完全小白篇-用python爬取豆瓣电影影评
完全小白篇-用python爬取豆瓣影评
- 打开豆瓣电影
-
- 随机电影的所有影评网页
- 跳转逻辑
- 分析影评内容获取方法
- 逐一正则提取影评
-
- 针对标签格式过于多样的处理
- 针对提出请求的频率的限制
- 存储方式(本次sqlite3)
- 附:豆瓣短评的正则提取逻辑
python爬虫5天速成
这一个项目其实是受B站的课程启发的,里面讲述了用python爬取豆瓣评分top250的各类信息,这也是我最初选择学习爬虫的启蒙教程。另外一点就是和爬网络小说也比较像,用python爬取网络小说因为是最最单纯的爬取文本数据
所以就有这一次我自己想到的项目:爬取任意豆瓣电影的所有影评。
打开豆瓣电影
随机电影的所有影评网页
本次打开的是《信条》
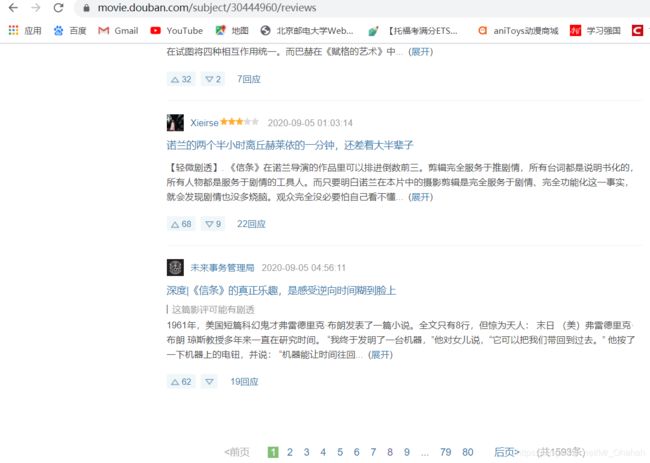
影评是实时更新的(本图发布时间是2020/9/7 8:47),从表面来看各个影评摘要部分摆在这个网页还是相当整齐的,这对于正则提取来说相对友好。
第x页其实是基于每一页都只存放20条影评摘要的,实际上我们对网页栏写入"?start=x"就会令豆瓣服务器返回一个从第x条影评摘要开始的网页:

我们检查网页源代码,在中间部分会发现各个存放摘要信息的盒子:

跳转逻辑
分析一下当前这种页面的特点:
- 每一页固定只有20条影评摘要
- 每一条影评摘要都会相对应有一个a标签以供跳转到影评人具体影评
- 可以通过"start="来获取指定序列的网页
所以我们可以制定一个基本爬取方案:
1. 获取该电影影评网站的网页源代码
2. 正则提取a标签跳转链接(并存入一个列表)
3. 根据列表跳转到具体影评人影评,获取那个页面的源代码
4. 从中正则提取需要的内容
5. 寻找方法存储提取的内容
分析影评内容获取方法
我们打开第一个影评人的影评,并检查源代码:

他的网页其实已经相当复杂了,因为我们不仅仅要剔除什么样式也没有的p标签,还要针对性去处理有data-page、data-align样式的p标签。(先用个小本本记下来这些特点)
我们再打开另几个影评的源代码。下图是第三篇影评的形式:

他居然还会在p标签里内置span标签另加样式。。。所以我们的任务就额外多了一个去除span标签
往下翻几条,发现所有的网页无外乎就以上几种了:
- 啥内容也没有的p标签
- 有data-page="0"样式的p标签
- 有 data-align="" 或 data-align=“left” 的p标签
- data-page和data-align两种样式都有的p标签
- p标签里内置的span标签(且一旦有居然都是< span style=“font-weight: bold;” >这样的标签)
逐一正则提取影评
针对标签格式过于多样的处理
由于每个网页的提取规则都不同,实在难以实现可移植性高的代码,所以只能针对这个项目针对性地写代码调整:
- 正则提取所有p标签内容
- 将内容化为string形式并删除< p data-align data-page>、< span style=“font-weight: bold;” >这样的东西
- 整合好每一篇标题+影评,进行存储
针对提出请求的频率的限制
豆瓣的反爬虫这么严格了现在?
豆瓣也是多少年的老网站了,反爬机制估计也是很成熟,实际情况就是,经过试验,全功率无限制运行程序(while循环速度)会导致豆瓣在你爬到第40篇时就对你的IP关闭服务,设置1s一次请求的话会在140篇的位置对你的IP关闭服务,2s一次请求的话会在520-530篇对你的IP关闭服务。3s相对安全,能爬1080左右的影评,4s一次请求不用担心访问被拒的。
方法很简单,调用python自带 time 库的 time.sleep() 函数即可
存储方式(本次sqlite3)
干爬不存有点浪费这个项目。本次采用创建+写数据库的形式存储爬取的信息。因为内容很多所以采用边爬边存
- 调用sqlite3库
import sqlite3 - 在程序运行最开始创建这个数据库:
# 删除先前的数据库方便直接建表
if os.path.exists("TENET.db"):
os.remove("TENET.db")
# 连接数据库
TENET = sqlite3.connect("TENET.db")
c = TENET.cursor() #游标
sql = '''
create table Review
(
id int primary key,
title text not null,
review text nut null
);
'''
c.execute(sql) # 执行sql操作
TENET.commit() # 提交数据库操作
TENET.close() # 关闭数据库
- 每当获取好一个影评,就调用插入当前表单:
# 调用saveData([j,title,text])
def saveData(review_text):
TENET = sqlite3.connect("TENET.db")
c = TENET.cursor() #游标
print("写入影评:"+str(review_text[0]))
# 利用占位符方式写入表单
c.execute("insert into Review values(?,?,?)", (review_text[0]+1,review_text[1],review_text[2]))
TENET.commit() # 提交数据库操作
TENET.close() # 关闭数据库
完整代码:
from bs4 import BeautifulSoup #网页解析,数据获取
import os
import re #正则表达式,文字匹配
import urllib.request,urllib.error,urllib.parse #指定url,获取网页数据
import sqlite3
import time
# 影评跳转链接匹配
findLink = re.compile(r'.*
',re.S) # 指定规则,创建正则表达式对象
# 影评标题匹配
findTitle = re.compile(r'(.*?)',re.S)
# re.S防止换行符影响我们提取
# 根据指定url获取网页html源代码
def getHtml(baseurl):
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.46 (KHTML, like Gecko) Chrome/83.0.4133.126 Safari/537.46"
# cookie信息如果你真想以一个登陆用户身份访问网页的话就写上
}
# 向豆瓣服务器发送请求
req = urllib.request.Request(url=baseurl, headers=head)
html=""
# 为了在受到反爬系统反制时及时收手,采用try方式,如果访问失败直接返回空字符串协助main函数跳出循环
try:
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "reason"):
print(e.reason)
else:
print("访问发生了其他错误")
html=""
return html
def saveData(review_text):
TENET = sqlite3.connect("TENET.db")
c = TENET.cursor() #游标
print("写入影评:"+str(review_text[0]))
c.execute("insert into Review values(?,?,?)", (review_text[0]+1,review_text[1],review_text[2]))
TENET.commit() #提交数据库操作
TENET.close() #关闭数据库
def main():
if os.path.exists("TENET.db"):
os.remove("TENET.db")
TENET = sqlite3.connect("TENET.db")
print("数据库连接完成")
c = TENET.cursor() #游标
sql = '''
create table Review
(
id int primary key,
title text not null,
review text nut null
);
'''
c.execute(sql)
TENET.commit() #提交数据库操作
TENET.close() #关闭数据库
baseurl = "https://movie.douban.com/subject/30444960/reviews?start="
i = 0
j = 0
# 1000+影评运行时间会在1h左右,也许就会产生新一整页影评。所以不用for循环,直接上while
running = True
# 获取《信条》影评网页源代码信息
while running:
# 以20为单位相当于在跳转到“第几页”
html = getHtml(baseurl+str(i*20))
if html!="":
# 逐一解析影评页面每一个标签
soup = BeautifulSoup(html,'html.parser')
# 用于记录所有具体影评链接
a_href_data = []
for item in soup.find_all('div',class_="main-bd"):
item = str(item)
link = re.findall(findLink, item)[0]
a_href_data.append(link)
# 接下来开始访问所有影评网页
for url in a_href_data:
# 我太菜了,反反爬只能用此下等卑微的措施
time.sleep(4)
# 获取单个影评网页源代码信息
html = getHtml(url)
# 逐一解析一个影评的每一个标签
soup = BeautifulSoup(html,'html.parser')
# 标题
title = ""
for item in soup.find_all('h1'):
item = str(item)
title = re.findall(findTitle, item)[0]
title = re.sub("\n","",title)
# 找内容所在的盒子
for item in soup.find_all('div',id="link-report"):
item = str(item)
# 影评内容
text = ""
# 一个影评盒子内的p标签们全部由soup处理
soup_content = BeautifulSoup(item,'html.parser')
# 针对所有p标签内容
for item_content in soup_content.find_all('p'):
item_content = str(item_content)
# 针对span标签的额外处理
item_content = re.sub(r'',"",item_content) # 删除span
item_content = re.sub(''," ",item_content) # 删除span
item_content = re.sub(r'' ,"",item_content) # 删除有样式的p报签
item_content = re.sub(''
,"",item_content) # 删除没样式的p标签
item_content = re.sub(''," ",item_content) # 删除p标签
# 写影评
if item_content!="":
text+=item_content+"\n"
print(title+" 已获取完成")
# 存入数据库
saveData([j,title,text])
j+=1
i+=1
else:
running = False
# os.system("pause")
if __name__ == "__main__":
main()
附:豆瓣短评的正则提取逻辑

如果你真的对大数据有兴趣的话建议学一些做词云图之类的东西