格块的坐标为 (x, y),其中 0 <= x, y < 10^6。
我们从源方格 source 开始出发,意图赶往目标方格 target。每次移动,我们都可以走到网格中在四个方向上相邻的方格,只要该方格不在给出的封锁列表 blocked 上。
只有在可以通过一系列的移动到达目标方格时才返回 true。否则,返回 false。
示例 1:
输入:blocked = [[0,1],[1,0]], source = [0,0], target = [0,2] 输出:false 解释: 从源方格无法到达目标方格,因为我们无法在网格中移动。
示例 2:
输入:blocked = [], source = [0,0], target = [999999,999999] 输出:true 解释: 因为没有方格被封锁,所以一定可以到达目标方格。
提示:
0 <= blocked.length <= 200blocked[i].length == 20 <= blocked[i][j] < 10^6source.length == target.length == 20 <= source[i][j], target[i][j] < 10^6source != target
解法
Java
class Solution {
private static final int[] dx = {0, 0, -1, 1};
private static final int[] dy = {1, -1, 0, 0};
public boolean isEscapePossible(int[][] blocked, int[] source, int[] target) {
if (blocked.length < 2) {
return Boolean.TRUE;
}
return walk(blocked, source, target) && walk(blocked, target, source);
}
private Boolean walk(int[][] blocked, int[] source, int[] target) {
int N = 1000000;
Set<Pair<Integer, Integer>> visitSet = new HashSet<>();
Queue<Pair<Integer, Integer>> queue = new LinkedList<>();
Pair<Integer, Integer> start = new Pair<>(source[0], source[1]);
queue.add(start);
visitSet.add(start);
Set<Pair> blockedSet = Arrays.stream(blocked).map(item -> new Pair(item[0], item[1])).collect(Collectors.toSet());
while (!queue.isEmpty()) {
Pair<Integer, Integer> top = queue.poll();
Integer x = top.getKey();
Integer y = top.getValue();
for (int i = 0; i < 4; i++) {
int newY = y + dy[i];
int newX = x + dx[i];
Pair<Integer, Integer> pair = new Pair<>(newX, newY);
if (newX < 0 || newY < 0 || newX >= N || newY >= N || visitSet.contains(pair) || blockedSet.contains(pair)) {
continue;
}
queue.add(pair);
visitSet.add(pair);
if (queue.size() >= blocked.length || (newX == target[0] && newY == target[1])) {
return Boolean.TRUE;
}
}
}
return Boolean.FALSE;
}
}
1037. 有效的回旋镖
题目描述
回旋镖定义为一组三个点,这些点各不相同且不在一条直线上。
给出平面上三个点组成的列表,判断这些点是否可以构成回旋镖。
示例 1:
输入:[[1,1],[2,3],[3,2]] 输出:true
示例 2:
输入:[[1,1],[2,2],[3,3]] 输出:false
提示:
points.length == 3points[i].length == 20 <= points[i][j] <= 100
解法
Java
class Solution {
public boolean isBoomerang(int[][] points) {
double temp1;
double temp2;
double temp3;
Arrays.sort(points, new Comparator<int[]>() {
@Override
public int compare(int[] ints, int[] t1) {
return ints[0] - t1[0];
}
});
if (points[0][0] == points[1][0]) {
if (points[0][1] == points[1][1])
return false;
temp1 = 1;
} else {
temp1 = (points[0][1] - points[1][1]) * 1.0 / (points[0][0] - points[1][0]);
}
if (points[1][0] == points[2][0]) {
if (points[1][1] == points[2][1])
return false;
temp2 = 1;
} else {
temp2 = (points[1][1] - points[2][1]) * 1.0 / (points[1][0] - points[2][0]);
}
if (points[0][0] == points[2][0]) {
if (points[0][1] == points[2][1])
return false;
temp3 = 1;
} else {
temp3 = (points[0][1] - points[2][1]) * 1.0 / (points[0][0] - points[2][0]);
}
if (temp1 == temp2 && temp1 == temp3 && temp2 == temp3) {
return false;
} else {
return true;
}
}
}
1038. 从二叉搜索树到更大和树
题目描述
给出二叉 搜索 树的根节点,该二叉树的节点值各不相同,修改二叉树,使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
示例:

输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8] 输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
提示:
- 树中的节点数介于
1和100之间。 - 每个节点的值介于
0和100之间。 - 给定的树为二叉搜索树。
注意:该题目与 538: https://leetcode-cn.com/problems/convert-bst-to-greater-tree/ 相同
解法
Java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private int max = 0;
public TreeNode bstToGst(TreeNode root) {
if (root == null) return new TreeNode(0);
int temp = bstToGst(root.right).val;
root.val += (temp > max ? temp : max);
max = root.val > max ? root.val : max;
if (root.left != null) {
int temp2 = bstToGst(root.left.right).val;
root.left.val += max > temp2 ? max : temp2;
max = max > root.left.val ? max : root.left.val;
bstToGst(root.left.left);
}
return root;
}
}
1041. 困于环中的机器人
题目描述
在无限的平面上,机器人最初位于 (0, 0) 处,面朝北方。机器人可以接受下列三条指令之一:
"G":直走 1 个单位"L":左转 90 度"R":右转 90 度
机器人按顺序执行指令 instructions,并一直重复它们。
只有在平面中存在环使得机器人永远无法离开时,返回 true。否则,返回 false。
示例 1:
输入:"GGLLGG" 输出:true 解释: 机器人从 (0,0) 移动到 (0,2),转 180 度,然后回到 (0,0)。 重复这些指令,机器人将保持在以原点为中心,2 为半径的环中进行移动。
示例 2:
输入:"GG" 输出:false 解释: 机器人无限向北移动。
示例 3:
输入:"GL" 输出:true 解释: 机器人按 (0, 0) -> (0, 1) -> (-1, 1) -> (-1, 0) -> (0, 0) -> ... 进行移动。
提示:
1 <= instructions.length <= 100instructions[i]在{'G', 'L', 'R'}中
解法
Java
class Solution {
public boolean isRobotBounded(String instructions) {
int col = 0;
int row = 0;
char[] orders = instructions.toCharArray();
int order = 0;
for (int i = 0; i < 4; i++) {
for (char ch : orders) {
if (ch == 'L') {
order--;
if (order == -3) {
order = 1;
}
} else if (ch == 'R') {
order++;
if (order == 2) {
order = -2;
}
} else {
switch (order) {
case 0:
row++;
break;
case 1:
col++;
break;
case -1:
col--;
break;
case -2:
row--;
break;
default:
break;
}
}
}
if (col == 0 && row == 0) {
return true;
}
}
return false;
}
}
1043. 分隔数组以得到最大和
题目描述
给出整数数组 A,将该数组分隔为长度最多为 K 的几个(连续)子数组。分隔完成后,每个子数组的中的值都会变为该子数组中的最大值。
返回给定数组完成分隔后的最大和。
示例:
输入:A = [1,15,7,9,2,5,10], K = 3 输出:84 解释:A 变为 [15,15,15,9,10,10,10]
提示:
1 <= K <= A.length <= 5000 <= A[i] <= 10^6
解法
Java
class Solution {
public int maxSumAfterPartitioning(int[] A, int K) {
int[] dp = new int[A.length];
int max = 0;
for (int i = 0; i < A.length; i++) {
max = 0;
for (int k = 0; k < K && i - k >= 0; k++) {
max = Math.max(max, A[i - k]);
dp[i] = Math.max(dp[i], (i - 1 >= k ? dp[i - k - 1] : 0) + max * (k + 1));
}
}
return dp[A.length - 1];
}
}
1046. 最后一块石头的重量
题目描述
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块最重的石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
- 如果
x == y,那么两块石头都会被完全粉碎; - 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
提示:
1 <= stones.length <= 301 <= stones[i] <= 1000
解法
Java
class Solution {
public int lastStoneWeight(int[] stones) {
Queue<Integer> queue = new PriorityQueue<>(Comparator.reverseOrder());
for (int stone : stones) {
queue.offer(stone);
}
while (queue.size() > 1) {
int x = queue.poll();
int y = queue.poll();
if (x != y) {
queue.offer(x - y);
}
}
return queue.isEmpty() ? 0 : queue.poll();
}
}
1047. 删除字符串中的所有相邻重复项
题目描述
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
输入:"abbaca" 输出:"ca" 解释: 例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。
提示:
1 <= S.length <= 20000S仅由小写英文字母组成。
解法
Java
class Solution {
public String removeDuplicates(String S) {
char[] cs = new char[S.length()];
int top = -1;
for (char c : S.toCharArray()) {
if (top >= 0 && c == cs[top]) {
--top;
} else {
cs[++top] = c;
}
}
return String.valueOf(cs, 0, top + 1);
}
}
1048. 最长字符串链
题目描述
给出一个单词列表,其中每个单词都由小写英文字母组成。
如果我们可以在 word1 的任何地方添加一个字母使其变成 word2,那么我们认为 word1 是 word2 的前身。例如,"abc" 是 "abac" 的前身。
词链是单词 [word_1, word_2, ..., word_k] 组成的序列,k >= 1,其中 word_1 是 word_2 的前身,word_2 是 word_3 的前身,依此类推。
从给定单词列表 words 中选择单词组成词链,返回词链的最长可能长度。
示例:
输入:["a","b","ba","bca","bda","bdca"] 输出:4 解释:最长单词链之一为 "a","ba","bda","bdca"。
提示:
1 <= words.length <= 10001 <= words[i].length <= 16words[i]仅由小写英文字母组成。
解法
Java
class Solution {
public int longestStrChain(String[] words) {
Arrays.sort(words, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return Integer.compare(o1.length(), o2.length());
}
});
int res = 0;
Map<String, Integer> map = new HashMap<>();
for (String word : words) {
int x = 1;
for (int i = 0; i < word.length(); ++i) {
String pre = word.substring(0, i) + word.substring(i + 1);
x = Math.max(x, map.getOrDefault(pre, 0) + 1);
}
map.put(word, x);
res = Math.max(res, x);
}
return res;
}
}
1051. 高度检查器
题目描述
学校在拍年度纪念照时,一般要求学生按照 非递减 的高度顺序排列。
请你返回能让所有学生以 非递减 高度排列的最小必要移动人数。
注意,当一组学生被选中时,他们之间可以以任何可能的方式重新排序,而未被选中的学生应该保持不动。
示例:
输入:heights = [1,1,4,2,1,3] 输出:3 解释: 当前数组:[1,1,4,2,1,3] 目标数组:[1,1,1,2,3,4] 在下标 2 处(从 0 开始计数)出现 4 vs 1 ,所以我们必须移动这名学生。 在下标 4 处(从 0 开始计数)出现 1 vs 3 ,所以我们必须移动这名学生。 在下标 5 处(从 0 开始计数)出现 3 vs 4 ,所以我们必须移动这名学生。
示例 2:
输入:heights = [5,1,2,3,4] 输出:5
示例 3:
输入:heights = [1,2,3,4,5] 输出:0
提示:
1 <= heights.length <= 1001 <= heights[i] <= 100
解法
Java
class Solution {
public int heightChecker(int[] heights) {
int[] copy = Arrays.copyOf(heights, heights.length);
Arrays.sort(copy);
int res = 0;
for (int i = 0; i < heights.length; ++i) {
if (heights[i] != copy[i]) {
++res;
}
}
return res;
}
}
1052. 爱生气的书店老板
题目描述
今天,书店老板有一家店打算试营业 customers.length 分钟。每分钟都有一些顾客(customers[i])会进入书店,所有这些顾客都会在那一分钟结束后离开。
在某些时候,书店老板会生气。 如果书店老板在第 i 分钟生气,那么 grumpy[i] = 1,否则 grumpy[i] = 0。 当书店老板生气时,那一分钟的顾客就会不满意,不生气则他们是满意的。
书店老板知道一个秘密技巧,能抑制自己的情绪,可以让自己连续 X 分钟不生气,但却只能使用一次。
请你返回这一天营业下来,最多有多少客户能够感到满意的数量。
示例:
输入:customers = [1,0,1,2,1,1,7,5], grumpy = [0,1,0,1,0,1,0,1], X = 3 输出:16 解释: 书店老板在最后 3 分钟保持冷静。 感到满意的最大客户数量 = 1 + 1 + 1 + 1 + 7 + 5 = 16.
提示:
1 <= X <= customers.length == grumpy.length <= 200000 <= customers[i] <= 10000 <= grumpy[i] <= 1
解法
- 用
s累计不使用秘密技巧时,满意的顾客数; - 用
t计算大小为X的滑动窗口最多增加的满意的顾客数; - 结果即为
s+t。
Java
class Solution {
public int maxSatisfied(int[] customers, int[] grumpy, int X) {
// 用s累计不使用秘密技巧时,满意的顾客数
// 用t计算大小为X的滑动窗口最多增加的满意的顾客数
// 结果即为s+t
int s = 0, t = 0;
for (int i = 0, win = 0, n = customers.length; i < n; ++i) {
if (grumpy[i] == 0) {
s += customers[i];
} else {
win += customers[i];
}
if (i >= X && grumpy[i - X] == 1) {
win -= customers[i - X];
}
// 求滑动窗口的最大值
t = Math.max(t, win);
}
return s + t;
}
}
1053. 交换一次的先前排列
题目描述
给你一个正整数的数组 A(其中的元素不一定完全不同),请你返回可在 一次交换(交换两数字 A[i] 和 A[j] 的位置)后得到的、按字典序排列小于 A 的最大可能排列。
如果无法这么操作,就请返回原数组。
示例 1:
输入:[3,2,1] 输出:[3,1,2] 解释: 交换 2 和 1
示例 2:
输入:[1,1,5] 输出:[1,1,5] 解释: 这已经是最小排列
示例 3:
输入:[1,9,4,6,7] 输出:[1,7,4,6,9] 解释: 交换 9 和 7
示例 4:
输入:[3,1,1,3] 输出:[1,3,1,3] 解释: 交换 1 和 3
提示:
1 <= A.length <= 100001 <= A[i] <= 10000
解法
Java
class Solution {
public int[] prevPermOpt1(int[] A) {
for (int i = A.length - 2; i >= 0; --i) {
if (A[i] > A[i + 1]) {
int k = i + 1;
for (int j = k + 1; j < A.length; ++j) {
if (A[j] < A[i] && A[j] > A[k]) {
k = j;
}
}
int t = A[i];
A[i] = A[k];
A[k] = t;
return A;
}
}
return A;
}
}
1054. 距离相等的条形码
题目描述
在一个仓库里,有一排条形码,其中第 i 个条形码为 barcodes[i]。
请你重新排列这些条形码,使其中两个相邻的条形码 不能 相等。 你可以返回任何满足该要求的答案,此题保证存在答案。
示例 1:
输入:[1,1,1,2,2,2] 输出:[2,1,2,1,2,1]
示例 2:
输入:[1,1,1,1,2,2,3,3] 输出:[1,3,1,3,2,1,2,1]
提示:
1 <= barcodes.length <= 100001 <= barcodes[i] <= 10000
解法
Java
class Solution {
public int[] rearrangeBarcodes(int[] barcodes) {
Map<Integer, Integer> map = new HashMap<>();
for (int x : barcodes) {
map.put(x, map.getOrDefault(x, 0) + 1);
}
Data[] ds = new Data[map.size()];
int i = 0;
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
ds[i++] = new Data(entry.getKey(), entry.getValue());
}
Arrays.sort(ds);
i = 0;
for (Data d : ds) {
while (d.cnt-- > 0) {
barcodes[i] = d.x;
i += 2;
if (i >= barcodes.length) {
i = 1;
}
}
}
return barcodes;
}
class Data implements Comparable<Data> {
int x, cnt;
public Data(int x, int cnt) {
this.x = x;
this.cnt = cnt;
}
@Override
public int compareTo(Data o) {
return Integer.compare(o.cnt, cnt);
}
}
}
1071. 字符串的最大公因子
题目描述
对于字符串 S 和 T,只有在 S = T + ... + T(T 与自身连接 1 次或多次)时,我们才认定 “T 能除尽 S”。
返回最长字符串 X,要求满足 X 能除尽 str1 且 X 能除尽 str2。
示例 1:
输入:str1 = "ABCABC", str2 = "ABC" 输出:"ABC"
示例 2:
输入:str1 = "ABABAB", str2 = "ABAB" 输出:"AB"
示例 3:
输入:str1 = "LEET", str2 = "CODE" 输出:""
提示:
1 <= str1.length <= 10001 <= str2.length <= 1000str1[i]和str2[i]为大写英文字母
解法
Java
class Solution {
public String gcdOfStrings(String str1, String str2) {
if (!(str1 + str2).equals(str2 + str1)) {
return "";
}
int len = gcd(str1.length(), str2.length());
return str1.substring(0, len);
}
private int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
}
1072. 按列翻转得到最大值等行数
题目描述
给定由若干 0 和 1 组成的矩阵 matrix,从中选出任意数量的列并翻转其上的 每个 单元格。翻转后,单元格的值从 0 变成 1,或者从 1 变为 0 。
返回经过一些翻转后,行上所有值都相等的最大行数。
示例 1:
输入:[[0,1],[1,1]] 输出:1 解释:不进行翻转,有 1 行所有值都相等。
示例 2:
输入:[[0,1],[1,0]] 输出:2 解释:翻转第一列的值之后,这两行都由相等的值组成。
示例 3:
输入:[[0,0,0],[0,0,1],[1,1,0]] 输出:2 解释:翻转前两列的值之后,后两行由相等的值组成。
提示:
1 <= matrix.length <= 3001 <= matrix[i].length <= 300- 所有
matrix[i].length都相等 matrix[i][j]为0或1
解法
Java
class Solution {
public int maxEqualRowsAfterFlips(int[][] matrix) {
Map<String, Integer> map = new HashMap<>();
for (int[] row : matrix) {
if (row[0] == 1) {
for (int i = 0; i < row.length; ++i) {
row[i] ^= 1;
}
}
StringBuilder sb = new StringBuilder();
for (int x : row) {
sb.append(x);
}
String s = sb.toString();
map.put(s, map.getOrDefault(s, 0) + 1);
}
return map.values().stream().max(Integer::compareTo).get();
}
}
1073. 负二进制数相加
题目描述
给出基数为 -2 的两个数 arr1 和 arr2,返回两数相加的结果。
数字以 数组形式 给出:数组由若干 0 和 1 组成,按最高有效位到最低有效位的顺序排列。例如,arr = [1,1,0,1] 表示数字 (-2)^3 + (-2)^2 + (-2)^0 = -3。数组形式 的数字也同样不含前导零:以 arr 为例,这意味着要么 arr == [0],要么 arr[0] == 1。
返回相同表示形式的 arr1 和 arr2 相加的结果。两数的表示形式为:不含前导零、由若干 0 和 1 组成的数组。
示例:
输入:arr1 = [1,1,1,1,1], arr2 = [1,0,1] 输出:[1,0,0,0,0] 解释:arr1 表示 11,arr2 表示 5,输出表示 16 。
提示:
1 <= arr1.length <= 10001 <= arr2.length <= 1000arr1和arr2都不含前导零arr1[i]为0或1arr2[i]为0或1
解法
Java
class Solution {
public int[] addNegabinary(int[] arr1, int[] arr2) {
List<Integer> list = new ArrayList<>();
int carry = 0;
for (int i = arr1.length - 1, j = arr2.length - 1; i >= 0 || j >= 0 || carry != 0; --i, --j) {
carry += (i >= 0 ? arr1[i] : 0) + (j >= 0 ? arr2[j] : 0);
list.add(carry & 1);
carry = -(carry >> 1);
}
while (list.size() > 1 && list.get(list.size() - 1) == 0) {
list.remove(list.size() - 1);
}
Collections.reverse(list);
return list.stream().mapToInt(x -> x).toArray();
}
}
1074. 元素和为目标值的子矩阵数量
题目描述
给出矩阵 matrix 和目标值 target,返回元素总和等于目标值的非空子矩阵的数量。
子矩阵 x1, y1, x2, y2 是满足 x1 <= x <= x2 且 y1 <= y <= y2 的所有单元 matrix[x][y] 的集合。
如果 (x1, y1, x2, y2) 和 (x1', y1', x2', y2') 两个子矩阵中部分坐标不同(如:x1 != x1'),那么这两个子矩阵也不同。
示例 1:
输入:matrix = [[0,1,0],[1,1,1],[0,1,0]], target = 0 输出:4 解释:四个只含 0 的 1x1 子矩阵。
示例 2:
输入:matrix = [[1,-1],[-1,1]], target = 0 输出:5 解释:两个 1x2 子矩阵,加上两个 2x1 子矩阵,再加上一个 2x2 子矩阵。
提示:
1 <= matrix.length <= 3001 <= matrix[0].length <= 300-1000 <= matrix[i] <= 1000-10^8 <= target <= 10^8
解法
Java
class Solution {
public int numSubmatrixSumTarget(int[][] matrix, int target) {
int row = matrix.length, col = matrix[0].length;
int[][] sum = new int[row][col];
int ans = 0;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
if (i == 0 && j == 0) {
sum[i][j] = matrix[i][j];
} else if (i == 0) {
sum[i][j] = matrix[i][j] + sum[i][j - 1];
} else if (j == 0) {
sum[i][j] = matrix[i][j] + sum[i - 1][j];
} else {
sum[i][j] = matrix[i][j] - sum[i - 1][j - 1] + sum[i - 1][j] + sum[i][j - 1];
}
for (int k = 0; k <= i; k++) {
for (int l = 0; l <= j; l++) {
int main = (k != 0 && l != 0) ? sum[k - 1][l - 1] : 0;
int left = k != 0 ? sum[k - 1][j] : 0;
int up = l != 0 ? sum[i][l - 1] : 0;
if (sum[i][j] - left - up + main == target) {
ans++;
}
}
}
}
}
return ans;
}
}
1079. 活字印刷
题目描述
你有一套活字字模 tiles,其中每个字模上都刻有一个字母 tiles[i]。返回你可以印出的非空字母序列的数目。
示例 1:
输入:"AAB" 输出:8 解释:可能的序列为 "A", "B", "AA", "AB", "BA", "AAB", "ABA", "BAA"。
示例 2:
输入:"AAABBC" 输出:188
提示:
1 <= tiles.length <= 7tiles由大写英文字母组成
解法
Java
class Solution {
public int numTilePossibilities(String tiles) {
int[] cnt = new int[26];
for (char c : tiles.toCharArray()) {
++cnt[c - 'A'];
}
return dfs(cnt);
}
private int dfs(int[] cnt) {
int res = 0;
for (int i = 0; i < cnt.length; ++i) {
if (cnt[i] > 0) {
++res;
--cnt[i];
res += dfs(cnt);
++cnt[i];
}
}
return res;
}
}
1080. 根到叶路径上的不足节点
题目描述
给定一棵二叉树的根 root,请你考虑它所有 从根到叶的路径:从根到任何叶的路径。(所谓一个叶子节点,就是一个没有子节点的节点)
假如通过节点 node 的每种可能的 “根-叶” 路径上值的总和全都小于给定的 limit,则该节点被称之为「不足节点」,需要被删除。
请你删除所有不足节点,并返回生成的二叉树的根。
示例 1:

输入:root = [1,2,3,4,-99,-99,7,8,9,-99,-99,12,13,-99,14], limit = 1
输出:[1,2,3,4,null,null,7,8,9,null,14]
示例 2:
输入:root = [5,4,8,11,null,17,4,7,1,null,null,5,3], limit = 22
输出:[5,4,8,11,null,17,4,7,null,null,null,5]
示例 3:

输入:root = [5,-6,-6], limit = 0 输出:[]
提示:
- 给定的树有
1到5000个节点 -10^5 <= node.val <= 10^5-10^9 <= limit <= 10^9
解法
Java
class Solution {
public TreeNode sufficientSubset(TreeNode root, int limit) {
if (root == null) {
return null;
}
limit -= root.val;
if (root.left == null && root.right == null) {
return limit > 0 ? null : root;
}
root.left = sufficientSubset(root.left, limit);
root.right = sufficientSubset(root.right, limit);
return root.left == null && root.right == null ? null : root;
}
}
1081. 不同字符的最小子序列
题目描述
返回字符串 text 中按字典序排列最小的子序列,该子序列包含 text 中所有不同字符一次。
示例 1:
输入:"cdadabcc" 输出:"adbc"
示例 2:
输入:"abcd" 输出:"abcd"
示例 3:
输入:"ecbacba" 输出:"eacb"
示例 4:
输入:"leetcode" 输出:"letcod"
提示:
1 <= text.length <= 1000text由小写英文字母组成
注意:本题目与 316 https://leetcode-cn.com/problems/remove-duplicate-letters/ 相同
解法
Java
class Solution {
public String smallestSubsequence(String text) {
int[] cnt = new int[26];
for (char c : text.toCharArray()) {
++cnt[c - 'a'];
}
boolean[] vis = new boolean[26];
char[] cs = new char[text.length()];
int top = -1;
for (char c : text.toCharArray()) {
--cnt[c - 'a'];
if (!vis[c - 'a']) {
while (top >= 0 && c < cs[top] && cnt[cs[top] - 'a'] > 0) {
vis[cs[top--] - 'a'] = false;
}
cs[++top] = c;
vis[c - 'a'] = true;
}
}
return String.valueOf(cs, 0, top + 1);
}
}
1089. 复写零
题目描述
给你一个长度固定的整数数组 arr,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。
注意:请不要在超过该数组长度的位置写入元素。
要求:请对输入的数组 就地 进行上述修改,不要从函数返回任何东西。
示例 1:
输入:[1,0,2,3,0,4,5,0] 输出:null 解释:调用函数后,输入的数组将被修改为:[1,0,0,2,3,0,0,4]
示例 2:
输入:[1,2,3] 输出:null 解释:调用函数后,输入的数组将被修改为:[1,2,3]
提示:
1 <= arr.length <= 100000 <= arr[i] <= 9
解法
Java
class Solution {
public void duplicateZeros(int[] arr) {
int n = arr.length;
int i = 0, j = 0;
while (j < n) {
if (arr[i] == 0) ++j;
++i;
++j;
}
--i; // i 回到最后一次合法的位置
--j; // j 同理,但 j 仍可能等于 n(例如输入 [0])
while (i >= 0) {
if (j < n) arr[j] = arr[i];
if (arr[i] == 0) arr[--j] = arr[i];
--i;
--j;
}
}
}
1090. 受标签影响的最大值
题目描述
我们有一个项的集合,其中第 i 项的值为 values[i],标签为 labels[i]。
我们从这些项中选出一个子集 S,这样一来:
|S| <= num_wanted- 对于任意的标签
L,子集S中标签为L的项的数目总满足<= use_limit。
返回子集 S 的最大可能的 和。
示例 1:
输入:values = [5,4,3,2,1], labels = [1,1,2,2,3], num_wanted = 3, use_limit = 1
输出:9
解释:选出的子集是第一项,第三项和第五项。
示例 2:
输入:values = [5,4,3,2,1], labels = [1,3,3,3,2], num_wanted = 3, use_limit = 2
输出:12
解释:选出的子集是第一项,第二项和第三项。
示例 3:
输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 1
输出:16
解释:选出的子集是第一项和第四项。
示例 4:
输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 2
输出:24
解释:选出的子集是第一项,第二项和第四项。
提示:
1 <= values.length == labels.length <= 200000 <= values[i], labels[i] <= 200001 <= num_wanted, use_limit <= values.length
解法
Java
class Solution {
public int largestValsFromLabels(int[] values, int[] labels, int num_wanted, int use_limit) {
class Data implements Comparable<Data> {
int value, label;
public Data(int value, int label) {
this.value = value;
this.label = label;
}
@Override
public int compareTo(Data o) {
return Integer.compare(o.value, this.value);
}
}
int n = values.length;
Data[] ds = new Data[n];
for (int i = 0; i < n; ++i) {
ds[i] = new Data(values[i], labels[i]);
}
Arrays.sort(ds);
int[] map = new int[20001];
int res = 0;
for (int i = 0; i < n && num_wanted != 0; ++i) {
if (++map[ds[i].label] <= use_limit) {
res += ds[i].value;
--num_wanted;
}
}
return res;
}
}
1091. 二进制矩阵中的最短路径
题目描述
在一个 N × N 的方形网格中,每个单元格有两种状态:空(0)或者阻塞(1)。
一条从左上角到右下角、长度为 k 的畅通路径,由满足下述条件的单元格 C_1, C_2, ..., C_k 组成:
- 相邻单元格
C_i和C_{i+1}在八个方向之一上连通(此时,C_i和C_{i+1}不同且共享边或角) C_1位于(0, 0)(即,值为grid[0][0])C_k位于(N-1, N-1)(即,值为grid[N-1][N-1])- 如果
C_i位于(r, c),则grid[r][c]为空(即,grid[r][c] == 0)
返回这条从左上角到右下角的最短畅通路径的长度。如果不存在这样的路径,返回 -1 。
示例 1:
输入:[[0,1],[1,0]]

输出:2
示例 2:
输入:[[0,0,0],[1,1,0],[1,1,0]]
输出:4
提示:
1 <= grid.length == grid[0].length <= 100grid[i][j]为0或1
解法
Java
class Solution {
public int shortestPathBinaryMatrix(int[][] grid) {
int n = grid.length;
if (grid[0][0] == 1 || grid[n - 1][n - 1] == 1) {
return -1;
}
Queue<int[]> queue = new ArrayDeque<>();
boolean[][] vis = new boolean[n][n];
queue.offer(new int[]{0, 0});
vis[0][0] = true;
int[][] dirs = new int[][]{{0, 1}, {1, 1}, {1, 0}, {1, -1}, {0, -1}, {-1, -1}, {-1, 0}, {-1, 1}};
int res = 1;
while (!queue.isEmpty()) {
int size = queue.size();
while (size