Hive 数据表操作
文章目录
- 1. 数据类型
- 2. 表操作
-
-
- 2.1 表的创建
- 2.2 删除表
-
- 3. 内部表和外部表
-
- 3.1 内部表和外部表的区别
-
- 3.1.1 内部表
- 3.1.2 外部表
- 3.2 创建内部表
- 3.3 创建外部表
- 3.4 内外部表转换
- 4. 数据加载和导出
-
- 4.1 数据加载
-
- 4.1.1 `LOAD关键字`加载数据
- 4.1.2 `INSERT SELECT` 加载数据
- 4.1.3 数加载的选择
- 4.2 数据导出
-
- 4.2.1 `insert overwrite`
- 4.2.2 `hive shell`
- 5. 复杂类型数据使用
-
- 5.1 array类型
- 5.2 map类型
- 5.3 struct类型
- 6. 分区表
-
- 6.1 分区表概述
- 6.2 分区表创建相关语法
- 7. 分桶表
-
- 7.1 分桶表概述
- 7.2 分桶表的创建
- 7.3 分桶表数据的加载
- 8. 修改表
-
- 8.1 修改表相关语句
1. 数据类型
Hive中支持的数据类型如下:

Hive中支持的数据类型比较多,其中红色是使用比较多的类型。
2. 表操作
2.1 表的创建
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)]
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
创建表关键字解释:
EXTERNAL:创建外部表
PARTITIONED BY:分区表
CLUSTERED BY:分桶表
STORED AS:存储格式
LOCATION:存储位置
…
-- 简单表创建类似mysql中创建表:
CREATE TABLE test(
id INT,
name STRING,
gender STRING
);
2.2 删除表
DROP TABLE table_name;
3. 内部表和外部表
3.1 内部表和外部表的区别

3.1.1 内部表
未被external关键字修饰的即是内部表, 即普通表。 内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据(metadata)及存储数据,因此内部表不适合和其他工具共享数据。
3.1.2 外部表
被external关键字修饰的即是外部表。外部表是指表数据可以在任何位置,通过LOCATION关键字指定。 数据存储的不同也代表了这个表在理念是并不是Hive内部管理的,而是可以随意临时链接到外部数据上的。所以,在删除外部表的时候, 仅仅是删除元数据(表的信息),不会删除数据本身。
3.2 创建内部表
基础表创建:
-- 创建一个基础的内部表
create table if not exists stu(id int,name string);
创建表,默认的数据分隔符是\001,是一种特殊字符,是ASCII值,键盘是打不出来的,且在某些文本编辑器中的显示是为SOH。
指定分隔符
-- 自行指定分隔符 '\t'
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t';
row format delimited fields terminated by '\t':表示以\t分隔
其他创建表形式:
-- 1. 基于查询结果建表,CREATE TABLE table_name as
create table stu3 as select * from stu2;
-- 2. 基于已存在的表结构建表,CREATE TABLE table_name like
create table stu4 like stu2;
-- 查看表类型和详情
DESC FORMATTED stu2;
删除内部表:
DROP TABLE table_name:删除表
删除内部表,表信息以及表数据全部都被删除
3.3 创建外部表
外部表,创建表被EXTERNAL关键字修饰,从概念是被认为并非Hive拥有的表,只是临时关联数据去使用。创建外部表也很简单,基于外部表的特性,可以总结出: 外部表 和 数据 是相互独立的。
- 可以先有表,然后把数据移动到表指定的
LOCATION中 - 也可以先有数据,然后创建表通过
LOCATION指向数据
先创建外部表,然后移动数据到location目录:
-- 1. 首先创建文件 test_external.txt,并添加如下内容
1 hadoop
2 spark
3 hive
-- 2. 创建外部表:
create external table test_ext1(id int, name string) row format delimited fields terminated by ‘\t’ location ‘/tmp/test_ext1’;
-- 3. 可以看到,目录/tmp/test_ext1被创建
select * from test_ext1,空结果,无数据
-- 4. 上传数据:
hadoop fs -put test_external.txt /tmp/test_ext1/
-- 5. 查看数据
select * from test_ext1
先存在数据,后创建外部表:
-- 1. hdfs上创建目录
hadoop fs -mkdir /tmp/test_ext2
-- 2. 上传文件到hdfs指定目录下
hadoop fs -put test_external.txt /tmp/test_ext2/
-- 3. 创建外部表,指定数据地址
create external table test_ext2(id int, name string) row format delimited fields terminated by ‘\t’ location ‘/tmp/test_ext2’;
-- 4. 查询数据
select * from test_ext2;
删除外部表:
drop table test_ext1;
drop table test_ext2;
外部表删除后,表的元数据信息不存在了,但是hdfs上的数据文件依旧存在
3.4 内外部表转换
-- 内部表转外部表
alter table stu set tblproperties('EXTERNAL'='TRUE');
-- 外部表转内部表
alter table stu set tblproperties('EXTERNAL'='FALSE');
可以通过desc formatted stu;语句查看表类型

4. 数据加载和导出
4.1 数据加载
4.1.1 LOAD关键字加载数据
使用load语法将外部数据加载到hive内
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename;
LOAD:加载数据关键字[LOCAL]:数据是否在本地,如果使用了local关键字,数据不在HDFS,需要使用file://协议指定路径;不使用local关键字,数据在HDFS,可以使用hdfs://协议指定路径[OVERWRITE]:是否覆盖已经存在的数据,使用overwrite进行覆盖,不使用``overwrite则不覆盖
-- 加载本地数据到hive表中
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load;
-- 加载hdfs中的数据到表中
load data inpath '/tmp/search_log.txt' overwrite into table myhive.test_load;
注意:基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)
4.1.2 INSERT SELECT 加载数据
通过SQL语句查询的方式,将查询语句的结果插入到其他表中,被SELECT查询的表可以是内部表或者外部表
INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
INSERT INTO TABLE tbl1 SELECT * FROM tbl2;
-- 覆盖加载
INSERT OVERWRITE TABLE tbl1 SELECT * FROM tbl2;
4.1.3 数加载的选择
- 数据在本地:推荐使用
load data local - 数据在HDFS:如果不保留原始文件,推荐使用
LOAD方式加载;如果保留原始文件,推荐使用外部表先关联数据,然后通过INSERT SELECT外部表的形式加载数据 - 数据已经在表中:只可以使用
INSERT SELECT
4.2 数据导出
4.2.1 insert overwrite
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysql等
insert overwrite [local] directory ‘path’ select_statement1 FROM from_statement;
-- 将查询的结果导出到本地 - 使用默认列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;
-- 将查询的结果导出到本地 - 指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;
-- 将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;
4.2.2 hive shell
-- 执行SQL语句的方式导出
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt
-- 执行SQL脚本的方式导出
bin/hive -f export.sql > /home/hadoop/export4/export4.txt
5. 复杂类型数据使用
5.1 array类型
建表语句
create table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ',';
row format delimited fields terminated by '\t':表示列分隔符是\tCOLLECTION ITEMS TERMINATED BY ',':表示集合(array)元素的分隔符是逗号
查询相关
-- 1. 查询所有数据
select * from myhive.test_array;
-- 2. 查询loction数组中第一个元素
select name, work_locations[0] location from myhive.test_array;
-- 3. 查询location数组中元素的个数
select name, size(work_locations) location from myhive.test_array;
-- 4. 查询location数组中包含tianjin的信息
select * from myhive.test_array where array_contains(work_locations,'tianjin');
5.2 map类型
map类型其实就是简单的指代:Key-Value型数据格式。 有如下数据文件,其中members字段是key-value型数据
字段与字段分隔符: “,”;需要map字段之间的分隔符:"#";map内部k-v分隔符:":"
id,name,members,age
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
建表语句
-- MAP KEYS TERMINATED BY ':' 表示key-value之间用:分隔;COLLECTION ITEMS TERMINATED BY '#'表示map类型数据之间的数据用#分割
create table myhive.test_map(
id int, name string, members map<string,string>, age int
)
row format delimited
fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';
常用查询
# 1. 查询全部
select * from myhive.test_map;
# 2. 查询father、mother这两个map的key
select id, name, members['father'] father, members['mother'] mother, age from myhive.test_map;
# 3. 查询全部map的key,使用map_keys函数,结果是array类型
select id, name, map_keys(members) as relation from myhive.test_map;
# 4. 查询全部map的value,使用map_values函数,结果是array类型
select id, name, map_values(members) as relation from myhive.test_map;
# 5. 查询map类型的KV对数量
select id,name,size(members) num from myhive.test_map;
# 6. 查询map的key中有brother的数据
select * from myhive.test_map where array_contains(map_keys(members), 'brother');
5.3 struct类型
struct类型是一个复合类型,可以在一个列中存入多个子列,每个子列允许设置类型和名称
-- 字段之间用#分割,struct之间冒号分割
1#周杰轮:11
2#林均杰:16
3#刘德滑:21
4#张学油:26
5#蔡依临:23
建表语句
create table myhive.test_struct(
id string, info struct<name:string, age:int>
)
row format delimited
fields terminated by '#'
COLLECTION ITEMS TERMINATED BY ':';
常用查询
-- 直接使用列名.子列名 即可从struct中取出子列查询
select ip, info.name from hive_struct;
6. 分区表
6.1 分区表概述
在Hive中,我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小文件,这样操作小文件速度就会快很多而且更加容易
如下图student表,按照月份进行分区(单分区表),每个分区就是一个文件夹
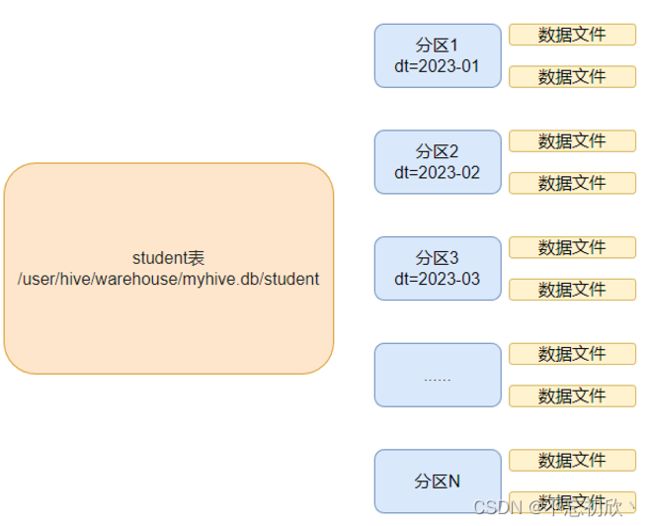
同时Hive也支持多个字段分区,多分区带有层级关系,如下图:

6.2 分区表创建相关语法
语法如下:
create table tablename(...) partitioned by (分区列 列类型, ......)
row format delimited fields terminated by '';
相关示例如下:
-- 1. 创建普通分区表
create table score(id string, score int) partitioned by (month string) row format delimited fields terminated by '';
-- 1.1 加载数据到普通分区表中
load data local inpath 'score.txt' into table score partition(month='202304')
-- 2. 创建一个表带有多个分区
create table score(id string, score int) partitioned by (year string, month string, day string) row format delimited fields terminated by '';
-- 2.1 加载数据到一个多分区的表中
load data local inpath 'score.txt' into table score partition(year='2023', month='04', day='01')
-- 3. 查看分区
show partitions score;
-- 4. 添加一个分区
alter table score add partition(month='202305');
-- 5. 同时添加多个分区,添加分区后可以在hdfs文件系统中看到表下面多了文件夹
alter table score add partition(month='202304') partition(month='202305')
-- 6. 删除分区
alter table score drop partition(month='202306')
7. 分桶表
7.1 分桶表概述
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式。但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储

7.2 分桶表的创建
-- 1. 开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
set hive.enforce.bucketing=true;
-- 2. 通过 clustered by指定分桶字段,into num buckets指定分桶数量
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
7.3 分桶表数据的加载
分桶表的数据加载通过load data无法执行,只能通过insert select
- 创建一个临时表(外部表或内部表),可以通过load data 加载数据进入表
- 然后通过
insert select从临时表向分桶表中插入数据
-- 1. 创建临时表
create table course(id string, name string) row format delimited fields terminated by '\t';
-- 2. 向普通表中加载数据
load data local inpath 'course.txt' into table course;
-- 3. 通过 insert overwrite select给分桶表加载数据
insert overwrite table course select * from course cluster by(id);
为什么分桶表加载数据不可以使用load data,只能使用insert select插入数据?
一旦有了分桶设置,比如分桶数量为3,那么,表内文件或分区内数据文件的数量就限定为3,当数据插入的时候,需要一分为3,进入三个桶文件内。那么如何将数据分成三份,划分的规则是什么?数据的三份划分基于分桶列的值进行hash取模来决定。由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已,所以无法用于分桶表数据插入。因此必须使用insert select的语法,因为会触发MapReduce,进行hash取模计算。
分桶表的性能提升:
- 分区表的性能提升:在指定分区列的前提下,减少被操作的数据量,从而提升性能
- 分桶表的性能提升:基于分桶列的特定操作,如:过滤、JOIN、分组,均可带来性能提升。
同样的数据被Hash加密后的结果是一致的,如hadoop hash取模结果是1,无论计算多少次,字符串hadoop的取模结果都是1。因此同样key(分桶列的值)的数据,会在同一个桶中。
8. 修改表
8.1 修改表相关语句
表的重命名
语法:alter table old_table_name rename to new_table_name;
alter table score rename to score5;
修改表属性值
语法:ALTER TABLE table_name SET TBLPROPERTIES table_properties;
-- 修改内外部表属性
ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL"="TRUE");
-- 修改表注释
如:ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment);
更多属性修改:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties
添加分区
ALTER TABLE tablename ADD PARTITION (month='201101');
新分区是空的没数据,需要手动添加或上传数据文件
修改分区值
ALTER TABLE tablename PARTITION (month='202304') RENAME TO PARTITION (month='202305');
删除分区
ALTER TABLE tablename DROP PARTITION (month='202304');
添加列
ALTER TABLE table_name ADD COLUMNS (v1 int, v2 string);
修改列名
ALTER TABLE test_change CHANGE v1 v1new INT;
删除表
DROP TABLE tablename;
清空表
-- 只能清空内部表
TRUNCATE TABLE tablename;