ClickHouse集群模式总结
目录
背景
一、ClickHouse集群模式分类
1、MergeTree + Distributed+单副本
1.1架构说明
1.2优缺点
2、 MergeTree + Distributed+多副本
2.1架构说明
2.2 优缺点
3、MergeTree + Distributed+集群复制
3.1架构说明
3.2优缺点
4、ReplicatedMergeTree + Distributed
4.1架构说明
4.2优缺点
5、架构总结
背景
针对公司项目中的ClickHouse集群部署模式的使用总结。
一、ClickHouse集群模式分类
当前基于ClickHouse的特性,目前部署CK(ClickHouse,后续都简称为CK)集群时,主要有以下4种集群架构:
1、MergeTree + Distributed+单副本
架构如图
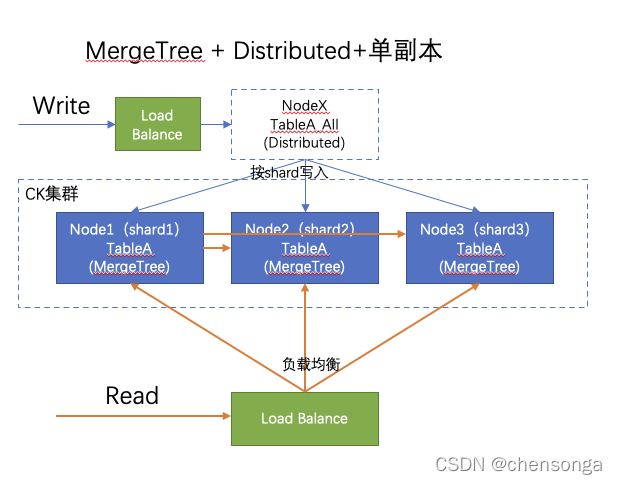
1.1架构说明
写:数据写入集群任意节点的Distributed表,由CK按照随机的方式,将每次写入的数据随机写入某一个shard中;
读:一般都是通过nginx或其他Load Balance插件进行负载均衡,查询某一个节点的分布式表;由CK集群内部调用其他的Node节点,进行分布式并行查询,查询性能高!
1.2优缺点
优点:不需要做数据冗余,写入性能最高且磁盘空间使用相对较少(无副本);查询时能有效利用整体集群计算能力,相对查询数据较快;
缺点:有致命的缺陷,没有数据备份;当一台节点下线后,将导致整个集群处于不可用状态;一般不推荐使用;
总结:整体读写性能都非常好,但是存在数据丢失的较大风险,慎用!
2、 MergeTree + Distributed+多副本
MergeTree+Distribute+多副本架构是在单副本架构基础上衍生而来,主要解决了1中带来的数据无备份、不安全问题
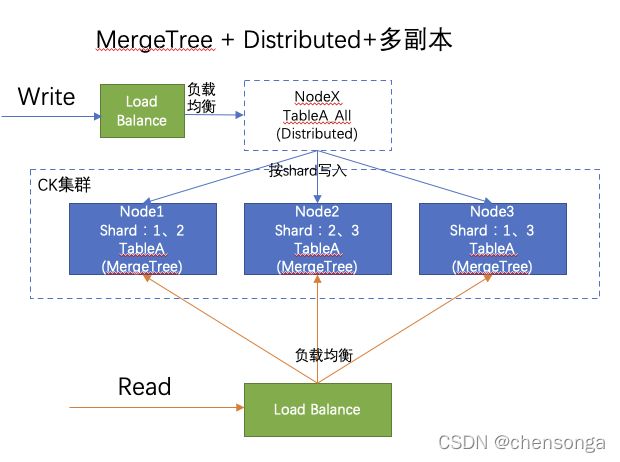
2.1架构说明
写:数据写入集群任意节点的Distributed表,有CK按照随机的方式对各个节点写入至少2个shard数据;如架构图,数据一共有2份,每台节点理论上保存了2/3;
读:查询某一个节点的分布式表;由CK集群内部调用其他的Node节点,进行分布式并行查询,查询性能较高;
2.2 优缺点
优点:数据有了副本机制,数据是安全的;读写查询效率较高;任一一台节点下线,整个集群还是正常使用;
缺点:如需要替换其中一台机器,由于没有数据同步机制,将导致该节点缺少历史数据,导致查询时数据可能不完整。
3、MergeTree + Distributed+节点复制
架构如图
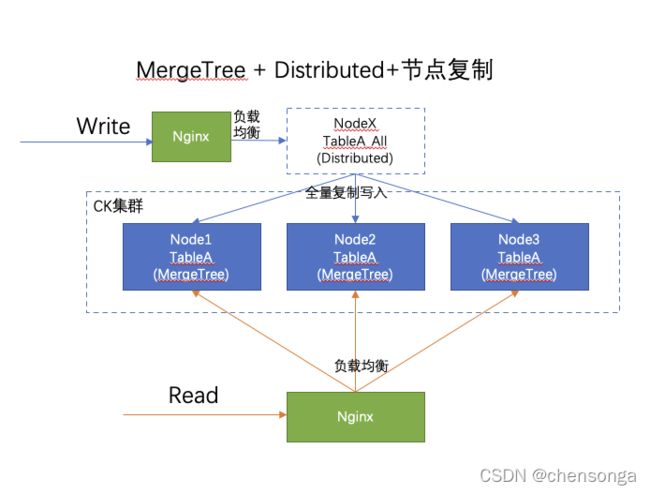
3.1架构说明
写:数据写入集群中任意节点中的Distribute表,有CK负责将全量数据写入各个节点中。
读:由于相同的MergeTree表在各个节点数据都是一致的,查询性能也不错,并发查询性能和分布式集群模式差距可以忽略;
3.2优缺点
优点:数据有多个全量副本,数据丢失风险非常小;整体查询性能不弱;
缺点:写入性能较差;单查询时没有充分利用分布式集群性能优势,不适合做较大规模以上的集群;当单个节点数据写入出现问题,将导致集群数据不一致;
4、ReplicatedMergeTree + Distributed
架构如图
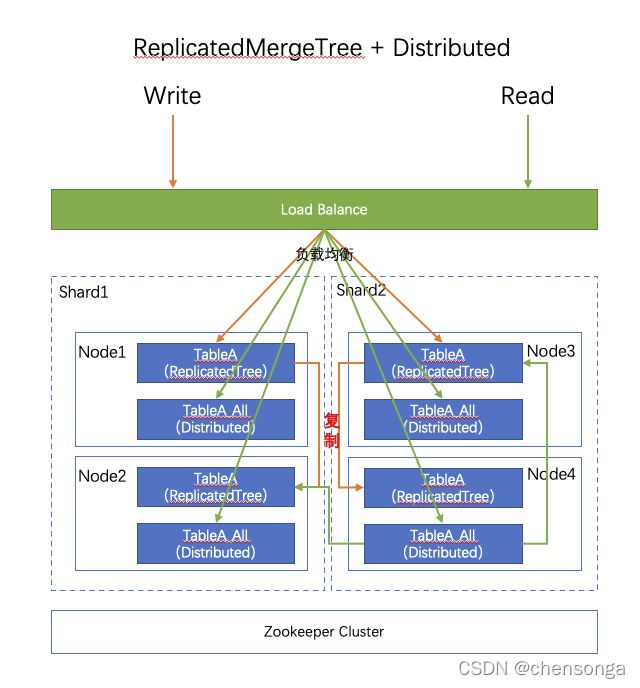
4.1架构说明
写:数据通过LB(可自己实现负载均衡策略)直接写入ReplicatedMergeTree表,由CK通过Zookeeper保障写入对应的副本中;
读:查询对应的Distribute表,有CK路由至各个节点shard下的某一个副本,进行分布式查询,整体查询性能较高,且相同shard CK会进行负载查询各个副本,能有效的利用集群资源;单个查询能力较强(有 1/副本 的集群资源参与单次查询),并发查询能力较强;
4.2优缺点
优点:数据有副本机制,能保障数据安全;单节点下线后不影响整体集群功能;查询和写入性能都较高;
5、架构总结
经历以上部署架构之后,将当前部署的架构整理如下,在ReplicatedMergeTree+Distributed的集群模式下,引入了chproxy组件。
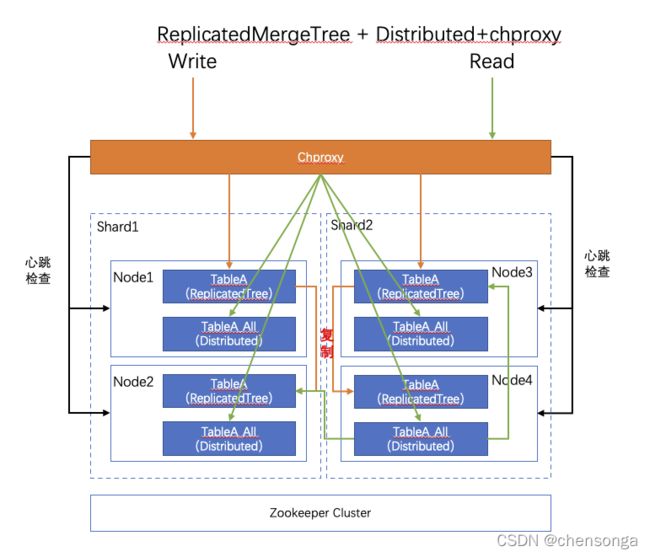
优点:
1、chproxy会定期发送心跳检测CK节点,自动判断节点是否进行路由分发,节点掉线和上线chproxy可以自动检测到,无需维护;
2、负载均衡策略chproxy内置多种常用的策略,满足需求;
3、chproxy可以实现用户管理和限流管理,减少了客户端的开发成本,对接CK转变到对接chproxy无需做客户端的代码调整;
4、继承了ReplicatedMergeTree+Distributed 集群模式的全部优点;