论文阅读之Fast RCNN
- 准备
- 0 VGGnetSimonyan and Zisserman 2014
- 思想
- 1 相关工作
- 2 作者的贡献
- 结构
- 1 ROI pooling
- 2 多任务损失函数
- 21 softmaxlog loss
- 22 regressionsmooth L1 loss
- 23 截断SVD优化
- 训练
- 1 初始化
- 2 微调
- 21 训练样本
- 22 ROI池化层的后向传播
- 主要结果
- 1 mAPmean Accuracy Precision
- 2 训练和测试时间
- 3 精调哪一个层
- 4 多任务损失函数好吗
- 5 Softmax还是SVM
- 6 更多的候选区好吗
- 一些问题
0 准备
0.0 VGGnet[Simonyan and Zisserman, 2014]
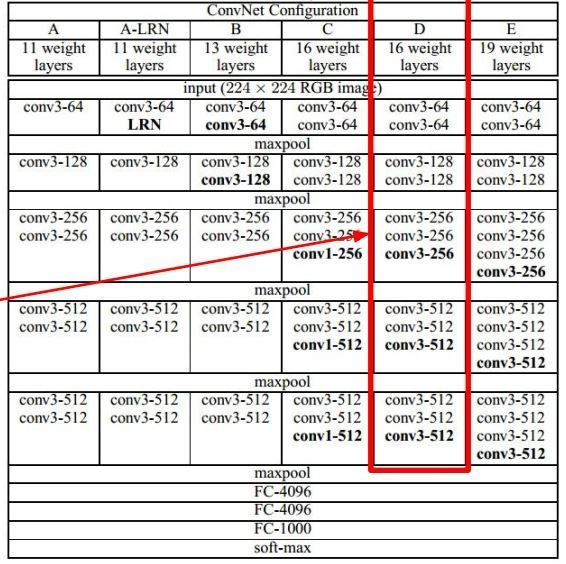
输入大小为224*224(全连接层要求输入是固定的)
13个卷积层(卷积核为3*3,stride=1,pad=1),3个全连接层(4096-4096-1000),5个池化层
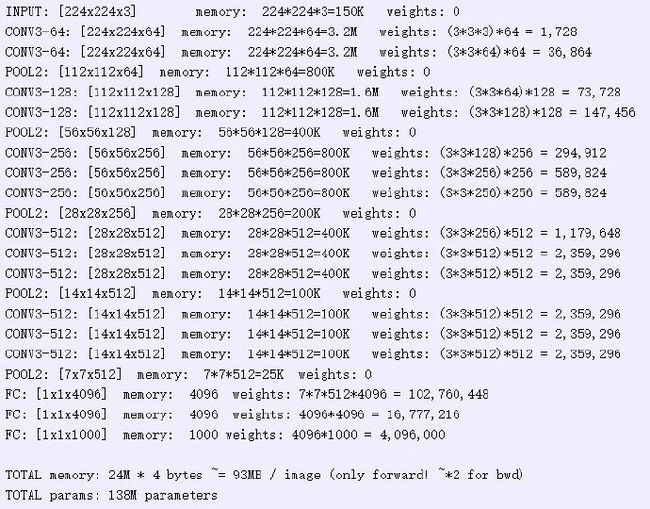
最后卷积层的输出是14*14*512,经过池化后的输出为7*7*512=25088
1 思想
1.1 相关工作
RCNN的训练是多级的
- 微调卷积网络(log loss)
- 训练SVM代替softmax
- 边框回归
PS:其实应该是Softmax也可以,只不过SVM的效果更好,那么多级训练的重点在将分类和回归结合起来(原文的边框回归使用的方法不详)
RCNN耗时耗空间
- 对每一个区域都要计算特征(其实好多区域是重叠的)
- 要想使用SVM,那么就要把每个区域的特征存储到硬盘上(网络不是一体的)
SPPnet不能更新卷积层
(对SPPnet的具体结构不了解)
从所有图片的所有RoI中均匀取样,这样每个SGD的mini-batch中包含了不同图像中的样本,反向传播需要计算每一个RoI感受野的卷积层梯度,通常所有RoI会覆盖整个图像,这样又慢又耗内存。
1.2 作者的贡献
- 使用多任务损失函数,一体化训练
- 使用ROI来共享特征计算
2 结构
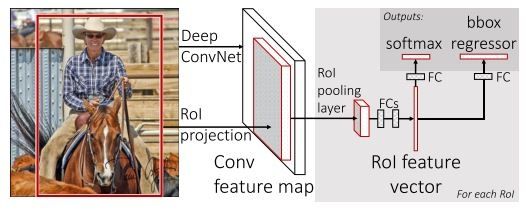
- 对整幅图像卷积得到特征(注意没有wrap,可以更好地保存特征)
- 候选区域映射到卷积特征图上
- ROI pooling得到固定长度的向量
- 将向量送入全连接层并计算分类和回归损失
2.1 ROI pooling

- 将候选区域对应的卷积特征图划分成固定的H*W等份
- 每一等份做最大池化
- 得到H*W长的向量送入全连接层
由VGGnet的结构,实际上向量的长度是c*H*W=512*7*7=25088
一点理解:
7x7表示的是包含了图像的位置和特征(联想提取边缘),512是不同的特征
原来的最大池化是等比例缩小,可以保证尺度不变性。如果对原图缩放,会失去图像的尺度信息,而如果是对特征缩放,效果会更好一点(但是感觉好像是一样的。。。)
所以,怎样可以保持图像的尺度不变显得尤为重要(或许overfeat将网络改成全连接层就是这个思想?)
2.2 多任务损失函数
2.2.1 softmax(log loss)
利用特征可以进行分类(假设是线性)
Q1:特征怎样进行分类
对K个类,经过线性加权(最后的全连接层)得到K+1个分数
我们希望真正的类分数越高越好(用概率来衡量)。
训练的时候要使最后的总得分最高(总概率最大)
注意,现在分类的正确率可以达到一个很高的水平
2.2.2 regression(smooth L1 loss)
Q1:为什么可以根据特征做回归?
根据特征,进行加权得到缩放和平移参数(比如你从特征中知道有人和背景,那么你就可以调整人的位置)
Q2:怎样根据特征做回归
假设有K类
对每一个候选区域,得到一个K*4个回归值t
根据ground truth,得到候选区域的真实回归值v
假设ground truth的类别为u(背景用0表示),计算t和v之间的L1 loss
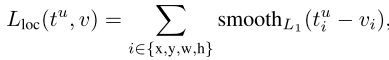
其中
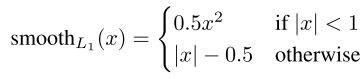
这里使用的是smooth L1 loss,主要是因为smooth L1 loss对异常值不敏感
###2.2.3 multi-task loss
将分类误差和回归误差组合起来,实验使用的lamda=1
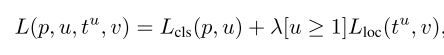
2.2.3 截断SVD优化
![]()
因为测试的时候每次都要计算20488*4096(fc6的矩阵乘法),计算起来特别耗时间(122ms,卷积层才使用146ms)。所以,对权值矩阵做一个SVD分解(主成分分析),然后取t个分量计算即可(不考虑SVD的时间的话,降到了37ms)
3 训练
3.1 初始化
使用预训练的ImageNet网络
Image ——> Image + ROI
max pooling ——> ROI pooling (2等分变成7等分,输出相同)
FC(4096-1000)+softmax ——> FC+softmax over K+1 categories && FC + BB
3.2 微调
3.2.1 训练样本:
stochastic gradient descent (SGD) mini- batches are sampled hierarchically, first by sampling N images and then by sampling R/N RoIs from each image. Critically, RoIs from the same image share computation and memory in the forward and backward passes.
论文中使用了N =2 and R = 128,缺点是可能收敛比较慢
IOU 的门限使用了 0.5
3.2.2 ROI池化层的后向传播
参考池化层的后向传播,但要考虑一个mini-batch里面ROI是重叠的,所以最后的梯度要累加(太细节不需要考虑)
4 主要结果
4.1 mAP(mean Accuracy Precision)
AP表示准确率,是指所有检测样本中被正确检测样本的比率
Recision表示召回率,是指所有应该检测的样本被检测出来的概率
| * | 相关 | 不相关 |
|---|---|---|
| 检索到的 | 99 | 1 |
| 未检索到的 | 5 | 95 |
那么准确率是99/(99+1)=99%,召回率是99/(99+5)
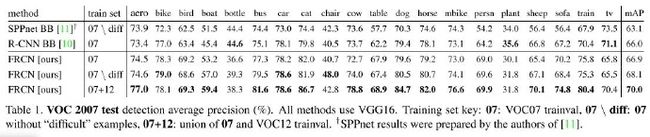
相比SPPnet,因为微调了卷积层,还有使用了多任务损失函数,所以大约有3%的提升
相比RCNN,因为多任务损失函数,大约有0.9%的提升(提升程度不大)
4.2 训练和测试时间
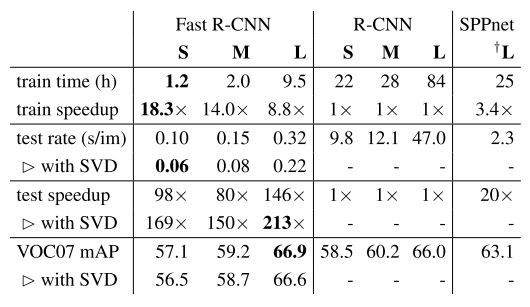
只考虑大型网络,Fast-RCNN的时间相当快(ROI,single-stage),处理一张图片大约花费0.22s
4.3 精调哪一个层?

一般来说,越靠近输入层,得到的特征越泛化,微调的必要性就不是很大(当然如果数据量大的话微调所有层应该会更好)。
4.4 多任务损失函数好吗?

多任务损失函数比多阶段的训练结果大约有3%的提升,这个也只是实验证明,并没有充分的解释(也有可能只是作者使用方法的问题)
4.5 Softmax还是SVM?
从结果来看,使用Softmax和SVM的结果相差不大
作者的解释
We note that softmax, unlike one-vs-rest SVMs, introduces competition between classes when scoring a RoI
4.6 更多的候选区好吗?
原文中使用了2k个候选区域和45k个候选区域进行实验,得到结果
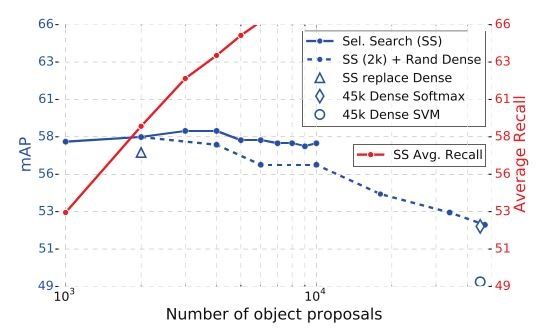
对于召回率来说,更多的区域意味着更多被监测的可能性,所以会增加
但对于准确率,更多的区域带来更大的误检率,所以准确度会下降
5 一些问题
Q1:ROI pooling的现实意义是什么?会影响特征吗?
Q2:原文强调的尺度不变性是什么?
- Brute force learning:
采用单一的固定的尺寸大小,让网络自己从数据中学习到尺度不变性 - Image pyramid:
输入多尺度的图片
(论文中采用第一种方法,第二种由于GPU显存的设置,在大型网络上实现不了)
实验结果:

结论:
采用图像金字塔的方法对准确率提高不大,而图像金字塔的方法十分耗时耗空间 在速度和准确率的权衡上,也许brute force learning 的方法更具实际意义。