阿里面试官:Redis分片集群都不懂?还来面试?
面试官:聊下Redis的分片集群,先聊 Redis Cluster好咯?
面试官:Redis Cluser是Redis 3.x才有的官方集群方案,这块你了解多少?
候选者:嗯,要不还是从基础讲起呗?
候选者:在前面聊Redis的时候,提到的Redis都是「单实例」存储所有的数据。
候选者:1. 主从模式下实现读写分离的架构,可以让多个从服务器承载「读流量」,但面对「写流量」时,始终是只有主服务器在抗。
候选者:2. 「纵向扩展」升级Redis服务器硬件能力,但升级至一定程度下,就不划算了。
候选者:纵向扩展意味着「大内存」,Redis持久化时的”成本”会加大(Redis做RDB持久化,是全量的,fork子进程时有可能由于使用内存过大,导致主线程阻塞时间过长)
候选者:所以,「单实例」是有瓶颈的

候选者:「纵向扩展」不行,就「横向扩展」呗。
候选者:用多个Redis实例来组成一个集群,按照一定的规则把数据「分发」到不同的Redis实例上。当集群所有的Redis实例的数据加起来,那这份数据就是全的
候选者:其实就是「分布式」的概念(:只不过,在Redis里,好像叫「分片集群」的人比较多?
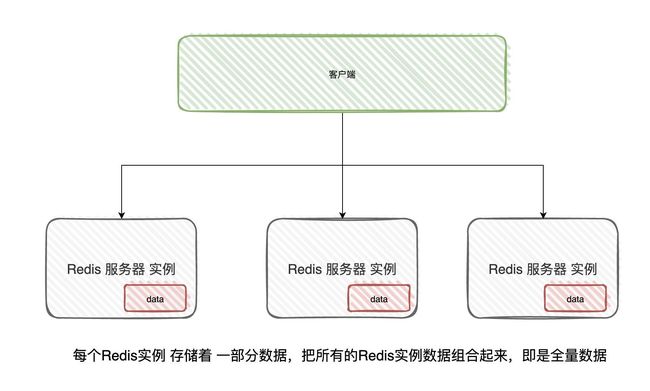
候选者:从前面就得知了,要「分布式存储」,就肯定避免不了对数据进行「分发」(也是路由的意思)
候选者:从Redis Cluster讲起吧,它的「路由」是做在客户端的(SDK已经集成了路由转发的功能)
候选者:Redis Cluster对数据的分发的逻辑中,涉及到「哈希槽」(Hash Solt)的概念
候选者:Redis Cluster默认一个集群有16384个哈希槽,这些哈希槽会分配到不同的Redis实例中
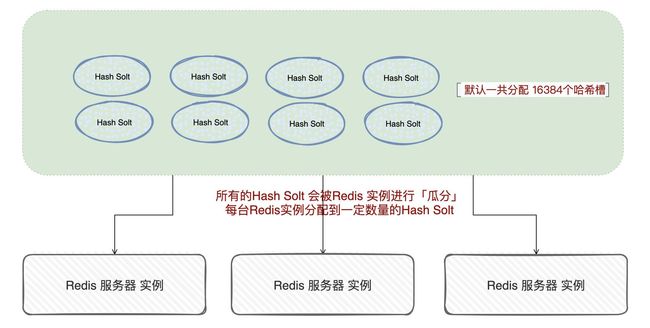
候选者:至于怎么「瓜分」,可以直接均分,也可以「手动」设置每个Redis实例的哈希槽,全由我们来决定
候选者:重要的是,我们要把这16384个都得瓜分完,不能有剩余!
候选者:当客户端有数据进行写入的时候,首先会对key按照CRC16算法计算出16bit的值(可以理解为就是做hash),然后得到的值对16384进行取模
候选者:取模之后,自然就得到其中一个哈希槽,然后就可以将数据插入到分配至该哈希槽的Redis实例中
面试官:那问题就来了,现在客户端通过hash算法算出了哈希槽的位置,那客户端怎么知道这个哈希槽在哪台Redis实例上呢?
候选者:是这样的,在集群的中每个Redis实例都会向其他实例「传播」自己所负责的哈希槽有哪些。这样一来,每台Redis实例就可以记录着「所有哈希槽与实例」的关系了(:
候选者:有了这个映射关系以后,客户端也会「缓存」一份到自己的本地上,那自然客户端就知道去哪个Redis实例上操作了
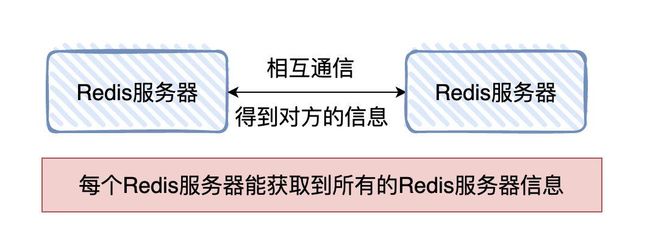
面试官:那我又有问题了,在集群里也可以新增或者删除Redis实例啊,这个怎么整?
候选者:当集群删除或者新增Redis实例时,那总会有某Redis实例所负责的哈希槽关系会发生变化
候选者:发生变化的信息会通过消息发送至整个集群中,所有的Redis实例都会知道该变化,然后更新自己所保存的映射关系
候选者:但这时候,客户端其实是不感知的(:
候选者:所以,当客户端请求时某Key时,还是会请求到「原来」的Redis实例上。而原来的Redis实例会返回「moved」命令,告诉客户端应该要去新的Redis实例上去请求啦
候选者:客户端接收到「moved」命令之后,就知道去新的Redis实例请求了,并且更新「缓存哈希槽与实例之间的映射关系」
候选者:总结起来就是:数据迁移完毕后被响应,客户端会收到「moved」命令,并且会更新本地缓存

面试官:那数据还没完全迁移完呢?
候选者:如果数据还没完全迁移完,那这时候会返回客户端「ask」命令。也是让客户端去请求新的Redis实例,但客户端这时候不会更新本地缓存
面试官:了解了
面试官:说白了就是,如果集群Redis实例存在变动,由于Redis实例之间会「通讯」
面试官:所以等到客户端请求时,Redis实例总会知道客户端所要请求的数据在哪个Redis实例上
面试官:如果已经迁移完毕了,那就返回「move」命令告诉客户端应该去找哪个Redis实例要数据,并且客户端应该更新自己的缓存(映射关系)
面试官:如果正在迁移中,那就返回「ack」命令告诉客户端应该去找哪个Redis实例要数据
候选者:不愧是你…
面试官:那你知道为什么哈希槽是16384个吗?
候选者:嗯,这个。是这样的,Redis实例之间「通讯」会相互交换「槽信息」,那如果槽过多(意味着网络包会变大),网络包变大,那是不是就意味着会「过度占用」网络的带宽
候选者:另外一块是,Redis作者认为集群在一般情况下是不会超过1000个实例
候选者:那就取了16384个,即可以将数据合理打散至Redis集群中的不同实例,又不会在交换数据时导致带宽占用过多

面试官:了解了
面试官:那你知道为什么对数据进行分区在Redis中用的是「哈希槽」这种方式吗?而不是一致性哈希算法
候选者:在我理解下,一致性哈希算法就是有个「哈希环」,当客户端请求时,会对Key进行hash,确定在哈希环上的位置,然后顺时针往后找,找到的第一个真实节点
候选者:一致性哈希算法比「传统固定取模」的好处就是:如果集群中需要新增或删除某实例,只会影响一小部分的数据
候选者:但如果在集群中新增或者删除实例,在一致性哈希算法下,就得知道是「哪一部分数据」受到影响了,需要进行对受影响的数据进行迁移
面试官:嗯…
候选者:而哈希槽的方式,我们通过上面已经可以发现:在集群中的每个实例都能拿到槽位相关的信息
候选者:当客户端对key进行hash运算之后,如果发现请求的实例没有相关的数据,实例会返回「重定向」命令告诉客户端应该去哪儿请求
候选者:集群的扩容、缩容都是以「哈希槽」作为基本单位进行操作,总的来说就是「实现」会更加简单(简洁,高效,有弹性)。过程大概就是把部分槽进行重新分配,然后迁移槽中的数据即可,不会影响到集群中某个实例的所有数据。

面试官:那你了解「服务端 路由」的大致原理吗?
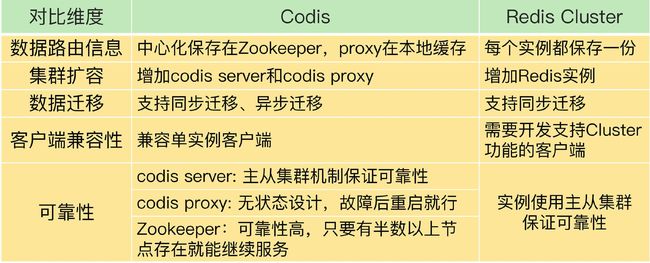
候选者:嗯,服务端路由一般指的就是,有个代理层专门对接客户端的请求,然后再转发到Redis集群进行处理
候选者:上次最后面试的时候,也提到了,现在比较流行的是Codis
候选者:它与Redis Cluster最大的区别就是,Redis Cluster是直连Redis实例的,而Codis则客户端直连Proxy,再由Proxy进行分发到不同的Redis实例进行处理

候选者:在Codis对Key路由的方案跟Redis Cluster很类似,Codis初始化出1024个哈希槽,然后分配到不同的Redis服务器中
候选者:哈希槽与Redis实例的映射关系由Zookeeper进行存储和管理,Proxy会通过Codis DashBoard得到最新的映射关系,并缓存在本地上
面试官:那如果我要扩容Codis Redis实例的流程是怎么样的?
候选者:简单来说就是:把新的Redis实例加入到集群中,然后把部分数据迁移到新的实例上
候选者:大概的过程就是:1.「原实例」某一个Solt的部分数据发送给「目标实例」。2.「目标实例」收到数据后,给「原实例」返回ack。3.「原实例」收到ack之后,在本地删除掉刚刚给「目标实例」的数据。4.不断循环1、2、3步骤,直至整个solt迁移完毕
候选者:Codis也是支持「异步迁移」的,针对上面的步骤2,「原实例」发送数据后,不等待「目标实例」返回ack,就继续接收客户端的请求。
候选者:未迁移完的数据标记为「只读」,不会影响到数据的一致性。如果对迁移中的数据存在「写操作」,那会让客户端进行「重试」,最后会写到「目标实例」上

候选者:还有就是,针对 bigkey,异步迁移采用了「拆分指令」的方式进行迁移,比如有个set元素有10000个,那「原实例」可能就发送10000条命令给「目标实例」,而不是一整个bigkey一次性迁移(因为大对象容易造成阻塞)
面试官:了解了。
本文总结:
-
分片集群诞生理由:写性能在高并发下会遇到瓶颈&&无法无限地纵向扩展(不划算)
-
分片集群:需要解决「数据路由」和「数据迁移」的问题
-
Redis Cluster数据路由:
- Redis Cluster默认一个集群有16384个哈希槽,哈希槽会被分配到Redis集群中的实例中
- Redis集群的实例会相互「通讯」,交互自己所负责哈希槽信息(最终每个实例都有完整的映射关系)
- 当客户端请求时,使用CRC16算法算出Hash值并模以16384,自然就能得到哈希槽进而得到所对应的Redis实例位置
-
为什么16384个哈希槽:16384个既能让Redis实例分配到的数据相对均匀,又不会影响Redis实例之间交互槽信息产生严重的网络性能开销问题
-
Redis Cluster 为什么使用哈希槽,而非一致性哈希算法:哈希槽实现相对简单高效,每次扩缩容只需要动对应Solt(槽)的数据,一般不会动整个Redis实例
-
Codis数据路由:默认分配1024个哈希槽,映射相关信息会被保存至Zookeeper集群。Proxy会缓存一份至本地,Redis集群实例发生变化时,DashBoard更新Zookeeper和Proxy的映射信息
-
Redis Cluster和Codis数据迁移:Redis Cluster支持同步迁移,Codis支持同步迁移&&异步迁移
- 把新的Redis实例加入到集群中,然后把部分数据迁移到新的实例上(在线)

【对线面试官+从零编写Java项目】 持续高强度更新中!求star
原创不易!!求三连!!