Python基础语法面试题(内附答案),建议先收藏
1. 输入与输出
1.1 代码中要修改不可变数据会出现什么问题? 抛出什么异常?
代码不会正常运行,抛出 TypeError 异常。
1.2 a=1,b=2,不用中间变量交换 a 和 b 的值?
方法一:
1. a = a+b
2. b = a-b
3. a = a-b方法二:
1. a = a^b
2. b =b^a
3. a = a^b方法三:
1. a,b = b,a1.3 print 调用 Python 中底层的什么方法?
print 方法默认调用 sys.stdout.write 方法,即往控制台打印字符串。
1.4 下面这段代码的输出结果将是什么?请解释?
1. class Parent(object):
2. x = 1
3. class Child1(Parent):
4. pass
5. class Child2(Parent):
6. pass
7. print Parent.x, Child1.x, Child2.x
8. Child1.x = 2
9. print parent.x, Child1.x, Child2.x
10. parent.x = 3
11. print Parent.x, Child1.x, Child2.x结果为:
1 1 1 #继承自父类的类属性 x,所以都一样,指向同一块内存地址。
1 2 1 #更改 Child1,Child1 的 x 指向了新的内存地址。
3 2 3 #更改 Parent,Parent 的 x 指向了新的内存地址。
1.5 简述你对 input()函数的理解?
在 Python3 中,input()获取用户输入,不论用户输入的是什么,获取到的都是字符串类型的。
在 Python2 中有 raw_input()和 input(), raw_input()和 Python3 中的 input()作用是一样的,
input()输入的是什么数据类型的,获取到的就是什么数据类型的。
2. 条件与循环
2.1 阅读下面的代码,写出 A0,A1 至 An 的最终值。
1. A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
2. A1 = range(10)
3. A2 = [i for i in A1 if i in A0]
4. A3 = [A0[s] for s in A0]
5. A4 = [i for i in A1 if i in A3]
6. A5 = {i:i*i for i in A1}
7. A6 = [[i,i*i] for i in A1]答:
1. A0 = {'a': 1, 'c': 3, 'b': 2, 'e': 5, 'd': 4}
2. A1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
3. A2 = []
4. A3 = [1, 3, 2, 5, 4]
1. A4 = [1, 2, 3, 4, 5]
2. A5 = {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
3. A6 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36],[7, 49],[8, 64] [9,81]]2.2 Python2 中 range 和 xrange 的区别?
两者用法相同,不同的是 range 返回的结果是一个列表,而 xrange 的结果是一个生成器,前者是
直接开辟一块内存空间来保存列表,后者是边循环边使用,只有使用时才会开辟内存空间,所以当列表
很长时,使用 xrange 性能要比 range 好。
2.3 考虑以下 Python 代码,如果运行结束,命令行中的运行结果是什么?
1. l = []
2. for i in xrange(10):
3. l.append({‘num’:i})
4. print l在考虑以下代码,运行结束后的结果是什么?
1. l = []
2. a = {‘num’:0}
3. for i in xrange(10):
4. a[‘num’] = i
5. l.append(a)
6. print l以上两段代码的运行结果是否相同,如果不相同,原因是什么?
上方代码的结果:
1. [{‘num’:0},{‘num’:1},{‘num’:2},{‘num’:3},{‘num’:4},{‘num’:5},{‘num’:6},{‘num’:7},{‘num’:8},
{‘num’:9}]下方代码结果:
1. [{‘num’:9},{‘num’:9},{‘num’:9},{‘num’:9},{‘num’:9},{‘num’:9},{‘num’:9},{‘num’:9},{‘num’:9},
{‘num’:9}]原因是:字典是可变对象,在下方的 l.append(a)的操作中是把字典 a 的引用传到列表 l 中,当后
续操作修改 a[‘num’]的值的时候,l 中的值也会跟着改变,相当于浅拷贝。
2.4 以下 Python 程序的输出?
1. for i in range(5,0,-1):
2. print(i)答:5 4 3 2 1
3. 文件操作
3.1 4G 内存怎么读取一个 5G 的数据?
方法一:
可以通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后
在读取后面的 500MB 的数据。
方法二:
可以通过 linux 命令 split 切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行
数切割,可以按照文件大小切割。
3.2 现在考虑有一个 jsonline 格式的文件 file.txt 大小约为 10K,之前处理文件的
代码如下所示:
1. def get_lines():
2. l = []
3. with open(‘file.txt’,‘rb’) as f:
4. for eachline in f:
5. l.append(eachline)
6. return l
7. if __name__ == ‘__main__’:
8. for e in get_lines():
9. process(e) #处理每一行数据现在要处理一个大小为 10G 的文件,但是内存只有 4G,如果在只修改 get_lines 函数而其他代
码保持不变的情况下,应该如何实现?需要考虑的问题都有哪些?
1. def get_lines():
2. l = []
3. with open(‘file.txt’,’rb’) as f:
4. data = f.readlines(60000)
5. l.append(data)
6. yield l要考虑到的问题有:
内存只有 4G 无法一次性读入 10G 的文件,需要分批读入。分批读入数据要记录每次读入数据的位
置。分批每次读入数据的大小,太小就会在读取操作上花费过多时间。
3.3 read、readline 和 readlines 的区别?
read:读取整个文件。
readline:读取下一行,使用生成器方法。
readlines:读取整个文件到一个迭代器以供我们遍历。
3.4.补充缺失的代码?
1.def print_directory_contents(sPath):
2. """
3. 这个函数接收文件夹的名称作为输入参数
4. 返回该文件夹中文件的路径
5. 以及其包含文件夹中文件的路径
6. """
7. # 补充代码
8. ------------代码如下--------------------
9. import os
10. for sChild in os.listdir(sPath):
11. sChildPath = os.path.join(sPath, sChild)
12. if os.path.isdir(sChildPath):
13. print_directory_contents(sChildPath)
14. else:
15. print(sChildPath)4. 异常
4.1在except中return后还会不会执行finally中的代码?怎么抛出自定义异常?
会继续处理 finally 中的代码;用 raise 方法可以抛出自定义异常。
4.2 介绍一下 except 的作用和用法?
except: #捕获所有异常
except: <异常名>: #捕获指定异常
except:<异常名 1, 异常名 2> : 捕获异常 1 或者异常 2
except:<异常名>,<数据>:捕获指定异常及其附加的数据
except:<异常名 1,异常名 2>:<数据>:捕获异常名 1 或者异常名 2,及附加的数据
5. 模块与包
5.1 常用的 Python 标准库都有哪些
os 操作系统,time 时间,random 随机,pymysql 连接数据库,threading 线程,multiprocessing
进程,queue 队列。
第三方库:
django 和 flask 也是第三方库,requests,virtualenv,selenium,scrapy,xadmin,celery,
re,hashlib,md5。
常用的科学计算库(如 Numpy,Scipy,Pandas)。
5.2 赋值、浅拷贝和深拷贝的区别?
一、赋值
在 Python 中,对象的赋值就是简单的对象引用,这点和 C++不同,如下所示:
16.a = [1,2,"hello",['python', 'C++']]
17.b = a 在上述情况下,a 和 b 是一样的,他们指向同一片内存,b 不过是 a 的别名,是引用。
我们可以使用 b is a 去判断,返回 True,表明他们地址相同,内容相同,也可以使用 id()函数来查
看两个列表的地址是否相同。
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了对象的引用。也就是
说除了 b 这个名字之外,没有其他的内存开销。修改了 a,也就影响了 b,同理,修改了 b,也就影响了 a。
二、浅拷贝(shallow copy)
浅拷贝会创建新对象,其内容非原对象本身的引用,而是原对象内第一层对象的引用。
浅拷贝有三种形式:切片操作、工厂函数、copy 模块中的 copy 函数。
比如上述的列表 a;
切片操作:b = a[:] 或者 b = [x for x in a];
工厂函数:b = list(a);
copy 函数:b = copy.copy(a);
浅拷贝产生的列表 b 不再是列表 a 了,使用 is 判断可以发现他们不是同一个对象,使用 id 查看,
他们也不指向同一片内存空间。但是当我们使用 id(x) for x in a 和 id(x) for x in b 来查看 a 和 b 中元
素的地址时,可以看到二者包含的元素的地址是相同的。
在这种情况下,列表 a 和 b 是不同的对象,修改列表 b 理论上不会影响到列表 a。
但是要注意的是,浅拷贝之所以称之为浅拷贝,是它仅仅只拷贝了一层,在列表 a 中有一个嵌套的
list,如果我们修改了它,情况就不一样了。
比如:a[3].append('java')。查看列表 b,会发现列表 b 也发生了变化,这是因为,我们修改了嵌
套的 list,修改外层元素,会修改它的引用,让它们指向别的位置,修改嵌套列表中的元素,列表的地
址并未发生变化,指向的都是用一个位置。
三、深拷贝(deep copy)
深拷贝只有一种形式,copy 模块中的 deepcopy()函数。
深拷贝和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因此,它的时间和空
间开销要高。
同样的对列表 a,如果使用 b = copy.deepcopy(a),再修改列表 b 将不会影响到列表 a,即使嵌
套的列表具有更深的层次,也不会产生任何影响,因为深拷贝拷贝出来的对象根本就是一个全新的对象,
不再与原来的对象有任何的关联。
四、拷贝的注意点?
对于非容器类型,如数字、字符,以及其他的“原子”类型,没有拷贝一说,产生的都是原对象的
引用。
如果元组变量值包含原子类型对象,即使采用了深拷贝,也只能得到浅拷贝。
5.3__init__ 和__new__的区别?
init 在对象创建后,对对象进行初始化。
new 是在对象创建之前创建一个对象,并将该对象返回给 init。
5.4 Python 里面如何生成随机数?
在 Python 中用于生成随机数的模块是 random,在使用前需要 import. 如下例子可以酌情列
举:
random.random():生成一个 0-1 之间的随机浮点数;
random.uniform(a, b):生成[a,b]之间的浮点数;
random.randint(a, b):生成[a,b]之间的整数;
random.randrange(a, b, step):在指定的集合[a,b)中,以 step 为基数随机取一个数;
random.choice(sequence):从特定序列中随机取一个元素,这里的序列可以是字符串,列表,元组等。
5.5 输入某年某月某日,判断这一天是这一年的第几天?(可以用 Python 标准库)
1. import datetime
2. def dayofyear():
3. year = input("请输入年份:")
4. month = input("请输入月份:")
5. day = input("请输入天:")
6. date1 = datetime.date(year=int(year),month=int(month),day=int(day))
7. date2 = datetime.date(year=int(year),month=1,day=1)
8. return (date1 - date2 + 1).days5.6 打乱一个排好序的 list 对象 alist?
1. import random
2. random.shuffle(alist) 5.7 说明一下 os.path 和 sys.path 分别代表什么?
os.path 主要是用于对系统路径文件的操作。
sys.path 主要是对 Python 解释器的系统环境参数的操作(动态的改变 Python 解释器搜索路径)。
5.8 Python 中的 os 模块常见方法?
- os.remove()删除文件
- os.rename()重命名文件
- os.walk()生成目录树下的所有文件名
- os.chdir()改变目录
- os.mkdir/makedirs 创建目录/多层目录
- os.rmdir/removedirs 删除目录/多层目录
- os.listdir()列出指定目录的文件
- os.getcwd()取得当前工作目录
- os.chmod()改变目录权限
- os.path.basename()去掉目录路径,返回文件名
- os.path.dirname()去掉文件名,返回目录路径
- os.path.join()将分离的各部分组合成一个路径名
- os.path.split()返回(dirname(),basename())元组
- os.path.splitext()(返回 filename,extension)元组
- os.path.getatime\ctime\mtime 分别返回最近访问、创建、修改时间
- os.path.getsize()返回文件大小
- os.path.exists()是否存在
- os.path.isabs()是否为绝对路径
- os.path.isdir()是否为目录
- os.path.isfile()是否为文件
5.9 Python 的 sys 模块常用方法?
- sys.argv 命令行参数 List,第一个元素是程序本身路径
- sys.modules.keys() 返回所有已经导入的模块列表
- sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback 当前处理的异常详细信息
- sys.exit(n) 退出程序,正常退出时 exit(0)
- sys.hexversion 获取 Python 解释程序的版本值,16 进制格式如:0x020403F0
- sys.version 获取 Python 解释程序的版本信息
- sys.maxint 最大的 Int 值
- sys.maxunicode 最大的 Unicode 值
- sys.modules 返回系统导入的模块字段,key 是模块名,value 是模块
- sys.path 返回模块的搜索路径,初始化时使用 PYTHONPATH 环境变量的值
- sys.platform 返回操作系统平台名称
- sys.stdout 标准输出
- sys.stdin 标准输入
- sys.stderr 错误输出
- sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
- sys.exec_prefix 返回平台独立的 python 文件安装的位置
- sys.byteorder 本地字节规则的指示器,big-endian 平台的值是'big',little-endian 平台的值是'little'
- sys.copyright 记录 python 版权相关的东西
- sys.api_version 解释器的 C 的 API 版本
- sys.version_info 元组则提供一个更简单的方法来使你的程序具备 Python 版本要求功能
5.10 unittest 是什么?
在 Python 中,unittest 是 Python 中的单元测试框架。它拥有支持共享搭建、自动测试、在测试 中暂停代码、将不同测试迭代成一组,等的功能。
5.11 模块和包是什么?
在 Python 中,模块是搭建程序的一种方式。每一个 Python 代码文件都是一个模块,并可以引用其他的模块,比如对象和属性。
一个包含许多 Python 代码的文件夹是一个包。一个包可以包含模块和子文件夹。
6. Python 特性
6.1 Python 是强语言类型还是弱语言类型?
Python 是强类型的动态脚本语言。
强类型:不允许不同类型相加。
动态:不使用显示数据类型声明,且确定一个变量的类型是在第一次给它赋值的时候。
脚本语言:一般也是解释型语言,运行代码只需要一个解释器,不需要编译。
6.2 谈一下什么是解释性语言,什么是编译性语言?
计算机不能直接理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言编写的程序。
解释性语言在运行程序的时候才会进行翻译。
编译型语言写的程序在执行之前,需要一个专门的编译过程,把程序编译成机器语言(可执行文件)。
6.3 Python 中有日志吗?怎么使用?
有日志。
Python 自带 logging 模块,调用 logging.basicConfig()方法,配置需要的日志等级和相应的参数,
Python 解释器会按照配置的参数生成相应的日志。
6.4 Python 是如何进行类型转换的?
内建函数封装了各种转换函数,可以使用目标类型关键字强制类型转换,进制之间的转换可以用
int(‘str’,base=’n’)将特定进制的字符串转换为十进制,再用相应的进制转换函数将十进制转换为目标进制。
可以使用内置函数直接转换的有:
list---->tuple tuple(list)
tuple---->list list(tuple)
6.5 Python2 与 Python3 的区别?
1) 核心类差异
1. Python3 对 Unicode 字符的原生支持。
Python2 中使用 ASCII 码作为默认编码方式导致 string 有两种类型 str 和 unicode,Python3 只
支持 unicode 的 string。Python2 和 Python3 字节和字符对应关系为:

2. Python3 采用的是绝对路径的方式进行 import。
Python2 中相对路径的 import 会导致标准库导入变得困难(想象一下,同一目录下有 file.py,如
何同时导入这个文件和标准库 file)。Python3 中这一点将被修改,如果还需要导入同一目录的文件必
须使用绝对路径,否则只能使用相关导入的方式来进行导入。
3. Python2中存在老式类和新式类的区别,Python3统一采用新式类。新式类声明要求继承object,
必须用新式类应用多重继承。
4. Python3 使用更加严格的缩进。Python2 的缩进机制中,1 个 tab 和 8 个 space 是等价的,所
以在缩进中可以同时允许 tab 和 space 在代码中共存。这种等价机制会导致部分 IDE 使用存在问题。
Python3 中 1 个 tab 只能找另外一个 tab 替代,因此 tab 和 space 共存会导致报错:TabError:
inconsistent use of tabs and spaces in indentation.
2) 废弃类差异
1. print 语句被 Python3 废弃,统一使用 print 函数
2. exec 语句被 python3 废弃,统一使用 exec 函数
3. execfile 语句被 Python3 废弃,推荐使用 exec(open("./filename").read())
4. 不相等操作符"<>"被 Python3 废弃,统一使用"!="
5. long 整数类型被 Python3 废弃,统一使用 int
6. xrange 函数被 Python3 废弃,统一使用 range,Python3 中 range 的机制也进行修改并提高了
大数据集生成效率
7. Python3 中这些方法再不再返回 list 对象:dictionary 关联的 keys()、values()、items(),zip(),
map(),filter(),但是可以通过 list 强行转换:
1. mydict={"a":1,"b":2,"c":3}
2. mydict.keys() #
3. list(mydict.keys()) #['a', 'c', 'b'] 8. 迭代器 iterator 的 next()函数被 Python3 废弃,统一使用 next(iterator)
9. raw_input 函数被 Python3 废弃,统一使用 input 函数
10. 字典变量的 has_key 函数被 Python 废弃,统一使用 in 关键词
11. file 函数被 Python3 废弃,统一使用 open 来处理文件,可以通过 io.IOBase 检查文件类型
12. apply 函数被 Python3 废弃
13. 异常 StandardError 被 Python3 废弃,统一使用 Exception
3) 修改类差异
1. 浮点数除法操作符“
/”和“//”的区别
“
/ ”:
Python2:若为两个整形数进行运算,结果为整形,但若两个数中有一个为浮点数,则结果为
浮点数;
Python3:为真除法,运算结果不再根据参加运算的数的类型。
“//”:
Python2:返回小于除法运算结果的最大整数;从类型上讲,与"/"运算符返回类型逻辑一致。
Python3:和 Python2 运算结果一样。
2. 异常抛出和捕捉机制区别
Python2
1. raise IOError, "file error" #抛出异常
2. except NameError, err: #捕捉异常 Python3
1. raise IOError("file error") #抛出异常
2. except NameError as err: #捕捉异常3. for 循环中变量值区别
Python2,for 循环会修改外部相同名称变量的值
1. i = 1
2. print ('comprehension: ', [i for i in range(5)])
3. print ('after: i =', i )
#i=4 Python3,for 循环不会修改外部相同名称变量的值
1. i = 1
2. print ('comprehension: ', [i for i in range(5)])
3. print ('after: i =', i )
#i=1 4. round 函数返回值区别
Python2,round 函数返回 float 类型值
1. isinstance(round(15.5),int) #True Python3,round 函数返回 int 类型值
1. isinstance(round(15.5),float) #True 5. 比较操作符区别
Python2 中任意两个对象都可以比较
1. 11 < 'test' #TruePython3 中只有同一数据类型的对象可以比较
1. 11 < 'test' # TypeError: unorderable types: int() < str()4) 第三方工具包差异
我们在 pip 官方下载源 pypi 搜索 Python2.7 和 Python3.5 的第三方工具包数可以发现,Python2.7 版本对应的第三方工具类目数量是 28523,Python3.5 版本的数量是 12457,这两个版本在第三方工具包支持数量差距相当大。
我们从数据分析的应用角度列举了常见实用的第三方工具包(如下表),并分析这些工具包在Python2.7 和 Python3.5 的支持情况:
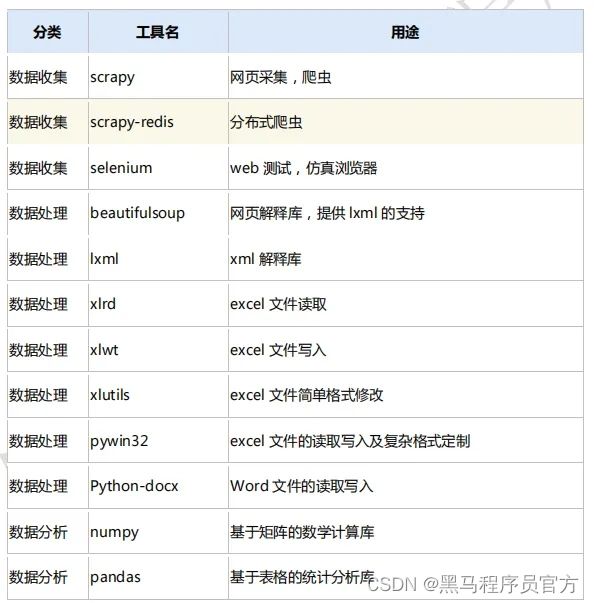

5) 工具安装问题
windows 环境
Python2 无法安装 mysqlclient。Python3 无法安装 MySQL-python、flup、functools32、Gooey、 Pywin32、 webencodings。
matplotlib 在 python3 环境中安装报错:The following required packages can not be built:freetype, png。需要手动下载安装源码包安装解决。 scipy 在 Python3 环境中安装报错,
numpy.distutils.system_info.NotFoundError,需要自己手 工下载对应的安装包,依赖 numpy,pandas 必须严格根据 python 版本、操作系统、64 位与否。运行 matplotlib 后发现基础包 numpy+mkl 安装失败,需要自己下载,国内暂无下载源
centos 环境下
Python2 无法安装 mysql-python 和 mysqlclient 包,报错:EnvironmentError: mysql_config not found,解决方案是安装 mysql-devel 包解决。使用 matplotlib 报错:no module named _tkinter, 安装 Tkinter、tk-devel、tc-devel 解决。
pywin32 也无法在 centos 环境下安装。
6.6 关于 Python 程序的运行方面,有什么手段能提升性能?
1、使用多进程,充分利用机器的多核性能
2、对于性能影响较大的部分代码,可以使用 C 或 C++编写
3、对于 IO 阻塞造成的性能影响,可以使用 IO 多路复用来解决
4、尽量使用 Python 的内建函数
5、尽量使用局部变量
6.7 Python 中的作用域?
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定。当 Python 遇到一个变量的话它会按照这的顺序进行搜索:
本地作用域(Local)--->当前作用域被嵌入的本地作用域(Enclosing locals)--->全局/模块作用域
(Global)--->内置作用域(Built-in)。
6.8 什么是 Python?
- Python 是一种编程语言,它有对象、模块、线程、异常处理和自动内存管理,可以加入其他语言的对比。
- Python 是一种解释型语言,Python 在代码运行之前不需要解释。
- Python 是动态类型语言,在声明变量时,不需要说明变量的类型。
- Python 适合面向对象的编程,因为它支持通过组合与继承的方式定义类。
- 在 Python 语言中,函数是第一类对象。
- Python 代码编写快,但是运行速度比编译型语言通常要慢。
- Python 用途广泛,常被用走"胶水语言",可帮助其他语言和组件改善运行状况。
- 使用 Python,程序员可以专注于算法和数据结构的设计,而不用处理底层的细节。
6.9 什么是 Python 自省?
Python 自省是 Python 具有的一种能力,使程序员面向对象的语言所写的程序在运行时,能够获得
对象的类 Python 型。Python 是一种解释型语言,为程序员提供了极大的灵活性和控制力。
6.10 什么是 Python 的命名空间?
在 Python 中,所有的名字都存在于一个空间中,它们在该空间中存在和被操作——这就是命名空间。它就好像一个盒子,每一个变量名字都对应装着一个对象。当查询变量的时候,会从该盒子里面寻找相应的对象。
6.11 你所遵循的代码规范是什么?请举例说明其要求?
PEP8 规范。
1. 变量
常量:大写加下划线 USER_CONSTANT。
私有变量 : 小写和一个前导下划线 _private_value。
Python 中不存在私有变量一说,若是遇到需要保护的变量,使用小写和一个前导下划线。但这只是程序员之间的一个约定,用于警告说明这是一个私有变量,外部类不要去访问它。但实际上,外部类还是可以访问到这个变量。
内置变量 : 小写,两个前导下划线和两个后置下划线 __class__
两个前导下划线会导致变量在解释期间被更名。这是为了避免内置变量和其他变量产生冲突。用户
定义的变量要严格避免这种风格。以免导致混乱。
2. 函数和方法
总体而言应该使用,小写和下划线。但有些比较老的库使用的是混合大小写,即首单词小写,之后
每个单词第一个字母大写,其余小写。但现在,小写和下划线已成为规范。
私有方法 :小写和一个前导下划线
这里和私有变量一样,并不是真正的私有访问权限。同时也应该注意一般函数不要使用两个前导下
划线(当遇到两个前导下划线时,Python 的名称改编特性将发挥作用)。
特殊方法 :小写和两个前导下划线,两个后置下划线
这种风格只应用于特殊函数,比如操作符重载等。
函数参数 : 小写和下划线,缺省值等号两边无空格
3. 类
类总是使用驼峰格式命名,即所有单词首字母大写其余字母小写。类名应该简明,精确,并足以从
中理解类所完成的工作。常见的一个方法是使用表示其类型或者特性的后缀,例如:
SQLEngine,MimeTypes 对于基类而言,可以使用一个 Base 或者 Abstract 前缀 BaseCookie,
AbstractGroup
4. 模块和包
除特殊模块 __init__ 之外,模块名称都使用不带下划线的小写字母。
若是它们实现一个协议,那么通常使用 lib 为后缀,例如:
import smtplib
import os
import sys
5. 关于参数
5.1 不要用断言来实现静态类型检测。断言可以用于检查参数,但不应仅仅是进行静态类型检测。
Python 是动态类型语言,静态类型检测违背了其设计思想。断言应该用于避免函数不被毫无意义的调
用。
5.2 不要滥用 *args 和 **kwargs。*args 和 **kwargs 参数可能会破坏函数的健壮性。它们使签
名变得模糊,而且代码常常开始在不应该的地方构建小的参数解析器。
6. 其他
6.1 使用 has 或 is 前缀命名布尔元素
is_connect = True
has_member = False
6.2 用复数形式命名序列
members = ['user_1', 'user_2']
6.3 用显式名称命名字典
person_address = {'user_1':'10 road WD', 'user_2' : '20 street huafu'}
6.4 避免通用名称
诸如 list, dict, sequence 或者 element 这样的名称应该避免。
6.5 避免现有名称
诸如 os, sys 这种系统已经存在的名称应该避免。
7. 一些数字
一行列数 : PEP 8 规定为 79 列。根据自己的情况,比如不要超过满屏时编辑器的显示列数。
一个函数 : 不要超过 30 行代码, 即可显示在一个屏幕类,可以不使用垂直游标即可看到整个函数。
一个类 : 不要超过 200 行代码,不要有超过 10 个方法。一个模块 不要超过 500 行。
8. 验证脚本
可以安装一个 pep8 脚本用于验证你的代码风格是否符合 PEP8。
7. Linux 基础和 git
7.1 Linux 的基本命令(怎么区分一个文件还是文件夹)
ls -F 在显示名称的时候会在文件夹后添加“
/”,在文件后面加“
*”。
7.2 日志以什么格式,存放在哪里?
日志以文本可以存储在“/var/log/”目录下后缀名为.log。
7.3 Linux 查看某个服务的端口?
1. netstat -anp | grep service_name 7.4 ubuntu 系统如何设置开机自启动一个程序?
直接修改/etc/rc0.d ~ /etc/rc6.d 和/etc/rcS.d 文件夹的内容,添加需启动的程序,S 开头的表示
启动,K 开头的表示不启动。
7.5 在 linux 中 find 和 grep 的区别
Linux 系统中 grep 命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep 全称是 Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
linux 下的 find:
功能:在目录结构中搜索文件,并执行指定的操作。此命令提供了相当多的查找条件,功能很强大。
语法:find 起始目录寻找条件操作
说明:find 命令从指定的起始目录开始,递归地搜索其各个子目录,查找满足寻找条件的文件并对
之采取相关的操作。
简单点说说,grep 是查找匹配条件的行,find 是搜索匹配条件的文件。
7.6 Linux 重定向命令有哪些?有什么区别?
1、重定向>
Linux 允许将命令执行结果重定向到一个文件,本应显示在终端上的内容保存到指定文件中。如:ls >
test.txt ( test.txt 如果不存在,则创建,存在则覆盖其内容 )。
2、重定向>>
>>这个是将输出内容追加到目标文件中。如果文件不存在,就创建文件;如果文件存在,则将新的
内容追加到那个文件的末尾,该文件中的原有内容不受影响。
7.7 软连接和硬链接的区别?
软连接类似 Windows 的快捷方式,当删除源文件时,那么软链接也失效了。硬链接可以理解为源
文件的一个别名,多个别名所代表的是同一个文件。当 rm 一个文件的时候,那么此文件的硬链接数减
1,当硬链接数为 0 的时候,文件被删除。
7.8 10 个常用的 Linux 命令?
pwd 显示工作路径
ls 查看目录中的文件
cd /home 进入 '/ home' 目录'
cd .. 返回上一级目录
cd ../.. 返回上两级目录
mkdir dir1 创建一个叫做 'dir1' 的目录'
rm -f file1 删除一个叫做 'file1' 的文件',-f 参数,忽略不存在的文件,从不给出提示。
rmdir dir1 删除一个叫做 'dir1' 的目录'
groupadd group_name 创建一个新用户组
groupdel group_name 删除一个用户组
tar -cvf archive.tar file1 创建一个非压缩的 tarball
tar -cvf archive.tar file1 file2 dir1 创建一个包含了 'file1', 'file2' 以及 'dir1'的档案文件
tar -tf archive.tar 显示一个包中的内容
tar -xvf archive.tar 释放一个包
tar -xvf archive.tar -C /tmp 将压缩包释放到 /tmp 目录下
tar -cvfj archive.tar.bz2 dir1 创建一个 bzip2 格式的压缩包
tar -xvfj archive.tar.bz2 解压一个 bzip2 格式的压缩包
tar -cvfz archive.tar.gz dir1 创建一个 gzip 格式的压缩包
tar -xvfz archive.tar.gz 解压一个 gzip 格式的压缩包
7.9 Linux 关机命令有哪些?

7.10 git 合并文件有冲突,如何处理?
1、git merge 冲突了,根据提示找到冲突的文件,解决冲突如果文件有冲突,那么会有类似的标记
2、修改完之后,执行 git add 冲突文件名
3、git commit 注意:没有-m 选项 进去类似于 vim 的操作界面,把 conflict 相关的行删除掉直接 push 就可以了,因为刚刚已经执行过相关 merge 操作了。