【C++】STL常用容器:string类(详解及模拟实现)
前言:
关于STL的学习,就从最常用的string类开始吧!在本篇博客中会详细介绍string的使用方法和细节,最后再模拟实现一个string类。
承接上文:【C++】模板初阶 | STL简介
废话不多说,下面直接进入正题
文章目录
-
-
- 1. 标准库中的string类
-
- 1.1 string类
- 1.2 string类常用接口
-
- 1.2.1 string类对象的常见构造
- 1.2.2 string类对象的容量操作
- 1.2.3 string类对象的访问及遍历操作
- 1.2.4 string类对象的增删查改操作
- 1.2.5 string类非成员函数
- 2 string类的模拟实现
-
- 2.1 string类面试问题
- 2.2 浅拷贝
- 2.3 深拷贝
-
- 2.3.1 传统写法的String
- 2.3.2 现代写法
- 2.4 写时拷贝(了解)
- 2.5 string类的模拟实现(包含全部的常用接口 | 代码量:400行左右)
-
1. 标准库中的string类
1.1 string类
点击跳转:string类的文档,初学者可以多多查阅该文档辅助学习
string类相关知识介绍:
- 字符串是表示字符序列的类
- 标准的字符串类提供了对此对象的支持,其接口类似于标准字符容器的接口,但添加了专门用于操作单字节字符字符串的设计特性
string类是使用char,即作为它的字符类型,使用它的默认char_traits和分配器类型(关于模板的更多信息,可在上面提供的文档中查阅basic_string)string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类,并使用char_traits和allocator作为basic_string的默认参数(更多具体信息可直接参考basic_string)- 注意,这个类独立于所使用的编码来处理字节:即如果用来处理多字节或变长字符(如UTF-8)的序列,这个类的所有成员(如长度、大小)以及它的迭代器,将仍然按照字节(而不是实际编码的字符)来操作
总结:
- string是表示字符串的字符串类
- 该类的接口与常规容器接口基本相同,再添加了一些专门用来操作string的常规操作
- string在底层实现实际是:basic_string模板类实例的别名
typedef basic_stirng<char, char_traits, allocator> string;
-
不能操作多字节或变长字符的序列
-
在使用string类时,必须包含头文件string以及using namespace std;
#includeusing namespace std;
1.2 string类常用接口
需注意,这里只介绍常用接口,string类除了常用接口,还有很多其他的接口函数,这些在以后做题有需要再自行查阅文档即可,介绍了常用接口,其他接口上手也会比较容易
1.2.1 string类对象的常见构造
| (constructor)函数名称 | 功能说明 |
|---|---|
| string()(重点) | 构造空的string类对象,即空字符串 |
| string(const char* s)(重点) | 用C-string来构造string类对象 |
| string(const char* s, size_t n) | 用C-string前n个字符来构造string类对象 |
| string(size_t n, char c) | string类对象中包含n个字符c |
| string(const string& s)(重点) | 拷贝构造函数 |
| string(const string& s, size_t pos, size_t len = npos) | 从s对象pos位置字符开始,依次复制,跨越len字符部分(如果len大于pos后面部分长度,直接拷贝到字符串末尾) |
下面是一段使用string构造函数的参考代码:
void test_string1()
{
//构造空的string对象s1
string s1;
//用C-string构造s2对象
string s2("hello world");
//string s2 = "hello world";//支持,隐式类型转换,构造 + 拷贝构造 -》优化后 -- 直接构造 二者等价
cout << s1 << endl;
cout << s2 << endl;
//拷贝构造
string s3(s2);
cout << s3 << endl;
//string(const string & str, size_t pos, size_t len = npos);
// npos 的值表示直到 str 结束的所有字符。
//从第6个字符的位置,向后拷贝5个字符
string s4(s2, 6, 5);
cout << s4 << endl;
//第三个参数len大于后面字符长度,有多少拷贝多少,直到结尾
string s5(s2, 6, 15);
cout << s5 << endl;
//缺省第三个参数,默认从pos位置开始拷贝,直到结尾
string s6(s2, 6);
cout << s6 << endl;
//用C-string前5个字符初始化
string s7("hello world", 5);
cout << s7 << endl;
//用100个字符x初始化
string s8(100, 'x');
cout << s8 << endl;
}
1.2.2 string类对象的容量操作
| 函数名称 | 功能说明 |
|---|---|
| size_t size() const(重点) | 返回字符串有效字符长度(以字节为单位) |
| size_t length() const | 返回字符串有效字符长度(以字节为单位) |
| size_t capacity() const | 返回当前为字符串分配的存储空间的大小,以字节为单位表示 |
| bool empty() const(重点) | 检测字符串是否为空串,是则返回true,否则返回false |
| void clear()(重点) | 清空有效字符,该字符串将变为空字符串(长度为 0 个字符) |
| void reserve(size_t n = 0)(重点) | 为字符串预留空间:请求将字符串容量调整为计划的大小变化,使其长度不超过 n 个字符。如果 n 大于当前字符串容量,则该函数会导致容器将其容量增加到 n 个字符(或更大)。在所有其他情况下,收缩字符串容量被视为非绑定请求:容器实现可以自由地进行优化,并使字符串的容量大于n。 |
| void resize(size_t n)(重点) | 将字符串的大小调整为 n 个字符的长度。如果 n 小于当前字符串长度,则当前值将缩短为其前 n 个字符,并删除超出 nth 的字符。如果 n 大于当前字符串长度,且未指定字符c,则将末尾初始化为空字符。 |
| void resize(size_t n, char c)(重点) | n小于当前长度,同上;n大于当前长度,则通过在末尾插入所需数量的字符以达到 n 的大小来扩展当前内容。如果指定了 c,则新元素将初始化为 c 的副本。 |
注意:
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是使用size()
- clear()只是将string中的有效字符情况,但不会改变底层空间的大小
- resize(size_t n) 与resize(size_t n, char c) 都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(size_t n) 是用0来填充多出来的元素空间,resize(size_t n, char c) 是用字符c来填充多出来的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,则底层空间总大小不变
- reserve(size_t n = 0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserve不会改变容量大小(这个函数一般用来扩容)
下面是一段测试代码:
//------------------------------------------------------------------------
// 测试string容量相关的接口
// size/clear/resize
void Test_string2()
{
// 注意:string类对象支持直接用cin和cout进行输入和输出
string s("hello, hanhan!!!");
cout << s.size() << endl;
cout << s.length() << endl;
cout << s.capacity() << endl;
cout << s << endl;
// 将s中的字符串清空,注意清空时只是将size清0,不改变底层空间的大小
s.clear();
cout << s.size() << endl;
cout << s.capacity() << endl;
// 将s中有效字符个数增加到10个,多出位置用'a'进行填充
// “aaaaaaaaaa”
s.resize(10, 'a');
cout << s.size() << endl;
cout << s.capacity() << endl;
// 将s中有效字符个数增加到15个,多出位置用缺省值'\0'进行填充
// "aaaaaaaaaa\0\0\0\0\0"
// 注意此时s中有效字符个数已经增加到15个
s.resize(15);
cout << s.size() << endl;
cout << s.capacity() << endl;
cout << s << endl;
// 将s中有效字符个数缩小到5个
s.resize(5);
cout << s.size() << endl;
cout << s.capacity() << endl;
cout << s << endl;
}
//reserve
//-------------------------------------------------------------------
void Test_string3()
{
string s;
// 测试reserve是否会改变string中有效元素个数
s.reserve(100);
cout << s.size() << endl;
cout << s.capacity() << endl;
// 测试reserve参数小于string的底层空间大小时,是否会将空间缩小
s.reserve(50);
cout << s.size() << endl;
cout << s.capacity() << endl;
}
// 利用reserve提高插入数据的效率,避免增容带来的开销
//---------------------------------------------------------------------
void TestPushBack()
{
string s;
size_t sz = s.capacity();
cout << "making s grow:\n";
for (int i = 0; i < 100; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
//——————————————————————————————————
// 构建vector(容器)时,如果提前已经知道string中大概要放多少个元素,可以提前将string中空间设置好
void TestPushBackReserve()
{
string s;
s.reserve(100);
size_t sz = s.capacity();
cout << "making s grow:\n";
for (int i = 0; i < 100; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
1.2.3 string类对象的访问及遍历操作
string对象的遍历方法有:
- for + [ ]
- 范围for(C++11支持更简洁的范围for的新遍历方式,底层实际上是迭代器)
- 迭代器 begin() + end()
| 函数名称 | 功能说明 |
|---|---|
| char& operator[ ] (size_t pos)(重点);const char& operator[ ] (size_t pos)const(重点) | 返回pos位置的字符,const string对象调用 |
| iterator begin();const_iterator begin() const | 返回指向字符串的第一个字符的迭代器 |
| iterator end();const_iterator end() const | 返回指向字符串的末尾后字符的迭代器(获取最后一个字符下一个位置的迭代器) |
| reverse_iterator rbegin();const_reverse_iterator rbegin() const | 返回指向字符串的最后一个字符(即其反向开头)的反向迭代器 |
| reverse_iterator rend()const_reverse_iterator rend() const | 返回一个反向迭代器,该迭代器指向字符串第一个字符(被视为其反向端点)前面的理论元素 |
测试代码1:
// string的遍历
// begin()+end() for+[] 范围for
// 注意:string遍历时使用最多的还是for+下标 或者 范围for(C++11后才支持)
// begin()+end()大多数使用在需要使用STL提供的算法操作string时,比如:采用reverse逆置string
void Teststring4()
{
string s1("hello hanhan");
const string s2("Hello hanhan");
cout << s1 << " " << s2 << endl;
cout << s1[0] << " " << s2[0] << endl;
s1[0] = 'H';
cout << s1 << endl;
// s2[0] = 'h'; 代码编译失败,因为const类型对象不能修改
}
void Test_string4()
{
string s("hello hanhan");
// 3种遍历方式:
// 需要注意的以下三种方式除了遍历string对象,还可以遍历是修改string中的字符,
// 另外以下三种方式对于string而言,第一种使用最多
// 1. for+operator[]
for (size_t i = 0; i < s.size(); ++i)
cout << s[i] << endl;
// 2.迭代器
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it << endl;
++it;
}
// string::reverse_iterator rit = s.rbegin();
// C++11之后,直接使用auto定义迭代器,让编译器自行推导迭代器的类型
auto rit = s.rbegin();
while (rit != s.rend())
cout << *rit << endl;
// 3.范围for
for (auto ch : s)
cout << ch << endl;
}
测试代码2:
void test_string4()
{
string s("hello");
//迭代器
//iterator像指针一样类型,有可能是指针,也有可能不是指针,但他的用法像指针一样
string::iterator it = s.begin();
while (it != s.end())//注意使用的是不等于,不使用小于!!!!!
{
cout << *it << " ";
++it;
}
cout << endl;
//范围for -- 自动迭代,自动判断结束
//依次取s中的每个字符赋值给ch
for (auto ch : s)
{
cout << ch << " ";
}
cout << endl;
list<int> lt(10, 1);
list<int>::iterator lit = lt.begin();
while (lit != lt.end())//
{
cout << *lit << " ";
lit++;
}
cout << endl;
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
//范围for的底层其实就是迭代器
}
void PrintString(const string& str)
{
//const迭代器,可读不可写,不能改变
string::const_iterator it = str.begin();
while (it != str.end())
{
cout << *it << " ";
it++;
}
cout << endl;
string::const_reverse_iterator rit = str.rbegin();
while (rit != str.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl;
}
void test_string5()
{
string s("hello");
//反向迭代器
string::reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl;
PrintString(s);
}
用迭代器遍历还是一个比较重要的知识,后面要学的vector、list也有迭代器的遍历,所以上面的两段测试代码,建议可以跟着在vs下跑一遍,尽量熟悉使用方法并加深理解。
1.2.4 string类对象的增删查改操作
| 函数名称 | 功能说明 |
|---|---|
| void push_back (char c) | 将字符 c 追加到字符串的末尾,使其长度增加 1 |
| string& append (const string& str)(该函数还有其他重载形式) | 在字符串后追加一个字符串 |
| string& operator+= (const string& str)(重点);string& operator+= (const char* s)(重点);string& operator+= (char c)(重点) | 在字符串的当前值末尾追加其他字符(或字符串)来扩展字符串 |
| const char* c_str() const(重点) | 获取 C 字符串等效项(即string->C字符串) |
| size_t find (const string& str, size_t pos = 0) const(重点);size_t find (const char* s, size_t pos = 0) const(重点);size_t find (char c, size_t pos = 0) const(重点);static const size_t npos = -1 | 从字符串pos位置开始往后搜索指定的序列的第一个匹配项,并返回第一个匹配项的第一个字符的位置;若未找到,则返回npos(size_t的最大值,即-1) |
| rfind(使用方法和上面的find一样,也有其他重载形式) | 从字符串pos位置开始往前搜索指定的序列的第一个匹配项,并返回第一个匹配项的第一个字符的位置;若未找到,则返回npos(size_t的最大值,即-1) |
| string substr (size_t pos = 0, size_t len = npos) const | 在str中从pos位置开始,截取len个字符,返回一个新构造的对象,其值初始化为此对象的子字符串的副本 |
| string& erase (size_t pos = 0, size_t len = npos) | 删除字符串值中从字符位置 pos 开始并跨越 len 字符的部分 |
注意:
- 在string尾部追加字符时,str.push_back© / str.append(1, c) / str += ‘c’ 三种方法实现方式基本一样,一般情况下string类的+=操作用得比较多,+=操作不仅可以连接单个字符,还可以连接字符串
- 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好,以此减少扩容时的消耗
测试代码:
// 测试string:
// 1. 插入(拼接)方式:push_back append operator+=
// 2. 正向和反向查找:find() + rfind()
// 3. 截取子串:substr()
// 4. 删除:erase
void Teststring5()
{
string str;
str.push_back(' '); // 在str后插入空格
str.append("hello"); // 在str后追加一个字符"hello"
str += 'b'; // 在str后追加一个字符'b'
str += "it"; // 在str后追加一个字符串"it"
cout << str << endl;
cout << str.c_str() << endl; // 以C语言的方式打印字符串
// 获取file的后缀
string file("string.cpp");
size_t pos = file.rfind('.');
string suffix(file.substr(pos, file.size() - pos));
cout << suffix << endl;
// npos是string里面的一个静态成员变量
// static const size_t npos = -1;
// 取出url中的域名
string url("http://www.cplusplus.com/reference/string/string/find/");
cout << url << endl;
size_t start = url.find("://");
if (start == string::npos)
{
cout << "invalid url" << endl;
return;
}
start += 3;
size_t finish = url.find('/', start);
string address = url.substr(start, finish - start);
cout << address << endl;
// 删除url的协议前缀
pos = url.find("://");
url.erase(0, pos + 3);
cout << url << endl;
}
1.2.5 string类非成员函数
| 函数名称 | 功能说明 |
|---|---|
| string operator+ (const string& lhs, const string& rhs);string operator+ (const string& lhs, const char* rhs);string operator+ (const char* lhs, const string& rhs);string operator+ (const string& lhs, char rhs);string operator+ (const string& lhs, char rhs); | 返回一个新构造的字符串对象,其值是 lhs 中的字符后跟 rhs 的字符的串联。(尽量少用,因为传值返回,导致深拷贝效率低) |
| istream& operator>> (istream& is, string& str);(重点) | 输入运算符重载 |
| ostream& operator<< (ostream& os, const string& str);(重点) | 输出运算符重载 |
| istream& getline (istream& is, string& str, char delim)(重点);istream& getline (istream& is, string& str)(重点); | 获取一行字符串:从 is 中提取字符并将其存储到 str 中,直到找到分隔字符 delim(或换行符“\n”)。如果到达文件的末尾,或者在输入操作期间发生其他错误,则提取也会停止。如果找到分隔符,则将其提取并丢弃(即不存储它,下一个输入操作将在它之后开始)。请注意,调用之前的任何内容都将替换为新提取的序列。每个提取的字符都追加到字符串中,就好像调用了其成员push_back |
| relational operators (string)(重点) | 大小比较(大小比较比较简单,若想了解详细内容请查阅文档) |
上面列举了string类常用的一些接口,这些要求大家熟悉使用,string类中还有很多其他的操作,这里不再一一列出,以后遇到时,可自行查阅文档:string类的文档
2 string类的模拟实现
2.1 string类面试问题
在面试中,面试官总喜欢让学生去模拟实现string类,最主要是模拟实现string类的构造、拷贝构造、赋值运算符重载以及析构函数。大家可以看看下面的string类实现是否有问题?
// 为了和标准库区分,此处使用String
class String
{
public:
/*
String()
:_str(new char[1])
{
_str = '\0';
}
*/
//String(const char* str = "\0") 错误示范,实际上有两个\0
//String(const char* str = nullptr) 错误示范
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以直接断言报错
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
// 测试
void TestString()
{
String s1("hello world!");
String s2(s1);
}
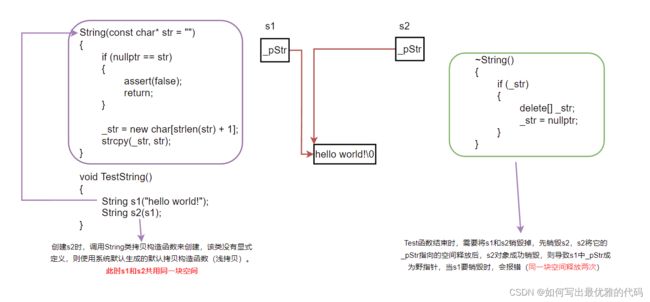
结论:上面的String类没有显式定义其拷贝构造函数于赋值运算符重载,此时编译器会生成默认的,当使用s1拷贝构造s2时,编译器会调用默认的拷贝构造,最终导致s1、s2共用一块内存空间,在销毁对象时,对同一块空间释放多次而导致程序崩溃,这种就是浅拷贝的危害
2.2 浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时,该资源就会被释放掉,此时另一个对象并不知道该资源已被释放,以为还有效,所以当它继续对资源进行访问时操作时,就会发生访问违规,程序崩溃。
2.3 深拷贝
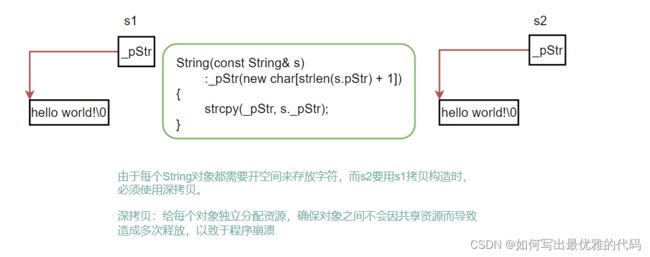
深拷贝:与浅拷贝相对应,一般用来解决浅拷贝问题,即:实现每个对象都有一份独立的资源,不要和其他对象共享。在一个类中涉及到资源的管理时,其拷贝构造函数、赋值运算符重载以及析构函数必须显式定义,一般情况下都是按照深拷贝方式实现。
2.3.1 传统写法的String
class String
{
public:
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以认为程序error
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
strcpy(_str, s._str);
}
String& operator=(const String& s)
{
if (this != &s)
{
char* pStr = new char[strlen(s._str) + 1];
strcpy(pStr, s._str);
delete[] _str;
_str = pStr;
}
return *this;
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
2.3.2 现代写法
class String
{
public:
String(const char* str = "")
{
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
// 对比下传统写法和现代写法的拷贝构造、赋值那个实现比较好?
String(const String& s)
: _str(nullptr)
{
String strTmp(s._str);
swap(_str, strTmp._str);
}
String& operator=(String s)
{
swap(_str, s._str);
return *this;
}
/*
String& operator=(const String& s)
{
if(this != &s)
{
String strTmp(s);
swap(_str, strTmp._str);
}
return *this;
}
*/
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
可以对比一下传统写法和现代写法中的拷贝构造、赋值的写法,看看哪个更优。
实际上,现代写法感觉会比较好,它利用了一些临时对象作为工具,交换他们所指向的空间,在出了函数作用域,由系统进行自我销毁,不再需要手动去释放。
2.4 写时拷贝(了解)
写时拷贝是一种拖延症,是在浅拷贝的基础上增加了引用计数的方式来实现的。
引用计数:用来记录同一块资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该资源,就给计数增加1。当某个对象被销毁时,先给该引用计数减1,然后再检查是否需要释放资源,如果计数为1,说明该对象是资源的最后一个使用者,将该对象销毁时,可以将该资源进行释放;否则就不能释放,因为还有其他对象在使用该资源。
2.5 string类的模拟实现(包含全部的常用接口 | 代码量:400行左右)
#include