现代化数据管理和集成的关键 - 数据编织
What is data fabric?
Gartner defines data fabric as a design concept that serves as an integrated layer (fabric) of data and connecting processes. A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata assets to support the design, deployment and utilization of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.
Data fabric leverages both human and machine capabilities to access data in place or support its consolidation where appropriate. It continuously identifies and connects data from disparate applications to discover unique, business-relevant relationships between the available data points. The insight supports re-engineered decision-making, providing more value through rapid access and comprehension than traditional data management practices.
For example, a supply chain leader using a data fabric can add newly encountered data assets to known relationships between supplier delays and production delays more rapidly, and improve decisions with the new data (or for new suppliers or new customers).
Think of data fabric as a self driving car
Consider two scenarios. In the first, the driver is active and paying full attention to the route, and the car’s autonomous element has minimum or no intervention. In the second, the driver is slightly lazy and loses focus, and the car immediately switches to a semi-autonomous mode and makes the necessary course corrections.
Both scenarios sum up how data fabric works. It monitors the data pipelines as a passive observer at first and starts suggesting alternatives that are far more productive. When both the data “driver” and the machine-learning are comfortable with repeated scenarios, they complement each other by automating improvisational tasks (that consume too many manual hours), while leaving the leadership free to focus on innovation.
What D&A leaders need to know about data fabric
- Data fabric is not merely a combination of traditional and contemporary technologies but a design concept that changes the focus of human and machine workloads.
- The new and upcoming technologies such as semantic knowledge graphs, active metadata management, and embedded machine learning (ML) are required to realize the data fabric design.
- The design optimizes data management by automating repetitive tasks such as profiling datasets, discovering and aligning schema to new data sources, and at its most advanced, healing the failed data integration jobs.
- No existing stand-alone solution can facilitate a full-fledged data fabric architecture. D&A leaders can ensure a formidable data fabric architecture using a blend of built and bought solutions. For example, they can opt for a promising data management platform with 65-70% of the capabilities needed to stitch together a data fabric. The missing capabilities can be achieved with a homegrown solution.
How can D&A leaders ensure a data fabric architecture that delivers business value?
To deliver business value through data fabric design, D&A leaders should ensure a solid technology base, identify the required core capabilities, and evaluate the existing data management tools.
Here are the key pillars of a data fabric architecture D&A leaders must know.
No 1. Data fabric must collect and analyze all forms of metadata
Contextual information lays the foundation of a dynamic data fabric design. There should be a mechanism (like a well-connected pool of metadata) that enables data fabric to identify, connect, and analyze all kinds of metadata such as technical, business, operational, and social.
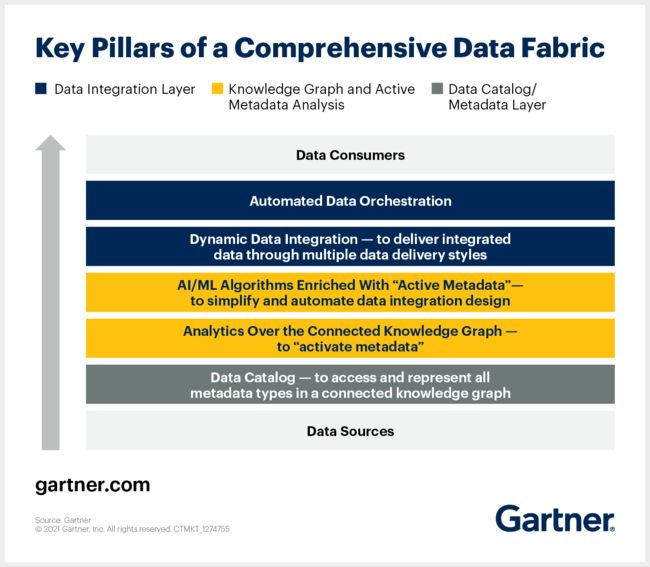
No 2. Data fabric must convert passive metadata to active metadata
For frictionless sharing of data, it is important for enterprises to activate metadata. For this to happen, data fabric should:
- Continuously analyzes available metadata for key metrics and statistics and then builds a graph model.
- Graphically depict metadata in an easy-to-understand manner, based on their unique and business-relevant relationships.
- Leverage key metadata metrics to enable AI/ML algorithms, that learn over time and churn out advanced predictions regarding data management and integration.
No 3. Data fabric must create and curate knowledge graphs
Knowledge graphs enable data and analytics leaders to derive business value — by enriching data with semantics.
The semantic layer of the knowledge graph makes it more intuitive and easy to interpret, making the analysis easy for D&A leaders. It adds depth and meaning to the data usage and content graph, allowing AI/ML algorithms to use the information for analytics and other operational use cases.
Integration standards and tools used regularly by data integration experts and data engineers can ensure easy access to - and delivery from - a knowledge graph. D&A leaders should leverage that; otherwise, the adoption of data fabric can face many interruptions.
No 4. Data fabric must have a robust data integration backbone
Data fabric should be compatible with various data delivery styles (including, but not limited to, ETL, streaming, replication, messaging, and data virtualization or data microservices). It should support all types of data users – including IT users (for complex integration requirements) and business users (for self-service data preparation).