MYBATIS源码深度分析---mapper初始化过程(三)
文章目录
- 前言
- 一、SqlMapper初始化
-
- mapper的注册
- 创建MapperProxyFactory 载入Mapper接口保
- 解析mapper.xml
-
- 准备阶段
- 解析
- 解析SQL公共片段
- 解析SQL
- SqlSource对象的创建
- 生成MappedStatement加入到configuration对象中
- 解析mapper接口中所有方法
前言
在前面跟踪configuration对象初始化赋值的时候我们没有详细展开parseConfiguration(XNode root) 中众多解析各个标签的方法,这里我们再回到parseConfiguration中调用的mapperElement(root.evalNode(“mappers”))探究下mybatis到底是如何解析和管理我们mapper对象的。mapper身为一个一个接口又是如何执行到其中映射到的sql执行方法,为什么#{}可以防止sql注入等众多问题
一、SqlMapper初始化
进入到mapperElement(XNode parent)首先会去解析我们的子标签,首先我们要知道标签下包含哪几种子标签又分别有什么作用。这里可以去查看源码中的dtd文件,也可以查看官方文档。下图中列举除了配置mapper的四种方式,到这里我们引出一个问题这四种方式的优先级是怎样的呢?
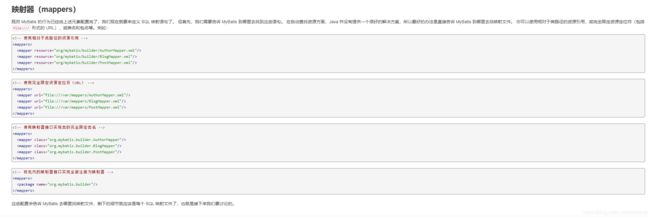 提示:为了追踪采用package批量配置的情况下的源码情况,我没有新加入mapper而是将resource方式配置改为了package
提示:为了追踪采用package批量配置的情况下的源码情况,我没有新加入mapper而是将resource方式配置改为了package
进入mapperElement(XNode parent)源码首先它在做了一个NP判断后通过for循环来向内递归取出mappers下的子节点存入一个ArrayList容器。这里我们通过使用debug的evaluate获取到parent也就是标签对象的第一个子节点,也正如我们预想的那样首次for循环直接拿到了我们mybatis-config.xml配置中的package信息。继续往下直接判断当前mapper是否是通过包类型批量注册的,从下面几段代码我们就能看出四种mapper加载方式的优先级。依次是package、resource、url、class。因为我们的配置中下只有一个标签所以第一次循环判断"package".equals(child.getName())为true会直接进入package逻辑。如果是还配置了标签的情况下,因为dtd文件规定必须写在最前面的规则此时就会进入else逻辑。在这里需要注意不要同时将同一个mapper重复配置,否则的话会抛出异常sqlsession构建失败。
下面我们进入关键的configuration.addMappers(mapperPackage)方法看看mybatis到底是如何存储mapper的。
public void addMappers(String packageName) {
mapperRegistry.addMappers(packageName);
}
public class MapperRegistry {
private final Configuration config;
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();
public void addMappers(String packageName) {
addMappers(packageName, Object.class);
}
public void addMappers(String packageName, Class<?> superType) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> mapperSet = resolverUtil.getClasses();
for (Class<?> mapperClass : mapperSet) {
addMapper(mapperClass);
}
}
}
首先会将我们的packageName中的.转换为/。转换后的地址为:org/apache/ibatis/demo,在得到包路径后mybatis会使用自己封装的VFS文件工具类将包下所有的文件都解析出来。在演示案例中我没有进行分包而是将所有文件都丢在了一个包下,可以看到此时mybatis将pojo类,mapper接口和xml文件类路径都解析了出来放在了一个list容器中。但是我们只需要mapper文件,看看mybatis又是如何过滤的。首先
if (child.endsWith(".class"))过滤掉了非class文件,这里xml就首先被排除了。继续往下走进入addIfMatching()方法
首先将之前我们转换成的物理类路径转换为了全限定类名。然后使用AppClassloader类加载器加载对应类,通过简单的类型判断后将Student类加入到了我们set容器matches对象中。这里会将Student类与StudentMapper接口都加入,这里会产生一个问题Student是对象实体类并不是我们需要的mapper接口加入到容器中是否会对后面的处理产生影响。带着这个问题我们继续深入,回到addMappers(String packageName, Class superType)方法。此时可以看到resolverUtil.getClasses()返回的正是之前的matches对象,其中装着Student和StudentMapper两个类。下面将进入我们真正的核心看看mapper到底是如何存储的。
mapper的注册
首先它会判断传入的是否是一个接口,如果不是则不做任何操作直接返回。这里也解决了我们上面的疑惑,Student实体类会被自动过滤掉。接着进入第二次循环,这次会取出我们的mapper对象。此时顺利通过第一层判断type.isInterface(),紧接着hasMapper(type)回到我们的mappers注册容器Map
public <T> void addMapper(Class<T> type) {
/**
* 判断我们传入进来的type类型是不是接口
*/
if (type.isInterface()) {
/**
* 判断我们的缓存中有没有该类型
*/
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
/**
* 创建一个MapperProxyFactory 把我们的Mapper接口保存到工厂类中
*/
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try. mapper注解构造器
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
/**
* 进行解析
*/
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
创建MapperProxyFactory 载入Mapper接口保
我们知道,接口中定义的方法必须通过某个类实现该接口,然后创建该类的实例,才能通过实例调用方法。所以SqlSession对象的getMapper()方法返回的一定是某个类的实例。具体是哪个类的实例呢?实际上getMapper()方法返回的是一个动态代理对象。在这里我们就不难看出 knownMappers.put(type, new MapperProxyFactory<>(type));在进行put的时候new了一个MapperProxyFactory。我们深入进入看一下MapperProxyFactory到底是什么,首先到这里我们需要一个代理的概念众所周知java中存在两种代理方式一种是JDK动态代理、一种是cflib动态代理。而mybatis又是使用的那种呢,其实我们可以猜到一定是JDK动态代理。因为从这二者的实现区别来看jdk只能对实现了接口的类生成代理而不能针对类,CGLib是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法(继承)。
解析mapper.xml
准备阶段
在构建好 MapperAnnotationBuilder parser对象后紧接着就会调用其中的parse()方法对mapper.xml文件进行解析。首先会到configuration对象的Set loadedResources容器中查找是否已经加载过,loadedResources主要作用是用来存放我们的mapper接口和maperr.xml文件。如果不存在则开始解析mapper.xml,进入loadXmlResource()方法,这里为了防止spring在此之前已经加载所以需要进行二次判断再次确定configuration的loaddedResource中没有mapper.xml后开始解析。将类路径中的.替换为/转换为物理路径,从而获取到mapper.xml的字节输入流对象。通过这里的源码我们可以看到,mybatis在当前包下如果没有找到mapper就会去classpath下加载。这也解释了原生mybatismapper.xml可以跟mapper接口放在同目录下或者是resource目录下的原因。在这里不得不提到mybatis与spring整合时的mapper-locations配置它可以以数组的形式允许我们配置多个xml文件扫描路径在spring启动的时候就会帮我们自动的加载mapper.xml文件,如果单独使用mybatis的情况下我们不想依照mybatis约定的目录放置xml文件还需要程序员手动去加载,从这一点也更加说明的spring的强大之处为我们的开发简化了很多繁琐且不必要的步骤让人使用起来更得心应手。
进入实际解析的parse()方法,首先获取标签的XNode对象,通过解析生成的XNode对象拿到标签中的namespace属性值,并赋值给XMLMapperBuilder对象中的MapperBuilderAssistant builderAssistant下的currentNamespace属性。在BaseBuilder类的子类中,MapperBuilderAssistant类最为特殊,因为它本身不是建造者类而是一个建造者辅助类。它继承 BaseBuilder 类的原因仅仅是因为要使用 BaseBuilder类中的方法。MyBatis 映射文件中的设置项非常多,包括命名空间、缓存共享、结果映射等。最终这些设置将解析生成不同的类,而 MapperBuilderAssistant类是这些解析类的辅助类。MapperBuilderAssistant 类提供了许多辅助方法,如 Mapper 命名空间的设置、缓存的创建、鉴别器的创建等接下来会去连续的解析cache-ref、cache、parameterMap标签,这几个标签因为本次案例中没有进行相关配置不进行展开。在学习mybatis缓存模块会详细研究。
解析
在解析的过程中首先会去获取它的子节点进行判断是否为
解析SQL公共片段
include节点的解析是由 XMLIncludeTransformer负责的,它能将 SQL语句中的 include节点替换为被引用的 SQL片段。XMLIncludeTrans former 类中的 applyIncludes(Node)方法是解析 include节点的入口方法,而 applyIncludes(Node,Properties,boolean)方法则是核心方法。

解析SQL
SqlSource是我们mybatis中重中之重的一个接口,在 mapping 包中,与 SQL 语句处理功能相关的类主要有三个,它们是MappedStatement类、SqlSource类和 BoundSql类。其中 MappedStatement类表示的是数据库操作节点(select、insert、update、delete四类节点)内的所有内容;SqlSource类是数据库操作标签中包含的 SQL语句;BoundSql类则是 SqlSource类进一步处理的产物。

SqlSource是一个解析实体接口,它对应了 MappedStatement中的 SQL语句。接口中只定义了一个用以返回一个 BoundSql 对象的方法。
SqlSource接口有四种实现类:
- DynamicSqlSource: 动态 SQL语句。所谓动态 SQL是指含有动态 SQL节点(如“if”节点)或者含有“${}”占位符的语句。
- RawSqlSource: 原生 SQL语句。指非动态语句,语句中可能含“#{}”占位符,但不含有动态 SQL节点,也不含有“${}”占位符。·
- StaticSqlSource: 静态语句。语句中可能含有“?”,可以直接提交给数据库执行。
- ProviderSqlSource: 上面的几种都是通过 XML 文件获取的 SQL 语句,而ProviderSqlSource是通过注解映射的形式获取的 SQL语句
而 DynamicSqlSource 和 RawSqlSource 都会被处理成 StaticSqlSource,然后再通过StaticSqlSource的 getBoundSql方法得到 SqlSource对象。
可以看到我们的SqlSource实现类是RawSqlSource完全符合上面给出的定义,而这里不得不思考的一个点是mybatis是如何根据xml中的sql节点辨别SqlSource的返回类型的。想要揭晓答案我们就不得不进入到createSqlSource()方法中仔细研究一番了。
SqlSource对象的创建
首先我们在继XMLStatementBuilder和XMLMapperBuilder之后需要来认识一个新的构造器XMLScriptBuilder,我们知道映射文件中的数据库操作语句如下代码,它实际上是由众多 SQL节点组成的一棵树。要想解析这棵树,首先要做的是将 XML中的信息读取进来,然后在内存中将 XML树组建为 SQL 节点树。而SQL 节点树的组建则就是由 XMLScriptBuilder 类负责。在创建好XMLScriptBuilder对象后将调用它的parseScriptNode()方法来解析sql
<update id="updateByExample" parameterType="map">
update u_actionhistory
set id = #{record.id,jdbcType=BIGINT},
resourceid = #{record.resourceid,jdbcType=BIGINT},
kind = #{record.kind,jdbcType=VARCHAR},
seq = #{record.seq,jdbcType=INTEGER},
action = #{record.action,jdbcType=VARCHAR},
userid = #{record.userid,jdbcType=BIGINT},
username = #{record.username,jdbcType=VARCHAR},
updatedate = #{record.updatedate,jdbcType=TIMESTAMP}
<if test="_parameter != null">
<include refid="Update_By_Example_Where_Clause" />
if>
update>
首先mybatis会去检查我们的sql中是否包含动态标签,进入到parseDynamicTags(XNode node)方法。第一步它会将我们如标签下如等所有子标签解析生成一个NodeList对象。下面有一个需要注意的点是Node.CDATA_SECTION_NODE,它表示文档中的 CDATA 区段(文本不会被解析器解析),而所有 XML 文档中的文本均会被解析器解析。只有 CDATA 区段(CDATA section)中的文本会被解析器忽略。TEXT_NODE:表示元素或属性中的文本内容。在某些情况下,我们在xml中要使用大量XML敏感的字符,而我们又不希望逐一的对其进行转移。这时候使用CDATA段是最理想的。在CDATA中将文本的内容写入,那么这段文本内容会被忽略检查,无论里面是否包含XML敏感内容,全部被当作普通的文本去看待。
CDATA的定义:
CDATA DTD的属性类型,全名character data,指不由xml解析器进行解析的文本数据。在标记的CDATA下,所有的标记、实体引用(特殊字符)都
会被忽
略,而被当作字符数据来看待。
CDATA的形式:
CDATA的形式如下: <![CDATA[文本内容]]> CDATA的文本内容中不能出现字符串“]]>”,也不能嵌套。 CDATA区域是由“<![CDATA["为开始标记,以
“]]>”为结束标记,注意CDATA为大写。
DTD实例:
指定类型为CDATA以后就可以在XML中被用于实例,例如下面payment 元素的type属性被指定为CDATA类型后在XML中就可以赋于”check”的字符数据。
check">
获取当前节点中的字符串内容,用来创建TextSqlNode对象利用此对象的isDynamic()方法来对当前节点判断是否为动态Sql源。至于它是如何进行判断的呢,其实它的原理很简单它直接调用string的int indexOf(String str)方法去查找看sql字符串中是否有"KaTeX parse error: Expected '}', got 'EOF' at end of input: …非动态。存在则继续往下解析判断{"是否完整。然后用 handleToken方法的返回值替换“ x x x ” 字 符 串 。 G e n e r i c T o k e n P a r s e r 提 供 的 占 位 符 定 位 功 能 应 用 非 常 广 泛 , 而 不 仅 仅 局 限 在 X M L 解 析 中 , 毕 竟 它 的 名 称 是 “ 通 用 的 ” 占 位 符 解 析 器 。 S Q L 语 句 的 解 析 也 离 不 开 它 的 帮 助 。 S Q L 语 句 中 使 用 “ # ” 或 “ {xxx}”字符串。GenericTokenParser提供的占位符定位功能应用非常广泛,而不仅仅局限在 XML解析中,毕竟它的名称是“通用的”占位符解析器。SQL 语句的解析也离不开它的帮助。SQL语句中使用“#{}”或“ xxx”字符串。GenericTokenParser提供的占位符定位功能应用非常广泛,而不仅仅局限在XML解析中,毕竟它的名称是“通用的”占位符解析器。SQL语句的解析也离不开它的帮助。SQL语句中使用“#”或“{}”来设置的占位符也是依靠 GenericTokenParser 来完成解析的。TokenHandler 是一个接口,它只定义了一个抽象方法handleToken。handleToken 方法要求输入一个字符串,然后返回一个字符串。例如,可以输入一个变量的名称,然后返回该变量的值。PropertyParser类的内部类 VariableTokenHandler便继承了该接口。
/**
* GenericTokenParser类是通用的占位符解析器,共有三个属性
* /
public GenericTokenParser(String openToken, String closeToken, TokenHandler handler) {
this.openToken = openToken; // 占位符的起始标志
this.closeToken = closeToken; // 占位符的结束标志
this.handler = handler; //
}
private GenericTokenParser createParser(TokenHandler handler) {
return new GenericTokenParser("${", "}", handler);
}
/**
* 根据一个字符串,给出另一个字符串。多用在字符串替换等处
* 具体实现中,会以content作为键,从variables中找出并返回对应的值
* 由键寻值的过程中支持设置默认值,如果启用默认值,则content形如“key:defaultValue”
* 如果没有启用默认值,则content“key”
*/
@Override
public String handleToken(String content) {
if (variables != null) {
String key = content;
if (enableDefaultValue) { // 如果启用默认值,则设置默认值
// 找出键与默认值分隔符的位置
final int separatorIndex = content.indexOf(defaultValueSeparator);
String defaultValue = null;
if (separatorIndex >= 0) {
// 分隔符以前是键
key = content.substring(0, separatorIndex);
// 分隔符以后是默认值
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());
}
if (defaultValue != null) {
return variables.getProperty(key, defaultValue);
}
}
if (variables.containsKey(key)) {
// 尝试寻找非默认值
return variables.getProperty(key);
}
}
// 如果variables为null,不发生任何变化,直接原样返回
return "${" + content + "}";
}
textSqlNode.isDynamic()判定当前为非动态sql源。对于 TextSqlNode对象而言,如果内部含有“KaTeX parse error: Expected 'EOF', got '#' at position 41: …我们当前demo中因为只有一个#̲{}占位符所以它是非动态的,接…{}和动态标签的解析,注意看下图此时的#{}还没有被解析。但是当我们再往下执行就会发现#{}被替换为了?,在使用MixedSqlNode构建RawSqlSource的构造方法里又发生了什么??
通过观察构造函数我们大致可以初步猜测是getSql()方法中发生了解析操作,很尴尬我猜错了这里只是将SqlNode rootSqlNode对象中的sql赋值给了 DynamicContext context中的 StringJoiner sqlBuilder属性。StringJoiner 是jdk8新加的类这里不多做解释。继续往下会调用另一个重载构造函数。
public RawSqlSource(Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) {
this(configuration, getSql(configuration, rootSqlNode), parameterType);
}
public void appendSql(String sql) {
sqlBuilder.add(sql);
}
这里又回到了我们熟悉的GenericTokenParser,在之前判断动态sql源时它用来解析KaTeX parse error: Expected 'EOF', got '#' at position 20: …当下我们可以看到此时它用来解析#̲{}。具体过程我们就不再深入跟…{}时基本一致,最终它会将参数占位符#{}转换为?。下面我们进入handler.getParameterMappings()这里有我们需要关注的点,之前在我们创建ParameterMappingTokenHandler handler 对象的时候就已经将parameterType赋值给了其中的 private Class parameterType字段,而在将#{}解析为?时再调用handleToken(expression.toString())的过程中会将我们的sql方法参数类型转换为ParameterMapping并加入到private List parameterMappings中。所以当我们创建StaticSqlSource对象handler.getParameterMappings()时就会获取到ParameterMapping其中记录着javaType,jdbcType,typeHandler等许多关键信息。
至此我们的sqlSource对象算圆满创建完成,继续回到XMLStatementBuilder中接着会获取StatementType来记录我们的SQL语句种类,指是否为预编译的语句、是否为存储过程等。一直往下直接进入最最关键的一步构建MappedStatement对象。还记得我们之前说的与 SQL 语句处理功能相关的类主要有三个,它们是MappedStatement类、SqlSource类和 BoundSql类。其中 MappedStatement类表示的是数据库操作节点(select、insert、update、delete四类节点)内的所有内容。
生成MappedStatement加入到configuration对象中
我们可以看一下一个MappedStatement对象都包含了哪些内容, builderAssistant.addMappedStatement(。。。)成功将我们当前解析的sql转换为MappedStatement对象并加入到configuration对象中。到这里studentMapper.xml的解析工作就全部完成,并将其加入到configuration的LoadedResource标识这已经加载完毕。最后bindMapperForNamespace()方法将再次确认我们的mapper与mapper.xml双双完成注册。
public final class MappedStatement {
private String resource;//mapper配置文件名,如:UserMapper.xml
private Configuration configuration;//全局配置
private String id;//节点的id属性加命名空间,如:com.lucky.mybatis.dao.UserMapper.selectByExample
private Integer fetchSize;
private Integer timeout;//超时时间
private StatementType statementType;//操作SQL的对象的类型
private ResultSetType resultSetType;//结果类型
private SqlSource sqlSource;//sql语句
private Cache cache;//缓存
private ParameterMap parameterMap;
private List<ResultMap> resultMaps;
private boolean flushCacheRequired;
private boolean useCache;//是否使用缓存,默认为true
private boolean resultOrdered;//结果是否排序
private SqlCommandType sqlCommandType;//sql语句的类型,如select、update、delete、insert
private KeyGenerator keyGenerator;
private String[] keyProperties;
private String[] keyColumns;
private boolean hasNestedResultMaps;
private String databaseId;//数据库ID
private Log statementLog;
private LanguageDriver lang;
private String[] resultSets;
}
解析完成后,会将mapper.xml文件加入到configuration对象的loaderReource对象中用来表示已经加载过。接着 parsePendingResultMaps();与 XMLConfigBuilder类中的 parse方法不同,XMLMapperBuilder的 parse方法结尾处有三个 parsePending*方法。它们用来处理解析过程中的暂时性错误。由 configurationElement(parser.evalNode("/mapper"))语句触发后,系统会依次解析映射文件的各个节点。解析时是从上到下读取文件解析的,可能会解析到一个节点,但它引用的节点还没有被定义。例如在解析“id=“girlUserMap””的 resultMap时,它通过“extends=“userMap””引用的“id=“userMap””的 resultMap由于位置处在girlUserMap的下方所以还未被读入。此时就会出现暂时性的错误。遇到这样的情况mybatis就会采用暂时标记完全处理完之后再回过头重新尝试一次的策略。这是解决无序依赖的一种常见办法,即先尝试第一轮解析,并在解析时将所有节点读入。之后进行第二轮解析,处理第一轮解析时依赖寻找失败的节点。由于已经在第一遍解析时读入了所有节点,因此第二遍解析的依赖总是可以找到的。还有另外一种方法,更为直接和简单,即在第一轮解析时只读入所有节点,但不处理依赖关系,然后在第二轮解析时只处理依赖关系。Spring初始化时对 Bean之间的依赖处理采用的就是这种方式。parsePendingResultMaps()方法用来处理我们解析resultMap抛出异常时不完整的标签,在捕获不完整元素异常后会将其解析器加入到configuration对象的IncompleteResultMap中,在全部解析成功后会尝试再次去解析如果这次解析仍然失败mybatis就直接放弃对应元素并抛出异常。下面紧接两个方法功能类似就不详细说明。
catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
解析mapper接口中所有方法
在这里出现一个很陌生的判断isBridge()判断当前方法是否为桥接方法,什么是桥接方法。详细解析请见:https://blog.csdn.net/mhmyqn/article/details/47342577
https://www.cnblogs.com/kendoziyu/p/what-is-java-bridge-method.html
用白话文解释其实就是由于泛型擦除这个弊端,在方法中不能确定方法参数类型的情况下编译器会帮我们生成一个桥接方法将泛型方法与object方法联系起来。该操作是为了排除桥接方法。桥接方法是为了匹配泛型的类型擦除而由编译器自动引入的,并非用户编写的方法,因此要排除掉。
桥接方法是 JDK 1.5 引入泛型后,为了使Java的泛型方法生成的字节码和 1.5 版本前的字节码相兼容,由编译器自动生成的方法。
在字节码中,桥接方法会被标记 ACC_BRIDGE 和 ACC_SYNTHETIC
ACC_BRIDGE 用来说明 桥接方法是由 Java 编译器 生成的
ACC_SYNCTHETIC 用来表示 该类成员没有出现在源代码中,而是由编译器生成
桥接方法的产生:
实现泛型接口的类,编译器会为 这个类生成 桥接方法
继承超类的方法,并且升级方法的返回类型(即子类覆写超类方法时,返回类型升级为原返回类型的父类)
不是桥接方法,调用parseStatement(method);解析mapper方法,首先获取方法参数类型和sql语言解析驱动默认XMLLanguageDriver。然后会尝试通过getSqlSourceFromAnnotations()去解析方法是否使用了注解,如果有则生成对应的sqlsource对象。循环结束后依然会调用一个parsePendingMethods();尝试再次解析之前失败的方法。到最后将loadCompleted标识改为true揭示这mapper解析全部完成。如果解析失败的话则将之前加入configuration的mapper对象进行删除。最后返回configuration对象解析工作全部结束。又回到了我们第二章节sqlSessionFactory.openSession();使用sqlsession操作数据库的环节。到这里mapper初始化阶段就算暂时结束。