Kafka 核心源码解读【六】--副本管理模块
文章目录
-
- 1 AbstractFetcherThread:拉取消息分几步?
-
- 1.1 课前案例
- 1.2 抽象基类:AbstractFetcherThread
-
- 1.2.1 类定义及字段
- 1.2.2 分区读取状态
- 1.2.3 重要方法
- 1.3 总结
- 2 ReplicaFetcherThread:Follower如何拉取Leader消息?
-
- 2.1 AbstractFetcherThread 类:doWork 方法
- 2.2 子类:ReplicaFetcherThread
-
- 2.2.1 类定义及字段
- 2.2.2 processPartitionData 方法
- 2.2.3 buildFetch 方法
- 2.2.4 truncate 方法
- 2.3 总结
- 3 ReplicaManager(上):必须要掌握的副本管理类定义和核心字段
-
- 3.1 代码结构
- 3.2 ReplicaManager 类定义
- 3.3 重要的自定义字段
-
- 3.3.1 controllerEpoch
- 3.3.2 allPartitions
- 3.3.3 replicaFetcherManager
- 3.4 总结
- 4 ReplicaManager(中):副本管理器是如何读写副本的?
-
- 4.1 副本写入:appendRecords
- 4.2 副本读取:fetchMessages
- 4.3 总结
- 5 ReplicaManager(下):副本管理器是如何管理副本的?
-
- 5.1 分区及副本管理
-
- 5.1.1 becomeLeaderOrFollower 方法
- 5.1.2 makeLeaders 方法
- 5.1.3 makeFollowers 方法
- 5.2 ISR 管理
-
- 5.2.1 maybeShrinkIsr
- 5.2.2 maybePropagateIsrChanges 方法
- 5.3 总结
- 6 MetadataCache:Broker是怎么异步更新元数据缓存的?
-
- 6.1 MetadataCache 类
-
- 6.1.1 类定义及字段
- 6.1.2 重要方法
- 6.1.3 判断类方法
- 6.1.4 获取类方法
- 6.1.5 更新类方法
- 6.2 总结
1 AbstractFetcherThread:拉取消息分几步?
从今天开始,我们正式进入到第 5 大模块“副本管理模块”源码的学习。
在 Kafka 中,副本是最重要的概念之一。为什么这么说呢?在前面的课程中,我曾反复提到过副本机制是 Kafka 实现数据高可靠性的基础。具体的实现方式就是,同一个分区下的多个副本分散在不同的 Broker 机器上,它们保存相同的消息数据以实现高可靠性。对于分布式系统而言,一个必须要解决的问题,就是如何确保所有副本上的数据是一致的。
针对这个问题,最常见的方案当属 Leader/Follower 备份机制(Leader/Follower Replication)。在 Kafka 中, 分区的某个副本会被指定为 Leader,负责响应客户端的读写请求。其他副本自动成为 Follower,被动地同步 Leader 副本中的数据。
这里所说的被动同步,是指 Follower 副本不断地向 Leader 副本发送读取请求,以获取 Leader 处写入的最新消息数据。
那么在接下来的两讲,我们就一起学习下 Follower 副本是如何通过拉取线程做到这一点的。另外,Follower 副本在副本同步的过程中,还可能发生名为截断(Truncation)的操作。我们一并来看下它的实现原理。
1.1 课前案例
坦率地说,这部分源码非常贴近底层设计架构原理。你可能在想:阅读它对我实际有什么帮助吗?我举一个实际的例子来说明下。我们曾经在生产环境中发现,一旦 Broker 上的副本数过多,Broker 节点的内存占用就会非常高。查过 HeapDump 之后,我们发现根源在于 ReplicaFetcherThread 文件中的 buildFetch 方法。这个方法里有这样一句:
val builder = fetchSessionHandler.newBuilder()
这条语句底层会实例化一个 LinkedHashMap。如果分区数很多的话,这个 Map 会被扩容很多次,因此带来了很多不必要的数据拷贝。这样既增加了内存的 Footprint,也浪费了 CPU 资源。
你看,通过查询源码,我们定位到了这个问题的根本原因。后来,我们通过将负载转移到其他 Broker 的方法解决了这个问题。其实,Kafka 社区也发现了这个 Bug,所以当你现在再看这部分源码的时候,就会发现这行语句已经被修正了。它现在长这个样子,你可以体会下和之前有什么不同:
val builder = fetchSessionHandler.newBuilder(partitionMap.size, false)
你可能也看出来了,修改前后最大的不同,其实在于修改后的这条语句直接传入了 FETCH 请求中总的分区数,并直接将其传给 LinkedHashMap,免得再执行扩容操作了。
好了,我们说回 Follower 副本从 Leader 副本拉取数据这件事儿。不知道你有没有注意到,我在前面的例子提到了一个名字:ReplicaFetcherThread,也就是副本获取线程。没错,Kafka 源码就是通过这个线程实现的消息拉取及处理。今天这节课,我们先从抽象基类 AbstractFetcherThread 学起,看看它的类定义和三个重要方法。下节课,我们再继续学习 AbstractFetcherThread 类的一个重要方法,以及子类 ReplicaFetcherThread 的源码。这样,我们就能彻底搞明白 Follower 端同步 Leader 端消息的原理。
1.2 抽象基类:AbstractFetcherThread
等等,我们不是要学 ReplicaFetcherThread 吗?为什么要先从它的父类 AbstractFetcherThread 开始学习呢?其实,这里的原因也很简单,那就是因为 AbstractFetcherThread 类是 ReplicaFetcherThread 的抽象基类。它里面定义和实现了很多重要的字段和方法,是我们学习 ReplicaFetcherThread 源码的基础。同时,AbstractFetcherThread 类的源码给出了很多子类需要实现的方法。因此,我们需要事先了解这个抽象基类,否则便无法顺畅过渡到其子类源码的学习。
好了,我们来正式认识下 AbstractFetcherThread 吧。它的源码位于 server 包下的 AbstractFetcherThread.scala 文件中。从名字来看,它是一个抽象类,实现的功能是从 Broker 获取多个分区的消息数据,至于获取之后如何对这些数据进行处理,则交由子类来实现。
1.2.1 类定义及字段
我们看下 AbstractFetcherThread 类的定义和一些重要的字段:
abstract class AbstractFetcherThread(name: String, // 线程名称
clientId: String, // Client Id,用于日志输出
val sourceBroker: BrokerEndPoint, // 数据源Broker地址,也就是Leader副本所在的Broker是哪台
failedPartitions: FailedPartitions,// 处理过程中出现失败的分区
fetchBackOffMs: Int = 0, // 获取操作重试间隔
isInterruptible: Boolean = true, // 线程是否允许被中断
val brokerTopicStats: BrokerTopicStats)// Broker端主题监控指标
extends ShutdownableThread(name, isInterruptible) {
// 定义FetchData类型表示获取的消息数据
type FetchData = FetchResponse.PartitionData[Records]
// 定义EpochData类型表示Leader Epoch数据
type EpochData = OffsetForLeaderEpochRequestData.OffsetForLeaderPartition
private val partitionStates = new PartitionStates[PartitionFetchState]
......
}
我们来看一下 AbstractFetcherThread 的构造函数接收的几个重要参数的含义。
- name:线程名字。
- sourceBroker:源 Broker 节点信息。源 Broker 是指此线程要从哪个 Broker 上读取数据。
- failedPartitions:线程处理过程报错的分区集合。
- fetchBackOffMs:当获取分区数据出错后的等待重试间隔,默认是 Broker 端参数 replica.fetch.backoff.ms 值。
- brokerTopicStats:Broker 端主题的各类监控指标,常见的有 MessagesInPerSec、BytesInPerSec 等。
这些字段中比较重要的是 sourceBroker,因为它决定 Follower 副本从哪个 Broker 拉取数据,也就是 Leader 副本所在的 Broker 是哪台。
除了构造函数的这几个字段外,AbstractFetcherThread 类还定义了两个 type 类型。用关键字 type 定义一个类型,属于 Scala 比较高阶的语法特性。从某种程度上,你可以把它当成一个快捷方式,比如 FetchData 这句:
type FetchData = FetchResponse.PartitionData[Records]
这行语句类似于一个快捷方式:以后凡是源码中需要用到 FetchResponse.PartitionData[Records]的地方,都可以简单地使用 FetchData 替换掉,非常简洁方便。自定义类型 EpochData,也是同样的用法。
FetchData 定义里的 PartitionData 类型,是客户端 clients 工程中 FetchResponse 类定义的嵌套类。FetchResponse 类封装的是 FETCH 请求的 Response 对象,而里面的 PartitionData 类是一个 POJO 类,保存的是 Response 中单个分区数据拉取的各项数据,包括从该分区的 Leader 副本拉取回来的消息、该分区的高水位值和日志起始位移值等。
public PartitionData(Errors error, // 错误码
long highWatermark, // 高水位值
long lastStableOffset, // 最新LSO值
long logStartOffset, // 最新Log Start Offset值
// 期望的Read Replica
// KAFKA 2.4之后支持部分Follower副本可以对外提供读服务
Optional<Integer> preferredReadReplica,
// 该分区对应的已终止事务列表
List<AbortedTransaction> abortedTransactions,
Optional<FetchResponseData.EpochEndOffset> divergingEpoch,
// 消息集合,最重要的字段!
T records) {
}
PartitionData 这个类定义的字段中,除了我们已经非常熟悉的 highWatermark 和 logStartOffset 等字段外,还有一些属于比较高阶的用法:
- preferredReadReplica,用于指定可对外提供读服务的 Follower 副本;
- abortedTransactions,用于保存该分区当前已终止事务列表;
- lastStableOffset 是最新的 LSO 值,属于 Kafka 事务的概念。
关于这几个字段,你只要了解它们的基本作用就可以了。实际上,在 PartitionData 这个类中,最需要你重点关注的是 records 字段。因为它保存实际的消息集合,而这是我们最关心的数据。
说到这里,如果你去查看 EpochData 的定义,能发现它也是 PartitionData 类型。但,你一定要注意的是,EpochData 的 PartitionData 是 OffsetsForLeaderEpochRequest 的 PartitionData 类型。
事实上,在 Kafka 源码中,有很多名为 PartitionData 的嵌套类。很多请求类型中的数据都是按分区层级进行分组的,因此源码很自然地在这些请求类中创建了同名的嵌套类。我们在查看源码时,一定要注意区分 PartitionData 嵌套类是定义在哪类请求中的,不同类型请求中的 PartitionData 类字段是完全不同的。
1.2.2 分区读取状态
类好了,我们把视线拉回到 AbstractFetcherThread 类。在这个类的构造函数中,我们看到它还封装了一个名为 PartitionStates[PartitionFetchState]类型的字段。
是不是看上去有些复杂?不过没关系,我们分开来看,先看它泛型的参数类型 PartitionFetchState 类。直观上理解,它是表征分区读取状态的,保存的是分区的已读取位移值和对应的副本状态。
注意这里的状态有两个,一个是分区读取状态,一个是副本读取状态。副本读取状态由 ReplicaState 接口表示,如下所示:
sealed trait ReplicaState
// 截断中
case object Truncating extends ReplicaState
// 获取中
case object Fetching extends ReplicaState
可见,副本读取状态有截断中和获取中两个:当副本执行截断操作时,副本状态被设置成 Truncating;当副本被读取时,副本状态被设置成 Fetching。
而分区读取状态有 3 个,分别是:
- 可获取,表明副本获取线程当前能够读取数据。
- 截断中,表明分区副本正在执行截断操作(比如该副本刚刚成为 Follower 副本)。
- 被推迟,表明副本获取线程获取数据时出现错误,需要等待一段时间后重试。
值得注意的是,分区读取状态中的可获取、截断中与副本读取状态的获取中、截断中两个状态并非严格对应的。换句话说,副本读取状态处于获取中,并不一定表示分区读取状态就是可获取状态。对于分区而言,它是否能够被获取的条件要比副本严格一些。
接下来,我们就来看看这 3 类分区获取状态的源码定义:
case class PartitionFetchState(fetchOffset: Long,
lag: Option[Long],
currentLeaderEpoch: Int,
delay: Option[DelayedItem],
state: ReplicaState,
lastFetchedEpoch: Option[Int]) {
// 分区可获取的条件是副本处于Fetching且未被推迟执行
def isReadyForFetch: Boolean = state == Fetching && !isDelayed
// 副本处于ISR的条件:没有lag
def isReplicaInSync: Boolean = lag.isDefined && lag.get <= 0
// 分区处于截断中状态的条件:副本处于Truncating状态且未被推迟执行
def isTruncating: Boolean = state == Truncating && !isDelayed
// 分区处于截断中状态的条件:副本处于Truncating状态且未被推迟执行
def isDelayed: Boolean = delay.exists(_.getDelay(TimeUnit.MILLISECONDS) > 0)
......
}
这段源码中有 4 个方法,你只要重点了解 isReadyForFetch 和 isTruncating 这两个方法即可。因为副本获取线程做的事情就是这两件:日志截断和消息获取。
至于 isReplicaInSync,它被用于副本限流,出镜率不高。而 isDelayed,是用于判断是否需要推迟获取对应分区的消息。源码会不断地调整那些不需要推迟的分区的读取顺序,以保证读取的公平性。
这个公平性,其实就是在 partitionStates 字段的类型 PartitionStates 类中实现的。这个类是在 clients 工程中定义的。它本质上会接收一组要读取的主题分区,然后以轮询的方式依次读取这些分区以确保公平性。
鉴于咱们这门儿课聚焦于 Broker 端源码,因此,这里我只是简单和你说下这个类的实现原理。如果你想要深入理解这部分内容,可以翻开 clients 端工程的源码,自行去探索下这部分的源码。
public class PartitionStates<S> {
private final LinkedHashMap<TopicPartition, S> map = new LinkedHashMap<>();
......
public void updateAndMoveToEnd(TopicPartition topicPartition, S state) {
map.remove(topicPartition);
map.put(topicPartition, state);
updateSize();
}
......
}
前面说过了,PartitionStates 类用轮询的方式来处理要读取的多个分区。那具体是怎么实现的呢?简单来说,就是依靠 LinkedHashMap 数据结构来保存所有主题分区。LinkedHashMap 中的元素有明确的迭代顺序,通常就是元素被插入的顺序。
假设 Kafka 要读取 5 个分区上的消息:A、B、C、D 和 E。如果插入顺序就是 ABCDE,那么自然首先读取分区 A。一旦 A 被读取之后,为了确保各个分区都有同等机会被读取到,代码需要将 A 插入到分区列表的最后一位,这就是 updateAndMoveToEnd 方法要做的事情。
具体来说,就是把 A 从 map 中移除掉,然后再插回去,这样 A 自然就处于列表的最后一位了。大体上,PartitionStates 类就是做这个用的。
1.2.3 重要方法
说完了 AbstractFetcherThread 类的定义,我们再看下它提供的一些重要方法。
这个类总共封装了近 40 个方法,那接下来我就按照这些方法对于你使用 Kafka、解决 Kafka 问题的重要程度,精选出 4 个方法做重点讲解,分别是 processPartitionData、truncate、buildFetch 和 doWork。这 4 个方法涵盖了拉取线程所做的最重要的 3 件事儿:处理拉取后的结果、执行截断操作、构建 FETCH 请求。而 doWork 方法,其实是串联起了前面的这 3 个方法。好了,我们一个一个来看看吧。
首先是它最重要的方法 processPartitionData,用于处理读取回来的消息集合。它是一个抽象方法,因此需要子类实现它的逻辑。具体到 Follower 副本而言, 是由 ReplicaFetcherThread 类实现的。以下是它的方法签名:
protected def processPartitionData(
topicPartition: TopicPartition, // 读取哪个分区的数据
fetchOffset: Long, // 读取到的最新位移值
partitionData: FetchData // 读取到的分区消息数据
): Option[LogAppendInfo] // 写入已读取消息数据前的元数据
我们需要重点关注的字段是,该方法的返回值 Option[LogAppendInfo]:
- 对于 Follower 副本读消息写入日志而言,你可以忽略这里的 Option,因为它肯定会返回具体的 LogAppendInfo 实例,而不会是 None。
- 至于 LogAppendInfo 类,我们在“日志模块”中已经介绍过了。它封装了很多消息数据被写入到日志前的重要元数据信息,比如首条消息的位移值、最后一条消息位移值、最大时间戳等。
除了 processPartitionData 方法,另一个重要的方法是 truncate 方法,其签名代码如下:
protected def truncate(
topicPartition: TopicPartition, // 要对哪个分区下副本执行截断操作
truncationState: OffsetTruncationState // Offset + 截断状态
): Unit
这里的 OffsetTruncationState 类封装了一个位移值和一个截断完成与否的布尔值状态。它的主要作用是,告诉 Kafka 要把指定分区下副本截断到哪个位移值。
第 3 个重要的方法是 buildFetch 方法。代码如下:
protected def buildFetch(
// 一组要读取的分区列表 // 分区是否可读取取决于PartitionFetchState中的状态
partitionMap: Map[TopicPartition, PartitionFetchState]):
// 封装FetchRequest.Builder对象
ResultWithPartitions[Option[ReplicaFetch]]
第 4 个重要的方法是 doWork。虽然它的代码行数不多,但却是串联前面 3 个方法的主要入口方法,也是 AbstractFetcherThread 类的核心方法。因此,我们要多花点时间,弄明白这些方法是怎么组合在一起共同工作的。我会在下节课和你详细拆解这里面的代码原理。
1.3 总结
今天,我们主要学习了 Kafka 的副本同步机制和副本管理器组件。目前,Kafka 副本之间的消息同步是依靠 ReplicaFetcherThread 线程完成的。我们重点阅读了它的抽象基类 AbstractFetcherThread 线程类的代码。作为拉取线程的公共基类,AbstractFetcherThread 类定义了很多重要方法。我们来回顾一下这节课的重点。
- AbstractFetcherThread 类:拉取线程的抽象基类。它定义了公共方法来处理所有拉取线程都要实现的逻辑,如执行截断操作,获取消息等。
- 拉取线程逻辑:循环执行截断操作和获取数据操作。
- 分区读取状态:当前,源码定义了 3 类分区读取状态。拉取线程只能拉取处于可读取状态的分区的数据。

2 ReplicaFetcherThread:Follower如何拉取Leader消息?
上节课,我们已经学习了 AbstractFetcherThread 的定义,以及 processPartitionData、truncate、buildFetch 这三个方法的作用。现在,你应该掌握了拉取线程源码的处理逻辑以及支撑这些逻辑实现的代码结构。不过,在上节课的末尾,我卖了个关子——我把串联起这三个方法的 doWork 方法留到了今天这节课。等你今天学完 doWork 方法,以及这三个方法在子类 ReplicaFetcherThread 中的实现代码之后,你就能完整地理解 Follower 副本应用拉取线程(也就是 ReplicaFetcherThread 线程),从 Leader 副本获取消息并处理的流程了。
不过,在上节课的末尾,我卖了个关子——我把串联起这三个方法的 doWork 方法留到了今天这节课。等你今天学完 doWork 方法,以及这三个方法在子类 ReplicaFetcherThread 中的实现代码之后,你就能完整地理解 Follower 副本应用拉取线程(也就是 ReplicaFetcherThread 线程),从 Leader 副本获取消息并处理的流程了。
那么,现在我们就开启 doWork 以及子类 ReplicaFetcherThread 代码的阅读。
2.1 AbstractFetcherThread 类:doWork 方法
doWork 方法是 AbstractFetcherThread 类的核心方法,是线程的主逻辑运行方法,代码如下:
override def doWork(): Unit = {
maybeTruncate() // 执行副本截断操作
maybeFetch() // 执行消息获取操作
}
怎么样,简单吧?AbstractFetcherThread 线程只要一直处于运行状态,就是会不断地重复这两个操作。获取消息这个逻辑容易理解,但是为什么 AbstractFetcherThread 线程总要不断尝试去做截断呢?
这是因为,分区的 Leader 可能会随时发生变化。每当有新 Leader 产生时,Follower 副本就必须主动执行截断操作,将自己的本地日志裁剪成与 Leader 一模一样的消息序列,甚至,Leader 副本本身也需要执行截断操作,将 LEO 调整到分区高水位处。那么,具体到代码,这两个操作又是如何实现的呢?首先,我们看看 maybeTruncate 方法。它的代码不长,还不到 10 行:
private def maybeTruncate(): Unit = {
// 将所有处于截断中状态的分区依据有无Leader Epoch值进行分组
val (partitionsWithEpochs, partitionsWithoutEpochs) = fetchTruncatingPartitions()
// 对于有Leader Epoch值的分区,将日志截断到Leader Epoch值对应的位移值处
if (partitionsWithEpochs.nonEmpty) {
truncateToEpochEndOffsets(partitionsWithEpochs)
}
// 对于没有Leader Epoch值的分区,将日志截断到高水位值处
if (partitionsWithoutEpochs.nonEmpty) {
truncateToHighWatermark(partitionsWithoutEpochs)
}
}
maybeTruncate 方法的逻辑特别简单。首先,是对分区状态进行分组。既然是做截断操作的,那么该方法操作的就只能是处于截断中状态的分区。代码会判断这些分区是否存在对应的 Leader Epoch 值,并按照有无 Epoch 值进行分组。这就是 fetchTruncatingPartitions 方法做的事情。
日志模块提到过 Leader Epoch 机制,它是用来替换高水位值在日志截断中的作用。这里便是 Leader Epoch 机制典型的应用场景:
- 当分区存在 Leader Epoch 值时,源码会将副本的本地日志截断到 Leader Epoch 对应的最新位移值处,即方法 truncateToEpochEndOffsets 的逻辑实现;
- 相反地,如果分区不存在对应的 Leader Epoch 记录,那么依然使用原来的高水位机制,调用方法 truncateToHighWatermark 将日志调整到高水位值处。
由于 Leader Epoch 机制属于比较高阶的知识内容,这里我们的重点是理解高水位值在截断操作中的应用,我就不再和你详细讲解 Leader Epoch 机制了。如果你希望深入理解这个机制,你可以研读一下 LeaderEpochFileCache 类的源码。因此,我们重点看下 truncateToHighWatermark 方法的实现代码。
private[server] def truncateToHighWatermark(partitions: Set[TopicPartition]): Unit = inLock(partitionMapLock) {
val fetchOffsets = mutable.HashMap.empty[TopicPartition, OffsetTruncationState]
// 遍历每个要执行截断操作的分区对象
for (tp <- partitions) {
// 获取分区的分区读取状态
val partitionState = partitionStates.stateValue(tp)
if (partitionState != null) {
// 取出高水位值。分区的最大可读取位移值就是高水位值
val highWatermark = partitionState.fetchOffset
val truncationState = OffsetTruncationState(highWatermark, truncationCompleted = true)
info(s"Truncating partition $tp to local high watermark $highWatermark")
// 执行截断到高水位值
if (doTruncate(tp, truncationState))
fetchOffsets.put(tp, truncationState)
}
}
// 更新这组分区的分区读取状态
updateFetchOffsetAndMaybeMarkTruncationComplete(fetchOffsets)
}
我来和你解释下 truncateToHighWatermark 方法的逻辑:首先,遍历给定的所有分区;然后,依次为每个分区获取当前的高水位值,并将其保存在前面提到的分区读取状态类中;之后调用 doTruncate 方法执行真正的日志截断操作。等到将给定的所有分区都执行了对应的操作之后,代码会更新这组分区的分区读取状态。
doTruncate 方法底层调用了抽象方法 truncate,而 truncate 方法是在 ReplicaFetcherThread 中实现的。我们一会儿再详细说它。至于 updateFetchOffsetAndMaybeMarkTruncationComplete 方法,是一个只有十几行代码的私有方法。我就把它当作课后思考题留给你,由你来思考一下它是做什么用的吧。
updateFetchOffsetAndMaybeMarkTruncationComplete方法作用:这个方法主要目的是将给定的一组分区去刷新Fetcher线程读取它们的位移值以及设置截断完成与否的状态。当FetcherThread在执行日志截断操作时需要调用该方法。比如如果截断到高水位值,那么updateFetchOffsetAndMaybeMarkTruncationComplete会将这些分区的读取位移值设置为高水位处。
说完了 maybeTruncate 方法,我们再看看 maybeFetch 方法,代码如下:
private def maybeFetch(): Unit = {
val fetchRequestOpt = inLock(partitionMapLock) {
// 为partitionStates中的分区构造FetchRequest
// partitionStates中保存的是要去获取消息的分区以及对应的状态
val ResultWithPartitions(fetchRequestOpt, partitionsWithError) = buildFetch(partitionStates.partitionStateMap.asScala)
// 处理出错的分区,处理方式主要是将这个分区加入到有序Map末尾
// 等待后续重试
handlePartitionsWithErrors(partitionsWithError, "maybeFetch")
// 如果当前没有可读取的分区,则等待fetchBackOffMs时间等候后续重试
if (fetchRequestOpt.isEmpty) {
trace(s"There are no active partitions. Back off for $fetchBackOffMs ms before sending a fetch request")
partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS)
}
fetchRequestOpt
}
// 发送FETCH请求给Leader副本,并处理Response
fetchRequestOpt.foreach { case ReplicaFetch(sessionPartitions, fetchRequest) =>
processFetchRequest(sessionPartitions, fetchRequest)
}
}
同样地,maybeFetch 做的事情也基本可以分为 3 步。
第 1 步,为 partitionStates 中的分区构造 FetchRequest 对象,严格来说是 FetchRequest.Builder 对象。构造了 Builder 对象之后,通过调用其 build 方法,就能创建出所需的 FetchRequest 请求对象。这里的 partitionStates 中保存的是,要去获取消息的一组分区以及对应的状态信息。这一步的输出结果是两个对象:
- 一个对象是 ReplicaFetch,即要读取的分区核心信息 + FetchRequest.Builder 对象。而这里的核心信息,就是指要读取哪个分区,从哪个位置开始读,最多读多少字节,等等。
- 另一个对象是一组出错分区。
第 2 步,处理这组出错分区。处理方式是将这组分区加入到有序 Map 末尾等待后续重试。如果发现当前没有任何可读取的分区,代码会阻塞等待一段时间。第 3 步,发送 FETCH 请求给对应的 Leader 副本,并处理相应的 Response,也就是 processFetchRequest 方法要做的事情。
第 3 步,发送 FETCH 请求给对应的 Leader 副本,并处理相应的 Response,也就是 processFetchRequest 方法要做的事情。
processFetchRequest 是 AbstractFetcherThread 所有方法中代码量最多的方法,逻辑也有些复杂。为了更好地理解它,我提取了其中的精华代码展示给你,并在每个关键步骤上都加了注释:
private def processFetchRequest(sessionPartitions: util.Map[TopicPartition, FetchRequest.PartitionData],
fetchRequest: FetchRequest.Builder): Unit = {
val partitionsWithError = mutable.Set[TopicPartition]()
val divergingEndOffsets = mutable.Map.empty[TopicPartition, EpochEndOffset]
var responseData: Map[TopicPartition, FetchData] = Map.empty
try {
trace(s"Sending fetch request $fetchRequest")
// 给Leader发送FETCH请求
responseData = fetchFromLeader(fetchRequest)
} catch {
......
}
// 更新请求发送速率指标
fetcherStats.requestRate.mark()
if (responseData.nonEmpty) {
// process fetched data
inLock(partitionMapLock) {
responseData.forKeyValue { (topicPartition, partitionData) =>
Option(partitionStates.stateValue(topicPartition)).foreach { currentFetchState =>
// It's possible that a partition is removed and re-added or truncated when there is a pending fetch request.
// In this case, we only want to process the fetch response if the partition state is ready for fetch and
// the current offset is the same as the offset requested.
// 获取分区核心信息
val fetchPartitionData = sessionPartitions.get(topicPartition)
// 处理Response的条件:
// 1. 要获取的位移值和之前已保存的下一条待获取位移值相等
// 2. 当前分区处于可获取状态
if (fetchPartitionData != null && fetchPartitionData.fetchOffset == currentFetchState.fetchOffset && currentFetchState.isReadyForFetch) {
partitionData.error match {
case Errors.NONE =>
try {
// Once we hand off the partition data to the subclass, we can't mess with it any more in this thread
// 交由子类完成Response的处理
val logAppendInfoOpt = processPartitionData(topicPartition, currentFetchState.fetchOffset,
partitionData)
logAppendInfoOpt.foreach { logAppendInfo =>
val validBytes = logAppendInfo.validBytes
val nextOffset = if (validBytes > 0) logAppendInfo.lastOffset + 1 else currentFetchState.fetchOffset
val lag = Math.max(0L, partitionData.highWatermark - nextOffset)
fetcherLagStats.getAndMaybePut(topicPartition).lag = lag
// ReplicaDirAlterThread may have removed topicPartition from the partitionStates after processing the partition data
if (validBytes > 0 && partitionStates.contains(topicPartition)) {
// Update partitionStates only if there is no exception during processPartitionData
val newFetchState = PartitionFetchState(nextOffset, Some(lag),
currentFetchState.currentLeaderEpoch, state = Fetching,
logAppendInfo.lastLeaderEpoch)
// 将该分区放置在有序Map读取顺序的末尾,保证公平性
partitionStates.updateAndMoveToEnd(topicPartition, newFetchState)
fetcherStats.byteRate.mark(validBytes)
}
}
if (isTruncationOnFetchSupported) {
partitionData.divergingEpoch.ifPresent { divergingEpoch =>
divergingEndOffsets += topicPartition -> new EpochEndOffset()
.setPartition(topicPartition.partition)
.setErrorCode(Errors.NONE.code)
.setLeaderEpoch(divergingEpoch.epoch)
.setEndOffset(divergingEpoch.endOffset)
}
}
} catch {
......
}
// 如果读取位移值越界,通常是因为Leader发生变更
case Errors.OFFSET_OUT_OF_RANGE =>
// 调整越界,主要办法是做截断
if (handleOutOfRangeError(topicPartition, currentFetchState, fetchPartitionData.currentLeaderEpoch))
// 如果依然不能成功,加入到出错分区列表
partitionsWithError += topicPartition
// 如果Leader Epoch值比Leader所在Broker上的Epoch值要新
case Errors.UNKNOWN_LEADER_EPOCH =>
debug(s"Remote broker has a smaller leader epoch for partition $topicPartition than " +
s"this replica's current leader epoch of ${currentFetchState.currentLeaderEpoch}.")
// 加入到出错分区列表
partitionsWithError += topicPartition
// 如果Leader Epoch值比Leader所在Broker上的Epoch值要旧
case Errors.FENCED_LEADER_EPOCH =>
if (onPartitionFenced(topicPartition, fetchPartitionData.currentLeaderEpoch))
partitionsWithError += topicPartition
// 如果Leader发生变更
case Errors.NOT_LEADER_OR_FOLLOWER =>
debug(s"Remote broker is not the leader for partition $topicPartition, which could indicate " +
"that the partition is being moved")
// 加入到出错分区列表
partitionsWithError += topicPartition
case Errors.UNKNOWN_TOPIC_OR_PARTITION =>
warn(s"Received ${Errors.UNKNOWN_TOPIC_OR_PARTITION} from the leader for partition $topicPartition. " +
"This error may be returned transiently when the partition is being created or deleted, but it is not " +
"expected to persist.")
partitionsWithError += topicPartition
case _ =>
error(s"Error for partition $topicPartition at offset ${currentFetchState.fetchOffset}",
partitionData.error.exception)
// 加入到出错分区列表
partitionsWithError += topicPartition
}
}
}
}
}
}
if (divergingEndOffsets.nonEmpty)
truncateOnFetchResponse(divergingEndOffsets)
if (partitionsWithError.nonEmpty) {
// 处理出错分区列表
handlePartitionsWithErrors(partitionsWithError, "processFetchRequest")
}
}

结合着代码注释和流程图,我再和你解释下 processFetchRequest 的核心逻辑吧。这样你肯定就能明白拉取线程是如何执行拉取动作的了。
我们可以把这个逻辑,分为以下 3 大部分。
第 1 步,调用 fetchFromLeader 方法给 Leader 发送 FETCH 请求,并阻塞等待 Response 的返回,然后更新 FETCH 请求发送速率的监控指标。
第 2 步,拿到 Response 之后,代码从中取出分区的核心信息,然后比较要读取的位移值,和当前 AbstractFetcherThread 线程缓存的、该分区下一条待读取的位移值是否相等,以及当前分区是否处于可获取状态。
如果不满足这两个条件,说明这个 Request 可能是一个之前等待了许久都未处理的请求,压根就不用处理了。
相反,如果满足这两个条件且 Response 没有错误,交由子类实现具体的 Response 处理,也就是调用 processPartitionData 方法。之后将该分区放置在有序 Map 的末尾以保证公平性。而如果该 Response 有错误,那么就调用对应错误的定制化处理逻辑,然后将出错分区加入到出错分区列表中。
第 3 步,调用 handlePartitionsWithErrors 方法,统一处理上一步处理过程中出现错误的分区。
2.2 子类:ReplicaFetcherThread
到此,AbstractFetcherThread 类的学习我们就完成了。接下来,我们再看下 Follower 副本侧使用的 ReplicaFetcherThread 子类。
前面说过了,ReplicaFetcherThread 继承了 AbstractFetcherThread 类。ReplicaFetcherThread 是 Follower 副本端创建的线程,用于向 Leader 副本拉取消息数据。我们依然从类定义和重要方法两个维度来学习这个子类的源码。ReplicaFetcherThread 类的源码位于 server 包下的同名 scala 文件中。这是一个 300 多行的小文件,因为大部分的处理逻辑都在父类 AbstractFetcherThread 中定义过了。
2.2.1 类定义及字段
我们先学习下 ReplicaFetcherThread 类的定义和字段:
class ReplicaFetcherThread(name: String,
fetcherId: Int,
sourceBroker: BrokerEndPoint,
brokerConfig: KafkaConfig,
failedPartitions: FailedPartitions,
replicaMgr: ReplicaManager,
metrics: Metrics,
time: Time,
quota: ReplicaQuota,
leaderEndpointBlockingSend: Option[BlockingSend] = None)
extends AbstractFetcherThread(name = name,
clientId = name,
sourceBroker = sourceBroker,
failedPartitions,
fetchBackOffMs = brokerConfig.replicaFetchBackoffMs,
isInterruptible = false,
replicaMgr.brokerTopicStats) {
// 副本Id就是副本所在Broker的Id
......
// 用于执行请求发送的类
private val leaderEndpoint = leaderEndpointBlockingSend.getOrElse(
new ReplicaFetcherBlockingSend(sourceBroker, brokerConfig, metrics, time, fetcherId,
s"broker-$replicaId-fetcher-$fetcherId", logContext))
// Follower发送的FETCH请求被处理返回前的最长等待时间
private val maxWait = brokerConfig.replicaFetchWaitMaxMs
// 每个FETCH Response返回前必须要累积的最少字节数
private val minBytes = brokerConfig.replicaFetchMinBytes
// 每个合法FETCH Response的最大字节数
private val maxBytes = brokerConfig.replicaFetchResponseMaxBytes
// 单个分区能够获取到的最大字节数
private val fetchSize = brokerConfig.replicaFetchMaxBytes
override protected val isOffsetForLeaderEpochSupported: Boolean = brokerConfig.interBrokerProtocolVersion >= KAFKA_0_11_0_IV2
override protected val isTruncationOnFetchSupported = ApiVersion.isTruncationOnFetchSupported(brokerConfig.interBrokerProtocolVersion)
// 维持某个Broker连接上获取会话状态的类
val fetchSessionHandler = new FetchSessionHandler(logContext, sourceBroker.id)
......
}
ReplicaFetcherThread 类的定义代码虽然有些长,但你会发现没那么难懂,因为构造函数中的大部分字段我们上节课都学习过了。现在,我们只要学习 ReplicaFetcherThread 类特有的几个字段就可以了。
ReplicaFetcherThread 类的定义代码虽然有些长,但你会发现没那么难懂,因为构造函数中的大部分字段我们上节课都学习过了。现在,我们只要学习 ReplicaFetcherThread 类特有的几个字段就可以了。
- fetcherId:Follower 拉取的线程 Id,也就是线程的编号。单台 Broker 上,允许存在多个 ReplicaFetcherThread 线程。Broker 端参数 num.replica.fetchers,决定了 Kafka 到底创建多少个 Follower 拉取线程。
- brokerConfig:KafkaConfig 类实例。虽然我们没有正式学习过它的源码,但之前学过的很多组件代码中都有它的身影。它封装了 Broker 端所有的参数信息。同样地,ReplicaFetcherThread 类也是通过它来获取 Broker 端指定参数的值。
- replicaMgr:副本管理器。该线程类通过副本管理器来获取分区对象、副本对象以及它们下面的日志对象。
- quota:用做限流。限流属于高阶用法,如果你想深入理解这部分内容的话,可以自行阅读 ReplicationQuotaManager 类的源码。现在,只要你下次在源码中碰到 quota 字样的,知道它是用作 Follower 副本拉取速度控制就行了。
- leaderEndpointBlockingSend:这是用于实现同步发送请求的类。所谓的同步发送,是指该线程使用它给指定 Broker 发送请求,然后线程处于阻塞状态,直到接收到 Broker 返回的 Response。
除了构造函数中定义的字段之外,ReplicaFetcherThread 类还定义了与消息获取息息相关的 4 个字段。
- maxWait:Follower 发送的 FETCH 请求被处理返回前的最长等待时间。它是 Broker 端参数 replica.fetch.wait.max.ms 的值。
- minBytes:每个 FETCH Response 返回前必须要累积的最少字节数。它是 Broker 端参数 replica.fetch.min.bytes 的值。
- maxBytes:每个合法 FETCH Response 的最大字节数。它是 Broker 端参数 replica.fetch.response.max.bytes 的值。
- fetchSize:单个分区能够获取到的最大字节数。它是 Broker 端参数 replica.fetch.max.bytes 的值。
这 4 个参数都是 FETCH 请求的参数,主要控制了 Follower 副本拉取 Leader 副本消息的行为,比如一次请求到底能够获取多少字节的数据,或者当未达到累积阈值时,FETCH 请求等待多长时间等。
重要方法
接下来,我们继续学习 ReplicaFetcherThread 的 3 个重要方法:processPartitionData、buildFetch 和 truncate。为什么是这 3 个方法呢?因为它们代表了 Follower 副本拉取线程要做的最重要的三件事:处理拉取的消息、构建拉取消息的请求,以及执行截断日志操作。
2.2.2 processPartitionData 方法
我们先来看 processPartitionData 方法。AbstractFetcherThread 线程从 Leader 副本拉取回消息后,需要调用 processPartitionData 方法进行后续动作。该方法的代码很长,我给其中的关键步骤添加了注释:
override def processPartitionData(topicPartition: TopicPartition,
fetchOffset: Long,
partitionData: FetchData): Option[LogAppendInfo] = {
val logTrace = isTraceEnabled
// 从副本管理器获取指定主题分区对象
val partition = replicaMgr.getPartitionOrException(topicPartition)
// 获取日志对象
val log = partition.localLogOrException
// 将获取到的数据转换成符合格式要求的消息集合
val records = toMemoryRecords(partitionData.records)
maybeWarnIfOversizedRecords(records, topicPartition)
// 要读取的起始位移值如果不是本地日志LEO值则视为异常情况
if (fetchOffset != log.logEndOffset)
throw new IllegalStateException("Offset mismatch for partition %s: fetched offset = %d, log end offset = %d.".format(
topicPartition, fetchOffset, log.logEndOffset))
if (logTrace)
trace("Follower has replica log end offset %d for partition %s. Received %d messages and leader hw %d"
.format(log.logEndOffset, topicPartition, records.sizeInBytes, partitionData.highWatermark))
// Append the leader's messages to the log
// 写入Follower副本本地日志
val logAppendInfo = partition.appendRecordsToFollowerOrFutureReplica(records, isFuture = false)
if (logTrace)
trace("Follower has replica log end offset %d after appending %d bytes of messages for partition %s"
.format(log.logEndOffset, records.sizeInBytes, topicPartition))
val leaderLogStartOffset = partitionData.logStartOffset
// For the follower replica, we do not need to keep its segment base offset and physical position.
// These values will be computed upon becoming leader or handling a preferred read replica fetch.
// 更新Follower副本的高水位值
val followerHighWatermark = log.updateHighWatermark(partitionData.highWatermark)
// 尝试更新Follower副本的Log Start Offset值
log.maybeIncrementLogStartOffset(leaderLogStartOffset, LeaderOffsetIncremented)
if (logTrace)
trace(s"Follower set replica high watermark for partition $topicPartition to $followerHighWatermark")
// Traffic from both in-sync and out of sync replicas are accounted for in replication quota to ensure total replication
// traffic doesn't exceed quota.
// 副本消息拉取限流
if (quota.isThrottled(topicPartition))
quota.record(records.sizeInBytes)
// 更新统计指标值
if (partition.isReassigning && partition.isAddingLocalReplica)
brokerTopicStats.updateReassignmentBytesIn(records.sizeInBytes)
brokerTopicStats.updateReplicationBytesIn(records.sizeInBytes)
// 返回日志写入结果
logAppendInfo
}
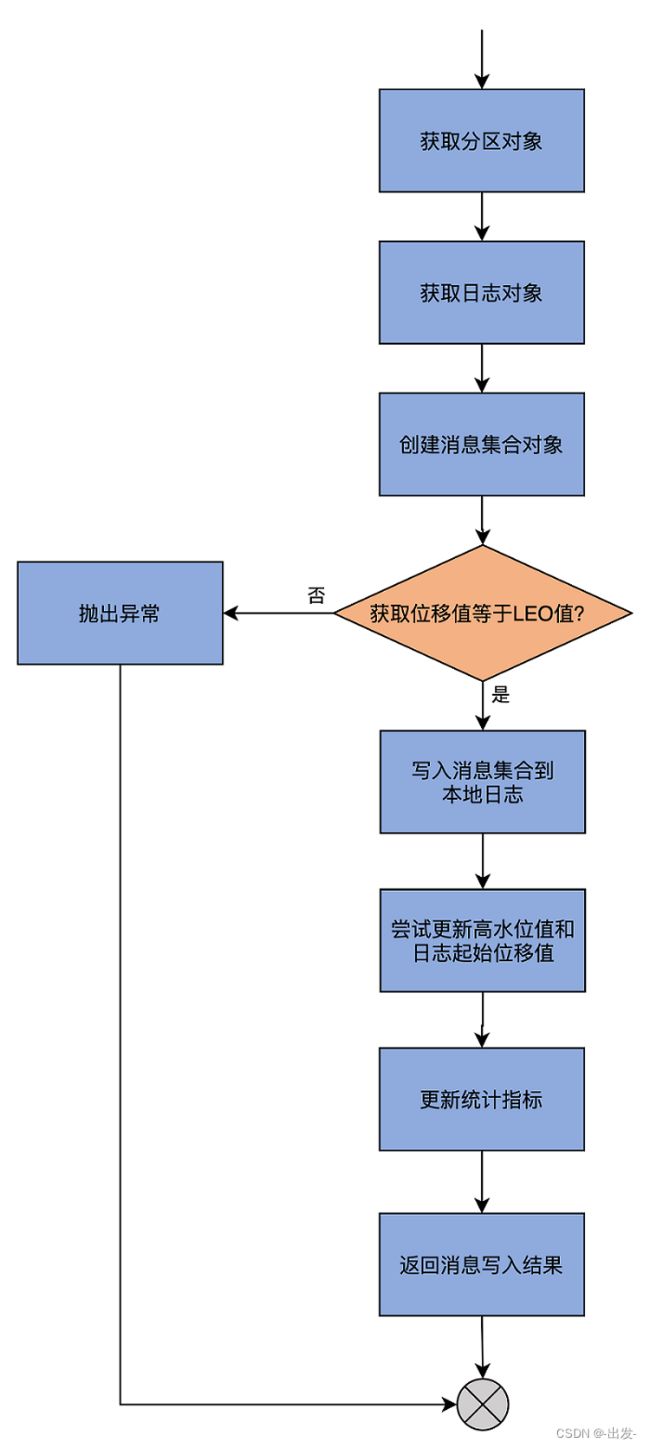
processPartitionData 方法中的 process,实际上就是写入 Follower 副本本地日志的意思。因此,这个方法的主体逻辑,就是调用分区对象 Partition 的 appendRecordsToFollowerOrFutureReplica 写入获取到的消息。如果你沿着这个写入方法一路追下去,就会发现它调用的是我们在日志模块中讲到过的 appendAsFollower 方法。你看一切都能串联起来,源码也没什么大不了的,对吧?
当然,仅仅写入日志还不够。我们还要做一些更新操作。比如,需要更新 Follower 副本的高水位值,即将 FETCH 请求 Response 中包含的高水位值作为新的高水位值,同时代码还要尝试更新 Follower 副本的 Log Start Offset 值。
那为什么 Log Start Offset 值也可能发生变化呢?这是因为 Leader 的 Log Start Offset 可能发生变化,比如用户手动执行了删除消息的操作等。Follower 副本的日志需要和 Leader 保持严格的一致,因此,如果 Leader 的该值发生变化,Follower 自然也要发生变化,以保持一致。
除此之外,processPartitionData 方法还会更新其他一些统计指标值,最后将写入结果返回。
2.2.3 buildFetch 方法
接下来, 我们看下 buildFetch 方法。此方法的主要目的是,构建发送给 Leader 副本所在 Broker 的 FETCH 请求。它的代码如下:
override def buildFetch(partitionMap: Map[TopicPartition, PartitionFetchState]): ResultWithPartitions[Option[ReplicaFetch]] = {
val partitionsWithError = mutable.Set[TopicPartition]()
val builder = fetchSessionHandler.newBuilder(partitionMap.size, false)
// 遍历每个分区,将处于可获取状态的分区添加到builder后续统一处理
// 对于有错误的分区加入到出错分区列表
partitionMap.forKeyValue { (topicPartition, fetchState) =>
// We will not include a replica in the fetch request if it should be throttled.
if (fetchState.isReadyForFetch && !shouldFollowerThrottle(quota, fetchState, topicPartition)) {
try {
val logStartOffset = this.logStartOffset(topicPartition)
val lastFetchedEpoch = if (isTruncationOnFetchSupported)
fetchState.lastFetchedEpoch.map(_.asInstanceOf[Integer]).asJava
else
Optional.empty[Integer]
builder.add(topicPartition, new FetchRequest.PartitionData(
fetchState.fetchOffset,
logStartOffset,
fetchSize,
Optional.of(fetchState.currentLeaderEpoch),
lastFetchedEpoch))
} catch {
case _: KafkaStorageException =>
// The replica has already been marked offline due to log directory failure and the original failure should have already been logged.
// This partition should be removed from ReplicaFetcherThread soon by ReplicaManager.handleLogDirFailure()
partitionsWithError += topicPartition
}
}
}
val fetchData = builder.build()
val fetchRequestOpt = if (fetchData.sessionPartitions.isEmpty && fetchData.toForget.isEmpty) {
None
} else {
// 构造FETCH请求的Builder对象
val requestBuilder = FetchRequest.Builder
.forReplica(fetchRequestVersion, replicaId, maxWait, minBytes, fetchData.toSend)
.setMaxBytes(maxBytes)
.toForget(fetchData.toForget)
.metadata(fetchData.metadata)
Some(ReplicaFetch(fetchData.sessionPartitions(), requestBuilder))
}
// 返回Builder对象以及出错分区列表
ResultWithPartitions(fetchRequestOpt, partitionsWithError)
}
同样,我使用一张图来展示其完整流程。
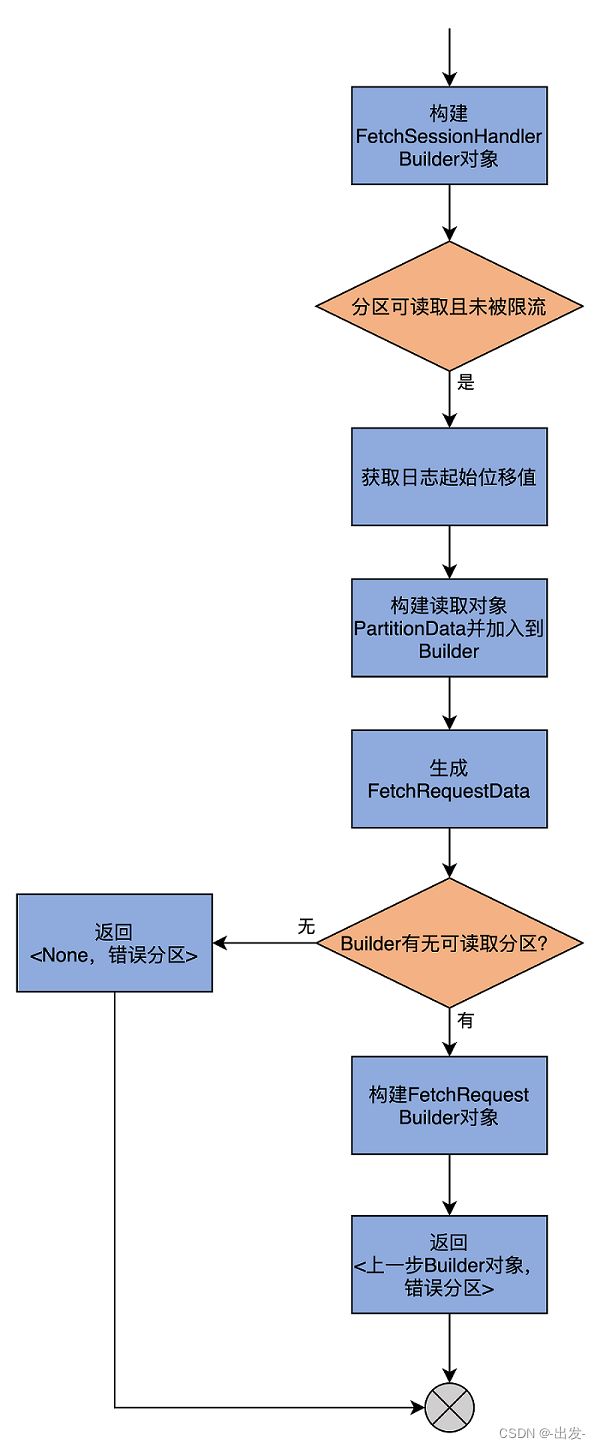
这个方法的逻辑比 processPartitionData 简单。前面说到过,它就是构造 FETCH 请求的 Builder 对象然后返回。有了 Builder 对象,我们就可以分分钟构造出 FETCH 请求了,仅需要调用 builder.build() 即可。
当然,这个方法的一个副产品是汇总出错分区,这样的话,调用方后续可以统一处理这些出错分区。值得一提的是,在构造 Builder 的过程中,源码会用到 ReplicaFetcherThread 类定义的那些与消息获取相关的字段,如 maxWait、minBytes 和 maxBytes。
2.2.4 truncate 方法
最后,我们看下 truncate 方法的实现。这个方法的主要目的是对给定分区执行日志截断操作。代码如下:
override def truncate(tp: TopicPartition, offsetTruncationState: OffsetTruncationState): Unit = {
// 拿到分区对象
val partition = replicaMgr.getPartitionOrException(tp)
// 拿到分区本地日志
val log = partition.localLogOrException
// 执行截断操作,截断到的位置由offsetTruncationState的offset指定
partition.truncateTo(offsetTruncationState.offset, isFuture = false)
if (offsetTruncationState.offset < log.highWatermark)
warn(s"Truncating $tp to offset ${offsetTruncationState.offset} below high watermark " +
s"${log.highWatermark}")
// mark the future replica for truncation only when we do last truncation
if (offsetTruncationState.truncationCompleted)
replicaMgr.replicaAlterLogDirsManager.markPartitionsForTruncation(brokerConfig.brokerId, tp,
offsetTruncationState.offset)
}
总体来说,truncate 方法利用给定的 offsetTruncationState 的 offset 值,对给定分区的本地日志进行截断操作。该操作由 Partition 对象的 truncateTo 方法完成,但实际上底层调用的是 Log 的 truncateTo 方法。truncateTo 方法的主要作用,是将日志截断到小于给定值的最大位移值处。
2.3 总结
好了,我们总结一下。就像我在开头时所说,AbstractFetcherThread 线程的 doWork 方法把上一讲提到的 3 个重要方法全部连接在一起,共同完整了拉取线程要执行的逻辑,即日志截断(truncate)+ 日志获取(buildFetch)+ 日志处理(processPartitionData),而其子类 ReplicaFetcherThread 类是真正实现该 3 个方法的地方。如果用一句话归纳起来,那就是:Follower 副本利用 ReplicaFetcherThread 线程实时地从 Leader 副本拉取消息并写入到本地日志,从而实现了与 Leader 副本之间的同步。以下是一些要点:
- doWork 方法:拉取线程工作入口方法,联结所有重要的子功能方法,如执行截断操作,获取 Leader 副本消息以及写入本地日志。
- truncate 方法:根据 Leader 副本返回的位移值和 Epoch 值执行本地日志的截断操作。
- buildFetch 方法:为一组特定分区构建 FetchRequest 对象所需的数据结构。
- processPartitionData 方法:处理从 Leader 副本获取到的消息,主要是写入到本地日志中。
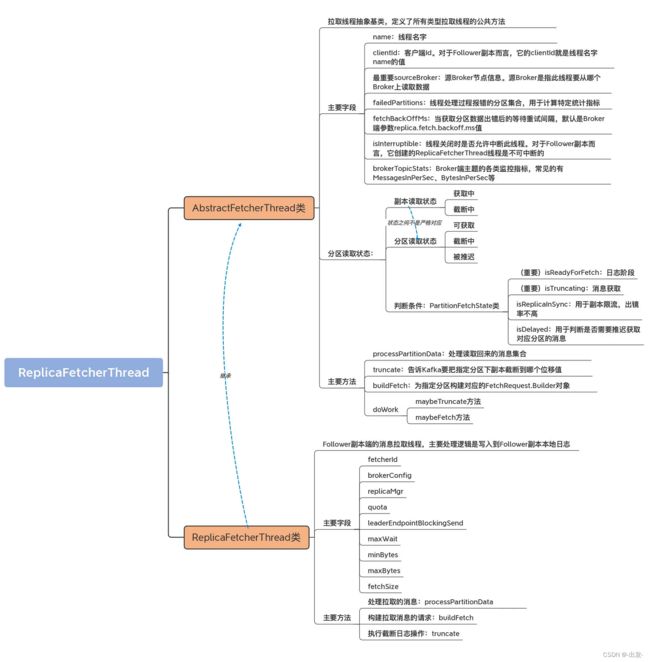
实际上,今天的内容中多次出现副本管理器的身影。如果你仔细查看代码,你会发现 Follower 副本正是利用它来获取对应分区 Partition 对象的,然后依靠该对象执行消息写入。那么,副本管理器还有哪些其他功能呢?下一讲我将一一为你揭晓。
3 ReplicaManager(上):必须要掌握的副本管理类定义和核心字段
今天,我们要学习的是 Kafka 中的副本管理器 ReplicaManager。它负责管理和操作集群中 Broker 的副本,还承担了一部分的分区管理工作,比如变更整个分区的副本日志路径等。
你一定还记得,前面讲到状态机的时候,我说过,Kafka 同时实现了副本状态机和分区状态机。但对于管理器而言,Kafka 源码却没有专门针对分区,定义一个类似于“分区管理器”这样的类,而是只定义了 ReplicaManager 类。该类不只实现了对副本的管理,还包含了很多操作分区对象的方法。
ReplicaManager 类的源码非常重要,它是构建 Kafka 副本同步机制的重要组件之一。副本同步过程中出现的大多数问题都是很难定位和解决的,因此,熟练掌握这部分源码,将有助于我们深入探索线上生产环境问题的根本原因,防止以后踩坑。下面,我给你分享一个真实的案例。
我们团队曾碰到过一件古怪事:在生产环境系统中执行删除消息的操作之后,该操作引发了 Follower 端副本与 Leader 端副本的不一致问题。刚碰到这个问题时,我们一头雾水,在正常情况下,Leader 端副本执行了消息删除后,日志起始位移值被更新了,Follower 端副本也应该更新日志起始位移值,但是,这里的 Follower 端的更新失败了。我们查遍了所有日志,依然找不到原因,最后还是通过分析 ReplicaManager 类源码,才找到了答案。
我们先看一下这个错误的详细报错信息:
Caused by: org.apache.kafka.common.errors.OffsetOutOfRangeException: Cannot increment the log start offset to 22786435 of partition XXX-12 since it is larger than the high watermark 22786129
这是 Follower 副本抛出来的异常,对应的 Leader 副本日志则一切如常。下面的日志显示出 Leader 副本的 Log Start Offset 已经被成功调整了。
INFO Incrementing log start offset of partition XXX-12 to 22786435
碰到这个问题时,我相信你的第一反应和我一样:这像是一个 Bug,但又不确定到底是什么原因导致的。后来,我们顺着 KafkaApis 一路找下去,直到找到了 ReplicaManager 的 deleteRecords 方法,才看出点端倪。
Follower 副本从 Leader 副本拉取到消息后,会做两个操作:
- 写入到自己的本地日志;
- 更新 Follower 副本的高水位值和 Log Start Offset。
如果删除消息的操作 deleteRecords 发生在这两步之间,因为 deleteRecords 会变更 Log Start Offset,所以,Follower 副本在进行第 2 步操作时,它使用的可能是已经过期的值了,因而会出现上面的错误。由此可见,这的确是一个 Bug。在确认了这一点之后,后面的解决方案也就呼之欲出了:虽然 deleteRecords 功能实用方便,但鉴于这个 Bug,我们还是应该尽力避免在线上环境直接使用该功能。
说到这儿,我想说一句,碰到实际的线上问题不可怕,可怕的是我们无法定位到问题的根本原因。写过 Java 项目的你一定有这种体会,很多时候,单纯依靠栈异常信息是不足以定位问题的。特别是涉及到 Kafka 副本同步这块,如果只看输出日志的话,你是很难搞清楚这里面的原理的,因此,我们必须要借助源码,这也是我们今天学习 ReplicaManager 类的主要目的。
接下来,我们就重点学习一下这个类。它位于 server 包下的同名 scala 文件中。这是一个有着将近 1900 行的大文件,里面的代码结构很琐碎。
因为副本的读写操作和管理操作都是重磅功能,所以,在深入细节之前,我们必须要理清 ReplicaManager 类的结构之间的关系,并且搞懂类定义及核心字段,这就是我们这节课的重要目标。
在接下来的两节课里,我会给你详细地解释副本读写操作和副本管理操作。学完这些之后,你就能清晰而深入地掌握 ReplicaManager 类的主要源码了,最重要的是,你会搞懂副本成为 Leader 或者是 Follower 时需要执行的逻辑,这就足以帮助你应对实际遇到的副本操作问题了。
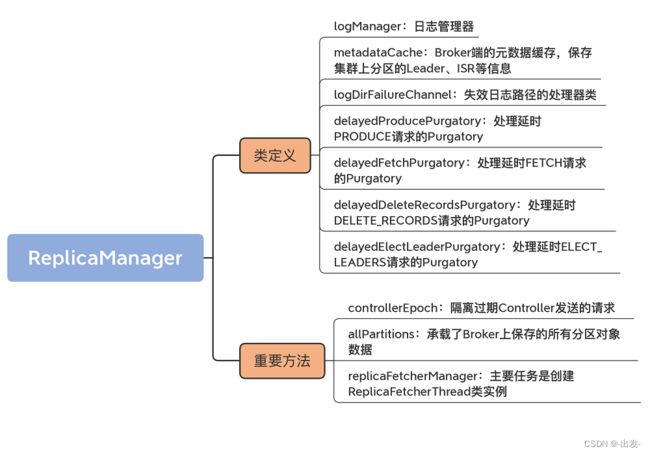
3.1 代码结构
我们首先看下这个 scala 文件的代码结构。我用一张思维导图向你展示下:
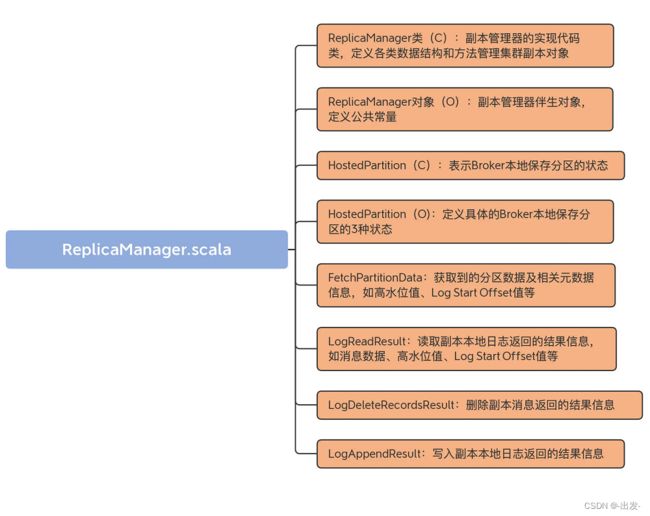
虽然从代码结构上看,该文件下有 8 个部分, 不过 HostedPartition 接口以及实现对象放在一起更好理解,所以,我把 ReplicaManager.scala 分为 7 大部分。
- ReplicaManager 类:它是副本管理器的具体实现代码,里面定义了读写副本、删除副本消息的方法以及其他管理方法。
- ReplicaManager 对象:ReplicaManager 类的伴生对象,仅仅定义了 3 个常量。
- HostedPartition 及其实现对象:表示 Broker 本地保存的分区对象的状态。可能的状态包括:不存在状态(None)、在线状态(Online)和离线状态(Offline)。
- FetchPartitionData:定义获取到的分区数据以及重要元数据信息,如高水位值、Log Start Offset 值等。
- LogReadResult:表示副本管理器从副本本地日志中读取到的消息数据以及相关元数据信息,如高水位值、Log Start Offset 值等。
- LogDeleteRecordsResult:表示副本管理器执行副本日志删除操作后返回的结果信息。
- LogAppendResult:表示副本管理器执行副本日志写入操作后返回的结果信息。
从含义来看,FetchPartitionData 和 LogReadResult 很类似,它们的区别在哪里呢?
其实,它们之间的差别非常小。如果翻开源码的话,你会发现,FetchPartitionData 类总共有 8 个字段,而构建 FetchPartitionData 实例的前 7 个字段都是用 LogReadResult 的字段来赋值的。你大致可以认为两者的作用是类似的。只是,FetchPartitionData 还有个字段标识该分区是不是处于重分配中。如果是的话,需要更新特定的 JXM 监控指标。这是这两个类的主要区别。
其实,它们之间的差别非常小。如果翻开源码的话,你会发现,FetchPartitionData 类总共有 8 个字段,而构建 FetchPartitionData 实例的前 7 个字段都是用 LogReadResult 的字段来赋值的。你大致可以认为两者的作用是类似的。只是,FetchPartitionData 还有个字段标识该分区是不是处于重分配中。如果是的话,需要更新特定的 JXM 监控指标。这是这两个类的主要区别。
在这 7 个部分中,ReplicaManager 类是我们学习的重点。其他类要么仅定义常量,要么就是保存数据的 POJO 类,作用一目了然,我就不展开讲了。
3.2 ReplicaManager 类定义
接下来,我们就从 Replica 类的定义和重要字段这两个维度入手,进行学习。首先看 ReplicaManager 类的定义。
class ReplicaManager(val config: KafkaConfig, // 配置管理类
metrics: Metrics, // 监控指标类
time: Time, // 定时器类
val zkClient: Option[KafkaZkClient], // ZooKeeper客户端
scheduler: Scheduler, // Kafka调度器
val logManager: LogManager, // 日志管理器
val isShuttingDown: AtomicBoolean, // 是否已经关闭
quotaManagers: QuotaManagers, // 配额管理器
val brokerTopicStats: BrokerTopicStats, // Broker主题监控指标类
val metadataCache: MetadataCache, // Broker元数据缓存
logDirFailureChannel: LogDirFailureChannel,
// 处理延时PRODUCE请求的Purgatory
val delayedProducePurgatory: DelayedOperationPurgatory[DelayedProduce],
// 处理延时FETCH请求的Purgatory
val delayedFetchPurgatory: DelayedOperationPurgatory[DelayedFetch],
// 处理延时DELETE_RECORDS请求的Purgatory
val delayedDeleteRecordsPurgatory: DelayedOperationPurgatory[DelayedDeleteRecords],
// 处理延时ELECT_LEADERS请求的Purgatory
val delayedElectLeaderPurgatory: DelayedOperationPurgatory[DelayedElectLeader],
threadNamePrefix: Option[String],
configRepository: ConfigRepository,
val alterIsrManager: AlterIsrManager) extends Logging with KafkaMetricsGroup {
......
}
ReplicaManager 类构造函数的字段非常多。有的字段含义很简单,像 time 和 metrics 这类字段,你一看就明白了,我就不多说了,我详细解释几个比较关键的字段。这些字段是我们理解副本管理器的重要基础。
-
logManager
这是日志管理器。它负责创建和管理分区的日志对象,里面定义了很多操作日志对象的方法,如 getOrCreateLog 等。
-
metadataCache
这是 Broker 端的元数据缓存,保存集群上分区的 Leader、ISR 等信息。注意,它和我们之前说的 Controller 端元数据缓存是有联系的。每台 Broker 上的元数据缓存,是从 Controller 端的元数据缓存异步同步过来的。
-
logDirFailureChannel
这是失效日志路径的处理器类。Kafka 1.1 版本新增了对于 JBOD 的支持。这也就是说,Broker 如果配置了多个日志路径,当某个日志路径不可用之后(比如该路径所在的磁盘已满),Broker 能够继续工作。那么,这就需要一整套机制来保证,在出现磁盘 I/O 故障时,Broker 的正常磁盘下的副本能够正常提供服务。
其中,logDirFailureChannel 是暂存失效日志路径的管理器类。我们不用具体学习这个特性的源码,但你最起码要知道,该功能算是 Kafka 提升服务器端高可用性的一个改进。有了它之后,即使 Broker 上的单块磁盘坏掉了,整个 Broker 的服务也不会中断。
-
四个 Purgatory 相关的字段
这 4 个字段是 delayedProducePurgatory、delayedFetchPurgatory、delayedDeleteRecordsPurgatory 和 delayedElectLeaderPurgatory,它们分别管理 4 类延时请求的。其中,前两类我们应该不陌生,就是处理延时生产者请求和延时消费者请求;后面两类是处理延时消息删除请求和延时 Leader 选举请求,属于比较高阶的用法(可以暂时不用理会)。
在副本管理过程中,状态的变更大多都会引发对延时请求的处理,这时候,这些 Purgatory 字段就派上用场了。
只要掌握了刚刚的这些字段,就可以应对接下来的副本管理操作了。其中,最重要的就是 logManager。它是协助副本管理器操作集群副本对象的关键组件。
3.3 重要的自定义字段
学完了类定义,我们看下 ReplicaManager 类中那些重要的自定义字段。这样的字段大约有 20 个,我们不用花时间逐一学习它们。像 isrExpandRate、isrShrinkRate 这样的字段,我们只看名字,就能知道,它们是衡量 ISR 变化的监控指标。下面,我详细介绍几个对理解副本管理器至关重要的字段。我会结合代码,具体讲解它们的含义,同时还会说明它们的重要用途。
3.3.1 controllerEpoch
我们首先来看 controllerEpoch 字段。
这个字段的作用是隔离过期 Controller 发送的请求。这就是说,老的 Controller 发送的请求不能再被继续处理了。至于如何区分是老 Controller 发送的请求,还是新 Controller 发送的请求,就是看请求携带的 controllerEpoch 值,是否等于这个字段的值。以下是它的定义代码:
@volatile private[server] var controllerEpoch: Int = KafkaController.InitialControllerEpoch
该字段表示最新一次变更分区 Leader 的 Controller 的 Epoch 值,其默认值为 0。Controller 每发生一次变更,该字段值都会 +1。
在 ReplicaManager 的代码中,很多地方都会用到它来判断 Controller 发送过来的控制类请求是否合法。如果请求中携带的 controllerEpoch 值小于该字段值,就说明这个请求是由一个老的 Controller 发出的,因此,ReplicaManager 直接拒绝该请求的处理。
值得注意的是,它是一个 var 类型,这就说明它的值是能够动态修改的。当 ReplicaManager 在处理控制类请求时,会更新该字段。可以看下下面的代码:
// becomeLeaderOrFollower方法
// 处理LeaderAndIsrRequest请求时
controllerEpoch = leaderAndIsrRequest.controllerEpoch
// stopReplicas方法
// 处理StopReplicaRequest请求时
this.controllerEpoch = controllerEpoch
// maybeUpdateMetadataCache方法
// 处理UpdateMetadataRequest请求时
controllerEpoch = updateMetadataRequest.controllerEpoch
Broker 上接收的所有请求都是由 Kafka I/O 线程处理的,而 I/O 线程可能有多个,因此,这里的 controllerEpoch 字段被声明为 volatile 型,以保证其内存可见性。
3.3.2 allPartitions
下一个重要的字段是 allPartitions。这节课刚开始时我说过,Kafka 没有所谓的分区管理器,ReplicaManager 类承担了一部分分区管理的工作。这里的 allPartitions,就承载了 Broker 上保存的所有分区对象数据。其定义代码如下:
protected val allPartitions = new Pool[TopicPartition, HostedPartition](
valueFactory = Some(tp => HostedPartition.Online(Partition(tp, time, configRepository, this)))
)
从代码可见,allPartitions 是分区 Partition 对象实例的容器。这里的 HostedPartition 是代表分区状态的类。allPartitions 会将所有分区对象初始化成 Online 状态。
值得注意的是,这里的分区状态和我们之前讲到的分区状态机里面的状态完全隶属于两套“领导班子”。也许未来它们会有合并的可能。毕竟,它们二者的功能是有重叠的地方的,表示的含义也有相似之处。比如它们都定义了 Online 状态,其实都是表示正常工作状态下的分区状态。当然,这只是我根据源码功能做的一个大胆推测,至于是否会合并,我们拭目以待吧。
再多说一句,Partition 类是表征分区的对象。一个 Partition 实例定义和管理单个分区,它主要是利用 logManager 帮助它完成对分区底层日志的操作。ReplicaManager 类对于分区的管理,都是通过 Partition 对象完成的。
3.3.3 replicaFetcherManager
第三个比较关键的字段是 replicaFetcherManager。它的主要任务是创建 ReplicaFetcherThread 类实例。上节课,我们学习了 ReplicaFetcherThread 类的源码,它的主要职责是帮助 Follower 副本向 Leader 副本拉取消息,并写入到本地日志中。
下面展示了 ReplicaFetcherManager 类的主要方法 createFetcherThread 源码:
protected def createReplicaFetcherManager(metrics: Metrics, time: Time, threadNamePrefix: Option[String], quotaManager: ReplicationQuotaManager) = {
// 创建ReplicaFetcherThread线程实例并返回
new ReplicaFetcherManager(config, this, metrics, time, threadNamePrefix, quotaManager)
}
该方法的主要目的是创建 ReplicaFetcherThread 实例,供 Follower 副本使用。线程的名字是根据 fetcherId 和 Broker ID 来确定的。ReplicaManager 类利用 replicaFetcherManager 字段,对所有 Fetcher 线程进行管理,包括线程的创建、启动、添加、停止和移除。
3.4 总结
这节课,我主要介绍了 ReplicaManager 类的定义以及重要字段。它们是理解后面 ReplicaManager 类管理功能的基础。
总的来说,ReplicaManager 类是 Kafka Broker 端管理分区和副本对象的重要组件。每个 Broker 在启动的时候,都会创建 ReplicaManager 实例。该实例一旦被创建,就会开始行使副本管理器的职责,对其下辖的 Leader 副本或 Follower 副本进行管理。
我们再简单回顾一下这节课的重点。
- ReplicaManager 类:副本管理器的具体实现代码,里面定义了读写副本、删除副本消息的方法,以及其他的一些管理方法。
- allPartitions 字段:承载了 Broker 上保存的所有分区对象数据。ReplicaManager 类通过它实现对分区下副本的管理。
- replicaFetcherManager 字段:创建 ReplicaFetcherThread 类实例,该线程类实现 Follower 副本向 Leader 副本实时拉取消息的逻辑。
今天,我多次提到 ReplicaManager 是副本管理器这件事。实际上,副本管理中的两个重要功能就是读取副本对象和写入副本对象。对于 Leader 副本而言,Follower 副本需要读取它的消息数据;对于 Follower 副本而言,它拿到 Leader 副本的消息后,需要将消息写入到自己的底层日志上。那么,读写副本的机制是怎么样的呢?下节课,我们深入地探究一下 ReplicaManager 类重要的副本读写方法。
4 ReplicaManager(中):副本管理器是如何读写副本的?
上节课,我们学习了 ReplicaManager 类的定义和重要字段,今天我们接着学习这个类中的读写副本对象部分的源码。无论是读取副本还是写入副本,都是通过底层的 Partition 对象完成的,而这些分区对象全部保存在上节课所学的 allPartitions 字段中。可以说,理解这些字段的用途,是后续我们探索副本管理器类功能的重要前提。
4.1 副本写入:appendRecords
所谓的副本写入,是指向副本底层日志写入消息。在 ReplicaManager 类中,实现副本写入的方法叫 appendRecords。
眼整个 Kafka 源码世界,需要副本写入的场景有 4 个。
- 场景一:生产者向 Leader 副本写入消息;
- 场景二:Follower 副本拉取消息后写入副本;
- 场景三:消费者组写入组信息;
- 场景四:事务管理器写入事务信息(包括事务标记、事务元数据等)。
除了第二个场景是直接调用 Partition 对象的方法实现之外,其他 3 个都是调用 appendRecords 来完成的。
该方法将给定一组分区的消息写入到对应的 Leader 副本中,并且根据 PRODUCE 请求中 acks 设置的不同,有选择地等待其他副本写入完成。然后,调用指定的回调逻辑。
我们先来看下它的方法签名:
def appendRecords(timeout: Long, // 请求处理超时时间
requiredAcks: Short, // 请求acks设置
internalTopicsAllowed: Boolean, // 是否允许写入内部主题
origin: AppendOrigin, // 写入方来源
entriesPerPartition: Map[TopicPartition, MemoryRecords], // 待写入消息
// 回调逻辑
responseCallback: Map[TopicPartition, PartitionResponse] => Unit,
delayedProduceLock: Option[Lock] = None,
recordConversionStatsCallback: Map[TopicPartition, RecordConversionStats] => Unit = _ => ()): Unit = {
......
}
输入参数有很多,而且都很重要,我一个一个地说。
-
timeout:请求处理超时时间。对于生产者来说,它就是 request.timeout.ms 参数值。
-
requiredAcks:是否需要等待其他副本写入。对于生产者而言,它就是 acks 参数的值。而在其他场景中,Kafka 默认使用 -1,表示等待其他副本全部写入成功再返回。
-
internalTopicsAllowed:是否允许向内部主题写入消息。对于普通的生产者而言,该字段是 False,即不允许写入内部主题。对于 Coordinator 组件,特别是消费者组 GroupCoordinator 组件来说,它的职责之一就是向内部位移主题写入消息,因此,此时,该字段值是 True。
-
origin:AppendOrigin 是一个接口,表示写入方来源。当前,它定义了 3 类写入方,分别是 Replication、Coordinator 和 Client。Replication 表示写入请求是由 Follower 副本发出的,它要将从 Leader 副本获取到的消息写入到底层的消息日志中。Coordinator 表示这些写入由 Coordinator 发起,它既可以是管理消费者组的 GroupCooridnator,也可以是管理事务的 TransactionCoordinator。Client 表示本次写入由客户端发起。前面我们说过了,Follower 副本同步过程不调用 appendRecords 方法,因此,这里的 origin 值只可能是 Replication 或 Coordinator。
-
entriesPerPartition:按分区分组的、实际要写入的消息集合。
-
responseCallback:写入成功之后,要调用的回调逻辑函数。
-
delayedProduceLock:专门用来保护消费者组操作线程安全的锁对象,在其他场景中用不到。
-
recordConversionStatsCallback:消息格式转换操作的回调统计逻辑,主要用于统计消息格式转换操作过程中的一些数据指标,比如总共转换了多少条消息,花费了多长时间。
接下来,我们就看看,appendRecords 如何利用这些输入参数向副本日志写入消息。我把它的完整代码贴出来。对于重要的步骤,我标注了注释:
// requiredAcks合法取值是-1,0,1,否则视为非法
if (isValidRequiredAcks(requiredAcks)) {
val sTime = time.milliseconds
// 调用appendToLocalLog方法写入消息集合到本地日志
val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,
origin, entriesPerPartition, requiredAcks)
debug("Produce to local log in %d ms".format(time.milliseconds - sTime))
val produceStatus = localProduceResults.map { case (topicPartition, result) =>
topicPartition -> ProducePartitionStatus(
result.info.lastOffset + 1, // 设置下一条待写入消息的位移值
// 构建PartitionResponse封装写入结果
new PartitionResponse(
result.error,
result.info.firstOffset.map(_.messageOffset).getOrElse(-1),
result.info.logAppendTime,
result.info.logStartOffset,
result.info.recordErrors.asJava,
result.info.errorMessage
)
) // response status
}
......
// 尝试更新消息格式转换的指标数据
recordConversionStatsCallback(localProduceResults.map { case (k, v) => k -> v.info.recordConversionStats })
// 需要等待其他副本完成写入
if (delayedProduceRequestRequired(requiredAcks, entriesPerPartition, localProduceResults)) {
// create delayed produce operation
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
// 创建DelayedProduce延时请求对象
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)
// create a list of (topic, partition) pairs to use as keys for this delayed produce operation
val producerRequestKeys = entriesPerPartition.keys.map(TopicPartitionOperationKey(_)).toSeq
// try to complete the request immediately, otherwise put it into the purgatory
// this is because while the delayed produce operation is being created, new
// requests may arrive and hence make this operation completable.
// 再一次尝试完成该延时请求
// 如果暂时无法完成,则将对象放入到相应的Purgatory中等待后续处理
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
} else {
// we can respond immediately
// 无需等待其他副本写入完成,可以立即发送Response
val produceResponseStatus = produceStatus.map { case (k, status) => k -> status.responseStatus }
// 调用回调逻辑然后返回即可
responseCallback(produceResponseStatus)
}
} else { // 如果requiredAcks值不合法
// If required.acks is outside accepted range, something is wrong with the client
// Just return an error and don't handle the request at all
val responseStatus = entriesPerPartition.map { case (topicPartition, _) =>
topicPartition -> new PartitionResponse(
Errors.INVALID_REQUIRED_ACKS,
LogAppendInfo.UnknownLogAppendInfo.firstOffset.map(_.messageOffset).getOrElse(-1),
RecordBatch.NO_TIMESTAMP,
LogAppendInfo.UnknownLogAppendInfo.logStartOffset
)
}
// 构造INVALID_REQUIRED_ACKS异常并封装进回调函数调用中
responseCallback(responseStatus)
}
为了帮助你更好地理解,我再用一张图说明一下 appendRecords 方法的完整流程。
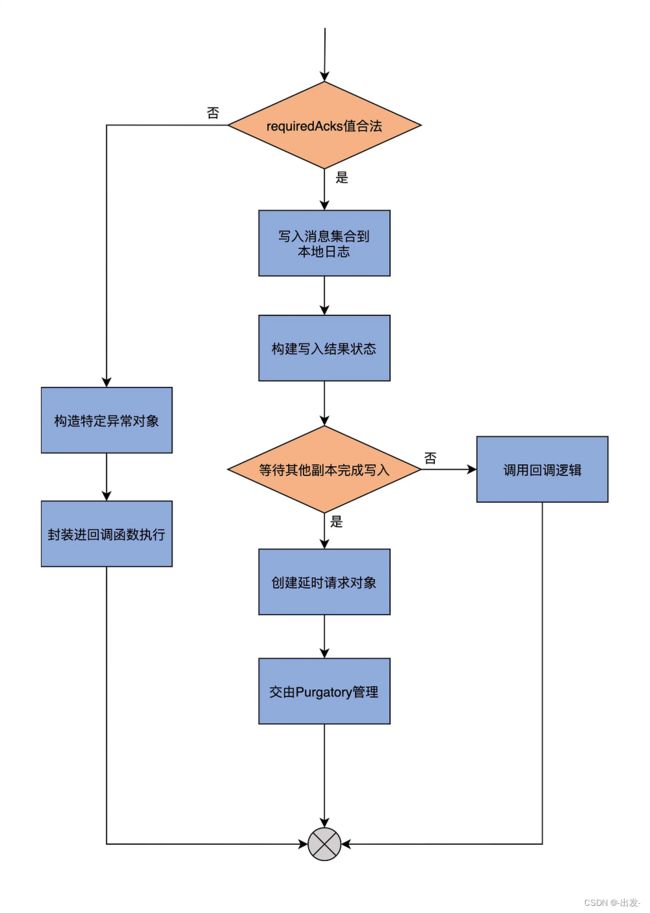
我再给你解释一下它的执行流程。
首先,它会判断 requiredAcks 的取值是否在合理范围内,也就是“是否是 -1、0、1 这 3 个数值中的一个”。如果不是合理取值,代码就进入到外层的 else 分支,构造名为 INVALID_REQUIRED_ACKS 的异常,并将其封装进回调函数中执行,然后返回结果。否则的话,代码进入到外层的 if 分支下。
进入到 if 分支后,代码调用 appendToLocalLog 方法,将要写入的消息集合保存到副本的本地日志上。然后构造 PartitionResponse 对象实例,来封装写入结果以及一些重要的元数据信息,比如本次写入有没有错误(errorMessage)、下一条待写入消息的位移值、本次写入消息集合首条消息的位移值,等等。待这些做完了之后,代码会尝试更新消息格式转换的指标数据。此时,源码需要调用 delayedProduceRequestRequired 方法,来判断本次写入是否算是成功了。
如果还需要等待其他副本同步完成消息写入,那么就不能立即返回,代码要创建 DelayedProduce 延时请求对象,并把该对象交由 Purgatory 来管理。DelayedProduce 是生产者端的延时发送请求,对应的 Purgatory 就是 ReplicaManager 类构造函数中的 delayedProducePurgatory。所谓的 Purgatory 管理,主要是调用 tryCompleteElseWatch 方法尝试完成延时发送请求。如果暂时无法完成,就将对象放入到相应的 Purgatory 中,等待后续处理。
如果无需等待其他副本同步完成消息写入,那么,appendRecords 方法会构造响应的 Response,并调用回调逻辑函数,至此,方法结束。
从刚刚的分析中,我们可以知道,appendRecords 实现消息写入的方法是 appendToLocalLog,用于判断是否需要等待其他副本写入的方法是 delayedProduceRequestRequired。下面我们就深入地学习下这两个方法的代码。
首先来看 appendToLocalLog。从它的名字来看,就是写入副本本地日志。我们来看一下该方法的主要代码片段。
private def appendToLocalLog(internalTopicsAllowed: Boolean,
origin: AppendOrigin,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
requiredAcks: Short): Map[TopicPartition, LogAppendResult] = {
......
entriesPerPartition.map { case (topicPartition, records) =>
brokerTopicStats.topicStats(topicPartition.topic).totalProduceRequestRate.mark()
brokerTopicStats.allTopicsStats.totalProduceRequestRate.mark()
// reject appending to internal topics if it is not allowed
// 如果要写入的主题是内部主题,而internalTopicsAllowed=false,则返回错误
if (Topic.isInternal(topicPartition.topic) && !internalTopicsAllowed) {
(topicPartition, LogAppendResult(
LogAppendInfo.UnknownLogAppendInfo,
Some(new InvalidTopicException(s"Cannot append to internal topic ${topicPartition.topic}"))))
} else {
try {
// 获取分区对象
val partition = getPartitionOrException(topicPartition)
// 向该分区对象写入消息集合
val info = partition.appendRecordsToLeader(records, origin, requiredAcks)
......
// 返回写入结果
(topicPartition, LogAppendResult(info))
} catch {
......
}
}
}
}
我忽略了很多打日志以及错误处理的代码。你可以看到,该方法主要就是利用 Partition 的 appendRecordsToLeader 方法写入消息集合,而后者就是利用我们在日志模块中学到的 appendAsLeader 方法写入本地日志的。总体来说,appendToLocalLog 的逻辑不复杂,你应该很容易理解。
下面我们看下 delayedProduceRequestRequired 方法的源码。它用于判断消息集合被写入到日志之后,是否需要等待其他副本也写入成功。我们看下它的代码:
// 1. required acks = -1
// 2. there is data to append
// 3. at least one partition append was successful (fewer errors than partitions)
private def delayedProduceRequestRequired(requiredAcks: Short,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
localProduceResults: Map[TopicPartition, LogAppendResult]): Boolean = {
requiredAcks == -1 &&
entriesPerPartition.nonEmpty &&
localProduceResults.values.count(_.exception.isDefined) < entriesPerPartition.size
}
该方法返回一个布尔值,True 表示需要等待其他副本完成;False 表示无需等待。上面的代码表明,如果需要等待其他副本的写入,就必须同时满足 3 个条件:
- requiredAcks 必须等于 -1;
- 依然有数据尚未写完;
- 至少有一个分区的消息已经成功地被写入到本地日志。
其实,你可以把条件 2 和 3 联合在一起来看。如果所有分区的数据写入都不成功,就表明可能出现了很严重的错误,此时,比较明智的做法是不再等待,而是直接返回错误给发送方。相反地,如果有部分分区成功写入,而部分分区写入失败了,就表明可能是由偶发的瞬时错误导致的。此时,不妨将本次写入请求放入 Purgatory,再给它一个重试的机会。
4.2 副本读取:fetchMessages
好了,说完了副本的写入,下面我们进入到副本读取的源码学习。
在 ReplicaManager 类中,负责读取副本数据的方法是 fetchMessages。不论是 Java 消费者 API,还是 Follower 副本,它们拉取消息的主要途径都是向 Broker 发送 FETCH 请求,Broker 端接收到该请求后,调用 fetchMessages 方法从底层的 Leader 副本取出消息。
和 appendRecords 方法类似,fetchMessages 方法也可能会延时处理 FETCH 请求,因为 Broker 端必须要累积足够多的数据之后,才会返回 Response 给请求发送方。
可以看一下下面的这张流程图,它展示了 fetchMessages 方法的主要逻辑。

我们来看下该方法的签名:
def fetchMessages(timeout: Long, // 请求处理超时时间
replicaId: Int, // 副本 ID
fetchMinBytes: Int, // 能够获取的最小字节数
fetchMaxBytes: Int, // 能够获取的最大字节数
hardMaxBytesLimit: Boolean, // 对能否超过最大字节数做硬限制
fetchInfos: Seq[(TopicPartition, PartitionData)], // 规定了读取分区的信息
quota: ReplicaQuota, // 限速控制
responseCallback: Seq[(TopicPartition, FetchPartitionData)] => Unit,
isolationLevel: IsolationLevel,
clientMetadata: Option[ClientMetadata]): Unit = {
......
}
这些输入参数都是我们理解下面的重要方法的基础,所以,我们来逐个分析一下。
- timeout:请求处理超时时间。对于消费者而言,该值就是 request.timeout.ms 参数值;对于 Follower 副本而言,该值是 Broker 端参数 replica.fetch.wait.max.ms 的值。
- replicaId:副本 ID。对于消费者而言,该参数值是 -1;对于 Follower 副本而言,该值就是 Follower 副本所在的 Broker ID。
- fetchMinBytes & fetchMaxBytes:能够获取的最小字节数和最大字节数。对于消费者而言,它们分别对应于 Consumer 端参数 fetch.min.bytes 和 fetch.max.bytes 值;对于 Follower 副本而言,它们分别对应于 Broker 端参数 replica.fetch.min.bytes 和 replica.fetch.max.bytes 值。
- hardMaxBytesLimit:对能否超过最大字节数做硬限制。如果 hardMaxBytesLimit=True,就表示,读取请求返回的数据字节数绝不允许超过最大字节数。
- fetchInfos:规定了读取分区的信息,比如要读取哪些分区、从这些分区的哪个位移值开始读、最多可以读多少字节,等等。
- quota:这是一个配额控制类,主要是为了判断是否需要在读取的过程中做限速控制。
- responseCallback:Response 回调逻辑函数。当请求被处理完成后,调用该方法执行收尾逻辑。
有了这些铺垫之后,我们进入到方法代码的学习。为了便于学习,我将整个方法的代码分成两部分:第一部分是读取本地日志;第二部分是根据读取结果确定 Response。
// 判断该读取请求是否来自于Follower副本或Consumer
val isFromFollower = Request.isValidBrokerId(replicaId)
val isFromConsumer = !(isFromFollower || replicaId == Request.FutureLocalReplicaId)
// 根据请求发送方判断可读取范围
// 如果请求来自于普通消费者,那么可以读到高水位值
// 如果请求来自于配置了READ_COMMITTED的消费者,那么可以读到Log Stable Offset值
// 如果请求来自于Follower副本,那么可以读到LEO值
val fetchIsolation = if (!isFromConsumer)
FetchLogEnd
else if (isolationLevel == IsolationLevel.READ_COMMITTED)
FetchTxnCommitted
else
FetchHighWatermark
// Restrict fetching to leader if request is from follower or from a client with older version (no ClientMetadata)
val fetchOnlyFromLeader = isFromFollower || (isFromConsumer && clientMetadata.isEmpty)
// 定义readFromLog方法读取底层日志中的消息
def readFromLog(): Seq[(TopicPartition, LogReadResult)] = {
val result = readFromLocalLog(
replicaId = replicaId,
fetchOnlyFromLeader = fetchOnlyFromLeader,
fetchIsolation = fetchIsolation,
fetchMaxBytes = fetchMaxBytes,
hardMaxBytesLimit = hardMaxBytesLimit,
readPartitionInfo = fetchInfos,
quota = quota,
clientMetadata = clientMetadata)
if (isFromFollower) updateFollowerFetchState(replicaId, result)
else result
}
// 读取消息并返回日志读取结果
val logReadResults = readFromLog()
这部分代码首先会判断,读取消息的请求方到底是 Follower 副本,还是普通的 Consumer。判断的依据就是看 replicaId 字段是否大于 0。Consumer 的 replicaId 是 -1,而 Follower 副本的则是大于 0 的数。一旦确定了请求方,代码就能确定可读取范围。
这里的 fetchIsolation 是读取隔离级别的意思。对于 Follower 副本而言,它能读取到 Leader 副本 LEO 值以下的所有消息;对于普通 Consumer 而言,它只能“看到”Leader 副本高水位值以下的消息。
待确定了可读取范围后,fetchMessages 方法会调用它的内部方法 readFromLog,读取本地日志上的消息数据,并将结果赋值给 logReadResults 变量。readFromLog 方法的主要实现是调用 readFromLocalLog 方法,而后者就是在待读取分区上依次调用其日志对象的 read 方法执行实际的消息读取。
fetchMessages 方法的第二部分,是根据上一步的读取结果创建对应的 Response。我们看下具体实现:
// check if this fetch request can be satisfied right away
var bytesReadable: Long = 0
var errorReadingData = false
var hasDivergingEpoch = false
// 统计总共可读取的字节数
val logReadResultMap = new mutable.HashMap[TopicPartition, LogReadResult]
logReadResults.foreach { case (topicPartition, logReadResult) =>
brokerTopicStats.topicStats(topicPartition.topic).totalFetchRequestRate.mark()
brokerTopicStats.allTopicsStats.totalFetchRequestRate.mark()
if (logReadResult.error != Errors.NONE)
errorReadingData = true
if (logReadResult.divergingEpoch.nonEmpty)
hasDivergingEpoch = true
bytesReadable = bytesReadable + logReadResult.info.records.sizeInBytes
logReadResultMap.put(topicPartition, logReadResult)
}
// 判断是否能够立即返回Reponse,满足以下4个条件中的任意一个即可:
// 1. 请求没有设置超时时间,说明请求方想让请求被处理后立即返回
// 2. 未获取到任何数据
// 3. 已累积到足够多的数据
// 4. 读取过程中出错
if (timeout <= 0 || fetchInfos.isEmpty || bytesReadable >= fetchMinBytes || errorReadingData || hasDivergingEpoch) {
val fetchPartitionData = logReadResults.map { case (tp, result) =>
val isReassignmentFetch = isFromFollower && isAddingReplica(tp, replicaId)
tp -> result.toFetchPartitionData(isReassignmentFetch)
}
// 构建返回结果
responseCallback(fetchPartitionData)
} else { // 如果无法立即完成请求
// construct the fetch results from the read results
val fetchPartitionStatus = new mutable.ArrayBuffer[(TopicPartition, FetchPartitionStatus)]
fetchInfos.foreach { case (topicPartition, partitionData) =>
logReadResultMap.get(topicPartition).foreach(logReadResult => {
val logOffsetMetadata = logReadResult.info.fetchOffsetMetadata
fetchPartitionStatus += (topicPartition -> FetchPartitionStatus(logOffsetMetadata, partitionData))
})
}
val fetchMetadata: SFetchMetadata = SFetchMetadata(fetchMinBytes, fetchMaxBytes, hardMaxBytesLimit,
fetchOnlyFromLeader, fetchIsolation, isFromFollower, replicaId, fetchPartitionStatus)
val delayedFetch = new DelayedFetch(timeout, fetchMetadata, this, quota, clientMetadata,
responseCallback)
// create a list of (topic, partition) pairs to use as keys for this delayed fetch operation
// 构建DelayedFetch延时请求对象
val delayedFetchKeys = fetchPartitionStatus.map { case (tp, _) => TopicPartitionOperationKey(tp) }
// try to complete the request immediately, otherwise put it into the purgatory;
// this is because while the delayed fetch operation is being created, new requests
// may arrive and hence make this operation completable.
// 再一次尝试完成请求,如果依然不能完成,则交由Purgatory等待后续处理
delayedFetchPurgatory.tryCompleteElseWatch(delayedFetch, delayedFetchKeys)
}
这部分代码首先会根据上一步得到的读取结果,统计可读取的总字节数,之后,判断此时是否能够立即返回 Reponse。那么,怎么判断是否能够立即返回 Response 呢?实际上,只要满足以下 4 个条件中的任意一个即可:
- 请求没有设置超时时间,说明请求方想让请求被处理后立即返回;
- 未获取到任何数据;
- 已累积到足够多数据;
- 读取过程中出错。
如果这 4 个条件一个都不满足,就需要进行延时处理了。具体来说,就是构建 DelayedFetch 对象,然后把该延时对象交由 delayedFetchPurgatory 后续自动处理。
至此,关于副本管理器读写副本的两个方法 appendRecords 和 fetchMessages,我们就学完了。本质上,它们在底层分别调用 Log 的 append 和 read 方法,以实现本地日志的读写操作。当完成读写操作之后,这两个方法还定义了延时处理的条件。一旦发现满足了延时处理的条件,就交给对应的 Purgatory 进行处理。
从这两个方法中,我们已经看到了之前课程中单个组件融合在一起的趋势。就像我在开篇词里面说的,虽然我们学习单个源码文件的顺序是自上而下,但串联 Kafka 主要组件功能的路径却是自下而上。
就拿这节课的副本写入操作来说,日志对象的 append 方法被上一层 Partition 对象中的方法调用,而后者又进一步被副本管理器中的方法调用。我们是按照自上而下的方式阅读副本管理器、日志对象等单个组件的代码,了解它们各自的独立功能的,现在,我们开始慢慢地把它们融合在一起,勾勒出了 Kafka 操作分区副本日志对象的完整调用路径。咱们同时采用这两种方式来阅读源码,就可以更快、更深入地搞懂 Kafka 源码的原理了。
4.3 总结
今天,我们学习了 Kafka 副本状态机类 ReplicaManager 是如何读写副本的,重点学习了它的两个重要方法 appendRecords 和 fetchMessages。我们再简单回顾一下。
- appendRecords:向副本写入消息的方法,主要利用 Log 的 append 方法和 Purgatory 机制,共同实现 Follower 副本向 Leader 副本获取消息后的数据同步工作。
- fetchMessages:从副本读取消息的方法,为普通 Consumer 和 Follower 副本所使用。当它们向 Broker 发送 FETCH 请求时,Broker 上的副本管理器调用该方法从本地日志中获取指定消息。

下节课中,我们要把重心转移到副本管理器对副本和分区对象的管理上。这是除了读写副本之外,副本管理器另一大核心功能,你一定不要错过!
5 ReplicaManager(下):副本管理器是如何管理副本的?
上节课我们学习了 ReplicaManager 类源码中副本管理器是如何执行副本读写操作的。现在我们知道了,这个副本读写操作主要是通过 appendRecords 和 fetchMessages 这两个方法实现的,而这两个方法其实在底层分别调用了 Log 的 append 和 read 方法,也就是我们在日志模块中学到的日志消息写入和日志消息读取方法。
今天,我们继续学习 ReplicaManager 类源码,看看副本管理器是如何管理副本的。这里的副本,涵盖了广义副本对象的方方面面,包括副本和分区对象、副本位移值和 ISR 管理等。因此,本节课我们结合着源码,具体学习下这几个方面。
5.1 分区及副本管理
除了对副本进行读写之外,副本管理器还有一个重要的功能,就是管理副本和对应的分区。ReplicaManager 管理它们的方式,是通过字段 allPartitions 来实现的。
所以,我想先带你复习下 3.3.2 allPartitions 中的 allPartitions 的代码。不过,这次为了强调它作为容器的属性,我们要把注意力放在它是对象池这个特点上,即 allPartitions 把所有分区对象汇集在一起,统一放入到一个对象池进行管理。
protected val allPartitions = new Pool[TopicPartition, HostedPartition](
valueFactory = Some(tp => HostedPartition.Online(Partition(tp, time, configRepository, this)))
)
从代码可以看到,每个 ReplicaManager 实例都维护了所在 Broker 上保存的所有分区对象,而每个分区对象 Partition 下面又定义了一组副本对象 Replica。通过这样的层级关系,副本管理器实现了对于分区的直接管理和对副本对象的间接管理。应该这样说,ReplicaManager 通过直接操作分区对象来间接管理下属的副本对象。
对于一个 Broker 而言,它管理下辖的分区和副本对象的主要方式,就是要确定在它保存的这些副本中,哪些是 Leader 副本、哪些是 Follower 副本。
这些划分可不是一成不变的,而是随着时间的推移不断变化的。比如说,这个时刻 Broker 是分区 A 的 Leader 副本、分区 B 的 Follower 副本,但在接下来的某个时刻,Broker 很可能变成分区 A 的 Follower 副本、分区 B 的 Leader 副本。
而这些变更是通过 Controller 给 Broker 发送 LeaderAndIsrRequest 请求来实现的。当 Broker 端收到这类请求后,会调用副本管理器的 becomeLeaderOrFollower 方法来处理,并依次执行“成为 Leader 副本”和“成为 Follower 副本”的逻辑,令当前 Broker 互换分区 A、B 副本的角色。
5.1.1 becomeLeaderOrFollower 方法
这里我们又提到了 LeaderAndIsrRequest 请求。其实,我们在学习Controller 和控制类请求的时候就多次提到过它,在Controller模块 中也详细学习过它的作用了。因为隔的时间比较长了,我怕你忘记了,所以这里我们再回顾下。
简单来说,它就是告诉接收该请求的 Broker:在我传给你的这些分区中,哪些分区的 Leader 副本在你这里;哪些分区的 Follower 副本在你这里。
becomeLeaderOrFollower 方法,就是具体处理 LeaderAndIsrRequest 请求的地方,同时也是副本管理器添加分区的地方。下面我们就完整地学习下这个方法的源码。由于这部分代码很长,我将会分为 3 个部分向你介绍,分别是处理 Controller Epoch 事宜、执行成为 Leader 和 Follower 的逻辑以及构造 Response。
我们先看 becomeLeaderOrFollower 方法的第 1 大部分,处理 Controller Epoch 及其他相关准备工作的流程图:
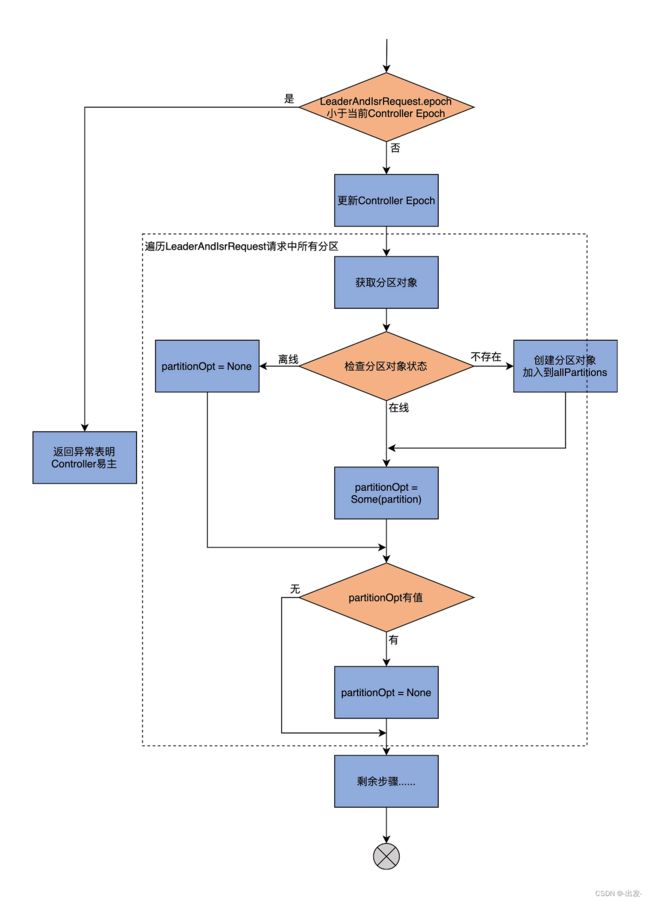
因为 becomeLeaderOrFollower 方法的开头是一段仅用于调试的日志输出,不是很重要,因此,我直接从 if 语句开始讲起。第一部分的主体代码如下:
//第一部分的主体代码
// 如果LeaderAndIsrRequest携带的Controller Epoch 小于当前Controller的Epoch值
if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) {
stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from controller $controllerId with " +
s"correlation id $correlationId since its controller epoch ${leaderAndIsrRequest.controllerEpoch} is old. " +
s"Latest known controller epoch is $controllerEpoch")
// 说明Controller已经易主,抛出相应异常
leaderAndIsrRequest.getErrorResponse(0, Errors.STALE_CONTROLLER_EPOCH.exception)
} else {
val responseMap = new mutable.HashMap[TopicPartition, Errors]
// 更新当前Controller Epoch值
controllerEpoch = leaderAndIsrRequest.controllerEpoch
val partitionStates = new mutable.HashMap[Partition, LeaderAndIsrPartitionState]()
// First create the partition if it doesn't exist already
// 遍历LeaderAndIsrRequest请求中的所有分区
requestPartitionStates.foreach { partitionState =>
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)
// 从allPartitions中获取对应分区对象
val partitionOpt = getPartition(topicPartition) match {
// 如果是Offline状态
case HostedPartition.Offline =>
stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from " +
s"controller $controllerId with correlation id $correlationId " +
s"epoch $controllerEpoch for partition $topicPartition as the local replica for the " +
"partition is in an offline log directory")
// 添加对象异常到Response,并设置分区对象变量partitionOpt=None
responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)
None
case _: HostedPartition.Deferred =>
throw new IllegalStateException("We should never be deferring partition metadata changes and becoming a leader or follower when using ZooKeeper")
// 如果是Online状态,直接赋值partitionOpt即可
case HostedPartition.Online(partition) =>
Some(partition)
// 如果是None状态,则表示没有找到分区对象
// 那么创建新的分区对象,将新创建的分区对象加入到allPartitions统一管理
// 然后赋值partitionOpt字段
case HostedPartition.None =>
val partition = Partition(topicPartition, time, configRepository, this)
allPartitions.putIfNotExists(topicPartition, HostedPartition.Online(partition))
Some(partition)
}
// 检查分区的Leader Epoch值
......
}
//第二部分的主体代码
}
现在,我们一起来学习下这部分内容的核心逻辑。
首先,比较 LeaderAndIsrRequest 携带的 Controller Epoch 值和当前 Controller Epoch 值。如果发现前者小于后者,说明 Controller 已经变更到别的 Broker 上了,需要构造一个 STALE_CONTROLLER_EPOCH 异常并封装进 Response 返回。否则,代码进入 else 分支。
然后,becomeLeaderOrFollower 方法会更新当前缓存的 Controller Epoch 值,再提取出 LeaderAndIsrRequest 请求中涉及到的分区,之后依次遍历这些分区,并执行下面的两步逻辑。
第 1 步,从 allPartitions 中取出对应的分区对象。在第 23 节课,我们学习了分区有 3 种状态,即在线(Online)、离线(Offline)和不存在(None),这里代码就需要分别应对这 3 种情况:
- 如果是 Online 状态的分区,直接将其赋值给 partitionOpt 字段即可;
- 如果是 Offline 状态的分区,说明该分区副本所在的 Kafka 日志路径出现 I/O 故障时(比如磁盘满了),需要构造对应的 KAFKA_STORAGE_ERROR 异常并封装进 Response,同时令 partitionOpt 字段为 None;
- 如果是 None 状态的分区,则创建新分区对象,然后将其加入到 allPartitions 中,进行统一管理,并赋值给 partitionOpt 字段。
第 2 步,检查 partitionOpt 字段表示的分区的 Leader Epoch。检查的原则是要确保请求中携带的 Leader Epoch 值要大于当前缓存的 Leader Epoch,否则就说明是过期 Controller 发送的请求,就直接忽略它,不做处理。
总之呢,becomeLeaderOrFollower 方法的第一部分代码,主要做的事情就是创建新分区、更新 Controller Epoch 和校验分区 Leader Epoch。我们在日志模块说到过 Leader Epoch 机制,因为是比较高阶的用法,你可以不用重点掌握,这不会影响到我们学习副本管理。不过,如果你想深入了解的话,推荐你课下自行阅读下 LeaderEpochFileCache.scala 的源码。
当为所有分区都执行完这两个步骤之后,becomeLeaderOrFollower 方法进入到第 2 部分,开始执行 Broker 成为 Leader 副本和 Follower 副本的逻辑:
// 确定Broker上副本是哪些分区的Leader副本
val partitionsToBeLeader = partitionStates.filter { case (_, partitionState) =>
partitionState.leader == localBrokerId
}
// 确定Broker上副本是哪些分区的Follower副本
val partitionsToBeFollower = partitionStates.filter { case (k, _) => !partitionsToBeLeader.contains(k) }
val highWatermarkCheckpoints = new LazyOffsetCheckpoints(this.highWatermarkCheckpoints)
val partitionsBecomeLeader = if (partitionsToBeLeader.nonEmpty)
// 调用makeLeaders方法为partitionsToBeLeader所有分区
// 执行"成为Leader副本"的逻辑
makeLeaders(controllerId, controllerEpoch, partitionsToBeLeader, correlationId, responseMap,
highWatermarkCheckpoints)
else
Set.empty[Partition]
val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)
// 调用makeFollowers方法为令partitionsToBeFollower所有分区
// 执行"成为Follower副本"的逻辑
makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap,
highWatermarkCheckpoints)
else
Set.empty[Partition]
val followerTopicSet = partitionsBecomeFollower.map(_.topic).toSet
// 对于当前Broker成为Follower副本的主题,移除它们之前的Leader副本监控指标
// 对于当前Broker成为Leader副本的主题,移除它们之前的Follower副本监控指
updateLeaderAndFollowerMetrics(followerTopicSet)
// 如果有分区的本地日志为空,说明底层的日志路径不可用
// 标记该分区为Offline状态
leaderAndIsrRequest.partitionStates.forEach { partitionState =>
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)
/*
* If there is offline log directory, a Partition object may have been created by getOrCreatePartition()
* before getOrCreateReplica() failed to create local replica due to KafkaStorageException.
* In this case ReplicaManager.allPartitions will map this topic-partition to an empty Partition object.
* we need to map this topic-partition to OfflinePartition instead.
*/
if (localLog(topicPartition).isEmpty)
markPartitionOffline(topicPartition)
}
首先,这部分代码需要先确定两个分区集合,一个是把该 Broker 当成 Leader 的所有分区;一个是把该 Broker 当成 Follower 的所有分区。判断的依据,主要是看 LeaderAndIsrRequest 请求中分区的 Leader 信息,是不是和本 Broker 的 ID 相同。如果相同,则表明该 Broker 是这个分区的 Leader;否则,表示当前 Broker 是这个分区的 Follower。
一旦确定了这两个分区集合,接着,代码就会分别为它们调用 makeLeaders 和 makeFollowers 方法,正式让 Leader 和 Follower 角色生效。之后,对于那些当前 Broker 成为 Follower 副本的主题,代码需要移除它们之前的 Leader 副本监控指标,以防出现系统资源泄露的问题。同样地,对于那些当前 Broker 成为 Leader 副本的主题,代码要移除它们之前的 Follower 副本监控指标。
最后,如果有分区的本地日志为空,说明底层的日志路径不可用,那么标记该分区为 Offline 状态。所谓的标记为 Offline 状态,主要是两步:第 1 步是更新 allPartitions 中分区的状态;第 2 步是移除对应分区的监控指标。
小结一下,becomeLeaderOrFollower 方法第 2 大部分的主要功能是,调用 makeLeaders 和 makeFollowers 方法,令 Broker 在不同分区上的 Leader 或 Follower 角色生效。关于这两个方法的实现细节,一会儿我再详细说。
现在,让我们看看第 3 大部分的代码,构造 Response 对象。这部分代码是 becomeLeaderOrFollower 方法的收尾操作。
// 启动高水位检查点专属线程
// 定期将Broker上所有非Offline分区的高水位值写入到检查点文件
startHighWatermarkCheckPointThread()
// 添加日志路径数据迁移线程
maybeAddLogDirFetchers(partitionStates.keySet, highWatermarkCheckpoints)
// 关闭空闲副本拉取线程
replicaFetcherManager.shutdownIdleFetcherThreads()
// 关闭空闲日志路径数据迁移线程
replicaAlterLogDirsManager.shutdownIdleFetcherThreads()
// 执行Leader变更之后的回调逻辑
onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)
if (leaderAndIsrRequest.version() < 5) {
// 构造LeaderAndIsrRequest请求的Response并返回
val responsePartitions = responseMap.iterator.map { case (tp, error) =>
new LeaderAndIsrPartitionError()
.setTopicName(tp.topic)
.setPartitionIndex(tp.partition)
.setErrorCode(error.code)
}.toBuffer
new LeaderAndIsrResponse(new LeaderAndIsrResponseData()
.setErrorCode(Errors.NONE.code)
.setPartitionErrors(responsePartitions.asJava), leaderAndIsrRequest.version())
} else {
val topics = new mutable.HashMap[String, List[LeaderAndIsrPartitionError]]
responseMap.asJava.forEach { case (tp, error) =>
if (!topics.contains(tp.topic)) {
topics.put(tp.topic, List(new LeaderAndIsrPartitionError()
.setPartitionIndex(tp.partition)
.setErrorCode(error.code)))
} else {
topics.put(tp.topic, new LeaderAndIsrPartitionError()
.setPartitionIndex(tp.partition)
.setErrorCode(error.code)::topics(tp.topic))
}
}
val topicErrors = topics.iterator.map { case (topic, partitionError) =>
new LeaderAndIsrTopicError()
.setTopicId(topicIds.get(topic))
.setPartitionErrors(partitionError.asJava)
}.toBuffer
new LeaderAndIsrResponse(new LeaderAndIsrResponseData()
.setErrorCode(Errors.NONE.code)
.setTopics(topicErrors.asJava), leaderAndIsrRequest.version())
}
我们来分析下这部分代码的执行逻辑吧。
首先,这部分开始时会启动一个专属线程来执行高水位值持久化,定期地将 Broker 上所有非 Offline 分区的高水位值写入检查点文件。这个线程是个后台线程,默认每 5 秒执行一次。
同时,代码还会添加日志路径数据迁移线程。这个线程的主要作用是,将路径 A 上面的数据搬移到路径 B 上。这个功能是 Kafka 支持 JBOD(Just a Bunch of Disks)的重要前提。
之后,becomeLeaderOrFollower 方法会关闭空闲副本拉取线程和空闲日志路径数据迁移线程。判断空闲与否的主要条件是,分区 Leader/Follower 角色调整之后,是否存在不再使用的拉取线程了。代码要确保及时关闭那些不再被使用的线程对象。
再之后是执行 LeaderAndIsrRequest 请求的回调处理逻辑。这里的回调逻辑,实际上只是对 Kafka 两个内部主题(__consumer_offsets 和 __transaction_state)有用,其他主题一概不适用。所以通常情况下,你可以无视这里的回调逻辑。
等这些都做完之后,代码开始执行这部分最后,也是最重要的任务:构造 LeaderAndIsrRequest 请求的 Response,然后将新创建的 Response 返回。至此,这部分方法的逻辑结束。
纵观 becomeLeaderOrFollower 方法的这 3 大部分,becomeLeaderOrFollower 方法最重要的职责,在我看来就是调用 makeLeaders 和 makeFollowers 方法,为各自的分区列表执行相应的角色确认工作。
接下来,我们就分别看看这两个方法是如何实现这种角色确认的。
5.1.2 makeLeaders 方法
makeLeaders 方法的作用是,让当前 Broker 成为给定一组分区的 Leader,也就是让当前 Broker 下该分区的副本成为 Leader 副本。这个方法主要有 3 步:
- 停掉这些分区对应的获取线程;
- 更新 Broker 缓存中的分区元数据信息;
- 将指定分区添加到 Leader 分区集合。
我们结合代码分析下这些都是如何实现的。首先,我们看下 makeLeaders 的方法签名:
// controllerId:Controller所在Broker的ID
// controllEpoch:Controller Epoch值,可以认为是Controller版本号
// partitionStates:LeaderAndIsrRequest请求中携带的分区信息
// correlationId:请求的Correlation字段,只用于日志调试
// responseMap:按照主题分区分组的异常错误集合
// highWatermarkCheckpoints:操作磁盘上高水位检查点文件的工具类
private def makeLeaders(controllerId: Int,
controllerEpoch: Int,
partitionStates: Map[Partition, LeaderAndIsrPartitionState],
correlationId: Int,
responseMap: mutable.Map[TopicPartition, Errors],
highWatermarkCheckpoints: OffsetCheckpoints): Set[Partition] = {
......
}
可以看出,makeLeaders 方法接收 6 个参数,并返回一个分区对象集合。这个集合就是当前 Broker 是 Leader 的所有分区。在这 6 个参数中,以下 3 个参数比较关键,我们看下它们的含义。
- controllerId:Controller 所在 Broker 的 ID。该字段只是用于日志输出,无其他实际用途。
- controllerEpoch:Controller Epoch 值,可以认为是 Controller 版本号。该字段用于日志输出使用,无其他实际用途。
- partitionStates:LeaderAndIsrRequest 请求中携带的分区信息,包括每个分区的 Leader 是谁、ISR 都有哪些等数据。
好了,现在我们继续学习 makeLeaders 的代码。我把这个方法的关键步骤放在了注释里,并省去了一些日志输出相关的代码。
// 使用Errors.NONE初始化ResponseMap
partitionStates.keys.foreach { partition =>
......
responseMap.put(partition.topicPartition, Errors.NONE)
}
val partitionsToMakeLeaders = mutable.Set[Partition]()
try {
// 停止消息拉取
replicaFetcherManager.removeFetcherForPartitions(partitionStates.keySet.map(_.topicPartition))
stateChangeLogger.info(s"Stopped fetchers as part of LeaderAndIsr request correlationId $correlationId from " +
s"controller $controllerId epoch $controllerEpoch as part of the become-leader transition for " +
s"${partitionStates.size} partitions")
// Update the partition information to be the leader
// 更新指定分区的Leader分区信息
partitionStates.forKeyValue { (partition, partitionState) =>
try {
if (partition.makeLeader(partitionState, highWatermarkCheckpoints))
partitionsToMakeLeaders += partition
else
......
} catch {
case e: KafkaStorageException =>
......
// 把KAFKA_SOTRAGE_ERRROR异常封装到Response中
responseMap.put(partition.topicPartition, Errors.KAFKA_STORAGE_ERROR)
}
}
} catch {
case e: Throwable =>
......
}
......
partitionsToMakeLeaders
我把主要的执行流程,梳理为了一张流程图:

结合着图,我再带着你学习下这个方法的执行逻辑。
首先,将给定的一组分区的状态全部初始化成 Errors.None。
然后,停止为这些分区服务的所有拉取线程。毕竟该 Broker 现在是这些分区的 Leader 副本了,不再是 Follower 副本了,所以没有必要再使用拉取线程了。
最后,makeLeaders 方法调用 Partition 的 makeLeader 方法,去更新给定一组分区的 Leader 分区信息,而这些是由 Partition 类中的 makeLeader 方法完成的。该方法保存分区的 Leader 和 ISR 信息,同时创建必要的日志对象、重设远端 Follower 副本的 LEO 值。
那远端 Follower 副本,是什么意思呢?远端 Follower 副本,是指保存在 Leader 副本本地内存中的一组 Follower 副本集合,在代码中用字段 remoteReplicas 来表征。
ReplicaManager 在处理 FETCH 请求时,会更新 remoteReplicas 中副本对象的 LEO 值。同时,Leader 副本会将自己更新后的 LEO 值与 remoteReplicas 中副本的 LEO 值进行比较,来决定是否“抬高”高水位值。
而 Partition 类中的 makeLeader 方法的一个重要步骤,就是要重设这组远端 Follower 副本对象的 LEO 值。
makeLeaders 方法执行完 Partition.makeLeader 后,如果当前 Broker 成功地成为了该分区的 Leader 副本,就返回 True,表示新 Leader 配置成功,否则,就表示处理失败。倘若成功设置了 Leader,那么,就把该分区加入到已成功设置 Leader 的分区列表中,并返回该列表。
至此,方法结束。我再来小结下,makeLeaders 的作用是令当前 Broker 成为给定分区的 Leader 副本。接下来,我们再看看与 makeLeaders 方法功能相反的 makeFollowers 方法。
5.1.3 makeFollowers 方法
makeFollowers 方法的作用是,将当前 Broker 配置成指定分区的 Follower 副本。我们还是先看下方法签名:
// controllerId:Controller所在Broker的Id
// controllerEpoch:Controller Epoch值
// partitionStates:当前Broker是Follower副本的所有分区的详细信息
// correlationId:连接请求与响应的关联字段
// responseMap:封装LeaderAndIsrRequest请求处理结果的字段
// highWatermarkCheckpoints:操作高水位检查点文件的工具类
private def makeFollowers(controllerId: Int,
controllerEpoch: Int,
partitionStates: Map[Partition, LeaderAndIsrPartitionState],
correlationId: Int,
responseMap: mutable.Map[TopicPartition, Errors],
highWatermarkCheckpoints: OffsetCheckpoints) : Set[Partition] = {
....
}
你看,makeFollowers 方法的参数列表与 makeLeaders 方法,是一模一样的。这里我也就不再展开了。
其中比较重要的字段,就是 partitionStates 和 responseMap。基本上,你可以认为 partitionStates 是 makeFollowers 方法的输入,responseMap 是输出。
因为整个 makeFollowers 方法的代码很长,所以我接下来会先用一张图解释下它的核心逻辑,让你先有个全局观;然后,我再按照功能划分带你学习每一部分的代码。
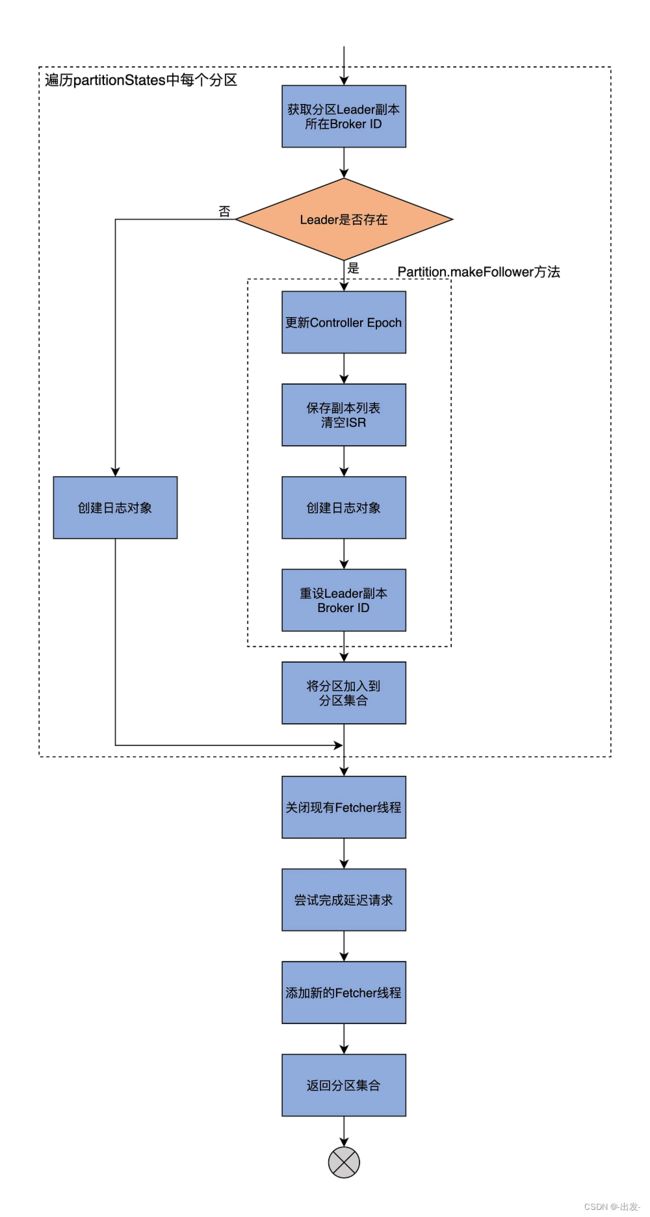
总体来看,makeFollowers 方法分为两大步:
-
第 1 步,遍历 partitionStates 中的所有分区,然后执行“成为 Follower”的操作;
-
第 2 步,执行其他动作,主要包括重建 Fetcher 线程、完成延时请求等。
首先,我们学习第 1 步遍历 partitionStates 所有分区的代码:
// 第一部分:遍历partitionStates所有分区
partitionStates.forKeyValue { (partition, partitionState) =>
......
// 将所有分区的处理结果的状态初始化为Errors.NONE
responseMap.put(partition.topicPartition, Errors.NONE)
}
val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()
try {
// TODO: Delete leaders from LeaderAndIsrRequest
// 遍历partitionStates所有分区
partitionStates.forKeyValue { (partition, partitionState) =>
// 拿到分区的Leader Broker ID
val newLeaderBrokerId = partitionState.leader
try {
// 在元数据缓存中找到Leader Broke对象
metadataCache.getAliveBrokers.find(_.id == newLeaderBrokerId) match {
// Only change partition state when the leader is available
// 如果Leader确实存在
case Some(_) =>
// 执行makeFollower方法,将当前Broker配置成该分区的Follower副本
if (partition.makeFollower(partitionState, highWatermarkCheckpoints))
// 如果配置成功,将该分区加入到结果返回集中
partitionsToMakeFollower += partition
else // 如果失败,打印错误日志
......
// 如果Leader不存在
case None =>
......
// 依然创建出分区Follower副本的日志对象
partition.createLogIfNotExists (isNew = partitionState.isNew, isFutureReplica = false,
highWatermarkCheckpoints)
}
} catch {
case e: KafkaStorageException =>
......
}
}
// 第二部分:执行其他动作
}
在这部分代码中,我们可以把它的执行逻辑划分为两大步骤。
第 1 步,将结果返回集合中所有分区的处理结果状态初始化为 Errors.NONE;第 2 步,遍历 partitionStates 中的所有分区,依次为每个分区执行以下逻辑:
- 从分区的详细信息中获取分区的 Leader Broker ID;
- 拿着上一步获取的 Broker ID,去 Broker 元数据缓存中找到 Leader Broker 对象;
- 如果 Leader 对象存在,则执行 Partition 类的 makeFollower 方法将当前 Broker 配置成该分区的 Follower 副本。如果 makeFollower 方法执行成功,就说明当前 Broker 被成功配置为指定分区的 Follower 副本,那么将该分区加入到结果返回集中。
- 如果 Leader 对象不存在,依然创建出分区 Follower 副本的日志对象。
说到 Partition 的 makeFollower 方法的执行逻辑,主要是包括以下 4 步:
- 更新 Controller Epoch 值;
- 保存副本列表(Assigned Replicas,AR)和清空 ISR;
- 创建日志对象;
- 重设 Leader 副本的 Broker ID。
接下来,我们看下 makeFollowers 方法的第 2 步,执行其他动作的代码:
// 第二部分:执行其他动作
// 移除现有Fetcher线程
replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition))
// 尝试完成延迟请求
partitionsToMakeFollower.foreach { partition =>
completeDelayedFetchOrProduceRequests(partition.topicPartition)
}
if (isShuttingDown.get()) {
......
} else {
// we do not need to check if the leader exists again since this has been done at the beginning of this process
// 为需要将当前Broker设置为Follower副本的分区
// 确定Leader Broker和起始读取位移值fetchOffset
val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map { partition =>
val leader = metadataCache.getAliveBrokers.find(_.id == partition.leaderReplicaIdOpt.get).get
.brokerEndPoint(config.interBrokerListenerName)
val log = partition.localLogOrException
val fetchOffset = initialFetchOffset(log)
partition.topicPartition -> InitialFetchState(leader, partition.getLeaderEpoch, fetchOffset)
}.toMap
// 使用上一步确定的Leader Broker和fetchOffset添加新的Fetcher线程
replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)
}
......
// 返回需要将当前Broker设置为Follower副本的分区列表
partitionsToMakeFollower
你看,这部分代码的任务比较简单,逻辑也都是线性递进的,很好理解。我带你简单地梳理一下。
首先,移除现有 Fetcher 线程。因为 Leader 可能已经更换了,所以要读取的 Broker 以及要读取的位移值都可能随之发生变化。
然后,为需要将当前 Broker 设置为 Follower 副本的分区,确定 Leader Broker 和起始读取位移值 fetchOffset。这些信息都已经在 LeaderAndIsrRequest 中了。
接下来,使用上一步确定的 Leader Broker 和 fetchOffset 添加新的 Fetcher 线程。
最后,返回需要将当前 Broker 设置为 Follower 副本的分区列表。
至此,副本管理器管理分区和副本的主要方法实现,我们就都学完啦。可以看出,这些代码实现的大部分,都是围绕着如何处理 LeaderAndIsrRequest 请求数据展开的。比如,makeLeaders 拿到请求数据后,会为分区设置 Leader 和 ISR;makeFollowers 拿到数据后,会为分区更换 Fetcher 线程以及清空 ISR。
LeaderAndIsrRequest 请求是 Kafka 定义的最重要的控制类请求。搞懂它是如何被处理的,对于你弄明白 Kafka 的副本机制是大有裨益的。
5.2 ISR 管理
除了读写副本、管理分区和副本的功能之外,副本管理器还有一个重要的功能,那就是管理 ISR。这里的管理主要体现在两个方法:
- 一个是 maybeShrinkIsr 方法,作用是阶段性地查看 ISR 中的副本集合是否需要收缩;
- 另一个是 maybePropagateIsrChanges 方法,作用是定期向集群 Broker 传播 ISR 的变更。
首先,我们看下 ISR 的收缩操作。
5.2.1 maybeShrinkIsr
收缩是指,把 ISR 副本集合中那些与 Leader 差距过大的副本移除的过程。所谓的差距过大,就是 ISR 中 Follower 副本滞后 Leader 副本的时间,超过了 Broker 端参数 replica.lag.time.max.ms 值的 1.5 倍。
稍等,为什么是 1.5 倍呢?你可以看下面的代码:
def startup(): Unit = {
// start ISR expiration thread
// A follower can lag behind leader for up to config.replicaLagTimeMaxMs x 1.5 before it is removed from ISR
scheduler.schedule("isr-expiration", maybeShrinkIsr _, period = config.replicaLagTimeMaxMs / 2, unit = TimeUnit.MILLISECONDS)
......
}
我来解释下。ReplicaManager 类的 startup 方法会在被调用时创建一个异步线程,定时查看是否有 ISR 需要进行收缩。这里的定时频率是 replicaLagTimeMaxMs 值的一半,而判断 Follower 副本是否需要被移除 ISR 的条件是,滞后程度是否超过了 replicaLagTimeMaxMs 值。
因此理论上,滞后程度小于 1.5 倍 replicaLagTimeMaxMs 值的 Follower 副本,依然有可能在 ISR 中,不会被移除。这就是数字“1.5”的由来了。
接下来,我们看下 maybeShrinkIsr 方法的源码。
private def maybeShrinkIsr(): Unit = {
trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR")
// Shrink ISRs for non offline partitions
allPartitions.keys.foreach { topicPartition =>
onlinePartition(topicPartition).foreach(_.maybeShrinkIsr())
}
}
可以看出,maybeShrinkIsr 方法会遍历该副本管理器上所有分区对象,依次为这些分区中状态为 Online 的分区,执行 Partition 类的 maybeShrinkIsr 方法。这个方法的源码如下:
def maybeShrinkIsr(): Unit = {
// 判断是否需要执行ISR收缩
val needsIsrUpdate = !isrState.isInflight && inReadLock(leaderIsrUpdateLock) {
needsShrinkIsr()
}
val leaderHWIncremented = needsIsrUpdate && inWriteLock(leaderIsrUpdateLock) {
leaderLogIfLocal.exists { leaderLog => // 如果是Leader副本
// 获取不同步的副本Id列表
val outOfSyncReplicaIds = getOutOfSyncReplicas(replicaLagTimeMaxMs)
// 如果存在不同步的副本Id列表
if (outOfSyncReplicaIds.nonEmpty) {
val outOfSyncReplicaLog = outOfSyncReplicaIds.map { replicaId =>
s"(brokerId: $replicaId, endOffset: ${getReplicaOrException(replicaId).logEndOffset})"
}.mkString(" ")
// 计算收缩之后的ISR列表
val newIsrLog = (isrState.isr -- outOfSyncReplicaIds).mkString(",")
info(s"Shrinking ISR from ${isrState.isr.mkString(",")} to $newIsrLog. " +
s"Leader: (highWatermark: ${leaderLog.highWatermark}, endOffset: ${leaderLog.logEndOffset}). " +
s"Out of sync replicas: $outOfSyncReplicaLog.")
// 更新ZooKeeper中分区的ISR数据以及Broker的元数据缓存中的数据
shrinkIsr(outOfSyncReplicaIds)
// we may need to increment high watermark since ISR could be down to 1
// 尝试更新Leader副本的高水位值
maybeIncrementLeaderHW(leaderLog)
} else {
false
}
// 如果不是Leader副本,什么都不做
}
}
// some delayed operations may be unblocked after HW changed
// 如果Leader副本的高水位值抬升了
if (leaderHWIncremented)
// 尝试解锁一下延迟请求
tryCompleteDelayedRequests()
}
可以看出,maybeShrinkIsr 方法的整个执行流程是:
-
第 1 步,判断是否需要执行 ISR 收缩。主要的方法是,调用 needShrinkIsr 方法来获取与 Leader 不同步的副本。如果存在这样的副本,说明需要执行 ISR 收缩。
-
第 2 步,再次获取与 Leader 不同步的副本列表,并把它们从当前 ISR 中剔除出去,然后计算得出最新的 ISR 列表。
-
第 3 步,调用 shrinkIsr 方法去更新 ZooKeeper 上分区的 ISR 数据以及 Broker 上元数据缓存。
-
第 4 步,尝试更新 Leader 分区的高水位值。这里有必要检查一下是否可以抬升高水位值的原因在于,如果 ISR 收缩后只剩下 Leader 副本一个了,那么高水位值的更新就不再受那么多限制了。
-
第 5 步,根据上一步的结果,来尝试解锁之前不满足条件的延迟操作。
我把这个执行过程,梳理到了一张流程图中:
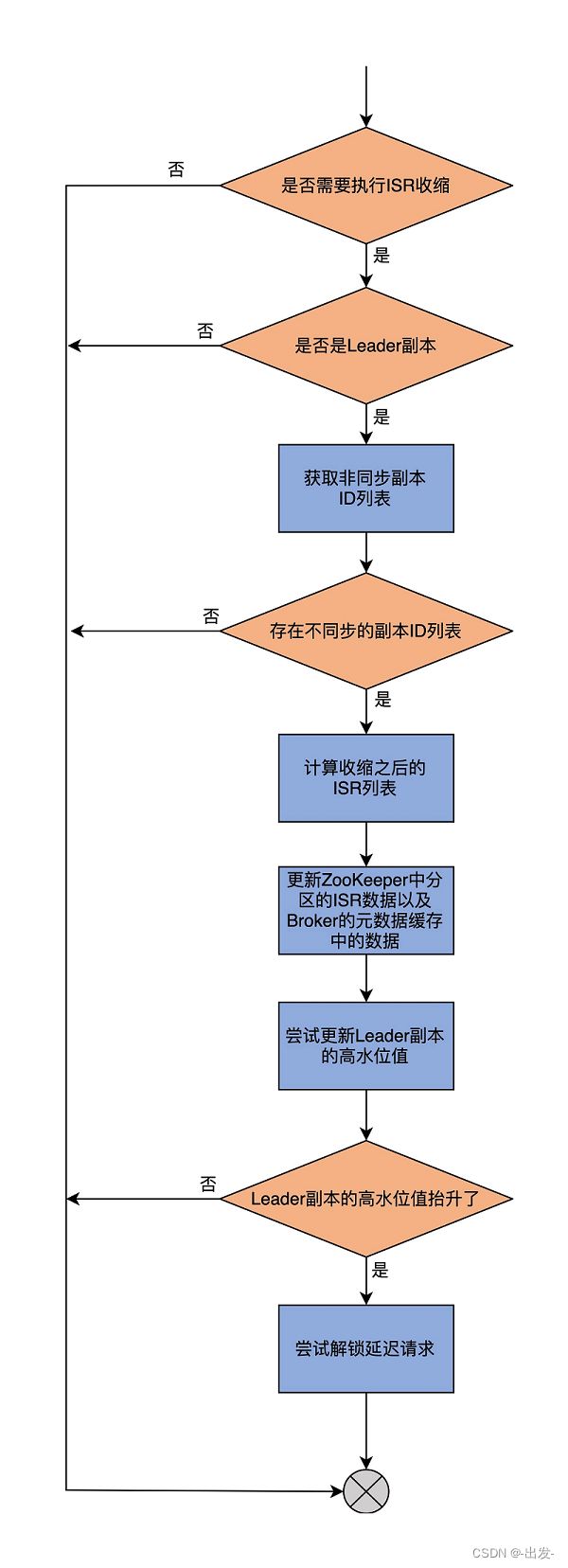
5.2.2 maybePropagateIsrChanges 方法
ISR 收缩之后,ReplicaManager 还需要将这个操作的结果传递给集群的其他 Broker,以同步这个操作的结果。这是由 ISR 通知事件来完成的。
在 ReplicaManager 类中,方法 maybePropagateIsrChanges 专门负责创建 ISR 通知事件。这也是由一个异步线程定期完成的,代码如下:
override def start(): Unit = {
scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges _,
period = isrChangeNotificationConfig.checkIntervalMs, unit = TimeUnit.MILLISECONDS)
}
接下来,我们看下 maybePropagateIsrChanges 方法的代码:
private[server] def maybePropagateIsrChanges(): Unit = {
val now = time.milliseconds()
// ISR变更传播的条件,需要同时满足:
// 1. 存在尚未被传播的ISR变更
// 2. 最近5秒没有任何ISR变更,或者自上次ISR变更已经有超过1分钟的时间
isrChangeSet synchronized {
if (isrChangeSet.nonEmpty &&
(lastIsrChangeMs.get() + isrChangeNotificationConfig.lingerMs < now ||
lastIsrPropagationMs.get() + isrChangeNotificationConfig.maxDelayMs < now)) {
// 创建ZooKeeper相应的Znode节点
zkClient.propagateIsrChanges(isrChangeSet)
// 清空isrChangeSet集合
isrChangeSet.clear()
// 更新最近ISR变更时间戳
lastIsrPropagationMs.set(now)
}
}
}
可以看到,maybePropagateIsrChanges 方法的逻辑也比较简单。我来概括下其执行逻辑。
首先,确定 ISR 变更传播的条件。这里需要同时满足两点:
- 一是, 存在尚未被传播的 ISR 变更;
- 二是, 最近 5 秒没有任何 ISR 变更,或者自上次 ISR 变更已经有超过 1 分钟的时间。
一旦满足了这两个条件,代码会创建 ZooKeeper 相应的 Znode 节点;然后,清空 isrChangeSet 集合;最后,更新最近 ISR 变更时间戳。
5.3 总结
今天,我们重点学习了 ReplicaManager 类的分区和副本管理功能,以及 ISR 管理。我们再完整地梳理下 ReplicaManager 类的核心功能和方法。
- 分区 / 副本管理。ReplicaManager 类的核心功能是,应对 Broker 端接收的 LeaderAndIsrRequest 请求,并将请求中的分区信息抽取出来,让所在 Broker 执行相应的动作。
- becomeLeaderOrFollower 方法。它是应对 LeaderAndIsrRequest 请求的入口方法。它会将请求中的分区划分成两组,分别调用 makeLeaders 和 makeFollowers 方法。
- makeLeaders 方法。它的作用是让 Broker 成为指定分区 Leader 副本。
- makeFollowers 方法。它的作用是让 Broker 成为指定分区 Follower 副本的方法。
- ISR 管理。ReplicaManager 类提供了 ISR 收缩和定期传播 ISR 变更通知的功能。
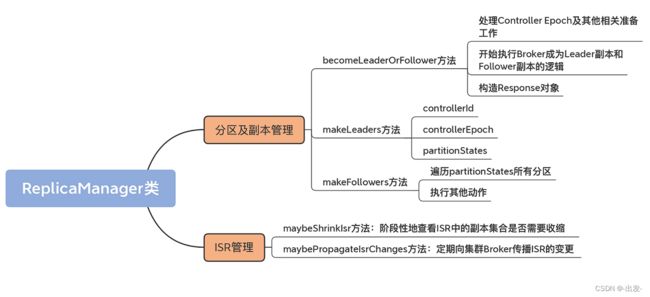
掌握了这些核心知识点,你差不多也就掌握了绝大部分的副本管理器功能,比如说 Broker 如何成为分区的 Leader 副本和 Follower 副本,以及 ISR 是如何被管理的。
你可能也发现了,有些非核心小功能我们今天并没有展开,比如 Broker 上的元数据缓存是怎么回事。下一节课,我将带你深入到这个缓存当中,去看看它到底是什么。
6 MetadataCache:Broker是怎么异步更新元数据缓存的?
今天,我们学习 Broker 上的元数据缓存(MetadataCache)。
你肯定很好奇,前面我们不是学过 Controller 端的元数据缓存了吗?这里的元数据缓存又是啥呢?其实,这里的 MetadataCache 是指 Broker 上的元数据缓存,这些数据是 Controller 通过 UpdateMetadataRequest 请求发送给 Broker 的。换句话说,Controller 实现了一个异步更新机制,能够将最新的集群信息广播给所有 Broker。
那么,为什么每台 Broker 上都要保存这份相同的数据呢?这里有两个原因。
第一个,也是最重要的原因,就是保存了这部分数据,Broker 就能够及时响应客户端发送的元数据请求,也就是处理 Metadata 请求。Metadata 请求是为数不多的能够被集群任意 Broker 处理的请求类型之一,也就是说,客户端程序能够随意地向任何一个 Broker 发送 Metadata 请求,去获取集群的元数据信息,这完全得益于 MetadataCache 的存在。
第二个原因是,Kafka 的一些重要组件会用到这部分数据。比如副本管理器会使用它来获取 Broker 的节点信息,事务管理器会使用它来获取分区 Leader 副本的信息,等等。
总之,MetadataCache 是每台 Broker 上都会保存的数据。Kafka 通过异步更新机制来保证所有 Broker 上的元数据缓存实现最终一致性。
在实际使用的过程中,你可能会碰到这样一种场景:集群明明新创建了主题,但是消费者端却报错说“找不到主题信息”,这种情况通常只持续很短的时间。不知道你是否思考过这里面的原因,其实说白了,很简单,这就是因为元数据是异步同步的,因此,在某一时刻,某些 Broker 尚未更新元数据,它们保存的数据就是过期的元数据,无法识别最新的主题。
等你今天学完了 MetadataCache 类,特别是元数据的更新之后,就会彻底明白这个问题了。下面,我们就来学习下 MetadataCache 的类代码。
6.1 MetadataCache 类
MetadataCache 类位于 server 包下的同名 scala 文件中。
MetadataCache 的实例化是在 Kafka Broker 启动时完成的,具体的调用发生在 KafkaServer 类的 startup 方法中。
// KafkaServer.scala
metadataCache = MetadataCache.zkMetadataCache(config.brokerId)
一旦实例被成功创建,就会被 Kafka 的 4 个组件使用。我来给你解释一下这 4 个组件的名称,以及它们各自使用该实例的主要目的。
- KafkaApis:这是源码入口类。它是执行 Kafka 各类请求逻辑的地方。该类大量使用 MetadataCache 中的主题分区和 Broker 数据,执行主题相关的判断与比较,以及获取 Broker 信息。
- AdminManager:这是 Kafka 定义的专门用于管理主题的管理器,里面定义了很多与主题相关的方法。同 KafkaApis 类似,它会用到 MetadataCache 中的主题信息和 Broker 数据,以获取主题和 Broker 列表。
- ReplicaManager:这是我们刚刚学过的副本管理器。它需要获取主题分区和 Broker 数据,同时还会更新 MetadataCache。
- TransactionCoordinator:这是管理 Kafka 事务的协调者组件,它需要用到 MetadataCache 中的主题分区的 Leader 副本所在的 Broker 数据,向指定 Broker 发送事务标记。
6.1.1 类定义及字段
搞清楚了 MetadataCache 类被创建的时机以及它的调用方,我们就了解了它的典型使用场景,即作为集群元数据集散地,它保存了集群中关于主题和 Broker 的所有重要数据。那么,接下来,我们来看下这些数据到底都是什么。
class ZkMetadataCache(brokerId: Int) extends MetadataCache with Logging {
private val partitionMetadataLock = new ReentrantReadWriteLock()
@volatile private var metadataSnapshot: MetadataSnapshot = MetadataSnapshot(partitionStates = mutable.AnyRefMap.empty,
topicIds = Map.empty, controllerId = None, aliveBrokers = mutable.LongMap.empty, aliveNodes = mutable.LongMap.empty)
this.logIdent = s"[MetadataCache brokerId=$brokerId] "
private val stateChangeLogger = new StateChangeLogger(brokerId, inControllerContext = false, None)
......
}
构造函数只需要一个参数:brokerId,即 Broker 的 ID 序号。除了这个参数,该类还定义了 4 个字段。
partitionMetadataLock 字段是保护它写入的锁对象,logIndent 和 stateChangeLogger 字段仅仅用于日志输出,而 metadataSnapshot 字段保存了实际的元数据信息,它是 MetadataCache 类中最重要的字段,我们要重点关注一下它。
该字段的类型是 MetadataSnapshot 类,该类是 MetadataCache 中定义的一个嵌套类。以下是该嵌套类的源码:
case class MetadataSnapshot(partitionStates: mutable.AnyRefMap[String, mutable.LongMap[UpdateMetadataPartitionState]],
topicIds: Map[String, Uuid],
controllerId: Option[Int],
aliveBrokers: mutable.LongMap[Broker],
aliveNodes: mutable.LongMap[collection.Map[ListenerName, Node]])
从源码可知,它是一个 case 类,相当于 Java 中配齐了 Getter 方法的 POJO 类。同时,它也是一个不可变类(Immutable Class)。正因为它的不可变性,其字段值是不允许修改的,我们只能重新创建一个新的实例,来保存更新后的字段值。
我们看下它的各个字段的含义。
- partitionStates:这是一个 Map 类型。Key 是主题名称,Value 又是一个 Map 类型,其 Key 是分区号,Value 是一个 UpdateMetadataPartitionState 类型的字段。UpdateMetadataPartitionState 类型是 UpdateMetadataRequest 请求内部所需的数据结构。一会儿我们再说这个类型都有哪些数据。
- controllerId:Controller 所在 Broker 的 ID。
- aliveBrokers:当前集群中所有存活着的 Broker 对象列表。
- aliveNodes:这也是一个 Map 的 Map 类型。其 Key 是 Broker ID 序号,Value 是 Map 类型,其 Key 是 ListenerName,即 Broker 监听器类型,而 Value 是 Broker 节点对象。
现在,我们说说 UpdateMetadataPartitionState 类型。这个类型的源码是由 Kafka 工程自动生成的。UpdateMetadataRequest 请求所需的字段用 JSON 格式表示,由 Kafka 的 generator 工程负责为 JSON 格式自动生成对应的 Java 文件,生成的类是一个 POJO 类,其定义如下:
static public class UpdateMetadataPartitionState implements Message {
private String topicName; // 主题名称
private int partitionIndex; // 分区号
private int controllerEpoch; // Controller Epoch值
private int leader; // Leader副本所在Broker ID
private int leaderEpoch; // Leader Epoch值
private List<Integer> isr; // ISR列表
private int zkVersion; // ZooKeeper节点Stat统计信息中的版本号
private List<Integer> replicas; // 副本列表
private List<Integer> offlineReplicas; // 离线副本列表
private List<RawTaggedField> _unknownTaggedFields; // 未知字段列表
......
}
可以看到,UpdateMetadataPartitionState 类的字段信息非常丰富,它包含了一个主题分区非常详尽的数据,从主题名称、分区号、Leader 副本、ISR 列表到 Controller Epoch、ZooKeeper 版本号等信息,一应俱全。从宏观角度来看,Kafka 集群元数据由主题数据和 Broker 数据两部分构成。所以,可以这么说,MetadataCache 中的这个字段撑起了元数据缓存的“一半天空”。
6.1.2 重要方法
接下来,我们学习下 MetadataCache 类的重要方法。你需要记住的是,这个类最重要的方法就是操作 metadataSnapshot 字段的方法,毕竟,所谓的元数据缓存,就是指 MetadataSnapshot 类中承载的东西。我把 MetadataCache 类的方法大致分为三大类:判断类;获取类;更新类。这三大类方法是由浅入深的关系,我们先从简单的判断类方法开始。
我把 MetadataCache 类的方法大致分为三大类:判断类;获取类;更新类。这三大类方法是由浅入深的关系,我们先从简单的判断类方法开始。
6.1.3 判断类方法
所谓的判断类方法,就是判断给定主题或主题分区是否包含在元数据缓存中的方法。MetadataCache 类提供了两个判断类的方法,方法名都是 contains,只是输入参数不同。
// 判断给定主题是否包含在元数据缓存中
def contains(topic: String): Boolean = {
metadataSnapshot.partitionStates.contains(topic)
}
// 判断给定主题分区是否包含在元数据缓存中
def contains(tp: TopicPartition): Boolean = getPartitionInfo(tp.topic, tp.partition).isDefined
// 获取给定主题分区的详细数据信息。如果没有找到对应记录,返回None
def getPartitionInfo(topic: String, partitionId: Int): Option[UpdateMetadataPartitionState] = {
metadataSnapshot.partitionStates.get(topic).flatMap(_.get(partitionId))
}
第一个 contains 方法用于判断给定主题是否包含在元数据缓存中,比较简单,只需要判断 metadataSnapshot 中 partitionStates 的所有 Key 是否包含指定主题就行了。
第二个 contains 方法相对复杂一点。它首先要从 metadataSnapshot 中获取指定主题分区的分区数据信息,然后根据分区数据是否存在,来判断给定主题分区是否包含在元数据缓存中。
判断类的方法实现都很简单,代码也不多,很好理解,我就不多说了。接下来,我们来看获取类方法。
6.1.4 获取类方法
MetadataCache 类的 getXXX 方法非常多,其中,比较有代表性的是 getAllTopics 方法、getAllPartitions 方法和 getPartitionReplicaEndpoints,它们分别是获取主题、分区和副本对象的方法。在我看来,这是最基础的元数据获取方法了,非常值得我们学习。
首先,我们来看入门级的 get 方法,即 getAllTopics 方法。该方法返回当前集群元数据缓存中的所有主题。代码如下:
private def getAllTopics(snapshot: MetadataSnapshot): Set[String] = {
snapshot.partitionStates.keySet
}
它仅仅是返回 MetadataSnapshot 数据类型中 partitionStates 字段的所有 Key 字段。前面说过,partitionStates 是一个 Map 类型,Key 就是主题。怎么样,简单吧?
如果我们要获取元数据缓存中的分区对象,该怎么写呢?来看看 getAllPartitions 方法的实现。
private def getAllPartitions(snapshot: MetadataSnapshot): Map[TopicPartition, UpdateMetadataPartitionState] = {
snapshot.partitionStates.flatMap { case (topic, partitionStates) =>
partitionStates.map { case (partition, state ) => (new TopicPartition(topic, partition.toInt), state) }
}.toMap
}
和 getAllTopics 方法类似,它的主要思想也是遍历 partitionStates,取出分区号后,构建 TopicPartition 实例,并加入到返回集合中返回。
最后,我们看一个相对复杂一点的 get 方法:getPartitionReplicaEndpoints。
def getPartitionReplicaEndpoints(tp: TopicPartition, listenerName: ListenerName): Map[Int, Node] = {
// 使用局部变量获取当前元数据缓存
val snapshot = metadataSnapshot
// 获取给定主题分区的数据
snapshot.partitionStates.get(tp.topic).flatMap(_.get(tp.partition)).map { partitionInfo =>
// 拿到副本Id列表
val replicaIds = partitionInfo.replicas
replicaIds.asScala
.map(replicaId => replicaId.intValue() -> {
// 获取副本所在的Broker Id
snapshot.aliveBrokers.get(replicaId.longValue()) match {
// 根据Broker Id去获取对应的Broker节点对象
case Some(broker) =>
// 根据Broker Id去获取对应的Broker节点对象
broker.getNode(listenerName).getOrElse(Node.noNode())
case None => // 如果找不到节点
Node.noNode()
}}).toMap
.filter(pair => pair match {
case (_, node) => !node.isEmpty
})
}.getOrElse(Map.empty[Int, Node])
}
这个 getPartitionReplicaEndpoints 方法接收主题分区和 ListenerName,以获取指定监听器类型下该主题分区所有副本的 Broker 节点对象,并按照 Broker ID 进行分组。
首先,代码使用局部变量获取当前的元数据缓存。这样做的好处在于,不需要使用锁技术,但是,就像我开头说过的,这里有一个可能的问题是,读到的数据可能是过期的数据。不过,好在 Kafka 能够自行处理过期元数据的问题。当客户端因为拿到过期元数据而向 Broker 发出错误的指令时,Broker 会显式地通知客户端错误原因。客户端接收到错误后,会尝试再次拉取最新的元数据。这个过程能够保证,客户端最终可以取得最新的元数据信息。总体而言,过期元数据的不良影响是存在的,但在实际场景中并不是太严重。
拿到主题分区数据之后,代码会获取副本 ID 列表,接着遍历该列表,依次获取每个副本所在的 Broker ID,再根据这个 Broker ID 去获取对应的 Broker 节点对象。最后,将这些节点对象封装到返回结果中并返回。
6.1.5 更新类方法
下面,我们进入到今天的“重头戏”:Broker 端元数据缓存的更新方法。说它是重头戏,有两个原因:
- 跟前两类方法相比,它的代码实现要复杂得多,因此,我们需要花更多的时间去学习;
- 元数据缓存只有被更新了,才能被读取。从某种程度上说,它是后续所有 getXXX 方法的前提条件。
源码中实现更新的方法只有一个:updateMetadata 方法。该方法的代码比较长,我先画一张流程图,帮助你理解它做了什么事情。

updateMetadata 方法的主要逻辑,就是读取 UpdateMetadataRequest 请求中的分区数据,然后更新本地元数据缓存。接下来,我们详细地学习一下它的实现逻辑。
为了你掌握,我将该方法分成几个部分来讲,首先来看第一部分代码:
def updateMetadata(correlationId: Int, updateMetadataRequest: UpdateMetadataRequest): Seq[TopicPartition] = {
inWriteLock(partitionMetadataLock) {
// 保存存活Broker对象。Key是Broker ID,Value是Broker对象
val aliveBrokers = new mutable.LongMap[Broker](metadataSnapshot.aliveBrokers.size)
// 保存存活节点对象。Key是Broker ID,Value是监听器->节点对象
val aliveNodes = new mutable.LongMap[collection.Map[ListenerName, Node]](metadataSnapshot.aliveNodes.size)
// 从UpdateMetadataRequest中获取Controller所在的Broker ID
// 如果当前没有Controller,赋值为None
val controllerIdOpt = updateMetadataRequest.controllerId match {
case id if id < 0 => None
case id => Some(id)
}
// 遍历UpdateMetadataRequest请求中的所有存活Broker对象
updateMetadataRequest.liveBrokers.forEach { broker =>
val nodes = new java.util.HashMap[ListenerName, Node]
val endPoints = new mutable.ArrayBuffer[EndPoint]
// 遍历它的所有EndPoint类型,也就是为Broker配置的监听器
broker.endpoints.forEach { ep =>
val listenerName = new ListenerName(ep.listener)
endPoints += new EndPoint(ep.host, ep.port, listenerName, SecurityProtocol.forId(ep.securityProtocol))
// 将<监听器,Broker节点对象>对保存起来
nodes.put(listenerName, new Node(broker.id, ep.host, ep.port))
}
// 将Broker加入到存活Broker对象集合
aliveBrokers(broker.id) = Broker(broker.id, endPoints, Option(broker.rack))
// 将Broker节点加入到存活节点对象集合
aliveNodes(broker.id) = nodes.asScala
}
......
}
}
这部分代码的主要作用是给后面的操作准备数据,即 aliveBrokers 和 aliveNodes 两个字段中保存的数据。
因此,首先,代码会创建这两个字段,分别保存存活 Broker 对象和存活节点对象。aliveBrokers 的 Key 类型是 Broker ID,而 Value 类型是 Broker 对象;aliveNodes 的 Key 类型也是 Broker ID,Value 类型是 < 监听器,节点对象 > 对。
然后,该方法从 UpdateMetadataRequest 中获取 Controller 所在的 Broker ID,并赋值给 controllerIdOpt 字段。如果集群没有 Controller,则赋值该字段为 None。
接着,代码会遍历 UpdateMetadataRequest 请求中的所有存活 Broker 对象。取出它配置的所有 EndPoint 类型,也就是 Broker 配置的所有监听器。
最后,代码会遍历它配置的监听器,并将 < 监听器,Broker 节点对象 > 对保存起来,再将 Broker 加入到存活 Broker 对象集合和存活节点对象集合。至此,第一部分代码逻辑完成。
再来看第二部分的代码。这一部分的主要工作是确保集群 Broker 配置了相同的监听器,同时初始化已删除分区数组对象,等待下一部分代码逻辑对它进行操作。代码如下:
// 使用上一部分中的存活Broker节点对象
// 获取当前Broker所有的<监听器,节点>对
aliveNodes.get(brokerId).foreach { listenerMap =>
val listeners = listenerMap.keySet
// 如果发现当前Broker配置的监听器与其他Broker有不同之处,记录错误日志
if (!aliveNodes.values.forall(_.keySet == listeners))
error(s"Listeners are not identical across brokers: $aliveNodes")
}
val newTopicIds = updateMetadataRequest.topicStates().asScala
.map(topicState => (topicState.topicName(), topicState.topicId()))
.filter(_._2 != Uuid.ZERO_UUID).toMap
val topicIds = mutable.Map.empty[String, Uuid]
topicIds ++= metadataSnapshot.topicIds
topicIds ++= newTopicIds
// 构造已删除分区数组,将其作为方法返回结果
val deletedPartitions = new mutable.ArrayBuffer[TopicPartition]
// UpdateMetadataRequest请求没有携带任何分区信息
if (!updateMetadataRequest.partitionStates.iterator.hasNext) {
// 构造新的MetadataSnapshot对象,使用之前的分区信息和新的Broker列表信息
metadataSnapshot = MetadataSnapshot(metadataSnapshot.partitionStates, topicIds.toMap, controllerIdOpt, aliveBrokers, aliveNodes)
} else {
......
}
这部分代码首先使用上一部分中的存活 Broker 节点对象,获取当前 Broker 所有的 < 监听器, 节点 > 对。
之后,拿到为当前 Broker 配置的所有监听器。如果发现配置的监听器与其他 Broker 有不同之处,则记录一条错误日志。
接下来,代码会构造一个已删除分区数组,将其作为方法返回结果。然后判断 UpdateMetadataRequest 请求是否携带了任何分区信息,如果没有,则构造一个新的 MetadataSnapshot 对象,使用之前的分区信息和新的 Broker 列表信息;如果有,代码进入到该方法的最后一个部分。
最后一部分全部位于上面代码中的 else 分支上。这部分的主要工作是提取 UpdateMetadataRequest 请求中的数据,然后填充元数据缓存。代码如下:
if (!updateMetadataRequest.partitionStates.iterator.hasNext) {
// 构造新的MetadataSnapshot对象,使用之前的分区信息和新的Broker列表信息
metadataSnapshot = MetadataSnapshot(metadataSnapshot.partitionStates, topicIds.toMap, controllerIdOpt, aliveBrokers, aliveNodes)
} else {
// 否则,进入到方法最后一部分
//since kafka may do partial metadata updates, we start by copying the previous state
// 备份现有元数据缓存中的分区数据
val partitionStates = new mutable.AnyRefMap[String, mutable.LongMap[UpdateMetadataPartitionState]](metadataSnapshot.partitionStates.size)
metadataSnapshot.partitionStates.forKeyValue { (topic, oldPartitionStates) =>
val copy = new mutable.LongMap[UpdateMetadataPartitionState](oldPartitionStates.size)
copy ++= oldPartitionStates
partitionStates(topic) = copy
}
val traceEnabled = stateChangeLogger.isTraceEnabled
val controllerId = updateMetadataRequest.controllerId
val controllerEpoch = updateMetadataRequest.controllerEpoch
// 获取UpdateMetadataRequest请求中携带的所有分区数据
val newStates = updateMetadataRequest.partitionStates.asScala
// 遍历分区数据
newStates.foreach { state =>
// per-partition logging here can be very expensive due going through all partitions in the cluster
val tp = new TopicPartition(state.topicName, state.partitionIndex)
// 如果分区处于被删除过程中
if (state.leader == LeaderAndIsr.LeaderDuringDelete) {
// 将分区从元数据缓存中移除
removePartitionInfo(partitionStates, topicIds, tp.topic, tp.partition)
if (traceEnabled)
stateChangeLogger.trace(s"Deleted partition $tp from metadata cache in response to UpdateMetadata " +
s"request sent by controller $controllerId epoch $controllerEpoch with correlation id $correlationId")
// 将分区加入到返回结果数据
deletedPartitions += tp
} else {
// 将分区加入到元数据缓存
addOrUpdatePartitionInfo(partitionStates, tp.topic, tp.partition, state)
if (traceEnabled)
stateChangeLogger.trace(s"Cached leader info $state for partition $tp in response to " +
s"UpdateMetadata request sent by controller $controllerId epoch $controllerEpoch with correlation id $correlationId")
}
}
val cachedPartitionsCount = newStates.size - deletedPartitions.size
stateChangeLogger.info(s"Add $cachedPartitionsCount partitions and deleted ${deletedPartitions.size} partitions from metadata cache " +
s"in response to UpdateMetadata request sent by controller $controllerId epoch $controllerEpoch with correlation id $correlationId")
// 使用更新过的分区元数据,和第一部分计算的存活Broker列表及节点列表,构建最新的元数据缓存
metadataSnapshot = MetadataSnapshot(partitionStates, topicIds.toMap, controllerIdOpt, aliveBrokers, aliveNodes)
}
// 返回已删除分区列表数组
deletedPartitions
首先,该方法会备份现有元数据缓存中的分区数据到 partitionStates 的局部变量中。
之后,获取 UpdateMetadataRequest 请求中携带的所有分区数据,并遍历每个分区数据。如果发现分区处于被删除的过程中,就将分区从元数据缓存中移除,并把分区加入到已删除分区数组中。否则的话,代码就将分区加入到元数据缓存中。
最后,方法使用更新过的分区元数据,和第一部分计算的存活 Broker 列表及节点列表,构建最新的元数据缓存,然后返回已删除分区列表数组。至此,updateMetadata 方法结束。
6.2 总结
今天,我们学习了 Broker 端的 MetadataCache 类,即所谓的元数据缓存类。该类保存了当前集群上的主题分区详细数据和 Broker 数据。每台 Broker 都维护了一个 MetadataCache 实例。Controller 通过给 Broker 发送 UpdateMetadataRequest 请求的方式,来异步更新这部分缓存数据。
我们来回顾下这节课的重点。
- MetadataCache 类:Broker 元数据缓存类,保存了分区详细数据和 Broker 节点数据。
- 四大调用方:分别是 ReplicaManager、KafkaApis、TransactionCoordinator 和 AdminManager。
- updateMetadata 方法:Controller 给 Broker 发送 UpdateMetadataRequest 请求时,触发更新。
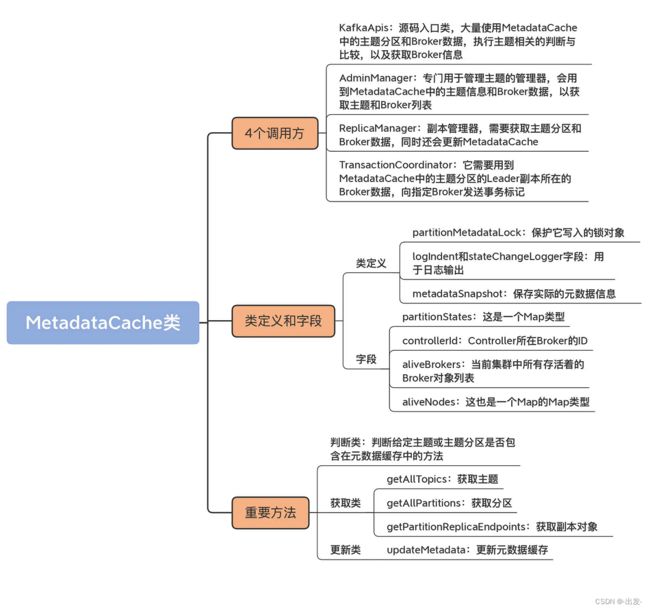
最后,我想和你讨论一个话题。
有人认为,Kafka Broker 是无状态的。学完了今天的内容,现在你应该知道了,Broker 并非是无状态的节点,它需要从 Controller 端异步更新保存集群的元数据信息。由于 Kafka 采用的是 Leader/Follower 模式,跟多 Leader 架构和无 Leader 架构相比,这种分布式架构的一致性是最容易保证的,因此,Broker 间元数据的最终一致性是有保证的。不过,就像我前面说过的,你需要处理 Follower 滞后或数据过期的问题。需要注意的是,这里的 Leader 其实是指 Controller,而 Follower 是指普通的 Broker 节点。
总之,这一路学到现在,不知道你有没有这样的感受,很多分布式架构设计的问题与方案是相通的。比如,在应对数据备份这个问题上,元数据缓存和 Kafka 副本其实都是相同的设计思路,即使用单 Leader 的架构,令 Leader 对外提供服务,Follower 只是被动地同步 Leader 上的数据。