【Netty权威指南】19-可靠性
作为一个基础的NIO通信框架, Netty被广泛应用于大数据处理、互联网消息中间件游戏和金融行业等。不同的行业对软件的可靠性需求不同,例如对通信软件的可靠性要求往往需要达到5个9。
1、Netty可靠性需求
我们从Netty的主要应用场景和Netty的运行环境两个维度分析 Netty的可靠性需求。
首先分析 Netty的主要应用场景。
Netty的主要应用场景如下。
1.RPC框架的基础网络通信框架:主要用于分布式节点之间的通信和数据交换,在各个业务领域均有典型的应用,例如阿里的分布式服务框架 Dubbo、消息队列 RocketMQ、大数据处理 Hadoop的基础通信和序列化框架Avro。
2.私有协议的基础通信框架:例如Thrift协议、 Dubbo协议等。
3.公有协议的基础通信框架:例如HTTP协议、SMPP协议等。
从运行环境上看,基于Netty开发的应用面临的是网络环境也不同,手游服务运行的GSM3 G/WIFI网络环境可靠性差,偶尔会出现闪断、网络单通等问题。互联网应用在业务高峰期会出现网络拥堵,而且各地用户的网络环境差别也很大,部分地区网速和网络质量不高。
从应用场景看, Netty是基础的通信框架,一旦出现Bug,轻则需要重启应用,重则可能导致整个业务中断。它的可靠性会影响整个业务集群的数据通信和交换,在当今以分布式为主的软件架构体系中,通信中断就意味着整个业务中断,分布式架构下对通信的可靠性要求非常高。
从运行环境看,Netty会面临恶劣的网络环境,这就要求它自身的可靠性要足够好,平台能够解决的可靠性问题需要由Nety自身来解决,否则会导致上层用户关注过多的底层故障,这将降低Netty的易用性,同时增加用户的开发和运维成本。
Netty的可靠性是如此重要,它的任何故障都可能会导致业务中断,蒙受巨大的经济损失。因此, Netty在版本的迭代中不断加入新的可靠性特性来满足用户日益增长的高可靠和健壮性需求。
2、Netty高可靠性设计
2.1、网络通信类故障
2.1.1、客户端连接超时
在传统的同步阻塞编程模式下,客户端 Socket发起网络连接,往往需要指定连接超时时间,这样做的目的主要有两个。
1.在同步阻塞IO模型中,连接操作是同步阻塞的,如果不设置超时时间,客户端IO线程可能会被长时间阻塞,这会导致系统可用IO线程数的减少。
2.业务层需要:大多数系统都会对业务流程执行时间有限制,例如WEB交互类的响应时间要小于3S。客户端设置连接超时时间是为了实现业务层的超时。
JDK原生的 Socket连接接口定义如下:
public void connect(SocketAddress endpoint, int timeout) throws IOException;用户调用 Socket的 connect方法将被阻塞,直到连接成功或者发生连接超时等异常。
对于NIO的 SocketChannel,在非阻塞模式下,它会直接返回连接结果,如果没有连接成功,也没有发生IO异常,则需要将 SocketChannel注册到 Selector上监听连接结果。所以,异步连接的超时无法在API层面直接设置,而是需要通过定时器来主动监测。
下面我们首先看下 JDK NIO类库的 SocketChannel连接接口定义:
从上面的接口定义可以看出,NIO类库并没有现成的连接超时接口供用户直接使用,如果要在NIO编程中支持连接超时,往往需要NIO框架或者用户自己封装实现。
下面我们看下Netty是如何支持连接超时的,首先,在创建NIO客户端的时候,可以配置连接超时参数:
设置完连接超时之后, Netty在发起连接的时候,会根据超时时间创建 ScheduledFuture挂载在 Reactor线程上,用于定时监测是否发生连接超时,相关代码如下:
创建连接超时定时任务之后,会由 NioEventLoop负责执行。如果已经连接超时,但是服务端仍然没有返回TCP握手应答,则关闭连接,代码如上所示。
如果在超时期限内处理完成连接操作,则取消连接超时定时任务,相关代码如下:
Netty的客户端连接超时参数与其他常用的TCP参数一起配置,使用起来非常方便,上层用户不用关心底层的超时实现机制。这既满足了用户的个性化需求,又实现了故障的分层隔离。
2.1.2、通信对端强制关闭连接
在客户端和服务端正常通信过程中,如果发生网络闪断、对方进程突然宕机或者其他非正常关闭链路事件时,TCP链路就会发生异常。由于TCP是全双工的,通信双方都需要关闭和释放 Socket句柄才不会发生句柄的泄漏。
在实际的NIO编程过程中,我们经常会发现由于句柄没有被及时关闭导致的功能和可靠性问题。究其原因总结如下:
1.IO的读写等操作并非仅仅集中在 Reactor线程内部,用户上层的一些定制行为可能会导致IO操作的外逸,例如业务自定义心跳机制。这些定制行为加大了统一异常处理的难度,IO操作越发散,故障发生的概率就越大;
2.一些异常分支没有考虑到,由于外部环境诱因导致程序进入这些分支,就会引起故障。
下面我们通过故障模拟,看Netty是如何处理对端链路强制关闭异常的。首先启动Netty服务端和客户端,TCP链路建立成功之后,双方维持该链路,査看链路状态,结果如图23-1所示。
强制关闭客户端,模拟客户端宕机,服务端控制台打卬如图23-2所示异常。
从堆栈信息可以判断,服务端已经监控到客户端强制关闭了连接,下面我们看下服务端是否已经释放了连接句柄,再次执行 netstat命令,执行结果如图23-3所示。

从执行结果可以看出,服务端已经关闭了和客户端的TCP连接,句柄资源正常释放由此可以得出结论,Netty底层已经自动对该故障进行了处理。
下面我们一起看下Netty是如何感知到链路关闭异常并进行正确处理的,查看AbstractByteBuf的 writeBytes方法,它负责将指定Channel的缓冲区数据写入到 ByteBuf中,详细代码如下。
在调用 SocketChannel的read方法时发生了 IOException,从 Channel中读取数据报道缓冲区中的代码如下:
为了保证IO异常被统一处理,该异常向上抛,由 NioByteUnsafe进行统一异常处理,代码如下:
2.1.3、链路关闭
对于短连接协议,例如HTTP协议,通信双方数据交互完成之后,通常按照双方的约定由服务端关闭连接,客户端获得TCP连接关闭请求之后,关闭自身的 Socket连接,双方正式断开连接。
在实际的NIO编程过程中,经常存在一种误区:认为只要是对方关闭连接,就会发生IO异常,捕获IO异常之后再关闭连接即可。实际上,连接的合法关闭不会发生IO异常,它是一种正常场景,如果遗漏了该场景的判断和处理就会导致连接句柄泄漏。
下面我们一起模拟故障,看Netty是如何处理的。测试场景设计如下:改造下Netty客户端,双发链路建立成功之后,等待120s,客户端正常关闭链路。看服务端是否能够感知并释放句柄资源。
首先启动Netty客户端和服务端,双方TCP链路连接正常,如图23-4所示。
120S之后,客户端关闭连接,进程退出,为了能够看到整个处理过程,我们在服务端的 Reactor线程处设置断点,先不做处理,此时链路状态如图23-5所示。

从上图可以看出,此时服务端并没有关闭 Socket连接,链路处于 CLOSE_WAIT状态,放开代码让服务端执行完,结果如图23-6所示。
下面我们一起看下服务端是如何判断出客户端关闭连接的,当连接被对方合法关闭后,被关闭的 SocketChannel会处于就绪状态, SocketChannel的read操作返回值为-1,说明连接已经被关闭, NioByteUnsafe的 read()代码片段如下:
如果 SocketChannel被设置为非阻塞,则它的read操作可能返回三个值:
1.大于0:表示读取到了字节数
2.等于0:没有读取到消息,可能TCP处于Kep- Alive状态,接收到的是TCP握手消息
3.-1:连接已经被对方关闭。
Netty通过判断 ChannelRead操作的返回值进行不同的逻辑处理,如果返回-1,说明链路已经关闭,则调用 closeOnRead方法关闭句柄,释放资源,代码如下:
己方或者对方主动关闭链接并不属于异常场景,因此不会产生 Exception事件通知Pipeline。
2.1.4、定制I/O故障
在大多数场景下,当底层网络发生故障的时候,应该由底层的NIO框架负责释放资源,处理异常等。上层的业务应用不需要关心底层的处理细节。但是,在一些特殊的场景下,用户可能需要感知这些异常,并针对这些异常进行定制处理,例如:
1.客户端的断连重连机制;
2.消息的缓存重发
3.接口日志中详细记录故障细节
4.运维相关功能,例如告警、触发邮件/短信等
Netty的处理策略是发生IO异常,底层的资源由它负责释放,同时将异常堆栈信息以事件的形式通知给上层用户,由用户对异常进行定制。这种处理机制既保证了异常处理的安全性,也向上层提供了灵活的定制能力。
具体接口定义以及默认实现(ChannelHandlerAdapter类)如下:
2.2、链路的有效性检测
当网络发生单通、连接被防火墙Hang住、长时间GC或者通信线程发生非预期异常时,会导致链路不可用且不易被及时发现。特别是异常发生在凌晨业务低谷期间,当早晨业务髙峰期到来时,由于链路不可用会导致瞬间的大批量业务失败或者超时,这将对系统的可靠性产生重大的威胁。
从技术层面看,要解决链路的可靠性问题,必须周期性的对链路进行有效性检测。目前最流行和通用的做法就是心跳检测。
心跳检测机制分为三个层面:
1.TCP层面的心跳检测,即TCP的Keep-Alive机制,它的作用域是整个TCP协议栈;
2.协议层的心跳检测,主要存在于长连接协议中。例如SMPP协议;
3.应用层的心跳检测,它主要由各业务产品通过约定方式定时给对方发送心跳消息实现
心跳检测的目的就是确认当前链路可用,对方活着并且能够正常接收和发送消息。做为高可靠的NIO框架, Netty也提供了心跳检测机制,下面我们一起熟悉下心跳的检测原理。
心跳检测的原理示意图如图23-7所示。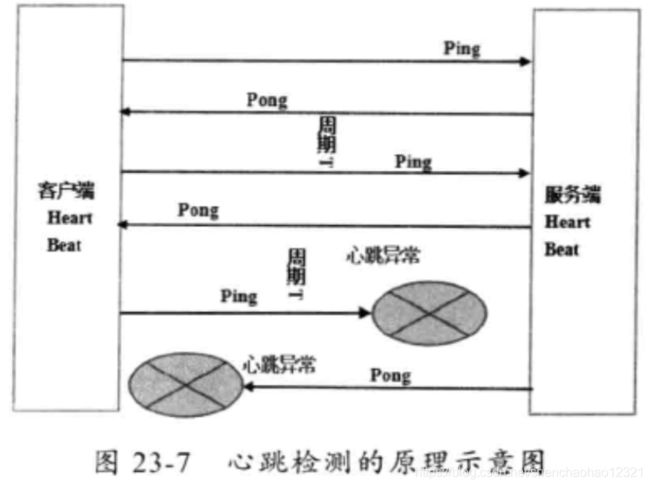
不同的协议,心跳检测机制也存在差异,归纳起来主要分为两类
1.Ping-Pong型心跳:由通信一方定时发送Ping消息,对方接收到Ping消息之后,立即返回Pong应答消息给对方,属于请求-响应型心跳。
2.Ping-Ping型心跳:不区分心跳请求和应答,由通信双方按照约定定时向对方发送心跳Ping消息,它属于双向心跳。
心跳检测策略如下:
1.连续N次心跳检测都没有收到对方的Pong应答消息或者Ping请求消息,则认为链路已经发生逻辑失效,这被称作心跳超时。
2.读取和发送心跳消息的时候如果直接发生了IO异常,说明链路已经失效,这被称为心跳失败。
无论发生心跳超时还是心跳失败,都需要关闭链路,由客户端发起重连操作,保证链路能够恢复正常。
Netty的心跳检测实际上是利用了链路空闲检测机制实现的,相关代码包路径如图23-8所示。
Netty提供的空闲检测机制分为三种
1.读空闲,链路持续时间t没有读取到任何消息
2.写空闲,链路持续时间t没有发送任何消息;
3.读写空闲,链路持续时间t没有接收或者发送任何消息。
Netty的默认读写空闲机制是发生超时异常,关闭连接,但是,我们可以定制它的超时实现机制,以便支持不同的用户场景
WriteTimeoutHandler的超时接口如下:
protected void writeTimedOut(ChannelHandlerContext ctx) throws Exception {
if (!closed) {
ctx.fireExceptionCaught(WriteTimeoutException.INSTANCE);
ctx.close();
closed = true;
}
}
链路空闲的时候并没有关闭链路,而是触发 IdleStateEvent事件,用户订阅IdleStateEvent事件,用于自定义逻辑处理,例如关闭链路、客户端发起重新连接、告警和打印日志等。利用Netty提供的链路空闲检测机制,可以非常灵活的实现协议层的心跳检测。
2.3、Reactor线程的保护
Reactor线程是IO操作的核心,NIO框架的发动机,一旦出现故障,将会导致挂载在其上面的多路用复用器和多个链路无法正常工作。因此它的可靠性要求非常高。
笔者就曾经遇到过因为异常处理不当导致 Reactor线程跑飞,大量业务请求处理失败的故障。下面我们一起看下Netty是如何有效提升 Reactor线程的可靠性的。
2.3.1、异常处理要谨慎
尽管 Reactor线程主要处理IO操作,发生的异常通常是IO异常,但是,实际上在一些特殊场景下会发生非IO异常,如果仅仅捕获IO异常可能就会导致 Reactor线程跑飞。
为了防止发生这种意外,在循环体内一定要捕获 Throwable,而不是IO异常或者 Exceptton。
Netty的 NioEventLoop代码如下;
捕获 Throwable之后,即便发生了意外未知异常,线程也不会跑飞,它休眠1S,防止死循环导致的异常绕接,然后继续恢复执行。这样处理的核心理念就是:
1.某个消息的异常不应该导致整条链路不可用;
2.某条链路不可用不应该导致其他链路不可用;
3.某个进程不可用不应该导致其他集群节点不可用
2.3.2、规避NIO BUG
通常情况下,死循环是可检测、可预防但是无法完全避免的。 Reactor线程通常处理的都是IO相关的操作,因此我们重点关注IO层面的死循环。
JDK NIO类库最著名的就是 epoll bug了,它会导致 Selector空轮询,IO线程CPU100%,严重影响系统的安全性和可靠性。SUN在JKD16 update18版本声称解决了该BUG,但是根据业界的测试和大家的反馈,直到JDK1.7的早期版本,该BUG依然存在,并没有完全被修复。
SUN在解决该BUG的问题上不给力,直到JDK1.7版本也没有完全修复。使用者只能从NIO框架层面进行问题规避,下面我们看下Netty是如何解决该问题的。
Netty的解决策略:
1.根据该BUG的特征,首先侦测该BUG是否发生
2.将问题 Selector上注册的 Channel转移到新建的 Selector上;
3.老的问题 Selector关闭,使用新建的 Selector替换
下面具体看下代码,首先检测是否发生了该BUG(NioEventLoop的 select())。
一旦检测发生该BUG,则重建 Selector,代码如下:
重建完成之后,替换老的 Selector,代码如下:
经过大量生产系统的运行验证, Netty的规避策略可以解决 epoll bug导致的IO线程CPU死循环问题。
2.4、内存保护
NIO通信的内存保护主要集中在如下几点:
1.链路总数的控制:每条链路都包含接收和发送缓冲区,链路个数太多容易导致内存溢出;
2.单个缓冲区的上限控制:防止非法长度或者消息过大导致内存溢出;
3.缓冲区内存释放:防止因为缓冲区使用不当导致的内存泄露
4.NIO消息发送队列的长度上限控制
2.4.1、缓冲区的内存泄漏保护
为了提升内存的利用率, Netty提供了内存池和对象池。但是,基于缓存池实现以后需要对内存的申请和释放进行严格的管理,否则很容易导致内存泄漏。
如果不采用内存池技术实现,每次对象都是以方法的局部变量形式被创建,使用完成之后,只要不再继续引用它,JVM会自动释放。但是,一旦引入内存池机制,对象的生命周期将由内存池负责管理,这通常是个全局引用,如果不显式释放JVM是不会回收这部分内存的。
对于Netty的用户而言,使用者的技术水平差异很大,一些对JVM内存模型和内存泄漏机制不了解的用户,可能只记得申请内存,忘记主动释放内存,特别是JAVA程序员。
为了防止因为用户遗漏导致内存泄漏, Netty在 Pipeline的尾 Handler中自动对内存进行释放, TailHandler的内存回收代码如下:
对于内存池,实际就是将缓冲区重新放到内存池中循环使用, PooledByteBuf的内存回收代码如下:
对于实现了 AbstractReferenceCountedByteBuf的 ByteBuf,内存申请、使用和释放的时候 Netty都会自动进行引用计数检测,防止非法使用内存。
2.4.2、缓冲区溢出保护
做过协议栈的读者都知道,当我们对消息进行解码的时候,需要创建缓冲区。缓冲区的创建方式通常有两种:
1.容量预分配,在实际读写过程中如果不够再扩展;
2.根据协议消息长度创建缓冲区
在实际的商用环境中,如果遇到畸形码流攻击、协议消息编码异常、消息丢包等问题时,可能会解析到一个超长的长度字段。笔者曾经遇到过类似问题,报文长度字段值竟然是2G多,由于代码的一个分支没有对长度上限做有效保护,结果导致内存溢出。系统重启后几秒内再次内存溢出,幸好及时定位出问题根因,险些酿成严重的事故。
Netty提供了编解码框架,因此对于解码缓冲区的上限保护就显得非常重要。下面我们看下Netty是如何对缓冲区进行上限保护的:
首先,在内存分配的时候指定缓冲区长度上限:
其次,在对缓冲区进行写入操作的时候,如果缓冲区容量不足需要扩展,首先对最大容量进行判断,如果扩展后的容量超过上限,则拒绝扩展:
在消息解码的时候,对消息长度进行判断,如果超过最大容量上限,则抛出解码异常,拒绝分配内存,以 LengthFieldBasedFrameDecoder的 decode方法为例进行说明:
2.5、流量整形
大多数的商用系统都有多个网元或者部件组成,例如参与短信互动,会涉及手机、基站、短信中心、短信网关、SPCP等网元。不同网元或者部件的处理性能不同。为了防止因为浪涌业务或者下游网元性能低导致下游网元被压垮,有时候需要系统提供流量整形功能。
下面我们一起看下流量整形(traffic shaping)的定义:流量整形(Traffic Shaping)是一种主动调整流量输出速率的措施。一个典型应用是基于下游网络结点的TP指标来控制本地流量的输岀。流量整形与流量监管的主要区别在于,流量整形对流量监管中需要丢弃的报文进行缓存——通常是将它们放入缓冲区或队列内,也称流量整形(Traffic Shaping,简称TS)。当令牌桶有足够的令牌时,再均勺的向外发送这些被缓存的报文。流量整形与流量监管的另一区别是,整形可能会增加延迟,而监管几乎不引入额外的延迟流量整形的原理示意图如图23-10所示。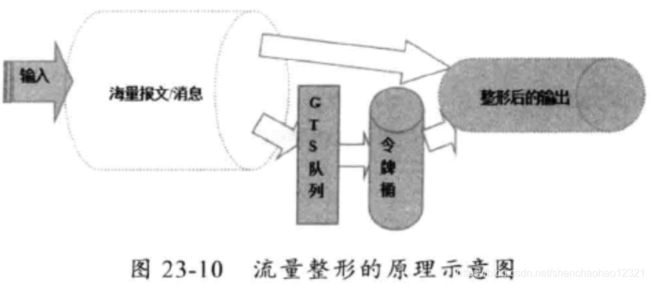
作为高性能的NIO框架,Netty的流量整形有两个作用
1.防止由于上下游网元性能不均衡导致下游网元被压垮,业务流程中断
2.防止由于通信模块接收消息过快,后端业务线程处理不及时导致的“撑死”问题。
下面我们就具体学习下 Netty的流量整形功能。
2.5.1、全局流量整形
全局流量整形的作用范围是进程级的,无论你创建了多少个 Channel,它的作用域针对所有的 Channel。
用户可以通过参数设置:报文的接收速率、报文的发送速率、整形周期。
GlobalTrafficShapingHandler的接口定义如下所示:
Netty流量整形的原理是:对每次读取到的ByteBuf可写字节数进行计算,获取当前的报文流量,然后与流量整形阈值对比。如果已经达到或者超过了阈值。则计算等待时间delay,将当前的 ByteBuf放到定时任务Task中缓存,由定时任务线程池在延迟 delay之后继续处理该 ByteBuf。相关代码如下: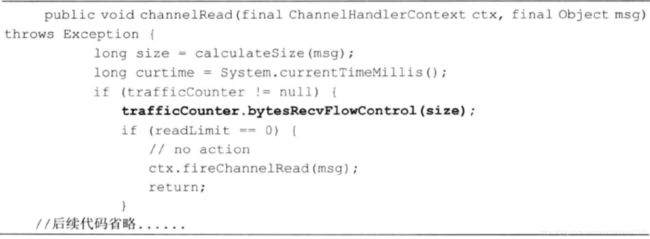
如果达到整形阈值,则对新接收的 ByteBuf进行缓存,放入线程池的消息队列中,稍后处理,代码如下:
定时任务的延时时间根据检测周期T和流量整形阈值计算得来,代码如下:
需要指出的是,流量整形的阈值 limit越大,流量整形的精度越高,流量整形功能是可靠性的一种保障,它无法做到100%的精确。这个跟后端的编解码以及缓冲区的处理策略相关,此处不再赘述。感兴趣的朋友可以思考下, Netty为什么不做到100%的精确。
流量整形与流控的最大区别在于流控会拒绝消息,流量整形不拒绝和丢弃消息,无论接收量多大,它总能以近似恒定的速度下发消息,跟变压器的原理和功能类似。
2.5.2、链路级流量整形
除了全局流量整形,Netty也支持链路级的流量整形, ChannelTrafficShapingHandler接口定义如下:
public ChannelTrafficShapingHandler(long writeLimit,
long readLimit, long checkInterval) {
super(writeLimit, readLimit, checkInterval);
}单链路流量整形与全局流量整形的最大区别就是它以单个链路为作用域,可以对不同的链路设置不同的整形策略。
它的实现原理与全局流量整形类似,我们不再赘述。值得说明的是,Netty支持用户自定义流量整形策略,通过继承 AbstractTrafficShapingHandler的 doAccounting方法可以定制整形策略。相关接口定义如下:
protected void doAccounting(TrafficCounter counter) {
// NOOP by default
}2.6、优雅停机接口
Java的优雅停机通常通过注册JDK的 ShutdownHook来实现,当系统接收到退出指令后,首先标记系统处于退出状态,不再接收新的消息,然后将积压的消息处理完,最后调用资源回收接口将资源销毁,最后各线程退出执行。
通常优雅退出有个时间限制,例如30S,如果到达执行时间仍然没有完成退出前的操作,则由监控脚本直接kill - 9 pid,强制退出。
Netty的优雅退出功能随着版本的优化和演进也在不断的增强,下面我们一起看下Netty的优雅退出。
首先看下 Reactor线程和线程组,它们提供了优雅退出接口。 EventExecutorGroup的接口定义如下:
/**
* Signals this executor that the caller wants the executor to be shut down. Once this method is called,
* {@link #isShuttingDown()} starts to return {@code true}, and the executor prepares to shut itself down.
* Unlike {@link #shutdown()}, graceful shutdown ensures that no tasks are submitted for 'the quiet period'
* (usually a couple seconds) before it shuts itself down. If a task is submitted during the quiet period,
* it is guaranteed to be accepted and the quiet period will start over.
*
* @param quietPeriod the quiet period as described in the documentation
* @param timeout the maximum amount of time to wait until the executor is {@linkplain #shutdown()}
* regardless if a task was submitted during the quiet period
* @param unit the unit of {@code quietPeriod} and {@code timeout}
*
* @return the {@link #terminationFuture()}
*/
Future shutdownGracefully(long quietPeriod, long timeout, TimeUnit unit);NioEventLoop的资源释放接口实现:
@Override
protected void cleanup() {
try {
selector.close();
} catch (IOException e) {
logger.warn("Failed to close a selector.", e);
}
}ChannelPipeline的关闭接口如图23-11所示。

目前Netty向用户提供的主要接口和类库都提供了资源销毁和优雅退出的接口,用户的自定义实现类可以继承这些接口,完成用户资源的释放和优雅退出。
3、优化建议
尽管Netty的可靠性已经做得非常出色,但是在生产实践中还是发现了一些待优化点,本小节将进行简单说明。希望后续的版本中可以解决,当然用户也可以根据自己的实际需要决定自行优化。
3.1、发送队列容量上限控制
Netty的NlO消息发送队列 ChannelOutboundBuffer并没有容量上限控制,它会随着消息的积压自动扩展,直到达到0x7fffffff。
如果网络对方处理速度比较慢,导致TCP滑窗长时间为0;或者消息发送方发送速度过快,或者一次批量发送消息量过大,都可能会导致 ChannelOutBoundBuffer的内存膨胀,这可能会导致系统的内存溢出。
建议优化方式如下:在启动客户端或者服务端的时候,通过启动项的 ChannelOption设置发送队列的长度,或者通过-D启动参数配置该长度。
3.2、回推发送失败的消息
当网络发生故障的时候,Netty会关闭链路,然后循环释放待未发送的消息,最后通知监听 listener。
这样的处理策略值得商榷,对于大多数用户而言,并不关心底层的网络O异常,他们希望链路恢复之后可以自动将尚未发送的消息重新发送给对方,而不是简单的销毁Netty销毁尚未发送的消息,用户可以通过监听器来得到消息发送异常通知,但是却无法获取原始待发送的消息。如果要实现重发,需要自己缓存消息,如果发送成功,自己删除,如果发送失败,重新发送。这对于大多数用户而言,非常麻烦,用户在开发业务代码的同时,还需要考虑网络lO层的异常并为之做特殊的业务逻辑处理。
下面我们看下Mina的实现,当发生链路异常之后,Mina会将尚未发送的整包消息队列封装到异常对象中,然后推送给用户 Handler,由用户来决定后续的处理策略。相比于Netty的“野蛮”销毁策略,Mina的策略更灵活和合理,由用户自己决定发送失败消息的后续处理策。
大多数场景下,业务用户会使用RPC框架,他们通常不需要直接针对Netty编程,如果Netty提供了发送失败消息的回推功能,RPC框架就可以进行封装,提供不同的策略给业务用户使用,例如:
1.缓存重发策略:当链路发生异常之后,尚未发送成功的消息自动缓存,待链路恢复正常之后重发失败的消息;
2.失败删除策略:当链路发生异常之后,尚未发送成功的消息自动销毁,它可能是非重要消息,例如日志消息,也可能是由业务直接监听异常并做特殊处理;
3.其他策略