玩转 Scrapy 框架 (二):Scrapy 架构、Request和Response介绍
目录
- 一、Scrapy 架构及目录源码分析
- 二、Request 和 Response 介绍
-
- 2.1 Request
- 2.2 Response
- 三、实例演示
-
- 3.1 POST 请求
- 3.2 GET 请求及响应信息打印
一、Scrapy 架构及目录源码分析
Scrapy 是一个基于 Python 开发的爬虫框架,可以说它是当前 Python 爬虫生态中最流行的爬虫框架,该框架提供了非常多爬虫的相关组件,架构清晰,可扩展性强。基于 Scrapy,我们可以灵活高效地完成各种爬虫需求。Scrapy 文档:https://docs.scrapy.org/en/latest/
首先从整体上看一下 Scrapy 框架的架构,如下图所示:
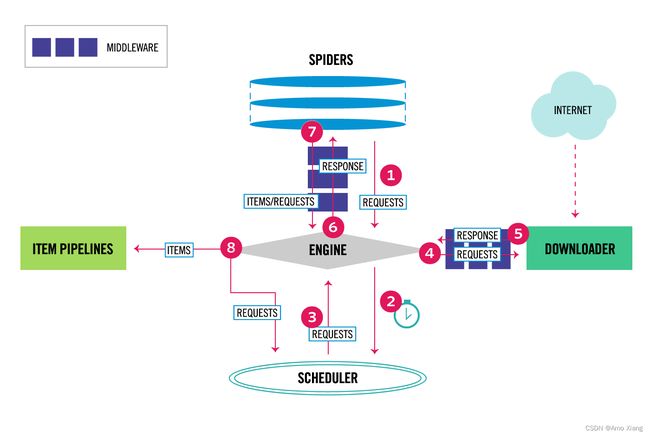
上图来源于 Scrapy 官方文档,初看上去可能比较复杂,下面我们来介绍一下。
Engine: 图中最中间的部分,中文可以称为引擎,用来处理整个系统的数据流和事件,是整个框架的核心,可以理解为整个框架的中央处理器(类似人的大脑),负责数据的流转和逻辑的处理。
Item: 它是一个抽象的数据结构,所以在图中没有体现出来,它定义了爬取结果的数据结构,爬取的数据会被赋值成 Item 对象。每个 Item 就是一个类,类里面定义了爬取结果的数据字段,可以理解为它用来规定爬取数据的存储格式。
Scheduler: 图中下方的部分,中文可以称为调度器,它用来接受 Engine 发过来的 Request 并将其加入队列中,同时也可以将 Request 发回给 Engine 供 Downloader 执行,它主要维护 Request 的调度逻辑,比如先进先出、先进后出、优先级进出等等。
Spiders: 图中上方的部分,中文可以称为蜘蛛,Spiders 是一个复数的统称,其可以对应多个 Spider,每个 Spider 里面定义了站点的爬取逻辑和页面的解析规则,它主要负责解析响应并生成 Item和新的请求然后发给 Engine 进行处理。
Downloader: 图中右侧部分,中文可以称为下载器,即完成 向服务器发送请求,然后拿到响应 的过程,得到的响应会再发送给 Engine 处理。
Item Pipelines: 图中左侧部分,中文可以称为项目管道,这也是一个复数统称,可以对应多个 Item Pipeline。Item Pipeline 主要负责处理由 Spider 从页面中抽取的 Item,做一些数据清洗、验证和存储等工作,比如将 Item 的某些字段进行规整,将 Item 存储到数据库等操作都可以由 Item Pipeline 来完成。
Downloader Middlewares: 图中 Engine 和 Downloader 之间的方块部分,中文可以称为下载器中间件,同样也是复数统称,其包含多个 Downloader Middleware,它是位于 Engine 和 Downloader 之间的 Hook 框架,负责实现 Downloader 和 Engine 之间的请求和响应的处理过程。
Spider Middlewares: 图中 Engine 和 Spiders 之间的方块部分,中文可以称为蜘蛛中间件,它是位于 Engine 和 Spiders 之间的 Hook 框架,负责实现 Spiders 和 Engine 之间的 Item,请求和响应的处理过程。
以上便是 Scrapy 中所有的核心组件,初看起来可能觉得非常复杂并且难以理解,但上手之后我们会慢慢发现其架构设计之精妙。
了解了 Scrapy 的基本组件和功能,通过图和描述我们可以知道,在整个爬虫运行的过程中,Engine 负责了整个数据流的分配和处理,数据流主要包括 Item、Request、Response 这三大部分,那它们又是怎么被 Engine 控制和流转的呢?结合官网的架构图来对数据流做一个简单说明:
- 启动爬虫项目时,Engine 根据要爬取的目标站点找到处理该站点的 Spider,Spider 会生成最初需要爬取的页面对应的一个或多个 Request,然后发给 Engine。
- Engine 从 Spider 中获取这些 Request,然后把它们交给 Scheduler 等待被调度
- Engine 向 Scheduler 索取下一个要处理的 Request,这时候 Scheduler 根据其调度逻辑选择合适的 Request 发送给 Engine
- Engine 将 Scheduler 发来的 Request 转发给 Downloader 进行下载执行,将 Request 发送给 Downloader 的过程会经由许多定义好的 Downloader Middlewares 的处理
- Downloader 将 Request 发送给目标服务器,得到对应的 Response,然后将其返回给 Engine。将 Response 返回 Engine 的过程同样会经由许多定义好的 Downloader Middlewares 的处理。
- Engine 从 Downloader 处接收到的 Response 里包含了爬取的目标站点的内容,Engine 会将此 Response 发送给对应的 Spider 进行处理,将 Response 发送给 Spider 的过程中会经由定义好的 Spider Middlewares 的处理
- Spider 处理 Response,解析 Response 的内容,这时候 Spider 会产生一个或多个爬取结果 Item 或者后续要爬取的目标页面对应的一个或多个 Request,然后再将这些 Item 或 Request 发送给 Engine 进行处理,将 Item 或 Request 发送给 Engine 的过程会经由定义好的 Spider Middlewares 的处理
- Engine 将 Spider 发回的一个或多个 Item 转发给定义好的 Item Pipelines 进行数据处理或存储的一系列操作,将 Spider 发回的一个或多个 Request 转发给 Scheduler 等待下一次被调度。
重复第2步到第8步,直到 Scheduler 中没有更多的 Request,这时候 Engine 会关闭 Spider,整个爬取过程结束。 从整体上来看,各个组件都只专注于一个功能,组件和组件之间的耦合度非常低,也非常容易扩展。再由 Engine 将各个组件组合起来,使得各个组件各司其职,互相配合,共同完成爬取工作。另外加上 Scrapy 对异步处理的支持,Scrapy 还可以最大限度地利用网络带宽,提高数据爬取和处理的效率。
二、Request 和 Response 介绍
在编写 Spider 时,我们大部分流程其实是在构造 Request 对象和解析 Response 对象,因此对于它们的用法和参数我们需要详细了解一下。
2.1 Request
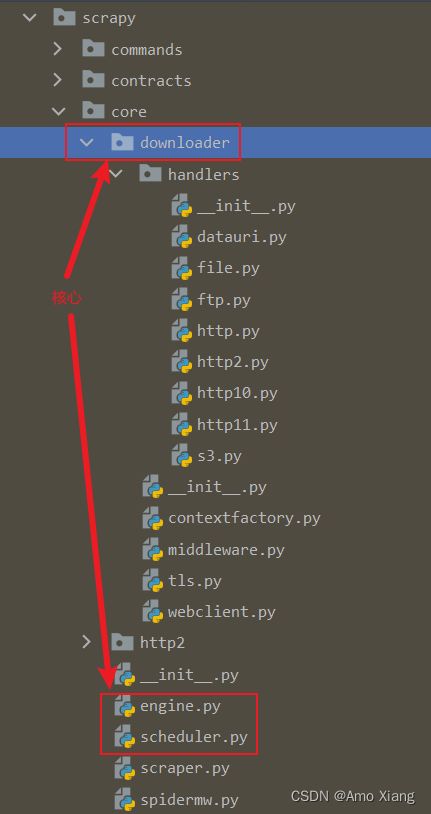
源码位置:

在 Scrapy 中,Request 对象实际上指的就是 scrapy.http.Request 的一个实例,它包含了 HTTP 请求的基本信息,用这个 Request 类我们可以构造 Request 对象发送 HTTP 请求,它会被 Engine 交给 Downloader 进行处理执行,返回一个 Response 对象。Request 的构造参数梳理如下:
- url: Request 的页面链接,即 Request URL。
- callback:Request 的回调方法,通常这个方法需要定义在 Spider 类里面,并且需要对应一个 response 参数,代表 Request 执行请求后得到的 Response 对象。如果这个 callback 参数不指定,默认会使用 Spider 类里面的 parse 方法。
- method:Request 的方法,默认是 GET,还可以设置为 POST、PUT、DELETE 等。
- meta:Request 请求携带的额外参数,利用 meta,我们可以指定任意处理参数,特定的参数经由 Scrapy 各个组件的处理,可以得到不同的效果。另外,meta 还可以用来向回调方法传递信息。
- body:Request 的内容,即 Request Body,往往 Request Body 对应的是 POST 请求,我们可以使用 FormRequest 或 JsonRequest 更方便地实现 POST 请求。
- headers:Request Headers,是字典形式。
- cookies:Request 携带的 Cookies,可以是字典或列表形式。
- encoding:Request 的编码,默认是 utf-8。
- prority:Request 优先级,默认是0,这个优先级是给 Scheduler 做 Request 调度使用的,数值越大,就越被优先调度并执行。
- dont_filter:Request 不去重,Scrapy 默认会根据 Request 的信息进行去重,使得在爬取过程中不会出现重复的请求,设置为 True 代表这个 Request 会被忽略去重操作,默认是 False。
- errback:错误处理方法,如果在请求过程中出现了错误,这个方法就会被调用。
- flags:请求的标志,可以用于记录类似的处理。
- cb_kwargs:回调方法的额外参数,可以作为字典传递。
值得注意的是,meta 参数是一个十分有用而且易扩展的参数,它可以以字典的形式传递,包含的信息不受限制,所以很多 Scrapy 的插件会基于 meta 参数做一些特殊处理。在默认情况下,Scrapy 就预留了一些特殊的 key 作为特殊处理。比如 request.meta['proxy'] 可以用来设置请求时使用的代理,request.meta['max_retry_times'] 可以设置用来设置请求的最大重试次数等。更多具体的内容可以参见:https://docs.scrapy.org/en/latest/topics/request-response.html
另外如上文所介绍的,Scrapy 还专门为 POST 请求提供了两个类 ------ FormRequest 和 JsonRequest,它们都是 Request 类的子类,我们可以利用 FormRequest 的 formdata 参数传递表单内容,利用 JsonRequest 的 json 参数传递 JSON 内容,其他的参数和 Request 基本是一致的。二者的详细介绍可以参考官方文档:
JsonRequest:https://docs.scrapy.org/en/latest/topics/request-response.html#jsonrequest
FormRequest:https://docs.scrapy.org/en/latest/topics/request-response.html#formrequest-objects
2.2 Response
源码位置:
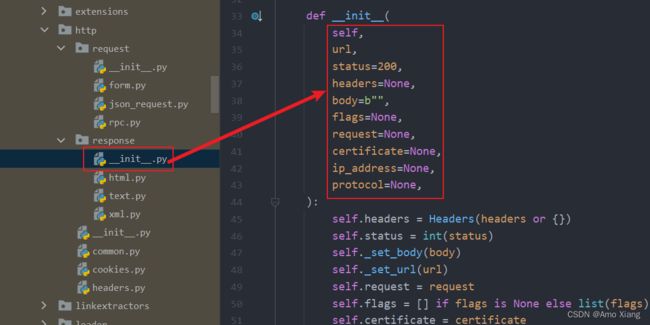
Request 由 Downloader 执行之后,得到的就是 Response 结果了,它代表的是 HTTP 请求得到的响应结果,同样地我们可以梳理一下其可用的属性和方法,以便我们做解析处理使用。
- url:Request URL。
- status:Response 状态码,如果请求成功就是 200。
- headers:Response Headers,是一个字典,字段是一一对应的。
- body:Response Body,这个通常就是访问页面之后得到的源代码结果了,比如里面包含的是 HTML 或者 JSON 字符串,但注意其结果是 bytes 类型。
- request:Response 对应的 Request 对象。
- certificate:是
twisted.internet.ssl.Certifucate类型的对象,通常代表一个 SSL 证书对象。 - ip_address:是一个 ipaddress.IPv4Address 或 IPv6Address 类型的对象,代表服务器的 IP 地址。
- urljoin:是对 URL 的一个处理方法,可以传入当前页面的相对 URL,该方法处理后返回的就是绝对 URL。
- follow/follow_all:是一个根据 URL 来生成后续 Request 的方法,和直接构造 Request 不同的是,该方法接收的 url 可以是相对 URL,不必一定是绝对 URL。
另外 Response 还有几个常用的子类,如 TextResponse 和 HtmlResponse, HtmlResponse 又是 TextResponse 的子类,实际上回调方法接收的 response 参数就是一个 HtmlResponse 对象,它还有几个常用的方法或属性。
text: 同 body 属性,但结果是 str 类型
encoding: Response 的编码,默认是 utf-8
selector: 根据 Response 的内容构造而成的 Selector 对象,利用它我们可以进一步调用 xpath、css 等方法进行结果的提取
xpath: 传入 XPath 进行内容提取,等同于调用 selector 的 xpath 方法
css: 传入CSS选择器进行内容提取,等同于调用 selector 的 css 方法
json: 是 Scrapy2.2新增的方法,利用该方法可以直接将text属性转换为JSON对象
以上便是对 Response 的基本介绍,关于 Response 更详细的解释可以参考官方文档:https://docs.scrapy.org/en/latest/topics/request-response.html#response-objects
小结:本小节介绍了 Request、Response 对象的基本数据结构,通过了解本节内容,我们便可以灵活地完成爬取逻辑的定制了。
三、实例演示
3.1 POST 请求
POST 请求主要是分为两种,一种是以 FormData 的形式提交表单,一种是发送 JSON 数据,二者分别可以使用 FormRequest 和 JsonRequest 来实现。分别发起两种 POST 请求,对比一下结果,示例代码如下:
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['www.httpbin.org']
# start_urls = ['https://www.httpbin.org/post']
start_url = 'https://www.httpbin.org/post'
# 大坑:注意这里的年龄千万不要写18 否则会报错 所有都以字符串的形式来表示
# 至于为什么可以自己去看源码
data = {"name": "Amo", "age": "18"}
def start_requests(self):
yield scrapy.http.FormRequest(self.start_url, callback=self.parse_response, formdata=self.data)
yield scrapy.http.JsonRequest(self.start_url, callback=self.parse_response,
data=self.data)
def parse_response(self, response, **kwargs):
print("text", response.text)
使用 start_requests() 方法生成了一个 FormRequest 和 JsonRequest,请求的页面链接修改为了 https://www.httpbin.org/post,它可以把 POST 请求的详情返回,另外 data 保持不变。运行结果如下图所示:

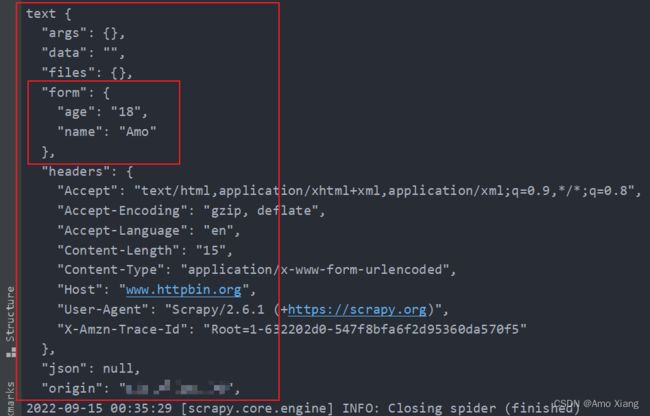
这里我们可以看到两种请求的效果。第一个 JsonRequest,我们可以观察到页面返回结果的 json 字段就是我们所请求时添加的 data 内容,这说明实际上是发送了 Content-Type 为 application/json 的 POST 请求,这种对应的就是发送 JSON 数据。
第二个 FormRequest,我们可以观察到页面返回结果的 form 字段就是我们请求时添加的 data 内容,这说明实际上是发送了 Content-Type 为 application/x-www-form-urlencoded 的 POST 请求,这种对应的就是表单提交。
这两种 POST 请求的发送方式我们需要区分清楚,并根据服务器的实际需要进行选择。
3.2 GET 请求及响应信息打印
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['www.httpbin.org']
# # 起始URL列表,当我们没有实现start_requests方法时,默认会从这个列表开始抓取
# start_urls = ['https://www.httpbin.org/get']
start_url = 'https://www.httpbin.org/get'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
cookies = {"name": "amo", "age": "18"}
def start_requests(self):
for offset in range(5):
url = self.start_url + f"?offset={offset}"
yield scrapy.Request(url, headers=self.headers, cookies=self.cookies,
callback=self.parse_response, meta={"offset": offset})
# start_url = 'https://www.httpbin.org/post'
# def parse(self, response, **kwargs): 当Response没有指定回调方法时,该方法会默认被调用
def parse_response(self, response, **kwargs):
print(response.url) # 请求页面的URL,即Request URL
print(response.request) # response对应的request对象
print(response.status) # 状态码,即 Response Status Code
print(response.headers) # 响应头,即 Response Headers
print(response.text) # 响应体,即 Response Body
print(response.meta) # 一些附加信息,这些参数往往会附在 meta 属性里
运行结果如下所示:

以上省略了部分结果,可以看到,这里分别打印出了 url、request、status、headers、text、meta 信息。
注意:Scrapy 框架几乎是 Python 爬虫学习和工作过程中必须掌握的框架,需要好好钻研和掌握。
至此今天的案例就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习 Python 基础的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!