oracle12c使用笔记
目录
-
-
- 1. DCL(数据库控制语言)
-
- (1)连接
- (2)用户管理
- 2. DDL(数据库定义语言)
-
- (1)表
- (2)约束
- (3)索引
- (4)序列
- (5)视图
- 3. DML(数据库操作语言)
- 4. DQL(数据库查询语言)
-
- (1)业务查询
- (2)系统查询
- (3)分页查询
- (4)查看表锁的原因
- (5)查询低效的SQL
- (6)查看表空间大小及使用情况
- (7)查看各用户的各种资源占用,可以运行下面的SQL
- (8)列出使用频率最高的5个查询:
- (9)消耗磁盘读取最多的sql top5:
- (10)找出需要大量缓冲读取(逻辑读)操作的查询:
-
1. DCL(数据库控制语言)
(1)连接
--断开数据库连接
disconn
请求连接(输入用户密码后就能连接上数据库)
--conn
--启动数据库(数据库启动后才能做相关操作)
startup;
--只启动实例不挂载数据库
startup nomount;
--关闭数据库
shutdown;

(2)用户管理
根据安装数据库的类型不同,创建用户也有些许差异,执行下面语句,确认数据库的类型是否CDB
select name,cdb from v$database;
如果CDB的值为NO,表示创建的数据库类型是非容器数据库,创建用户不需要在用户名前加上C##,正常创建即可
--创建用户(创建用户必须要有创建用户的权限)
create user song identified by 123456;
或者
create user song identified by 123456 default tablespace users temporary tablespace temp;

如果CDB的值为YES,表示创建的数据库类型是容器数据库,创建用户需要在用户名前加上C##才行,不加C##会报错
--创建用户(创建用户必须要有创建用户的权限)
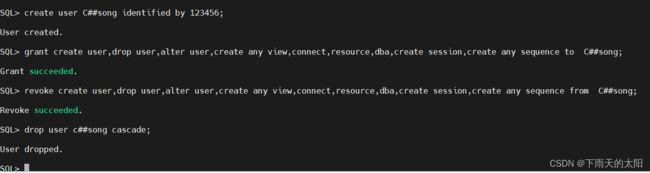
create user C##song identified by 123456;
或者
create user C##song identified by 123456 default tablespace users temporary tablespace temp;

修改用户密码
alter user c##song identified by 123456;
给用户授权
grant create user,drop user,alter user,create any view,connect,resource,dba,create session,create any sequence to C##song;
撤销权限
revoke create user,drop user,alter user,create any view,connect,resource,dba,create session,create any sequence from C##song;
删除用户(若用户拥有对象,则不能直接删除,否则将返回一个错误值。指定关键字cascade,可删除用户所有的对象,然后再删除用户)
drop user user_name cascade;
drop user c##song cascade;
2. DDL(数据库定义语言)
(1)表
--创建表
create table tb_student(
stu_num char(5) not null,
stu_name varchar2(50) not null,
stu_sex char(2) not null,
stu_age number(2),
stu_tel char(11)
);
--修改表名
alter table tb_student rename to tb_student2;
--删除表
drop table tb_student;
--增加列
alter table tb_student add stu_email varchar2(30);
--修改列
修改字段长度
alter table tb_student modify stu_email varchar2(50);
修改字段类型
alter table tb_student modify stu_email char(30);
--删除列
alter table tb_student drop column stu_email;
(2)约束
--创建表时添加主键约束
create table tb_student(
stu_num char(5) not null primary key,
stu_name varchar2(50) not null,
stu_sex char(2) not null,
stu_age number(2),
stu_tel char(11)
);
--或者是这样都可以
create table tb_student(
stu_num char(5) not null,
stu_name varchar2(50) not null,
stu_sex char(2) not null,
stu_age number(2),
stu_tel char(11),
primary key(stu_num)
);
--创建表以后再添加主键约束
alter table tb_student add constraints pk_stu_num primary key(stu_num);
--创建表时创建联合主键
create table tb_grade(
course_id char(3),
course_name varchar2(50),
stu_num char(5),
stu_name varchar2(50),
score number(3),
primary key(course_id,stu_num)
);
--或者是先创建表再创建联合主键
create table tb_grade(
course_id char(3),
course_name varchar2(50),
stu_num char(5),
stu_name varchar2(50),
score number(3)
);
alter table tb_grade add constraints pk_course_and_num primary key(course_id,stu_num);
--创建表时添加唯一约束
create table tb_student(
stu_num char(5) not null,
stu_name varchar2(50) not null,
stu_sex char(2) not null,
stu_age number(2),
stu_tel char(11),
constraint uq_stu_tel UNIQUE(stu_tel)
);
--创建表后添加唯一约束
alter table tb_student add constraints uq_stu_tel UNIQUE(stu_tel);
--删除唯一约束
alter table tb_student drop constraints uq_stu_tel;
--创建表后添加非空约束
alter table tb_student modify stu_name NOT NULL;
--取消非空约束
alter table tb_student modify stu_name NULL;
(3)索引
create index 索引名 on 表名(字段名)
--创建普通索引
create index index_stu_num on tb_student(stu_num);
--创建唯一索引
注意:一般主键会自带唯一索引
create unique index index_stu_num on tb_student(stu_num);
--创建联合索引
create index index_stu_num_tel on tb_student(stu_num,stu_tel);
--删除索引
drop index 索引名
drop index dex_stu_num;
(4)序列
序列主要是用于自增主键的,相当于MySQL里面的auto_increment(可以这样理解)
create sequence 序列名
--创建序列,默认无参数
create sequence mySequence;
--创建序列并定义起始值、步长、最大值、缓存(这里起始值为1,步长为1,最大值为10000,具体根据场景需要设置)
create sequence 序列名 start with 起始值 increment by 步长 minvalue 最小值 maxvalue 最大值 cache 缓存值 cycle 循环
create sequence mySequence start with 1 increment by 1;
create sequence mySequence start with 1 increment by 1 maxvalue 10000000;
--删除序列
drop sequence mySequence;
(5)视图
视图是一个虚表,它需要依赖表存在(不能独立存在),修改视图中的数据,它的基表的数据也会发生同样变化,修改基表的数据,视图的数据也会发生变化(除非数据不在视图中)
--创建简单视图
create view view_student as select stu_num,stu_name,stu_age from tb_student;
--覆盖原有视图(没有视图就创建,已有视图就覆盖)
create or replace view view_student as select stu_num,stu_name,stu_age from tb_student;
--创建只读视图
create or replace view view_student as select stu_num,stu_name,stu_age from tb_student with read only;
--创建复杂视图(语句中可能包含函数,分组,一个或多个表)
create or replace view emp_dep as select d.DEPARTMENT_ID as PARTMENT_ID,avg(e.SALARY) as salary_avg from EMPLOYEES e,DEPARTMENTS d where e.DEPARTMENT_ID = d.DEPARTMENT_ID group by d.DEPARTMENT_ID;
--查询视图中数据
select stu_num,stu_name,stu_age from view_student;
--更新视图中数据
update view_student set stu_name='张三' where stu_num = '00001';
--删除视图中数据
delete from view_student where stu_num = '00001';
--删除试图
drop view view_student;
注意:当视图定义中包含组函数、group by 子句、distinct、rownum其中之一时,不能使用delete
3. DML(数据库操作语言)
--向表中添加数据,这种方式可以指定插入哪些字段
insert into tb_student(stu_num,stu_name,stu_sex,stu_age,stu_tel) values('00001','张三','01',25,'13612345678');
--或者是,这种方式需要全字段插入
insert into tb_student values('00002','Lily','02',24,'13812345678');
--查询另一张表的结果插入到目标表中,两张表字段名称与类型匹配即可
insert into tb_student select * from tb_student2;
--在创建表时直接从其他表中导入,当然*也可以指定字段
create table tb_student3 as select * from tb_student;
--修改表中数据
update tb_student set stu_tel='13687654321' where stu_num='00001';
--删除数据
delete from tb_student where stu_num='00001';
--清空表数据
delete from tb_student2; //删除后可以恢复数据
truncate table tb_student3; //删除后不可以恢复数据
4. DQL(数据库查询语言)
(1)业务查询
--简单查询
查询所有列
select * from tb_student;
查询指定列
select stu_num,stu_name from tb_student;
--过滤查询
单个条件查询
select stu_num,stu_name from tb_student where stu_num = '00005';
多个条件查询
select stu_num,stu_name from tb_student where stu_num = '00005' and stu_name = '张三';
select stu_num,stu_name from tb_student where stu_num = '00005' or stu_name = '张三';
--分组查询
只分组不过滤
select stu_sex,count(*) from tb_student2 group by stu_sex;
先过滤再分组
select stu_sex,count(*) from tb_student2 where stu_age > 10 group by stu_sex;
先分组后过滤
select stu_sex,count(*) as count1 from tb_student2 group by stu_sex having stu_sex='01';
--排序查询
升序(默认是升序排列)
select stu_num,stu_name,stu_age,stu_tel from tb_student2 order by stu_age;
降序排列
select stu_num,stu_name,stu_age,stu_tel from tb_student2 order by stu_age desc;
--单个字段去重查询
select distinct stu_num from tb_student2;
--整个表的数据去重查询,如果stu_num字段只有普通索引,可以利用stu_num字段去重,当然*可以是指定的字段
select * from tb_student group by stu_num;
select stu_num,stu_name,stu_sex,stu_age,stu_tel from tb_student group by stu_num;
联表查询
内连接
左外连接
右外连接
全外连接
(2)系统查询
--查询当前用户有哪些表
select * from all_tables where owner='C##JAMY';
--查看表结构
desc tb_student2;
--查看所有用户
select * from all_users;
--查看所有DBA用户
select * from dba_users;
--查看当前用户
select * from user_users;
--设置当前用户密码永不过期
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;
--查看用户或角色系统权限(直接赋值给用户或角色的系统权限):
select * from dba_sys_privs;
--查看当前用户所拥有的权限
select * from user_sys_privs;
--只能查看登陆用户拥有的角色所包含的权限
select * from role_sys_privs;
--查看dba用户对象权限
select * from dba_tab_privs;
--查看所有用户对象权限
select * from all_tab_privs;
--查看当前用户对象权限
select * from user_tab_privs;
--查看用户或角色所拥有的角色
select * from dba_role_privs;
--查看当前用户或角色所拥有的角色
select * from user_role_privs;
--查看哪些用户有sysdba或sysoper系统权限(查询时需要相应权限)
select * from V$PWFILE_USERS;
--查询当前会话数
select count(*) from v$session;
--查询指定用户会话数
select count(*) from v$session where username='C##JAMY';
--查询所有会话
select * from v$session;
--查询指定用户的会话
select * from v$session where username='C##JAMY';
--查看被锁的表
select * from v$locked_object a, dba_objects b where b.object_id = a.object_id;
-- 查询oracle的最大连接数:
select * from v$parameter where name='processes';
--当前的连接数
select count(*) from v$process;
--数据库允许的最大连接数
select value from v$parameter where name = 'processes' ;
--日志文件位置
select * from V$diag_Info;
(3)分页查询
方式一(效率低):
select temp.LAST_NAME,temp.EMPLOYEE_ID,temp.SALARY
from (select rownum row_id,LAST_NAME,EMPLOYEE_ID,SALARY
from (select LAST_NAME,EMPLOYEE_ID,SALARY,rownum
from EMPLOYEES order by SALARY desc)) temp
where temp.row_id > 0 and temp.row_id <10;
方式二(效率高):
select temp.LAST_NAME,temp.EMPLOYEE_ID,temp.SALARY
from (select rownum row_id,LAST_NAME,EMPLOYEE_ID,SALARY
from (select LAST_NAME,EMPLOYEE_ID,SALARY,rownum
from EMPLOYEES order by SALARY desc) where rownum < 10) temp
where temp.row_id > 0;
(4)查看表锁的原因
select l.session_id sid,
s.serial#,
l.locked_mode,
l.oracle_username,
s.user#,
l.os_user_name,
s.machine,
s.terminal,
a.sql_text,
a.action from v$sqlarea a, v$session s, v$locked_object l
where l.session_id = s.sid and s.prev_sql_addr = a.address
order by sid,s.serial#;
(5)查询低效的SQL
SELECT EXECUTIONS, DISK_READS, BUFFER_GETS,
ROUND ((BUFFER_GETS-DISK_READS)/BUFFER_GETS, 2) Hit_radio,
ROUND (DISK_READS/EXECUTIONS, 2) Reads_per_run,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS>0
AND BUFFER_GETS > 0
AND (BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.8
ORDER BY 4 DESC;
(6)查看表空间大小及使用情况
SELECT a.tablespace_name "表空间名",
total "表空间大小",
free "表空间剩余大小",
(total - free) "表空间使用大小",
total / (1024 * 1024 * 1024) "表空间大小(G)",
free / (1024 * 1024 * 1024) "表空间剩余大小(G)",
(total - free) / (1024 * 1024 * 1024) "表空间使用大小(G)",
round((total - free) / total, 4) * 100 "使用率 %"
FROM (SELECT tablespace_name, SUM(bytes) free
FROM dba_free_space
GROUP BY tablespace_name) a,
(SELECT tablespace_name, SUM(bytes) total
FROM dba_data_files
GROUP BY tablespace_name) b
WHERE a.tablespace_name = b.tablespace_name;
(7)查看各用户的各种资源占用,可以运行下面的SQL
select se.SID, ses.username, ses.osuser, n.NAME, se.VALUE
from v$statname n, v$sesstat se, v$session ses
where n.statistic# = se.statistic# and
se.sid = ses.sid and
ses.username is not null and
n.name in ('CPU used by this session',
'db block gets',
'consistent gets',
'physical reads',
'free buffer requested',
'table scans (long tables)',
'table scan rows gotten',
'sorts (memory)',
'sorts (disk)',
'sorts (rows)',
'session uga memory max' ,
'session pga memory max')
order by sid, n.statistic#;
(8)列出使用频率最高的5个查询:
select sql_text,executions
from (select sql_text,executions,
rank() over
(order by executions desc) exec_rank
from v$sql)
where exec_rank <=5;
(9)消耗磁盘读取最多的sql top5:
select disk_reads,sql_text
from (select sql_text,disk_reads,
dense_rank() over
(order by disk_reads desc) disk_reads_rank
from v$sql)
where disk_reads_rank <=5;
(10)找出需要大量缓冲读取(逻辑读)操作的查询:
select buffer_gets,sql_text
from (select sql_text,buffer_gets,
dense_rank() over
(order by buffer_gets desc) buffer_gets_rank
from v$sql)
where buffer_gets_rank<=5;