ctf 逆向 回顾与总结
APK的另外讨论。
文章目录
- 基本功
-
- 内存
- 编译过程
- 反汇编
- IDA
- PE和ELF
- 段、块表、PE文件结构
- 程序入口
- 位置无关代码
- got和plt
- 动态分析
- 符号执行
- 插桩
- 值得留意的汇编指令
- 逆向中的SEH
- 壳
- 漏洞的生命周期
- 调用约定和返回值
- call analysis failed
- 栈帧,函数原语和sp analysis failed
- SHT table size or offset is invalid
- 如何找main函数
- 库函数识别
- 保护与混淆
- windows的一些碎片知识
- windows钩子
- Debugbreak()
- virtualProtect和mprotect
- 函数名修饰与UnDecorateSymbolName
-
- 协议分析
- 工具使用
-
- IDA使用
- IDA伪码复制出来的注意事项
- z3_solver解约束
- 第一个断点下在哪
- dnSpy
- x64dbg的三种断点
- x64dbg堆栈平衡法UPX/nspack/aspack脱壳
- OD
-
- SFX自动脱壳
- API调用查看
- 黑话
- run trace和hit trace
- 直接修改EIP
- dll/so的脱壳与动态调试
- ida远程调试elf
- GDB
- .net
- 解题
-
- 解题流程
- 隐藏提示性字符串的手法总结
- 特殊用户交互手法总结
- c++解题心得
- .net解题心得
- python pyc字节码补充说明
- 题目所给可执行文件无法运行
- 自加密/自修改
- 脱壳实践
- angr与控制流混淆的总结
- go总结
- 类型总结
- 感悟
- 爆破法
- 哈希算法的windows api
- 常用ascii
- mips逆向
- 固件逆向
- 文件对比
- 无能狂怒
- ida插件总结
基本功
内存
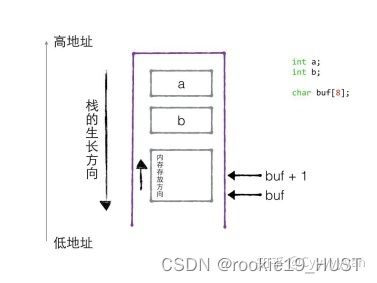
编译过程
- 编译,高级语言(.c)转汇编语言(.s)。注释信息丢失。
- 汇编,汇编语言(.s)转机器码(.o)。label信息(指令的起始位置)丢失。
- 链接,多个机器码(.o)合成一个有入口的可执行程序。函数名和变量类型信息丢失。
反汇编易,反编译难(因编译优化)。
反汇编
可能将数据识别为代码,或者将代码识别为数据。难点是判断函数入口。
除了线性扫描和递归下降,还有超集二进制代码重写反汇编(multiverse)(capstone中已实现),和基于概率的反汇编算法(David Brumley的BAP已实现)。
IDA
有庞大的函数签名库,通过FLIRT算法,识别函数首尾的字节特征,将机器码翻译成静态库函数的调用,这意味着丢失的函数名信息被找回来了一部分。(动态库函数直接看PE的导入表就能知道)。所以拿着7.0版本的,可以手动导入一下新的函数签名(操作步骤可参考《加密与解密》3.3)。7.0版本的另一个问题是无法本地调试32位。
PE和ELF
| PE | ELF |
|---|---|
| .exe | elf可执行文件 |
| .dll | .so |
| .lib | .a |
它们的结构都是类似的,我认为区别只在后续链接。so文件在链接时指定入口的话也可以执行。
具体怎么分节的,可以在用工具编辑的过程中熟悉。
在运行时,可执行文件的各节会映射到内存段。段有权限,越权会导致段错误。

共享库和动态库是一个意思。
段、块表、PE文件结构
.idata,存放外部函数地址。
.rodata,只读数据。
.rdata,资源数据段。
.data,全局变量。
静态变量static和全局变量extern存储位置是一样的,不过他们的作用范围不同,前者更小,限于文件。后者跨文件。
块表的一个例子如下图。voffset和vsize是内存映射时的,roffset和rsize是未加载文件时的。两者的区别,加载时各节之间会给一些空隙,以对齐内存。这就导致换算不那么直观,有时需要依靠动态调试时的偏移量来计算文件偏移。关系如下:
相对内存偏移(RVA) = 内存地址 - 加载基址
节偏移 = Voffset(该节在内存中的偏移量) - Roffset(该节在文件中的偏移量)
文件偏移 = 相对内存偏移(RVA) - 节偏移

下图可以帮助理解两种偏移,以及回顾PE文件结构。

PE文件头中几个重要的量:
- entrypoint,也就是oep,程序入口
- imagebase,加载基址
- sizeofimage,内存映像大小
- baseofcode,代码段rva
- baseofdata,数据段rva
程序入口
编译器会加头和尾,中间调用main。
位置无关代码
编译动态库时,必须带上参数-fpic,表示生成位置无关代码。这样无论动态库在内存中的什么位置,都可以正常执行。-fpic生成的代码中,对于同一个模块而言,指令和数据之间的偏移是固定的,指令对数据的引用可以是用相对地址而不是绝对地址。
got和plt
现代操作系统不允许修改代码段,只能修改数据段,所以需要把动态地址存在代码段以外的专门的地方,GOT表与PLT表应运而生。
以scanf为例,其代码从动态库中加载。
跳转顺序:call scanf —> scanf的plt表 —>scanf的got表
Procedure Linkage Table,Global Offset Table。
got表中存放scanf的真实位置。
在函数第一次调用时,其地址才通过连接器动态解析并加载到.got.plt中,之后got表中就存了真实位置。这叫延时加载。
静态编译的程序没有这两个段。在pwn中开启debug信息会有这样的提示:xxx is statically linked, skipping GOT/PLT symbols。此时无法从plt中获取库函数地址,直接去text段找就行。
动态分析
常用手法包括跟踪程序变量和插桩。
按分析者和被分析者的关系,可分为两大类方法。
- 分析引擎和被分析软件共享内存空间
- 在隔离环境中运行并记录执行迹
符号执行
指定find和avoid,获得到达目标位置的约束,求解约束获得输入的具体值。
angr非常值得研究,我认为其通用性恐怕超过时间盲注。
插桩
主要分为二进制插桩和源码插桩。
源码插桩之后需要重新编译链接。
二进制插桩则可分为静态和动态,前者直接编辑原来的二进制文件,后者则不修改。
CTF中使用较多的是二进制动态插桩。如果题目混淆了控制流,可以利用插桩记录执行过的基本块。另一个思路是,flag接近正确时会发生更多的运算,所以可以通过统计执行次数来逼近正确flag。
值得留意的汇编指令
x86 CPU上的NOP指令实质上是XCHG EAX, EAX,机器码0x90。
INT3,机器码CC。栈一般是用0xcc初始化,而堆一般使用0xcd初始化。而0xcc对应汉字编码为烫,int3指令机器码也为0xcc。而这并非偶然,当发生指针栈溢出时eip会指向初始化时填充的0xcc从而引发int3断点异常,使程序中断。
xor eax,eax,机器码31 C0。
RDTSC,用于计时。
rol,循环左移。
ret相当于pop eip,call相当于push eip+4和jmp。
enter相当于push ebp、mov ebp,esp和sub esp,leave相当于mov esp,ebp和pop ebp。
jmp,E9(16), EA(32), EB(8)。
rep movsd,si移动到di。
setz,setnz,将zf的值放进指定的通用寄存器里。
下面这个是字典序的机器码key-指令value查询,正好用于逆向。
https://www.cnblogs.com/marklove/p/15311785.html
浮点数相关指令可以参考:
https://www.felixcloutier.com/x86/vpcmpb:vpcmpub
repne scasb,检查rdi所指字符串的长度。长度会放在ecx。ecx的初始值如果为全F,则对ecx取反后再减一就是字符个数。
bswap,字节序取反。
逆向中的SEH
structured exception handling。
个人理解,回调函数是一个作为参数的函数。上游交给下游一个任务,同时给下游一个解决方案(也就是回调函数)。下游在完成这个任务的时候,会使用这个解决方案。知乎上的一个例子是,客人提前告知酒店要提供何种叫醒服务。
线程出错的时候,操作系统会执行用户定义的回调函数。
一个值得注意的地方是,ida中,在汇编视图下,函数的开头会有except_handler的标记,而在伪代码视图中则没有。如果在用户函数附近看见了这个标记,多半是有SEH的考点。
SEH的套路:
- 程序故意创造异常(比如xor eax,eax;jmp eax),然后将真正的处理逻辑放在SEH里,以实现关键代码隐藏。因为SEH是没有上游调用的,所以反汇编看不见相应函数。
壳
主要分为压缩壳和加密壳。前者如UPX,后者如ASProtect。
虚拟机壳也可独做一类,如VMProtect。
CTF中一般没有加密壳,原因是难度过大。
UPXShell是UPX自带的脱壳,但加壳时的过程可能遭修改,所以直接用可能不行,需要动态脱壳。
壳程序与原来的代码一般在不同的区段,相隔较远。
壳会在开始的时候保护现场,结束的时候恢复现场。
OEP,程序入口点,程序最开始执行的地方。
IAT,导入地址表,描述的是导入信息函数地址,在文件中是一个RVA数组,在内存中是一个函数地址数组,因此dump之后需要将函数地址数组转为RVA。不论是压缩壳还是加密壳,在脱壳过程中都需要修复IAT。
漏洞的生命周期
- 挖掘。二进制多用fuzz,web漏洞因人机交互多为手工挖掘。静态分析(抽象解释,符号执行,污点分析,特征分类),动态分析(代码流,数据流),机器学习方法(克隆检测方法可以用于漏洞挖掘)。有大量的商用漏洞扫描工具(比如web的OpenVAS,fuzz的AFL)。
- 分析,复现别人发布的POC(proof of concept),补丁对比。
- 利用
从crash中找漏洞,从漏洞中找能利用的,然后利用。
调用约定和返回值
32位四种约定,cdecl(cdecl是c declaration的缩写,见于x86 c代码),stdcall(见于windows api),thiscall,fastcall
都是从右往左依次入栈。
区别在于调用者清理/被调用者清理栈,参数是否放入寄存器。

64位两种约定,x86-64(windows)和systemV64(linux, macOS)。前者使用四个寄存器,后者使用六个寄存器。前者使用顺序是rcx,rdx,r8,r9。浮点用xmm。后者前 6 个参数是从左至右依次存放于 RDI,RSI,RDX,RCX,R8,R9。
return语句的变量会放在eax,如果存不下,高位放在edx。
call analysis failed
在IDA中,如果出现call analysis failed,可能是因为调用约定识别错了,导致栈不平衡。可以尝试修改函数的原型声明。
我个人在做题过程中遇到了非常邪门的情况,f5反编译报call analysis failed,正准备解决,忽然发现自己好了。我的操作是,点进了报错的函数,再退出来。
栈帧,函数原语和sp analysis failed
| 局部变量 |
| 老EBP |
| 返回地址 |
| 参数 |
所以说,参数是ebp+x,局部变量是ebp-x,返回地址是ebp+4。
注意,未必使用ebp来寻址局部变量,优化后用esp来寻址局部变量。IDA同样支持后者,但有可能会出现sp analysis failed,此时需要用户来检查IDA对ESP的推导过程,粗暴的解决方法是alt+k在报错的前一个位置改成报错位置的值。
call xxx相当于push eip+4和jmp xxx,ret相当于pop eip。
另外,可以用push reg和pop reg来实现对esp的加减,指令长度更短。如果没在函数调用前后看见sub esp可能是这种情况。
SHT table size or offset is invalid
SHT是section header table的缩写。从内存中dump出来的SO没有section header table,需要手动修复。
如何找main函数

库函数识别
除了更新函数签名库,还有一些其它方法来识别静态库函数:
- 看字符串。静态库的报错信息常常也在二进制文件中,用IDA可以看见。
- 手工比对。具体做法是,搞清楚具体使用的库,然后获得一份同样使用该库的静态编译二进制文件,然后用BinDiff(可作为IDA插件)这样的工具来比对。如果相似度很高,可以推测是同一个函数。
保护与混淆
针对静态分析的花指令总结如下:
- 相互抵消,比如push-add-nop-sub-pop
- 在指令之间插入脏字节,比如E8是call的首字节。会有反复横跳的jmp来跳过脏字节。或者一个不可能运行的条件跳转跳到E8数据上,导致数据被识别为代码。
- 指令替换,比如call和push-ret等效,jmp改为call-add esp 4。
- 代码自修改,其实压缩壳也算是一种代码自修改。一个特征是在IDA中,发现有数据被转为函数指针。可以dump内存中真正的代码然后IDA。也可以尝试直接阅读自修改的过程。
- 加密,主要是以VMProtect为代表的加密壳。先获取指令集(正道是完整获取,邪道是打log),然后写反汇编代码(本质是字符串处理函数)将字节码转为指令,然后整理成C语言(此时的结果很长,很多goto,难以阅读),再用C编译器重新编译(编译优化会大大缩短代码),然后IDA。
- 控制流混淆,如ollvm,整个程序被扁平化为一个巨大的switch语句块。永真跳转我想也属于此。angr可以通解此类问题。
- 代码藏匿,这个名字不太严谨,自己起的。比如把代码藏在.rodata。藏了的题目的rodata段的起止:4F4000,51DF04。没藏的普通程序的rodata段的起止:4000,4646。
针对动态分析的反调试方法总结如下:
- 利用windows ProcessEnvironmentBlock的being debugged字段(偏移量002)或NtGlobalFlag字段(偏移量068)判断是否处于调试。windows api类型的反调试都可以通过hook来绕过,自动hook插件如ScyllaHide。
- 内存校验可以发现软件断点,内存校验代码书中有个例子。一种轻量的绕过是把断点下在函数里面(如函数末尾)。
- linux下调用ptrace使父进程为唯一调试器。
- 偶尔会有针对具体调试器的检测,比如窗口名、进程名或是特有特征。
- 32/64架构切换,本意不是反调试,但windows下很多用户态调试器无法对架构切换后的代码进行调试。winDbg是内核态调试器,可以搞定这种情况。
- 直接破坏可执行文件结构,让程序无法直接运行。
- 我的揣测。使用比较小众的方法来编译,使得“可以直接运行,但gdb单步调试会报错”。我在网上看见的两种情况。第一种是,new得到的堆内存溢出使用(new到N个int却使用了N+2个int),使用的时候并不会报错,delete[]的时候GDB或CLR都会检查堆栈溢出,从而发现问题而报错。第二种是,send失败后默认发出SIGPIPE的信号,虽然在程序中有忽略这个信号,但是gdb默认是没有忽略这个信号,所以gdb先于进程发现这个信息就会终止进程。总结这两种情况就是,gdb自己的“过敏”。难怪windows的调试器都会有“忽略指定异常”的功能,想来就是解决这种情况。感觉本意不是反调试,但确实搞心态。
代码反调试的位置总结如下。需要注意的是,可能有两处,甚至多处反调试。
- 主动抛异常,在SEH中做反调试操作。可以配置调试器来忽视这种异常,确保由程序本身处理该异常。
- TLS线程本地存储,是解决多个线程同时访问全局变量的机制,TLS回调函数(函数名常常为tls callback)将先于entrypoint调用,有时会将反调试代码放在这里。
- main函数开头。
windows的一些碎片知识
dword,32位无符号整数。
windows三个主要子系统,kernel(进程/线程、内存、文件访问),user(鼠标键盘、窗口菜单),gdi(显示器、打印机)。
MessageBoxA的A指的是ANSI,与之并列的是W,widechar,宽字节,两字节一个字符,也就是unicode。
hwnd,wnd疑似window的缩写,hwnd表示窗口句柄。
lp,long pointer,长指针。LPCTSTR,c表示constant,T表示按宏适配A或W。
wcs前缀的函数用来处理宽字节字符串。
WOW64,windows-on-windows 64-bit,是64位系统的子系统,确保32位程序能够运行。所以说,system32中的是64位文件,wow64中的是32位文件。
HMODULE表示模块句柄。代表应用程序载入的模块,win32系统下通常是被载入模块的线性地址。
网友说,调用Windows提供的API后编译器都会安排一段__chkesp,另外在"直接调用地址"(本人注,指将数据类型转换为函数指针后进行调用)返回后,也会被插入这段代码。
windows钩子
Windows 窗口程序是靠消息驱动的,一切过程皆是消息,原本的消息传递过程是:系统接收到消息-将消息放入系统消息队列-将消息放入线程消息队列-线程中处理该消息,而钩子函数SetWindowsHookEx的作用就是拦截消息,用自定义的函数处理消息。
HHOOK WINAPI SetWindowsHookEx(
int idHook,
HOOKPROC lpfn,
HINSTANCE hMod,
DWORD dwThreadId);
/*
idHook:钩子的类型,即它处理的消息类型
lpfn:指向dll中的函数或者指向当前进程中的一段代码
hMod:dll的句柄
dwThreadId:线程ID,当此参数为0时表示设置全局钩子
*/
idHook的各种取值可以查windows文档,比如键盘钩子的id为13。
lpfn(int code, WPARAM wParam, LPARAM lParam),对于键盘钩子来说code的取值较少(记得只有0和3,0是action,3是noleave,noleave表示消息不离开队列),值得注意的是code小于0会直接交给下一个钩子。每个键盘按键对应的号码可以在windows doc查到,比如题目中遇到的:
v4 = *(_DWORD *)lParam;
if ( v4 == 'W' || v4 == 'S' || v4 == 'A' || v4 == 'D' ) {
another_func();
}
表示每按下wasd四个键,都会调用一次another_func。
键盘钩子函数可以避免scanf一类的函数的调用,影响数据流的分析。不知道还有没有其它深意。
Debugbreak()
应用程序执行到DebugBreak()函数后,打开Debug(调试)窗口,并在其中显示当前上下文信息。从开发的角度看,可以理解为在感兴趣的位置加了一句print。
本质上,debugbreak()的核心代码就是int3。
执行到此处时,正确的应对是让程序自行处理。int3的流程中自己会检查是否存在debugger,建议单步跟进去动调修改eax,而不是patch掉整个debugbreak过程,否则会影响程序逻辑(因为重要的代码就在debugbreak过程中)。
debugbreak可以与SEH考点结合,用于代码隐藏。
virtualProtect和mprotect
BOOL VirtualProtect(
LPVOID lpAddress, //需要修改的起始地址
SIZE_T dwSize, //长度
DWORD flNewProtect, //新的权限
PDWORD lpflOldProtect //看了但不太懂
);
通常text段中只能拥有读/写中的一种,调用这个API能调整text段的权限。比如说,允许运行过程中对代码段进行解密。这是一个windows API。0x4表示读写,0x40表示读写执行。
在linux中mprotect有类似的作用,不过mprotect没有第四个参数。
PROT_READ:可写,值为 1
PROT_WRITE:可读, 值为 2
PROT_EXEC:可执行,值为 4
PROT_NONE:不允许访问,值为 0
函数名修饰与UnDecorateSymbolName
c++在编译代码时,会对函数名进行变换(因为函数可以重载,光靠函数名无法区分调用的函数,所以需要添加返回值类型和参数顺序及类型,所以需要“函数签名”),称为C++ decorated name(特征是以问号开头),undname.exe的作用就是为我们还原函数签名。当我们release一个程序后,出现崩溃时,我们只能从map中分析是哪一个函数出的问题,有了undname.exe就可以迅速的找到函数了。
这张图展示了undname的输入和输出(本质是这个API的输入和输出)。



协议分析
鲁老师的逆向ppt第四章有详细的论述,挖坑待填。
工具使用
IDA使用
临时设置点option,全局设置改ida.cfg。
- 空格进行流图和代码的切换
- 用户可以修正IDA给的数据类型和函数类型
- 使用G能跳转到指定位置,ctrl+s能跳到指定区段
- File菜单下可以做python相关操作
- view菜单下的字符串窗口非常常用(shift f12)
- F5生成伪代码
- n,修改标识符
- 可以切换数据显示格式,比如字符/十六进制/十进制。注意将十六进制转为字符串的时候,有字节序的问题,需要将字符串倒置。
- 如果遇到连续的数据定义,改为数组。y,修改c语言变量类型。a,将一个个的byte转为字符串,方便复制(最好的复制方法是右键然后jump in a hex window)。整数数组可以edit-array。结构体和枚举题目里很少遇到,详见《加密与解密》3.3。
- 花指令的题目,c转为代码,d转为数据。如果f5提示你要在函数内操作,说明当前代码没有识别为函数,需要在函数起始位置edit-function-createfunction。另一种情况是F5不报错、没反应,option general把stack pointer打开,如果左侧没有显示栈偏移,说明当前所在的位置没有被识别为函数,不能F5。这时大概有两个思路,1-在没有栈偏移的范围内寻找红色字体,解决错误;2-直接往上翻,直到显示栈偏移,在可识别和不可识别的交界处创建函数,这时候会在output window报错,会暴露问题位置。
- 看伪码的时候,选中多行,右键,可以折叠。
IDA伪码复制出来的注意事项
IDA目录下的plugins目录下,有一个defs.h,有ROL、byteN等操作。挺全的,能减少伪码在clion中的修改。
LOWORD()得到一个32bit数的低16bit
HIWORD()得到一个32bit数的高16bit
LOBYTE()得到一个16bit数最低(最右边)那个字节
HIBYTE()得到一个16bit数最高(最左边)那个字节
z3_solver解约束
支持等式,不等式。支持整数,有理数。如果要用位运算,声明BitVecs。需要注意的是,打印顺序未必是声明顺序。
pip install z3_solver
from z3 import *
a, s, d = Ints('a s d')
# a, b, c, d = BitVecs('a b c d', 64)
#X = IntVector('x', 5)
#Y = RealVector('y', 5)
#P = BoolVector('p', 5)
x = Solver()
x.add(a-d == 18)
x.add(a+s == 12)
x.add(s-d == 20)
check = x.check()
print(check)
model = x.model()
print(model)
#for var in model:
# print('var',var,'=')
# print(hex(model[var].as_long()))
# 可以求出所有解
#while x.check() == sat:
# print (x.model())
# x.add(Or(a != s.model()[a], b != s.model()[b]))
https://ericpony.github.io/z3py-tutorial/guide-examples.htm
第一个断点下在哪
CFFexplorer是一个PE编辑器,常用于关闭动态基址(NT header-characteristic-勾选strip relocation info),但其hex editor功能也极其好用,可以按各种形式复制出来,甚至可以直接按C array复制出来。非常爽。不过CFF只能用于windows可执行文件。
linux下可以直接b main。
如果不能b main的话,先让程序处于运行状态,然后ps -aux | grep yourelf,查看进程号。
然后,cat /proc/43865/maps,第一个数字就是基址,加上ida里的地址即可。
linux下aslr的临时关闭如下,不过并不能帮助找到第一个断点的位置。
sudo sysctl -w kernel.randomize_va_space=0
dnSpy
能进行源码编辑,然后重编译。简直就跟自己写得一样。
unity游戏,游戏逻辑都在Managed/Assembly-CSharp.dll内。
x64dbg的三种断点
硬件断点的原理是将断点地址存放在调试寄存器DR0-DR3中,所以只能同时存在四个。
内存断点的原理是将指定内存页设PAGE_NOACCESS,触发内存访问异常。
软件断点的原理是将内存中指定指令修改为INT 3。
更详细的论述可以看《加密与解密》第二章第一节。
x64dbg堆栈平衡法UPX/nspack/aspack脱壳
上来直接F9,会从DLL模块跳到exe模块。
跳转之后的第一条,就是pushad。F8,然后栈顶下访问断点。
F9(可能需要两次F9),来到恢复现场的popad,然后继续F8,择机F4运行到光标位置。
popad之后的第一次跳转很有可能就是原始OEP。如AE7513跳转到AE155D。
用scylla插件dump,然后fix dump。
脱壳之后就可以在IDA中分析了,但由于ASLR不能运行。
CFF explorer可以修改Nt header,让程序不ASLR,从而可以运行。
以上步骤在有的题目中曾经完全成功过,也曾在其他题目中在最后一步失败,原因暂不明。
nspack,北斗压缩壳,流程基本一致。aspack也是上面这个流程。
有upx的elf我只遇到过一次,用upx -d pack.exe -o unpack.exe解的。
OD
SFX自动脱壳
虽然不知道原理是什么,不过我试了确实有用。设置为“字节方式跟踪”,能解aspack,其它压缩壳暂时没试过。刚跑出来的时候会分不清数据和代码,右键Analysis code就可以了。

API调用查看
可以查找当前模块中的所有API调用。然后搜索感兴趣的API调用。
黑话
HE是指硬件断点,可以通过执行表达式he addr来下断点。
BP,应该跟点一下左侧红点是一样的效果。
od可以通过上面两个指令直接对指定windows api下断点。
run trace和hit trace
据说可以记录执行过的指令、判断哪一部分执行了哪一部分没执行。
更详细的论述可以看《加密与解密》第二章第一节。
x64dbg中,来到“跟踪”选项卡,右键即可设置输出文件,开始trace。
配合断点使用,不能f9,长按f8即可。遇到断点的话,左侧的地址会显示黑色而非灰色,底栏也会提醒。
直接修改EIP
感觉这是一个非常有用的功能。
dll/so的脱壳与动态调试
Dll脱壳的最关键的步骤在于使用LordPE修改其Dll的标志,重命名后缀exe,然后可以用OD打开。dump之后改回来即可。但我注意到,x64dbg和OD其实都能打开dll,所以这个条目的必要性有待考证。
python的ctypes可以调用dll中的函数。如此看来,dll的调试比exe更简单,因为可以直接进行函数级的调试。
import ctypes
def baopo(i):
dll = ctypes.cdll.LoadLibrary("Interface.dll") #dll文件目录
print(i)
dll.GameObject(i) #调用GameObject()这个函数,输入参数为i。如果不止一个参数或者参数范围很大,可能得另想办法
for i in range(0,100):#从0~99开始爆破
baopo(i)
import ctypes
so = ctypes.CDLL('./sum.so')
print "so.sum(50) = %d" % so.sum(50)
# 1275
ida远程调试elf
dbgsrv目录下找linux server64,在虚拟机中运行。ida这边选remote linux debugger。
process option设置好host、port。如果积极拒绝就换桥接模式。
option里记得把该勾的勾上,至少把入口点断勾上。
GDB
linux很少有需要crack的软件,因为gdb不如OD、x64dbg好用而生气的时候要多多理解。网上对GDB的使用,一般是正经开发时的调试。一般的过程如下:
gdb
file 文件名
start 开始调试,仅限有main的情况。如果无main,只能b *0x入口点地址。如果有随机化,b __libc_start_main。
r 运行参数,即可带参数运行。
n步过,s步入。与其它调试器一样,箭头所指表示即将执行。enter能重复上一次的命令。
x/16xb addr,第一个/16表示展示数量,第二个x表示十六进制,第三个表示db。x/16c addr,即可以字符形式查看。
finish,运行到当前函数返回。
如果想看更多汇编,display /20i $pc。可以在pc基础上减。
info b可查看断点,del 断点编号可删除断点。
gdb也有硬件断点,hbreak。还有内存断点(读写均可断),watch。还可以catch syscall。catch syscall write非常好用,但会停在syscall触发的下一句话。
.net
.NET是框架,运行于操作系统之上,又独立于操作系统,可以理解为一套虚拟机,实现跨平台(不同的操作系统都行)、跨语言(C#、C++、VB都行,最终都会被翻译为MSIL微软中间语言。
IL和元数据共同构成了.net程序的基本要素。《加密与解密》第24章给了一个demo来说明IL语言“基于栈”的特点,并给了常用指令表。PEBrowseDbg是IL调试器。
强名称是.net的代码完整性保护机制。有名为strong name remove的工具,逻辑类似安卓的重打包、重签名。
无任何处理的情况下,.NET近乎开源。Visual Studio会捆绑安装Dotfuscator。名称混淆的基本原理是改变#String流中的字符串。
解题
解题流程
题目一般是给一个可执行文件。
- 如果是exe的话,可以尝试在cmd中运行,这样就不会一闪而过了。
- 先die查壳,然后看段名称有无异常(比如最经典的upx,或者自定义名称),然后放进IDA。
- 判断语言,然后使用对应的辅助脚本/分析工具。
| 语言 | 做法 |
|---|---|
| c++ | 类内函数加大了分析难度。ida_medigate插件利用c++的RTTI,能让虚函数调用更易读。 from ida_medigate.rtti_parser import GccRTTIParser GccRTTIParser.init_parser() GccRTTIParser.build_all() |
| rust | 题目给exe,IDA打开后会标记main,用户实际写的main函数的地址会包含于其中 |
| go | 通过观察字符串可以判断出go语言,IDA中运行go parser |
| unity/c# | de4dot脱壳,dnSpy打开assembly-csharp.dll,如果没找到关键就看有没有dllimport import的dll可能会在data/plugins下 如果有需要可以用菜鸟的在线c# |
| python | Pyinstaller这个库本⾝的打包原理⼤概就是先将py编译成pyc,然后部分压缩成pyz。 应对pyinstaller,python pyinstxtractor.py your.exe,将baselibrary中pyc第一行插入到原文件头后改pyc 应对pyc,pip install uncompyle,uncompyle6 attachment.pyc > attachment.py |
| Java | class文件可以用Intellij idea直接打开 jar用Java decompiler,或者用IDEA创建一个新的java项目,然后创建一个lib文件夹将jar包放入,右键选择lib文件夹的“Add as Library…”,将lib文件夹添加进项目依赖。成功添加后可以看到Jar包中反编译后的源代码。 |
| perl | perl也是脚本语言,也可以打包为exe,只能动态调试看自解压源码。 在第一句用户代码运行之前会自解压,动调时搜索script下断点然后F8即可 |
| brainfuck | bf是brainfuck语言反编译器插件 |
| pascal | 函数会很多,主函数应该在start附近,并且长度比较长 |
| delphi | 专门的工具Dede |
| mfc | resource hacker和xspy |
- 字符串view,一般会获得一些提示。如果什么都没找到,先试一下动态调试。如果题目没有输入,可能是读取文件。如果无法调试,或者连入手点都没找到,可能是因为静态的时候没显示全,这时候只能看汇编了。
- 先静态,去除反调试,然后编辑PE关闭ASLR,再动态分析,直接到感兴趣的地方下断点。
- 粉色的是库函数,一般不用看。重点关注IDA中用户写的函数,看不懂的,可以对照动态分析再看,如果题目做不到想执行哪就执行哪,可以把子函数的伪码直接复制出来执行。我推荐C语言,只需要很少的修改,ida export data的时候也比较方便。python则需要改代码和手动截断(移位运算的时候)。
- 只用看text段的函数。如果无法判断是不是重要的函数,或是根本没找到重要函数,看看xref to,一团乱麻的反而是不重要的。
- 如果不能快速解出,至少先确认flag的长度。
题目成百上千,最传统的题型当属encrypt和check函数。check函数最好是从后往前看。encrypt优先猜常见算法。
隐藏提示性字符串的手法总结
有的题不按套路出牌,根本就没有用户交互;
有的题做GUI,用图片等形式提供用户交互;
有的题会先对提示字符串做解密再显示;
有的题混淆引用字符串附近的代码(不影响xref)。
有的题给output,需要你还原当时的输入,这种需要你手工比对你的输出和预期输出。这类题不需要依赖提示性字符串。
特殊用户交互手法总结
读文件,会使用getfile这样的api。
读env,会使用getenv这样的api。环境变量不一定是可见字符。export CTF=“$(printf “\x0a\xda\xf2\x4f”)”。使用这样的交互,可能就是因为想输入不可见字符。
c++解题心得
题目中往往有大量的v36[4]和(*this+4)-4,语义难以理解。一定要足够抽象,看不懂的就当不存在。
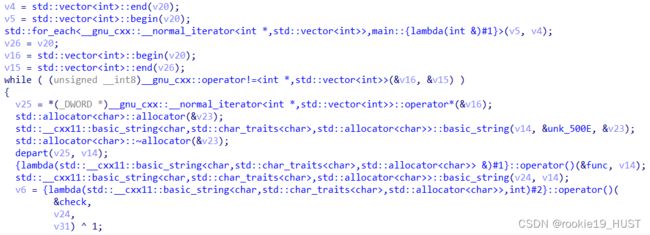
如果静态编译导致函数数量很大,且函数名为可读的修饰名,可以使用filter功能找关键函数(如下第一张图,如果不用filter功能的话,很容易在第二张图这样的东西里迷失):


lambda函数,以及带operator的,是关键函数。以下图为例,虽然代码行数多、字数多,但真正要看的其实不多。
下图中关键函数只有四个,第三行的lambda,depart,depart下面的lambda,和再下一行的lambda。
.net解题心得
dnSpy最强的功能应该就是源码编辑了。这使得.net的逆向题做起来和js一样方便。想看什么变量,直接print。
python pyc字节码补充说明
下面这篇文章是认真讨论了“肉眼阅读字节码”的问题,常见的范式如循环、dict的使用等。
https://www.cnblogs.com/yinguohai/p/11158492.html
uncompyle可以应付各个版本的完整pyc(python3.10似乎不支持,py3.10可以用在线网站),但如果pyc被文本形式贴出来,可以借助python自带的dis模块,或者肉眼看。
说实话,最大的难点恐怕是“发现这是python字节码”。此处我贴一个python字节码的demo供后续参考。
9 113 LOAD_NAME 2 (raw_input)
116 LOAD_CONST 29 ('please input your flag:')
119 CALL_FUNCTION 1
122 STORE_NAME 3 (flag)
题目所给可执行文件无法运行
曾在正赛中遇到动态调试打开闪退的问题,当时直接放弃了题目,误以为是有高深的反调试。
后来又遇到了这种情况,闪退其实是因为无法正常运行,比如缺dll之类的。
die能看见编译器的具体版本。考虑到网上的解决方案乱七八糟而且未必可逆,我觉得一个不错的解决方案是直接安装对应编译器。我安装VS2013后确实解决了打不开2013编译的题目程序的问题。一个月后我还老老实实装了vs2017。
自加密/自修改
感觉难点在于发现题目是自加密。在注意到“将数据转为函数指针后执行”这一操作后,可以下个内存断点。如果动调的时候出现illegal instruction,其中一种可能就是自修改并没有执行。
52pojie的ida 7.5记得运行一下绿化,就会自动配好python环境。
动态调试,可以用gdb然后x/,复制出来解密后的代码。这适用于就地加密的简单情况。如果不知道复制出来的代码往哪粘贴怎么办?在gdb中,dump binary memory my_binary_file.bin 0x22fd8a 0x22fd8a+450,粘贴到新的二进制文件里。
word里,用^p替换换行符,用^w替换连续空格。
然后调用下面的脚本,大范围patch。
a = """55 48 89"""
a=a.split(" ")
start=0x402219
for i in range(len(a)):
patch_byte(start+i, int(a[i],16))
print('done', time.time())
from idaapi import get_bytes
start=0x401000
end=0x432000
for i in range(start, end+1):
patch_byte(i, int.from_bytes(get_bytes(i, 1), byteorder='little')^0x23)
print('done', time.time())
AES和SM4每个分组16个字节。DES则是每个分组8字节。Findcrypt插件可以解决这类问题,edit-plugins。如果是自加密的话,需要找到IV(16字节)和key(16/24/32字节)。工作模式和填充可能只能多试几遍了。
脱壳实践
exe用动态调试器如od的trace,elf用ida remote linux debugger的trace。
在trace的结果中,除了关注pushad popad,还应当关注jmp(大跳,E9而非EB。x64中直接右键-搜索-匹配特征-E9,ida中search-text-jmp)。
ida在动态调试页面ctrl s可以看见与静态分析时不同的段,x32/x64则是在“内存布局”标签页查看。
dump内存的脚本:
import idaapi
data = idaapi.dbg_read_memory(start_address, data_length)
fp = open('d:\\dump', 'wb')
fp.write(data)
fp.close()
angr与控制流混淆的总结
较为深入详细的angr教程似乎只看见一个,https://bluesadi.github.io/0x401RevTrain-Tools/angr。
目前见过两类控制流混淆,一种是虚拟机,另一种是扁平化。
虚拟机题目,会逐位读取存储的指令序列,然后switch来执行。关键是要找到内存中的指令序列,然后逐句翻译出实际执行的代码。
扁平化题目,如果代码长度不用翻页,可以判断各switch的作用,对各case进行粗分类。多半能猜出数据流和具体处理手段。代码很长(经典症状就是一大堆while 1嵌套)就得用后面的脚本预处理了。
angr的本质是树遍历。现代的符号执行引擎基本上都是动态符号执行(或者叫混合执行)。以angr为例,默认情况下,只有从标准输入流中读取的数据会被符号化,其他数据都是具有实际值的。在angr中,无论是具体值还是符号量都有相同的类型——claripy.ast.bv.BV,也就是BitVector。
>>> claripy.BVV(666, 32) # 创建一个32位的有具体值的BV,666=0x29a
<BV32 0x29a>
>>> claripy.BVS('sym_var', 32) # 创建一个32位的符号值BV
<BV32 sym_var_97_32>
import angr
import claripy
proj = angr.Project('example-1') # 载入二进制文件
sym_flag = claripy.BVS('flag', 100 * 8) # BV的大小得设大一点,不然跑不出来,原因未知
state = proj.factory.entry_state(stdin=sym_flag) # 创建起始状态
simgr = proj.factory.simulation_manager(state) # 创建符号执行引擎
# simgr.step() # 单步执行
simgr.explore(find=0x40138F, avoid=0x80485A8) # 执行到find,避免avoid。加avoid会快很多。如果不止一个地址,可以把一个入参为state的函数传给find和avoid。
found = simgr.found[0]
# print(found.posix.dumps(0)) # 求能走出这条路径的标准输入
solver = simgr.found[0].solver
solver.add(simgr.found[0].regs.eax == 0) # 可以在路径求解约束中添加自己的约束
print(solver.eval(sym_flag, cast_to=bytes))
如果是gui,我想就难办了。如果想直接find correct,会很慢。实际解题的时候,一般是deflat和去除冗余代码块做预处理,然后才是经典解题流程。deflat 800行到100行需要几分钟,会显示实时进度。
# deflat.py来自https://github.com/cq674350529/deflat,需要angr环境
python deflat.py -f "C:\Users\ysnb\Downloads\attachment (4)" --addr 0x400620
# addr是需要deflat的函数地址
实际使用的过程中发现,deflat的结果可能会有错,还原的代码出现了死循环,并且没有与“right”用户交互语句相关的代码了。或者是所有的代码变成了nop。
go总结
运行go_parser之后,重点关注main开头的函数,可能在函数列表最下面。
go语言中字符串不以杠0结尾,而是以地址-长度的形式存储在rodata。ida f12看不见。str[1]就是str的长度,*str就是语义str。
fmt_print的第三个参数就是输出,点一层能看见地址和长度,点两层能看见字符串内容。
fmt_scan以空格分隔读入,fmt_scanf只读入符合格式的输入,fmt_scanln读入行。
fmt_scan的第三个参数就是输入。
总结一下就是,fmt的前两个参数不用管。
morestack_noctxt用于栈扩大,不用管。
go的数组长度不能改变,为了灵活,常常使用slice。
类型总结
目前常见的题目,一般是内置答案和用户输入双向奔赴,然后字符串比对。
因此一个基本的手法是,给用户输入的内存下断点,以追踪实际处理用户输入的代码。
如果重点是自定义的字符串处理函数,思维上可以采用函数中心视角。
为了能在一道题中设置多个考点,往往采用多段式的解谜。需要注意“continue”等字样。最终的答案可能是每关的password用下划线连接。
如果找不到关键代码,也可以先找关键数据。ida中用ctrl s可以跳转到rodata,关键的内容往往在rodata开头。
感悟
做rev题不要纠结具体逻辑。那是随题目而变的细枝末节。能穷举就穷举。做题时没有逆向工程,只有正向工程。写逆过程就是上了出题人的当了。尽量少用python,多复制ida里的c代码。
从做题角度来说,上面的确实是不错的方法,但伪代码还是要大致看懂的。我曾错误判断flag的长度,就是因为没有细看伪代码,本来是两位两位进行处理,误以为是一位一位处理,自然也就无法做对了。
一般来说一个子函数只做一件事,但未必。比如说,想进行大小写转换然后b64编码,自然的写法是在主函数中先后调用两个子函数。但其实也可以在b64编码函数的开头加一个大小写转换,主函数中只调用b64编码函数,也是一样的效果。所以如果感觉漏了什么关键函数,就检查一下是否存在这种一个子函数做了好几件事的情况。
如果编辑代码有困难,可以试试编辑堆栈/寄存器。难得感受到一次动态调试的魅力。
异构的题反而不难。
函数特别少的,比如三个的,直接angr。亲测windows exe也可以这样做。
爆破法
很不rev的一种做法是写脚本反复调用可执行文件,然后判断输出里是否包含特定文字,这种方法把整个可执行文件当黑盒,啥都不管。
更多时候需要读代码,提炼出判断条件。关键是看位与位之间是否有耦合关系,以判断一次穷举的位数,最理想的情况是每次穷举一位,复杂一点的可能需要一次穷举2位或者4位。
如果不得不传入整个字符串而不是一个字符的话,我的经验是从前往后穷举(做buu soullike的时候非常奇怪,感觉这是玄学经验)。详细来说,先初始化为0,穷举第一位,此时相当于传入长度为1的字符串(因为第二位以及后面的都是0)。得到第一位后,穷举第二位之前的初始化时把第一位加上。同理,穷举第三位前的初始化应该把字符串前两位赋值。这就是从前往后穷举的含义。
哈希算法的windows api
CryptCreateHash
md5 8003
sha1 8004
常用ascii
| flag{} | 66 6c 61 67 7b 7d | 102 108 97 103 123 125 |
mips逆向
从题目名字或者ida打开时能知道是mips。mips的题有时ida会报“is not decompilable”的错,jeb官网的demo版可以分析mips和mips64(不能用剪贴板,每次分析有限时,不过做题应该够用)。
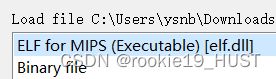
file能查看更多信息。关键是LSB(qemu-mipsel)和MSB(qemu-mips)、动态链接还是静态链接。

qemu的安装:apt-get install qemu
qemu的基本使用: qemu-mips -g 666 mipsfile
-g指定remote gdb连接的端口,-L指定动态链接库。
解mips的题目时遇到了ida cannot decompile的情况。经查询,安装了ida的mips插件。leafblower和mipslocalvars。
想动调得配qemu。QEMU User Mode可以直接跑异构程序,System Mode可以自定义内核和虚拟磁盘。
例题:
https://www.cnblogs.com/L1B0/p/8987288.html
固件逆向
大致记录一下操作步骤。
- binwalk -e
- binwalk -A
- firmware-mod-kit可以解压cpio、cramfs、squashfs格式的文件系统。前置依赖和下载地址见https://blog.csdn.net/ldwj2016/article/details/80712566。
- ghidra相较IDA更适合固件分析,至少拖进来就能看见函数。
文件对比
linux中,一般用cmp命令比较二进制文件,diff命令比较文本文件。
无能狂怒
逆向的坏处在于,可以在无自动混淆、无任何反调试保护、不修改编译后产生的文件、较少的代码行数/用户写的函数的情况下,设计一个算法正面锤烂你。开局一个唯一确定解,剩下全靠编。如果不放心题目的合法性,还可以利用出题方与解题方时间不等,提前用穷举法验证。如果我来设计,可以这样做:
- 设置一个假的长度判断,满足假长度的话就调用一些无用的加密、编码算法。不限制flag长度,而是要求输出最短flag确保唯一性。
- 添加一些参与了运算但其实没什么用的常数数组
- 写一些内容一样的函数,就可以将多次调用的函数改为只用一次
- 把局部变量改成只用一次的全局变量
- 调库(比如printf)前做一次封装,加一些有实际作用的用户代码
- 用一些无意义的malloc,将部分中间结果多存一份副本,也可以再对副本做一些无意义的运算
- 让随机数参与运算但条件永真(比如生成5个0-5、5个6-10的随机数,要求前五个的和小于后五个的和)。
- 使用奇怪的逻辑,比如把迷宫题的迷宫做一个加密、分开存放,也不使用上下左右的交互,而是多个按键对应同一个操作。
- 把循环展开。同样的操作做二十次,那就把除了偏移量以外完全相同的代码粘贴二十次。如果发生了编译优化,那就阻止这种优化。
- 为确保答案唯一,约束数量可以无限多(甚至可以是等效的约束,增加约束数量本意是增加if的嵌套层数),可以超过确定唯一解需要的约束数量。约束数列中前一半元素和后三分之二元素(正常的逻辑应该以整个数列为单位,并且循环之间一般不会部分重叠)的最值/四分之一分位点/加权平均,权值可以magic小数的形式分散在代码里,而不是连续存储。要求向量距离在两个浮点数之间。将第1、5、3、8个字符依次加入一个set,判断有没有重复。
- 打乱这些约束的代码块的顺序,让最终代码是条件一第一句-条件二第一句-条件三第一句…。
- 出题人花费大量的时间,设计不重复的静态花指令,安放在不同的函数里,强迫解题者一个一个解。或者故意使用重复的静态花指令引诱解题者使用脚本,使得脚本破坏正常代码。
- 总结一下就是,让一道题只能用angr来做(故意浪费时空资源,故意破坏源代码可读性),却又不能在24小时内用angr解出(较长的flag位数,位与位之间的强耦合,浮点数)。让人拿到源码都说不清代码做了什么,那逆向必然也做不出来。
ida插件总结
找加密算法常数的,findcrypt(我的ida版本好像预装了)
c++的,ida_medigate
go的,go_parser(啥都不用配,ida里run一个py文件就行)
反混淆的,d810
重命名的,renamer
mips的,leafblower和mipslocalvars。
keypatch(一般是预装的)
函数符号识别,finger,阿里云的,需要联网
另外有个lumina功能,在线查函数的,remote certificate好像要钱。
安装过程可能会涉及到idapythonrc.py,这个文件的示例在ida目录-python-examples-core下,作用是Setting IDAPython’s module search path。
通过idaapi.get_user_idadir()可以获取appdata的位置,然后把idapythonrc.py放进去。
idapythonrc.py中这样写:
import ida_idaapi
idaapi.require(‘ida_medigate’)
将源代码放在ida目录的python目录的Lib\site-packages(上面的步骤不知道是否必要,这一行方案之后就不再报module not found了)。