MyBatis源码的学习(14)---SqlSource和SqlNode


sqlSource接口中最底层的,最基础的是: StaticSqlSource,里面sql字段用于存放解析好的sql,比如将'#{}'替换为“?”占位符
BoundSql getBoundSql(Object parameterObject);RawSqlSource--.>StaticSqlSource-- >sql
常规的解析Mapper.xml的时候,我们创建SqlSource对象:
XMLStatementBuilder.parseStatementNode()
//XMLScriptBuilder类
public SqlSource parseScriptNode() {
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}一般我们的sql如果不存在动态标签,'${}',也就是isDynamic值为false时,我们创建的是一个RawSqlSource类型的对象,RawSqlSource中有一个SqlSource属性,是一个StaticSqlSource类型的对象,直接就会将'#{}'替换为‘?’占位符。这种类型的
SqlSource在getBoundSql()的时候,直接将StaticSqlSource.getBoundSql()返回,不需要进行parse操作。parse操作发生在我们的new RawSqlSource()这一步。
//RawSqlSource类
@Override
public BoundSql getBoundSql(Object parameterObject) {
return sqlSource.getBoundSql(parameterObject);
}
//StaticSqlSource类
@Override
public BoundSql getBoundSql(Object parameterObject) {
return new BoundSql(configuration, sql, parameterMappings, parameterObject);
}
对于,动态的sqlSource,DynamicSqlSource,我们只是直接创建了对象,并没有做sql的解析。sql的解析工作发生在,我们调用getBoundSql()的时候。

我们的sqlNode接口,使用了组合模式,用于构建一个树结构的数据。
MixedSqlNode混合节点,它下面可能还有其他节点,它的所有枝叶子节点都放到list中,我们拼接sql时候,遍历节点,然后组装就可以了。
public class MixedSqlNode implements SqlNode {
private final List contents;
public MixedSqlNode(List contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
//DynamicContext 里面有个stringBuild对象用来拼接sql,最终生成一个完整的sql(将动态标签,'${}'都处理好)
contents.forEach(node -> node.apply(context));
return true;
}
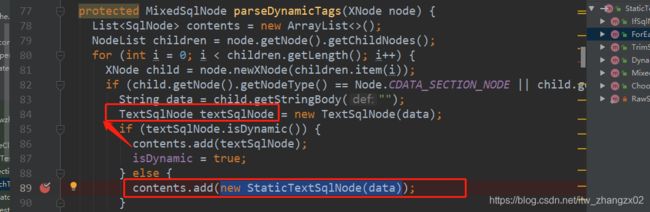
} 我们的根节点就是MixedSqlNode这个节点,它下面可以有很多平级的sqlNode,然后这些平级的sqlNode最终调用apply()方法,会一直解析下去,
最终我们最底层的sqlNode都是StaticTextSqlNode节点。
就比如,我们解析一对
片段。比如:
insert into u_user(usercode,username,createtime,usertype,mobile)
(#{user.userCode},#{user.userName}
,#{user.createTime},#{user.userType},#{user.mobile})
解析后:
insert into u_user(usercode,username,createtime,usertype,mobile)
values
(#{__frch_user_0.userCode},#{__frch_user_0.userName}
,#{__frch_user_0.createTime},#{__frch_user_0.userType},#{__frch_user_0.mobile})
,
(#{__frch_user_1.userCode},#{__frch_user_1.userName}
,#{__frch_user_1.createTime},#{__frch_user_1.userType},#{__frch_user_1.mobile})
,
(#{__frch_user_2.userCode},#{__frch_user_2.userName}
,#{__frch_user_2.createTime},#{__frch_user_2.userType},#{__frch_user_2.mobile})
我们再来看看,一般的文本节点:
TextSqlNode('${}') ,StaticTextSqlNode('#{}')在我们的TextSqlNode中,处理'${}'的一共有俩种TokenHandler:
DynamicCheckerTokenParser(只进行判断sql中是否有 '${}'存在,如果存在,最终生成一个DynamicSqlSource), BindingTokenParser(在我们调用getBoundSql的时候,会将'${}'进行赋值操作。select * from ${tablename} 变为
select * from user)另一种文本节点类:StaticTextSqlNode是最最基础的节点,它里面直接就是sql片段,可能包含'#{}'。
@Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
//处理动态标签和'${}',但是这时候,我们的'#{}'还未被处理
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
//parse方法中,会将'#{}'处理为"?"占位符,同时返回一个StaticSqlSource
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
//返回的就是一个最基础的 StaticSqlSource
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
//将实际入参放入map中
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}总结:对于非动态SQL(无sql标签或"$"),我们在生成sqlSource的时候,就会进行解析,将'#{}'替换为‘?’占位符。等到getBoundSql()的时候,直接返回值就可以了。
对于动态SQL,我们在调用getBoundSql()的时候才会开始做解析,解析完动态标签和'${]'之后,会继续进一步进行'#{}'的替换工作,然后返回一个BoundSql对象。