web自动化测试:Selenium+Python基础方法封装
01 目的
web自动化测试作为软件自动化测试领域中绕不过去的一个“香饽饽”,通常都会作为广大测试从业者的首选学习对象,相较于C/S架构的自动化来说,B/S有着其无法忽视的诸多优势,从行业发展趋、研发模式特点、测试工具支持,其整体的完整生态已经远远超过了C/S架构方面的测试价值。这篇文章,我们将深入探讨在Python中如何将Selenium的一些方法进行封装和二开,以便我们更高效地在自己的测试项目中灵活运用。
02 封装
既然选择了Python这门语言来实现web自动化,那我们就不得不讲到一个重要的概念,那就是面向对象编程理念中的封装。就字面意思来理解的话,就像是把各种物品放入一个箱子内,日后需要使用的话就必须从这个箱子里拿才可以获取那个放入的物品。而这个比喻内的箱子就是python内的类,而各类物品则是我们自己根据需要自定义的各种属性和数据、方法,后续需要使用这些属性、数据、方法时,只要引入对应的类并实例化即可。
2.1 基础功能分装
我们就先从最基本的浏览器操作开始,这里会遵循一些简单的日常业务操作进行介绍,并且对类内的方法进行拆解,逐一介绍。文中的代码会比较简单,也是方便大家可以更顺利的根据这些功能封装进行二开,无论是健壮性加强或者业务判断都可以自由添加其中。
我们定义的类名为:BrowserDriver,构造函数传入browser。

2.1.1 开启浏览器

这里解释一下,ChromeOptions()这个方法是chrome浏览器的参数对象,用来配置浏览器启动时的一些参数与属性,这里添加的是浏览器启动后不显示“正受到自动测试软件的控制”的提示,用法比较简单,add_experimental_option这边是添加试验性质的参数,另外比较常用的还有add_argument,add_extension(添加启动项、添加扩展)等方法。
FirefoxProfile()这个是用来指定火狐浏览器内用户设定档案,一般可以开启或关闭某些浏览器内的功能来达到我们的测试业务需求,如果你用selenium启动火狐的话都会默认新建一个这样的档案,那在代码中的话你可以指定档案的保存路径并在后续对其指定功能进行开启或关闭。
2.1.2 检查URL
封装的功能比较简单的,这里检查URL内是否含有http,大家可以根据自己的需求将判断逻辑这块加强,将错误之后抛异常的动作实现成自动添加http或https至url的开头处等都可。

如果你的UI测试中不需要将用例的结果进行数据持久化,可以替换两个判断分支中的业务操作,打印到后台还是写入文件根据自己的测试流程要求来自定义即可。这里的数据库操作使用了sqlalchemy模块,我们定义db创建一个ORM基类,拿博主的脚本举例,我的ORM模型名(表名)为TestCaseResult,将各个测试场景(URL格式检查与浏览器对象检查)下的错误场景报错信息写入。我们的基本信息如下,执行后插入一条数据,包含错误代码,结果具体信息与一个复合用例的标识判断。err_message = TestCaseResult(status=‘100200’, result=“URL格式有误”, is_composite=‘False’)可以看出错误信息的内容还是比较简单的。我们只需在执行过后检查对应的自动化平台结果页面即可看到对应报错信息。
另外使用sqlalchemy操作数据库前记得创建对应的数据库对象。

这里在连接参数后有三个选项,分别为:
echo: 当设置为True时会将orm语句转化为sql语句打印,一般debug的时候可用
pool_size: 连接池的大小,默认为5个,设置为0时表示连接无限制
pool_recycle: 设置时间以限制数据库多久没连接自动断开
当然我们本着易维护的思想理念,还是将数据库接连的动作进行常量设定。
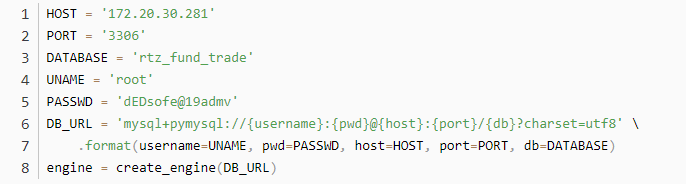
接下去使用engine = create_engine(DB_URI,echo=True)进行数据库的连接,因为操作数据库必须创建会话来进行控制,所以我们还需要使用session = sessionmaker(engine)()创建一个会话。之后就如最初的代码中所进行的操作来进行数据库的数据写入。当然以上说的这些操作大家应该将其也封装为一个或者多个类。
2.1.3 浏览器窗口操作
窗口操作也是比较常用的基础功能之一,以下将基本的最大化、最小化、前进、后退、刷新、设定尺寸大小封装起来。之后会判断可变参数的长度,根据传入的长度不同进行对应的窗口操作。

2.1.4 切换窗口
另一个日常较为频繁的业务操作就是切换窗口,也就是我们的标签页,我们可以使用遍历的方式获得一个当前所有的窗口列表,通过传递默认参数title来进行当前窗口的切换,直到匹配到与title相同的窗口。

2.1.5 获取页面元素
元素定位自然不必多说了,web自动化中的基础操作,也是日常接触的最多的功能,封装的功能只需传两个参数,定位方式与元素对应的属性值。这里可以改造的地方还是有很多的。比如不手动指定,通过持久化或者文件指定对应要查找的元素,需要定位的元素属性也可以通过其他方式进行抽出,总之二开的话大家可以根据业务需求进行灵活多变的定制。另外elements的定位就不演示了,大家举一反三即可。

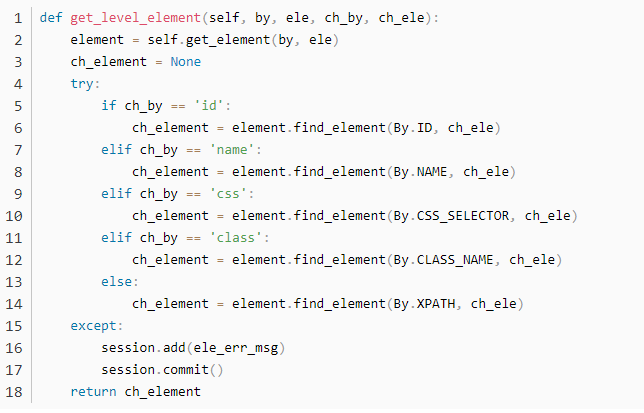
2.1.6 层级元素定位
层级元素定位的实现逻辑其实就是根据链式写法产生的,原生的find_element()方法是可以从当前捕捉到的元素层级开始往下再次定位的,我们就利用这一特性,先使用上一个定位元素的方法get_element()来再一次进行find_element()方法,这样就可以实现层级元素的定位操作。这里有一点需要注意的是,虽然原理如此,但切不可偷懒,调用两次get_element(),因为这个方法本身含有driver对象,两次调用会使程序无法识别具体使用的是哪个对象,从而导致报错。
2.1.7 信息输入操作
输入操作的封装也是相对比较直白的,定位元素并传值即可。需要注意的点就是如果定位的元素本身出了问题的话,我们可以利用判断条件来规避一些异常的情况。

2.1.8 点击操作
逻辑同信息输入操作,大家自行体会。

2.1.9 控件操作
控件的种类还是比较多的,这里就举个比较典型的例子。下面封装的是一个复选框(勾选框),这里的传参前两个就不介绍了,最后一个表示复选框目前的勾选状态,我这里定义的0为未勾选,1为已勾选状态。这里的实现逻辑大致为:判断对象是否为勾选状态,再判断是否需要勾选,结合两种状态一般就是有4个结果,勾选状态下勾选和不勾选、未勾选状态下勾选和不勾选。大家可以根据以下的判断逻辑解读一下。

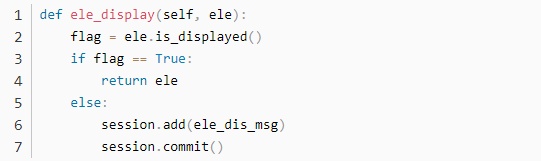
2.1.10 元素可见性操作
对于页面上的某些元素是否可见,我们也可以封装一个方法,用来增强整体的元素定位方法的健壮性,该方法可以直接在元素定位时进行调用,将原有的返回对象进行预先判断。
以上就是一些日常工作中使用的比较频繁的selenium内置方法的封装示例。
资源分享【这份资料必须领取~】
下方这份完整的软件测试视频学习教程已经上传CSDN官方认证的二维码,朋友们如果需要可以自行免费领取 【保证100%免费】

