Excel:数据处理
一、数据处理的内容
数据处理的内容主要有以下两项:
1.数据清洗。将多余重复的数据筛选出来,并剔除;将缺失的数据补足,将错误的数据纠正或删除。
2.数据加工。对清洗过后的数据进行字段的信息提取、计算、分组、转换等处理。
二、数据清洗
1.重复数据的处理

第一步,找出重复数据。
方法1:函数法
COUNTIF(range,criteria),对区域中满足单个指定条件的单元格进行计数。
- range:要计数的单元格范围。
- criteria:计算条件,可以为数字、表达式或文本,如32、>32或“三十二”。
在B2单元格输入=COUNTIF(A:A,A2),计算每一个员工编号出现的次数。
在C2单元格输入=COUNTIF(A$2:A2,A2),计算出现了两次及以上的重复项。以C9对应的编号为例,3表示从A1~A9,该编号是第3次出现。

方法2:高级筛选法


方法3:条件格式法


方法4:数据透视表

用数据透视表统计各项数据出现的频次,出现2次及以上为重复项。
第二步,删除重复数据。
方法1:通过菜单操作删除重复值



方法2:通过排序删除重复值

选择筛选功能,升序排序C列数据,删除大于1的数值即可。
方法3:通过筛选删除重复值


直接将筛选出来的重复值删除即可。
2.缺失数据的处理
在Excel中,缺失值一般以空值或错误标识符标记。那么,如何找出缺失值?
方法1:定位输入
适用情况:缺失值以空白单元格形式出现。
弹出定位对话框:
1.Ctrl+G组合键
2.开始–>编辑–>定位条件


如何处理缺失值?
方法1:用一个样本统计量的值代替缺失值。常用样本均值代替缺失值。
方法2:用一个统计模型计算出来的值代替缺失值。常用的模型有回归模型、判别模型等,需借助数据分析软件。
方法3:删除包含缺失值的数据记录。
方法4:保留包含缺失值的数据记录,分析时按需排除缺失值。
常用做法是,如果样本量比较大,一般采用定位查找功能一次性选出所有缺失值,再用Ctrl+Enter组合键填充样本均值。
方法2:查找替换
适用情况:缺失值以错误标识符形式出现。
以查找错误标识符“#DIV/0!”为例:
1.选中所有数据区域,按Ctrl+H组合键,弹出“查找和替换”对话框。
2.在“查找内容”中输入要搜索的文本或数字,在“替换为”中输入要替换成的内容,再单击“全部替换”按钮。

3.检查数据逻辑错误
以员工满意度问卷调查为例,错误数据出现的情况有:
1.被调查对象输入的选项不符合要求,比如,选择的选项超过了3个。
2.录入错误,比如,录入的数据出现了0、1之外的数据。
如何检查错误?
方法1:用IF函数检查错误情况1.
COUNT,计数。
COUNTIF,对满足指定条件的单元格进行计数。比如,COUNTIF(B3:H3,"<>0")表示“对B3:H3区域中不等于0的单元格进行计数”。
IF,判断逻辑值的真假。比如,IF(COUNTIF(B3:H3,"<>0")>3,"错误","正确")表示“如果录入的选项超过3个,则单元格显示’错误’,否则,显示’正确’”。
方法2:用条件格式检查错误情况2.
OR,或,至少一个为真,就范围TRUE。
AND,和,所有参数都为真,才返回TRUE。


三、数据加工
1.数据抽取
数据抽取,指保留某些字段的部分信息,组合成一个新字段。
1.字段分列,截取某一字段的部分信息;
2.字段合并,将某几个字段合并为一个新字段;
3.字段匹配,将原数据表中没有但其他表中有的字段匹配起来。
字段分列
方法1:菜单法。




方法2:函数法。

LEFT,截取字符串左边指定个数的字符。
RIGHT,截取字符串右边指定个数的字符。

字段合并
组合文本和数字的方式有:
1.CONCATENATE函数,如CONCATENATE(A2,"迟到",B2,"次")。
2.&运算符,如A2&“迟到”&B2&“次”。
TEXT函数
**作用:**在使用连接运算符连接数字和文本时,控制数字的显示方式。如果不用TEXT函数,则默认显示引用单元格的基本数据。比如,若单元格中数据为10%,不使用TEXT函数,合并后的数据则显示为0.1。
**注意:**合并数字和文本后,数据类型为文本,不能做数学运算。
字段匹配


如何将员工职位表中的职务信息提取到员工个人信息(销售部)表中?
1.在“员工个人信息(销售部)”表中F2单元格中输入=VLOOKUP(B2,[员工职位表.xlsx]Sheet1!$B$1:$D$11,3,0)。
2.复制单元格F2到F3:F7,完成数据提取。

VLOOKUP函数
作用:在表格的首列查找指定的数据,并返回指定的数据所在行中的指定列出的单元格内容。
- lookup_value:要在表中第一列查找的值,参数可以是值或引用。
- table_array:包含数据的单元格区域,可以是绝对区域或区域名称的引用。
- col_index_num:1,表示返回匹配值的列号,即返回table_array第一列中的值;2,表示返回匹配值的列号,即返回table_array第二列中的值,以此类推。
- range_lookup:近似匹配1,精确匹配0,常用0.
注意:table_array第一列的值必须是要查找的值(lookup_value),否则会出现错误标识“#N/A”。出现“#N/A”其他情况还有:
1.数据存在空格,可以用TRIM函数批量删除空格。
2.数据类型或格式不一致。
2.数据计算
2.1 简单计算
简单计算,能通过加减乘除计算出来的字段。
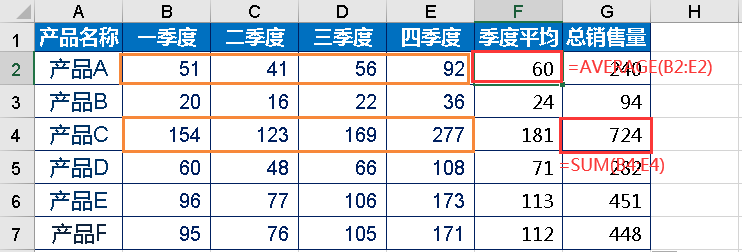
如下图,销售额=销售数量*单价,总销售额=∑各产品销售额。


2.2 函数计算
1.平均值与总和
AVERAGE():求平均值。
SUM():求和。
2.日期的加减法
输入当前系统时间/日期;
| 日期 | 公式 | 快捷键 |
|---|---|---|
| 2020/1/1 | =TODAY() | Ctrl+; |
| 13:39 | Ctrl+Shift+; | |
| 2009/1/1 | =NOW() | 1.Ctrl+; 2.按空格键 3.Ctrl+Shift+; |
DATE(year,month,day),返回指定日期。
YEAR(),返回某日期对应的年份。
MONTH(),返回以序列号表示的日其中的月份,用整数1~12表示。
DAY(),返回以序列号表示的日期的天数,用整数1~31表示。
DATEIF(start_date,end_date,unit),返回两个日期之间的年/月/日间隔数。unit有Y/M/D/YM/YD六种形式。
3.数据转换
3.1 数据表的行列互换
方法1:选择性粘贴。

方法2:Ctrl+Alt+V
3.2 多选题几种录入方式之间的转换
多选题的两种录入方式:
1.二分法,各选项用0和1表示该选项是否被录入。
2.多重分类法,直接录入选项的额代码。只能在SPSS里分析。
下图左边多重分类法中的“选项一”“选项二”“选项三”是多选题中选择的三个选项,比如,被调查者甲选的是A、B、C,那么B2:D2的单元格中分别输入1,2,3。

VLOOKUP,按列查找。
HLOOKUP(lookup_value,table_array,col_index_num,range_lookup),在表格的首行查找指定的数据,并返回指定的数据所在列中的指定行处的单元格内容。比如,HLOOKUP(1,B5:D5,1,0)表示“在B5:D5区域的第一行中查找数值1,找到数值1所在的列,返回该列对应的单元格区域的第一行数据,并精确匹配,否则,返回’#N/A’”。
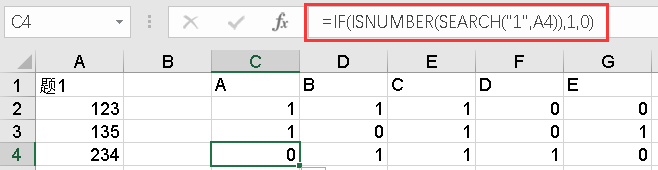
多重分类法转换为二分法录入数据,用SEARCH函数代替HLOOKUP函数。
| 函数/参数 | 含义 |
|---|---|
SEARCH(find_text,within_text,start_num) |
返回指定的字符串在原始字符串中首次出现的位置 |
find_text |
要查找的文本字符串 |
within_text |
要在哪一个字符串查找 |
start_num |
从within_text的第几个字符开始查找 |
例子如下,SEARCH("1",A4)表示在A4单元格的字符串中查找1。
4.数据分组
分组对应表如下图右表所示,用来确定分组的范围和标准。“阈值”,是每组覆盖的数值范围中的下限。“分组”,是每一组的组名。“备注”,是分组标准。

使用VLOOKUP实现数据分组,省略了最后一个参数range_lookup,默认近似匹配。这样,单元格B2公式不是在D列中查找0,而是查找接近A2,且不大于A2的值。“最接近且不大于”,如A5(=5.5),阈值中最接近A5且小于或等于A5的值是D2(=5),则对应的E2就是A5的分组。
四、数据抽样
普查,对总体中的对象都进行观察研究。
抽样调查,从总体中随机抽取部分样本进行分析。
RAND(),只能返回0~1之间的数。如要生成a ~ b之间的随机数,用公式=RAND()*(b-a)+a。
假设B列有表示100个人的编号(无表头),要随机抽取30个人,步骤如下:
1.对100个人生成不重复的序号,A1=1,A2=A1+1,……,A100=A99+1。
2.随机生成30个1~100的随机数,将公式=INT(RAND()*100复制到D列的30个单元格中。
3.参照A、B列,将D列随机数对应的编号匹配到E列中,将公式=VLOOKUP(D1,$A:$B,2,0)复制到E列的30个单元格中。
4.对抽取出来的编号去重,重复上述步骤,直到抽到了30个编号不重复的人。