信号量/基于环形队列的生产消费者模型
在基于阻塞队列的生产消费者模型的代码中有以下几点:
1.在线程访问临界资源之前,临界资源必须是满足条件的,即需要满足加锁,判断等等,防止多个线程同时访问临界资源。
2.但是对于某个临界资源是否满足生产消费的条件,我们一般是无法直接得知的,因此我们就需要对这个临界资源先进行加锁、然后检测条件、然后进行操作,最后解锁。
总结一句话就是,某个线程在操作临界资源的时候,有可能是不就绪的(不满足条件,不进行操作),但是由于我们无法提前得知,因此只能先加锁,再检测是否满足条件,然后决定要不要走下一步!而申请锁是有消耗的,这种消耗对于这个线程是无意义的消耗!这就是代码中的问题!
为此,引入信号量来解决这个问题。
信号量的概念
信号量在认识信号量这篇文章中介绍过,下面来二次简单认识一下。
为什么需要信号量?
一般情况的理念中,只要我们对资源进行整体加锁,就默认了我们对这个资源整体使用。但是在实际的情况下,可能存在一份公共资源允许多个线程同时访问不同的区域!
也就是说在线程想要访问临界资源的时候,就需要先申信号量,然后对号入座去访问临界资源中的某个区域。实现这个操作是程序员在编码的时候,保证不同线程可以并发访问公共资源的不同区域!
信号量是啥?
信号量本质是一个计数器,用于衡量临界资源中资源数量。
只要拥有信号量,在未来就一定拥有访问临界资源的一部分的资格。因此申请信号量的本质:对临界资源中特定小块资源的预订机制。
那么信号量是如何解决上面所说线程无意义消耗锁的问题呢?
两句话:只要申请成功了,那么就一定有给这个线程的资源。如果申请失败了,那么就说明条件不就绪,这个线程只能等下去了!这样就不需要再先加锁,然后判断条件了。
信号量PV原语
线程要访问临界资源中的某一区域,就要先申请信号量,所有的线程申请的是同一个信号量,因此信号量必须被所有线程都看到,这意味着,信号量本身也是一份公共资源:
既然信号量的本质是计数器,那么它就得会递增++或递减--,递减--即申请资源,递增++即归还资源。但是递增++和递减--都不是原子性的!因此会存在线程安全问题。
所以,对信号量的操作我们必须要保证其原子性!因此,信号量拥有自己的数据类型sem_t
申请资源称之为P,归还资源称之为V,因此信号量的核心操作就是:PV原语。
信号量的基本使用接口
①初始化信号量
#include
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数:
sem:需要操作的那个信号量的变量
pshared:0表示线程间共享,非零表示进程间共享
value:信号量初始值,即给信号量sem初始化为多少,取决于临界资源数量的多少 ②销毁信号量
int sem_destroy(sem_t *sem);③等待信号量
功能:等待信号量,会将信号量的值减1
int sem_wait(sem_t *sem); //P()④发布信号量
功能:发布信号量,表示资源使用完毕,可以归还资源了。将信号量值加1。
int sem_post(sem_t *sem);//V()基于环形队列的生产消费者模型
环形队列采用数组模拟,用模运算来模拟环状特性,即对数组的访问,下标采用下标模数组长度的形式来模拟环形队列。
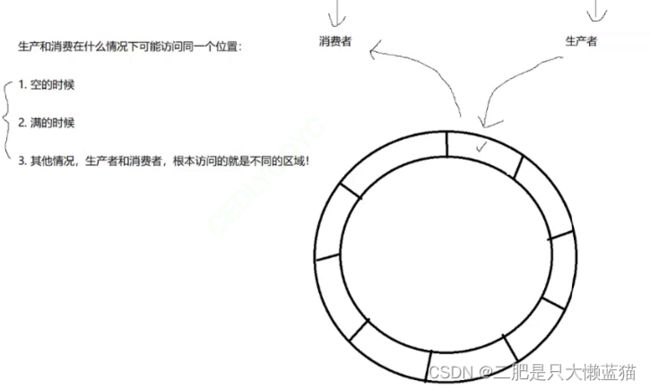
那么为了完成环形队列生产消费问题,其核心工作如下:
消费者不能超过生产者。
生产者不能把消费者套圈。
清楚生产者和消费者何时会站在一起。
①当队列是空的时候 ②当队列是满的时候
如果队列是空的,那么就一定是生产者先执行。如果队列是满的,那么一定是消费者先执行。
因此,当生产和消费者站在一起的时候,生产者消费者就会体现出互斥和同步关系!不站在一起的时候,就是互斥关系了。
生产消费过程的思路是这样的:
假设环形队列的长度为10,即有10个空间给生产消费者。
对于生产者而言的伪代码:
一开始的信号量:producter_sum = 10;
//申请成功,继续往下执行;申请失败,当前的执行流阻塞在申请处。
P(producter_sum);//申请信号量
从事生产活动---把数据放在队列当中
//从事完,那么改释放谁的信号量?释放信号量就相当于在计数器上减一,那么既然生产者生产了一个数据放在了队列当中,生产者即使走了,但是生产出来的数据还在这,此时表面,在环形队列中,多了一个让消费者消费的数据,因此V的是消费者的信号量
V(comsumer_sum);//此时consumer_sum就会++,因为归还了
对于消费者而言:
一开始的信号量:comsumer_sum = 10;
//申请成功,继续往下执行;申请失败,当前的执行流阻塞在申请处。
P(comsumer_sum);//申请信号量
从事消费活动---把放在队列当中的数据拿走
//从事完,那么改释放谁的信号量?消费者把数据拿走,不会归还给环形队列了,因此的环形队列中空了一格出来,因此归还资源,归还的是生产者的资源。
V(producter_sum);
对于生产消费者而言,在一开始的时候,环形队列是空的,生产者和消费者谁先申请信号量我们不知道,但是一定是生产者先申请成功的!
最后,生产和消费的位置我们要想清楚,在这个队列中,本质是数组,因此它们的位置就是下标,生产者对应着一个下标,消费者也对应着一个下标,在为空或者为满的时候,它们是下标相同,其它情况下标不相同。
代码示例
单消费者单生产者
RingQueue.hpp头文件代码
#pragma once
#include
#include
#include
#include
using namespace std;
static const int gcap = 10;
template
class RingQueue
{
private:
void P(sem_t &sem)
{
int n = sem_wait(&sem);
assert(n==0);
(void)n;
}
void V(sem_t &sem)
{
int n = sem_post(&sem);
assert(n==0);
(void)n;
}
public:
RingQueue(const int& cap = gcap)
:_queue(cap)
,_cap(cap)
{
int n =sem_init(&_spaceSem,0,_cap);
assert(n==0);
n = sem_init(&_dataSem,0,0);
assert(n==0);
_productorStep = _consumerStep = 0;
}
//生产者调用的push函数
void Push(const T &in)
{
P(_spaceSem);//申请信号量的P操作
//放入数据
_queue[_productorStep++] = in;
_productorStep %= _cap;//需要环形
V(_dataSem);
}
void Pop(T *out)
{
P(_dataSem);//申请信号量
//消费
*out = _queue[_consumerStep++];
_consumerStep %= _cap;
V(_spaceSem);
}
~RingQueue()
{
sem_destroy(&_spaceSem);
sem_destroy(&_dataSem);
}
private:
std::vector _queue;//用数组模拟队列
int _cap;//表示队列容量
sem_t _spaceSem;//生产者看中的空间资源,信号量
sem_t _dataSem;//消费者看中的数据资源,信号量
int _productorStep;//生产者的下标
int _consumerStep;//消费者的下标
}; main.cc代码
#include "RingQueue.hpp"
#include
#include
#include
#include
#include
void *ProductorRoutine(void *_rq)
{
RingQueue *rq = static_cast *>(_rq);//环形队列
while(true)
{
sleep(2);
int data = rand()%10+1;
rq->Push(data);
std::cout<<"生产完成,生产的数据是: "< *rq = static_cast *>(_rq);//环形队列
while(true)
{
int data;
rq->Pop(&data);
std::cout<<"消费完成,消费的数据是: "< *rq = new RingQueue();//环形队列
pthread_t p,c;
pthread_create(&p,nullptr,ProductorRoutine,rq);
pthread_create(&c,nullptr,ConsumerRoutine,rq);
pthread_join(p,nullptr);
pthread_join(c,nullptr);
delete rq;
return 0;
} 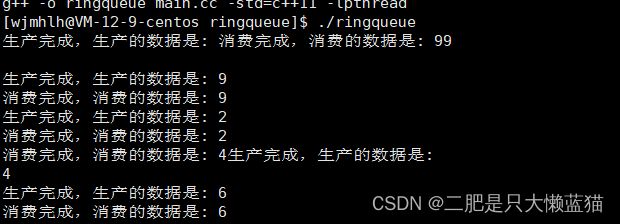
可以看到这个结果,生产者每两秒生产一个结果,消费者就消费一个结果,这就是同步!
生产者派发任务
当然,我们把代码改一下,让生产者给消费者派发任务。
这里复用阻塞队列实例代码中的Task类:
#pragma once
#include
#include
#include
using namespace std;
class Task//表示计算任务
{
using func_t = std::function;
// typedef std::function func_t;
public:
Task()
{}
Task(int x, int y,char op, func_t func):_x(x), _y(y),_op(op), _callback(func)
{}
string operator()()
{
int result = _callback(_x, _y,_op);
char buffer[1024];
snprintf(buffer,sizeof buffer,"%d %c %d = %d",_x,_op,_y,result);
return buffer;
}
string toTaskString()
{
char buffer[1024];
snprintf(buffer,sizeof buffer,"%d %c %d = ?",_x,_op,_y);
return buffer;
}
private:
int _x;
int _y;
char _op;
func_t _callback;
};
const string oper="+-*/%";
int mymath(int x,int y,char op)
{
int result = 0;
switch(op)
{
case '+':
result = x+y;
break;
case '-':
result = x-y;
break;
case '*':
result = x*y;
break;
case '/':
{
if(y==0)
{
std::cerr<<"div zero error!"< mian.cc代码:
#include "RingQueue.hpp"
#include"Task.hpp"
#include
#include
#include
#include
#include
#include
void *ProductorRoutine(void *_rq)
{
//RingQueue *rq = static_cast *>(_rq);//环形队列
RingQueue *rq = static_cast *>(_rq);//环形队列
while(true)
{
//version1
// sleep(2);
// int data = rand()%10+1;
// rq->Push(data);
// std::cout<<"生产完成,生产的数据是: "<Push(t);
std::cout<<"生产者派发了一个任务: "< *rq = static_cast *>(_rq);//环形队列
RingQueue *rq = static_cast *>(_rq);//环形队列
while(true)
{
//version1
// int data;
// rq->Pop(&data);
// std::cout<<"消费完成,消费的数据是: "<Pop(&t);//拿任务
std::string result = t();
std::cout<<"消费者消费了一个任务: "< *rq = new RingQueue();//环形队列
RingQueue *rq = new RingQueue();//环形队列
pthread_t p,c;
pthread_create(&p,nullptr,ProductorRoutine,rq);
pthread_create(&c,nullptr,ConsumerRoutine,rq);
pthread_join(p,nullptr);
pthread_join(c,nullptr);
delete rq;
return 0;
} 
多生产者多消费者
上面的单生产者和单消费者的代码示例中,维护了生产者和消费者之间的互斥和同步关系。接下来我们就演示如何维护生产者和生产者之间,消费者和消费者之间的互斥关系。
我们先来回想一下在阻塞队列当中,不管有几个生产者消费者,都只能有一个线程(生产者或消费者)在访问临界资源,因为那里有一把琐锁着。
而在这里的环形队列当中,只需要保证一个生产者,一个消费者在环形队列里面即可,也就是说需要两把锁,一个给生产者,一个给消费者,两个互不干扰,你忙你的我忙我的。
所有的生产者会共享一个Push方法,共享下标,因此在Push方法中加锁。同样的,所有的消费者会共享Pop方法,共享下标,因此也要在Pop方法中加锁。
加锁的位置,应该是在P操作之后,V操作之前,其原因是:
P操作申请信号量,只要申请成功了,就意味着一定能够正常生产或正常消费,此时就可以往后加锁去访问临界资源了。如果在P操作之前加锁,那么就会跟阻塞队列的加锁的问题如出一辙,即如果某个线程加锁了,但是在下一步的申请信号量申请失败,那么就会无意义的消耗锁资源了。
V操作是归还资源,能够访问临界资源,都是可以正常生产和消费的,那么在解锁之后就应该去归还资源了。
main.cc代码:
#include "RingQueue.hpp"
#include"Task.hpp"
#include
#include
#include
#include
#include
#include
string SelfName()
{
char name[128];
snprintf(name,sizeof(name),"thread[0x%x]",pthread_self());
return name;
}
void *ProductorRoutine(void *_rq)
{
//RingQueue *rq = static_cast *>(_rq);//环形队列
RingQueue *rq = static_cast *>(_rq);//环形队列
while(true)
{
//version1
// sleep(2);
// int data = rand()%10+1;
// rq->Push(data);
// std::cout<<"生产完成,生产的数据是: "<Push(t);
std::cout< *rq = static_cast *>(_rq);//环形队列
RingQueue *rq = static_cast *>(_rq);//环形队列
while(true)
{
//version1
// int data;
// rq->Pop(&data);
// std::cout<<"消费完成,消费的数据是: "<Pop(&t);//拿任务
std::string result = t();
std::cout< *rq = new RingQueue();//环形队列
RingQueue *rq = new RingQueue();//环形队列
pthread_t p[4], c[8];
for(int i = 0; i < 4; i++) pthread_create(p+i, nullptr, ProductorRoutine, rq);
for(int i = 0; i < 8; i++) pthread_create(c+i, nullptr, ConsumerRoutine, rq);
for(int i = 0; i < 4; i++) pthread_join(p[i], nullptr);
for(int i = 0; i < 8; i++) pthread_join(c[i], nullptr);
delete rq;
return 0;
} 头文件代码:
#pragma once
#include
#include
#include
#include
#include
using namespace std;
static const int gcap = 5;
template
class RingQueue
{
private:
void P(sem_t &sem)
{
int n = sem_wait(&sem);
assert(n==0);
(void)n;
}
void V(sem_t &sem)
{
int n = sem_post(&sem);
assert(n==0);
(void)n;
}
public:
RingQueue(const int& cap = gcap)
:_queue(cap)
,_cap(cap)
{
int n =sem_init(&_spaceSem,0,_cap);
assert(n==0);
n = sem_init(&_dataSem,0,0);
assert(n==0);
_productorStep = _consumerStep = 0;
pthread_mutex_init(&_pmutex,nullptr);
pthread_mutex_init(&_cmutex,nullptr);
}
//生产者调用的push函数
void Push(const T &in)
{
P(_spaceSem);//申请信号量的P操作
pthread_mutex_lock(&_pmutex);
//放入数据
_queue[_productorStep++] = in;
_productorStep %= _cap;//需要环形
pthread_mutex_unlock(&_pmutex);
V(_dataSem);
}
void Pop(T *out)
{
P(_dataSem);//申请信号量
pthread_mutex_lock(&_cmutex);
//消费
*out = _queue[_consumerStep++];
_consumerStep %= _cap;
pthread_mutex_unlock(&_cmutex);
V(_spaceSem);
}
~RingQueue()
{
sem_destroy(&_spaceSem);
sem_destroy(&_dataSem);
pthread_mutex_destroy(&_pmutex);
pthread_mutex_destroy(&_cmutex);
}
private:
std::vector _queue;//用数组模拟队列
int _cap;//表示队列容量
sem_t _spaceSem;//生产者看中的空间资源,信号量
sem_t _dataSem;//消费者看中的数据资源,信号量
int _productorStep;//生产者的下标
int _consumerStep;//消费者的下标
pthread_mutex_t _pmutex;//生产者的锁
pthread_mutex_t _cmutex;//消费者的锁
}; 多生产者和多消费者的意义
上面说了,不管有多少个生产者和消费者,在环形队列当中,最多就存在一个生产者和一个消费者,那么多生产者和多消费者的意义在哪呢?单生产者和单消费者不就已经可以满足这一条件了吗?
消费者处理任务是需要花时间的,生产者构建任务也是需要花时间的,如果只有单消费者和单生产者的话,就相当于一个人在搬砖,一个人砌墙一样,单生产者把砖搬到指定位置,然后返回去拿新砖,才能拿到下一块砖,砌墙的消费者也是同样的道理,很花费时间。而如果很多人去搬砖,很多人去砌墙,那么在一个生产者在搬砖的过程,另外的生产者也到了砖堆这个临界资源中拿砖,一个消费者在拿到砖后,赶往砌墙的过程中 ,其它的消费者也在第一个消费者拿到砖后,陆续去拿砖去砌墙,效率就会变得很高。
因此,多生产者多消费者的意义在于多生产者或多消费者并发执行,提供效率。