spark第五章:SparkSQL实例
系列文章目录
spark第一章:环境安装
spark第二章:sparkcore实例
spark第三章:工程化代码
spark第四章:基本操作
spark第五章:SparkSQL实例
文章目录
- 系列文章目录
- 前言
- 一、数据准备
-
- 1.数据导入
- 二、项目实例
-
- 1.需求简介
- 2.需求分析
- 3.功能实现
- 4.代码实现
- 总结
前言
上一次我们介绍了一下SparkSQL的基本操作,这次我们来完成一个项目实例.
一、数据准备
我们这次 Spark-sql 操作中所有的数据均来自 Hive,首先在 Hive 中创建表,,并导入数据。
一共有 3 张表: 1 张用户行为表,1 张城市表,1 张产品表.
具体数据去尚硅谷找.
1.数据导入
现在Hive里边创建一个atguigu数据库

SparkSql_Test.scala
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object SparkSql_Test {
def main(args: Array[String]): Unit = {
// 变更系统用户为atguigu
System.setProperty("HADOOP_USER_NAME","atguigu")
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use atguigu")
//准备数据
spark.sql(
"""
|CREATE TABLE `user_visit_action`(
| `date` string,
| `user_id` bigint,
| `session_id` string,
| `page_id` bigint,
| `action_time` string,
| `search_keyword` string,
| `click_category_id` bigint,
| `click_product_id` bigint,
| `order_category_ids` string,
| `order_product_ids` string,
| `pay_category_ids` string,
| `pay_product_ids` string,
| `city_id` bigint)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'datas/user_visit_action.txt' into table atguigu.user_visit_action
|""".stripMargin)
spark.sql(
"""
|CREATE TABLE `product_info`(
| `product_id` bigint,
| `product_name` string,
| `extend_info` string)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'datas/product_info.txt' into table atguigu.product_info
|""".stripMargin)
spark.sql(
"""
|CREATE TABLE `city_info`(
| `city_id` bigint,
| `city_name` string,
| `area` string)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'datas/city_info.txt' into table atguigu.city_info
|""".stripMargin)
//随便输出一下
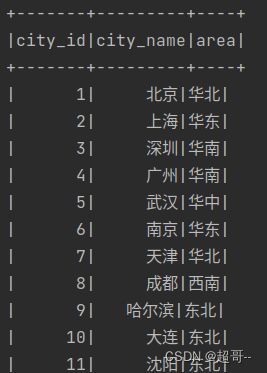
spark.sql("""select * from city_info""").show
spark.close()
}
}
正常输出代表执行成功
二、项目实例
1.需求简介
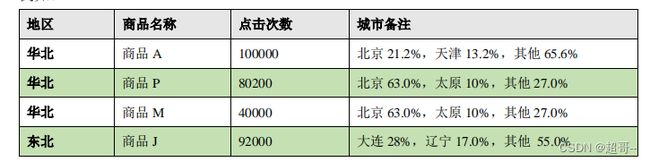
这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示.
2.需求分析
- 查询出来所有的点击记录,并与 city_info 表连接,得到每个城市所在的地区,与Product_info 表连接得到产品名称
- 按照地区和商品 id 分组,统计出每个商品在每个地区的总点击次数 每个地区内按照点击次数降序排列
- 只取前三名
- 城市备注需要自定义 UDAF 函数
3.功能实现
- 连接三张表的数据,获取完整的数据(只有点击)
- 将数据根据地区,商品名称分组
- 统计商品点击次数总和,取 Top3
- 实现自定义聚合函数显示备注
4.代码实现
SparkSql_Test1.scala
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
import org.apache.spark.sql.expressions.Aggregator
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object SparkSql_Test1 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","atguigu")
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use atguigu")
//查询基本数据
spark.sql(
"""
| SELECT
| a.*,
| p.product_name ,
| c.area ,
| c.city_name
| FROM user_visit_action a
| join product_info p on a.click_category_id = p.product_id
| JOIN city_info c on a.city_id =c.city_id
| WHERE a.click_product_id >-1
|""".stripMargin).createOrReplaceTempView("t1")
spark.udf.register("cityRemark",functions.udaf(new CityRemakeUDAF()))
// 根据区域,商品进行数据聚合
spark.sql(
"""
| select
| area,
| product_name,
| count(*) as clickCnt,
| cityRemark(city_name) as cityremake
| from t1 group by area,product_name
|""".stripMargin).createOrReplaceTempView("t2")
// 区域内对点击数量进行排行
spark.sql(
"""
| select
| *,
| rank() over (partition by area order by clickCnt desc ) as rank
| from t2
|""".stripMargin).createOrReplaceTempView("t3")
//取前三名
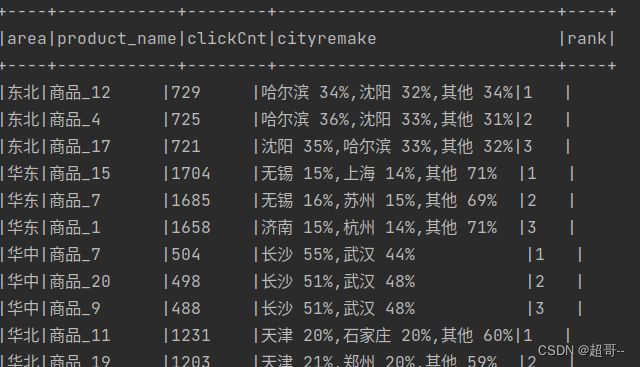
spark.sql(
"""
| select
| *
| from t3 where rank<=3
|
|""".stripMargin).show(truncate = false)
spark.close()
}
case class Buffer(var total :Long,var cityMap:mutable.Map[String,Long])
//自定义函数:实现城市备注功能
class CityRemakeUDAF extends Aggregator[String,Buffer,String]{
override def zero: Buffer = {
Buffer(0,mutable.Map[String,Long]())
}
override def reduce(buff: Buffer, city: String): Buffer = {
buff.total+=1
val newCount: Long = buff.cityMap.getOrElse(city,0L)+1
buff.cityMap.update(city,newCount)
buff
}
override def merge(buff1: Buffer, buff2: Buffer): Buffer = {
buff1.total+=buff2.total
val map1=buff1.cityMap
val map2=buff2.cityMap
// buff1.cityMap=map1.foldLeft(map2){
// case (map , (city,cnt)) =>{
// val newCount: Long = map.getOrElse(city, 0L) + cnt
// map.update(city,newCount)
// map
// }
// }
map2.foreach{
case (city,cnt)=>{
val newCount: Long = map1.getOrElse(city,0L)+cnt
map1.update(city,newCount)
}
}
buff1.cityMap=map1
buff1
}
override def finish(buff: Buffer): String = {
val remarkList =ListBuffer[String]()
val totalcnt: Long = buff.total
val cityMap: mutable.Map[String, Long] = buff.cityMap
val cityCntList: List[(String, Long)] = cityMap.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(2)
val hasMore: Boolean = cityMap.size > 2
var rsum=0L
cityCntList.foreach{
case (city,cnt)=>{
var r=cnt*100/totalcnt
remarkList.append(s"${city} ${r}%")
rsum+=r
}
}
if (hasMore){
remarkList.append(s"其他 ${100-rsum}%")
}
remarkList.mkString(",")
}
override def bufferEncoder: Encoder[Buffer] = Encoders.product
override def outputEncoder: Encoder[String] = Encoders.STRING
}
}
总结
SparkSQL的内容到这里基本就结束了,下一步开始学习SparkStreaming