在此博客中,我们将讨论一些需要扩展的微服务应用程序中经常使用的模式:
- 事件流
- 活动采购
- 多语言持久性
- 内存映像
- 命令查询责任分离
动机
Uber , Gilt和其他公司已经从单一架构转变为微服务架构,因为它们需要扩展。 整体应用程序将其所有功能置于单个进程中,扩展需要复制整个应用程序,这有其局限性。
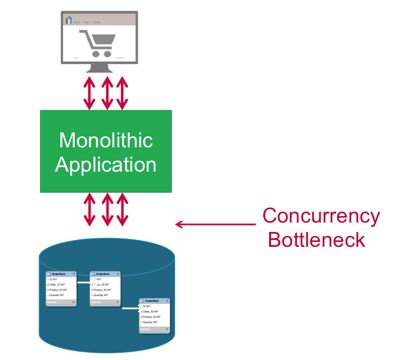
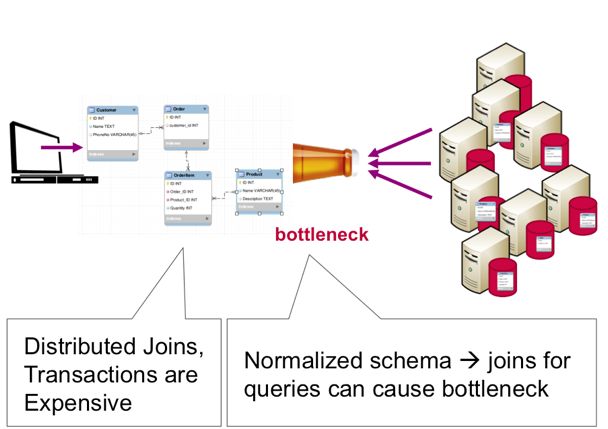
在分布式RDBMS中共享规范化表无法很好地扩展,因为分布式事务和联接可能会导致并发瓶颈。
微服务架构风格是一种将应用程序开发为围绕特定业务功能构建的小型独立可部署服务套件的方法。 微服务方法非常适合典型的大数据部署 。 通过在许多商用硬件服务器上部署服务,可以获得模块化,广泛的并行性和具有成本效益的扩展。 微服务模块化促进了独立的更新/部署,并有助于避免单点故障,从而有助于防止大规模中断。
事件流
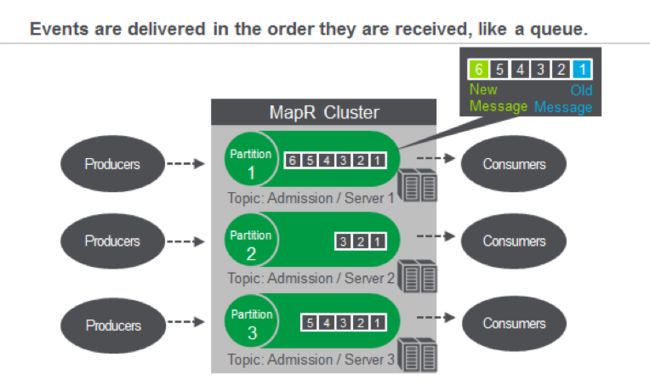
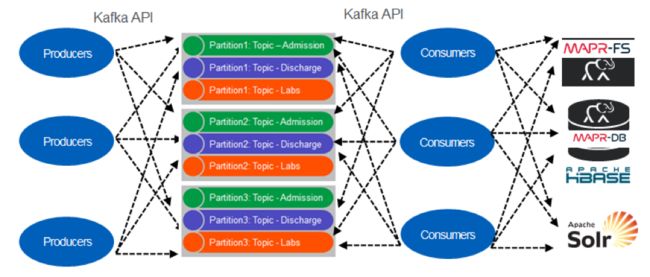
从单块架构过渡到微服务架构时,一种常见的架构模式是使用仅附加事件流(例如Kafka或MapR Streams(提供Kafka 0.9 API))进行事件源。 使用MapR Streams(或Kafka),事件被分组为称为主题的事件的逻辑集合。 主题已分区以进行并行处理。 您可以将分区的主题想成一个队列,事件按照接收的顺序传递。
与队列不同,事件是持久的,即使事件交付后仍保留在分区上,可供其他使用者使用。

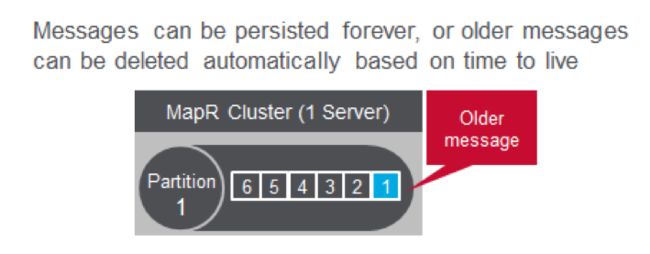
较旧的消息将根据Stream的生存时间设置自动删除,如果设置为0,则永远不会删除它们。
阅读时不会从主题中删除消息,并且主题可以具有多个不同的使用者,这允许不同的使用者出于不同的目的处理相同的消息。 当消费者丰富事件并将其发布到另一个主题时,也可以进行管道传输。
活动采购
事件源是一种体系结构模式,其中应用程序的状态由一系列事件确定,每个事件记录在仅追加事件存储或流中。 例如,假设每个“事件”都是对数据库中条目的增量更新。 在这种情况下,特定条目的状态仅是与该条目有关的事件的累积。 在下面的示例中,Stream保留所有存款和取款事件的队列,而数据库表保留当前帐户余额。
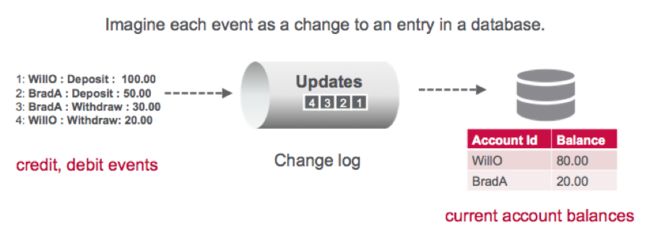
流或数据库中的哪一个使记录系统更好? 流中的事件可用于重建数据库中的当前帐户余额,但不能反过来。 数据库复制实际上是由供应商将更改写入更改日志,然后消费者在本地应用更改来进行的。 另一个众所周知的例子是源代码版本控制系统。

使用Stream,可以重放事件以创建数据的新视图,索引,缓存, 内存映像或实例化视图。
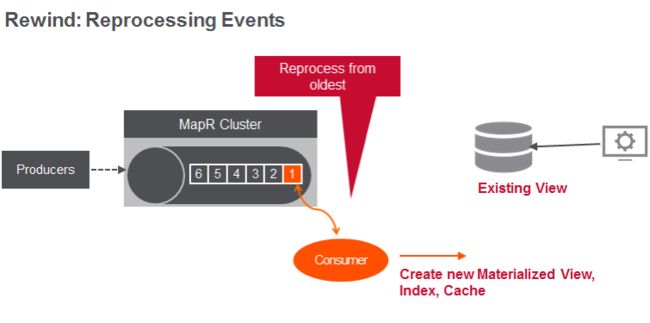
消费者只需从最早的消息到最新的消息,就可以创建新的数据视图。
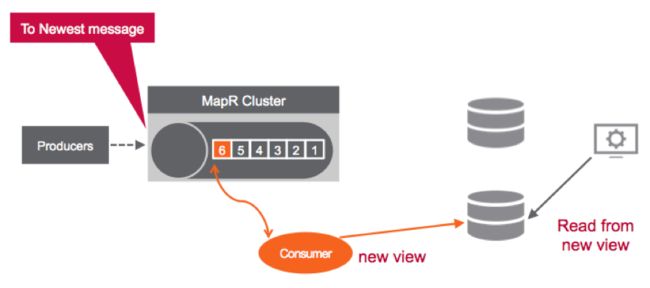
使用流对应用程序状态进行建模有几个优点:
- 传承 :问布拉达的余额怎么这么低?
- 审核 :它提供了审核跟踪,谁从帐户ID BradA中存款/退出了? 这就是会计交易的工作方式。
- 快退 :查看去年的帐户状态。
- 完整性 :我可以相信数据未被篡改吗?
- 是的,因为流是不可变的。
MapR流的复制提供了强大的测试和调试技术。 Stream的副本可用于重放事件的版本,以进行测试或调试。

满足不同需求的不同数据库和模式
有很多数据库,每种数据库根据数据的使用方式使用不同的技术 ,针对一种写入或读取模式进行了优化:图形查询,搜索,文档……如果您需要针对不同的数据使用相同的数据集该怎么办数据库,用于不同类型的查询? 流可以充当多个数据库的分发点,每个数据库提供不同的读取模式。 对应用程序状态的所有更改都保存到事件存储中,该存储是记录系统。 事件存储通过重新运行流中的事件来提供重建状态。
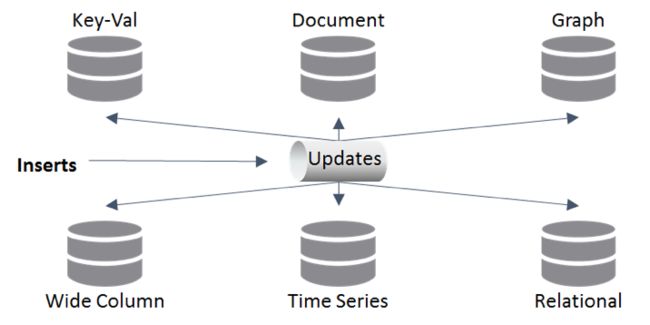
事件会泄漏到流的使用者数据库中。 多种语言的持久性提供了不同的专门的物化视图。
CQRS
命令和查询责任隔离(CQRS)是一种模式,用于将读取模型和查询与写入模型和通常使用事件源的命令分开。 让我们看一下如何使用CQRS模式来分离在线购物应用程序的商品评分功能。 下面在整体应用程序中显示的功能包括:用户对自己购买的商品进行评级,以及在购物时浏览商品评级。

在下面显示的CQRS设计中,我们使用事件源将“评分项目”写入“命令”与“获取项目评分”读取“查询”分离并分离。 评价项目事件将发布到流中。 处理程序进程从流中读取并在NoSQL文档样式数据库中保留项目等级的物化视图。


NoSQL和反规范化
使用MapR-DB时 ,表会根据键范围自动在整个群集中分区,并且每个服务器都是表子集的源。 按键范围对数据进行分组可提供真正快速的按行键读写。 使用MapR-DB,您可以设计架构,以便将一起读取的数据存储在一起 。

通常使用MapR-DB,您可以将一个规范化的关系数据库中的多个表归一化或存储在一个表中。 如果您的实体存在一对多关系,则可以在MapR-DB HBase中将其建模为单行,或者在MapR-DB JSON中将其建模为单个文档。 在下面的示例中,项目和相关的等级存储在一起,并且可以与索引行键上的单个get一起读取。 这使读取比将表连接在一起要快得多。
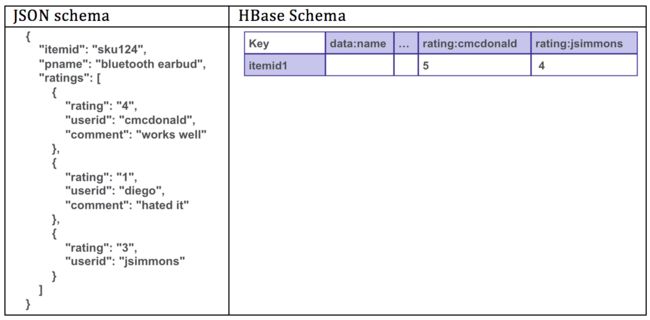
事件来源:数据的新用途
此处显示了将事件流用于费率项目和其他与购物相关的事件的优势。 这种设计使我们可以更广泛地使用此数据。 原始事件或丰富事件可以存储在便宜的存储中,例如MapR-FS 。 历史评级数据可用于构建建议的机器学习模型。 在队列中保留较长的数据保留时间也非常有用。 例如,可以处理该数据以构建以诸如Parquet之类的数据格式存储的购物交易历史记录的集合,该数据格式允许非常有效的查询。 其他流程可能会使用历史数据和与流媒体购物相关的事件以及机器学习来预测购物趋势 , 检测欺诈或建立交易发生位置的实时显示。
时装零售商的事件驱动架构
一家大型时装零售商希望提高季节敏捷性和库存纪律,以应对需求变化并减少降价促销。 事件驱动的解决方案架构如下所示:
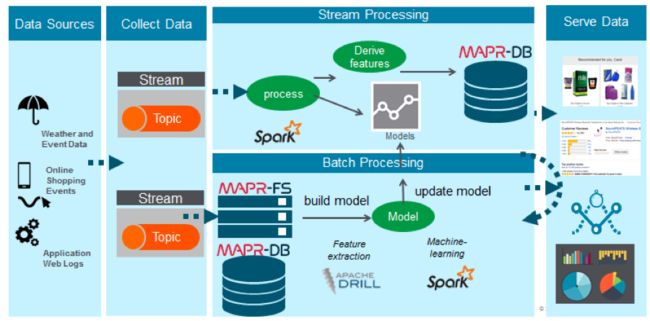
- 天气,世界事件和后勤数据是通过MapR Streams实时收集的,从而可以对潜在的后勤影响进行实时分析,并重新安排库存。
- Apache Spark用于批处理和流分析处理,以及用于预测供应链中断和产品推荐的机器学习。
- 数据存储在MapR-DB中,提供可伸缩的快速读写。 Apache Drill用于通过无模式SQL查询引擎进行交互式探索和预处理数据。
- 带有Drill的ODBC提供对现有BI工具的支持。
- MapR的企业功能提供了全球数据中心复制。
摘要
在此博客文章中,我们使用以下设计模式讨论了事件驱动的微服务架构: 事件源, 命令查询责任分离和多语种持久性 。 我们讨论的架构的所有组件都可以与MapR融合数据平台一起在同一集群上运行。
参考和更多信息
- 使用微服务构建企业应用程序的10大优势
- MapR的Jack Norris对微服务的影响
- 使用实时事件流和Spark机器学习进行欺诈检测
- 使用Apache API的实时流数据管道:Kafka,Spark流和HBase
- 流优先架构模式如何革新医疗平台
- MapR Streams页面
- 流数据架构电子书
- 颠倒数据库
- Kappa建筑
- 了解流处理
- Uber中的流处理
- Uber的事件驱动架构
- 不变性改变了一切
- NoSQL数据建模技术
翻译自: https://www.javacodegeeks.com/2017/02/event-driven-microservices-patterns.html