爬虫实战——豆瓣电影短评爬取
目录
- 一、任务概述
-
- 心路历程
- 方案制定
- 二、正式开工
-
- 准备工作
- 处理 json 数据获取电影 id
- 处理短评 html 源码
- 三、全部代码
- 用Access后续处理
一、任务概述
爬取豆瓣电影中2020年中国大陆的电影影评。
心路历程
在豆瓣电影分类栏里面,选取相应的标签(电影、中国大陆、2020),可以看到如下页面。

由于20部电影远达不到数据要求,不禁想要点击最下方的加载更多:鼠标右键->检查元素,切换到network选项,将页面滚动到最下方,点击加载更多。
会在network栏中出现一个网络请求,具体地址如下:https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=电影&start=20&countries=中国大陆&year_range=2020,2020
copy它的链接地址,粘贴并转到,可以获得如下页面。
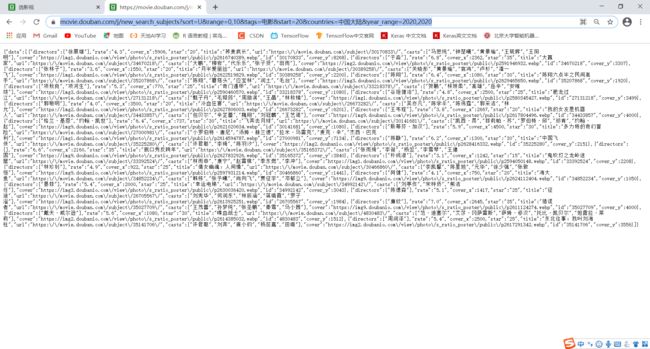
不难发现,该请求得到的内容中,包含了一系列的电影信息,以json的格式返回,内容截取部分整理后如下:
{
"data":
[
{
"directors":["徐展雄"],
"rate":"4.3",
"cover_x":5906,
"star":"20",
"title":"荞麦疯长",
"url":"https:\/\/movie.douban.com\/subject\/30170833\/",
"casts":["马思纯","钟楚曦","黄景瑜","王砚辉","王阳明"],
"cover":"https://img1.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2616740389.webp",
"id":"30170833",
"cover_y":8268
},
...
...
...
]
}
学过一点英语同时通过对比原来的页面可以推测出各个标签所代表的含义:
- “directors”:导演名单数组
- “rate”:评分
- “cover_x”:封面图片宽度
- “star”:我不清楚
- “title”:电影名
- “url”:页面地址
- “casts”:主演名单数组
- “cover”:封面地址
- “id”:id标识
- “cover_y”:封面图片长度
其中,链接中:
https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=电影&start=20&countries=中国大陆&year_range=2020,2020
start=20 这个参数引起了我的兴趣,修改它的值为0,发现得到的第一个数据就是“送你一朵小红花”,即原页面中的第一个电影。可以确认该参数代表着搜索的起始值。
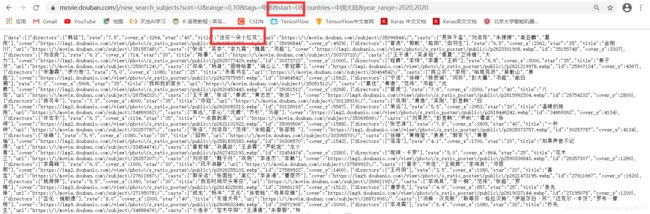
并且我们不难发现电影地址与 id 的关系。
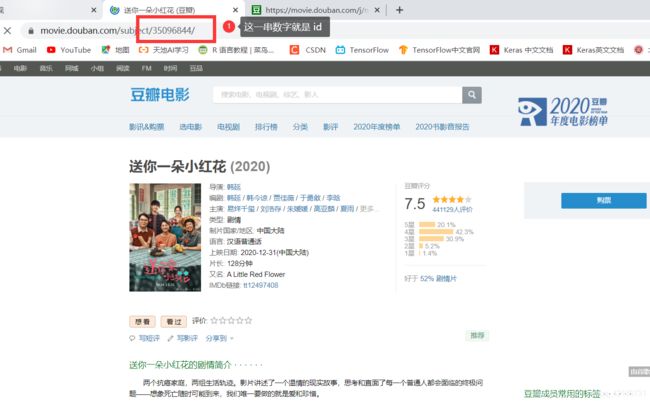
拖动电影页面,可以看到电影的评论(以短评为例),点进去。

点进去后可以进一步发现短评链接与电影 id 的关系,即:
https://movie.douban.com/subject/电影id/comments?status=P。
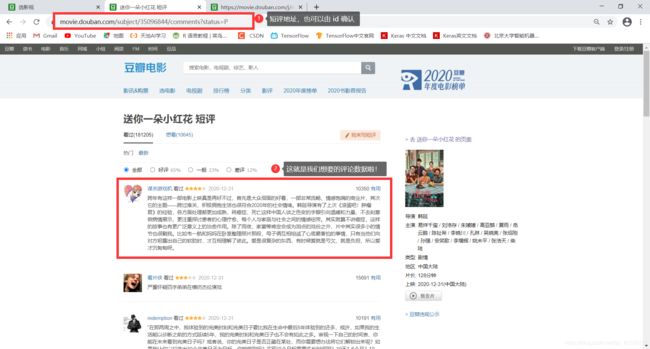
有了以上的探索分析,可以确认一个方案下来。
方案制定
使用 python 完成数据爬取,并将数据写入到 Excel 中。
首先,爬取下方链接:
https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=电影&start=20&countries=中国大陆&year_range=2020,2020
保存电影名、评分等信息,最重要的是保存 id 信息,因为我们要用它拼接相应电影的短评地址。
我们可以通过不断的修改 start 参数值获取搜索得到更多的电影。由于每次返回20条电影信息,因此每次将 start 增加20。
循环10次我们就可以得到200个电影,以及对应的电影 id。将id拼接成相应电影的短评地址,并爬取里面的内容:https://movie.douban.com/subject/电影id/comments?status=P
为了简单起见,仅爬取第一页的评论内容。
想爬取更多的评论内容可以修改以下地址的start值并进行爬取:
https://movie.douban.com/subject/35096844/comments?start=40&limit=20&status=P&sort=new_score
二、正式开工
准备工作
引入下列需要的包
import requests #请求网页源码,本文涉及到两种格式:html和json
import json #解析json格式的内容
from bs4 import BeautifulSoup #解析html格式源码
import random #产生随机数
import xlsxwriter #用于写入表格
时常,为了避免被反爬虫程序拦截,可以使用用户代理掩护:
user_agents = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36'
]
def getHeaders():
i = random.randint(0, 10)
user_agent = user_agents[i]
headers = {
'User-Agent': user_agent
}
return headers
上面给了10个代理,每次爬取随机产生一个,使用如下:
response = requests.get(url, headers=getHeaders())
处理 json 数据获取电影 id
一切就绪,先处理 json 格式内容,以获取一系列电影 id。
def gennerateIds():
ids=[]
infos=[]
url = 'https://movie.douban.com/j/new_search_subjects?sort=R&range=0,10&tags=电影&countries=中国大陆&year_range=2020,2020' #待爬取链接,本来还有start参数,被单独揪了出来
for i in range(10):
params={"start":20*i} #修改start参数,步长20,循环10次
response = requests.get(url, headers=getHeaders(),params=params) #随机获取一个代理,并传入start参数
data = json.loads(response.text) #直接将爬取获得的文本内容加载进来,loads()会返回一个字典类型,保存在变量data中
datalist = data["data"] #直接用字典访问方式就可以访问data内容
for item in datalist:
ids.append(item["id"])#电影id
infos.append((item["id"],item["title"],item["rate"],item["casts"],item["directors"]))#电影id,电影名,评分,主演,导演等
return ids,infos
if __name__ == '__main__':
ids,infos=gennerateIds() #保存返回的内容
# 下面创建一个 Excel 工作簿,添加两个表,分别用于保存短评和电影信息
workbook = xlsxwriter.Workbook('data3.xlsx')
worksheet = workbook.add_worksheet('comments')
worksheet1 =workbook.add_worksheet('movie_info')
# 写入 Movieinfos
rowindex=1 #控制写入表格时行数
for info in infos:
mid=info[0]
title=info[1]
rate=info[2]
casts=""
dires=""
for name in info[3]:
casts+=name+" "
for name in info[4]:
dires+=name+" "
worksheet1.write_row(rowindex,0,(mid,title,rate,casts,dires)) #写入表格
rowindex+=1
处理短评 html 源码
首先需要了解到每个评论对于的链接,知道它们的结构,在页面中,右键鼠标->检查元素。可以看到,每个短评内容都在class属性为“comment-item ”的div中。
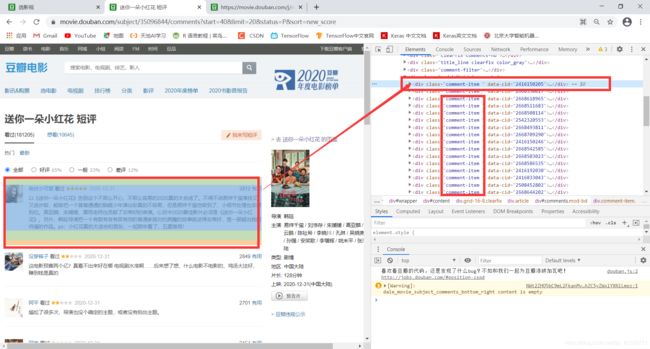
rowindex=1
for id in ids:
#根据 id 拼接 url
commenturl="https://movie.douban.com/subject/"+id+"/comments?status=P"
response2 = requests.get(commenturl, headers=getHeaders())
# 用BeautifulSoup解析
html = BeautifulSoup(response2.text, 'xml')
comments = html.find_all("div", attrs={"class": "comment-item "}) #找到所有短评的div,注意这里有一个空格
for comment in comments:
cid,name,text=pauseComment(comment) #解析每个短评的div的函数,下面给出
worksheet.write_row(rowindex, 0, (id,cid,name,text)) #写入表格
rowindex+=1
先观察我们需要的内容所在的标签,用户名在div->div->a标签的title属性,评论内容为一个“class”=“short”的span标签中的文本内容
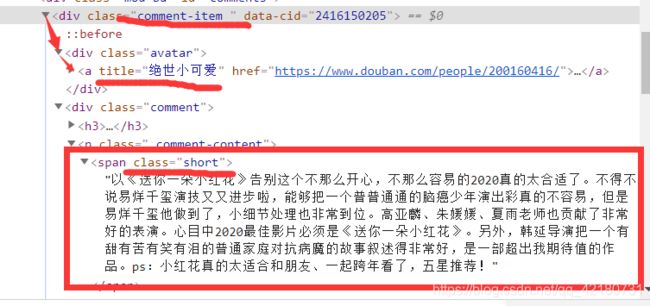
解析函数如下:
def pauseComment(commenthtml):
id=commenthtml['data-cid']
name=commenthtml.div.a['title']
span=commenthtml.find_all('span',attrs={"class":"short"})[0]
text=span.text
return id,name,text
最后别忘记了关闭工作簿。
workbook.close()
三、全部代码
import requests
import json
from bs4 import BeautifulSoup
import random
import xlsxwriter
user_agents = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36'
]
def getHeaders():
i = random.randint(0, 10)
user_agent = user_agents[i]
headers = {
'User-Agent': user_agent
}
return headers
def gennerateIds():
ids=[]
infos=[]
url = 'https://movie.douban.com/j/new_search_subjects?sort=R&range=0,10&tags=电影&countries=中国大陆&year_range=2020,2020'
for i in range(10):
params={"start":20*i}
response = requests.get(url, headers=getHeaders(),params=params)
data = json.loads(response.text)
datalist = data["data"]
for item in datalist:
ids.append(item["id"])
infos.append((item["id"],item["title"],item["rate"],item["casts"],item["directors"]))
return ids,infos
def pauseComment(commenthtml):
id=commenthtml['data-cid']
name=commenthtml.div.a['title']
span=commenthtml.find_all('span',attrs={"class":"short"})[0]
text=span.text
return id,name,text
if __name__ == '__main__':
ids,infos=gennerateIds()
workbook = xlsxwriter.Workbook('data3.xlsx')
worksheet = workbook.add_worksheet('comments')
worksheet1 =workbook.add_worksheet('movie_info')
# 写入 Movieinfos
rowindex=1
for info in infos:
mid=info[0]
title=info[1]
rate=info[2]
casts=""
dires=""
for name in info[3]:
casts+=name+" "
for name in info[4]:
dires+=name+" "
worksheet1.write_row(rowindex,0,(mid,title,rate,casts,dires))
rowindex+=1
# 写入影评数据
rowindex=1
for id in ids:
print(id)
commenturl="https://movie.douban.com/subject/"+id+"/comments?status=P"
response2 = requests.get(commenturl, headers=getHeaders())
html = BeautifulSoup(response2.text, 'xml')
comments = html.find_all("div", attrs={"class": "comment-item "})
for comment in comments:
cid,name,text=pauseComment(comment)
worksheet.write_row(rowindex, 0, (id,cid,name,text))
rowindex+=1
workbook.close()
用Access后续处理
先上数据成果吧,有两个表格,在一个工作簿里面:


导入到Access数据库:
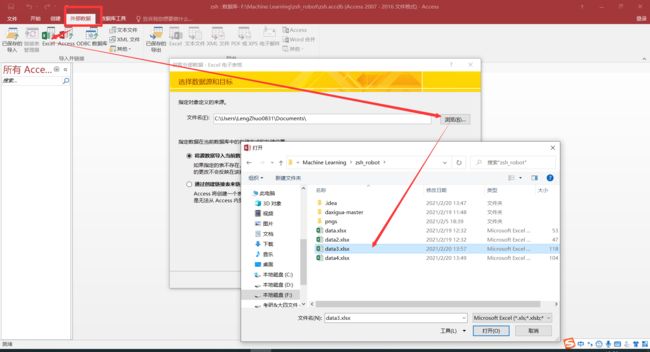
两个表都要勾选“第一列包含列标题”。
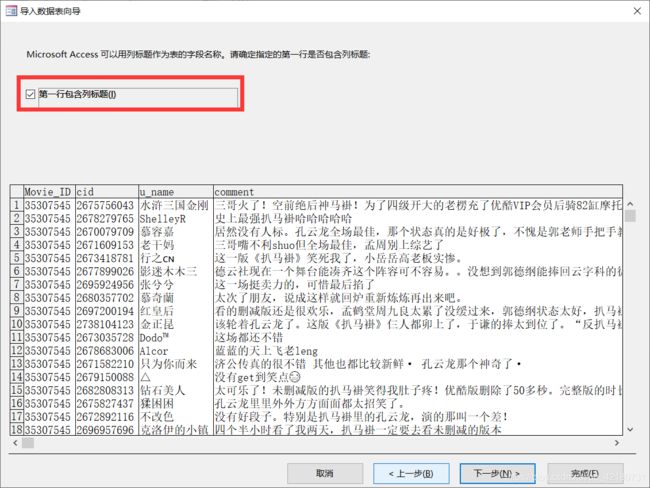
导入第二个Movie_info表时可以把第一个字段作为主键。其他直接点下一步。
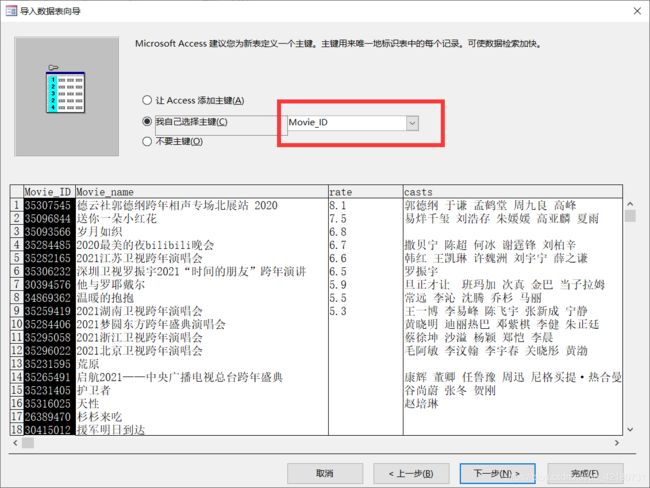
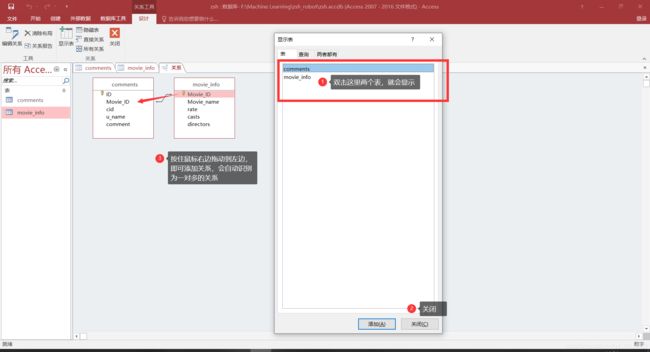
创建关系:

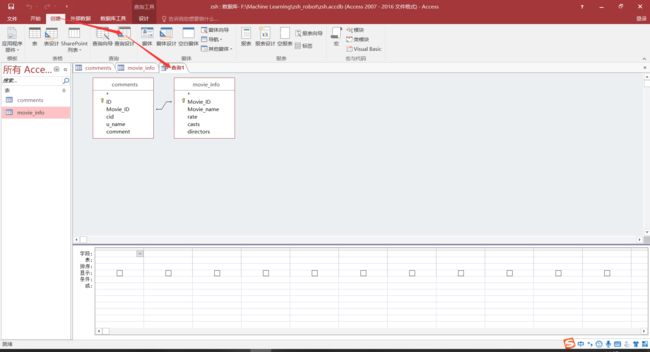
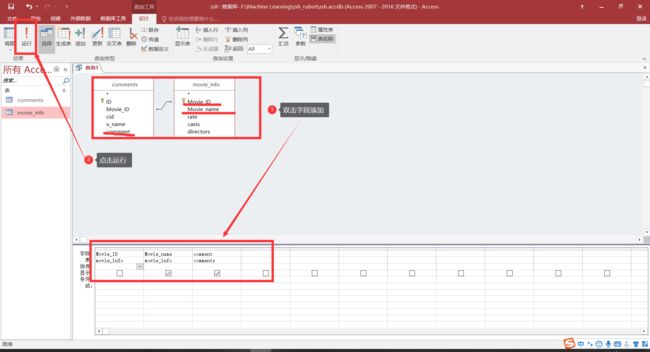
创建查询设计:
完成!
