Redis是单线程的,为什么还会这么快?
近段时间在看面试题,看到了这个问题的时候我一下就来了兴致,所以找资料深入研究了一下。
首先,我们先要去了解Redis是什么?
一、Redis简介
Redis是一个开源的内存中的数据结构存储系统,它可以用作:数据库、缓存、消息中间件。
它支持多种类型的数据结构:1、字符串(String),散列值(Hash),列表(List),集合(Set),有序集合(Sorted Set、ZSet) 与范围查询,Bitmaps,Hyperloglogs和地理空间(Geospatial)索引半径查询,最常见的数据结果类型由:String、List、Set、Hash、ZSet这五种。
Redis中内置了复制(Replication),LUA脚本(Lua scripting),LRU驱动事件(LRU evication),事务(Transactions)和不同级别的磁盘持久化(Persistence),并通过Redis哨兵(Sentinel),自动分区(Cluster)提供高可用性。
Redis也提供了持久化的选项,这些选项可以让用户将自己的数据保存到磁盘上面进行存储。根据实际情况,可以每隔一定时间将数据集导出到磁盘(快照),或者追加到命令日志中(AOF只追加文件),它会在执行写命令时,将被执行的写命令复制到磁盘里面,用户也可以自己关闭持久化功能,将Redis作为一个高效的网络的缓存数据功能使用。
Redis不使用表,它的数据库不会预定义或者强制要求用户对Redis存储的不同数据进行关联。
数据库的工作模式按照存储方式可分为:硬盘数据库和内存数据库,Redis将数据存储在内存里面,读写数据的时候都不会受硬盘I/O速度限制,所以速度非常快。
1、硬盘数据库的工作模式:
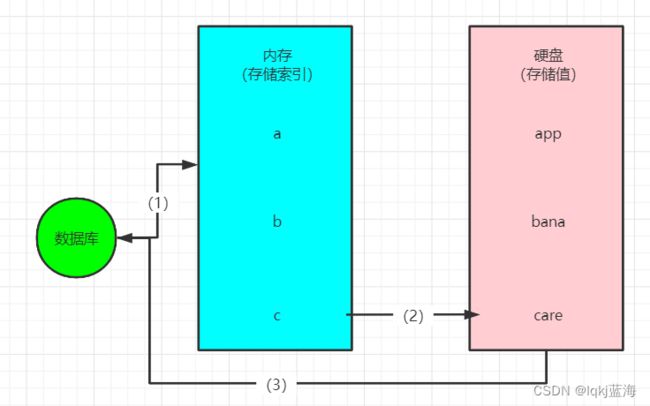
2、内存数据库工作模式

二、Redis到底有多快?
Redis采用的是基于内存的单进程单线程模型的KV数据库,由C语言编写,官网提供的数据是可以达到10w+的QPS(每秒内查询次数)。
这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
三、Redis为什么这么快?
1、Redis完全基于内存,绝大多数请求都是单纯的内存操作,非常快速,数据存在内存中,类似HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据的操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁的操作,没有因为可能出现死锁而导致的性能消耗;
4、采用多路 I / O 复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及客户端之间通信的应用协议不一样,Redis直接自己构建了VM机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
四、Redis为什么是单线程的?
上面的分析都是在强调Redis很快,官网表示,因为Redis是基于内存的操作,CPU不是Redis的性能瓶颈,Redis的瓶颈是机器的内存大小和网络带宽,既然单线程容易实现,而且CPU不会成为瓶颈,所以自然而然就采用了单线程了,因为如果使用多线程的话,CPU会进行上下文操作,这是一个耗时的操作。
注意:我们所说的单线程,只是在处理网络请求的时候只有一个线程来处理,一个正式的Redis Server 运行的时候肯定不止一个线程,例如:Redis进行持久化的时候会以子进程的方式执行
五、注意点
1、我们知道Redis是用“单线程和多路复用IO模型”来实现高性能的内存数据服务的,这种机制避免了使用锁,但是同时这种机制在进行sunion之类的比较耗时的命令时会使redis 的并发下降。
因为是单一的线程,所以同一时刻只有一个操作在进行,所以,耗时的命令会导致并发下降,不只是读并发,写并发也会下降。而单一线程也只能用到一个CPU核心,所以可以在同一多核的服务器中,可以启动多个实例,组成master-master或者master-slave的形式,耗时的读命令可以完全在slave进行。
2、我们不能任由操作系统负载均衡,因为我们自己更了解自己的程序,所以,我们可以手动地为其分配cpu核,而不会过多地占用CPU,或是让我们关键进程和一堆别的进程挤在一起。
CPU是一个重要的影响因素,因为是单线程模式,Redis更喜欢大缓存快速CPU,而不是多核。