Note14: selenium+python github测试框架
开源项目: GitHub - defnngj/xtest: test framework demo
目录
1.搭建测试框架
2.Web UI 自动化测试框架-包含如下内容
1.API的二次开发/封装
2.全局启动和关闭浏览器
3.参数化
4. 断言
1.搭建测试框架
开源项目一般都在github或者gitee,由于github访问国外网站可能网速较慢可以使用gitee。但大部分开源项目都在github因此这里以github实践.
1.打开github官网GitHub: Where the world builds software · GitHub,注册账号
2.注册成功后,点击新建框架

3. 为框架命名,以及选择相关配置
.gitignore:提交git时候忽略哪些文件类型,可直接选择python
LICENSE:商业协议,如别人在使用我的框架时候必须自己的代码也开源等,可直接选择apache license 2
README.md
4.点击创建
5.进入git官网Git - Downloading Package下载git并安装在本地
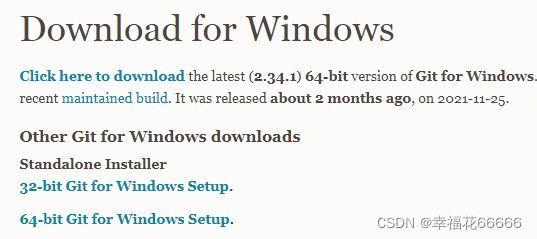
6.进入本地cmd窗口,可以输入git查看安装成功。在某磁盘创建目录如D盘github,然后cmd中进入该目录cd .\github\,进入目录后克隆自己创建的git 项目,命令:git clone https://XXX

7.下载完成后再自己本地的PyCharm中打开该项目:

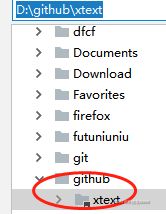
8.如果提交时候不想忽略某文件,可在.gitignore中删除;license为刚才选择商业协议等。

9.目前打开是项目目录,需要再创建一个安装目录。

10.1安装目录新建完成后会自动生成一个空的_init_.py文件
__init__.py 文件的作用是将文件夹变为一个Python模块,Python 中的每个模块的包中,都有__init__.py 文件。
通常__init__.py 文件为空,但是我们还可以为它增加其他的功能。我们在导入一个包时,实际上是导入了它的__init__.py文件。这样我们可以在__init__.py文件中批量导入我们所需要的模块,而不再需要一个一个的导入。
摘自:https://www.jb51.net/article/92863.htm
| 1 2 3 4 5 6 7 8 9 |
|
10.2然后可以将selenium API封装起来. webdriver.py:
import unittest
from .config import XTest
class TestCase(unittest.TestCase):
# 打开浏览器
def open(self,url):
XTest.driver.get(url)
10.3驱动可以写在config.py文件中:
class XTest:
driver=None
10.4 调用可以写在main方法中, runner.py
import unittest
from selenium import webdriver
from .config import XTest
browser_list=["Chrome","Firefox"]
def main(path,browser):
print("222")
if browser not in browser_list:
raise NameError("不支持{browser}浏览器",1)
elif browser =="Chrome":
XTest.driver=webdriver.Chrome()
elif browser =="Firefox":
XTest.driver=webdriver.Firefox()
suit=unittest.defaultTestLoader.discover(start_dir=path)
runner=unittest.TextTestRunner()
runner.run(suit)
11. 在外部创建test_xtest.py文件,测试xtext
import xtext
class BaiduTest(xtext.TestCase):
def test_baidu(self):
print("111")
self.open("https://www.baidu.com")
if __name__ == '__main__':
print("33")
xtext.main(path=r"D:\\github\\xtext\\",browser="Chrome")
问题:运行时候发现main方法并没有执行,之执行了test_baidu
原因:
之前所执行代码对应的方式是Run 'Unittests in xxx.py',PyCharm默认执行Unittests类的单元测试,忽略了if __name__ == '__main__':的执行,也就没有执行整个xxx.py文件
方案:
在PyCharm顶部的工具栏上,点击 Run-->Run...在弹出的Run选择框中,点击与文件xx.py同名的选项
(Run xx.py相当于执行整个xx.py文件,也就包含if __name__ == '__main__':其下的代码了)
摘自:[PyCharm] if __name__ == '__main__': 其下的代码未执行_解决方案 - 简书
2.Web UI 自动化测试框架-包含如下内容
1.API的二次开发/封装
2.全局启动和关闭浏览器
3.测试报告的封装
4.断言
5.参数化
6.安装 setup.py
7.命令行工具
13.测试报告的封装
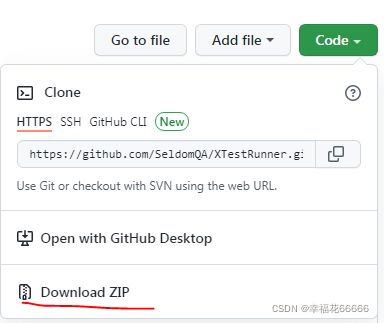
下载地址:https://github.com/SeldomQA/XTestRunner
https://github.com/SeldomQA/XTestRunner
可以用git下载,也可以直接下载ZIP包
目前代码:
1.API的二次开发/封装
2.全局启动和关闭浏览器

init:
from xtext.runner import main from .webdriver import TestCase
config:
class XTest:
driver=None
timeout=None
runner:
import unittest from selenium import webdriver from xtext.config import XTest import os # from xtext.TestRunner.HTMLTestRunner import HTMLTestRunner browser_list=["Chrome","Firefox"] def main(path=None,browser=None,timeout=5): if browser==None: XTest.driver = webdriver.Chrome() elif browser =="Chrome": XTest.driver=webdriver.Chrome() elif browser =="Firefox": XTest.driver=webdriver.Firefox() elif browser not in browser_list: raise NameError("不支持的浏览器类型:"+"%s"%browser) # 全局超时时间 XTest.timeout = timeout if path==None: path=os.getcwd() suit=unittest.defaultTestLoader.discover(start_dir=path) #text格式 runner=unittest.TextTestRunner() runner.run(suit) # HTML格式的报告/XML格式的报告 # with(open('result.html', 'wb')) as fp: # runner = HTMLTestRunner(stream=fp) # runner.run(suit) #全局关闭浏览器 if XTest.driver is not None: XTest.driver.quit()
webdriver:
import unittest from .config import XTest import time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException LOCATOR_LIST = { 'css': By.CSS_SELECTOR, 'id_': By.ID, 'name': By.NAME, 'xpath': By.XPATH, 'link_text': By.LINK_TEXT, 'partial_link_text': By.PARTIAL_LINK_TEXT, 'tag': By.TAG_NAME, 'class_name': By.CLASS_NAME, } class TestCase(unittest.TestCase): # 元素定位的封装方法2:按照动作分 def __find_element(self, **kwargs): ''' 定位元素 :param kwargs: :return: ''' if not kwargs: raise ValueError("Please specify a locator") if len(kwargs) > 1: raise ValueError("Please specify only one locator") by, value = next(iter(kwargs.items())) # 取值 try: LOCATOR_LIST[by] except KeyError: raise ValueError("Element type is not support") if by == "id_": self.__wait_element(By.ID,value) elem=XTest.driver.find_element(By.ID,value) elif by == "name": self.__wait_element(By.NAME, value) elem = XTest.driver.find_element(By.NAME, value) elif by == "class_name": self.__wait_element(By.CLASS_NAME, value) elem = XTest.driver.find_element(By.CLASS_NAME, value) elif by == "tag": self.__wait_element(By.TAG_NAME, value) elem = XTest.driver.find_element(By.TAG_NAME, value) elif by == "xpath": self.__wait_element(By.XPATH, value) elem = XTest.driver.find_element(By.XPATH, value) elif by == "link_text": self.__wait_element(By.LINK_TEXT, value) elem = XTest.driver.find_element(By.LINK_TEXT, value) elif by == "partial_link_text": self.__wait_element(By.PARTIAL_LINK_TEXT, value) elem = XTest.driver.find_element(By.PARTIAL_LINK_TEXT, value) elif by == "css": self.__wait_element(By.CSS_SELECTOR, value) elem = XTest.driver.find_element(By.CSS_SELECTOR, value) else: raise ValueError("s%"%by +"类型不支持") return elem def send_text(self,text,clear=False,enter=False,**kwargs): ''' 输入 :param text: 文本 :param clear: 是否清除输入框 :param enter: 是否回车 :param kwargs: :return: ''' elem=self.__find_element(**kwargs) if clear is True: elem.clear() elem.send_keys(text) if enter is True: elem.send_keys("\n") def __wait_element(self,by,value): ''' 元素显示等待 :param by: :param value: :return: ''' try: WebDriverWait(XTest.driver, XTest.timeout, 0.5).until(EC.visibility_of_element_located((by, value))) except TimeoutException: raise TimeoutException("查找元素超时") def click(self,**kwargs): ''' 元素点击 :param kwargs: :return: ''' elem=self.__find_element(**kwargs) elem.click() def get_text(self,**kwargs): ''' 获取文本 :param kwargs: :return: ''' elem=self.__find_element(**kwargs) return elem.text def open(self,url): '''打开浏览器''' XTest.driver.get(url) def close(self): ''' 关闭浏览器,如果有多个窗口,只关闭一个 :return: ''' XTest.driver.close() def close_all(self): ''' 关闭浏览器,如果有多个,全部关闭 :return: ''' XTest.driver.quit() def sleep(self,sec): ''' 休眠 :param sec: 单位秒 :return: ''' time.sleep(sec) #元素定位的封装方法1:按照8种定位方式分 class XPATH(): def __init__(self,xpath): self.ele=XTest.driver.find_element(By.XPATH, xpath) def click(self): self.ele.click() def set_text(self,text): self.ele.send_keys(text) class Id(): def __init__(self, id): self.elem = XTest.driver.find_element(By.ID, id) def set_text(self, text): self.elem.send_keys(text) def click(self): self.elem.click() class CSS(): def __init__(self, css): self.elem = XTest.driver.find_element(By.CSS_SELECTOR, css) def set_text(self, text): self.elem.send_keys(text) def click(self): self.elem.click()
至此,1API的二次开发/封装 和 2.全局启动和关闭浏览器完成
3.参数化
即数据驱动(针对多个用例,步骤一样,执行多个不同的数据)
安装: pip install parameterized
导包:from parameterized import parameterized
def test_baidu1(self,_,keyword): 第一个参数道代表名称case1/case2,第二个参数代表关键字)
功能层面的使用:
import xtext
from parameterized import parameterized
class BaiduTest(xtext.TestCase):
@parameterized.expand([
("case1", "hengge"),
("case2", "huarui is the best"),
]
)
def test_baidu1(self,_,keyword):
self.open("https://www.baidu.com")
self.sleep(2)
self.XPATH("//*[@id='kw']").set_text(keyword)
self.XPATH("//*[@id='su']").click()
if __name__ == '__main__':
# xtext.main(path=r"D:\\github\\xtext\\",browser="Chrome") #代表该执行文件的目录路径
xtext.main(None,"Chrome",timeout=2)
集成到框架:



为了更简洁对data文件进行修改:注释掉类data,对parameterized类的parameterized方法进行重写,并重命名为data,把原parameterized方法中相关的包导入进来
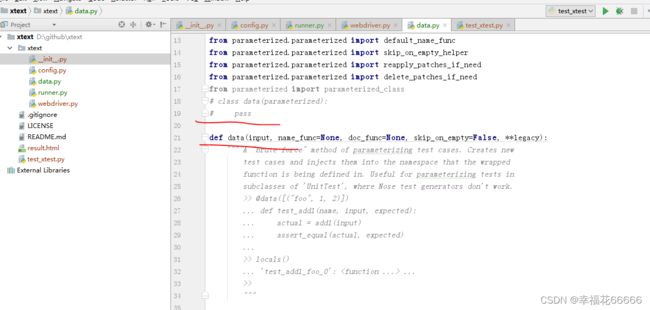
至此,实现了数据参数化。
放开格局,接下来实现文件参数化:

在xtest下创建文件,data.json,或者csv格式,xml格式。至此,代码段如下:
__init__.py
from xtext.runner import main
from .webdriver import TestCase
from .data import data,file_data,date_classconfig.py
class XTest:
driver=None
timeout=Nonedata.py
from parameterized import parameterized
import os
import csv
import json
import warnings
import codecs
import inspect as sys_inspect
from itertools import islice
from functools import wraps
from parameterized.parameterized import inspect
from parameterized.parameterized import parameterized
from parameterized.parameterized import default_doc_func
from parameterized.parameterized import default_name_func
from parameterized.parameterized import skip_on_empty_helper
from parameterized.parameterized import reapply_patches_if_need
from parameterized.parameterized import delete_patches_if_need
from parameterized import parameterized_class
# class data(parameterized):
# pass
def file_data(file="",line=0):
'''
数据文件参数化
:param file:
:param line: csv文件从第几行开始读取
:return:
'''
#python读取Jason文件
if file is None:
raise FileNotFoundError("请指定数据文件")
#文件后缀名判断
# print(file.split(".")[-1])
file_type=file.split(".")[-1]
if file_type=="json":
with open(file,"r") as load_f:
load_f=json.load(load_f)
print(load_f)
return data(load_f)
elif file_type=="csv":
csv_obj = csv.reader(codecs.open(file, 'r', 'utf_8_sig'))
data_list = []
for line in islice(csv_obj, line, None):
data_list.append(line)
return data(data_list)
#可继续扩展其他格式,如XML
else:
raise TypeError("文件类型不支持")
def data(input, name_func=None, doc_func=None, skip_on_empty=False, **legacy):
""" A "brute force" method of parameterizing test cases. Creates new
test cases and injects them into the namespace that the wrapped
function is being defined in. Useful for parameterizing tests in
subclasses of 'UnitTest', where Nose test generators don't work.
>> @data([("foo", 1, 2)])
... def test_add1(name, input, expected):
... actual = add1(input)
... assert_equal(actual, expected)
...
>> locals()
... 'test_add1_foo_0': ...
>>
"""
if "testcase_func_name" in legacy:
warnings.warn("testcase_func_name= is deprecated; use name_func=",
DeprecationWarning, stacklevel=2)
if not name_func:
name_func = legacy["testcase_func_name"]
if "testcase_func_doc" in legacy:
warnings.warn("testcase_func_doc= is deprecated; use doc_func=",
DeprecationWarning, stacklevel=2)
if not doc_func:
doc_func = legacy["testcase_func_doc"]
doc_func = doc_func or default_doc_func
name_func = name_func or default_name_func
def parameterized_expand_wrapper(f, instance=None):
frame_locals = inspect.currentframe().f_back.f_locals
parameters = parameterized.input_as_callable(input)()
if not parameters:
if not skip_on_empty:
raise ValueError(
"Parameters iterable is empty (hint: use "
"`parameterized.expand([], skip_on_empty=True)` to skip "
"this test when the input is empty)"
)
return wraps(f)(skip_on_empty_helper)
digits = len(str(len(parameters) - 1))
for num, p in enumerate(parameters):
name = name_func(f, "{num:0>{digits}}".format(digits=digits, num=num), p)
# If the original function has patches applied by 'mock.patch',
# re-construct all patches on the just former decoration layer
# of param_as_standalone_func so as not to share
# patch objects between new functions
nf = reapply_patches_if_need(f)
frame_locals[name] = parameterized.param_as_standalone_func(p, nf, name)
frame_locals[name].__doc__ = doc_func(f, num, p)
# Delete original patches to prevent new function from evaluating
# original patching object as well as re-constructed patches.
delete_patches_if_need(f)
f.__test__ = False
return parameterized_expand_wrapper
#很少用,和数据参数化的区别是在测试报告会生成2个类;如果用例是有关联的,先执行一个再执行下一个用参数化类更好用,但是麻烦
def date_class(attrs, input_values):
"""
参数化类
:param attrs:
:param input_values:
:return:
"""""
return parameterized_class(attrs, input_values)
runner.py
import unittest
from selenium import webdriver
from xtext.config import XTest
import os
# from xtext.TestRunner.HTMLTestRunner import HTMLTestRunner
browser_list=["Chrome","Firefox"]
def main(path=None,browser=None,timeout=5):
if browser==None:
XTest.driver = webdriver.Chrome()
elif browser =="Chrome":
XTest.driver=webdriver.Chrome()
elif browser =="Firefox":
XTest.driver=webdriver.Firefox()
elif browser not in browser_list:
raise NameError("不支持的浏览器类型:"+"%s"%browser)
# 全局超时时间
XTest.timeout = timeout
if path==None:
path=os.getcwd()
suit=unittest.defaultTestLoader.discover(start_dir=path)
#text格式
runner=unittest.TextTestRunner()
runner.run(suit)
# HTML格式的报告/XML格式的报告
# with(open('result.html', 'wb')) as fp:
# runner = HTMLTestRunner(stream=fp)
# runner.run(suit)
#全局关闭浏览器
if XTest.driver is not None:
XTest.driver.quit()
webdriver.py
import unittest
from .config import XTest
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
LOCATOR_LIST = {
'css': By.CSS_SELECTOR,
'id_': By.ID,
'name': By.NAME,
'xpath': By.XPATH,
'link_text': By.LINK_TEXT,
'partial_link_text': By.PARTIAL_LINK_TEXT,
'tag': By.TAG_NAME,
'class_name': By.CLASS_NAME,
}
class TestCase(unittest.TestCase):
# 元素定位的封装方法2:按照动作分
def __find_element(self, **kwargs):
'''
定位元素
:param kwargs:
:return:
'''
if not kwargs:
raise ValueError("Please specify a locator")
if len(kwargs) > 1:
raise ValueError("Please specify only one locator")
by, value = next(iter(kwargs.items())) # 取值
try:
LOCATOR_LIST[by]
except KeyError:
raise ValueError("Element type is not support")
if by == "id_":
self.__wait_element(By.ID,value)
elem=XTest.driver.find_element(By.ID,value)
elif by == "name":
self.__wait_element(By.NAME, value)
elem = XTest.driver.find_element(By.NAME, value)
elif by == "class_name":
self.__wait_element(By.CLASS_NAME, value)
elem = XTest.driver.find_element(By.CLASS_NAME, value)
elif by == "tag":
self.__wait_element(By.TAG_NAME, value)
elem = XTest.driver.find_element(By.TAG_NAME, value)
elif by == "xpath":
self.__wait_element(By.XPATH, value)
elem = XTest.driver.find_element(By.XPATH, value)
elif by == "link_text":
self.__wait_element(By.LINK_TEXT, value)
elem = XTest.driver.find_element(By.LINK_TEXT, value)
elif by == "partial_link_text":
self.__wait_element(By.PARTIAL_LINK_TEXT, value)
elem = XTest.driver.find_element(By.PARTIAL_LINK_TEXT, value)
elif by == "css":
self.__wait_element(By.CSS_SELECTOR, value)
elem = XTest.driver.find_element(By.CSS_SELECTOR, value)
else:
raise ValueError("s%"%by +"类型不支持")
return elem
def send_text(self,text,clear=False,enter=False,**kwargs):
'''
输入
:param text: 文本
:param clear: 是否清除输入框
:param enter: 是否回车
:param kwargs:
:return:
'''
elem=self.__find_element(**kwargs)
if clear is True:
elem.clear()
elem.send_keys(text)
if enter is True:
elem.send_keys("\n")
def __wait_element(self,by,value):
'''
元素显示等待
:param by:
:param value:
:return:
'''
try:
WebDriverWait(XTest.driver, XTest.timeout, 0.5).until(EC.visibility_of_element_located((by, value)))
except TimeoutException:
raise TimeoutException("查找元素超时")
def click(self,**kwargs):
'''
元素点击
:param kwargs:
:return:
'''
elem=self.__find_element(**kwargs)
elem.click()
def get_text(self,**kwargs):
'''
获取文本
:param kwargs:
:return:
'''
elem=self.__find_element(**kwargs)
return elem.text
def open(self,url):
'''打开浏览器'''
XTest.driver.get(url)
def close(self):
'''
关闭浏览器,如果有多个窗口,只关闭一个
:return:
'''
XTest.driver.close()
def close_all(self):
'''
关闭浏览器,如果有多个,全部关闭
:return:
'''
XTest.driver.quit()
def sleep(self,sec):
'''
休眠
:param sec: 单位秒
:return:
'''
time.sleep(sec)
#元素定位的封装方法1:按照8种定位方式分
class XPATH():
def __init__(self,xpath):
self.ele=XTest.driver.find_element(By.XPATH, xpath)
def click(self):
self.ele.click()
def set_text(self,text):
self.ele.send_keys(text)
class Id():
def __init__(self, id):
self.elem = XTest.driver.find_element(By.ID, id)
def set_text(self, text):
self.elem.send_keys(text)
def click(self):
self.elem.click()
class CSS():
def __init__(self, css):
self.elem = XTest.driver.find_element(By.CSS_SELECTOR, css)
def set_text(self, text):
self.elem.send_keys(text)
def click(self):
self.elem.click()
data.csv (xtext右键new-file)
name,keyword
case1,huahua
case2,hengdata.json
[
["case1", "unittest"],
["case2", "selenium "],
["case3", "python"]
]text_xtext.py
import xtext
from xtext import data
from xtext import file_data,date_class
# @date_class(
# ("name", "keyword"),
# [("case1", "xtest"),
# ("case2", "python")
# ])
class BaiduTest(xtext.TestCase):
@file_data("data.json",3)
def test_baidu1(self,_,keyword):
print("keyword-->",keyword)
self.open("https://www.baidu.com")
self.sleep(2)
self.XPATH("//*[@id='kw']").set_text(keyword)
self.XPATH("//*[@id='su']").click()
# def test_baidu2(self):
# self.open("https://www.baidu.com")
# self.send_text(text="huahua",xpath="//*[@id='kw']")
# self.click(xpath="//*[@id='su']")
#
# def test_baidu3(self):
# self.open("https://www.baidu.com")
# text=self.get_text(xpath="(//*[@class=\"s-bottom-layer-content\"]/p/a)[1]")
# print(text)
if __name__ == '__main__':
# xtext.main(path=r"D:\\github\\xtext\\",browser="Chrome") #代表该执行文件的目录路径
xtext.main(None,"Chrome",timeout=2)
4. 断言
由于webdriver主要是对selenium API的封装,所以把断言单独写一个文件 case.py
case.py的类继承了unittest.TestCase,webdriver.py的类也继承了这个,所以可以把webdriver.py的类继承关系去掉。

5.安装
6.命令行工具-脚手架/项目模板
7.logger日志